Test-Time Compute (推理期 算力 ) ,或者被称为 "System 2 思考 (慢思考)" ,是继 ChatGPT 诞生之后,AI 发展史上最大的一次 范式 转移。
它标志着大模型终于戒掉了"说话不过脑子"的毛病,真正学会了像人类顶级科学家一样,在开口之前先"打草稿"和"自我反思"。这也是以 OpenAI o1 模型为代表的新一代推理模型能够震撼世界的底层逻辑。
我们借用诺贝尔经济学奖得主丹尼尔·卡尼曼在《思考,快与慢》中提出的概念,来看看 AI 是如何完成这次进化的。
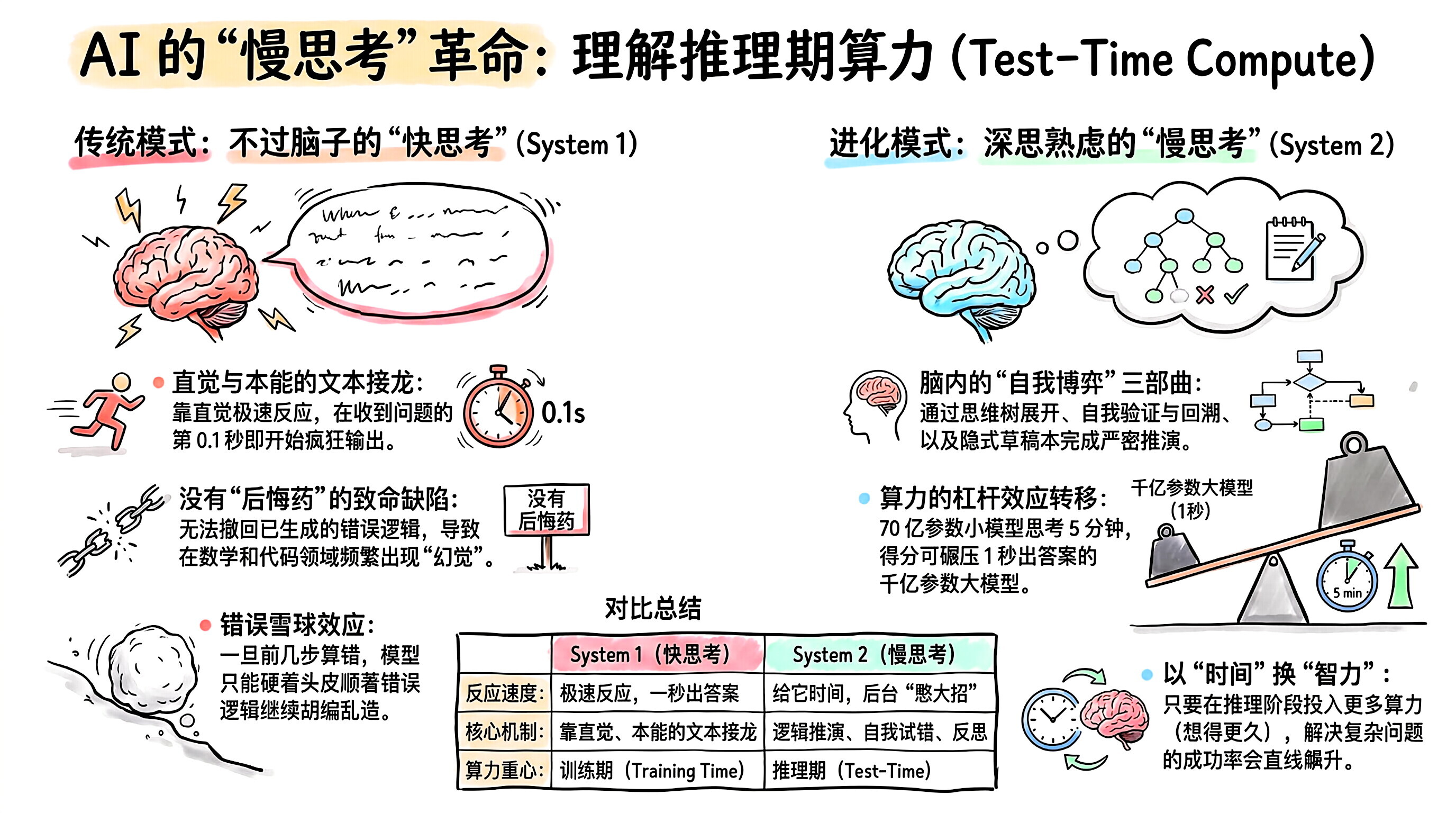
1.🛑 核心痛点:以前的大模型都是"不过脑子"的 (System 1)
从 GPT-3 到早期的 GPT-4,甚至大多数开源模型,它们的工作模式都属于 System 1 (快思考):靠直觉、本能、极速反应。
-
致命缺陷:没有"后悔药":传统的文本接龙(自回归生成)是一个字一个字往外蹦的。当你给它一道极其复杂的奥数题时,它在收到问题的第 0.1 秒就开始疯狂输出答案。
-
现象 :如果它在写到第三步时突然发现自己算错了,它没法把前面说出的话撤回(因为之前生成的词已经被当作已知条件了)。于是,它只能硬着头皮顺着错误的逻辑继续胡编乱造,这就是数学和代码领域"幻觉"的重灾区。
2.🧠 System 2 觉醒:让子弹飞一会儿
Test-Time Compute (推理期 算力 ) 提出了一个极其颠覆的想法: 与其花几百个亿去训练一个极其庞大的模型(在"训练期"砸算力),不如在用户提问后,多给模型一点时间去思考(在"推理期"砸算力)。
-
理念:如果一个问题很难,不要要求 AI 一秒钟出答案。给它 10 秒钟、1 分钟、甚至 1 个小时的计算资源,让它在后台"憋大招"。
-
Scaling Law 的延续 :科学家惊喜地发现,只要你在推理阶段给模型投入更多的算力(让它想得更久),它解决复杂数学、编程和逻辑推理问题的成功率就会直线飙升。
3.⚙️ 它是怎么在脑子里"打草稿"的?
当你使用具备 System 2 能力的模型(比如 o1)时,你会发现它在给出最终答案前,界面上会显示"思考中 (Thinking...)"。在这几十秒里,它的脑子里其实在上演一场极其激烈的自我博弈:
-
思维树展开 ( Tree of Thoughts):面对一个编程难题,它不会只顺着一条路走。它会在脑子里同时生成 A、B、C 三种不同的解题思路。
-
自我验证与回溯 (Self-Reflection & Backtracking) :它像下国际象棋一样,顺着思路 A 往下推演了几步,突然发现:"等等,如果用这种算法,最后内存会溢出,这条路不通。" 于是,它果断抛弃思路 A,退回到上一步,开始尝试思路 B。
-
隐式草稿本 (Hidden Scratchpad):它在后台洋洋洒洒写了几千字的分析、推导和验算代码(这些大部分不会展示给你看,为了节省你的阅读时间)。
-
最终输出:当它在脑海里确认思路 B 是完美无缺的之后,才把最终精简、准确的答案打印在你的屏幕上。
4.🚀 惊天大逆转:小模型打败大模型
Test-Time Compute 带来了 AI 工业界的一个巨大震动:算力 的 杠杆效应 发生了转移。
过去,只有参数量极其庞大(比如万亿参数)的巨无霸模型才能解开复杂的微积分题。 但现在,一个只有 70 亿参数的小模型 ,如果赋予它 System 2 的思考架构,并允许它在后台思考 5 分钟,它的最终得分竟然可以碾压一个回答只用 1 秒钟的千亿参数巨无霸!
这就是为什么现在的开源社区变得极其兴奋:普通人哪怕只有一张消费级显卡,只要愿意等,也能用小模型跑出极其震撼的逻辑推理结果。
总结
Test-Time Compute (System 2 思考) 补齐了大模型智力版图上最缺失的一块拼图------"耐心与反思"。
它不再单纯依赖读过多少书(训练数据),而是学会了利用现有的知识,通过极其严密的逻辑推演和自我试错,去解决全人类都从未见过的新问题。