一、引言
上一篇文章从 Flink 监控底层逻辑出发,介绍了Flink作业生产运行必盯的核心指标与完整的 Flink 作业监控体系的搭建。本文会结合近几年的生产问题排查经验,介绍几种常见生产问题场景下的异常指标识别与快速定位修复。
二、常见指标异常故障诊断
1.反压------最常见,也最容易被误解
现象:WebUI中某些算子显示"High"反压;outPoolUsage持续接近1.0;inPoolUsage逐渐升高。
定位方法:
- 确定瓶颈算子:从Source开始向后追踪。在Flink 新版本中,WebUI会直接标识瓶颈位置。对于旧版本,观察
outPoolUsage:某个算子的输出缓冲区使用率很高而下游算子的输入缓冲区使用率正常→瓶颈在该算子自身;如果下游算子的输入缓冲区也很高→瓶颈在下游。
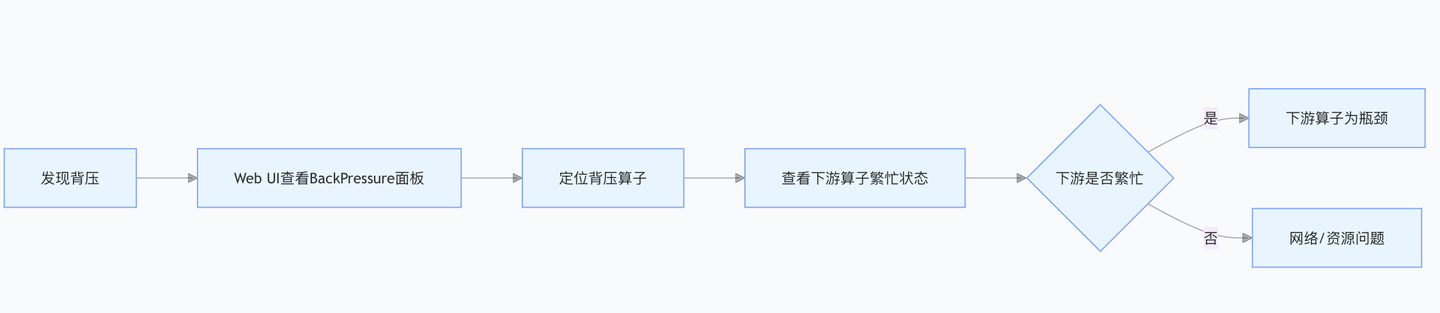
- 深入分析瓶颈算子内部:算子逻辑是否复杂(如大量的外部IO调用、复杂计算);是否使用了同步外部调用(如同步读写数据库);是否存在数据倾斜(部分子任务输入量远高于其他子任务)
- 查看ThreadDump和Flame Graph:通过WebUI获取TaskManager的线程堆栈,观察算子是否长时间阻塞在某个操作上。
修复策略:
| 根因 | 修复方法 |
|---|---|
| 下游外部系统瓶颈(数据库、Kafka等) | 优化外部系统配置(扩容、增加连接池、调优写入批次) |
| 算子计算密度过高 | 调大资源或增加该算子的并行度,或将复杂算子拆分为多个简单算子 |
| 数据倾斜 | 重新分区(keyBy 优化)、使用随机前缀、加盐等方法 |
| 网络瓶颈 | 增加网络缓冲区大小、检查网络配置 |
在解决反压问题之前,不要盲目增加Source并行度------这只会让数据堆积更快,反压更严重。
2.Checkpoint持续失败或超时------容错能力的警报
现象:numberOfFailedCheckpoints持续增加;lastCheckpointDuration超过超时阈值(默认10分钟);作业日志中出现"Checkpoint expired"或"Decline checkpoint"错误。
定位方法:
Flink的Checkpoint流程分为四个阶段,任何阶段的异常都可能导致失败:
- Trigger阶段:JobManager向所有Source发送RPC请求触发Checkpoint。
- Barrier对齐阶段:下游算子需等待所有上游的Checkpoint Barrier到达。
- 异步持久化阶段:状态后端将数据写入远程存储。
- 完成汇报阶段:所有Task向JM发送确认。
关键诊断指标:
- 对齐时间(Alignment Duration)过长 → 瓶颈在同步阶段,通常由反压引起。Flink的Chandy-Lamport分布式快照依赖于Barrier的传播,反压时Barrier在拥塞通道中流动缓慢,导致对齐等待时间急剧增加。
- 异步时间(Async Duration)过长 + Checkpointed Data Size较大 → 瓶颈在异步阶段的状态上传。
修复策略:
| 瓶颈阶段 | 修复方法 |
|---|---|
| 反压导致的对齐超时 | 先解决反压问题,反压解决后若仍有问题,考虑启用Unaligned Checkpoint |
| 状态数据过大导致异步上传慢 | 启用增量Checkpoint、增加并行度减少单Task的状态量、使用原生快照(原生快照生成速度更快、存储占用更小) |
| 状态后端存储慢或异常 | 解决存储后端服务稳定性与性能,检查网络/权限等 |
| 参数配置问题 | 适当增加execution.checkpointing.timeout(建议设为平均完成时间的1.5~2倍)、设置execution.checkpointing.tolerable-failed-checkpoints容忍少量失败 |
3.数据倾斜------热Key的噩梦
现象:作业整体吞吐量下降;在WebUI中,某个子任务的numRecordsInPerSecond远高于同并行度的其他子任务;该子任务的延迟和Checkpoint耗时也显著偏高。
定位方法:
- 检查
keyBy之后各分区的记录数分布。 - 分析数据中Key的分布情况,识别"热Key"。
- 查看是否有大量空值或默认值被用作Key(如
null、空字符串等)。
修复策略:
| 方法 | 说明 | 适用场景 |
|---|---|---|
| Key打散(加盐) | 为热Key添加随机前缀,先进行局部聚合,再去除前缀进行全局聚合 | Group聚合场景 |
| LocalGlobal聚合 | 开启Mini-Batch优化,先本地聚合再全局聚合,大幅减少Shuffle数据量 | SQL作业Group聚合 |
| 优化Key设计 | 使用更细粒度的Key,避免少数Key承载过多数据 | 通用 |
| 使用Rescale | keyBy().rescale()重新分区 | 部分场景 |
| 广播小表 | 对于大表Join小表,将小表广播到所有并发任务中 | Join场景 |
4.资源异常------资源的错配
现象:Flink作业的TM-cpu使用率长时间超过80%,频繁OOM触发作业重启
定位方法:
- 排查所有TM-cpu使用率是否都高,确认是数据倾斜还是整体资源配置不足的问题
- 检查Flink作业的资源配置,是否出现cpu核数与numberOfSlots错配情况
- 关注TM的内存使用率与GC监控,是否内存资源分配不合理
修复策略:
| 场景 | 修复方法 |
|---|---|
| 数据倾斜导致局部cpu高 | 按优化key设计、两阶段聚合等方法解决倾斜问题 |
| 整体cpu都很高 | 调大cpu资源或保持cpu核数与numberOfSlots对应(建议1:1或适当冗余) |
| 堆内存使用率一直很高,频繁fullGC | 调大内存资源或增加并行度 |
| old gc触发频繁 | 调大堆内存或提升old gc触发阈值 |
5.稳定性风险------最隐蔽的杀手
现象:作业规律性触发自动重启,numRestarts一直累加,但未触及容错重启策略失败停止
定位方法:
- 根据numRestarts指标增加时间点,横向观察其他功能/性能指标
- 根据对应时间段,排查JM/TM运行日志,定位报错原因
修复策略:
| 场景 | 修复方法 |
|---|---|
| 上游定期有批量卸数 | 实时处理增加健壮性,如增加限流或冗余一定资源应对 |
| 大状态使用未设置TTL | 设置合理的TTL,如StateTtlConfig配置过期时间,适当调大taskmanager.memory.managed.fraction |
| 内存压力大 | 调大整体内存或增加并行度 |
| 强依赖外部服务,如HBase维表查询超时 | 设计上增加缓存或降级能力,减少依赖影响 |
| 作业容错重启策略未有效覆盖numRestarts累增异常 | 优化restart-strategy,平衡容错能力与风险预警阻断 |
6.数据延迟------问题的具像化
现象:Flink作业加工的下游数据时效性延迟较大(currentEmitEventTimeLag与KafkaConsumer.records.lag.max不断增长),达到分钟级乃至小时级
定位原则:数据延迟是上述五种异常场景发生时,对外的直观表现;只要Flink作业处于亚健康状态,都会带来数据延迟,因此我们必须要做好运行指标的监控与预警,及时识别定位修复问题,避免数据延迟进一步扩散。
三、日常巡检与预防性优化要点
1.日常巡检清单
- 检查作业状态是否正常(RUNNING)
- 确认 Checkpoint 成功率 100%
- 查看背压状态,确保无持续红色 / 黄色
- 关注JM/TM资源使用率,确保维持在健康区间
- 监控延迟指标,确保符合 SLA
- 检查状态大小,确认无异常增长
- 查看重启次数,确保无频繁重启
2.预防性优化建议
- 配置基线:为每个作业建立指标基线,便于异常识别
- 定期压测:每月进行一次作业极限压测,验证系统容量
- 状态清理:定期清理过期状态,防止状态膨胀,同时避免小文件问题
- 文档完善:记录常见故障与解决方案,形成知识库
- 版本升级:及时升级 Flink 版本,利用最新优化特性
四、总结展望
在日常Flink集群与作业的运维过程中,运行指标的监控就是我们掌控生产运行状态的"眼睛",通过它可以实时反映当前集群作业的健康度,并评估出未来一段时间的运行趋势。我们要充分合理地运用这双"眼睛",帮助我们制定高效的事前预防机制、事中应急处置措施、事后治理优化方案,全方位保障FLink的生产稳定运行。