模型在数据集 A 上刚训完,效果稳定。过了几天,又来了数据集 B: 新场景、新类别,或者只是分布变了。
最顺手的做法,就是把现有模型拿出来,在 B 上接着训练。B 上的指标确实涨了,看起来一切正常; 可一回到 A 的评测,旧能力却明显暴跌。
更糟的是,这通常不是一次偶然波动,而像一条趋势线: 继续训练得越久,旧数据掉得越多。
这种现象有个正式名字: 灾难性遗忘。持续学习要解决的,不是怎样让模型不断接触新数据,而是怎样在学新东西的同时,尽量别把旧东西学没了。
很多时候,第一反应会是怀疑学习率、epoch、batch size,或者怀疑新数据脏了。可这些都排查完,现象还是反复出现,就该承认问题不在调参,而在顺序训练本身。先把讨论口径固定下来,再看主流方法到底在改什么。
1. 先把问题说清
持续学习里最容易混的,不是方法名,而是问题设定。常见设定可以先按"测试时到底给不给额外信息"分成三类:
- 任务增量 (task-incremental, TIL): 测试时给任务 ID 或者给出当前任务范围,模型只需要在该任务的类别里做判断。常见做法是多头分类器(每个任务一个 head),难度最低。
- 域增量 (domain-incremental, DIL): 输出空间不变(还是同一套类别或同一类任务),但输入分布在变,比如不同光照/不同采集域/不同风格。难点更像分布漂移。
- 类增量 (class-incremental, CIL): 测试时不给任务 ID,类别集合会随着阶段持续扩展,模型要在"所有已见类别"里直接分类。难度通常最高,也是最常被用来讨论灾难性遗忘的设定。
用两个常见玩具例子把这三件事拉开,会更直观:
- 用 MNIST 数字分类举例:
TIL: 第一阶段只学0-4,第二阶段只学5-9;测试时会告诉"现在考的是第 1 阶段还是第 2 阶段",模型只需要在对应那一半数字里选。DIL: 始终都是0-9十类分类,但第二阶段的数据换了域(比如旋转、噪声、风格变化);测试时不告诉阶段,仍要输出0-9。CIL: 第一阶段学0-4,第二阶段再加入5-9;测试时不告诉阶段,模型必须直接在0-9十个类里选。
- 用猫狗/多类分类举例:
TIL: "猫狗二分类"与"牛羊二分类"当作两个任务,测试时给任务 ID。DIL: 还是"猫狗二分类",但图片从室内变到室外、白天变到夜晚。CIL: 从"猫狗"开始,后续逐步加入"牛羊/马鹿...",最终要在所有已见动物类里直接分类。
把这三种设定放在一张图里对照,会更不容易串:

本文主线固定在经典 CV 分类视角下的 class-incremental learning。数据按阶段到来: 第 1 阶段先学一批类别,第 2 阶段再加一批新类别,后面继续追加。测试时不给任务 ID,模型必须直接在所有已见类别里做分类。
这个设定难,不只难在"会不会忘",还难在新类别刚看过、旧类别已经很久没看。于是两件事常常一起出现:
- 旧类别能力下降
- 预测更偏向最近学过的新类别
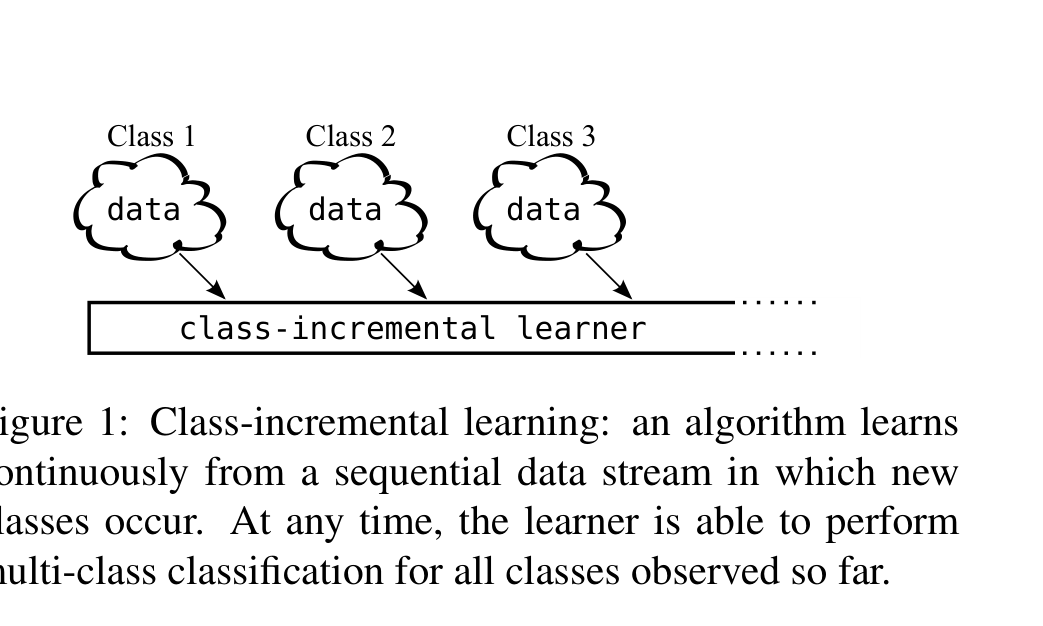
来源: iCaRL: Incremental Classifier and Representation Learning.
为了避免后面的方法比较变成凭感觉判断,口径先统一成两个核心指标。
Average Accuracy 用来看训练到当前阶段后,总体还剩多少能力:
AAt=1t∑k=1tAt,k AA_t = \dfrac{1}{t} \sum_{k=1}^{t} A_{t,k} AAt=t1k=1∑tAt,k
其中 At,kA_{t,k}At,k 表示训练到第 ttt 阶段后,用当前模型在第 kkk 个阶段测试集上的准确率。
Forgetting 用来看旧任务掉了多少:
Ft=1t−1∑k=1t−1(maxu∈{1,...,t−1}Au,k−At,k) F_t = \dfrac{1}{t-1} \sum_{k=1}^{t-1} \left(\max_{u \in \{1,\dots,t-1\}} A_{u,k} - A_{t,k}\right) Ft=t−11k=1∑t−1(u∈{1,...,t−1}maxAu,k−At,k)
它的意思很直接: 对每个旧阶段,先找历史最好成绩,再看当前成绩还剩多少。差值越大,忘得越厉害。
光看准确率还不够,工程上至少还要补两条:
- memory 代价: 要不要存旧样本、旧模型输出,或者额外参数
- compute 代价: 每来一个新阶段,训练流程会不会明显变慢
后面的方法都放在同一套问题里看:
- 它改了训练流程的哪一步
- 它通常怎么抑制遗忘
- 它额外付出了什么代价
2. 为什么顺序训练容易忘
顺序训练的关键问题是,参数更新只对当前阶段负责。梯度会把参数往"更适合当前数据"的方向推,但这组参数同时也承载着旧任务的信息。
如果新旧任务很接近,更新可能顺带保留不少旧能力。可一旦差异变大,或者训练持续得够久,旧任务依赖的表示就会被不断改写。于是出现一个很常见的现象: 新任务学得越稳,旧任务掉得越快。
这个过程可以压缩成三句话:
- 当前任务只奖励"对现在有用"的更新
- 旧任务不会在训练里发声,除非主动把它带回来
- 多个任务争用同一组参数时,后来的更新就可能覆盖前面的结果
持续学习方法看起来很多,主问题其实只有一个: 准备在哪一环插手,减少这种覆盖。
3. 方法地图: 到底改了哪一步
对概述文来说,最稳的记法不是按年份背方法名,而是看它在训练流程里改了哪一步。
下面这张流程图对应的是最核心的区分方式: 不同方法到底是在训练流程的哪一环插手。
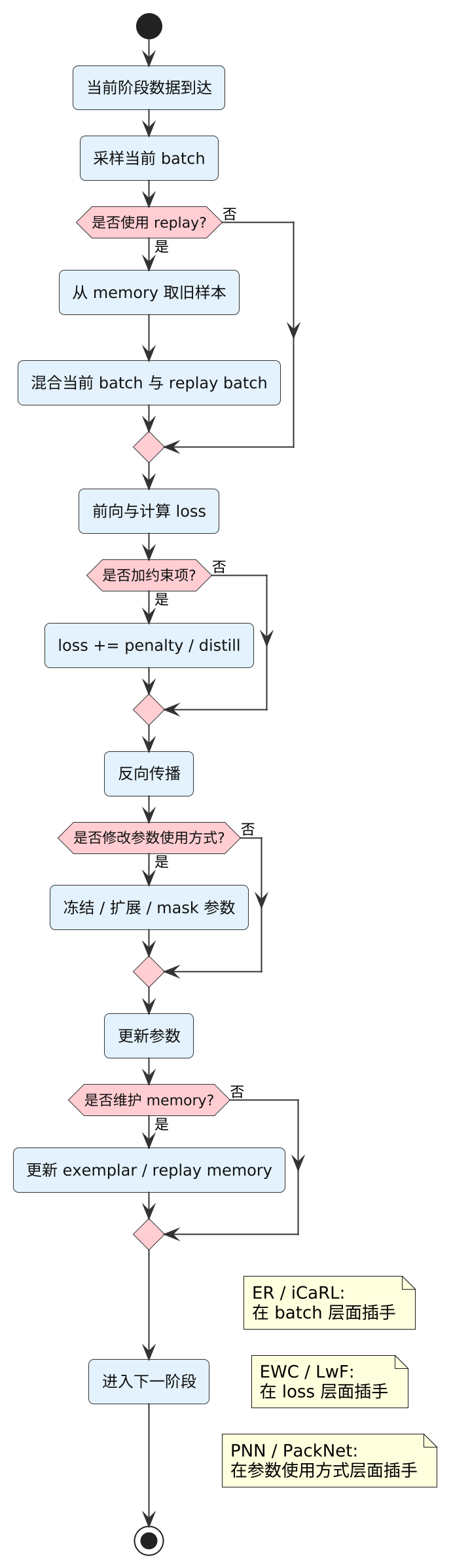
大多数方法都在尝试让"旧任务"重新出现在参数更新的决策里,区别主要在插入点不同。更细的优缺点和取舍,放到后文逐个方法展开。
三类主线,只记三句话:
EWC/LwF: 在 loss 上加约束(不方便存旧样本时常用)ER/iCaRL: 在 batch 里混回放(效果稳,但要付出 memory)PNN/PackNet: 在 参数使用方式 上做隔离(减少覆盖,但结构/管理更重)
下面直接进入具体方法。
4. 六个经典方法,快速扫一遍
这里按方法逐个扫一遍。每个方法只回答五件事: 它要解决什么、核心动作是什么、训练里怎么改、代价是什么、什么时候更适合用。
4.1 EWC: 给重要参数加约束
EWC 的基本判断是,不是所有参数都同样重要。旧任务里真正关键的参数,学新任务时不该被随便改掉。
最容易抓住的直觉是: EWC 不是把旧样本重新拿回来,而是在参数空间里给旧任务的重要方向加一层"别偏太远"的约束。更新不是不能动,而是某些方向不能乱动。
典型写法是在新任务损失之外,再加一项惩罚。参数越重要,偏离旧值的代价越大:
L=Lnew+λ∑iFi(θi−θi∗)2 L = L_{new} + \lambda \sum_i F_i (\theta_i - \theta_i^*)^2 L=Lnew+λi∑Fi(θi−θi∗)2
极简伪代码:
python
theta_star = theta_after_old_task
importance = estimate_importance(theta_star)
for batch in current_task:
loss = ce(model(batch.x), batch.y)
loss += lambda * penalty(theta, theta_star, importance)
loss.backward()
optimizer.step()适合什么时候用
- 不能保留旧样本
- 希望尽量少改训练主流程
代价
- 需要估计参数重要性
- 新旧任务差异很大时,单靠约束参数偏移往往不够
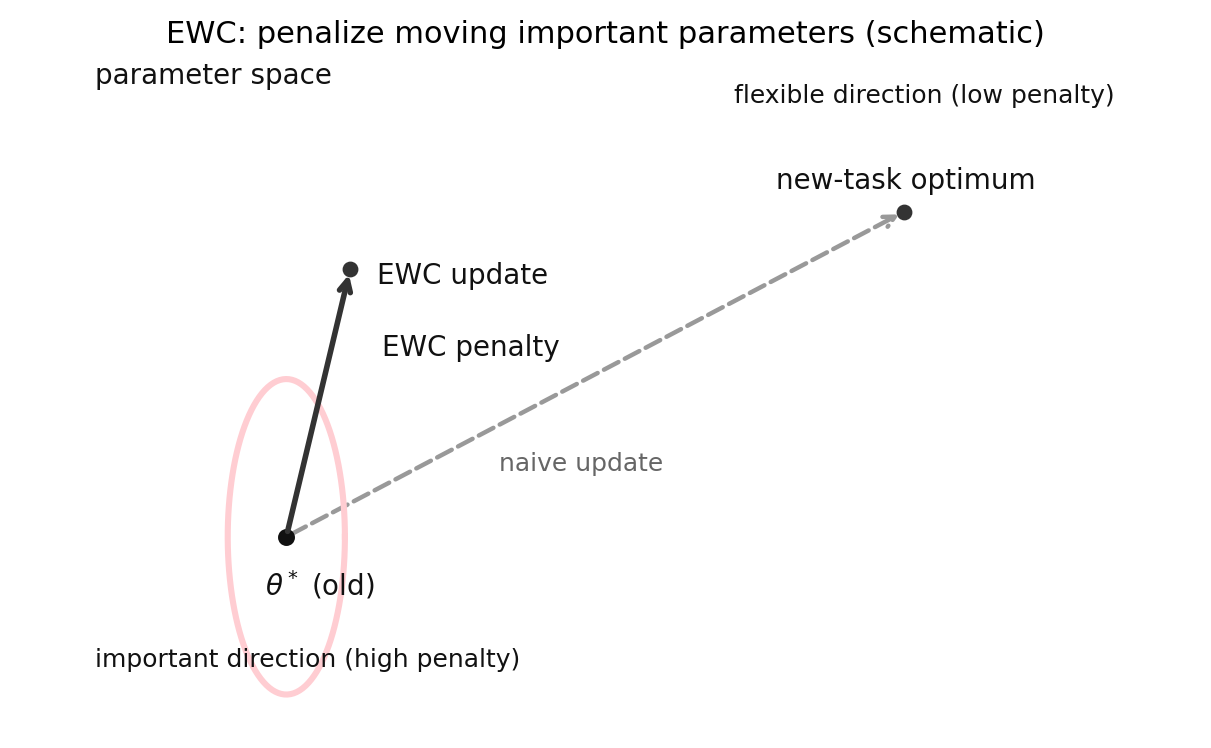
示意图:
EWC通过惩罚项抑制关键参数偏离旧解,避免在参数空间里"跑太远"。
4.2 LwF: 不盯参数,盯旧模型的输出
LwF 的思路是,旧模型在旧类别上的输出本身就是知识。学新任务时,不一定非得把旧样本拿回来,也可以要求新模型别把旧模型原来的判断改得太离谱。
极简伪代码:
python
teacher = copy(old_model)
for batch in current_task:
logits = model(batch.x)
loss_new = ce(logits_new_classes, batch.y)
soft_target = teacher(batch.x)
loss_old = distill(logits_old_classes, soft_target)
loss = loss_new + alpha * loss_old
loss.backward()
optimizer.step()适合什么时候用
- 不方便存旧样本
- 允许保留旧模型或旧模型输出
代价
- 要维护 teacher
- 如果新数据和旧任务分布差得太远,蒸馏信号会变弱
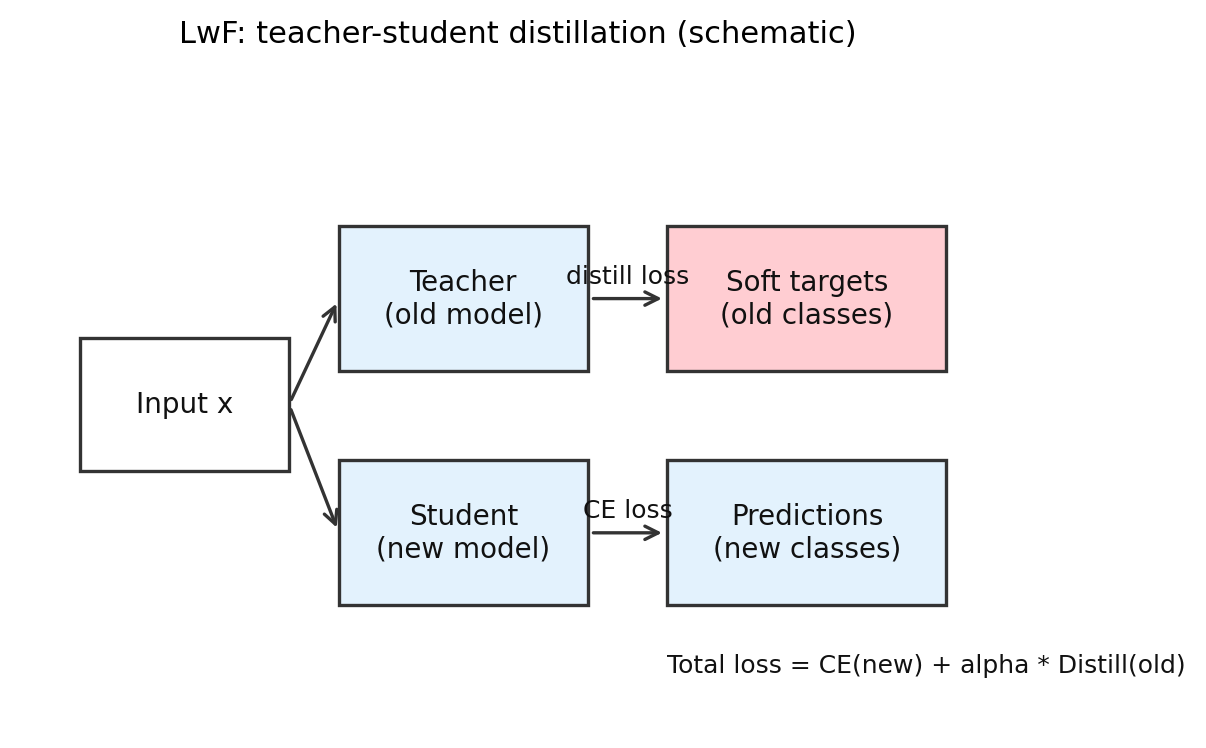
示意图:
LwF的核心是 teacher-student 蒸馏,用旧模型输出约束新模型在旧类别上的行为。
4.3 ER: 旧样本重新拿回来
ER 的逻辑最朴素,也最容易理解。忘是因为旧样本太久没出现,那就把旧样本重新拿回来,和当前样本一起训练。
极简伪代码:
python
for batch in current_task:
replay = sample(memory, m)
mixed = mix(batch, replay)
loss = ce(model(mixed.x), mixed.y)
loss.backward()
optimizer.step()
update_memory(memory, current_task)适合什么时候用
- 允许保存少量旧样本
- 需要一个稳健、直观的强基线
代价
- 要维护 memory
- memory 太小或样本维护得差,效果会明显打折
如果只想先试一条最不容易走偏的路线,ER 通常是很自然的起点。
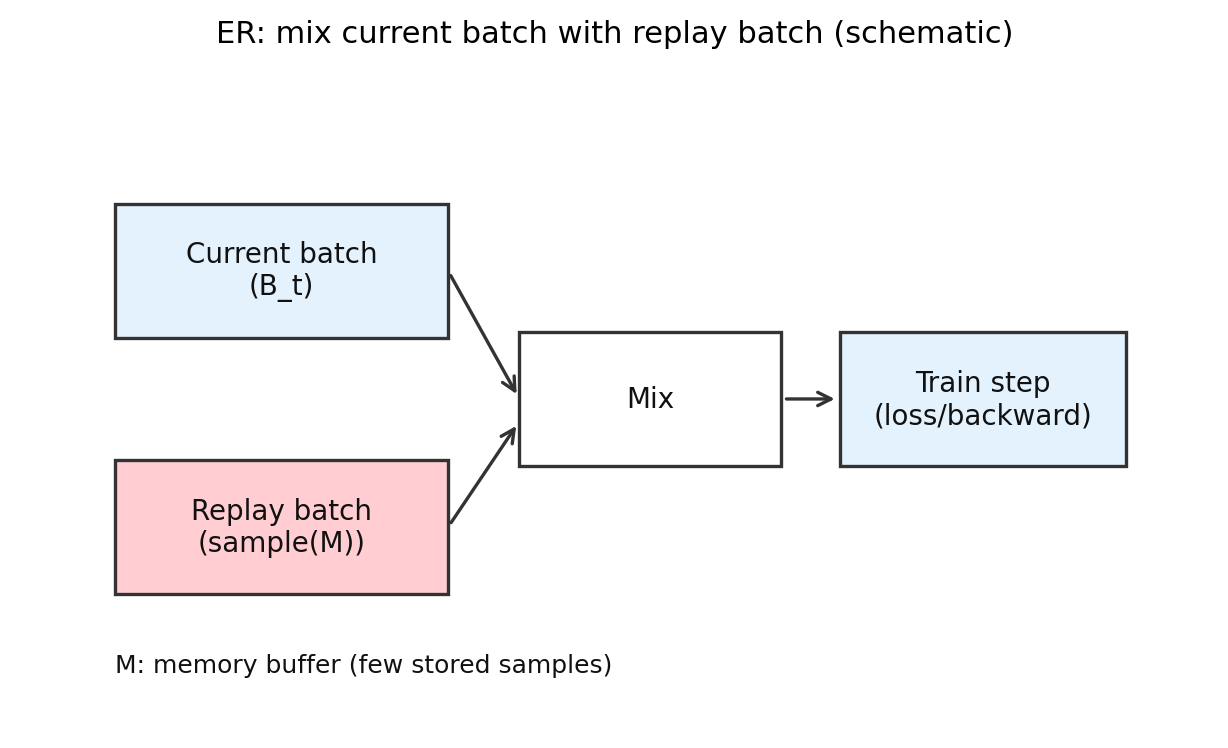
示意图:
ER的关键操作是把 replay batch 和当前 batch 混合到同一次更新里。
4.4 iCaRL: replay 不只是"存几张旧图"
iCaRL 可以看成 replay 路线在 class-incremental 场景下的一条经典老路。重点不只是存样本,而是怎么为每个类别维护 exemplar,并把表示学习和分类决策一起组织起来。
极简伪代码:
python
for task in tasks:
replay = load_exemplars(memory)
mixed = mix(task.data, replay)
train_representation(mixed)
memory = update_exemplars_per_class(memory, budget)
class_means = compute_class_means(memory)
predict_by_nearest_mean(class_means)适合什么时候用
- 明确是 class-incremental 分类设定
- 希望用 exemplar memory 做更系统的旧类维护
代价
- 流程比
ER更复杂 - 要维护 exemplar 选择和类均值表示
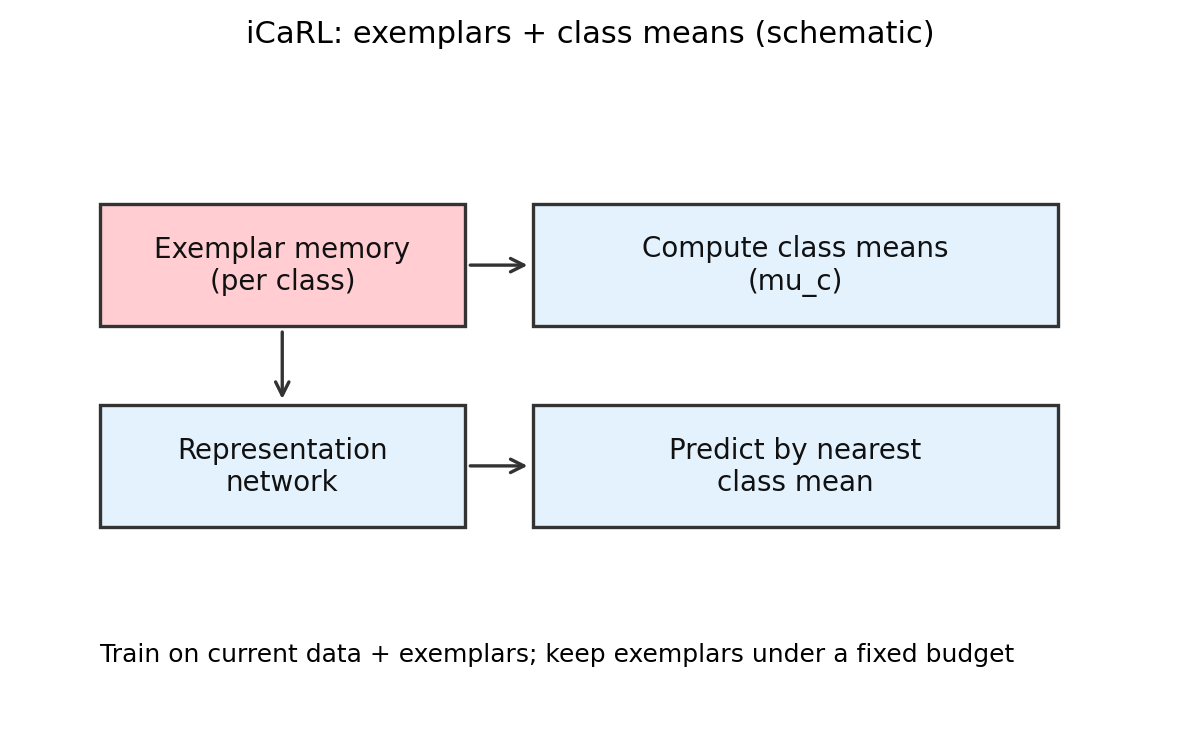
示意图:
iCaRL的典型做法是维护 exemplar,并用类别均值等结构化信息辅助分类与更新。
4.5 PNN: 旧参数直接别动了
PNN 的态度非常明确: 既然共用参数会覆盖,那就给新任务开一套新的参数列,旧列冻结。旧任务不再被后续更新改坏,新任务通过横向连接去借用旧表示。
极简伪代码:
python
freeze(old_columns)
new_column = init_new_column()
for batch in current_task:
h_old = forward(old_columns, batch.x)
h_new = forward(new_column, batch.x, lateral=h_old)
loss = ce(head(h_new), batch.y)
loss.backward()
optimizer.step()适合什么时候用
- 任务边界清楚
- 可以接受结构持续扩展
代价
- 任务越多,参数规模越大
- 结构管理和部署复杂度会上升
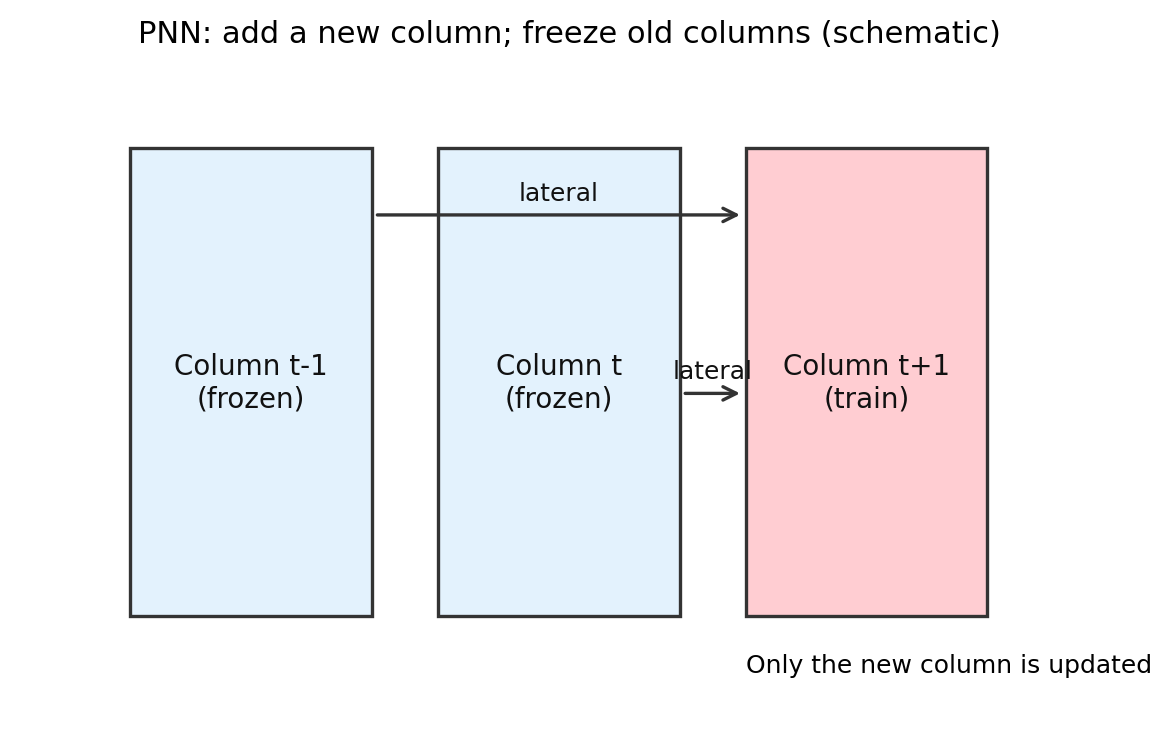
示意图:
PNN通过新增列并冻结旧列减少覆盖,同时用 lateral connection 复用旧表示。
4.6 PackNet: 在同一个网络里划地盘
PackNet 介于完全共享和完全分开之间。它不为每个任务新建整套结构,而是在一个任务训练完成后,把关键权重剪出来并冻结,把剩余容量留给后续任务。
极简伪代码:
python
train(task_t)
mask_t = prune_and_select_important_weights(theta)
freeze(theta[mask_t])
for next_task in future_tasks:
train_only_unfrozen_weights(next_task)
new_mask = update_mask(theta)适合什么时候用
- 不想无限扩模型
- 允许通过 mask 和剪枝管理参数
代价
- 训练流程更复杂
- 任务越来越多时,可用容量会越来越紧
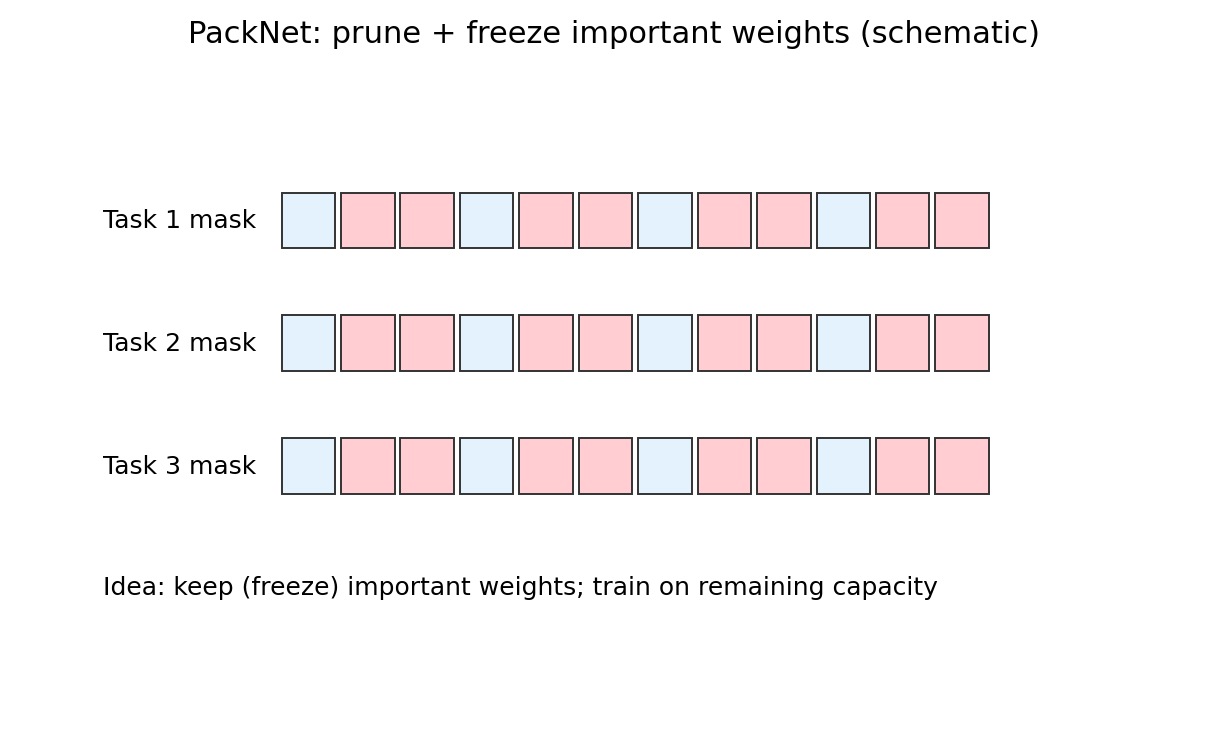
示意图:
PackNet用剪枝得到 mask,冻结已分配的权重,把剩余容量留给后续任务。
5. 怎么选: 按约束,不按流行度
持续学习没有一个绝对最好的方法。更实用的问法是: 手上的约束是什么。
- 允许保存旧样本 : 先看
ER- 原因很简单: 这是最直接把旧任务带回训练的方法,通常也是最稳的起点
- 不能保存旧样本 : 先看
EWC、LwF- 这两类方法更适合"不能回放旧数据,但还能接受额外约束"的场景
- 明确是 class-incremental 分类 :
iCaRL值得单独看- 它不只是 replay,还把 exemplar 和分类决策绑得更紧
- 任务边界清楚,且能接受更复杂结构 : 看
PNN、PackNet- 这类方法的核心优势是减少直接覆盖,但代价是结构和容量管理都更重
- 任务数会持续增长很多 : 要重点看结构扩展和 memory 开销
- 短期准确率并不能说明长期成本可不可控
真正的取舍通常就在三件事之间:
- 能不能保存旧数据
- 能不能接受更高的训练和部署复杂度
- 新旧任务差异到底有多大
这三件事里,前两件通常决定方法族群,最后一件决定方法效果能不能稳定。比如新旧任务非常接近时,约束类方法可能已经够用;可一旦差异很大,只靠约束很难替代 replay。反过来,如果业务完全不能保留旧数据,再强的 replay 路线也没有落地空间。
所以更实用的顺序往往不是"先问哪个方法最强",而是按下面三步筛:
- 先看旧数据能不能留
- 再看训练和部署复杂度能不能接受
- 最后再在剩下的方法里比较效果和成本
这样筛,通常比直接从论文名里挑更稳。
6. 延伸阅读
正文主线只保留了六个方法,是为了让篇幅还能保持清晰。继续往下看时,可以顺着这几条线索扩展:
SI: 和EWC一样属于参数重要性约束路线DER: replay 路线的常见延伸DGR: 不直接存旧样本,而是走生成回放GEM/A-GEM: 直接约束梯度更新方向
如果只想压缩成一句话,可以记住这个主线: 持续学习方法看起来很多,但大多数都在回答同一个问题: 怎样让新任务的更新别把旧任务整片冲掉。