AI 学习路线 03:线性代数、概率统计、梯度下降到底有什么用?
前言
很多人学 AI 时,一听到数学就头大:
- 线性代数是不是要先学完矩阵推导?
- 概率统计和大模型有什么关系?
- 梯度下降为什么能让模型变好?
- 向量、矩阵、张量到底在 AI 里做什么?
这篇文章不走"先堆公式"的路线,而是按 AI 中的实际用途来理解数学。
先记住一张总图:
text
线性代数:数据怎么表示
概率统计:模型怎么表达不确定性
微积分与优化:模型怎么调整参数也就是说,数学不是为了考试,而是为了帮我们回答三个问题:
- 文本、图片、音频为什么能变成数字?
- 模型为什么输出的是概率?
- 模型为什么能通过训练一步步变好?
一、数学在 AI 中分别负责什么?
| 数学模块 | 核心作用 | 在 AI 中解决的问题 |
|---|---|---|
| 线性代数 | 向量、矩阵、张量 | 数据怎么表示和计算 |
| 概率统计 | 概率、分布、期望、方差 | 模型怎么表达不确定性 |
| 微积分与优化 | 导数、梯度、损失函数 | 参数怎么调整,模型怎么变好 |
这三块不是孤立的。
一个模型训练过程大致是:
text
数据先变成向量 / 矩阵 / 张量
-> 模型输出每个结果的概率
-> 损失函数衡量错得多远
-> 梯度下降调整参数
-> 模型逐渐变好下面分开讲。
二、线性代数:AI 的数据表示语言
AI 处理不了"原始世界",它只能处理数字。
现实世界里有文本、图片、音频、用户、商品、行为记录,但模型真正能计算的是:
text
数字所以这些对象最后都要变成数字结构。
| 真实对象 | AI 中的表示 |
|---|---|
| 一个词 | 向量 |
| 一句话 | 向量序列 |
| 一张灰度图 | 矩阵 |
| 一张彩色图 | 三维张量 |
| 一段音频 | 数组 / 序列 |
| 一批训练样本 | 矩阵或张量 |
一句话:
线性代数是 AI 的数据表示语言。
三、标量、向量、矩阵、张量
先看图:

它们可以这样理解:
| 概念 | 通俗理解 | 例子 |
|---|---|---|
| 标量 Scalar | 一个数字 | 温度 26 |
| 向量 Vector | 一串数字 | [0.2, 0.8, -0.1] |
| 矩阵 Matrix | 二维数字表 | 灰度图片、表格数据 |
| 张量 Tensor | 更高维数字结构 | 彩色图片、视频、批量数据 |
最简单的记法:
text
标量:一个数字
向量:一行数字
矩阵:一张二维表
张量:多维数组比如一个用户特征:
text
[年龄, 消费金额, 登录次数]这就是一个向量。
一批用户特征:
text
[
[25, 1200, 10],
[32, 800, 5],
[28, 1500, 12]
]这就是一个矩阵。
四、Embedding:为什么文本可以变成向量?
模型不能直接理解"退款""苹果""天气"这些词,它需要数字。
所以会把文本变成向量:
text
苹果 -> [0.12, -0.35, 0.88, 0.04, ...]
退款 -> [0.40, 0.11, -0.20, 0.76, ...]这叫 Embedding。
Embedding 的功能是:
把文本、图片、用户、商品等对象表示成向量,让模型可以计算它们之间的关系。
看图:

如果两句话意思接近,它们的向量在空间里通常也更接近。
| 文本 A | 文本 B | 相似度直觉 |
|---|---|---|
| 怎么申请退款 | 订单怎么退货 | 高 |
| 怎么申请退款 | 今天天气怎么样 | 低 |
| 手机电池不耐用 | 手机续航很差 | 高 |
后面学习 RAG 时,Embedding 会非常重要。
RAG 里的知识库检索可以这样理解:
text
用户问题 -> 转成向量
文档片段 -> 转成向量
比较向量相似度
找出最相关的文档片段
交给大模型回答所以先记住:
Embedding = 把对象变成向量。
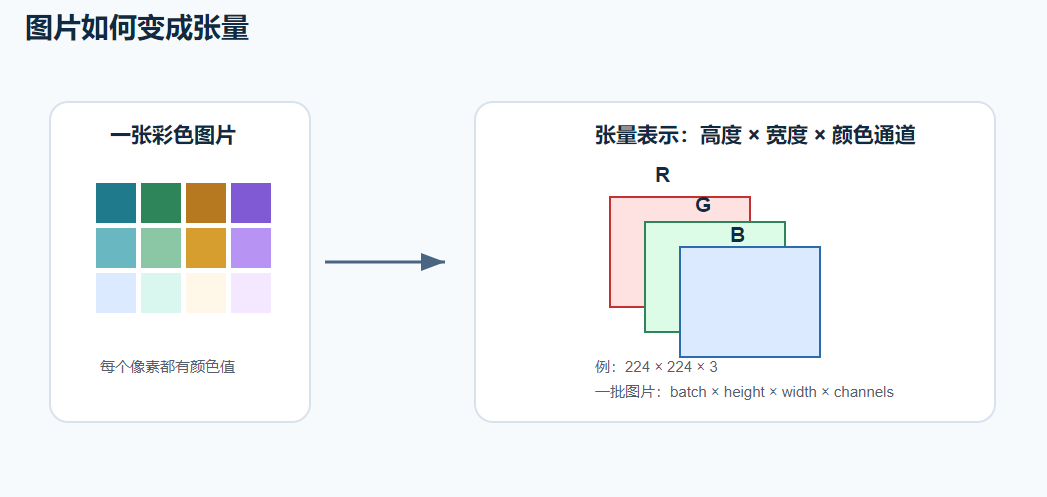
五、图片如何变成张量?
图片也不是神秘对象,本质上也是数字。
一张灰度图片可以看成二维矩阵:
text
[
[0, 10, 25],
[40, 80, 120],
[200, 220, 255]
]每个数字表示一个像素的亮度。
一张彩色图片通常有 RGB 三个颜色通道:
text
高度 × 宽度 × 3例如:
text
一张 224 × 224 的彩色图片
= 224 × 224 × 3 的张量如果是很多张图片一起训练,就会变成:
text
batch × height × width × channels也就是:
text
批量大小 × 高度 × 宽度 × 颜色通道这就是为什么深度学习框架里经常看到 Tensor 这个词。
张量不是玄学,它就是多维数组。
六、矩阵乘法在神经网络中做什么?
矩阵可以理解成很多向量排在一起。
比如一批样本:
text
[
[170, 65, 28],
[180, 75, 32],
[160, 50, 22]
]每一行是一个样本,每一列是一个特征。
神经网络内部大量计算,本质上就是矩阵和张量运算。

可以先记住这个形式:
text
输入特征矩阵 × 权重矩阵 = 下一层表示用符号写就是:
text
X × W = H其中:
X:输入特征矩阵W:模型要学习的权重矩阵H:变换后的新表示
一个 NumPy 小例子:
python
import numpy as np
# 3 个样本,每个样本有 3 个特征
X = np.array([
[170, 65, 28],
[180, 75, 32],
[160, 50, 22],
])
# 3 个输入特征,映射到 2 个新维度
W = np.array([
[0.1, 0.3],
[0.2, 0.4],
[0.5, 0.6],
])
H = X @ W
print(H)这里的 X @ W 就是矩阵乘法。
直觉上,它把原来的 3 个特征变成了 2 个新的表示。
示例输出可以理解成这样:

神经网络会反复做类似的事情:
text
输入 -> 矩阵变换 -> 激活函数 -> 再矩阵变换 -> 输出这也是 GPU 适合 AI 的原因之一:
GPU 擅长大规模并行矩阵计算。
七、概率统计:模型如何表达不确定性?
线性代数解决的是:
text
数据怎么表示概率统计解决的是:
text
模型怎么表达不确定性很多 AI 任务不是 100% 确定的。
比如一句评论:
text
这个手机续航很好模型可能不是只说"正面",而是输出:
text
正面:0.86
中性:0.10
负面:0.04这就是概率。
八、概率分布:多个结果的可能性
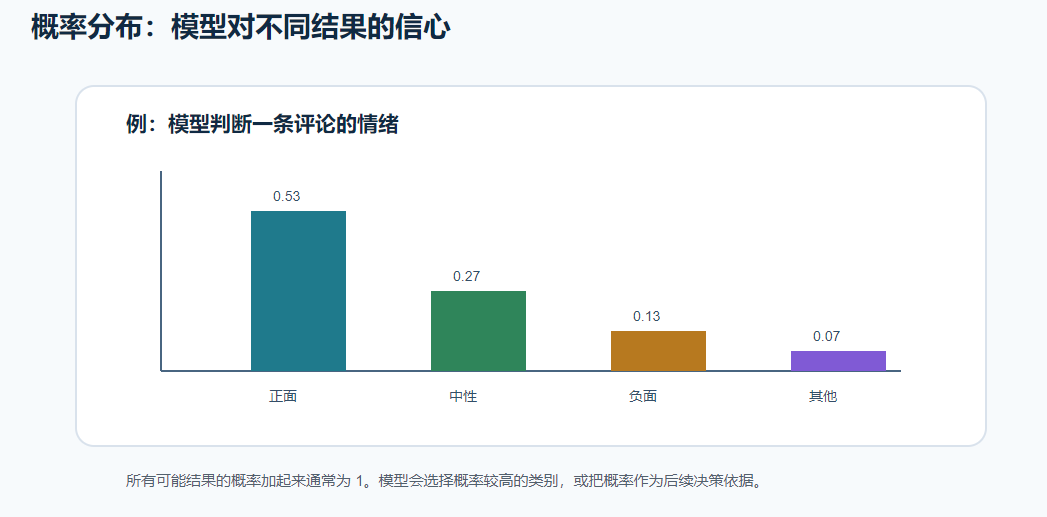
概率分布可以理解为:
所有可能结果,以及每个结果对应的概率。
比如情感分类:
| 类别 | 概率 |
|---|---|
| 正面 | 0.53 |
| 中性 | 0.27 |
| 负面 | 0.13 |
| 其他 | 0.07 |
这些概率通常加起来等于 1。
模型一般会选择概率最高的类别,但要注意:
概率最高,不代表一定正确。
它只是模型当前最有信心的判断。
九、分类任务中的概率
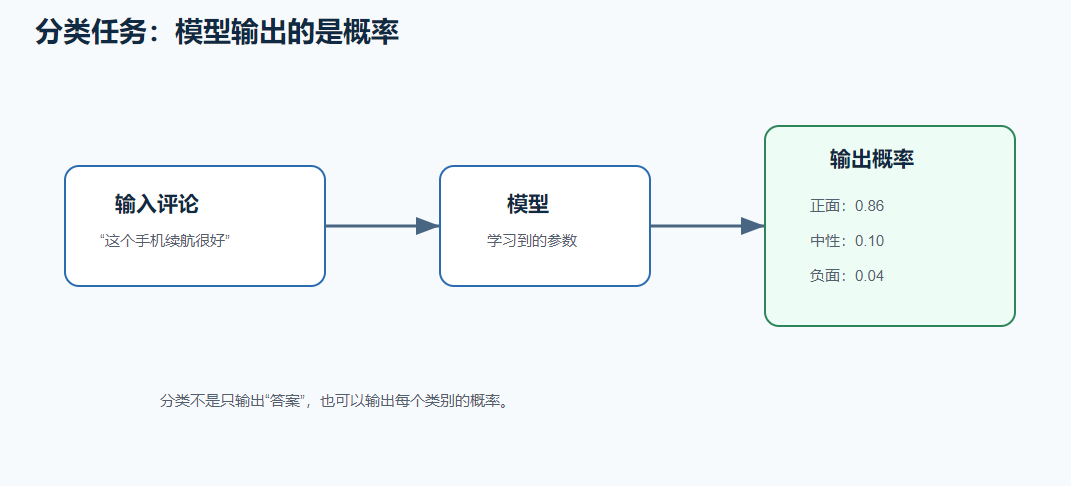
比如输入一句评论:
text
这个手机续航很好模型输出:
text
正面:0.86
中性:0.10
负面:0.04这说明模型更倾向于判断为"正面"。
但如果输入是:
text
手机还行,就是电池一般模型可能输出:
text
正面:0.35
中性:0.45
负面:0.20这时候模型其实没那么确定。
所以在真实项目中,不只是看最终类别,也会看概率高低。
例如:
text
概率 > 0.9:自动处理
0.6 < 概率 <= 0.9:正常展示
概率 <= 0.6:转人工或提示不确定这就是概率在业务里的价值。
十、大语言模型:预测下一个 token 的概率
大语言模型生成文本时,一个核心过程是:
text
根据上下文预测下一个 token 的概率分布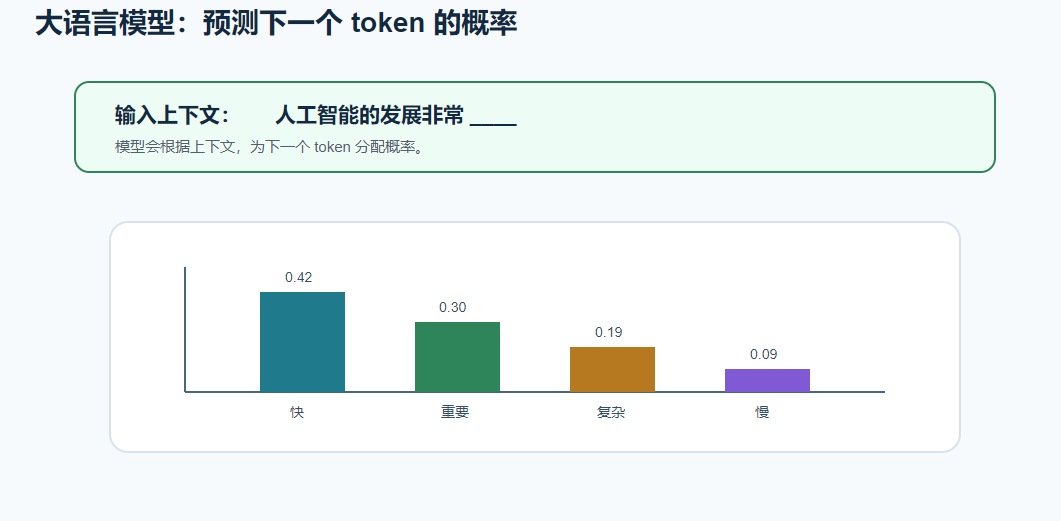
比如输入:
text
人工智能的发展非常 ____模型可能给出:
| 下一个 token | 概率 |
|---|---|
| 快 | 0.42 |
| 重要 | 0.30 |
| 复杂 | 0.19 |
| 慢 | 0.09 |
然后模型根据概率和采样策略选择一个 token。
如果选了"快",上下文变成:
text
人工智能的发展非常快然后模型继续预测下一个 token。
所以生成一段话,本质上是:
text
预测下一个 token
-> 拼到上下文后面
-> 再预测下一个 token
-> 重复很多次这也是为什么同一个问题,大模型有时回答不完全一样:
生成过程中可能存在采样,不一定每次都选择同一个 token。
十一、概率统计中的几个基础词
| 概念 | 通俗理解 | AI 中的例子 |
|---|---|---|
| 概率 | 某件事发生的可能性 | 评论是正面的概率 |
| 分布 | 多个可能结果及其概率 | 下一个 token 的概率分布 |
| 期望 | 平均意义上的结果 | 用户平均消费金额 |
| 方差 | 数据波动程度 | 用户消费是否分散 |
| 条件概率 | 已知某条件后事件发生的概率 | 已知用户点击广告后购买的概率 |
先不急着背公式,先理解它们在 AI 中解决什么问题:
text
概率:模型有多确定
分布:所有可能结果的概率
期望:平均结果
方差:波动大小
条件概率:在某个条件下发生的可能性十二、微积分与优化:模型如何变好?
线性代数告诉我们数据怎么表示。
概率统计告诉我们模型怎么表达不确定性。
微积分与优化则回答:
模型的参数为什么能一步步变好?
训练模型的目标,通常可以理解成:
text
让损失函数越来越小十三、损失函数:告诉模型错得有多远
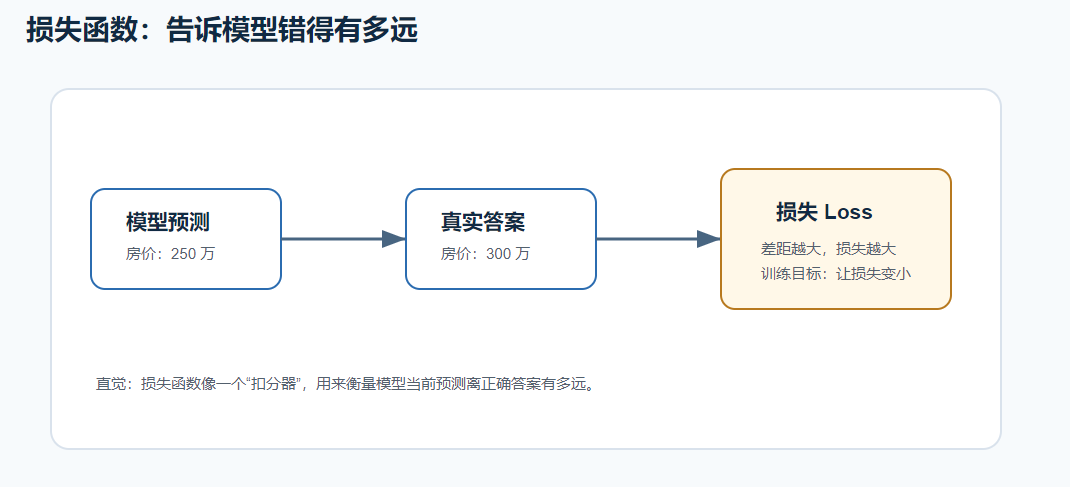
损失函数可以理解成"扣分器"。
它衡量:
text
模型预测结果 和 正确答案 差多远例如:
text
真实房价:300 万
预测房价:250 万
误差:50 万误差越大,损失越大;误差越小,损失越小。
训练目标就是:
text
让损失越来越小十四、梯度下降:沿着损失变小的方向走
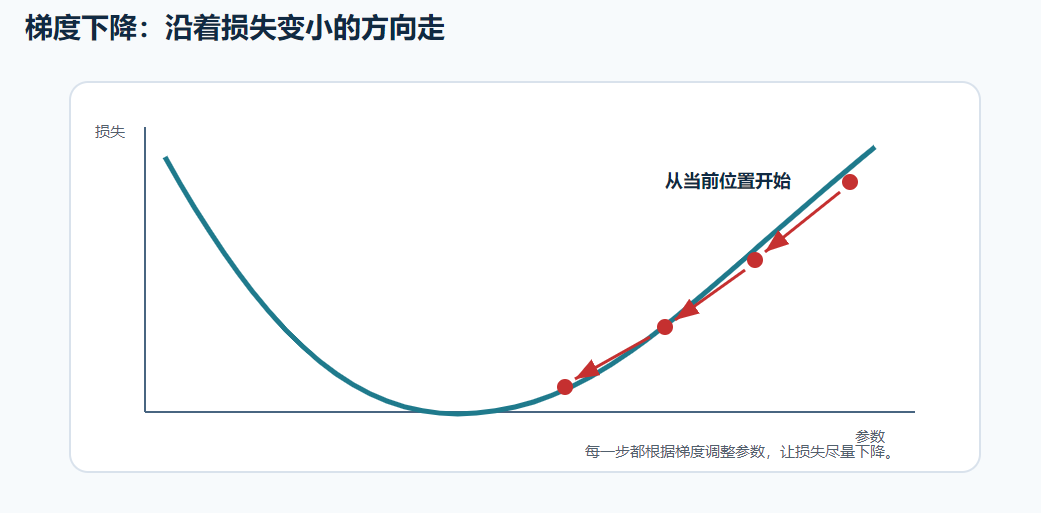
梯度可以先理解为:
参数往哪个方向调整,损失会下降得更快。
梯度下降就是:
text
沿着让损失变小的方向,一步步调整参数用下山类比:
| 下山类比 | AI 中的概念 |
|---|---|
| 山的高度 | 损失 |
| 当前位置 | 当前参数 |
| 往下走的方向 | 梯度方向 |
| 每次走多远 | 学习率 |
| 山谷 | 损失较小的位置 |
模型训练也是类似的过程:
text
当前参数
-> 计算损失
-> 计算梯度
-> 按梯度方向更新参数
-> 再计算损失
-> 重复十五、学习率:每一步走多远
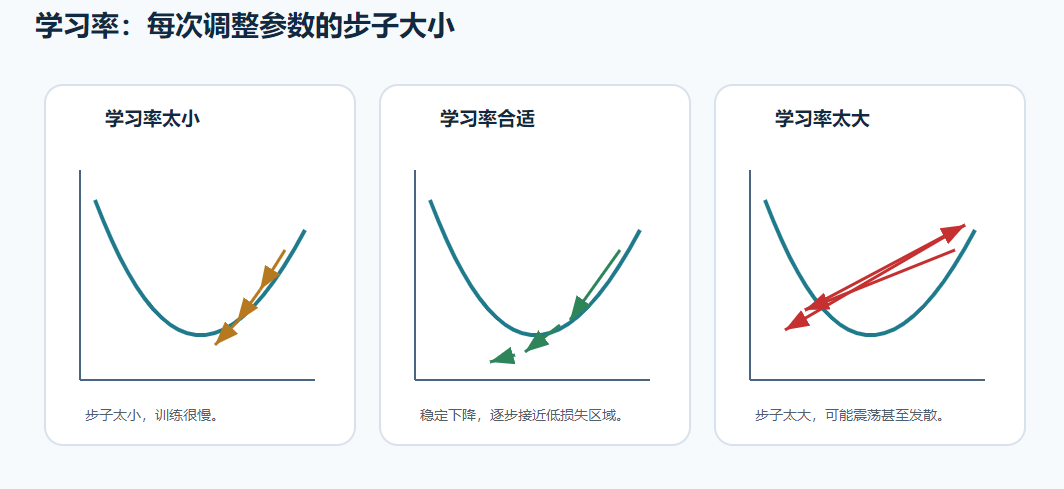
学习率控制每次更新参数的步子大小。
| 学习率 | 可能结果 |
|---|---|
| 太小 | 训练很慢 |
| 合适 | 稳定下降 |
| 太大 | 来回震荡,甚至无法收敛 |
可以理解成下山时的步长:
text
步子太小:走得很慢
步子合适:稳稳下降
步子太大:可能一步跨过山谷,在两边来回跳所以学习率是训练模型时非常重要的超参数。
十六、一个非常简化的训练例子
假设模型预测房价:
text
预测房价 = 面积 × 参数真实情况:
text
面积:100 平米
真实房价:300 万如果参数一开始是 2:
text
预测房价 = 100 × 2 = 200 万预测低了,损失较大。
模型会尝试把参数调大一些:
text
参数 2.5 -> 预测 250 万
参数 3.0 -> 预测 300 万真实模型会有成千上万甚至上亿参数,但核心思想仍然是:
text
看错多少
判断往哪改
每次改一点
重复很多次十七、面试中可以怎么回答
1. 为什么 AI 需要线性代数?
text
因为 AI 模型只能处理数字,文本、图片、音频等数据都需要转换成向量、矩阵或张量。
线性代数提供了这些数据表示和计算方式。
神经网络内部大量计算,本质上也是矩阵和张量运算。2. Embedding 是什么?
text
Embedding 是把文本、图片、用户、商品等对象转换成向量表示的方法。
向量表示之后,模型就可以计算对象之间的相似度或关系。
比如在 RAG 中,用户问题和文档片段都会被转成向量,再通过向量相似度找到相关内容。3. 概率统计在 AI 中有什么用?
text
概率统计帮助模型表达不确定性。
分类模型通常会输出每个类别的概率,大语言模型生成文本时也会预测下一个 token 的概率分布。
概率最高不代表一定正确,它只是模型当前的置信程度。4. 梯度下降在训练中做什么?
text
梯度下降是优化模型参数的方法。
损失函数衡量模型预测和真实答案的差距,梯度告诉参数应该往哪个方向调整能让损失下降。
模型通过不断计算损失、计算梯度、更新参数,让损失逐渐变小。5. 为什么 GPU 适合 AI?
text
AI 训练和推理中有大量矩阵和张量计算。
GPU 擅长大规模并行计算,所以相比 CPU 更适合处理深度学习中的矩阵运算。十八、常见误区
| 误区 | 更准确的理解 |
|---|---|
| 数学只是考试用 | 数学帮助理解 AI 的数据表示、预测和优化 |
| 文本不能变成数字 | 文本可以通过 Embedding 变成向量 |
| 张量很神秘 | 张量就是多维数组 |
| GPU 是因为更高级才快 | GPU 快在擅长大规模并行矩阵计算 |
| 概率最高就一定正确 | 概率只是模型置信度,仍可能判断错误 |
| LLM 是直接查答案 | LLM 会不断预测下一个 token 的概率分布 |
| 梯度下降是随便改参数 | 梯度下降是沿着让损失变小的方向调整参数 |
| 学习率越大越好 | 学习率太大可能震荡或发散 |
十九、自测题
题目
Q1. 线性代数在 AI 中最核心的作用之一是什么?
A. 删除模型参数
B. 帮助表示和计算数据,比如向量、矩阵、张量
C. 只负责网页排版
D. 替代所有训练数据
Q2. 向量更接近下面哪种理解?
A. 一张图片文件
B. 一个数字
C. 一串数字
D. 一个网页链接
Q3. Embedding 的作用是什么?
A. 删除文本
B. 压缩硬盘
C. 关闭模型
D. 把对象表示成向量
Q4. "怎么申请退款"和"订单怎么退货"在向量空间里通常应该怎样?
A. 不能表示成向量
B. 语义接近,向量距离相对更近
C. 必须变成图片才能比较
D. 完全无关,向量一定最远
Q5. 概率统计在 AI 中的重要作用是什么?
A. 只负责网页排版
B. 帮助模型表达不确定性和预测可能性
C. 删除训练数据
D. 替代所有向量计算
Q6. 大语言模型生成文本时,一个核心过程是什么?
A. 删除所有 token
B. 只查数据库
C. 固定复制训练数据
D. 根据上下文预测下一个 token 的概率分布
Q7. 方差更接近下面哪种理解?
A. 数据的平均水平
B. 数据的波动程度
C. 数据文件的大小
D. 数据库的密码
Q8. 损失函数主要用来做什么?
A. 衡量模型预测和正确答案之间的差距
B. 删除训练数据
C. 管理浏览器缓存
D. 替代 Python 解释器
Q9. 梯度下降更接近下面哪种说法?
A. 随机删除模型参数
B. 沿着让损失变小的方向,一步步调整参数
C. 把数据转成图片
D. 只运行一次模型,不做更新
Q10. 学习率太大可能导致什么?
A. 模型一定训练得更好
B. 训练震荡,甚至无法收敛
C. 损失函数自动消失
D. 不需要训练数据
答案与解析
| 题号 | 答案 | 解析 |
|---|---|---|
| Q1 | B | AI 数据通常需要表示成向量、矩阵、张量,线性代数是这些表示和计算的基础。 |
| Q2 | C | 向量可以理解成一串数字。 |
| Q3 | D | Embedding 是把文本、图片、用户、商品等对象表示成向量。 |
| Q4 | B | 语义接近的文本,在向量空间中通常距离更近。 |
| Q5 | B | 概率统计帮助模型表达不确定性。 |
| Q6 | D | 大语言模型生成文本时,会不断预测下一个 token 的概率分布。 |
| Q7 | B | 方差表示数据波动程度。 |
| Q8 | A | 损失函数衡量预测和正确答案之间的差距。 |
| Q9 | B | 梯度下降是沿着让损失变小的方向逐步调整参数。 |
| Q10 | B | 学习率太大可能导致震荡,甚至无法收敛。 |
二十、本篇小结
这篇文章用 AI 应用视角梳理了数学基础。
可以记住这几句话:
- 线性代数是 AI 的数据表示语言。
- 标量是一个数字,向量是一串数字,矩阵是二维表,张量是多维数组。
- Embedding 是把对象表示成向量,方便计算相似度。
- 图片可以表示成矩阵或张量。
- 神经网络内部大量计算是矩阵和张量运算。
- 概率统计帮助模型表达不确定性。
- 大语言模型生成文本时,会预测下一个 token 的概率分布。
- 损失函数衡量模型错得有多远。
- 梯度下降沿着让损失变小的方向更新参数。
- 学习率控制每次参数更新的步子大小。
二十一、下一篇预告
下一篇进入机器学习:
AI 学习路线 04:机器学习到底在学什么?从分类、回归到模型评估
会重点讲:
- 监督学习、无监督学习、强化学习
- 训练集、验证集、测试集
- 过拟合、欠拟合、泛化能力
- 回归、分类、聚类
- 常见机器学习算法和评估指标