一、基础知识
栈是一种操作被严格限制的特殊线性表 ,不像普通顺序表、链表可以随便在任意位置插入和删除元素。栈规定所有插入、删除操作,只能在同一端进行 。栈(Stack)最核心、最经典的特点就是后进先出 LIFO。即最后放进去的数据,最先拿出来;最先放进去的数据,压在最底下,最后才能取出。
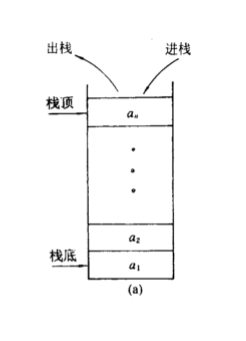
栈基础核心概念
-
栈顶:唯一允许做入栈、出栈操作的一端,是栈的动态操作端。
-
栈底:固定不动、不允许任何增删操作的一端。
-
入栈(压栈Push):往栈顶添加新元素。
-
出栈(弹栈Pop):从栈顶删除一个元素。
-
空栈:栈内部没有任何有效数据元素,不能执行出栈、取栈顶操作。
二、实现选择
栈底层只有两种实现方式:顺序栈(顺序表实现) 和链栈(单链表实现)。两种底层结构不同,操作位置不同,效率也不同。
1. 顺序表、链表操作效率区别
| 数据结构 | 头部增删 | 尾部增删 | 本篇选择 |
|---|---|---|---|
| 顺序表 | O(n) 很慢 | O(1) 极快 | 顺序栈选尾部做栈顶 |
| 单链表 | O(1) 极快 | O(n) 很慢 | 链栈选头部做栈顶 |
2. 为什么链栈要用链表头部做栈顶?
因为单链表头部插入、头部删除 不需要遍历链表,直接改指针就能完成,时间复杂度永远是 O(1) 如果在链表尾部做栈顶,每次都要遍历找尾,效率极低。所以链栈统一把链表头部当作栈顶,所有入栈出栈全部在头部完成,效率最高。
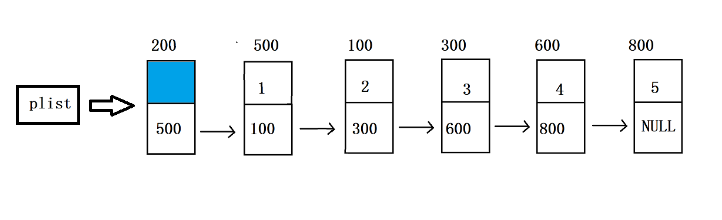
三、链栈结构体设计
链栈本质就是单链表改造而来,不需要连续内存空间,不需要提前固定容量,需要多少节点就动态开辟多少节点,内存利用率高,不会出现栈满溢出问题。
1. 设计思想
-
设计一个数据节点结构体:负责存储数据和指向下一个节点
-
设计一个栈管理结构体:只保存一个栈顶指针 top
-
栈顶指针永远指向链表第一个节点(栈顶位置)
-
所有入栈、出栈操作全部在链表头部操作
2. 结构体定义
cpp
// 统一元素类型,后期维护修改方便
typedef int ELEMTYPE;
// 链式栈数据节点结构体
typedef struct LSNode {
ELEMTYPE date; // 存储数据
struct LSNode* next; // 指向下一个节点指针
}LSNode;
// 链栈管理结构体
typedef struct LinkStack {
struct LSNode* top; // 栈顶指针,指向链表头部
}LinkStack;四、函数接口总览
为了保证链栈功能完整、代码规范,我们封装全套标准接口,覆盖初始化、入栈出栈、获取栈顶、判空、统计大小、打印、销毁全流程操作。
cpp
// 1.初始化链栈
void Init_LinkStack(LinkStack* pls);
// 2.入栈(头部插入)
bool Push(LinkStack* pls, ELEMTYPE val);
// 3.出栈(头部删除)
bool Pop(LinkStack* pls);
// 4.获取栈顶元素
ELEMTYPE Top(LinkStack* pls);
// 5.获取栈有效元素个数
int size(LinkStack* pls);
// 6.判断栈是否为空
bool Empty(LinkStack* pls);
// 7.销毁整个链栈,释放所有节点内存
void Destroy(LinkStack* pls);
// 8.遍历打印栈所有元素
void show(LinkStack* pls);五、函数实现
1. 链栈初始化函数
详细实现思路: 链栈刚创建的时候,没有任何数据节点,是一个空栈。空栈的标准就是栈顶指针不指向任何节点,直接置为 nullptr。初始化只需要做两件事:第一确保栈结构指针合法 ,第二把栈顶指针置空,代表当前没有任何元素。
cpp
void Init_LinkStack(LinkStack* pls) {
// 防止传入空指针,保护程序安全
assert(pls != nullptr);
// 栈顶指针置空,代表空栈
pls->top = nullptr;
}2. 入栈操作
详细实现思路: 链栈入栈就是链表头插法 。第一步先创建一个新节点 ,给新节点赋值;第二步必须先让新节点的 next 指向原来的栈顶节点,不能先改栈顶指针,不然会丢失后面所有节点;第三步再把栈顶指针移动到新节点上,让新节点成为新栈顶。指针顺序绝对不能乱,一改顺序链表直接断掉。
cpp
bool Push(LinkStack* pls, ELEMTYPE val) {
assert(pls != nullptr);
// 1.动态创建新节点
LSNode* pnewnode = new LSNode;
// 2.给新节点赋值
pnewnode->date = val;
// 3.新节点next指向原来栈顶(先接后面链)
pnewnode->next = pls->top;
// 4.栈顶指针移动到新节点(再改栈顶)
pls->top = pnewnode;
return true;
}3. 出栈操作
详细实现思路: 出栈就是链表头删法 。第一步先判断栈是不是空 栈,空栈没有元素不能出栈;第二步先用临时指针 保存当前栈顶节点,不然栈顶移动后找不到要删除的节点;第三步把栈顶指针 下移,指向原栈顶的下一个节点;第四步释放原来栈顶节点内存,防止内存泄漏。
cpp
bool Pop(LinkStack* pls) {
assert(pls != nullptr);
// 空栈不能出栈
if (Empty(pls))
return false;
// 1.保存当前栈顶节点
LSNode* p = pls->top;
// 2.栈顶指针下移,指向下一个节点
pls->top = p->next;
// 3.释放原栈顶节点内存
delete p;
return true;
}4. 获取栈顶元素
详细实现思路: 只是读取数据,不修改栈结构。先断言保证栈不为空,防止空栈取值崩溃;直接返回栈顶指针指向节点的数据即可,逻辑简单,但必须做非空判断。
cpp
ELEMTYPE Top(LinkStack* pls) {
assert(pls != nullptr && !Empty(pls));
// 直接返回栈顶数据
return pls->top->date;
}5. 统计栈有效元素个数
详细实现思路: 链栈没有下标,不能直接计算数量,只能从栈顶开始循环遍历所有节点,每遍历一个节点计数器加一,遍历到空结束,最终返回计数器数值。
cpp
int size(LinkStack* pls) {
assert(pls != nullptr);
int count = 0;
// 从栈顶遍历到末尾
for (LSNode* p = pls->top; p != nullptr; p = p->next)
count++;
return count;
}6. 判断栈是否为空
详细实现思路: 链栈没有节点时,栈顶指针一定是 nullptr,直接判断top 是否为空即可,逻辑最简单,也是所有函数的基础判断条件。
cpp
bool Empty(LinkStack* pls) {
assert(pls != nullptr);
// 栈顶为空就是空栈
return pls->top == nullptr;
}7. 销毁整个链栈
详细实现思路: 链栈节点都是new开辟在堆区,必须逐个释放不然内存泄漏。循环每次保存当前节点和下一个节点,先下移指针,再删除当前节点,循环直到所有节点全部释放,最后栈顶置空。
cpp
void Destroy(LinkStack* pls) {
assert(pls != nullptr);
LSNode* p = pls->top;
LSNode* q = nullptr;
// 循环逐个释放节点
while (p != nullptr) {
q = p->next;
delete p;
p = q;
}
// 栈顶置空,回归空栈状态
pls->top = nullptr;
}8. 打印栈所有元素
**详细实现思路:**从栈顶开始遍历所有有效节点,依次打印数据,直观展示栈内元素顺序,方便代码调试和学习观察。
cpp
void show(LinkStack* pls) {
assert(pls != nullptr);
for (LSNode* p = pls->top; p != nullptr; p = p->next) {
cout << p->date << " ";
}
cout << endl;
}六、顺序栈 vs 链栈
1. 底层存储结构
-
顺序栈:底层是动态数组,内存连续,依靠下标操作数据。
-
链栈:底层是单链表,内存不连续,依靠指针链接节点。
2. 栈顶位置选择
-
顺序栈:顺序表尾部做栈顶,尾插尾删 O(1)。
-
链栈:链表头部做栈顶,头插头删 O(1)。
3. 容量与空间特点
-
顺序栈:初始化必须固定容量,容易栈满溢出,空间分配多了浪费、少了不够用。
-
链栈:动态按需开辟节点,没有容量限制,不会溢出,用多少开多少,空间利用率高。
4. 访问效率
-
顺序栈:支持随机访问,读取速度快。
-
链栈:不支持随机访问,只能从头遍历,读取速度慢。
5. 增删操作效率
-
顺序栈:入栈出栈 O(1),无需移动元素。
-
链栈:入栈出栈 O(1),只改指针,效率同样极高。
6. 适用场景
-
选顺序栈:数据量固定、需要频繁查询、追求访问速度。
-
选链栈:数据量变化大、不确定数量、频繁增删、不想担心栈满溢出。