配图:开源 AI 工作流底座正在加速。重点不是追逐单个模型名,而是理解它如何进入自动化流程。
写在前面:这不是一篇泛 AI 新闻汇总。我的视角是自动化、效率工具和一人公司:这些更新到底会不会改变我们的信息处理、内容生产、知识管理和自动化执行方式?
今日主线

配图:信息发现 → 证据核验 → 价值判断 → 自动化执行 → 结果分发。
今天值得关注的不是某一条标题,而是几个底层模块同时变化:端侧推理、本地模型入口、高吞吐推理服务、模型适配层、Agent 编排层。
一句话总览
| 方向 | 代表事件 | 对工作流的影响 |
|---|---|---|
| llama.cpp | llama.cpp 一天多次更新,端侧推理仍在高频迭代 | 本地/边缘推理不是"玩具",它会进入隐私数据处理、低成本批处理和离线自动化。 |
| Ollama | Ollama 连续候选/补丁发布,本地模型入口继续稳定化 | 本地模型从"能跑"走向"可纳入日常自动化",适合内部知识库、脚本助手和私有数据预处理。 |
| LangChain | LangChain 组件密集发版,Agent 编排层继续细颗粒更新 | Agent 工作流的可靠性往往藏在适配器、工具调用、回调和运行时细节里。 |
| vLLM | vLLM v0.20.0 推进高吞吐推理服务 | 批量摘要、RAG、内容生成和自动客服的规模上限,最终会被推理吞吐与成本约束。 |
| Transformers | Transformers v5.6 系列快速补丁,模型适配层保持快节奏 | 模型能力真正落地,通常先要经过通用适配层、模型加载、推理接口和兼容性修复。 |
1. 端侧推理:llama.cpp 仍在高频前进
GitHub Release 显示,llama.cpp 在 4 月 24 日出现 b8920、b8922 等发布。它的意义不只是"又发了一个版本",而是代表本地/边缘推理仍在持续工程化。
- 效率价值:私有数据预处理、离线摘要、批量改写可以不必全部送到云端。
- 一人公司价值:小规模任务可以先用本地模型跑通,再决定哪些环节上云。
2. 本地模型入口:Ollama 继续补丁与候选发布
Ollama 的更新说明本地模型入口正在变得更接近日常工具。对于个人自动化,它的价值是把模型调用变成一个简单、稳定、可脚本化的接口。
3. Agent 编排:LangChain 组件密集更新
Agent 不是一句口号,实际落地依赖工具调用、适配器、状态管理、回调和运行时。LangChain 相关组件的快速发版,提醒我们:工作流可靠性经常藏在这些"小版本"里。
4. 高吞吐推理:vLLM 影响自动化规模上限
当一个流程需要大量生成、摘要、检索增强或自动客服时,决定成本的往往不是提示词,而是推理服务吞吐和资源利用率。vLLM 这类项目会直接影响自动化是否能从"演示"变成"可持续运行"。
5. 模型适配层:Transformers 仍是能力落地中间层
Transformers 的快速补丁说明,模型生态不是只由发布会驱动,真正落地还要经过通用适配层、模型加载、推理接口和兼容性修复。
6. 开源推理栈:真正的落地能力在这里
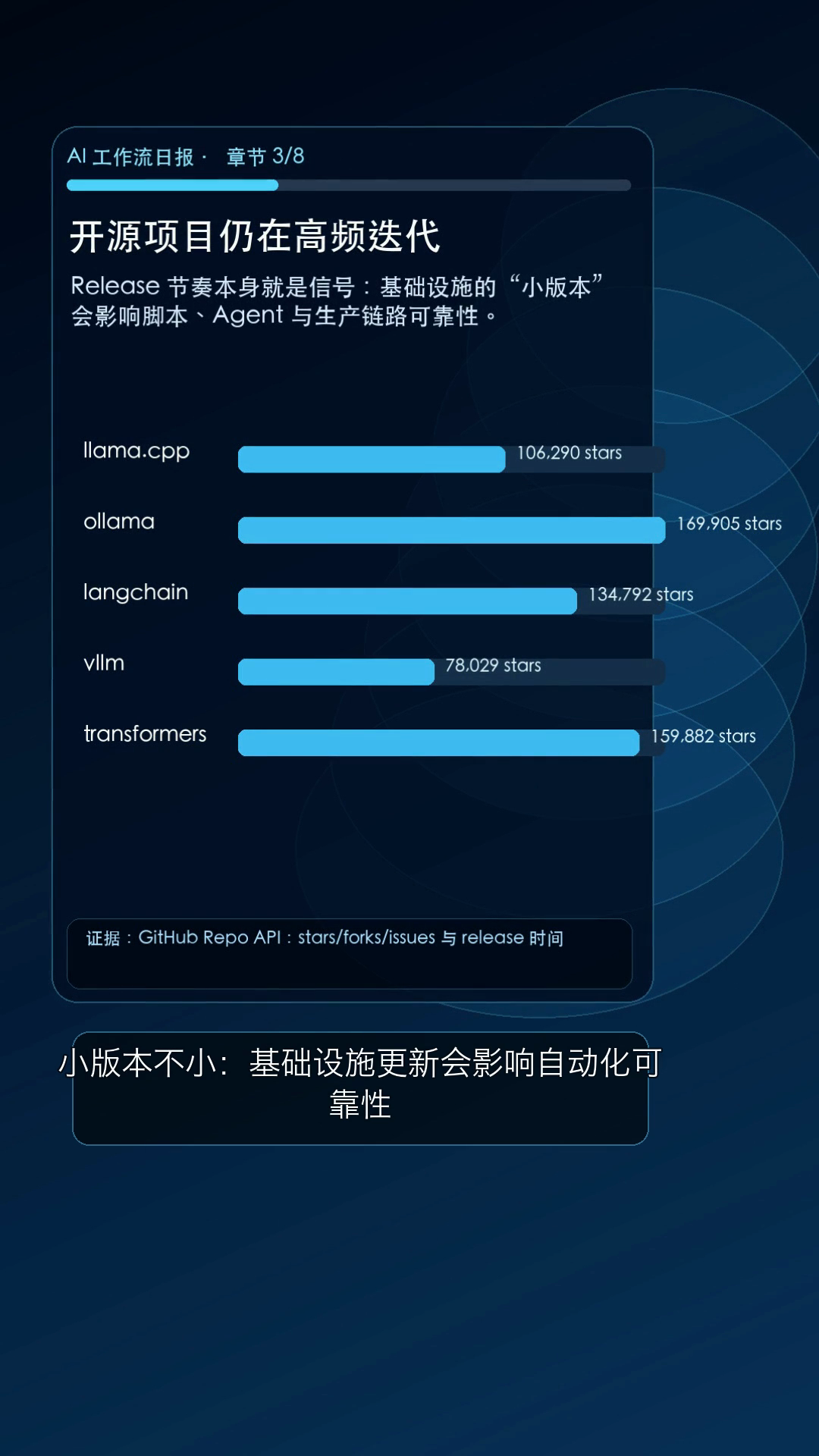
配图:开源项目热度与基础设施更新,指向应用层 / Agent 编排 / 推理服务 / 模型与数据 / 硬件成本的持续迭代。
如果从效率创作者视角看,今天这些新闻可以被拆成一个更实际的技术栈:
- 应用层:内容生产、知识库、客服、数据整理。
- Agent 编排层:把工具调用、状态和重试机制组织起来。
- 推理服务层:决定吞吐、延迟和成本。
- 模型与数据层:决定兼容性和可替换性。
- 硬件成本层:决定这个流程能不能长期运行。
给效率创作者的行动建议
- 不要只收藏新闻,先把更新映射到自己的流程模块。
- 本地推理适合处理隐私、低成本、可批量的任务。
- 云端高吞吐推理适合需要稳定规模化的任务。
- Agent 编排层要关注日志、重试、状态和工具权限。
- 每周复盘一次:哪些模型或工具可以替换掉重复人工判断?
我的结论
今天的 AI 工具圈变化,核心不是"又多了几个版本号",而是基础设施继续向可嵌入、可替换、可自动化的方向推进。对一人公司来说,真正的优势来自把这些变化变成自己的工作流资产,而不是把它们当成新的信息焦虑来源。