Hi,大家好,欢迎来到维元码簿。
本文属于 《Claude Code 源码 Deep Dive》 系列,专注于工具系统中的 内置工具全景与三方协作 板块。如果你想了解整个系列,可以先看系列开篇 | Claude Code 源码架构概览:51万行代码的模块地图。
本文讲两件事:Claude Code 有哪些内置工具、它们怎么分族协作;以及 MCP 和 Skills 这两种扩展机制跟内置工具到底是什么关系。
读完全文,你将能回答这几个问题:
- Claude Code 的 30+ 内置工具是怎么分类的?每一类的核心设计思路是什么?
- Tools、MCP、Skills 到底有什么区别? 三者都在 tools\[\] 里出现,但本质完全不同。
- 一个 MCP Server 怎么同时提供工具和技能? 双重身份的发现机制。
本篇覆盖的源码范围
| 模块 | 核心文件 | 核心代码行 | 文件总行 | 职责 |
|---|---|---|---|---|
| 内置工具实现 | src/tools/*/ |
各工具目录 | 5000+ 行 | 30+ 个工具的实现 |
| MCP 工具发现 | src/tools/MCPTool/MCPTool.ts + src/services/mcp/client.ts |
MCPTool.ts L27-77(基础定义)+ client.ts L595-1998(connectToServer + fetchToolsForClient) | 77 行 / 3349 行 | MCP 工具发现、包装、连接 |
| Skill 工具 | src/tools/SkillTool/SkillTool.ts + prompt.ts |
SkillTool.ts L331-869(SkillTool 定义)+ prompt.ts L1-242(budget 算法 + prompt 模板) | 1109 行 / 242 行 | Skill 解析、fork 执行、token budget |
| 命令注册 | src/commands.ts |
L547-608(getMcpSkillCommands + getSkillToolCommands + getSlashCommandToolSkills) | 755 行 | getSkillToolCommands、getSlashCommandToolSkills |
前情提要:从合约到全景
在姊妹篇Claude Code 深度拆解:工具系统------30+ 工具怎么统一注册、按需加载中,我们知道了工具怎么定义(Tool 接口)、怎么注册(assembleToolPool)、怎么按需加载(延迟加载)。但还有一个问题没回答:到底有哪些工具?
getAllBaseTools() 返回了 30+ 个工具------BashTool、ReadTool、EditTool、GlobTool、GrepTool......它们排成一个长列表。但如果你去看源码,会发现这些工具并非杂乱无章------它们按职责自然地分为几个"族",每族有独特的设计思路。
更让人困惑的是:除了内置工具,还有 MCP 和 Skills。它们都出现在 tools[] 数组里,模型看来它们都长一样(都是 JSON Schema),但背后的运行机制完全不同。MCP 是外部服务通过标准协议接入的连接,Skills 是用 Markdown 写的行为模板。这就是本文要拆解的核心命题。
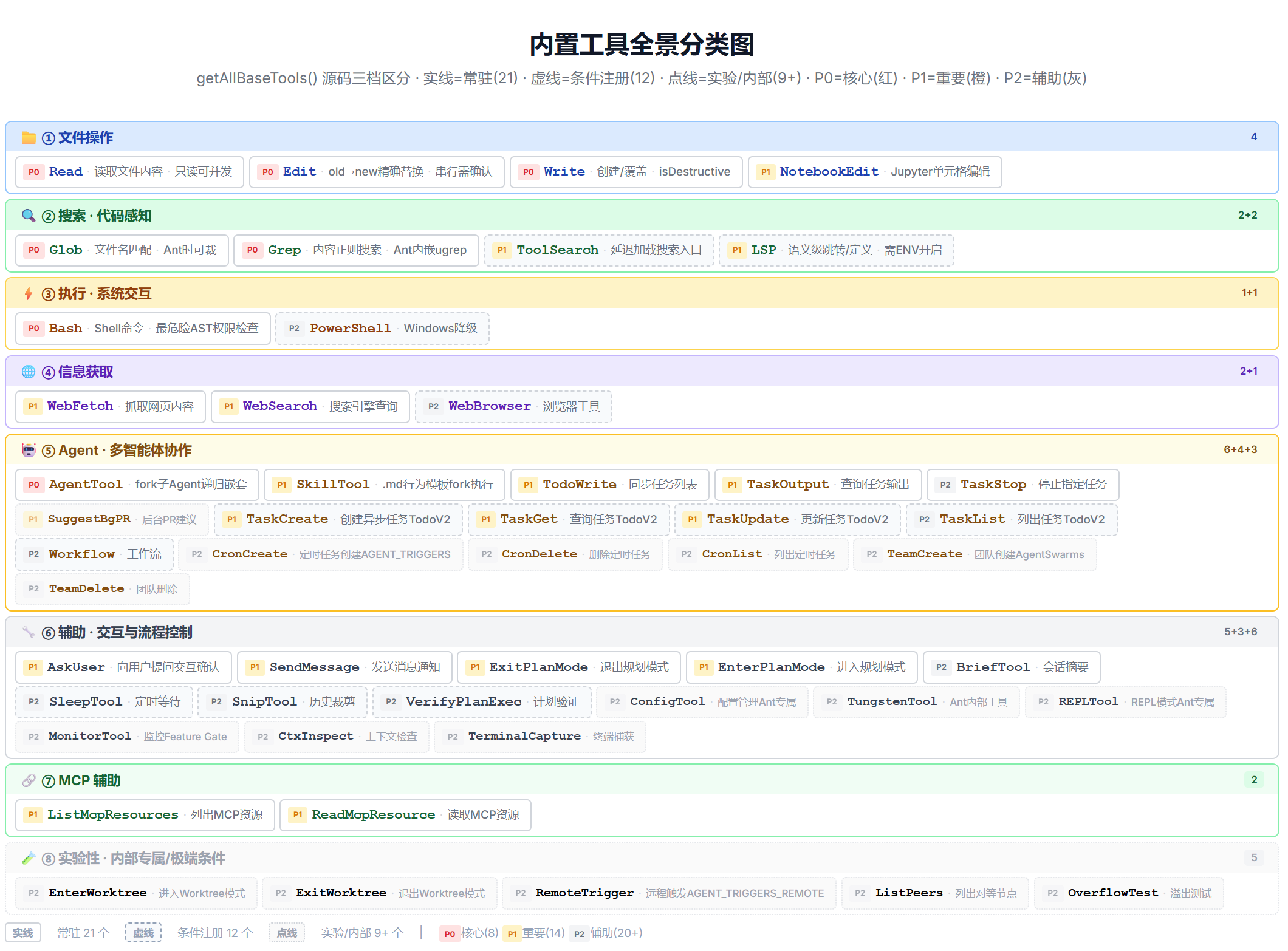
文件操作族------最核心的能力单元
文件操作是 Agent 最基本的能力。 不会读文件就无法理解项目,不会写文件就无法修改代码。Claude Code 用四个工具覆盖了文件操作的全部场景:Read / Edit / Write / NotebookEdit。

四个工具的定位和安全等级各不相同:
| 工具 | 操作类型 | isReadOnly | isDestructive | 安全等级 |
|---|---|---|---|---|
| Read | 读取文件内容 | true |
false |
最安全------只读,不影响任何文件 |
| Edit | 替换文件中的指定文本 | false |
false |
需确认------修改但不会破坏,因为需要精确匹配 old_string |
| Write | 创建或完整覆盖文件 | false |
true |
最危险------整个文件被替换,旧内容可能丢失 |
| NotebookEdit | 修改 Jupyter Notebook 的 Cell | false |
false |
专用------只对 .ipynb 文件有效 |
Edit 的替换策略为什么不 diff? EditTool 接受 old_string 和 new_string 两个参数,做的是精确字符串替换------找到 old_string 的位置,用 new_string 替换。不是 diff 补丁,不是行号定位,而是文本匹配。源码 src/tools/FileEditTool/types.ts 中 Schema 定义得很清楚:
typescript
// src/tools/FileEditTool/types.ts L9-13
old_string: z.string().describe('The text to replace'),
new_string: z.string().describe(
'The text to replace it with (must be different from old_string)'
)为什么这样设计?因为 LLM 生成 diff 格式很容易出错------行号可能对不上,diff 语法容易搞混。但 LLM 很擅长"复述"------它能看到文件内容,精确地复制要修改的部分,然后给出修改后的版本。old_string/new_string 的设计让模型"看到什么改什么",不需要理解 diff 语法。这个设计选择在 Schema 的字段名中就体现了意图:它不叫 patch 或 diff,而是叫 replace------直白地告诉模型,你要找到这段旧文本,把它换成这段新文本。
NotebookEdit 的 searchHint 设计。 NotebookEdit 的 searchHint 是 "jupyter"------工具名里没有 jupyter 这个词,但用户肯定会搜 jupyter。延迟加载时,用户说"帮我操作 Jupyter Notebook",模型通过 ToolSearch 搜索 "jupyter" 就能找到这个工具。这是一个典型的"以用户心智模型命名"的设计:用户不会搜 "notebook",但会搜 "jupyter"。
四个工具共享一个参数:file_path。它们操作同一个文件系统,但安全等级从只读到创建/覆盖递增------这也决定了它们在权限系统中受到的"关照"程度不同。Write 是权限检查最严格的,Read 是最宽松的。
搜索族------代码世界的眼睛
Agent 不搜索就无法定位问题。 搜索族提供三种互补的搜索能力:
| 工具 | 搜索维度 | 典型场景 | isReadOnly |
|---|---|---|---|
| Glob | 文件名模式匹配 | "找到所有 .test.ts 文件" | true |
| Grep | 文件内容搜索 | "找到所有 TODO 注释" | true |
| LSP | 语言语义搜索 | "找到 UserService 的所有引用" |
true |
三者的互补关系可以用一个例子说清楚:假设你要理解 UserService 这个类------先用 Glob 找到它所在的文件(**/UserService.ts),再用 Grep 搜索哪些文件 import 了它(grep "UserService"),最后用 LSP 找到它在代码中的所有语义引用("go to references")。
Ant-native 构建的特殊优化。 在 getAllBaseTools() 中有这样一行:
typescript
...(hasEmbeddedSearchTools() ? [] : [GlobTool, GrepTool]),当检测到 Ant-native 构建环境时,Glob 和 Grep 工具直接不注册。为什么?因为 Ant-native 构建在 bun 二进制中内嵌了 bfs(快速文件搜索)和 ugrep(快速内容搜索)------它们比 GlobTool/GrepTool 的 Node.js 实现快得多。
源码 src/utils/embeddedTools.ts 的注释写得很清楚这个设计的三层影响:
typescript
// src/utils/embeddedTools.ts L3-12
/**
* When true:
* - find/grep in Claude's Bash shell are shadowed by shell functions
* that invoke the bun binary with argv0='bfs' / 'ugrep'
* - The dedicated Glob/Grep tools are removed from the tool registry
* - Prompt guidance steering Claude away from find/grep is omitted
*/也就是说,嵌入式搜索工具开启后,不只是"不注册 Glob/Grep 工具"这么简单------模型在 Bash 里直接用 find 和 grep 命令时,底层已经被偷偷替换成了 bfs 和 ugrep,行为完全兼容但速度更快。而 src/utils/bash/ShellSnapshot.ts 中的 createFindGrepShellIntegration() 进一步解释了为什么选的是这两个工具:bfs 是 find 的 drop-in 替代,ugrep 是 grep 的替代------它们保证和原生命令的语义兼容,同时在隐藏文件、gitignore 等行为上对齐 GlobTool/GrepTool 的默认设置。这个设计选择不是随意的:文件名匹配和内容搜索是最基础的两种搜索需求,Glob 和 Grep 恰好覆盖了这两个维度。
这是一个很有意思的设计:同一个 Agent,在不同运行环境下可能有不同的工具集。 Feature Gate 在编译时决定工具的有无,运行时环境也可能进一步调整。
执行族------连接系统的大门
执行族是 Agent 和操作系统之间的桥梁。 没有执行族,Agent 只能"看"不能"做"------能读文件但不能跑命令,能搜代码但不能启动服务。
| 工具 | 运行环境 | 平台 |
|---|---|---|
| Bash | bash / sh | macOS, Linux, WSL |
| PowerShell | pwsh | Windows |
为什么需要两个 Shell?跨平台兼容性。 macOS 和 Linux 用 Bash,Windows 用 PowerShell。Claude Code 根据当前平台自动选择合适的 Shell 工具------在 Windows 上注册 PowerShellTool,在其他平台注册 BashTool。
BashTool 的特殊地位:最强大也最危险。 它可以执行任意 Shell 命令------这意味着模型可以做任何用户能做的事。这种力量是双刃剑:跑 git status 是安全的,但跑 rm -rf / 是灾难性的。所以 BashTool 是权限系统的重点保护对象:
- BashTool 有专门的 AST 权限检查(tree-sitter 解析命令)
- BashTool 是唯一使用沙盒隔离的工具
- BashTool 的错误会触发 siblingAbortController,级联取消所有并行工具
这些安全机制在姊妹篇权限沙盒与错误处理(./03-Claude Code深度拆解-工具系统-权限沙盒与错误处理.md)中展开。
Agent 控制族------工具调用工具、任务管理与状态追踪
这是工具系统中最"元"的一族------Agent 可以通过这些工具来管理自己的行为、追踪任务状态、甚至 fork 子 Agent 并行工作。 用户在终端里看到的 "Agent 正在思考"、任务进度条、TODO 列表更新,背后都是这套机制。它直接决定了用户体验的两个核心维度:Agent 的能力上限(能不能递归拆分任务)和用户的安全感(能不能看到 Agent 在做什么)。
任务管理:TodoWrite vs Task*
| 工具 | 功能 | 同步/异步 | 典型场景 |
|---|---|---|---|
| TodoWrite | 管理任务清单 | 同步 | 模型记录自己接下来要做什么 |
| TaskCreate | 创建异步任务 | 异步 | 启动后台任务,主 Agent 继续工作 |
| TaskGet | 获取任务详情 | 异步 | 查询后台任务状态和输出 |
| TaskUpdate | 更新任务状态 | 异步 | 修改任务元信息 |
| TaskList | 列出所有任务 | 异步 | 查看异步任务概览 |
| TaskStop | 停止异步任务 | 异步 | 终止后台任务 |
TodoWrite 是用户感知最强的工具之一。 你在终端里看到 Agent 输出的那个有序任务列表------"1. 读取文件 2. 分析逻辑 3. 修改代码"------就是 TodoWrite 的产物。模型用它来规划自己的行动步骤,而用户通过这个列表能实时看到 Agent 的"思路",这在长任务中极大地缓解了用户的焦虑感。模型每完成一步就更新一次 TODO,用户看到的是任务逐项被划掉的进度感。
*Task 系列解决的是"并发执行"的问题。** 当模型需要同时做几件互相独立的事------比如同时启动 3 个子 Agent 分别检查不同文件------TaskCreate 可以创建后台任务,主 Agent 不用等待,继续处理其他事情,稍后通过 TaskGet 查看结果。TodoWrite 和 Task* 的定位完全不同:TodoWrite 是"我接下来要做什么"(同步计划),Task* 是"我同时在做什么"(异步执行)。
AgentTool:递归的 Agent 树
AgentTool 是整个工具系统中最具野心的设计------它让 Agent 可以 fork 一个子 Agent,子 Agent 拥有自己的上下文和工具池,独立执行后再把结果回流。
更有意思的是子 Agent 的工具池里也包含 AgentTool------这意味着子 Agent 可以再 fork 子子 Agent,形成递归的 Agent 树。源码中 src/tools/AgentTool/runAgent.ts 甚至会为子 Agent 单独建立 MCP 连接(connectToServer + fetchToolsForClient),确保子 Agent 拥有和主 Agent 相同的工具能力。
为什么允许递归?因为有些任务天然需要分层:主 Agent 负责规划,子 Agent 负责执行,子子 Agent 负责验证。比如"重构这个模块",主 Agent 先分析依赖关系,然后 fork 子 Agent 分别处理不同文件,每个子 Agent 完成后再 fork 一个子子 Agent 跑测试验证。递归让 Agent 的行为可以按需分层,而不是把所有逻辑塞在一层里。
当然,递归不是无限深的------系统有深度限制防止失控。但对于用户来说,这意味着 Agent 真正具备了"分工协作"的能力:你能看到主 Agent 在分配任务,子 Agent 在并行工作,最终结果汇总。这是 Claude Code 从"单线程聊天"进化到"多线程编程助手"的关键机制。
信息获取族------模型的外部触角
默认情况下,模型的知识停留在训练数据的截止日期。 信息获取族让模型可以触及实时信息:
| 工具 | 功能 | 典型场景 |
|---|---|---|
| WebFetch | 抓取指定 URL 的网页内容 | 读取 API 文档、查看网页 |
| WebSearch | 搜索引擎查询 | 查找最新信息、搜索解决方案 |
这两个工具都受权限和网络策略控制。WebFetch 只能访问用户允许的域名列表,WebSearch 的搜索结果需要经过筛选。它们是模型连接外部世界的"触角"------但也因此受到更严格的限制。
辅助工具族------体验与流程控制
不是所有工具都操作代码。 辅助工具族不修改任何文件,但塑造了用户体验和 Agent 行为模式:
| 工具 | 功能 | 设计意图 |
|---|---|---|
| AskUserQuestion | 向用户提问 | 当模型不确定时主动询问 |
| BriefTool | 提供会话总结 | 长对话时帮助用户回顾 |
| EnterPlanMode | 进入规划模式 | 让模型先思考再行动 |
| ExitPlanMode | 退出规划模式 | 规划完毕,开始执行 |
| ConfigTool | 修改 Claude Code 配置 | 运行时调整设置(仅 Ant 内部) |
| SendMessage | 发送消息给用户 | IDE 模式下的通知机制 |
AskUserQuestion 是唯一一个 bypass 模式也拦不住的工具。 因为它的设计意图就是"必须用户参与"------模型用它来获取用户的选择,绕过权限检查没有意义,因为答案只能由用户提供。这个设计在权限系统的 8 层检查链中,对应的是第 1e 层"用户交互要求"。
MCP 讲清楚:模型怎么连上外部服务
MCP 不是"另一种工具",而是标准化的连接协议。 这是一个很多人会混淆的点。
假设你想让 Claude Code 连上 Slack------发消息、读频道。没有 MCP 的话,你需要为 Slack 写一套完整的 TypeScript 工具实现,提交 PR,等它被合并到主分支。有了 MCP,你只需要配置一个 Slack MCP Server,Claude Code 运行时就能自动发现并使用 Slack 的工具。
MCP 工具的发现链路是这样的(工具注册的完整流程见姊妹篇接口合约与注册组装(./03-Claude Code深度拆解-工具系统-接口合约与注册组装.md)):
.mcp.json 配置文件
│
▼
MCP Client 连接 MCP Server(stdio / SSE 传输)
│
▼
fetchToolsForClient() 调用 tools/list 协议
│
▼
返回的工具列表 → buildTool({ isMcp: true }) 包装
│
▼
与内置工具合并,进入 tools[] 数组关键的一步是 buildTool({ isMcp: true })。MCP 工具和内置工具使用同一个 Tool 接口------它们在运行时的执行流程完全相同。区别只在于来源(MCP Server vs TypeScript 代码)和 Schema 的复杂度(MCP 工具的 Schema 由外部服务定义,不可控)。
MCP Server 的双重身份。 一个 MCP Server 可以同时提供工具和技能:
tools/list协议 → 提供工具(如slack_send_message)prompts/list协议 → 提供技能(如slack_notify_team)
源码中明确区分了这两种身份:
typescript
// src/tools/SkillTool/SkillTool.ts --- MCP 技能筛选
const mcpSkills = context
.getAppState()
.mcp.commands.filter(
cmd => cmd.type === 'prompt' && cmd.loadedFrom === 'mcp',
)MCP 提供的工具走 MCPTool 路径(直接调用),MCP 提供的技能走 SkillTool 路径(fork 子 Agent 执行)。同一个 Server,两种接入方式------这是很多人没想到的。
Skills 讲清楚:一个 Markdown 文件怎么变成行为模板
Skill 不是"另一种工具",而是行为模板------不新增能力,但改变模型使用已有能力的方式。 这也是很多人分不清的点。
一个 Skill 就是一个 Markdown 文件(.md)。frontmatter 定义元信息(名称、描述、参数),正文定义 Prompt------告诉模型"遇到这种场景时,按这个流程做"。
Skill 的执行方式完全不同于 Tools 和 MCP。 这是理解三者区别最关键的一点。
当模型调用 Skill(input={skill: "deploy"}) 时,SkillTool 做了这些事:
-
在技能目录中找到
deploy.md文件 -
解析 Markdown 内容和 frontmatter
-
fork 一个子 Agent (
runAgent()),把 Skill 内容作为 Prompt 注入 -
子 Agent 独立执行,有自己的工具池和上下文
-
子 Agent 完成后,结果回流给主 Agent
主 Agent 调用 Skill("deploy")
│
▼
SkillTool.findCommand("deploy")
│
▼
prepareForkedCommandContext() → 构建 Prompt
│
▼
runAgent({ → fork 子 Agent
promptMessages: [skill内容],
availableTools: [...主Agent的工具池],
})
│
▼
子 Agent 独立执行 → 可以调用任何 Tool 和 MCP
│
▼
结果回流给主 Agent
这意味着 Skills 不新增能力(Tools 和 MCP 做这件事),而是改变模型使用已有能力的方式。 一个 deploy Skill 可能定义了"先用 BashTool 跑测试,再用 BashTool 构建 Docker 镜像,最后用 BashTool 推送到仓库"------每个步骤用的都是已有的 BashTool,但组合方式和顺序由 Skill 预定义。
Token 效率极高------这同样是渐进式披露思想的体现。 在姊妹篇接口合约与注册组装(./03-Claude Code深度拆解-工具系统-接口合约与注册组装.md)中,我们看到了延迟加载如何用渐进式披露控制 Token 成本:不用的工具不传 Schema。SkillTool 把同样的思想应用到了 Prompt 层面------不用的 Skill 不传正文,只传摘要。
Tools / MCP / Skills 的本质区别
一句话分清:Tools 是能力(能做什么)、MCP 是连接(能连到哪)、Skills 是行为(怎么做更聪明)。
下面这张全景图从四个维度做了对比,先看全貌:
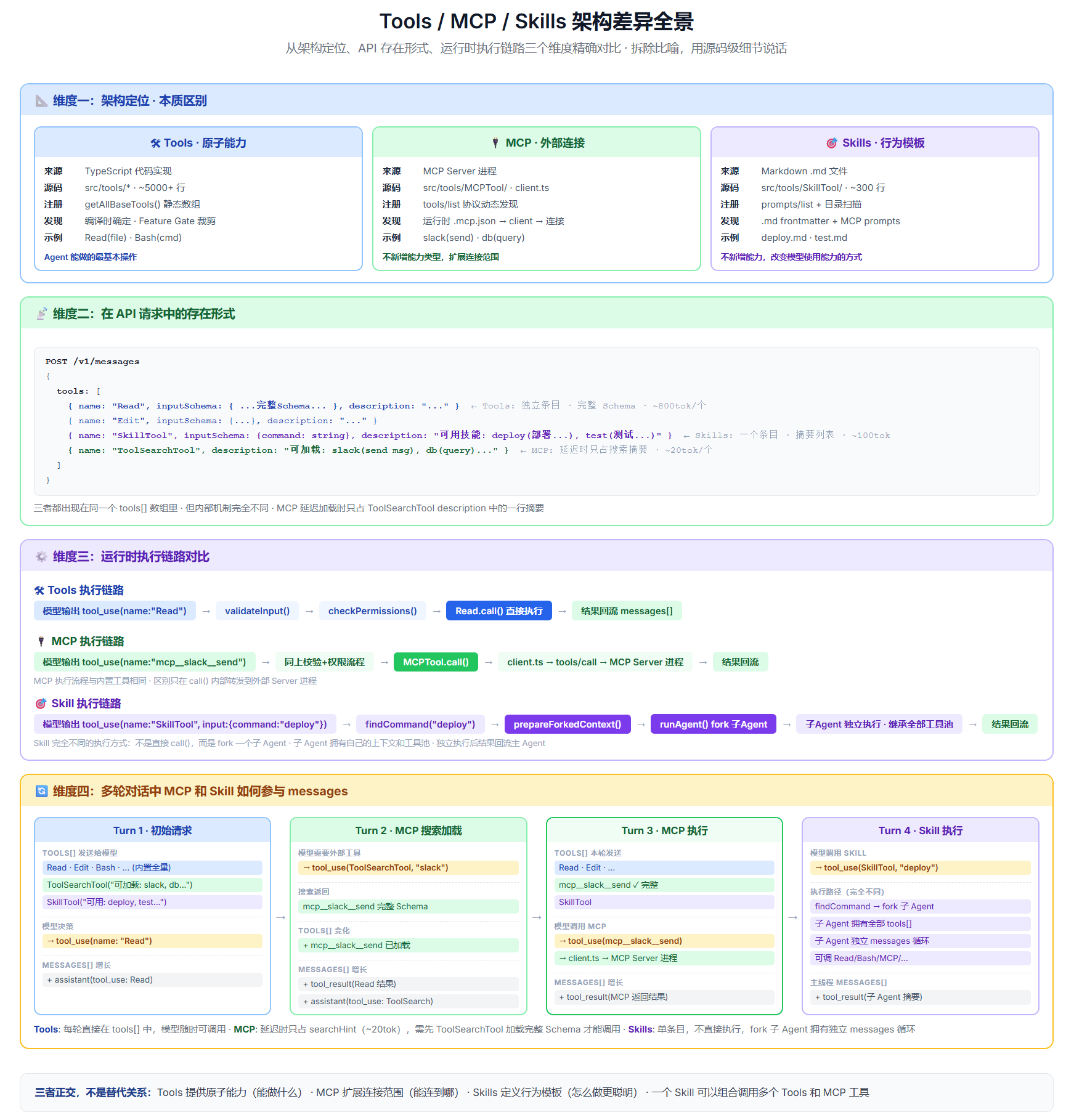
维度一:架构定位
三者根本不是同一个层面的东西。 这可能是本文最重要的一个认知------很多人把三者都当成"工具的来源"混为一谈,但实际上它们的架构定位完全不同。
Tools 是 TypeScript 代码写死的原子能力,编译时就确定了。getAllBaseTools() 返回的 30+ 个工具是一个静态列表,由 Feature Gate 在编译时裁剪------这意味着你没法在运行时凭空"发明"一个新工具,Tools 的能力边界是硬编码的。这是一种"安全优先"的思路:能力集是确定的、可控的、可审计的。
MCP 恰恰相反------它是运行时通过协议动态发现的外部服务。配置文件 .mcp.json 中声明一个 Server 地址,启动时 client.ts 的 connectToServer() 建立连接(支持 stdio 和 SSE 两种传输),然后 fetchToolsForClient() 调用 tools/list 协议获取工具列表。整个过程在运行时完成,新增 MCP Server 不需要修改一行 Claude Code 源码。
Skills 则是中间态:Markdown 文件定义行为模板,通过目录扫描(prompts/list + .md 扫描)动态发现,但它不新增能力------只编排已有能力。前端通过 frontmatter 声明元信息,正文通过 Prompt 注入改变模型的行为模式。
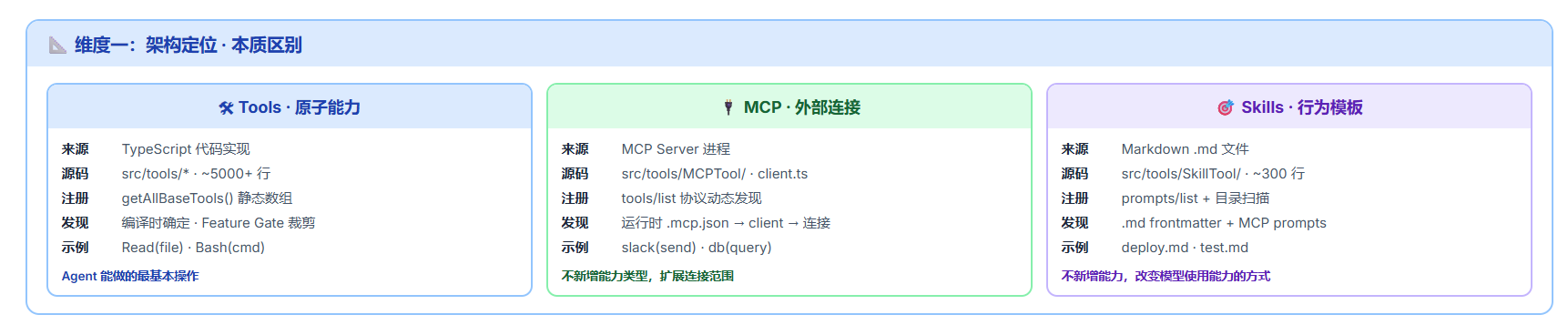
看源码路径就知道差异有多大:Tools 在 src/tools/* 下有 5000+ 行代码,每一种工具都是一套完整的 TypeScript 类;MCP 的发现逻辑在 src/services/mcp/client.ts 中(3349 行),核心是协议层的连接管理和工具包装;Skills 的核心在 src/tools/SkillTool/ 下只有约 300 行------因为它不实现新能力,本质上是"把一段 Prompt 注入到一个 fork 出来的子 Agent 里"。用一句话总结三者的本质:Tools 扩展"能做什么",MCP 扩展"能连到哪",Skills 扩展"怎么做更聪明"。
维度二:在 API 请求中的存在形式
三者都出现在同一个 tools[] 数组里,但占位方式完全不同。 这是最容易产生混淆的地方------从 API 角度看,它们长得一模一样(都是 JSON Schema),但内部的占位策略天差地别,直接决定了 Token 成本。
当你第一次发起对话时,发送给模型的 tools[] 数组大致是这样的:
- Read, Edit, Write, Bash, Glob, Grep...... 每个内置工具一个独立条目,带着完整 Schema(~500-2000 tok/个)。30 个内置工具的 Schema 加起来就占了好几万 token。这笔开销是固定的、始终存在的------不管你用不用,Schema 都在那里。
- SkillTool 一个条目,description 是所有可用技能的摘要列表(如
"可用技能: deploy(部署...), test(测试...), format(格式化...)"),大约 50-100 tok。正文内容不传------模型看到的只是一个"菜单"。 - MCP 工具不出现。 它们默认不在
tools[]里。取而代之的是 ToolSearchTool 的 description 中一行摘要(如"可加载: slack(send msg), db(query), github(create PR)"),约 20 tok/个。
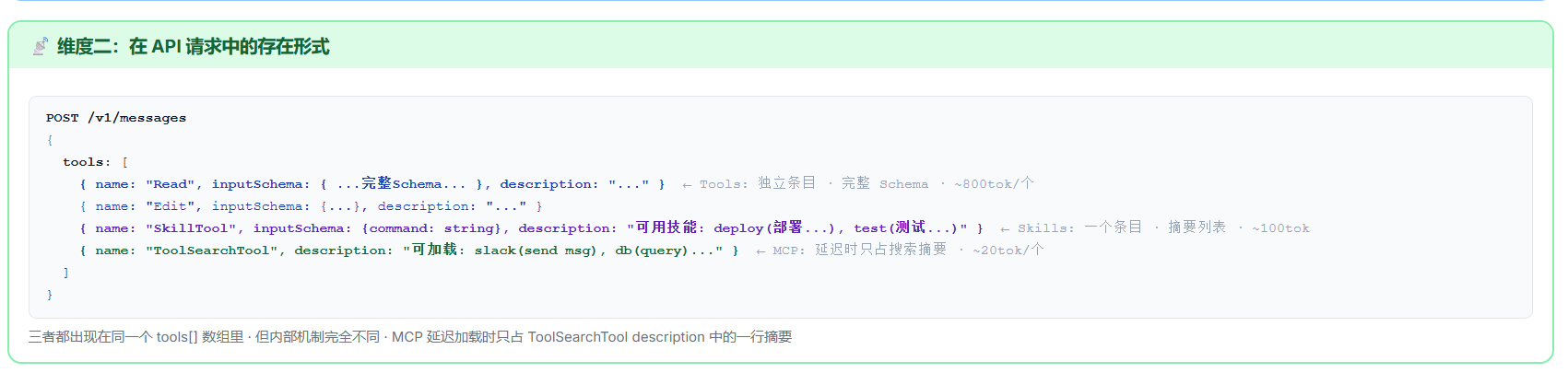
这个设计有深意。内置工具始终在是因为它们是高频刚需------Read、Edit、Bash 几乎每次对话都要用到。MCP 工具默认隐藏是因为它们可能很多(配置 5 个 MCP Server,每个提供 10 个工具,就是 50 个),全传 Schema 会把 Token 窗口撑爆。ToolSearchTool 扮演了一个"搜索引擎"的角色------模型需要什么外部工具,先搜,找到了再加载完整 Schema。
Skills 的策略更激进:所有技能永远只占一个 SkillTool 条目。即使你有 20 个 Skill 文件,对模型来说只有一行摘要。只有当模型真的调用了 SkillTool(command: "deploy"),Skill 的完整正文才会注入到 fork 出的子 Agent 的 Prompt 中。MCP 和 Skills 的 Token 效率都极高,本质上都是在做同一件事------渐进式披露:不用的不传,用到的才展开。这也是姊妹篇接口合约与注册组装(./03-Claude Code深度拆解-工具系统-接口合约与注册组装.md)中延迟加载思想在工具层面的具体体现。
维度三:运行时执行链路
三者的执行路径完全不同。 Tools 和 MCP 走的是同一条管道(call() 直接执行),但 Skills 走的是完全不同的路径------fork 子 Agent。这个差异不是实现细节,而是它们在架构中定位不同的直接体现。
Tools 的链路最直、最经典:模型在 content[] 中输出 tool_use 块(包含工具名和参数 JSON)→ 系统解析 tool_use → 调用对应的 Tool.call() → 执行结果以 tool_result 形式回流到 messages[] → 模型在下一轮看到结果后继续推理。这条链路每个工具都要经过校验输入(validateInput)、权限检查(checkPermissions)两个前置步骤------任何一步失败都会中止。
MCP 的链路和内置工具几乎一模一样------区别只在 call() 内部。MCPTool 的 call() 方法不直接执行,而是通过 client.ts 的 tools/call 协议把请求转发到外部 MCP Server 进程。MCP Server 处理完后返回结果,MCPTool 再把结果格式化成标准的 tool_result 回流传给模型。这意味着从模型视角看,调用 slack_send_message 和调用 Read 没有任何区别------但实际执行路径上,一个是在本地 TypeScript 函数中完成的,另一个是通过 JSON-RPC 协议跨进程通信完成的。
Skills 则完全不走这条管道。当模型调用 SkillTool(command: "deploy") 时,SkillTool 不会直接执行"部署"------它做的是 fork 一个全新的子 Agent,把 deploy.md 的内容作为 Prompt 注入,然后交给子 Agent 独立执行。子 Agent 拥有自己完整的上下文(独立的 messages\[\] 数组)和完整的工具池(继承主 Agent 的所有工具,包括 MCP 工具和 AgentTool 本身)。子 Agent 独立运行、独立决策------它可以调用 Bash、Read、Edit,甚至再 fork 更深的子 Agent。执行完毕后,子 Agent 的最终输出作为 tool_result 回流到主 Agent。

一言蔽之:Tools 和 MCP 是"我自己做"------主 Agent 直接调用、直接等待结果;Skills 是"我找个人来做"------主 Agent 委托一个子 Agent 去处理,自己只需等待最终汇报。这个差异也回答了为什么 Skill 不能设计成像 Tool 一样的直接 call():Skill 的执行往往需要多步操作(跑测试、构建镜像、推送仓库),中间可能需要模型多次推理和决策,这些不可能封装在一个同步函数调用里------必须由一个完整的 Agent 循环来承载。
维度四:多轮对话中如何参与 message
从对话时序来看,三者的出场时机和作用完全不同。 只看 API 请求中的 tools[] 数组只能得到一个静态快照,真正理解三者的区别需要看多轮对话的时间线。
Turn 1------初始请求。 用户说"帮我看看这个项目的测试覆盖情况"。模型收到 tools[] 数组:内置 Tools 全量在(Read、Edit、Bash、Glob、Grep......),MCP 只有 ToolSearchTool 的摘要行,Skills 只有 SkillTool 的摘要行。模型判断需要先读项目文件,于是输出 tool_use(name: "Glob", input: {pattern: "**/*.test.ts"})。这一轮只有内置工具参与了实际工作。
Turn 2------MCP 搜索加载。 运行测试后,模型判断需要发 Slack 通知团队。它注意到 ToolSearchTool 的 description 里提到 slack,于是调用 tool_use(ToolSearchTool, "slack")。系统执行搜索,找到 slack_send_message 和 slack_read_channel 两个 MCP 工具,然后调用 fetchToolsForClient() 拿它们的完整 Schema。从这一轮的回流开始,这两个工具作为独立条目出现在 tools[] 中,后续所有回合都能直接调用。
Turn 3------MCP 工具执行。 模型直接调用 tool_use(name: "mcp__slack__send_message", input: {channel: "C01...", text: "测试覆盖率报告..."})。这条调用走 MCPTool 路径,通过 tools/call 协议发到 Slack Server,Slack API 返回成功后,tool_result 回流到 messages[]。从模型角度看,这和调用 Read 没有区别。
Turn 4------Skill 执行。 用户说"帮我把当前分支部署到 staging"。模型判断这是一个需要多步操作的复杂任务,于是调用 tool_use(SkillTool, input: {command: "deploy"})。SkillTool 找到 deploy.md,fork 子 Agent。在子 Agent 内部:它先用 Bash 跑 git status 确认当前分支,然后用 Bash 跑 npm test,再用 Bash 跑 docker build -t app:staging .,最后用 Bash 跑 kubectl apply -f deploy.yaml。每一步都可能产生新的 tool_use 和 tool_result 在子 Agent 的 messages\[\] 中。全部完成后,子 Agent 的最终输出(如"已成功部署到 staging,版本号 xyz")作为主 Agent 的一个 tool_result 回流。

注意一个关键差异:MCP 工具被 ToolSearchTool 加载后,就变成了 tools[] 中的"一等公民"------它们和内置工具一样以独立条目出现,后续轮次可以直接调用,不需要再次搜索。而 Skills 永远是 SkillTool 的一个子命令------从外面看只是一个 tool_use(SkillTool, {command: "deploy"}) 调用,真正的复杂度(子 Agent 的所有推理、工具调用、中间结果)被封在子 Agent 内部,主 Agent 只能看到最终输出。这个设计非常巧妙:它让 Skills 在不污染主 Agent 上下文的前提下,完成任意复杂的操作。
三者不是替代关系,而是互补关系------它们扩展的是不同维度:能力、连接、行为。把它们都当成"工具的来源"是常见的误解,但它们真正的关系是正交的:你可以单独扩展任何一个维度,而不影响另外两个。你可以在不修改源码的前提下加 MCP Server 扩展连接范围,也可以在不写代码的前提下写 Markdown 文件扩展行为模式,还可以通过修改源码扩展核心能力。三种扩展方式的成本、门槛和风险各不相同,但它们在同一个 tools[] 数组中和谐共存------这正是 Claude Code 工具系统最精妙的设计。
本章小结
读完这些工具的源码,我最大的感受是:Claude Code 的工具设计不是一个"堆砌功能"的过程,而是一个"分层划界"的过程。六个工具族之间其实有很清晰的边界------文件操作管静态内容,搜索管信息定位,执行管系统交互,Agent 控制管任务编排,信息获取管外部知识,辅助工具管交互体验。每个族只做自己的事,不会越界。这种分层的清晰度,在你读 getAllBaseTools() 的时候不一定能感受到,但当你深入到每个工具的实现里去,就会发现它们的职责划分异常干净。
关于 Tools / MCP / Skills 三者的关系,说实话我一开始也是混淆的。它们都出现在 tools[] 数组里,从 API 的角度看长得一模一样。但读完源码之后我才意识到,这三者根本不是同一个层面的东西------Tools 是原子能力,MCP 是连接协议,Skills 是行为模板。我之前犯的错误,就是把它们都当成了"工具的来源",但实际上它们扩展的是完全不同的维度:能力、连接、行为。这个认知转变是读这篇文章最大的收获。
还有一个让我印象深刻的设计是 Skill 的 fork 执行模式。一个 Markdown 文件,fork 一个子 Agent 去执行,结果再回流------这个机制非常轻量,但表达力极强。你不需要写任何代码,只要用自然语言描述流程,模型就按你的方式去工作。这让我重新思考了"工具"和"指令"的区别------工具给你能力,指令给你方向,而 Skill 正好站在两者的交汇点上。
至于工具"怎么运行------从模型输出 tool_use 到结果回流",那是姊妹篇运行时流水线(./03-Claude Code深度拆解-工具系统-运行时流水线.md)的主题。
系列导航:
本文属于 《Claude Code 源码 Deep Dive》 系列中「工具系统」命题的子篇章,专注于 内置工具全景与三方协作。
姊妹篇 更新中,敬请期待:
- Claude Code 深度拆解:工具系统------30+ 工具怎么统一注册、按需加载
- Claude Code 深度拆解:工具系统------运行时流水线
- Claude Code 深度拆解:工具系统------权限、沙盒与错误处理
如果这篇文章对你有帮助,欢迎点赞收藏 支持一下。如果你对 Claude Code 源码感兴趣,欢迎关注本系列 后续更新。有任何想法或疑问,欢迎评论区留言讨论 👋