软件下载
- 夸克下载:****https://pan.quark.cn/s/0bb78d115783
- 更多资源: https://a-xing.top/4317.html
软件介绍
这是一个离线运行的本地语音识别转文字工具,基于 fast-whipser 开源模型,可将视频/音频中的人类声音识别并转为文字,可输出json格式、srt字幕带时间戳格式、纯文字格式。
fast-whisper 开源模型有 tiny/base/small/medium/large-v3, 内置 tiny 模型,tiny->large-v3识别效果越来越好,但所需计算机资源也更多,根据需要可自行下载后解压到 models 目录下即可。

软件特点
- **支持离线运行:**不联网即可使用
- **支持导出多种格式****:**支持导出 JSON、SRT 字幕(带时间戳)、TXT 纯文本三种格式。
- **内置开源大模型:**置 tiny 模型,同时支持下载 base/small/medium/large-v3 等模型替换,平衡识别精度与硬件性能。
- **支持硬件加速:**支持 CPU 运行,若配置 CUDA 环境可修改为 GPU 加速,提升识别速度。
- **操作简单:**解压运行即可使用
软件使用
软件解压
软件下载解压即可,解压路径尽可能设置为非中文路径下
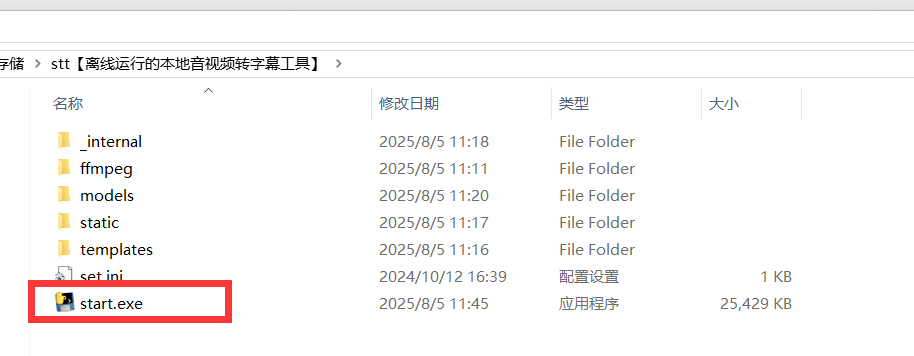
软件运行
双击 start.exe ,等待自动打开浏览器窗口即可**(若未能自动打开,请手动打开网址 http://127.0.0.1:9977)**
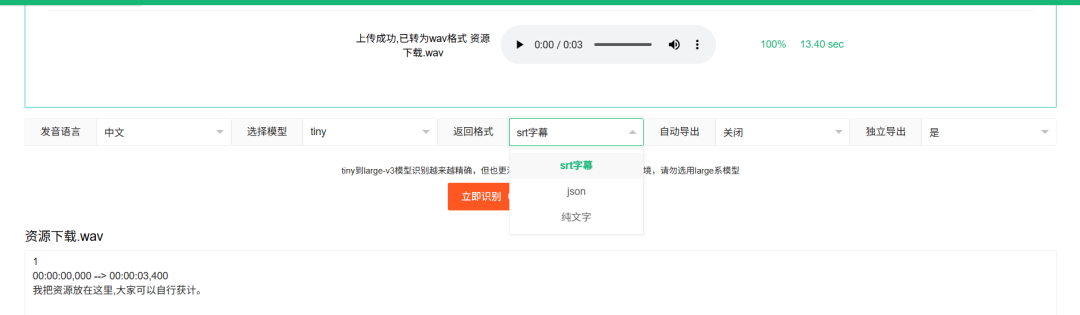
上传之后就可以识别了
支持导出三个格式
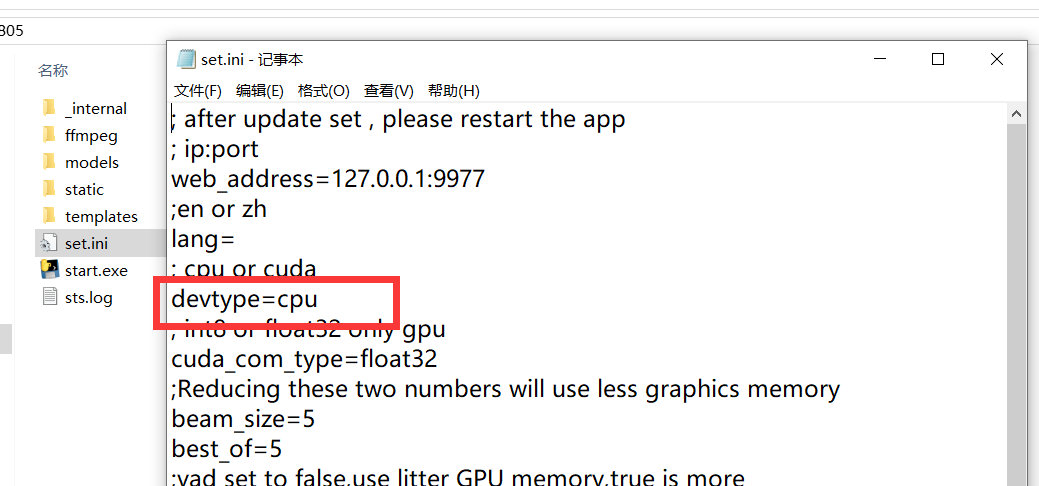
使用GPU
如果机器拥有英伟达GPU,并正确配置了CUDA环境,将自动使用CUDA加速注意:默认使用 cpu 运算,如果确定使用英伟达显卡,并且配置好了cuda 环境,请修改 set.ini 中 devtype=cpu为devtype=cuda,并重新启动,可使用cuda加速