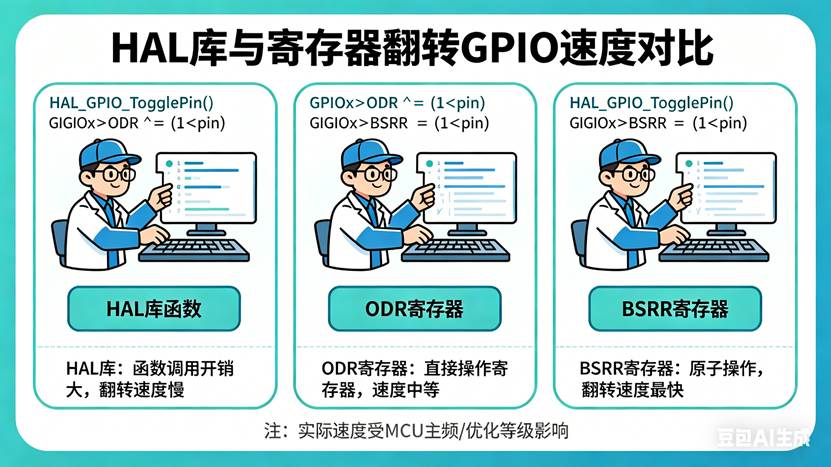
你有没有想过一个问题:同样是翻转GPIO引脚,用HAL库、用ODR寄存器、用BSRR寄存器,速度能差多少?教程中用示波器实测了三种方法:
- HAL库的HAL_GPIO_WritePin:最慢
- ODR寄存器的"读-改-写":中等
- BSRR寄存器的"只写":最快
速度差距,肉眼可见。那个"函数调用"的开销(对应教程3.14节),HAL库的HAL_GPIO_WritePin,代码写起来很简单:
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_8, GPIO_PIN_SET);
但背后有函数调用的代价:
- 入栈:保存当前函数的现场(LR、R0-R3等)
- 跳转:跳转到HAL_GPIO_WritePin函数
- 执行:函数内部的参数判断、寄存器操作
- 出栈:恢复现场,返回
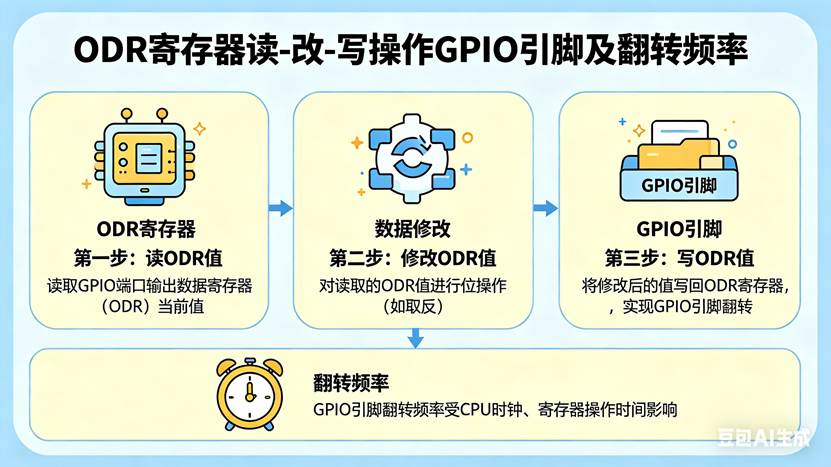
一条GPIO操作,背后是一堆指令。 教程中用示波器测量:HAL库方式翻转频率约1-3MHz 。**那个"读-改-写"的ODR(对应教程3.15节)**直接操作ODR寄存器:
GPIOA->ODR |= (1 << 8); // PA8置1
GPIOA->ODR &= ~(1 << 8); // PA8清0
但这里有个问题:读-改-写不是原子操作。|= 和 &= 编译后变成:
- 读ODR寄存器到CPU
- 修改某一位
- 写回ODR寄存器
三步操作,比直接写多了一步"读"。教程中用示波器测量:ODR方式翻转频率约9-18MHz。
**那个"只写"的BSRR(对应教程3.15节),**BSRR寄存器专门为"原子修改单个引脚"设计:
GPIOA->BSRR = (1 << 8); // 置位BS8,PA8输出高
GPIOA->BSRR = (1 << (8+16)); // 置位BR8,PA8输出低
BSRR分为低16位(置位)和高16位(复位)。
写1到BS8 → PA8高
写1到BR8 → PA8低
不需要读,直接写,一条指令搞定。 教程中用示波器测量:BSRR方式翻转频率可达50MHz以上(受GPIO速度模式限制)。
**那个"BSRR"的妙用,**BSRR还能同时设置多个引脚的状态:
GPIOA->BSRR = 0x000F0000; // 同时复位PA0-PA3
GPIOA->BSRR = 0x0000000F; // 同时置位PA0-PA3
一条指令,同时改多个引脚,原子操作。
那个"实测"的数据(对应教程3.15节)
| 方法 | 翻转频率 | 相对速度 |
|---|---|---|
| HAL_GPIO_WritePin | ~1-3 MHz | 1x |
| ODR读-改-写 | ~9-18 MHz | ~6x |
| BSRR只写 | ~50 MHz+ | ~25x |
差距巨大。
那个"速度模式"的影响(对应教程3.15节)
BSRR能跑50MHz,但前提是GPIO速度模式要设对。
教程中演示了:GPIO速度模式设2MHz,输出4MHz方波 → 方波变三角波。
速度模式要匹配实际翻转频率。这个故事的启示 ,为什么BSRR比ODR快?因为ODR需要"读-改-写",BSRR只需要"写" 。为什么寄存器比HAL快?因为函数调用有入栈出栈开销 。HAL方便,寄存器高效------看你要什么。
**写在最后,**下次你需要高速翻转GPIO(比如模拟SPI、驱动WS2812),别用HAL。
想想BSRR。一条指令,只写不读。快,才是硬道理。
(本文灵感源于于振南《新概念ARM32单片机》教程第3.14节"GPIO操作效率对比:库函数与寄存器"和第3.15节"GPIO速率实测",感谢作者将GPIO性能优化的底层逻辑讲得如此通透。)
如果您觉得这个故事对您有启发,欢迎点赞、转发,让更多工程师看到这个藏在BSRR背后的"只写"哲学。
