
该框架可以使模型访问超出其训练数据范围之外的信息,使得模型每次生成时可以利用检索提供外部更专业、更准确的知识,从而更好地回答用户问题。
下面直接把汪鹏《大模型 RAG 实战:RAG 原理、应用与系统构建》里的第 2 章 语言模型基础 、** 第 3 章 语言召回模型(文本向量化与检索)** 按原书结构帮你完整整理成一份清晰笔记,适合跟着 Karpathy 网课对照学习。Karpathy就是那个开发出GPT的人,他最近在YouTube上开课了,
RAG(Retrieval-Augmented Generation,检索增强生成)正式诞生于 2020 年,标志性事件是 Meta(原 Facebook AI Research)团队在 NeurIPS 2020 发表的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》。
所以这是一项非常年轻的技术,几乎是伴着我大学毕业至今一直在成长的技术。
第 2 章 语言模型基础(Transformer、BERT、GPT 系)
2.1 Transformer 基础(RAG 的底层骨架)
Transformer 是当前所有大模型(BERT/GPT/LLaMA)的基础架构,RAG 的 "向量化""语义匹配" 全依赖它。
2.1.1 词嵌入(Embedding)
- 把离散单词 → 连续向量(语义相近的词向量距离近)
- 作用:让模型能计算语义相似度(RAG 召回核心)
- 维度:常见 512/768/1024 维
2.1.2 编码器(Encoder,BERT 类)
- 结构:N 层(通常 12/24 层),每层包含:
- 多头自注意力(Multi-Head Attention) :
- 让每个词 "看" 句子里所有词,捕捉上下文依赖
- 例:"它" 指代前面的 "猫"
- 前馈神经网络(Feed-Forward):非线性变换,增强表达
- 多头自注意力(Multi-Head Attention) :
- 输出:上下文相关的词向量(同词不同义,向量不同)
- 用途:理解、编码、召回(RAG 的 embedding 模型)
2.1.3 解码器(Decoder,GPT 类)
- 结构:N 层,除了自注意力,还有掩码自注意力(只能看前面词)
- 特点:自回归生成(一个词一个词输出)
- 用途:生成答案(RAG 的 LLM 部分)
2.1.4 解码头(LM Head)
- 把解码器输出向量 → 词汇表概率
- 取概率最大的词作为下一个输出
2.2 自动编码器(Encoder-only:ELMo、BERT)
这类模型只用电编码器 ,擅长理解 / 分类 / 匹配 / 召回。
2.2.1 ELMo(早期上下文向量)
- 双向 LSTM,输出上下文相关向量
- 缺点:特征提取弱、并行差,被 BERT 取代
2.2.2 BERT(双向编码器,RAG 召回模型主力)
- 核心:双向 Transformer 编码器
- 预训练任务:
- MLM(掩码语言建模):随机遮词,预测被遮词 → 强语义理解
- NSP(下一句预测):判断两句是否连续 → 句子关系理解
- 输出:句子 / 文本的稠密向量(Dense Embedding)
- RAG 中的角色:文档向量化、查询向量化、语义召回
2.3 自回归模型(Decoder-only:GPT、LLaMA)
这类模型只用解码器 ,擅长生成 / 续写 / 问答,RAG 的 "生成端"。
2.3.1 GPT 系列(OpenAI)
- GPT-1:12 层 Transformer 解码器,自回归预训练
- GPT-2:更大参数,无监督续写,零样本能力
- GPT-3:175B 参数,in-context learning(提示词学习)
- 核心:上下文学习 + 自回归生成
- RAG 角色:接收检索结果 + 问题 → 生成答案
2.3.2 LLaMA(开源 GPT 类,RAG 常用)
- Meta 开源,7B~65B 参数
- 结构:同 GPT(Decoder-only)
- 优势:开源、可本地部署、适配中文
- RAG 角色:替代 GPT 作为本地生成引擎
2.4 本章小结(RAG 视角)
- Encoder(BERT) → 负责理解与召回(把文档 / 问题变成向量)
- Decoder(GPT/LLaMA) → 负责生成与回答(把检索结果 + 问题变成答案)
- RAG = BERT 类召回模型 + GPT 类生成模型 的组合系统
第 3 章 语言召回模型(RAG 核心:文本向量化 + 检索)
(原书第 3 章:RAG 中的文本向量化与检索模型)
3.1 召回模型的核心任务
- 给定 查询 Query ,从 知识库 Document 中找出 Top-K 最相关片段
- 本质:文本相似度计算 + 高效检索
3.2 文本向量化模型(Embedding Model)
把变长文本 → 定长稠密向量 ,保证语义相似 → 向量距离近。
3.2.1 稀疏向量模型(传统检索,如 TF-IDF、BM25)
- 特点:基于词频、无语义理解、速度快
- 原理:词出现次数越高,权重越大;不考虑上下文
- 缺点:无法理解同义词 / 多义词(如 "电脑"≈"计算机",稀疏模型不匹配)
- RAG 角色:基础召回、速度快、作为混合搜索的一路
3.2.2 稠密向量模型(Dense Embedding,RAG 主流)
基于 BERT/RoBERTa/SimBERT 等 Encoder 模型,输出上下文相关稠密向量。
- 训练目标:语义相似度最大化
- 输入:(Query, 正相关 Doc, 负相关 Doc)
- 损失:让 Query 与正 Doc 向量距离 < 与负 Doc 距离
- 代表模型:
- BERT-base:768 维,通用强
- all-MiniLM:轻量、快、适合本地
- text-embedding-ada-002:OpenAI 闭源,效果好
- RAG 优势:理解语义、匹配同义词、召回更准
3.2.3 混合检索(Sparse + Dense,工业界最优)
- 同时用 BM25(稀疏)+ 稠密向量(Dense) 两路召回
- 融合分数:最终相似度 = α・BM25 分数 + β・Dense 相似度
- 效果:兼顾速度、语义、关键词匹配,解决单一模型短板
3.3 向量检索引擎(Vector Database)
稠密向量召回必须依赖专用向量库(普通数据库无法高效算相似度)。
3.3.1 核心原理:近似最近邻(ANN)
- 问题:100 万 768 维向量,暴力算相似度太慢(O (N))
- 解决:ANN 算法 (如 FAISS、IVF、HNSW)
- 先聚类分桶 → 只在相似桶内搜索 → 速度提升 10~100 倍
- 牺牲极小精度,换百万级向量毫秒级召回
3.3.2 主流开源向量库(RAG 常用)
- FAISS(Meta):CPU/GPU 高效,适合小规模
- Milvus(Zilliz):分布式、高可用、工业级
- Chroma:轻量、本地部署、适合原型
- PGVector:PostgreSQL 插件,适合已有 PG 栈
3.4 召回模型评估指标
- Recall@K:前 K 个结果中包含正确文档的概率(RAG 优先看召回率)
- Precision@K:前 K 个结果中相关文档的比例
- MRR:正确文档在结果列表中的平均排名
3.5 本章小结(RAG 实战要点)
- 稀疏召回(BM25):快、关键词准、无语义
- 稠密召回(BERT 类):慢一点、语义准、理解上下文
- 工业级 RAG :BM25 + 稠密向量 + 向量库 ANN 检索 的混合方案
可以直接对照 Karpathy 网课的部分
- Karpathy 讲 Transformer/BERT/GPT 架构 → 对应本书第 2 章
- Karpathy 讲 Embedding / 向量检索 / 语义匹配 → 对应本书第 3 章
- RAG 整体 = Encoder(召回)+ Decoder(生成) 的流水线
TIPS:
Karpathy相关
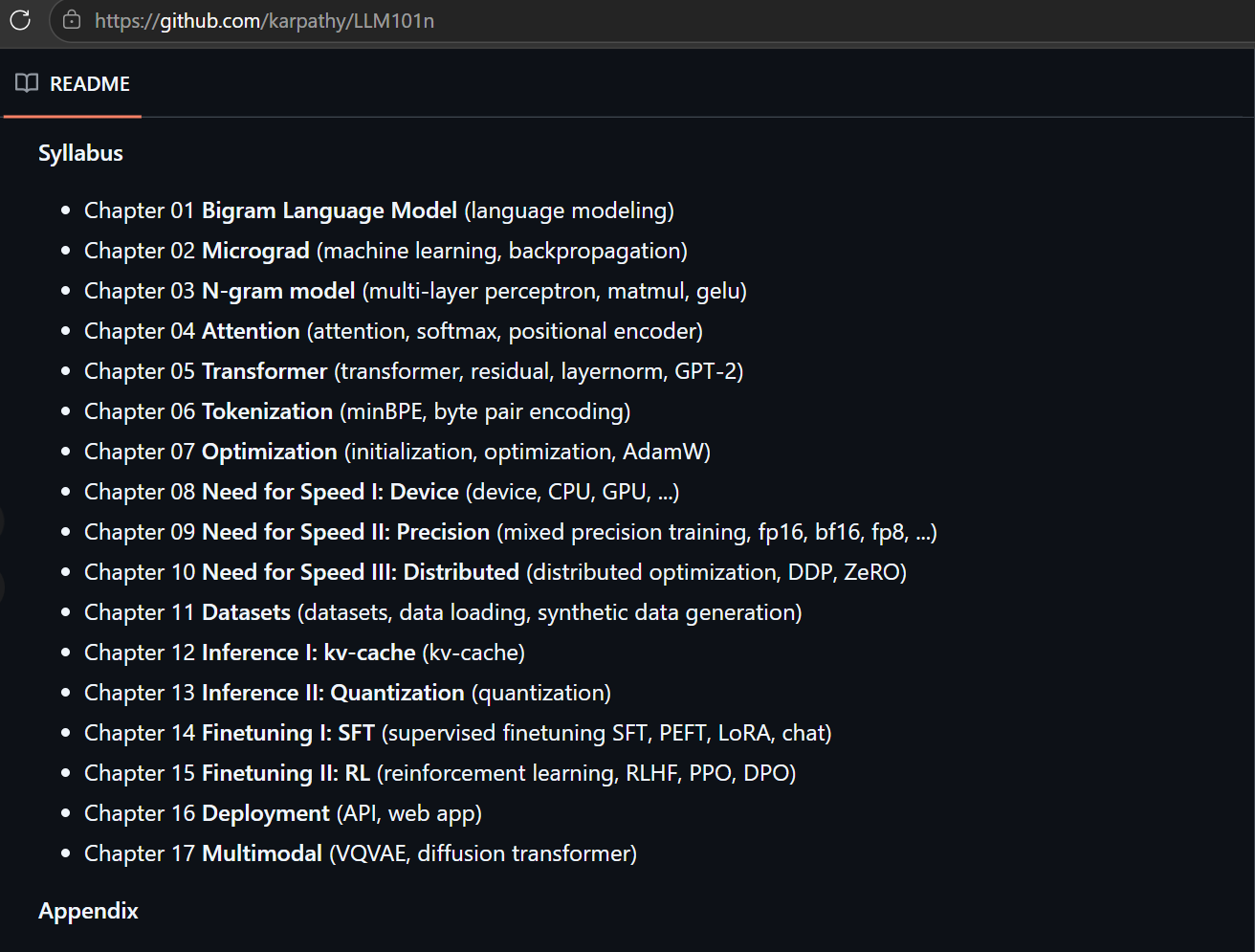
GitHub:
https://gist.github.com/karpathy
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
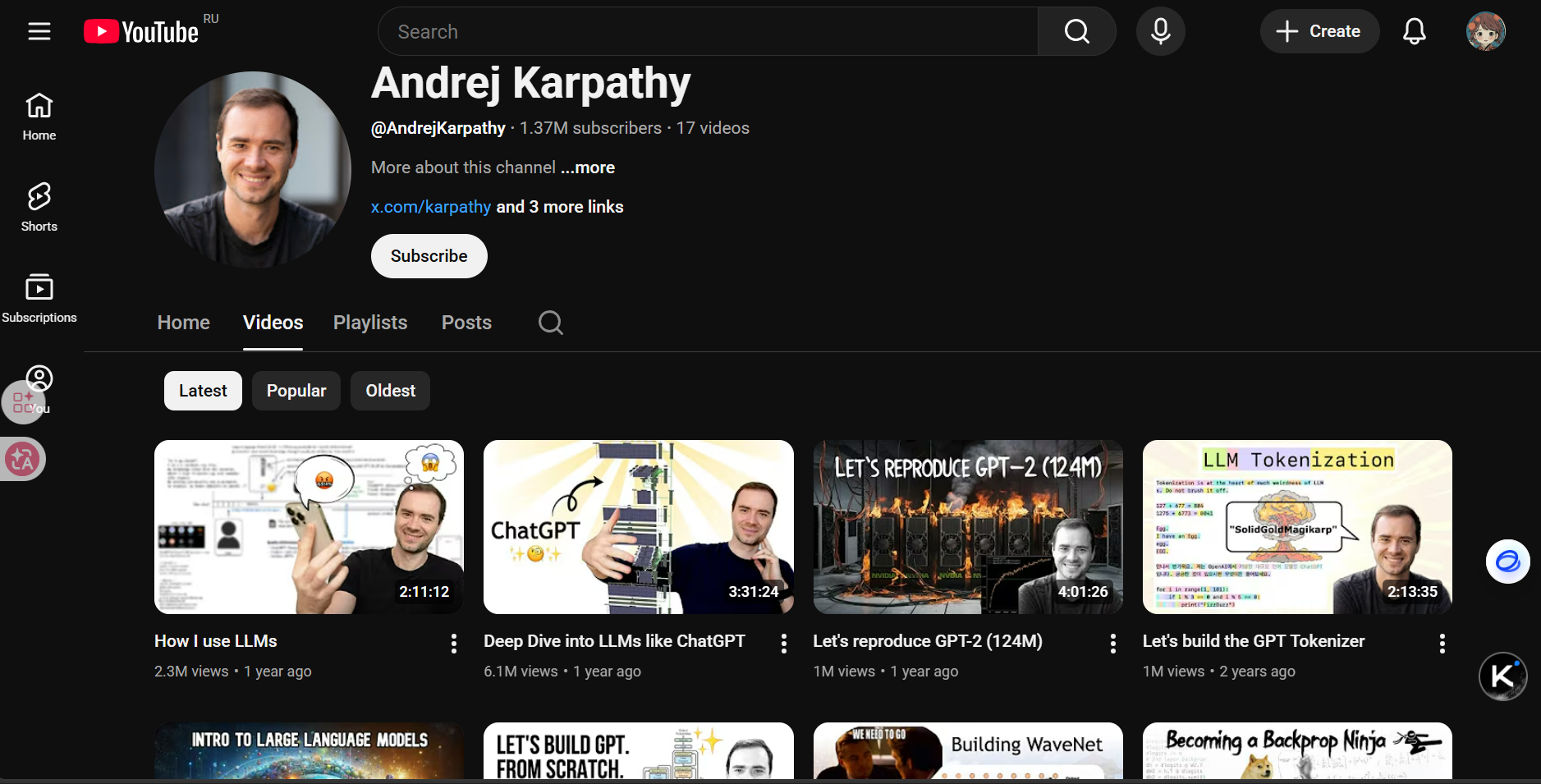
YouTube: