目录
摘要:
本文旨在彻底理解大小端模式的含义,并且讲解两种验证大小端模式的方法
一:现象及例题
1:现象
cpp
#include <stdio.h>
int main()
{
int a = 0x11223344;
return 0;
}调试以一行四列和一行一列查看&a:
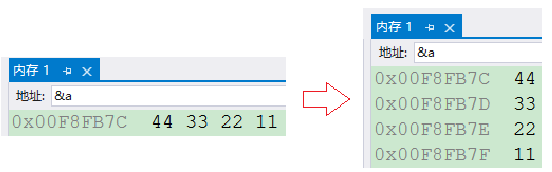
解释:
**①:**int a = 0x11223344 换算成32位就是:00010001 00100010 00110011 01000100,所以其中的8个二进制位是一个字节(00010001),两个16进制位是一个字节(11),其中的44(01000100)叫做32位中的低位字节,11(00010001)叫做32位中的高位字节
**②:**而现象是7C,7D,7E,7F呈递增的内存空间,分别存储的44,33,22,11,也就代表着一个四字节的整形,在内存中的存储是低位字节44存储在低地址处7C,高位字节11存储在高地址处7F
2:例题
cpp
#include <stdio.h>
// x86
int main()
{
int a[4] = { 1, 2, 3, 4 };
int* ptr = (int*)((int)a + 1);
printf("%x", *ptr);
return 0;
}
解释:
**①:**a为数组名,代表数组首元素的地址,被强转为int整形,然后+1,代表此时地址+1,然后再被强转为int*整形指针类型,此时求*ptr,等同于求元素1的第2个字节开始往后的4个字节,如图:
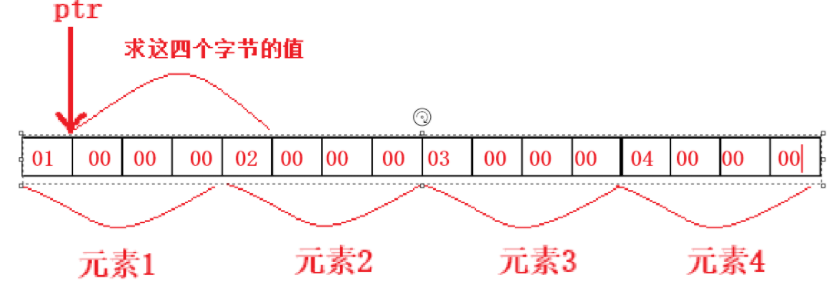
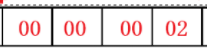
**②:**因为之前调试和该题是在相同环境下的,所以仍然是,一个整形内的地位字节存储在低地址处,高位字节存储在高地址处,所以要求的这四个字节的值如下图:
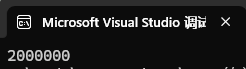
**③:**所以*ptr的值, *ptr2 = 0x2000000,所以值为2000000,当然4个人字节是8个16进制为,这里的2000000只有7位是因为把最前面的0省略了,如果以%p形式打印,则不会省略:
二:大小端概念
1:概念
其实超过⼀个字节的数据在内存中存储的时候,就有存储顺序的问题,按照不同的存储顺序,我们分为大端字节序存储和小端字节序存储,下⾯是具体的概念:
大端(存储)模式:
是指数据的低位字节内容保存在内存的⾼地址处,而数据的⾼位字节内容,保存在内存的低地址处。
小端(存储)模式:是指数据的低位字节内容保存在内存的低地址处,而数据的⾼位字节内容,保存在内存的⾼地址处。
所以上述的调试现象和例题,都是低位字节存储在低地址处,高位字节存储在高地址处,博主的环境就是小端模式!反之就是大端存储!
2:读取大小端
在初次学习大小端的时候,会有一个常见的误区,那就是一个整形在大端和小端的模式下,读取的时候,会不会值不同呢?
整形1在大端和小端下的存储:
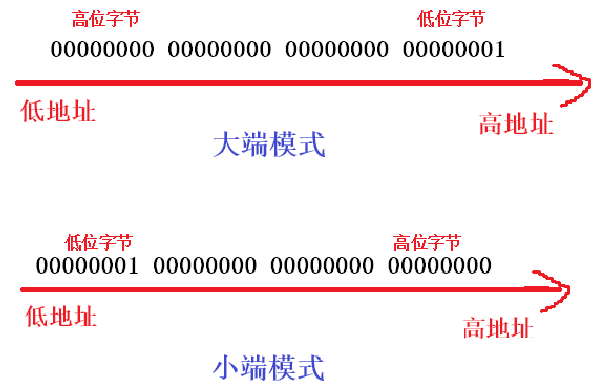
Q:会不会大端下读取到的1的补码为:00000000 00000000 00000000 00000001;而小端下读取到的补码为:00000001 00000000 00000000 00000000;这样前者为1,后者不为1(16777216)?
A:当然不会!
CPU会抹去大小端下存储机制的差异化,让我们读取到的值都一样!CPU会把内存中的字节重新组合成正确的数值,所以无论大端还是小端,读取到的补码都是:00000001 00000000 00000000 00000000。大端和小端的差异只存在于内存存储层面,CPU 读取后都会转换成统一的二进制格式(高位在左),所以数值永远一样。
而上文中的例题中的图为:
Q:此时可能会误以为为什么读取到的不是0x00000002?
A:此时按地址从低到高排列:00 00 00 02,CPU会将其恢复为高位在左,低位在右,也就是02000000,这才是这四个字节所存储的值,所以打印为2000000,
三:验证大小端的两种方式
1:验证的思路
面试中,验证大小端是一个常见的问题,我将介绍两种方式验证大小端
首先,需要知道一个char*指针去取地址的时候,在大小端取到的地址虽然相同,但是该字节的内容不相同!这是因为:
比如:
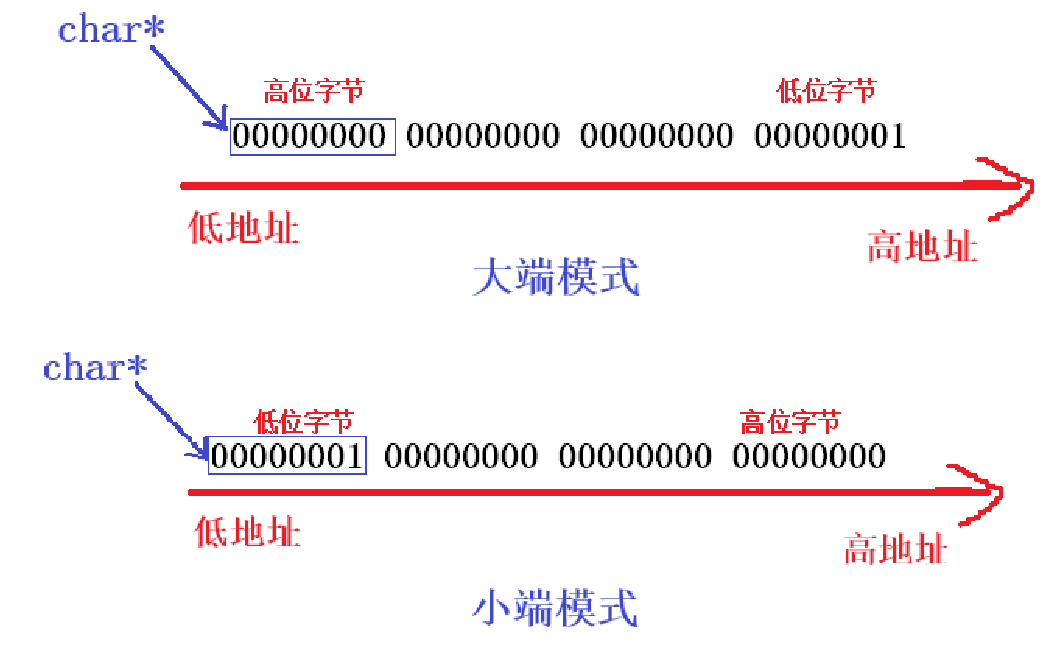
Q:CPU不是会重新组合比特位的顺序吗 为什么char*在大小端取到的还不一样?
A:在大端和小端中,一个字节的内容存储在一个地址处,这是恒定的!所谓的组合顺序,也不会改变每个地址中的存储的内容!此外,须知CPU 只在读取才做组合成正确数值这一操作
所以,验证大小端的思路就是我们利用整形1,整形1只有低位的那一个字节为1,其余中间都是0,所以如果我们单独利用char*取出整形存储在低地址处的那一个字节,如果*解引用验证为1,代表为小端,反之为0则大端
2:整形验证
cpp
#include <stdio.h>
int check_sys()
{
int i = 1;
return (*(char*)&i);
}
int main()
{
int ret = check_sys();
if (ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
**解释:**对整形i进行取地址,此时取到的就是整形i的起始地址,也就是存储在低地址处的那个字节的地址,然后进行强转char*,在*解引用,得到了该字节的值,为1则小端,反之大端
3:联合体验证
cpp
#include <stdio.h>
int check_sys()
{
union
{
int i;
char c;
}un;
un.i = 1;
return un.c;
}
int main()
{
int ret = check_sys();
if (ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
解释:
①: 联合体的成员变量占据同一块内存,所以读取 char 就是读取 int 的第一个字节。小端下整形该字节是 1,大端下整形该字节是 0,由此判断字节序。
**②:**所以需要把成员变量i置为1,再用c的值去判断
📌 作者 shylyly
📃 首次发布 2026.5.16
❌ 最新修改 无
📜 声明 由于笔者水平有限,文中难免有疏漏或不妥之处,还望读者不吝赐教。