背景
卷积神经网络(CNN)广泛应用于移动端视觉任务,GEMM 是其推理的性能瓶颈,脉动阵列(SA)通过局部寄存器通信高效加速 GEMM,被广泛应用于 TPU 等商用产品,但传统架构仍有优化空间。
面临问题
CNN 模型中普遍存在稀疏性,但利用稀疏性面临四大挑战:随机稀疏难以利用、结构化稀疏影响精度、索引存储开销大、SA 寄存器比率失衡。本文提出的 STA 架构一次性解决了这些问题。
| 问题 | 描述 |
|---|---|
| 随机稀疏难以利用 | 零元素位置无规律,需额外存储索引,负载不均衡导致硬件利用率低下 |
| 结构化稀疏影响精度 | 将零值按固定块组织虽便于硬件实现,但块尺寸较大时会显著损害 CNN 精度 |
| 索引存储开销大 | 传统方法需为每个非零元素存储索引,在 INT8 权值场景下开销尤为严重 |
| SA 寄存器比率失衡 | 每个 MAC 单元需要两个 INT8 寄存器 + 一个 INT32 累加器,比例存在优化空间 |
1. 引言
本文两大贡献:将标量 PE 泛化为 Tensor-PE 衍生出 STA 架构;引入 DBB 稀疏格式实现 STA-DBB,在面积效率和功耗上均大幅领先 SA 基线,同时完全向后兼容密集模型。
卷积层通常通过将二维卷积"降维"为 GEMM 核来执行。SA 由一列 MAC 处理单元(PE)构成,各单元之间仅通过局部的寄存器到寄存器通信传递操作数和结果,使其非常高效且易于扩展,不产生时序问题。这些优势使其被部署在 Google TPU 等商用产品中。
本文针对移动端 CNN 推理的窄 INT8 操作数,描述了两项对传统 SA 架构的重大改进:
- 第一(STA) :将传统的标量 PE 泛化为 Tensor-PE ,衍生出 Systolic Tensor Array(STA) 微架构家族。STA 通过增加 PE 内操作数复用和 datapath 效率,在同吞吐量下与时钟门控 SA 相比,电路面积减少最高 2.08 倍 ,功耗降低 1.36 倍。
- 第二(STA-DBB) :扩展 STA 以支持 Density-Bound Block(DBB) 新型块稀疏数据格式。该变体在处理专门训练的 DBB 稀疏模型时,相较于 SA 基线在同吞吐量下面积效率提升 3.14 倍 ,功耗效率提升 1.97 倍,同时完全向后兼容密集模型。
2. 背景与相关工作
2.1 面向 CNN 推理的脉动阵列
INT8 微架构的 datapath 成本相对较低,数据移动成本占比更高;本文以 TPU-like SA 为基线,通过时钟门控和输出驻留数据流进行优化。
本文以 TPU-like SA 为起点进行了修改:(1)对零操作数进行时钟门控;(2)采用输出驻留数据流------让较大的 INT32 累加器保持不动,而移动较小的 INT8 操作数。
2.2 CNN 的稀疏矩阵
DBB 是随机稀疏与结构化块稀疏之间的完美折中:对每个块的非零元素数量设定上限,在相同 NNZ 下获得更高精度,同时硬件计算量已知,保证高利用率。
CNN 层在权值数据和激活数据中均存在稀疏性。
- 随机稀疏(图 1a):零的位置没有约束,很难利用
- 结构化块稀疏(图 1b):硬件友好,但块尺寸较大时会损害 CNN 精度
本文提出 DBB (图 1c):对每个块的非零(NNZ)元素数量设定上限。例如由 8 个 8×1 块组成,每个块最多 3 个非零值(NNZ≤3)。这在相同 NNZ 下能获得更高 CNN 精度,同时硬件计算量已知,保证高利用率。DBB 采用位掩码压缩,可实现权重内存占用 减少 37.5%。
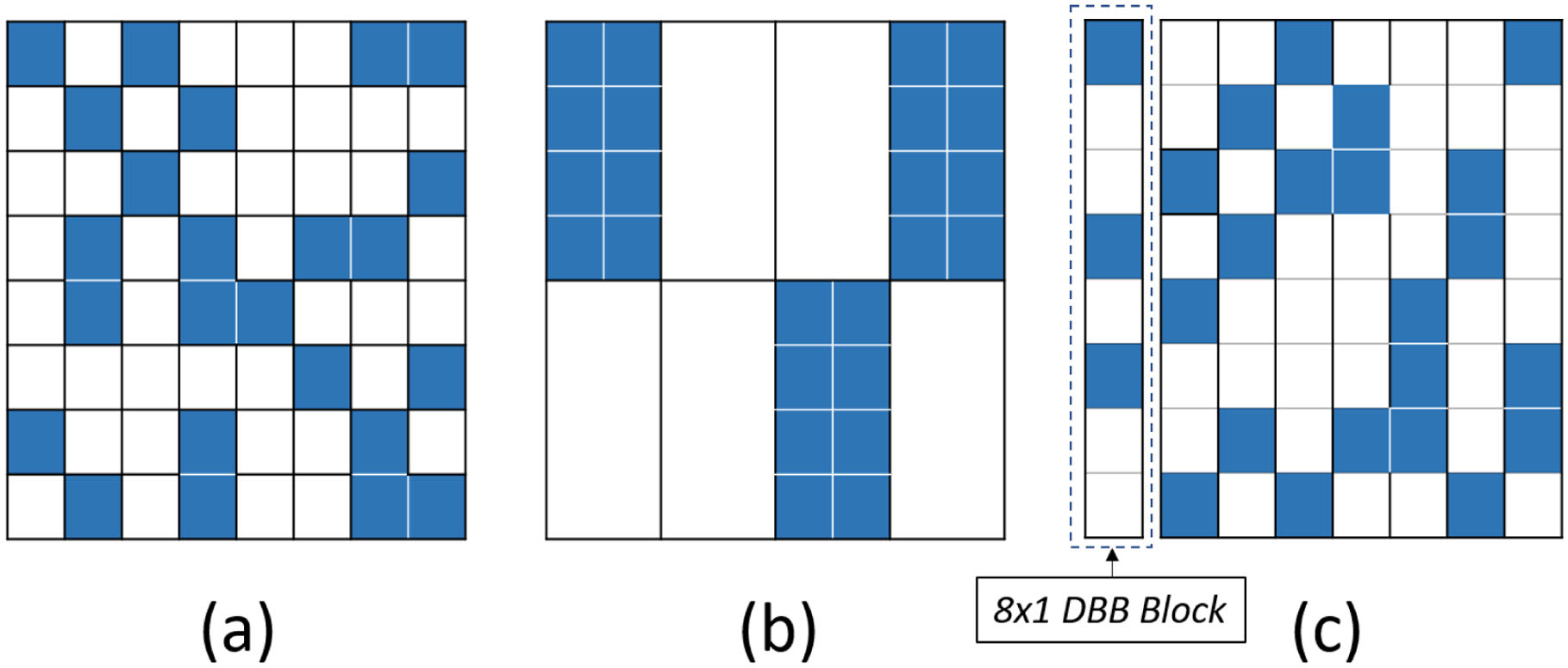
Fig 1. 三种稀疏矩阵格式对比:(a) 随机稀疏;(b) 块稀疏(4×2 块);© DBB(8×1 块)。填充元素表示非零值。
2.3 稀疏矩阵乘法加速器
索引方法存储开销巨大;本文在 SA 架构基础上另辟蹊径,采用 Tensor-PE + 新型结构化稀疏方案,而非随机稀疏。
利用零操作数的方法包括时钟门控和索引存储(例如 EIE、SCNN)。然而索引方法开销巨大。本文在 SA 架构基础上利用 Tensor-PE + 新型结构化稀疏 方案,而非随机稀疏,开创了一条新路径。
3. 密集 GEMM 加速器
3.1 传统脉动阵列(SA)
SA 通过局部寄存器通信实现高效 GEMM,但存在寄存器/MAC 比率失衡的优化空间;基线 SA 采用 INT8 操作数寄存器和 INT32 累加器。

Fig 2. SA 微architectures,将每个标量 PE 泛化为执行矩阵乘法的 tensor PE。Notation:A×B×C_M×N 表示 M×N 个 A×B×C tensor PE 的阵列。
图 2a 展示了经典的 SA,被广泛应用于产品中。目标应用为移动视觉场景,采用 INT8 操作数寄存器(REG)和 INT32 累加器寄存器(ACC)。传统 SA 仍有很大改进空间------放松操作数寄存器(REG)与 MAC 的比率。
3.2 脉动张量阵列(STA)
STA 将多个标量 PE 融合为一个 Tensor-PE,每个 Tensor-PE 内执行向量点积;经典 SA 是 STA 的特例(A=B=C=1);通过减少操作数缓冲区和累加器缓冲区,实现显著效率提升。
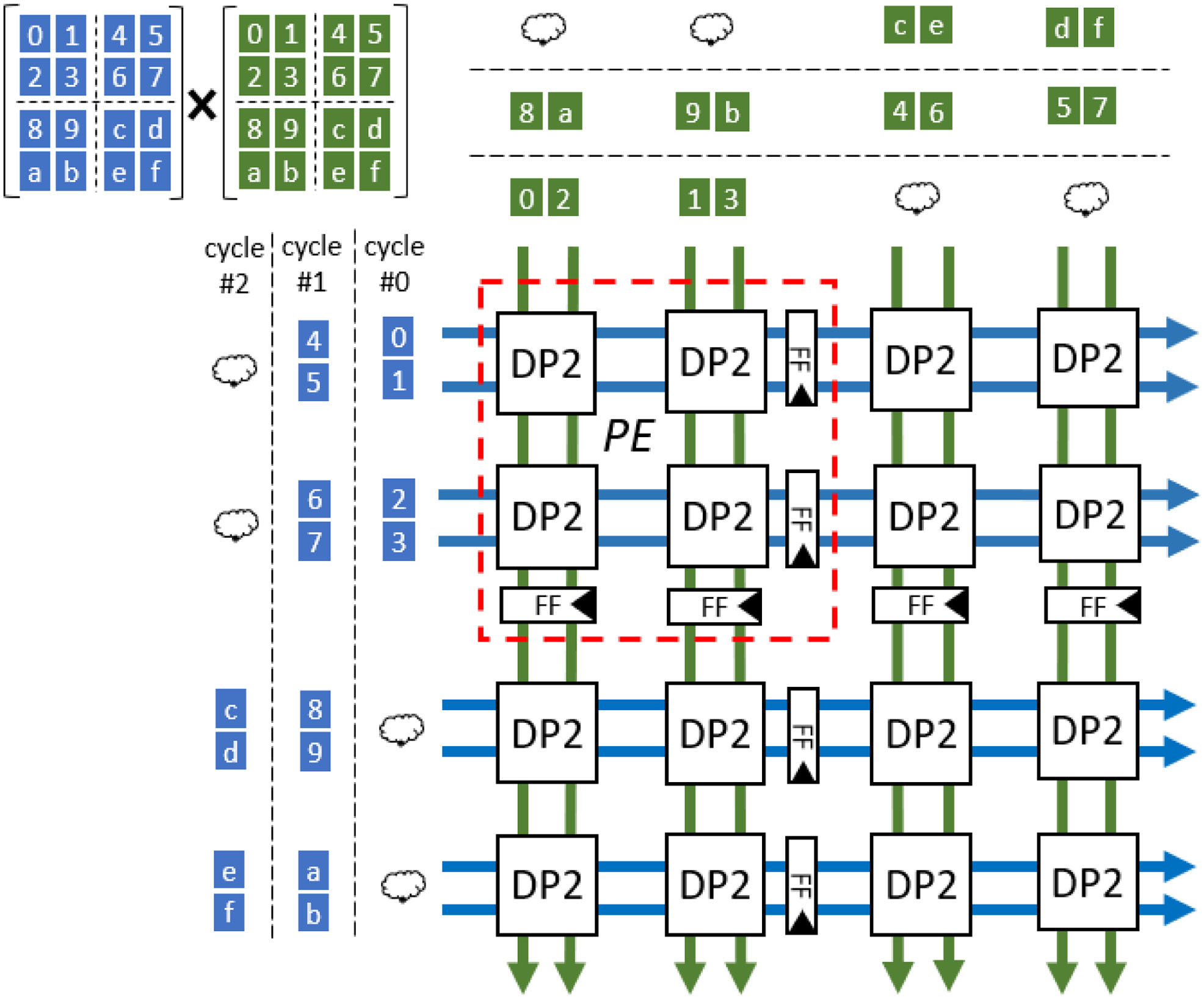
Fig 3. Example 2×2×2_2×2 STA 数据流。tensor PE 执行 4×4 × 4×4 矩阵乘法。
图 2b 展示了传统 SA,图 2a 展示了 Systolic Tensor Array(STA) ------通过将一组标量 PE 融合为单个 tensor PE 来实现泛化。
每个 STA 架构包含 M×N 个 tensor PE,每个 tensor PE 由 A×C 个 MAC 子阵列构成,每个 MAC 对 B 对操作数执行点积运算,表示为:
A×B×CM×N A \times B \times C_{M \times N} A×B×CM×N
图 2c 展示了一个 2×2 的 tensor PE 阵列,每个 tensor PE 有 2×2 的 datapath,包含 4 个操作数对点积单元(DP4)。经典 SA 是 STA 的特例(A=B=C=1,即 1×1×1_M×N)。
通过将每个 MAC 的操作数缓冲区减少 2 倍 ,累加器缓冲区减少 4 倍,实现了显著的效率提升。
4. CNN 稀疏 GEMM 加速器
4.1 Density-Bound Block(DBB)
DBB 对每个块的非零元素数量设定上限,是随机稀疏与块稀疏之间的完美折中:精度损失仅 0.1%~1.1%,内存减少 37.5%,硬件高利用率。
【请在此处插入 Fig 1 图片:liu2020_images/fig1_page2.jpeg】
Fig 1©. DBB(8×1 块)稀疏矩阵格式,对每个块的 NNZ 设定上限。
DBB 矩阵格式的核心理念很简单:对每个块的非零(NNZ)元素数量设定上限。这与传统的块稀疏格式不同------在传统格式中,每个块要么完全不受约束,要么全为零。DBB 是随机稀疏与块稀疏之间的完美折中,在相同 NNZ 下能获得更高的 CNN 精度。
DBB 采用简单的位掩码压缩来编码每个 8 元素块(每个块 1 字节开销),外加 4 字节非零数据,可实现权重内存占用 减少 37.5%。
4.2 面向 DBB 的 STA(STA-DBB)
STA-DBB 利用 DBB 上限削减物理 MAC 单元(节省 50%);用 MUX 替代乘法器,成本远低于 8 位乘法器;保持一半吞吐量密集 GEMM 向后兼容。
将 STA 架构扩展以支持 DBB 稀疏权值矩阵。当 DBB 块大小为 8、NNZ≤4 时,每个 8 输入点积单元(DP8)只需 4 个 MAC 单元而非 8 个,实现物理 MAC 减少 50%。
该方案在 MAC 前加一个多路复用器(MUX),根据非零权值的索引选择对应的激活值。在每个 SDP4 中,用两个 8 位 4:1 MUX 换取两个 8 位乘法器------MUX 的成本远低于 8 位乘法器。该阵列在每个时钟周期执行 16 个有效 MAC ,但仅使用 8 个物理乘法器。
重要的是,该架构仍以一半吞吐量支持传统密集 GEMM,完全向后兼容。
5. 结论
本文通过将标量 PE 泛化为 Tensor-PE(STA),增加 PE 内操作数复用,显著减少电路面积和功耗;进一步扩展的 STA-DBB 在处理 DBB 稀疏模型时效率和兼容性兼得,完全向后兼容传统密集模型。
文章信息
标题: Systolic Tensor Array: An Efficient Structured-Sparse GEMM Accelerator for Mobile CNN Inference
作者: Zhi-Gang Liu, Paul N. Whatmough, Matthew Mattina
单位: Arm ML Research Lab, Boston, MA, USA
期刊: IEEE Computer Architecture Letters, Vol. 19, No. 1, January-June 2020