vLLM 现已支持 DeepSeek V4 系列模型(deepseek-ai/DeepSeek-V4-Pro 和 deepseek-ai/DeepSeek-V4-Flash)。
这些模型采用了一种高效的长上下文注意力机制,专为处理多达 一百万 token 的任务而设计。虽然这种新的注意力设计初看可能显得复杂,但一旦系统性地审视,其底层原理其实非常直观。
本文分为三个部分:
- 在 vLLM 上部署 DeepSeek V4 的快速入门指南
- 从第一性原理解释 DeepSeek V4 的新架构设计
- 概述我们在 vLLM 上实现该模型的方法和优化挑战:混合 KV 缓存、内核融合和分离式服务。
这是我们的初始模型支持版本,进一步的优化工作正在积极进行中。我们希望接下来的技术解释能够帮助开源社区理解注意力机制本身以及我们当前实现决策背后的原理。
在 vLLM 上运行 DeepSeek V4
DeepSeek V4 包含两个模型:一个大型 1.6T 参数的 DeepSeek-V4-Pro 和一个小型 285B 参数的 DeepSeek-V4-Flash。两个模型都支持高达 100 万 token 的上下文,vLLM 对新注意力机制的实现旨在扩展到该上下文长度。
docker pull vllm/vllm-openai:deepseekv4-cu129DeepSeek-V4-Pro
这里我们强调为便于测试和原型设计而优化的单节点部署,包含一些可选优化如 FP4 索引器和 MTP。
以下命令可在 8xB200 或 8xB300 上运行。
bash
docker run --gpus all \
--ipc=host -p 8000:8000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
vllm/vllm-openai:deepseekv4-cu130 deepseek-ai/DeepSeek-V4-Pro \
--trust-remote-code \
--kv-cache-dtype fp8 \
--block-size 256 \
--enable-expert-parallel \
--data-parallel-size 8 \
--compilation-config '{"cudagraph_mode":"FULL_AND_PIECEWISE", "custom_ops":["all"]}' \
--attention_config.use_fp4_indexer_cache=True \
--tokenizer-mode deepseek_v4 \
--tool-call-parser deepseek_v4 \
--enable-auto-tool-choice \
--reasoning-parser deepseek_v4有关更多部署策略,包括分离式服务/更多 GPU 架构,请参考 部署指南。
DeepSeek-V4-Flash
这里我们强调为便于测试和原型设计而优化的单节点部署,包含一些可选优化如 FP4 索引器和 MTP。
以下命令可在 4xB200 或 4xB300 上运行。
bash
docker run --gpus all \
--ipc=host -p 8000:8000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
vllm/vllm-openai:deepseekv4-cu130 deepseek-ai/DeepSeek-V4-Flash \
--trust-remote-code \
--kv-cache-dtype fp8 \
--block-size 256 \
--enable-expert-parallel \
--data-parallel-size 4 \
--compilation-config '{"cudagraph_mode":"FULL_AND_PIECEWISE", "custom_ops":["all"]}' \
--attention_config.use_fp4_indexer_cache=True \
--tokenizer-mode deepseek_v4 \
--tool-call-parser deepseek_v4 \
--enable-auto-tool-choice \
--reasoning-parser deepseek_v4有关更多部署策略,包括分离式服务/更多 GPU 架构,请参考 部署指南。
DeepSeek V4 的注意力机制详解
长上下文推理面临两个主要挑战:
- KV 缓存内存增长 :KV 缓存随上下文长度线性增长。虽然 DeepSeek 风格的模型使用 多头潜在注意力 (MLA),其内存效率远高于标准多头注意力 (MHA) 或多查询注意力 (MQA),但考虑到 GPU 内存容量有限,扩展到一百万 token 仍然困难。
- 注意力计算成本 :在长上下文上计算注意力非常昂贵。即使使用 DeepSeek 稀疏注意力 (DSA) 等现有技术,计算仍然是一个显著瓶颈。
为了解决这些挑战,DeepSeek 团队设计了一种新的注意力机制,旨在同时压缩 KV 缓存和减少注意力计算时间。
- 共享键值向量 (2倍内存节省)。为保证正确性,我们对注意力输出应用 逆 RoPE 操作。
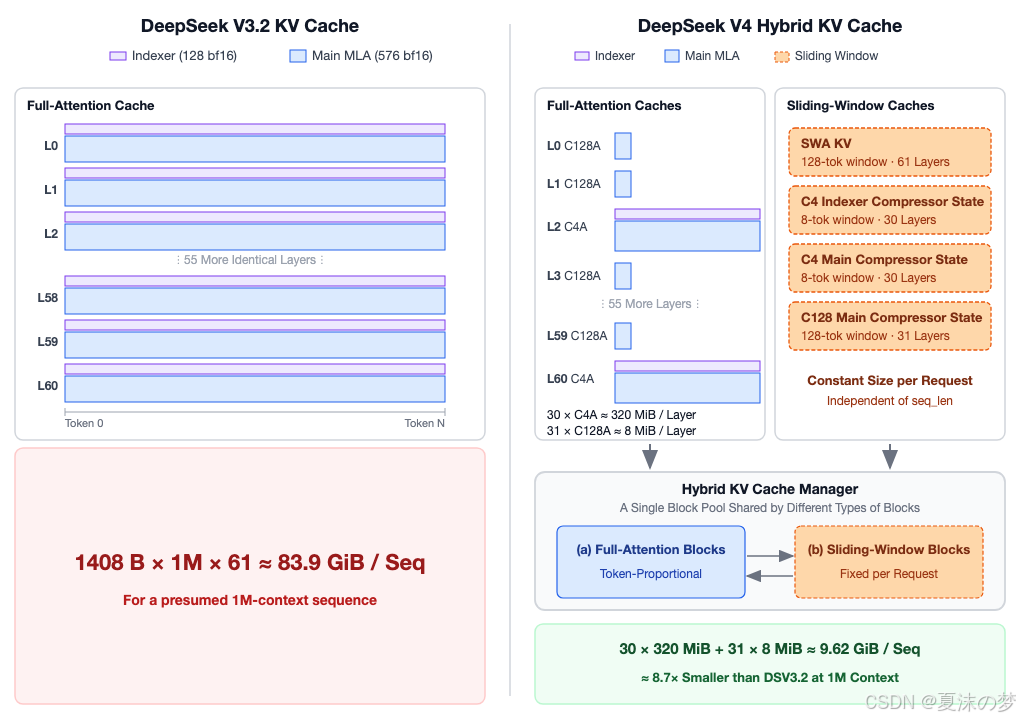
- 跨多个令牌压缩 KV 缓存 (4到128倍内存节省)。在 DeepSeek V4 中,有两种压缩方式:
c4a:将 KV 缓存压缩约 1/4。一个压缩令牌是 8个未压缩令牌 的加权和,步长为 4。c128a:将 KV 缓存压缩约 1/128。一个压缩令牌是 128个未压缩令牌 的加权和,步长为 128。
- DeepSeek 稀疏注意力 (有界注意力计算成本)。即使使用
c4a注意力压缩 KV 缓存,一百万 token 的序列仍有 25万个压缩令牌。为了加速注意力计算,我们可以使用 DeepSeek 稀疏注意力 (DSA) 仅关注前 k k k 个压缩令牌。 - 保持局部性:短滑动窗口。DeepSeek V4 使用大小为 128 的滑动窗口处理局部信息,在未压缩的令牌上操作,使查询令牌在达到压缩边界之前能够关注局部信息。
为了更好地说明这种新的注意力机制,以下是处理 13 个令牌的 c4a 注意力动画。有了上述细节,c128a 的情况也应该很容易理解。启动 交互式版本 可以悬停在令牌上检查连接。

高效的注意力设计带来了显著的 KV 缓存节省。使用 bf16 KV 缓存时,DeepSeek V4 在 100万上下文时每个序列仅有 9.62 GiB 的 KV 缓存。这比 61层 DeepSeek V3.2 风格堆栈的 83.9 GiB 估计值小约 8.7倍。在实践中,我们对索引器缓存使用 fp4,对注意力缓存使用 fp8,与 bf16 估计值相比,这进一步将 KV 缓存大小减少了约 2倍!
有关算术和数学解释的更多细节,请参阅附录。
vLLM 对 DeepSeek V4 的实现
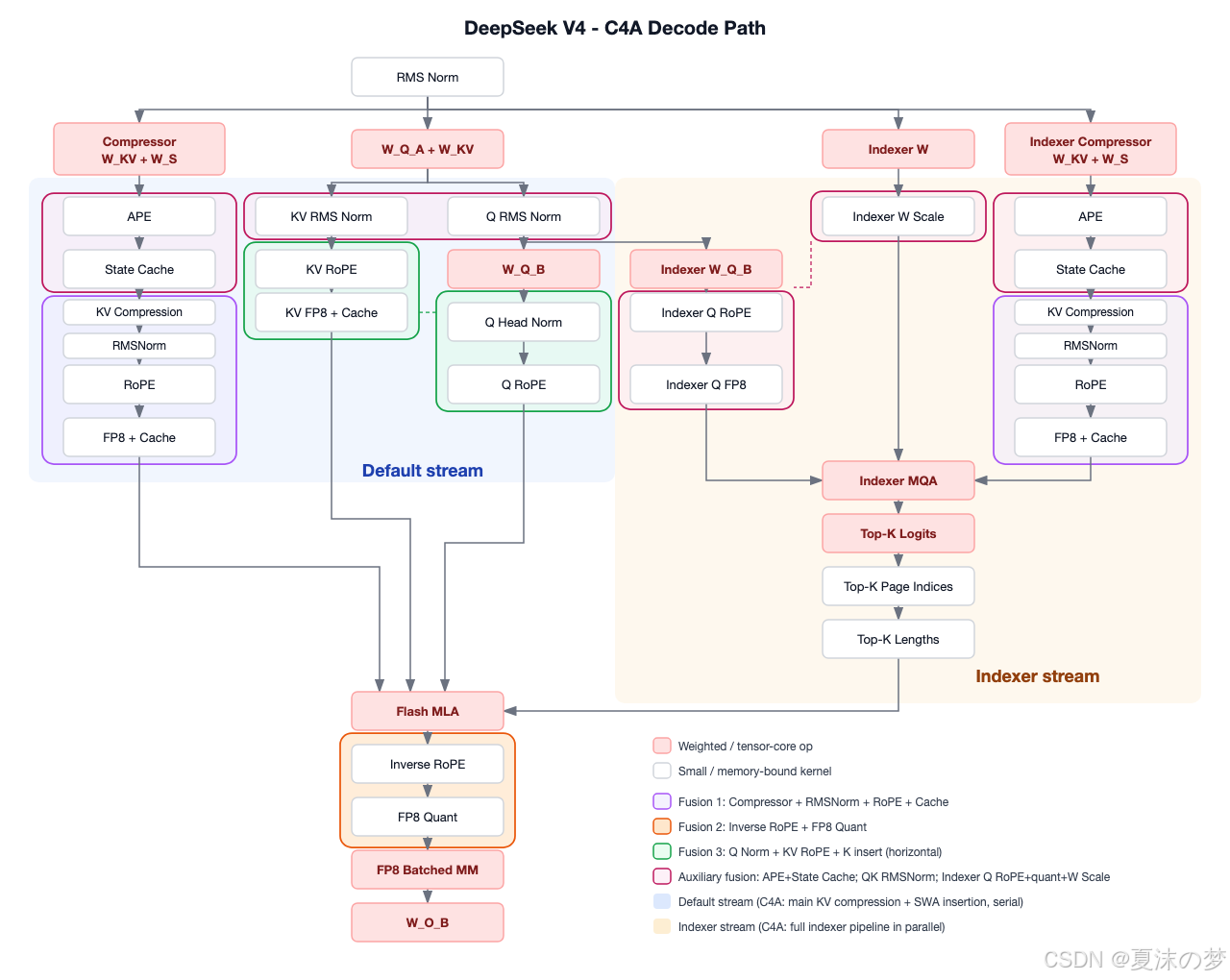
尽管结构上有所节省,注意力机制仍然具有内在复杂性,在 vLLM 中高效实现这些节省是一个系统工程问题,面临多个实现挑战:
- 与 DeepSeek V3.2 模型类似,注意力内核在预填充阶段使用 bfloat16 KV 缓存,在解码阶段部分使用逐令牌 fp8。
- 该模型混合使用
c4a和c128a注意力,某些注意力层仅使用滑动窗口处理局部信息而不进行压缩。异构的注意力类型使 KV 缓存管理变得更加复杂。 - 当批处理多个序列时,它们相对于 KV 缓存压缩边界可能处于不同的状态。
- 该模型附带原生 fp4 MoE 权重,需要在 vLLM 中进行特殊处理。
除了注意力机制本身外,还有其他一些更新,包括架构变化如 流形约束超连接,以及对 MoE 模块的一些更改。本文未涵盖这些内容,因为它们是更简单的模型更改,更容易适应。
vLLM 通过在两个方面进行优化来应对这些挑战:内存管理和内核效率。
保持 KV 缓存内存紧凑
vLLM 的 KV 缓存内存分配器必须在 GPU 内存中紧密打包多种类型的 KV 状态,同时仍能与前缀缓存、预填充/解码分离、CUDA 图以及 vLLM 服务路径的其余部分协同工作。三个设计选择使这一目标变得可控。
(1) 统一的逻辑块大小
不同的层以不同的速率压缩(c4a 为 1/4,c128a 为 1/128,SWA 为 1/1)。一个显而易见的设计是根据 压缩 条目的整数来调整每层的块大小。但这样每层都会有自己的页面布局,分配器必须分别处理所有层。
相反,我们将每个压缩层的逻辑块固定为 256个原始令牌位置 。c4a 块物理上包含 256 / 4 = 64 个压缩条目,c128a 块包含 256 / 128 = 2 个。分配块始终意味着保留请求上下文的下一个 256个原始位置,无论哪一层拥有它。槽位映射、调度器计费和前缀命中检测都可以使用相同的单位,而不是根据 compress_ratio 分支处理。
(2) 压缩器状态作为滑动窗口
每个压缩器层还为每个请求维护一个小的滚动残差:C4 的 8令牌(重叠)部分状态和 C128 的 128令牌部分状态。一个自然的初步设计是将该残差保存在每个请求的侧缓冲区中。这在孤立情况下可行,但一旦需要与服务栈的其余部分交互,就会变得尴尬。
使用侧缓冲区时,前缀缓存需要在每个可缓存边界快照滚动状态,将其与前缀哈希一起键入,并在命中时恢复。分离式预填充需要第二条传输路径,将残差与 KV 块一起从预填充工作器传输到解码工作器。每个需求单独处理都是可控的,但结合在一起就会创建另一个需要在各功能间维护的状态管理路径。
vLLM 通过将压缩器状态视为滑动窗口 KV 来避免这个问题。运行时不变量是相同的:每个请求固定大小,随着解码进行而推进,窗口外的状态要么被丢弃,要么通过缓存处理。因此我们在滑动窗口 KV 缓存规范下注册压缩器状态,sliding_window = coff * compress_ratio(C4 为 8,C128 为 128),并将其放入混合 KV 缓存管理器下的 SWA 风格块中。
这使得多个服务功能能够重用相同的抽象:
- 前缀缓存 重用正常的块语义。缓存命中落在 KV 缓存块边界(上述 256位置单位),该边界的压缩器状态已经是正确交接点。
- 分离式预填充 将压缩器状态视为 SWA 状态。仅传输窗口内的块,这在不引入单独的残差特定传输路径的情况下保留了传输大小节省。
- CUDA 图 和 MTP 遵循与 SWA 相同的集成模式,同时保留压缩器状态特定的元数据和实现细节。
(3) 统一页面大小
前两个选择仍然不够。C4 索引器块、c128a KV 块和 c4a 压缩器状态块仍然有不同的 页面大小(每块不同的字节数)。如果每种缓存类型都有自己的块池,我们最终会遇到试图消除的跨池碎片问题。
幸运的是,每种缓存类型的页面大小是乘积 block_size * compress_ratio * per_entry_size,所有三个因素都在我们的控制之下。如果我们仔细选择它们,不同的缓存类型会合并到少量 页面大小桶 中,每个桶可以由单个共享块池支持。