目录
[一、为什么需要 MCP?](#一、为什么需要 MCP?)
[二、MCP 的核心思想:让模型看到"工具说明",让系统执行"工具调用"](#二、MCP 的核心思想:让模型看到“工具说明”,让系统执行“工具调用”)
[三、AI 是如何判断是否需要调用 MCP 工具的?](#三、AI 是如何判断是否需要调用 MCP 工具的?)
[四、MCP 的完整调用流程](#四、MCP 的完整调用流程)
[五、MCP 工具为什么有时不会被调用?](#五、MCP 工具为什么有时不会被调用?)
[1. 工具描述太抽象](#1. 工具描述太抽象)
[2. 参数不完整](#2. 参数不完整)
[3. 系统 Prompt 限制](#3. 系统 Prompt 限制)
[4. 模型认为可以直接回答](#4. 模型认为可以直接回答)
[六、MCP 协议层与传输层](#六、MCP 协议层与传输层)
[七、stdio 传输层](#七、stdio 传输层)
[八、SSE 传输层](#八、SSE 传输层)
[九、stdio 和 SSE 怎么选?](#九、stdio 和 SSE 怎么选?)
[十、使用 Spring AI 构建自定义 MCP 天气服务](#十、使用 Spring AI 构建自定义 MCP 天气服务)
[1. McpServerApplication](#1. McpServerApplication)
[2. OpenMeteoService](#2. OpenMeteoService)
[十一、如何把一个 Java 方法变成 MCP 工具?](#十一、如何把一个 Java 方法变成 MCP 工具?)
[十二、OpenMeteoService 的实现思路](#十二、OpenMeteoService 的实现思路)
[第一步:初始化 RestClient](#第一步:初始化 RestClient)
[第三步:调用天气 API](#第三步:调用天气 API)
[十三、MCP Server 配置示例](#十三、MCP Server 配置示例)
[十四、结合 Lynxe/JManus 使用 MCP](#十四、结合 Lynxe/JManus 使用 MCP)
[十五、设计 MCP 工具的关键原则](#十五、设计 MCP 工具的关键原则)
[1. 工具名称要清晰](#1. 工具名称要清晰)
[2. description 要像业务说明,而不是技术说明](#2. description 要像业务说明,而不是技术说明)
[3. 参数 schema 要明确](#3. 参数 schema 要明确)
[4. 不要让一个工具做太多事](#4. 不要让一个工具做太多事)
[5. 返回结果尽量结构化](#5. 返回结果尽量结构化)
[6. 错误信息要可理解](#6. 错误信息要可理解)
[十六、MCP 和 Function Calling 的区别](#十六、MCP 和 Function Calling 的区别)
一、为什么需要 MCP?
过去我们在做 AI 应用时,经常会遇到一个问题:大模型本身很聪明,但它并不能直接访问企业内部系统,也不能天然知道实时数据。
比如用户问:
帮我查一下订单 8899 现在运输到哪里了?
如果只依赖大模型自身能力,它最多只能根据已有知识"编一个看起来合理的回答"。但订单状态是实时数据,必须查询业务系统、数据库、接口或者第三方服务。
再比如:
查询一下合肥今天的天气,并给出未来 7 天预报。
这个问题也不能靠模型凭空生成,因为天气数据具有实时性,需要调用外部天气 API。
因此,AI 应用真正落地时,模型不能只是一个"会聊天的大脑",还需要具备调用外部系统的能力。这个能力可以是:
- 查询数据库;
- 调用 HTTP 接口;
- 读取本地文件;
- 分析日志;
- 访问浏览器;
- 操作企业内部系统;
- 调用业务服务;
- 获取实时天气、订单、用户、车辆、运单等数据。
这时 MCP 就出现了。
MCP,全称是 Model Context Protocol,可以理解为一种让大模型和外部工具进行标准化连接的协议。它的目标不是让每个 AI 应用都重新发明一套工具调用规范,而是提供一种统一的方式,让模型、Agent、工具服务之间能够按照约定通信。
简单来说:
MCP 是大模型连接外部工具和上下文能力的一套标准协议。
它解决的是 AI 应用工程化过程中的一个核心问题:
如何让大模型稳定、规范、可扩展地使用外部工具?
在没有 MCP 之前,我们当然也可以让模型调用工具,比如通过 Function Calling、自定义插件、HTTP 接口封装等方式。但问题是,不同平台、不同框架、不同工具之间的接入方式不统一,迁移成本高,复用性差。
而 MCP 想做的事情,就是把工具服务抽象成一个标准协议。这样一个工具服务,只要按照 MCP 的规范暴露出来,理论上就可以被不同的 MCP Client、Agent 或 Host 使用。
对于企业 AI 应用来说,这个价值非常明显。我们可以把已有的业务能力封装成 MCP 工具,例如:
- 用户信息查询工具;
- 订单状态查询工具;
- 运单轨迹查询工具;
- 天气查询工具;
- 文件解析工具;
- 风控评分工具;
- 图片审核工具;
- 日志分析工具;
- 数据库查询工具。
模型并不需要知道这些工具背后是 HTTP、Dubbo、数据库、Spring Boot 还是其他系统。它只需要看到工具的结构化说明,然后根据用户意图判断是否需要使用工具。
二、MCP 的核心思想:让模型看到"工具说明",让系统执行"工具调用"
很多人第一次接触 MCP 或 Tool Calling 时,都会有一个疑问:
AI 是怎么知道什么时候该调用工具的?
它是真的自动调用了吗?
是不是背后写了很多 if else?
这里先说结论:
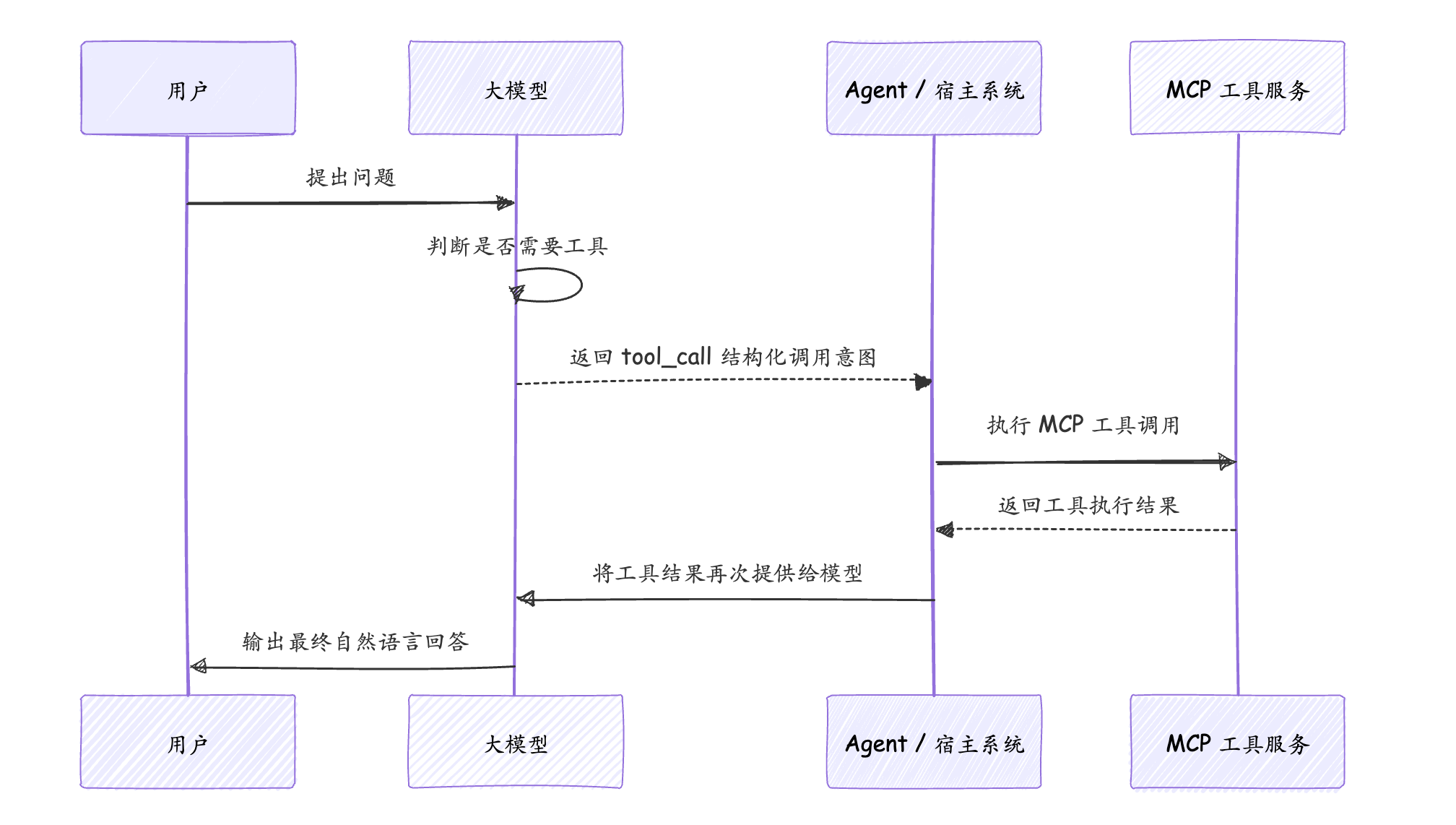
AI 并不会真正"执行" MCP 工具,它只是根据用户意图生成一条工具调用建议,真正执行工具的是 Agent 或 Host 系统。
也就是说,在完整调用链路中,大模型主要负责两件事:
- 判断当前问题是否需要外部工具;
- 如果需要,生成结构化的工具调用指令。
而真正去请求数据库、HTTP 接口、MCP Server 的,是宿主系统,也就是 Agent / Host。
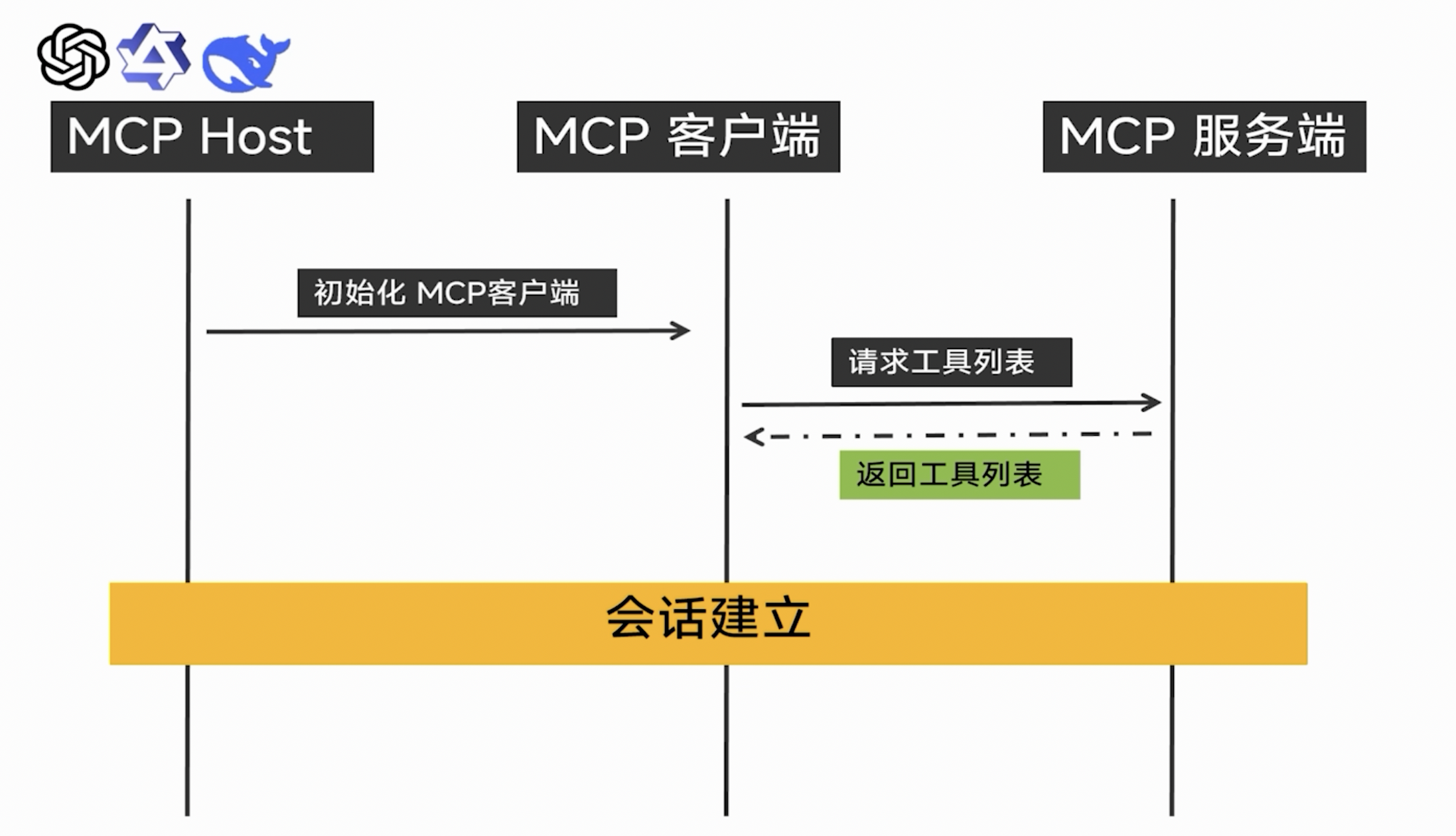
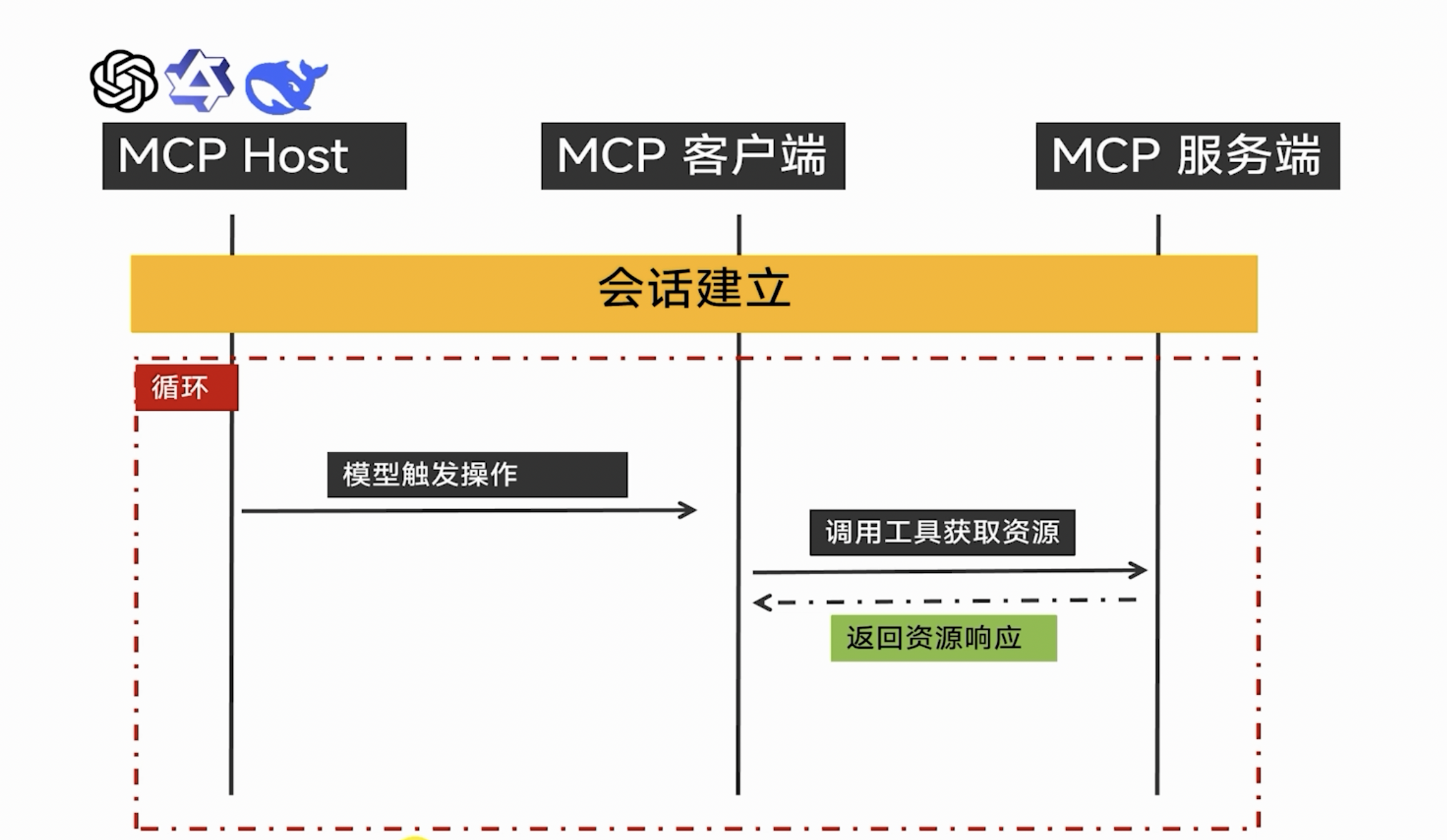
所以 MCP 工具在模型眼里,并不是一段可执行代码,而是一段结构化描述。一个典型的工具描述大概长这样:
{
"name": "get_user_info",
"description": "根据用户ID查询用户的基本信息",
"input_schema": {
"type": "object",
"properties": {
"userId": {
"type": "string"
}
},
"required": ["userId"]
}
}模型可以看到的关键信息主要有三个:
|----------------|----------------|
| 字段 | 作用 |
| name | 工具名称 |
| description | 工具用途描述 |
| input_schema | 工具需要的入参结构 |
模型并不知道这个工具背后到底是数据库查询、HTTP 请求,还是一个 Spring Boot 服务。它只知道:
有一个工具叫 get_user_info,它可以根据 userId 查询用户基本信息,并且需要传入 userId 参数。
这也解释了为什么工具的 description 非常重要。对于模型来说,description 就像工具级别的 prompt。description 写得越清楚,模型越容易在合适的场景下命中这个工具。
三、AI 是如何判断是否需要调用 MCP 工具的?
从本质上讲,这是一个意图判断问题。
当用户提出一个问题时,大模型会隐式判断:
这个问题我能直接回答吗?
还是必须借助外部工具?
比如下面几类问题,模型通常可以直接回答:
|------------------------|--------------------|
| 用户问题 | 是否需要工具 |
| 什么是 MCP? | 不需要 |
| 帮我写一段 Java 代码 | 不需要 |
| 解释一下 Spring Boot 的启动流程 | 不需要 |
| 帮我优化一段提示词 | 不需要 |
但下面这些问题就明显需要工具:
|-------------------|--------------------|
| 用户问题 | 是否需要工具 |
| 查一下用户 123 的认证状态 | 需要 |
| 查询订单 8899 当前运输状态 | 需要 |
| 获取某个城市实时天气 | 需要 |
| 分析昨天生产日志中的异常 | 需要 |
| 查询数据库中最近 10 条失败记录 | 需要 |
原因很简单:这些问题依赖外部实时数据,不能靠模型本身生成。
当模型发现问题需要外部能力时,它会进一步判断:
- 当前有哪些可用工具;
- 哪个工具的 description 和用户意图最匹配;
- 用户是否已经提供了必要参数;
- 如果参数完整,则生成工具调用;
- 如果参数不完整,则可能追问用户。
例如有这样一个工具:
{
"name": "get_order_status",
"description": "根据订单号查询订单当前状态",
"input_schema": {
"type": "object",
"properties": {
"orderId": {
"type": "string"
}
},
"required": ["orderId"]
}
}用户问:
帮我看看 8899 这个订单现在怎么样了
模型会做出判断:
- 这是订单实时状态问题;
- 不能靠模型直接回答;
- 当前存在一个"根据订单号查询订单当前状态"的工具;
- 用户提供了订单号 8899;
- 因此可以调用 get_order_status。
此时模型可能返回类似下面的结构化调用意图:
{
"tool_call": {
"name": "get_order_status",
"arguments": {
"orderId": "8899"
}
}
}注意,这段内容通常不是直接展示给用户看的,而是给Agent / Host 程序使用的。Agent 拿到这个 tool_call 后,才会真正去调用 MCP 工具服务。
四、MCP 的完整调用流程
一个标准的 MCP 工具调用流程可以分为六步:
- 用户提出问题;
- 大模型判断是否需要工具;
- 大模型生成 tool_call;
- Agent / Host 执行工具调用;
- 工具服务返回执行结果;
- Agent / Host 把工具结果交给模型,模型组织最终回答。
五、MCP 工具为什么有时不会被调用?
在实际开发中,我们经常会遇到一个问题:
我明明配置了 MCP 工具,为什么模型没有调用?
常见原因主要有四类。
1. 工具描述太抽象
例如:
{
"name": "doTaskV3",
"description": "执行任务"
}这种工具描述对模型非常不友好。模型不知道这个工具到底能干什么,也不知道什么时候应该使用。
更好的写法是:
{
"name": "get_order_status",
"description": "根据订单号查询订单当前状态,包括运输状态、物流单号、签收情况"
}工具描述应该尽量贴近用户真实表达,而不是贴近技术实现。
例如在物流场景中,不建议只写:
查询运单
可以写成:
根据运单号查询运输任务当前状态,包括装货、在途、卸货、签收、异常等信息。
这样模型更容易把用户问题和工具能力匹配起来。
2. 参数不完整
如果工具需要 orderId,但用户只说:
查一下订单状态
这时模型可能不会直接调用工具,因为缺少订单号。
除非系统 prompt 中明确允许模型先追问,否则模型可能会直接回复:
请提供订单号。
所以在设计工具参数时,要尽量控制 required 字段数量。能通过上下文补全的参数,就不要强制要求用户重复输入。
3. 系统 Prompt 限制
有些 Agent 系统会在系统提示词中限制工具调用,例如:
除非用户明确要求查询实时数据,否则不要调用工具。
这种情况下,即使工具存在,模型也可能不会调用。
4. 模型认为可以直接回答
如果用户的问题看起来像通用知识问题,模型可能直接回答,而不是调用工具。
例如:
北京天气怎么样?
有些模型可能直接根据常识回答"北京四季分明",而不是调用天气工具。
如果你希望实时问题必须走工具,就需要在系统 prompt 中明确约束:
涉及实时天气、订单、用户、车辆、运单、账户等动态数据时,必须调用对应工具,不允许基于模型知识直接回答。
六、MCP 协议层与传输层
MCP 可以从两个层面理解:
- 协议层;
- 传输层。
协议层关注的是:
- 工具如何描述;
- 工具如何发现;
- 参数如何定义;
- 请求和响应如何组织;
- 资源、提示词、工具如何暴露。
传输层关注的是:
- Client 和 Server 如何通信;
- 是通过本地进程通信,还是通过网络通信;
- 消息如何发送和接收。
在实际使用中,比较常见的 MCP 传输方式有两种:
- stdio;
- SSE。
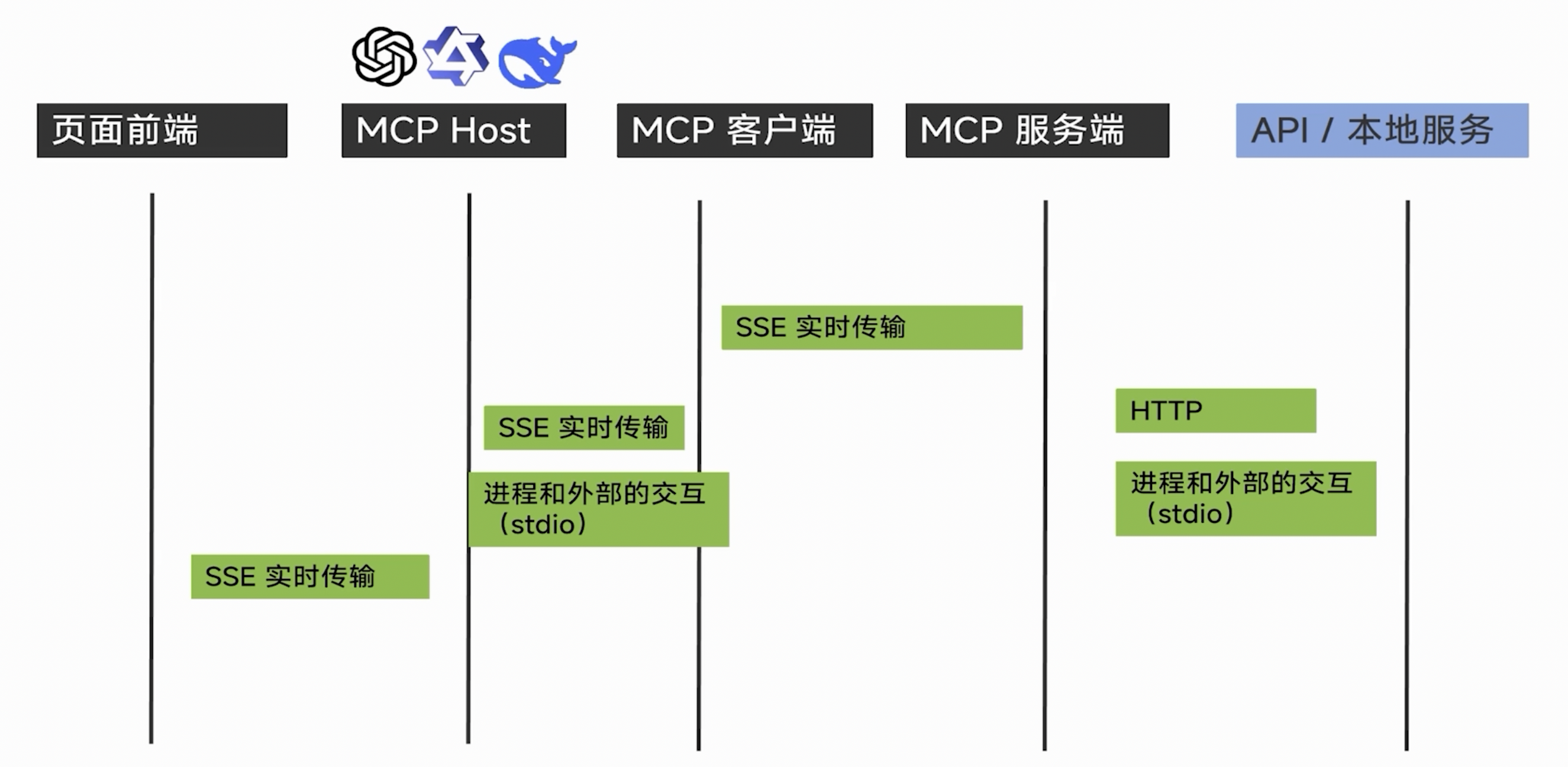
七、stdio 传输层
stdio 是 MCP 最基础的传输方式,全称是标准输入输出。
它的工作方式可以理解为:
MCP Client 启动一个子进程运行 MCP Server,然后通过 stdin 发送请求,通过 stdout 接收响应。
具体来说:
- 标准输入 stdin:客户端向 MCP Server 发送请求;
- 标准输出 stdout:MCP Server 返回响应;
- 标准错误 stderr:通常用于输出日志和错误信息。
stdio 的优点很明显:
- 简单可靠;
- 不需要网络配置;
- 适合本地部署;
- 进程隔离,安全性相对较好;
- 很适合桌面客户端、本地插件、本地开发调试。
但它也有明显限制:
- 只能单机使用;
- 不适合跨网络访问;
- 每个客户端通常需要独立启动服务进程;
- 不太适合企业级集中式工具服务。
可以把 stdio 理解为一种"本地插件式"的 MCP 服务部署方式。
例如你在本地运行一个文件系统 MCP Server,让 AI 帮你读取本地文件、搜索目录、分析代码,这种场景就很适合 stdio。
MCP Client
|
| stdin 请求
v
MCP Server 子进程
|
| stdout 响应
v
MCP Client八、SSE 传输层
SSE,全称是 Server-Sent Events,是一种基于 HTTP 的服务端推送机制。
在 MCP 场景中,SSE 适合将 MCP Server 部署成一个远程服务,多个客户端可以通过 HTTP 连接访问这个 MCP 服务。
SSE 的特点是:
- 客户端通过 HTTP 建立持久连接;
- 使用
text/event-stream内容类型; - 服务端可以持续向客户端推送消息;
- 支持自动重连;
- 支持事件 ID 和自定义事件类型。
相比 stdio,SSE 更适合企业级部署,因为它支持:
- 分布式部署;
- 跨网络访问;
- 多客户端连接;
- 使用标准 HTTP 协议;
- 可以结合网关、鉴权、日志、监控等基础设施。
当然,SSE 也会带来额外复杂度:
- 需要网络配置;
- 需要考虑服务鉴权;
- 需要处理连接稳定性;
- 需要考虑超时、重连、限流;
- 相比 stdio 本地进程方式更复杂。
如果你要把企业内部业务能力封装成 MCP 工具,例如订单查询、用户查询、运单轨迹查询、风控评分查询,那么更推荐使用 SSE 或其他 HTTP 类传输方式。
九、stdio 和 SSE 怎么选?
可以简单总结为:
|----------------|--------------------|
| 场景 | 推荐传输方式 |
| 本地开发调试 | stdio |
| 本地桌面插件 | stdio |
| 文件系统、浏览器本地操作 | stdio |
| 企业内部工具服务 | SSE |
| 多客户端共享 MCP 服务 | SSE |
| 需要跨网络访问 | SSE |
| 需要网关、鉴权、监控 | SSE |
一句话总结:
本地工具优先 stdio,企业服务优先 SSE。
在正式生产场景中,通常会更偏向 SSE,因为它更符合后端服务化思路。尤其对于 Java / Spring Boot 开发者来说,把 MCP Server 做成一个标准 Web 服务,再通过 SSE 暴露给 Agent 使用,会更贴近现有工程体系。
十、使用 Spring AI 构建自定义 MCP 天气服务
一个基于 Spring AI 的 MCP WebFlux Server 示例,这个示例提供了天气查询和空气质量查询两个工具能力。
项目结构大致如下:
参考Spring AI Alibaba示例代码 https://github.com/spring-ai-alibaba/examples
starter-webflux-server/
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ └── org/springframework/ai/mcp/sample/server/
│ │ │ ├── McpServerApplication.java
│ │ │ └── OpenMeteoService.java
│ │ └── resources/
│ │ └── application.properties
│ └── test/
│ └── java/
│ └── org/springframework/ai/mcp/sample/client/
│ ├── ClientStdio.java
│ ├── ClientSse.java
│ └── SampleClient.java
└── pom.xml其中核心类有两个:
1. McpServerApplication
这是 Spring Boot 应用入口,主要负责:
- 启动 Spring Boot 应用;
- 注册工具服务;
- 初始化 MCP Server;
- 暴露 MCP 通信端点。
2. OpenMeteoService
这是具体的工具服务类,提供两个主要工具:
|------------------------------|----------------|
| 工具方法 | 作用 |
| getWeatherForecastByLocation | 根据经纬度获取天气预报 |
| getAirQuality | 根据经纬度获取空气质量信息 |
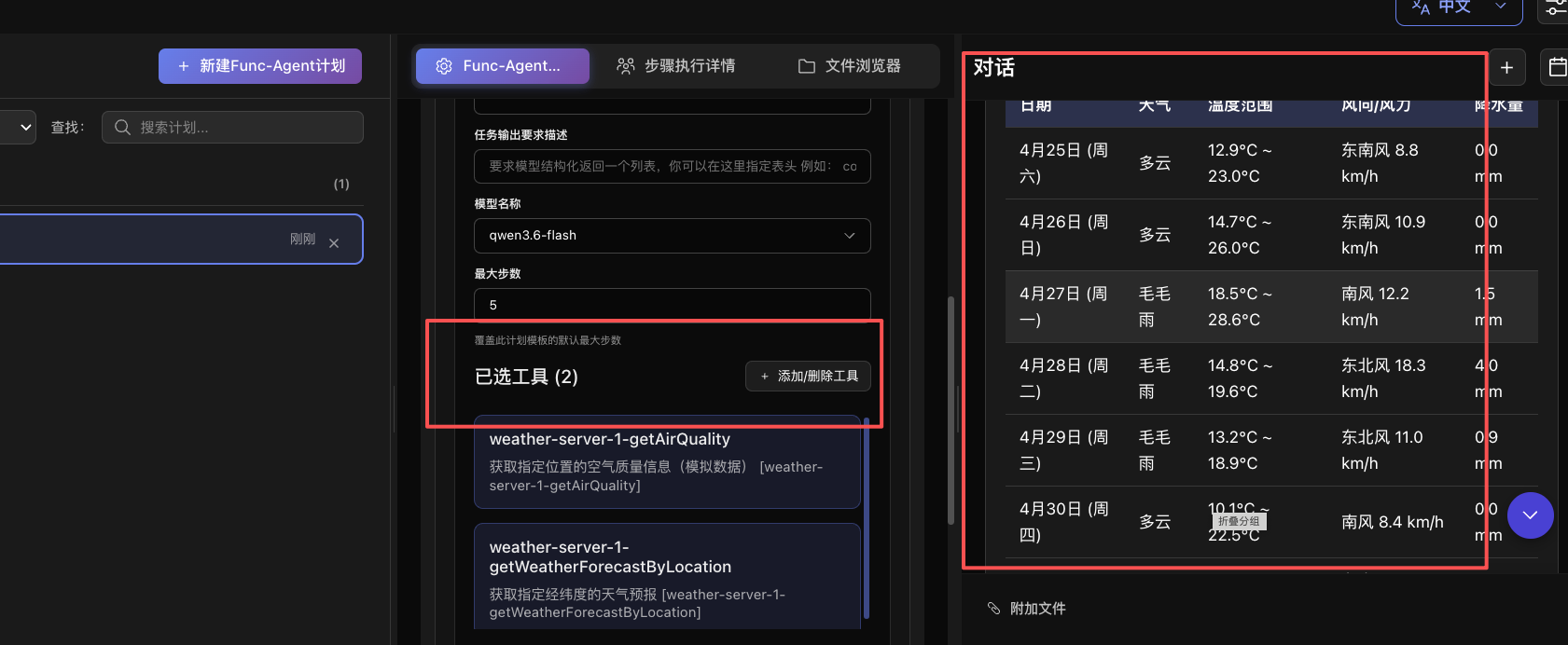
其中,getWeatherForecastByLocation 使用 OpenMeteo 免费 API,可以获取当前天气和未来 7 天预报,包括:
- 温度;
- 体感温度;
- 湿度;
- 风速;
- 风向;
- 降水量;
- 天气代码;
- 未来 7 天最高温和最低温。
getAirQuality 示例中提供的是模拟空气质量数据
十一、如何把一个 Java 方法变成 MCP 工具?
在 Spring AI 中,可以通过 @Tool 注解把普通 Java 方法声明为工具。
例如:
@Tool(description = "获取指定经纬度的天气预报")
public String getWeatherForecastByLocation(double latitude, double longitude) {
// 调用天气 API
// 拼接天气结果
return weatherInfo.toString();
}这个注解非常关键。
对模型来说,这个工具最终会被转成类似这样的结构化描述:
{
"name": "getWeatherForecastByLocation",
"description": "获取指定经纬度的天气预报",
"input_schema": {
"type": "object",
"properties": {
"latitude": {
"type": "number"
},
"longitude": {
"type": "number"
}
},
"required": ["latitude", "longitude"]
}
}当用户问:
查询北京未来 7 天天气
Agent 或模型需要先把"北京"转换成经纬度,例如北京经纬度大约是:
latitude = 39.9042
longitude = 116.4074然后模型生成工具调用:
{
"tool_call": {
"name": "getWeatherForecastByLocation",
"arguments": {
"latitude": 39.9042,
"longitude": 116.4074
}
}
}Host 接收到 tool_call 后,调用 MCP Server,MCP Server 再执行 Java 方法,最终返回天气数据。
十二、OpenMeteoService 的实现思路
OpenMeteoService 的实现大致可以分为四步。
第一步:初始化 RestClient
private static final String BASE_URL = "https://api.open-meteo.com/v1";
private final RestClient restClient;
public OpenMeteoService() {
this.restClient = RestClient.builder()
.baseUrl(BASE_URL)
.defaultHeader("Accept", "application/json")
.defaultHeader("User-Agent", "OpenMeteoClient/1.0")
.build();
}这里使用 Spring 的 RestClient 访问 OpenMeteo API。
第二步:定义天气响应结构
代码中通过 record 定义了天气数据模型,例如:
@JsonIgnoreProperties(ignoreUnknown = true)
public record WeatherData(
@JsonProperty("latitude") Double latitude,
@JsonProperty("longitude") Double longitude,
@JsonProperty("timezone") String timezone,
@JsonProperty("current") CurrentWeather current,
@JsonProperty("daily") DailyForecast daily,
@JsonProperty("current_units") CurrentUnits currentUnits) {
}这里有几个细节值得注意:
- 使用
@JsonIgnoreProperties(ignoreUnknown = true)忽略未知字段,避免 API 返回字段变化导致解析失败; - 使用
@JsonProperty映射 JSON 字段; - 使用 record 简化数据结构;
- 将 current、daily、units 拆成不同内部结构,便于后续格式化输出。
第三步:调用天气 API
var weatherData = restClient.get()
.uri("/forecast?latitude={latitude}&longitude={longitude}¤t=temperature_2m,apparent_temperature,relative_humidity_2m,precipitation,weather_code,wind_speed_10m,wind_direction_10m&daily=temperature_2m_max,temperature_2m_min,precipitation_sum,weather_code,wind_speed_10m_max,wind_direction_10m_dominant&timezone=auto&forecast_days=7",
latitude, longitude)
.retrieve()
.body(WeatherData.class);这里一次请求同时获取:
- 当前天气;
- 未来 7 天天气;
- 温度;
- 湿度;
- 降水;
- 风速;
- 风向;
- 天气代码。
第四步:格式化工具返回结果
工具最终返回的是字符串,例如:
当前天气:
温度: 18.2°C (体感温度: 17.5°C)
天气: 多云
风向: 东北风 (10.5 km/h)
湿度: 60%
降水量: 0.0 毫米
未来天气预报:
2026-04-25:
温度: 12.0°C ~ 22.0°C
天气: 多云
风向: 东风
降水量: 0.0 毫米为什么工具返回字符串也可以?
因为 MCP 工具的返回结果最终会再次交给模型。模型拿到工具返回的数据后,会把它组织成用户更容易理解的自然语言。
当然,在企业业务系统中,更建议工具优先返回结构化 JSON,而不是大段文本。原因是:
- JSON 更容易被模型二次理解;
- JSON 更容易被 Agent 流程节点处理;
- JSON 更容易做日志审计;
- JSON 更适合后续扩展;
- JSON 更容易做前端展示。
例如天气工具可以返回:
{
"location": {
"latitude": 39.9042,
"longitude": 116.4074
},
"current": {
"temperature": 18.2,
"feelsLike": 17.5,
"humidity": 60,
"weather": "多云",
"windDirection": "东北风",
"windSpeed": 10.5,
"precipitation": 0.0
},
"daily": [
{
"date": "2026-04-25",
"tempMin": 12.0,
"tempMax": 22.0,
"weather": "多云"
}
]
}十三、MCP Server 配置示例
server:
port: 8080
spring:
main:
banner-mode: off
ai:
mcp:
server:
name: my-weather-server
type: ASYNC
protocol: sse
sse-endpoint: /sse
sse-message-endpoint: /mcp十四、结合 Lynxe/JManus 使用 MCP
Lynxe,原名 JManus。它是 Manus 的 Java 实现,目前在阿里巴巴集团内部很多应用中已有使用,主要适合处理具有一定确定性要求的探索性任务,例如:
- 从海量数据中快速找到目标数据;
- 将分析结果转换成数据库中的结构化记录;
- 分析日志并给出告警;
- 组合多个工具完成复杂任务。
从定位上看,Lynxe 更像是一个 Java Agent 框架,而 MCP 则是工具协议层。两者结合后,可以形成比较完整的 AI 应用工程架构:
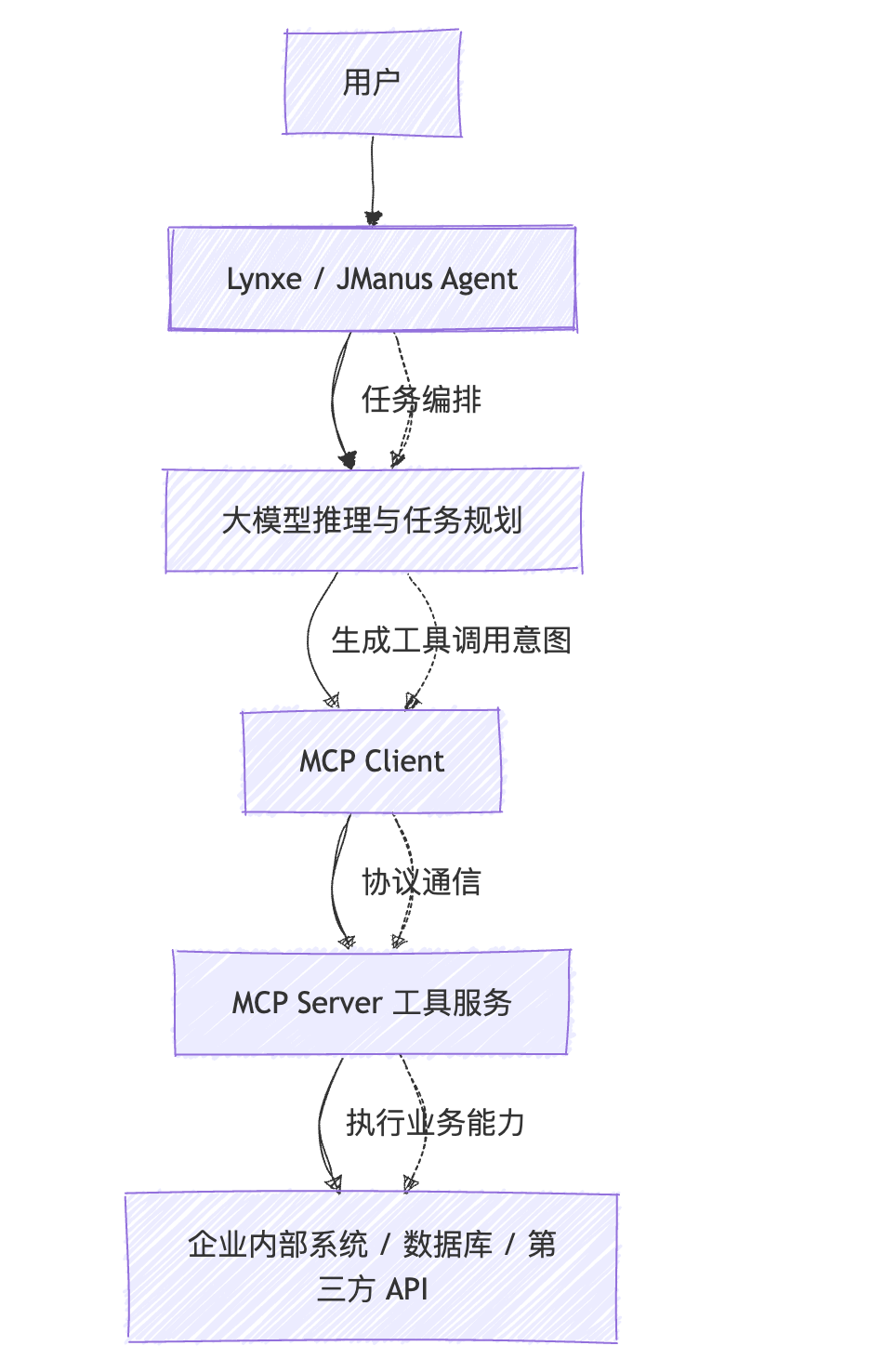
在这个架构中:
- Lynxe 负责 Agent 编排;
- 大模型负责意图理解和任务规划;
- MCP 负责工具标准化接入;
- Spring Boot 服务负责承载具体业务工具;
- 企业系统负责提供真实数据。
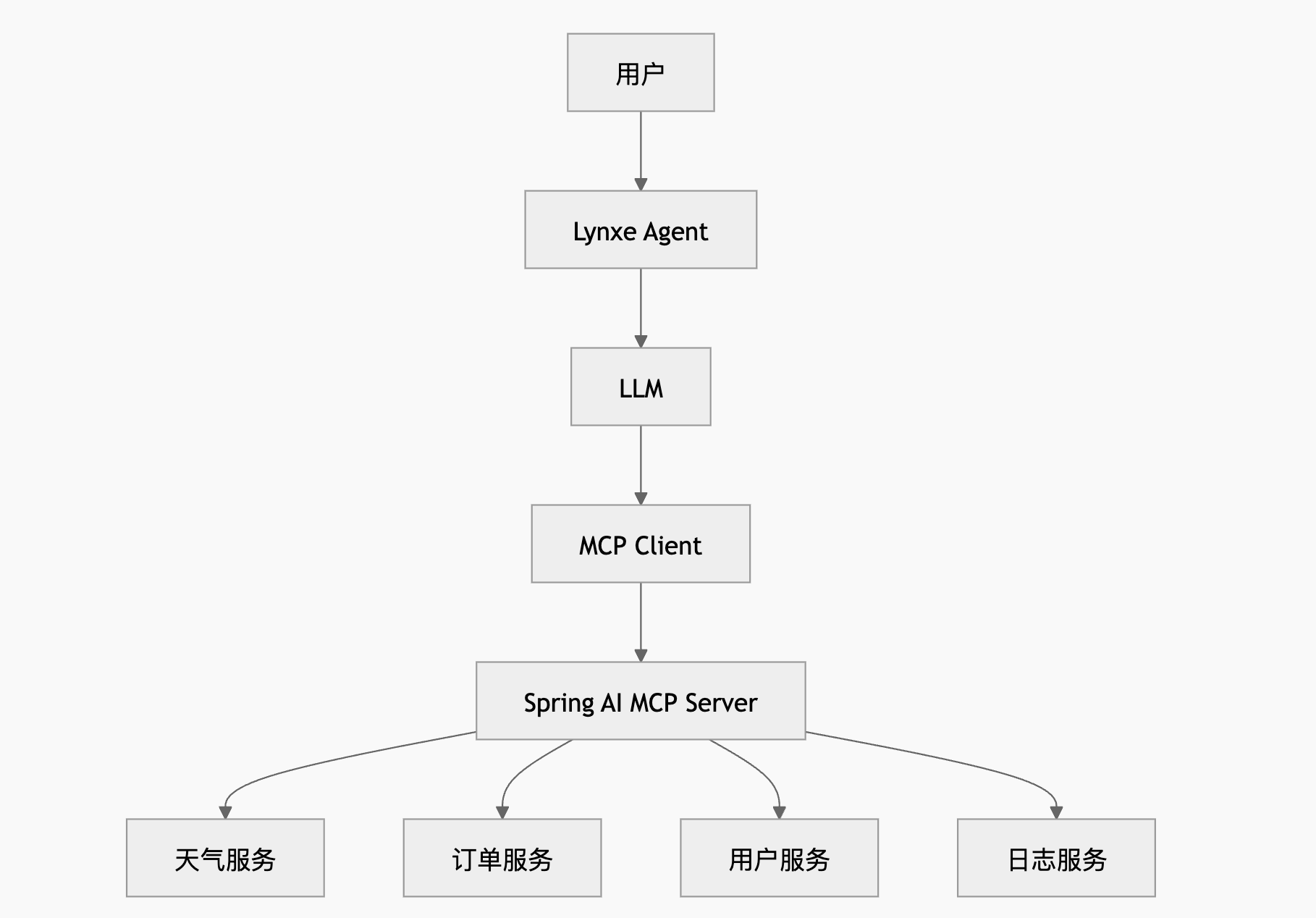
Lynxe代码仓库地址:
https://github.com/spring-ai-alibaba/Lynxe
本地启动jar

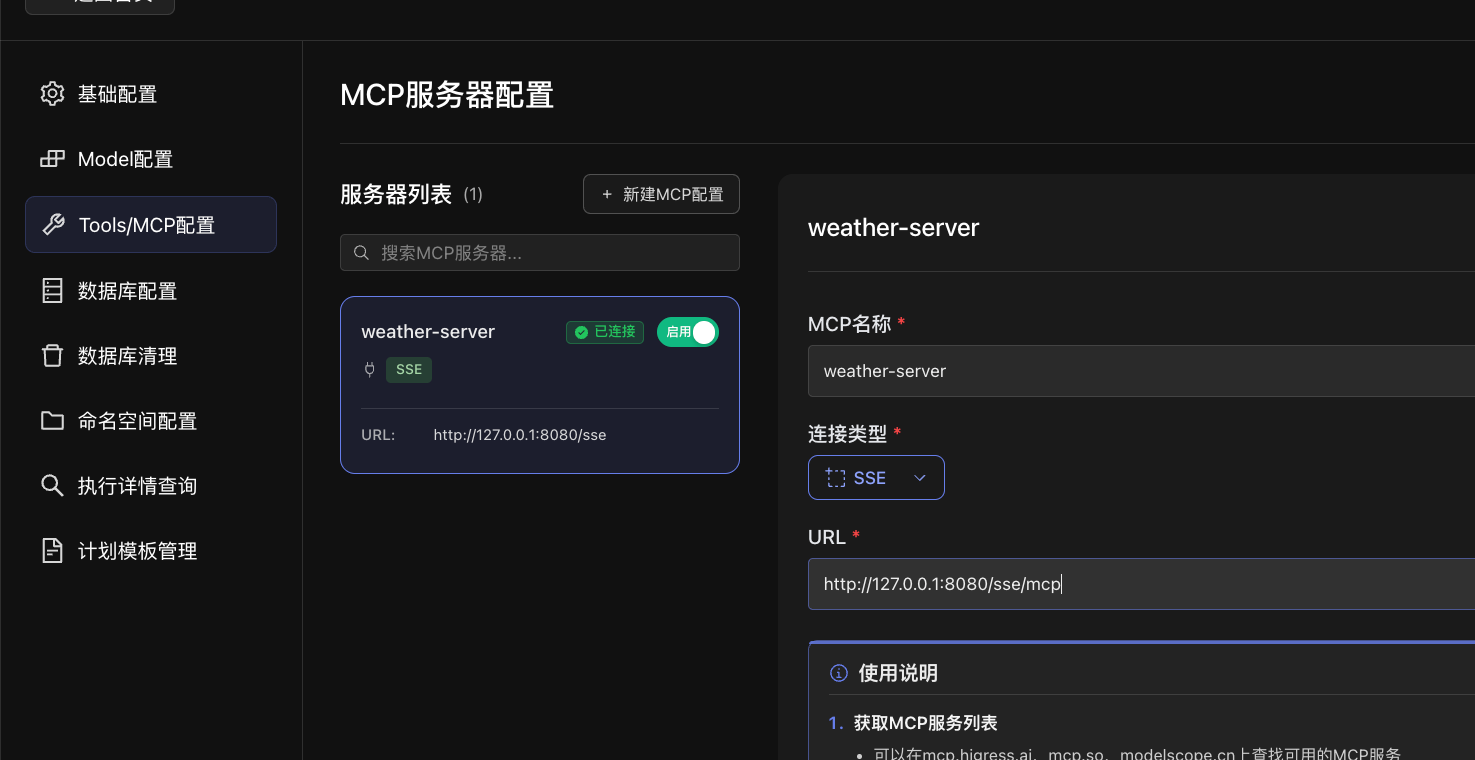
配置MCP服务
测试验证
十五、设计 MCP 工具的关键原则
MCP 工具不是简单把接口暴露出去就完事了。想让模型稳定调用工具,需要重点关注以下几个设计原则。
1. 工具名称要清晰
不推荐:
query
doTask
execute
handleData
toolV2推荐:
get_order_status
get_driver_info
get_weather_forecast
audit_transport_image
query_vehicle_track名称不是最关键的,但清晰名称有利于调试和维护。
2. description 要像业务说明,而不是技术说明
不推荐:
调用订单接口推荐:
根据订单号查询订单当前状态,包括是否发货、运输中、已签收、异常等信息模型是通过语义匹配来判断工具是否适用,所以 description 应该贴近用户真实问题。
3. 参数 schema 要明确
不推荐:
{
"params": {
"type": "object"
}
}推荐:
{
"orderId": {
"type": "string",
"description": "订单号,例如 8899"
}
}参数越明确,模型越容易正确提取。
4. 不要让一个工具做太多事
不推荐设计一个万能工具:
process_user_request它什么都能做,但模型不知道什么时候该用,也不知道怎么传参。
更推荐拆成多个边界清晰的工具:
get_user_info
get_order_status
get_driver_certification
get_vehicle_track5. 返回结果尽量结构化
工具返回自然语言可以工作,但不利于复杂流程。
推荐返回 JSON:
{
"success": true,
"data": {
"orderId": "8899",
"status": "已发货",
"trackingNo": "SF123456"
},
"message": "查询成功"
}6. 错误信息要可理解
不要只返回:
error建议返回:
{
"success": false,
"errorCode": "ORDER_NOT_FOUND",
"message": "未查询到订单号 8899 对应的订单信息"
}这样模型可以给用户一个更自然的解释。
十六、MCP 和 Function Calling 的区别
MCP 和 Function Calling 有什么区别?
可以简单理解:
Function Calling 更偏向模型厂商或模型 API 的工具调用能力,而 MCP 更偏向一个开放的上下文和工具连接协议。
Function Calling 关注的是:
- 模型如何声明函数;
- 模型如何生成函数调用;
- 函数调用结果如何返回给模型。
MCP 关注的是:
- 工具服务如何标准化暴露;
- Client 和 Server 如何通信;
- 工具、资源、提示词如何统一接入;
- 不同 Agent 和工具服务如何复用。
如果用一句话概括:
Function Calling 更像模型接口能力,MCP 更像 AI 工具生态协议。
在实际工程中,两者不是互斥关系。MCP Server 可以提供工具,Agent 可以通过模型的 Function Calling 能力决定调用哪个 MCP 工具。也就是说,Function Calling 解决"模型如何表达调用意图",MCP 解决"工具如何标准化提供能力"。