文章目录
- [AI Agent开发课程笔记记录 - 提升篇 About RAG](#AI Agent开发课程笔记记录 - 提升篇 About RAG)
-
- 了解RAG
- NativeRAG
- GraphRAG
- 搭建RAG(Qwen-Agent)
- [RAFT(Retrieval Augmented Fine-Tuning)](#RAFT(Retrieval Augmented Fine-Tuning))
- 具体案例
AI Agent开发课程笔记记录 - 提升篇 About RAG
了解RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种解决大模型"知识有限"和"幻觉"问题的技术架构。它的核心思路是:不让模型只依赖自己训练时记住的知识来回答,而是在回答前先去外部知识库(如公司文档、产品手册、数据库)中检索相关的片段,把这些片段作为"参考资料"和问题一起交给模型,让模型基于这些真实资料生成答案。 这样,模型既能回答私域或最新知识(无需重新训练),又能大幅减少胡编乱造,因为答案有据可循。典型的应用场景是:企业把自己的内部文档做成知识库,让AI客服能准确回答产品问题。
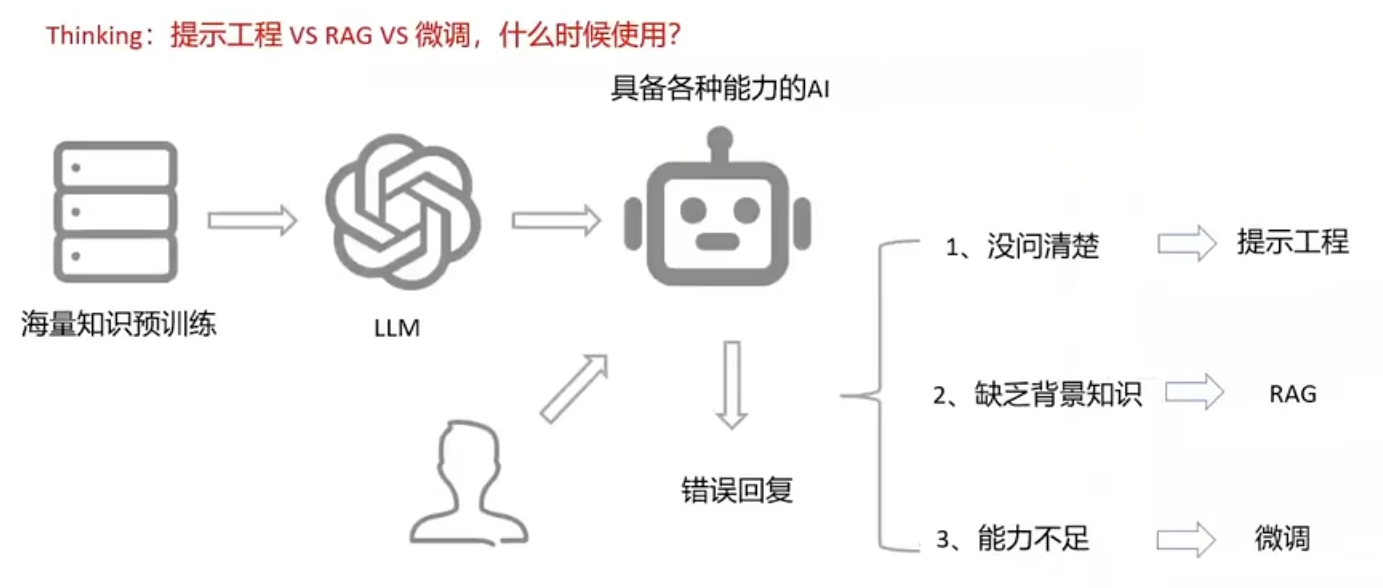
NativeRAG
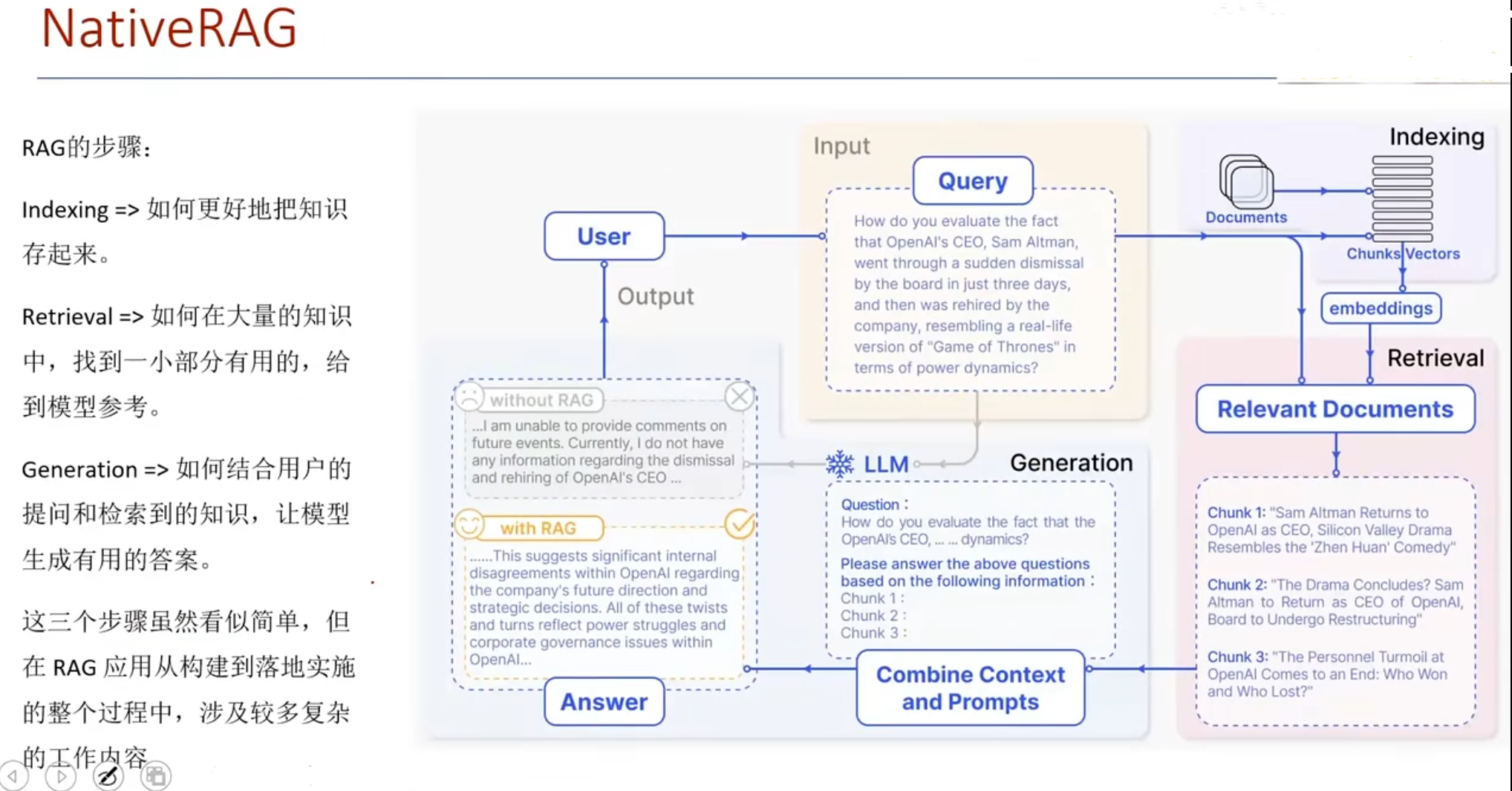
GraphRAG
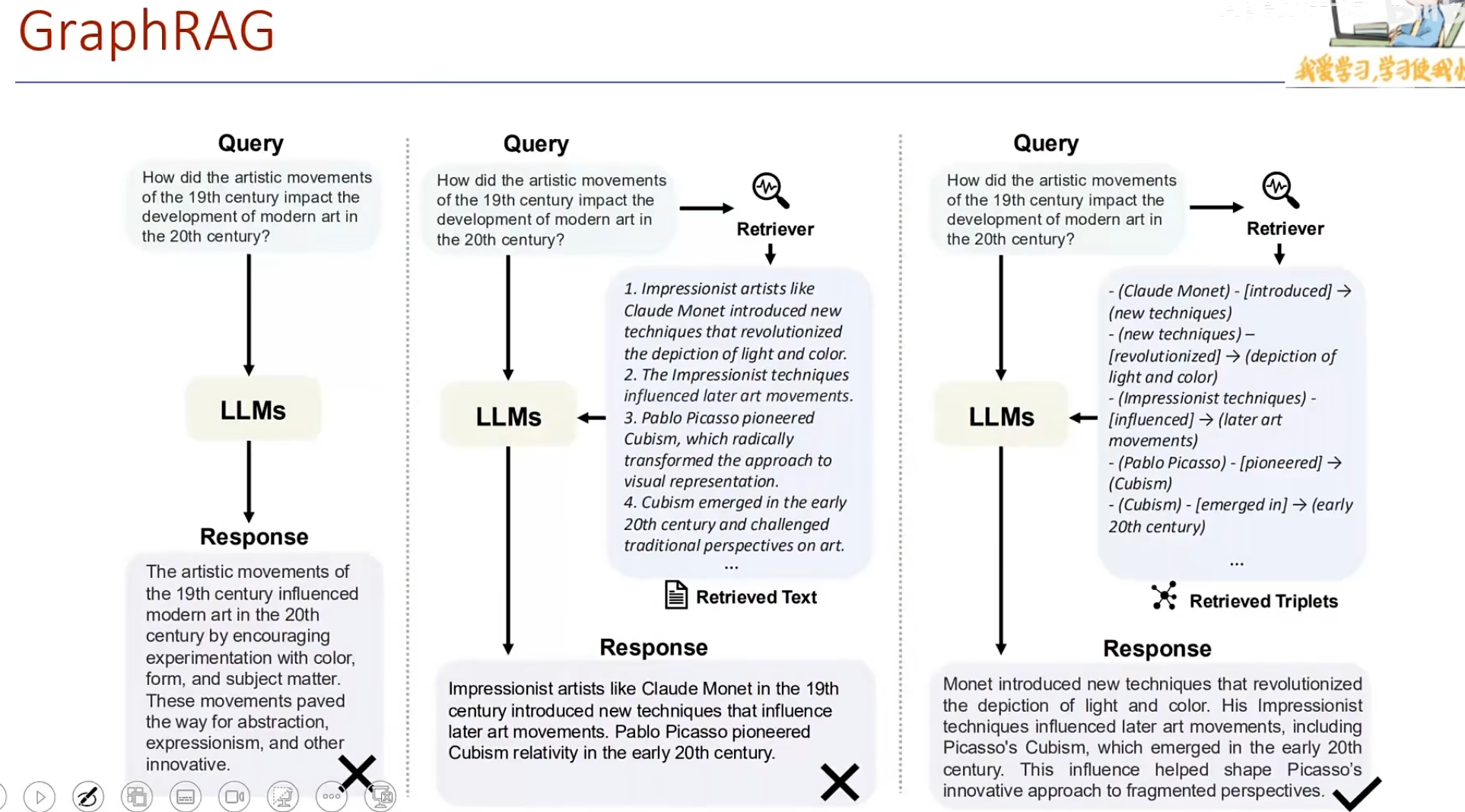
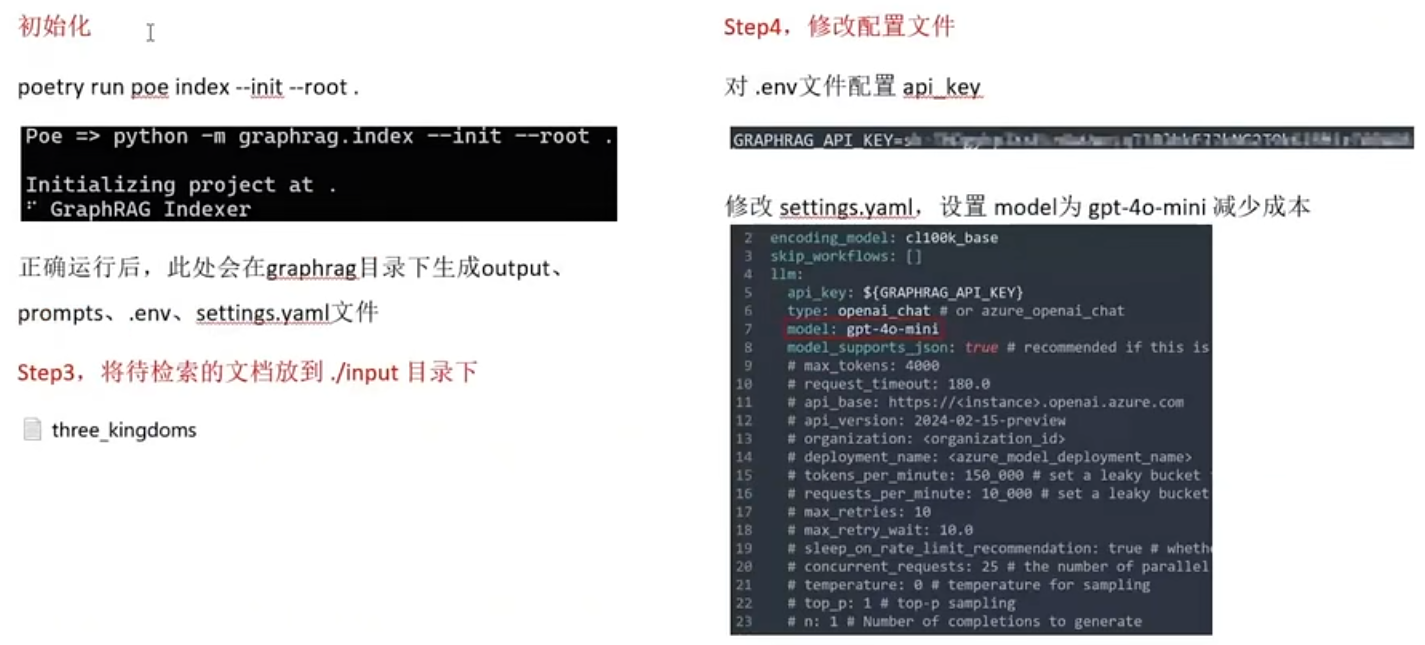
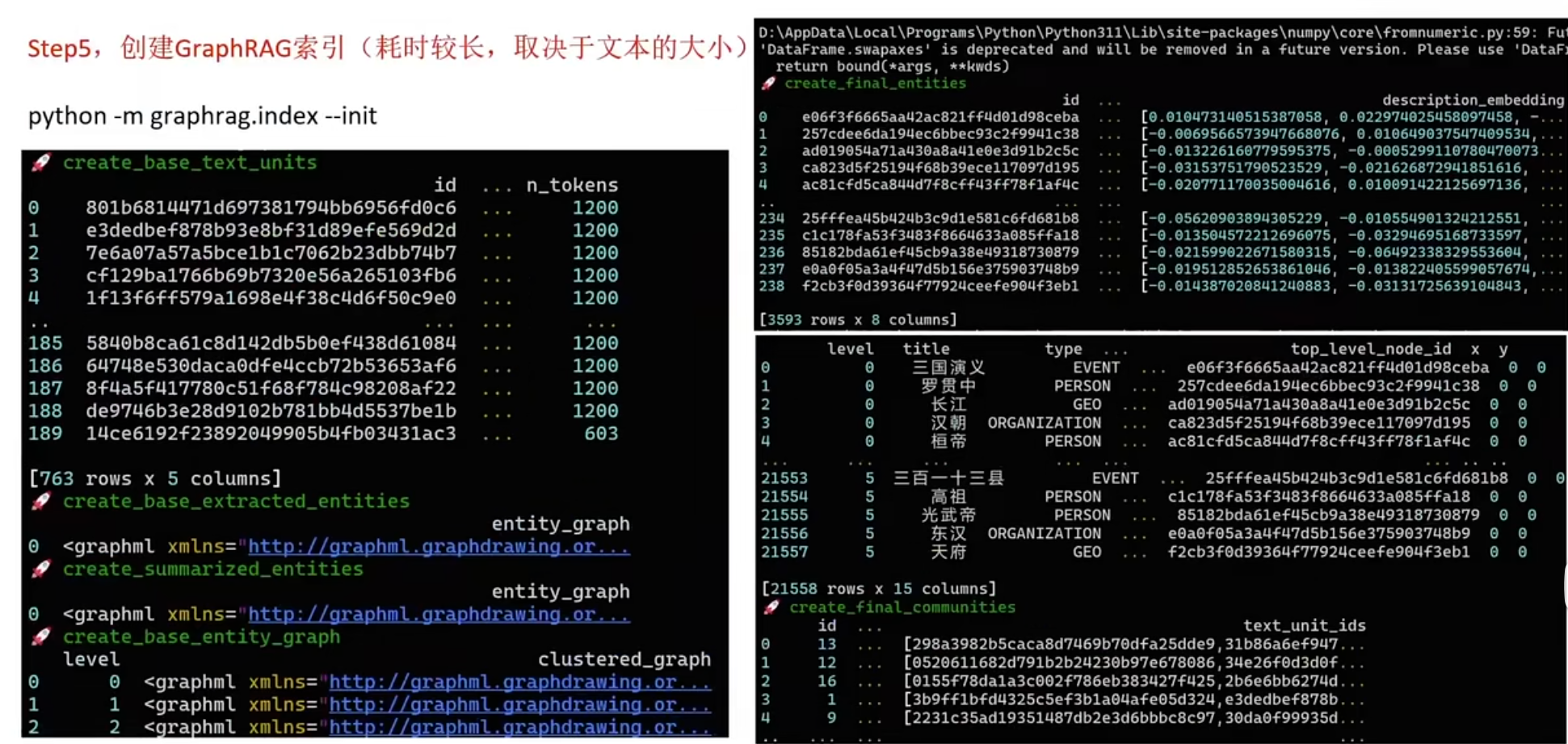
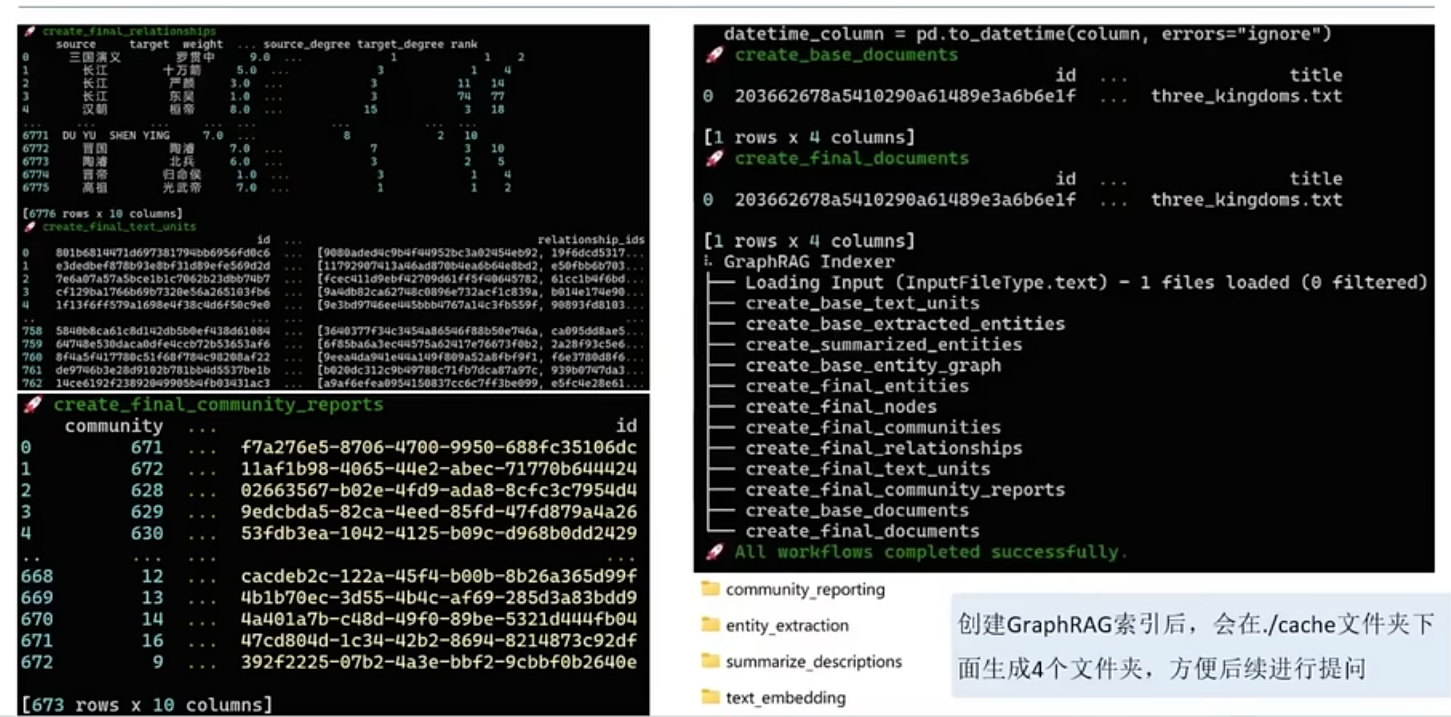

搭建RAG(Qwen-Agent)

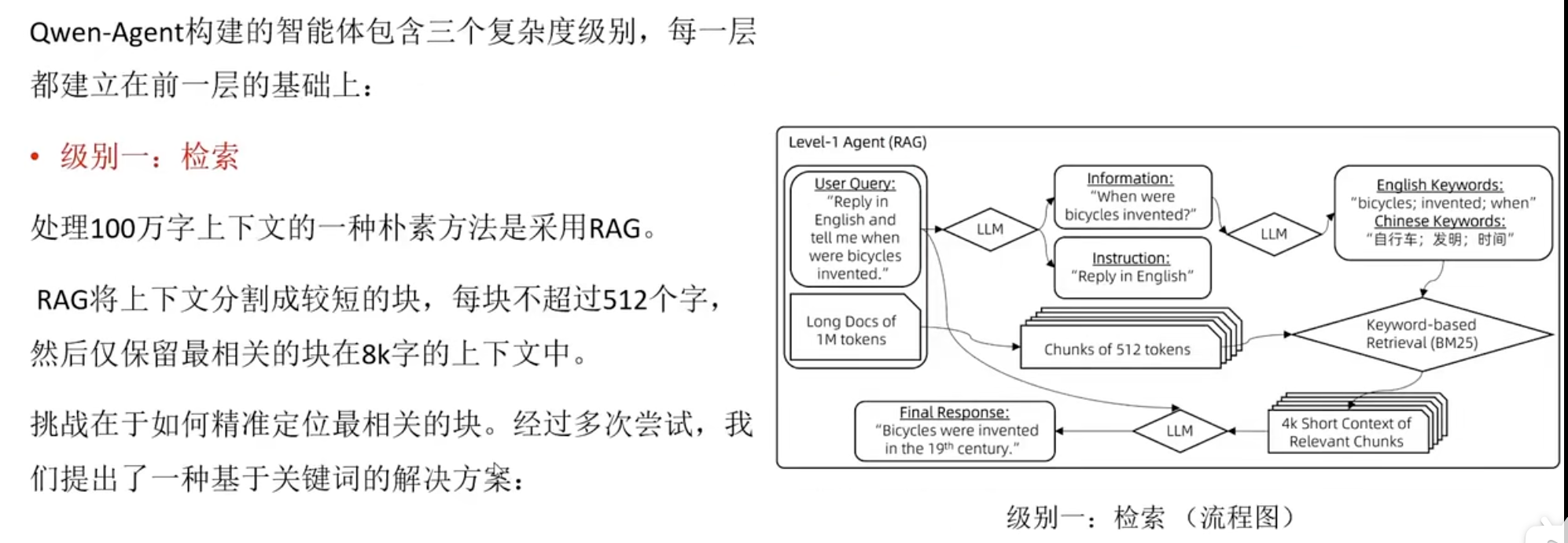
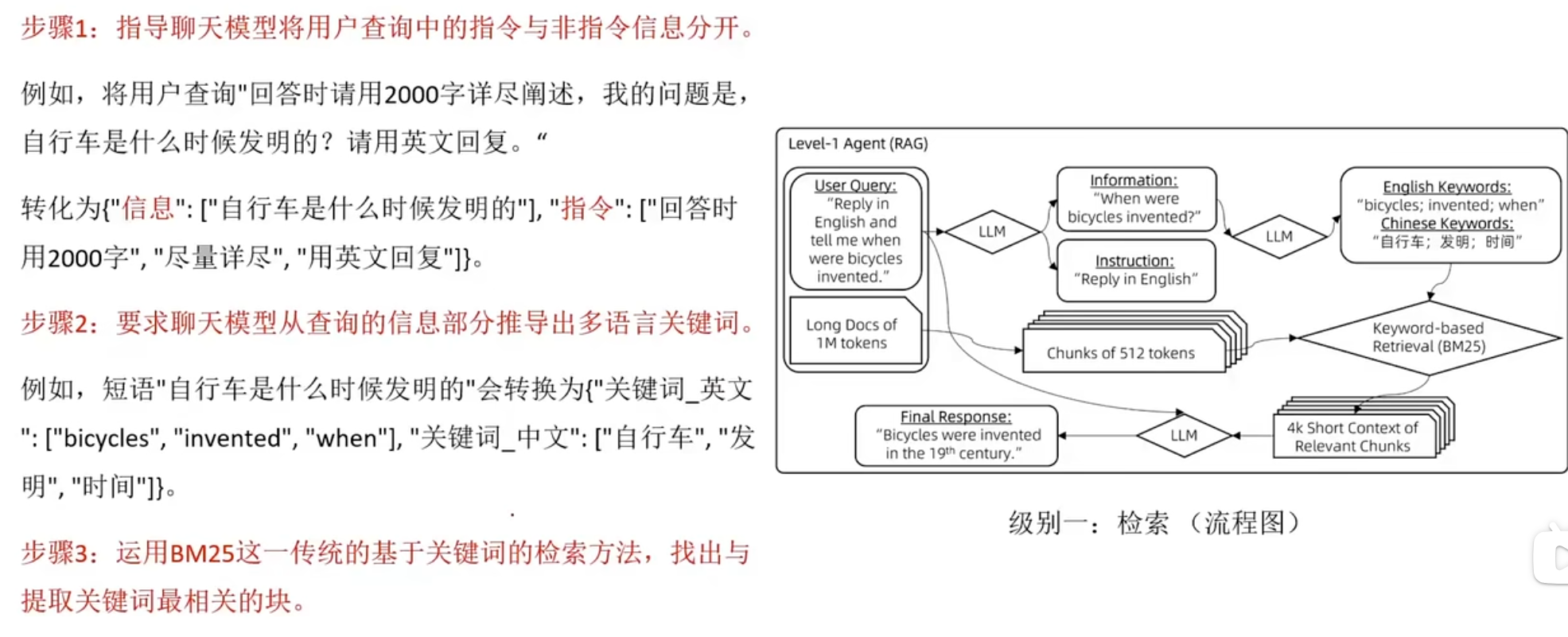
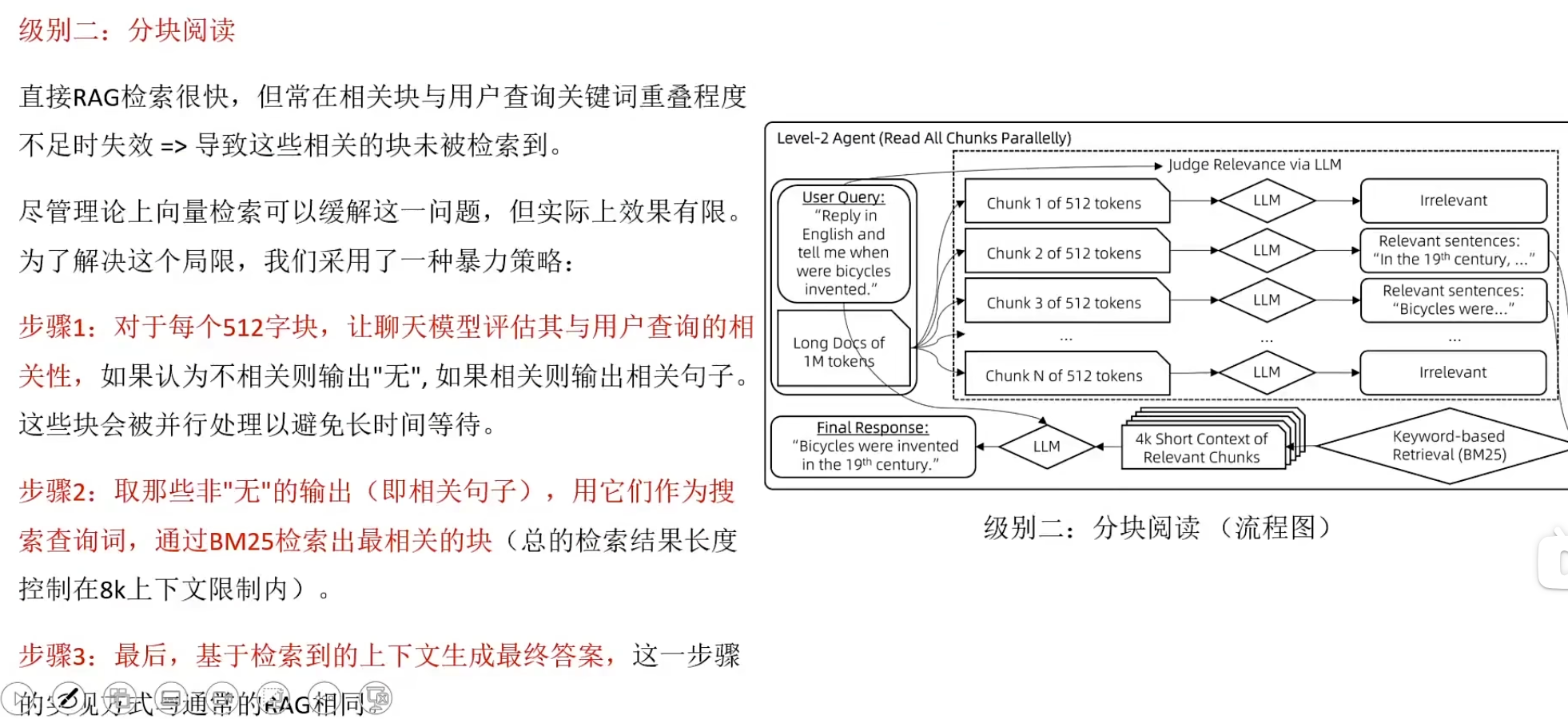

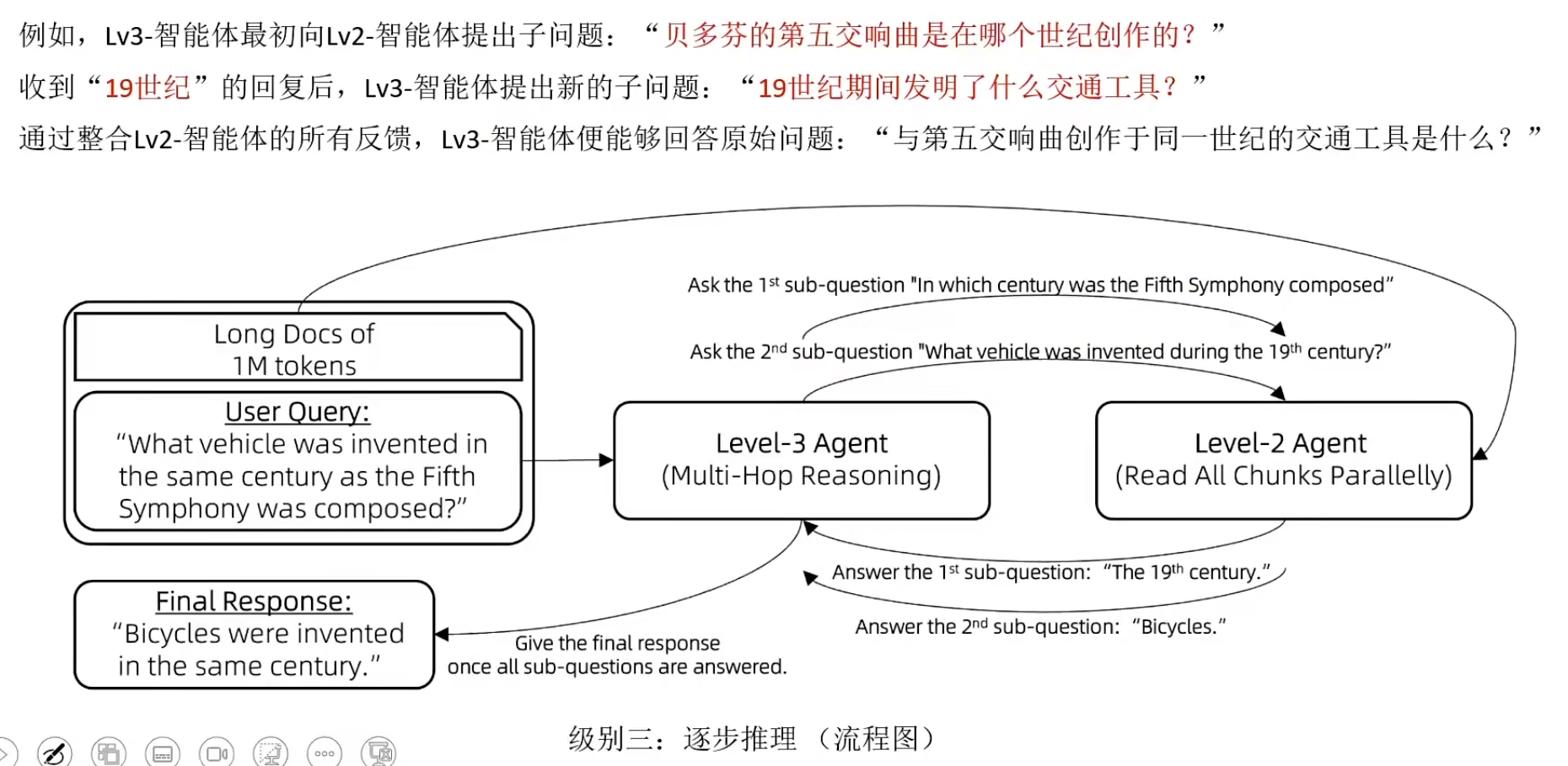
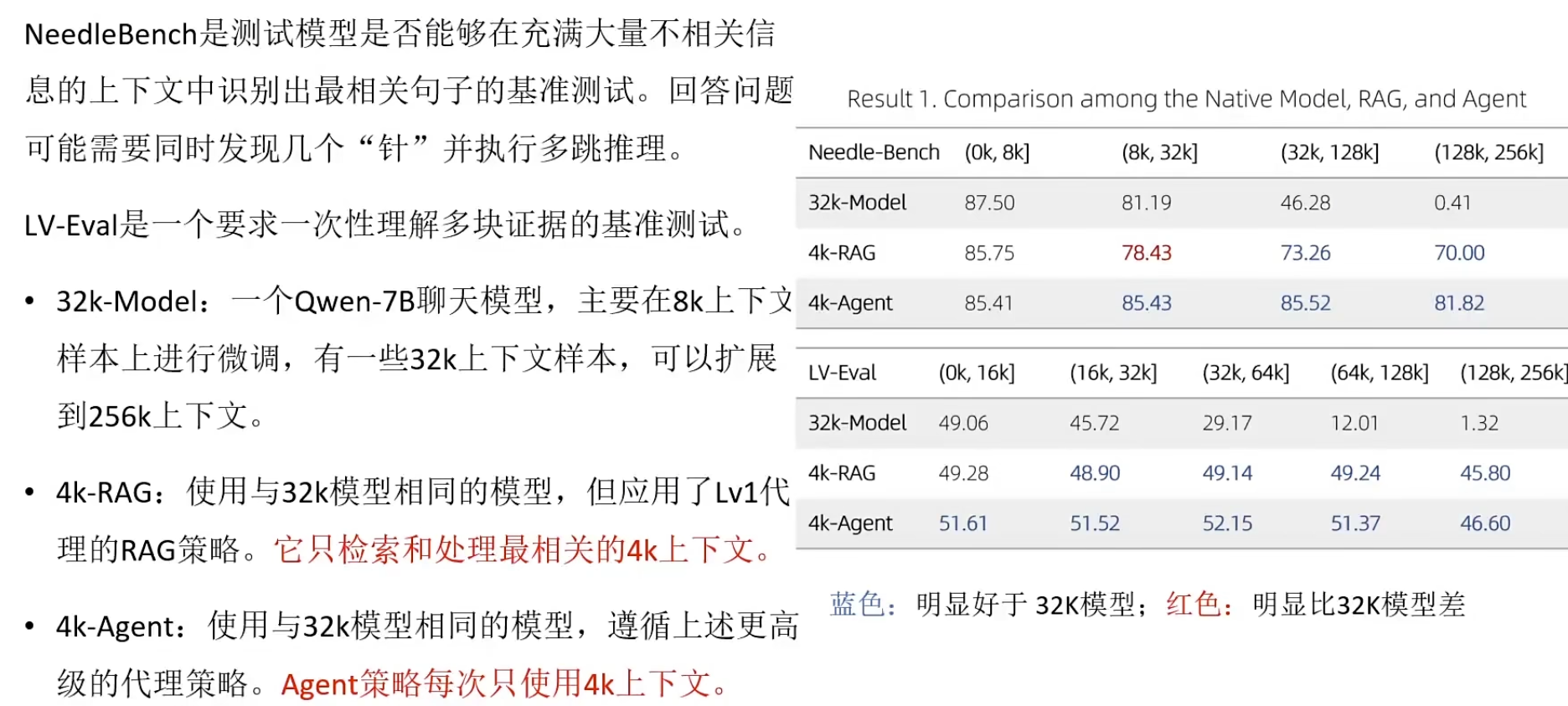
RAFT(Retrieval Augmented Fine-Tuning)
RAFT 是一种专门为了让大模型在「开卷考试(RAG)」中表现更好而设计的微调方法。
它的核心是:
在微调阶段,同时训练模型两种能力:
当给的相关文档有用时 → 学会忽略干扰文档 + 引用原文回答
当没给相关文档时 → 完全依赖自身参数知识回答(避免检索失败就崩掉)
👉 可以理解为:先让模型经历一遍「糟糕的检索结果」并学会应对,再上考场(真实 RAG)自然更稳。
RAFT 不是改变 RAG 的检索或生成架构,而是通过「带干扰文档 + 强制引用」的微调数据,把一个大模型从「盲答选手」训练成「开卷考学霸」------给文档就会用,不给也能答。
完整的RAFT流程包含三个清晰的步骤:

======================================================================
1、Qwen-Agent速度还可以,效果不错,因为是通过Agent模式来进行推理,而且做了一些优化是已经做过一些优化的RAGAgent。
2、GraphRAG对知识全面的理解,通过社区、实体、对知识进行了总结。用户在提问时,可以获得更全面的知识。
3、RAFT(Retrieval Augmented Fine-Tuning),采用在微调中训练RAG的能力,再进行开卷考试的时候,回答的结果会更好。
具体案例
deepseek_faiss_搭建本地知识库检索
Jupyter运行情况:https://github.com/monkeyhlj/LLM_development_learning/blob/main/RAG_demo/deepseek_faiss_搭建本地知识库检索.ipynb
python
# 基础文件处理
from PyPDF2 import PdfReader
# 文本分割
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 嵌入模型(阿里云DashScope)
from langchain_community.embeddings import DashScopeEmbeddings
# 向量数据库(FAISS)
from langchain_community.vectorstores import FAISS
# 问答链
from langchain.chains.question_answering import load_qa_chain
# 大模型(通义千问)
from langchain_community.llms import Tongyi
# 成本统计
from langchain_community.callbacks import get_openai_callback
# 配置阿里云灵积API Key(替换为你的有效Key)
DASHSCOPE_API_KEY = "sk-xxx"
# -------------------------- 步骤2:PDF文本提取 --------------------------
# 1. 读取PDF文件
pdf_path = r"C:\Users\houlj12\Desktop\work\test\LLM_development_learning\RAG_demo\docs\浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf"
pdf_reader = PdfReader(pdf_path)
print(f"PDF文件总页数:{len(pdf_reader.pages)}")
# 2. 逐页提取文本,记录每页文本和对应页码
page_texts = [] # 存储每页的完整文本
page_numbers = [] # 存储每页对应的页码
for page_idx, page in enumerate(pdf_reader.pages, start=1):
# 提取单页文本
extracted_text = page.extract_text()
if extracted_text:
clean_text = extracted_text.strip() # 清理首尾空格
page_texts.append(clean_text)
page_numbers.append(page_idx)
print(f"第{page_idx}页提取完成,文本长度:{len(clean_text)}字符")
else:
print(f"第{page_idx}页无有效文本")
# 打印提取结果预览
print(f"\n共提取到 {len(page_texts)} 页有效文本")
print(f"第1页文本预览:{page_texts[0][:200]}...")
# -------------------------- 步骤3:文本分割 --------------------------
# 1. 初始化中文友好的文本分割器
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", "!", "?", ",", "、", "."], # 优先按中文分句
chunk_size=1000, # 每个文本块最大字符数
chunk_overlap=200, # 文本块重叠字符(保证上下文连贯)
length_function=len, # 按字符长度分割
)
# 2. 分割文本并绑定每个文本块的页码
all_chunks = [] # 存储所有分割后的文本块
chunk_page_mapping = {} # 关键:文本块 → 对应页码的映射字典
for text, page_num in zip(page_texts, page_numbers):
# 分割单页文本为多个小块
chunks = text_splitter.split_text(text)
for chunk in chunks:
chunk = chunk.strip()
if chunk: # 跳过空文本块
all_chunks.append(chunk)
chunk_page_mapping[chunk] = page_num # 记录每个块的页码
# 打印分割结果
print(f"\n文本分割完成:")
print(f"- 原始有效页数:{len(page_texts)}")
print(f"- 分割后文本块数量:{len(all_chunks)}")
print(f"- 第1个文本块预览:{all_chunks[0][:100]}... 对应页码:{chunk_page_mapping[all_chunks[0]]}")
# -------------------------- 步骤4:Chroma向量库 --------------------------
# 替换FAISS为Chroma(需先安装:pip install chromadb)
from langchain_community.vectorstores import Chroma
# 初始化嵌入模型(保持不变)
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=DASHSCOPE_API_KEY,
)
# 构建Chroma向量库(替代FAISS)
knowledge_base = Chroma.from_texts(
texts=all_chunks, # 分割后的文本块
embedding=embeddings, # 嵌入模型
persist_directory="./local_rag_chroma_db" # 本地保存路径
)
# 绑定页码映射(保持不变)
knowledge_base.chunk_page_mapping = chunk_page_mapping
# 持久化向量库(Chroma需手动执行persist)
knowledge_base.persist()
print(f"\n Chroma向量库已保存至本地:.RAG_case/local_rag_chroma_db_case")
# -------------------------- 步骤5:问答查询 --------------------------
# 1. 初始化通义千问大模型
llm = Tongyi(
model_name='qwen-turbo', # 通义千问轻量版(速度快、成本低)
dashscope_api_key=DASHSCOPE_API_KEY,
temperature=0.1, # 降低随机性,保证回答准确性
)
# 2. 设置查询问题(可替换为任意问题)
query = "客户经理被投诉了,投诉一次扣多少分"
print(f"\n 开始查询:{query}")
# 3. 相似度检索(从向量库找最相关的文本块)
top_k = 3 # 返回最相关的3个文本块
related_docs = knowledge_base.similarity_search(query, k=top_k)
print(f"📄 检索到 {len(related_docs)} 个相关文本块")
# 4. 加载问答链(将检索结果拼接后传给LLM生成回答)
qa_chain = load_qa_chain(
llm=llm,
chain_type="stuff" # 适合短文本:将所有相关文本块拼接成prompt
)
# 5. 执行问答并统计API成本
with get_openai_callback() as cost:
# 执行问答
response = qa_chain.invoke({
"input_documents": related_docs, # 检索到的相关文本
"question": query # 用户问题
})
# 6. 打印结果
print("\n===== 问答结果 =====")
print(f"问题:{query}")
print(f"回答:{response['output_text']}")
print(f"\n API调用成本:{cost}")
# 7. 打印回答来源页码(去重)
print("\n===== 回答来源页码 =====")
unique_pages = set()
for doc in related_docs:
chunk_content = doc.page_content.strip()
# 从映射中获取文本块对应的页码
source_page = knowledge_base.chunk_page_mapping.get(chunk_content, "未知")
if source_page not in unique_pages:
unique_pages.add(source_page)
print(f"- 文本块来源页码:{source_page}")
if not unique_pages:
print(" 未找到相关文本块的页码信息")qwen-agent-multi-files
Jupyter运行情况:https://github.com/monkeyhlj/LLM_development_learning/blob/main/RAG_demo/qwen-agent-multi-files.ipynb
python
import pprint
import urllib.parse
import json5
from qwen_agent.agents import Assistant
from qwen_agent.tools.base import BaseTool, register_tool
import os
# 步骤 1(可选):添加一个名为 `my_image_gen` 的自定义工具。
@register_tool('my_image_gen')
class MyImageGen(BaseTool):
# `description` 用于告诉智能体该工具的功能。
description = 'AI 绘画(图像生成)服务,输入文本描述,返回基于文本信息绘制的图像 URL。'
# `parameters` 告诉智能体该工具有哪些输入参数。
parameters = [{
'name': 'prompt',
'type': 'string',
'description': '期望的图像内容的详细描述',
'required': True
}]
def call(self, params: str, **kwargs) -> str:
# `params` 是由 LLM 智能体生成的参数。
prompt = json5.loads(params)['prompt']
prompt = urllib.parse.quote(prompt)
return json5.dumps(
{'image_url': f'https://image.pollinations.ai/prompt/{prompt}'},
ensure_ascii=False)
from dotenv import load_dotenv
load_dotenv()
# 步骤 2:配置您所使用的 LLM。
llm_cfg = {
# 使用 DashScope 提供的模型服务:
'model': 'qwen-max',
'model_server': 'dashscope',
'api_key': os.getenv('DASHSCOPE_API_KEY'), # 从环境变量获取API Key
'generate_cfg': {
'top_p': 0.8
}
}
llm_cfg = {
# 使用 DashScope 提供的模型服务:
'model': 'deepseek-v3',
'model_server': 'https://dashscope.aliyuncs.com/compatible-mode/v1',
'api_key': os.getenv('DASHSCOPE_API_KEY'), # 从环境变量获取API Key
'generate_cfg': {
'top_p': 0.8
}
}
# 步骤 3:创建一个智能体。这里我们以 `Assistant` 智能体为例,它能够使用工具并读取文件。
system_instruction = '''你是一个乐于助人的AI助手。
在收到用户的请求后,你应该:
- 首先绘制一幅图像,得到图像的url,
- 然后运行代码`request.get`以下载该图像的url,
- 最后从给定的文档中选择一个图像操作进行图像处理。
用 `plt.show()` 展示图像。
你总是用中文回复用户。'''
tools = ['my_image_gen', 'code_interpreter'] # `code_interpreter` 是框架自带的工具,用于执行代码。
import os
# 获取文件夹下所有文件
file_dir = os.path.join('./', 'docs')
files = []
if os.path.exists(file_dir):
# 遍历目录下的所有文件
for file in os.listdir(file_dir):
file_path = os.path.join(file_dir, file)
if os.path.isfile(file_path): # 确保是文件而不是目录
files.append(file_path)
print('files=', files)
bot = Assistant(llm=llm_cfg,
system_message=system_instruction,
function_list=tools,
files=files)
# 步骤 4:作为聊天机器人运行智能体。
messages = [] # 这里储存聊天历史。
query = "介绍下雇主责任险"
# 将用户请求添加到聊天历史。
messages.append({'role': 'user', 'content': query})
response = []
current_index = 0
for response in bot.run(messages=messages):
if current_index == 0:
# 尝试获取并打印召回的文档内容
if hasattr(bot, 'retriever') and bot.retriever:
print("\n===== 召回的文档内容 =====")
retrieved_docs = bot.retriever.retrieve(query)
if retrieved_docs:
for i, doc in enumerate(retrieved_docs):
print(f"\n文档片段 {i+1}:")
print(f"内容: {doc.page_content}")
print(f"元数据: {doc.metadata}")
else:
print("没有召回任何文档内容")
print("===========================\n")
current_response = response[0]['content'][current_index:]
current_index = len(response[0]['content'])
print(current_response, end='')
# 将机器人的回应添加到聊天历史。
messages.extend(response)
print(messages)注:文档中带图片时,如何携带图片进行回答:多模态RAG (Multimodal RAG) 技术,后面再看下。
【代码仓库地址】https://github.com/monkeyhlj/LLM_development_learning