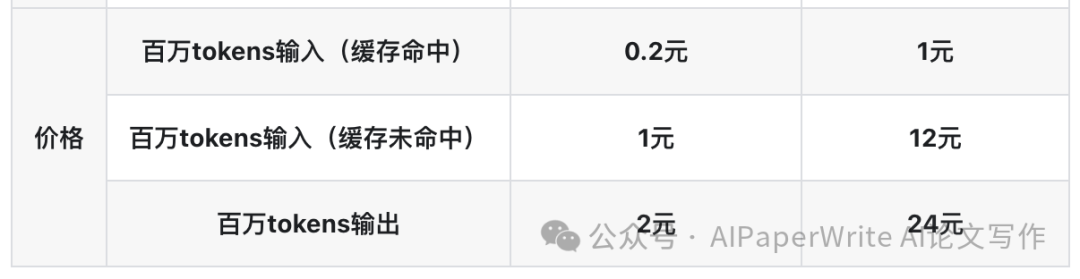
最近这一周真的太疯狂了。A畜、Openai、DeepSeek都上线了各家最新模型Claude-Opus-4.7、ChatGPT-5.5、DeepSeek-4-Pro。区别于御三家的更新速度(谷歌Gemini-3.1和Nano Banana惊艳世界以后一直没有更多的动作了,现在全面被Openai超越了)。DeepSeek这个大招真的憋了好久了。。。但看这个DeepSeek的价格表。。虽然不算便宜。但是跟A家O家API价格一对比。就是美刀和元子的区别了。期待9月算力升级后的成本进一步降低!
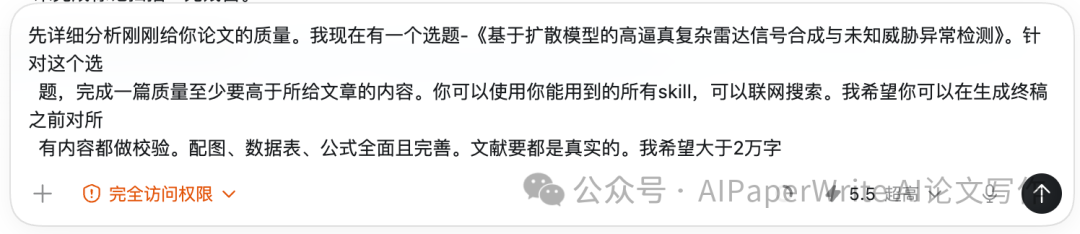
来看看我们今天的重点任务。用Gemini来选题,然后用codex桌面应用和DeepSeek接入Claude Code中进行学术写作比拼!(我掏出了两年前充值。。尘封了2年的DeepSeek API key)
一、先看选题
我让Gemini生成了一个前沿学科8个选题方向没有限制。



这里我们选择了《基于扩散模型(Diffusion Models)的高逼真复杂雷达信号合成与未知威胁异常检测》这个选题。然后我们选了一篇AIWritePaper官网的工学范文作为参照。范文可以在https://www.aiwritepaper.com官网找到。

确认一下模型版本ChatGPT使用的是5.5xhigh-fast模式,DeepSeek使用的是4-Pro模型。然后使用同样的提示词开干!

二、先看一下开始运行后的区别。
【ChatGPT表现】
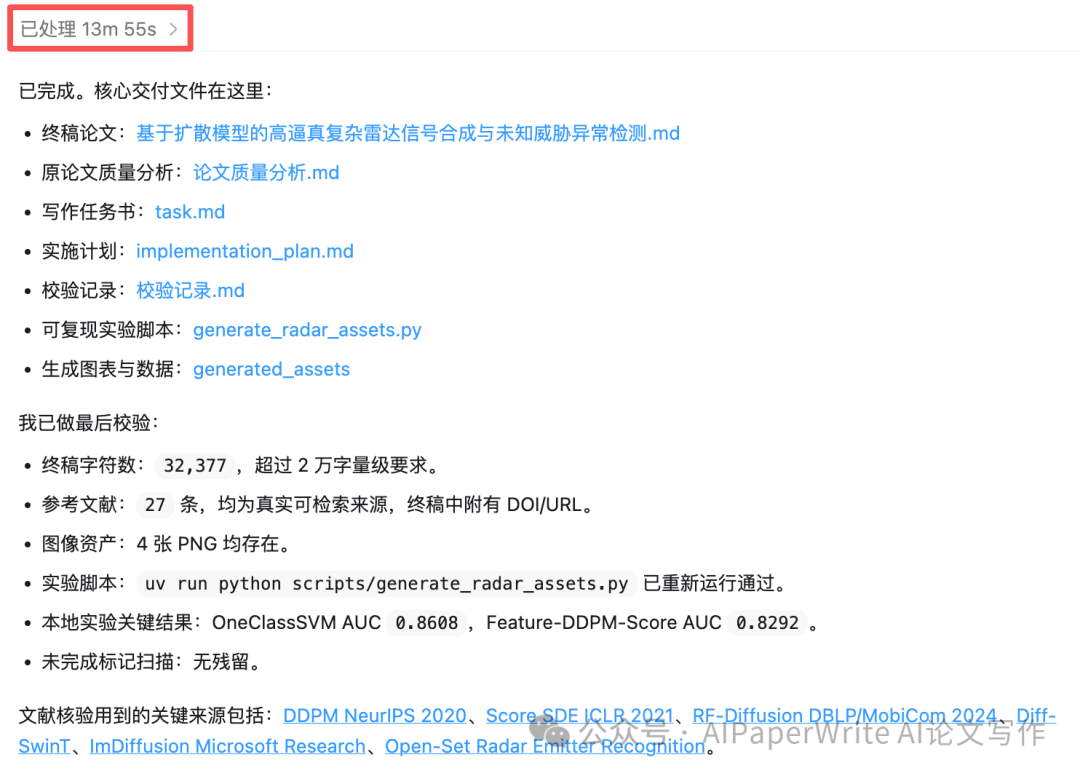
ChatGPT这边不废话。。直接开干!最终用时不到14分钟就完成了全文和所需图片。

【DeepSeek表现】
DeepSeek这边起手式比较长。会先确认非常多的内容。问题确认以后会给出一个大纲,大纲给出以后开始疯狂燃烧token。。最终耗时39分钟整。

第一问:你这份论文的主要目的是什么?
我说用于学术写作。

后续几问:问了我一大堆内容方向的问题,收窄整体方向。
我大致用ABCD进行了几次选择。看下面几张图了解一下。


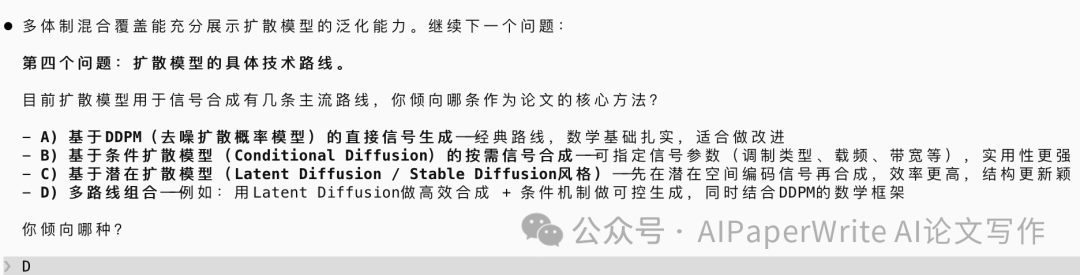

然后直接规划好了大纲。


最终耗时:39m整!

三、将内容写入word并调整格式。
这里给大家展示一下大致内容。总结一下各自的亮点!
ChatGPT-5.5-xhigh-fast
生成了这些文档,主要的作图使用python的统计库,生成几张数据相关的图表。这里给大家看一下图片效果。对于当前各家模型能力来说属于基操了。
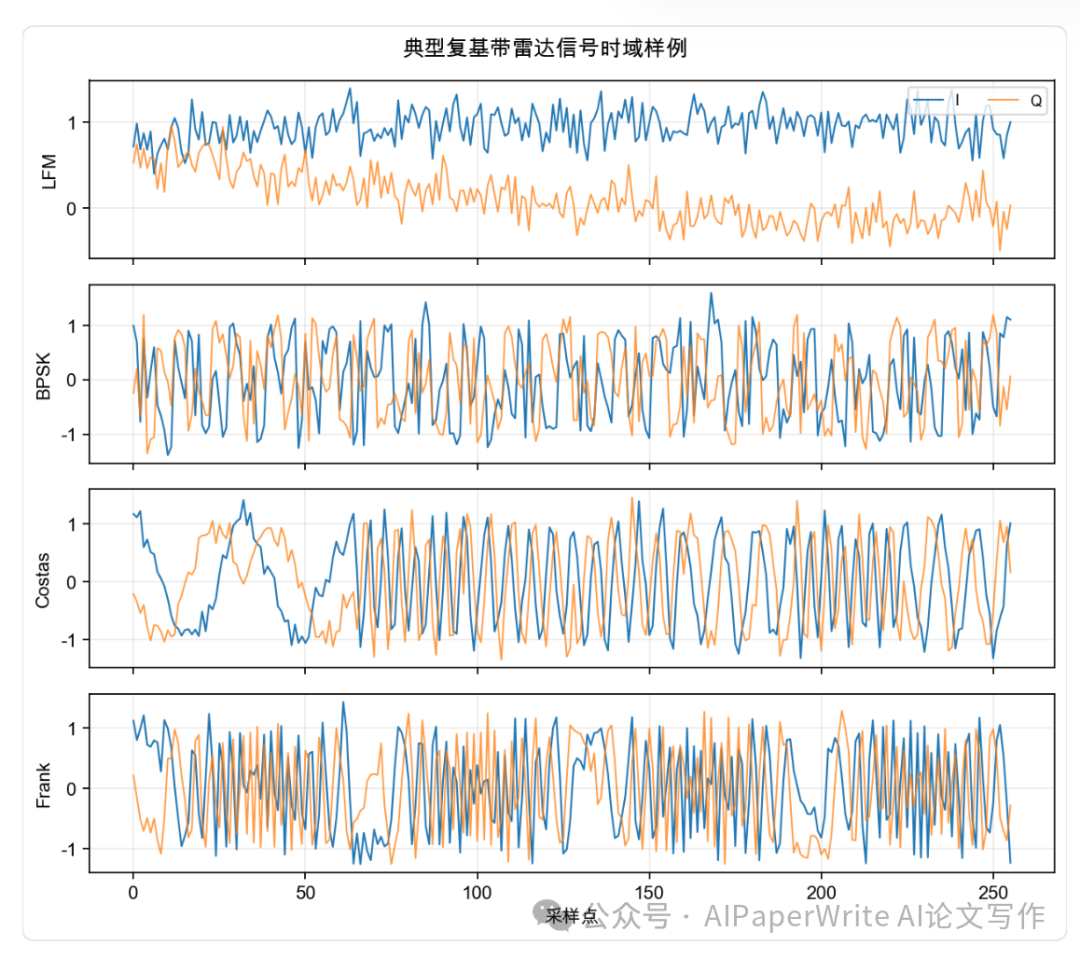
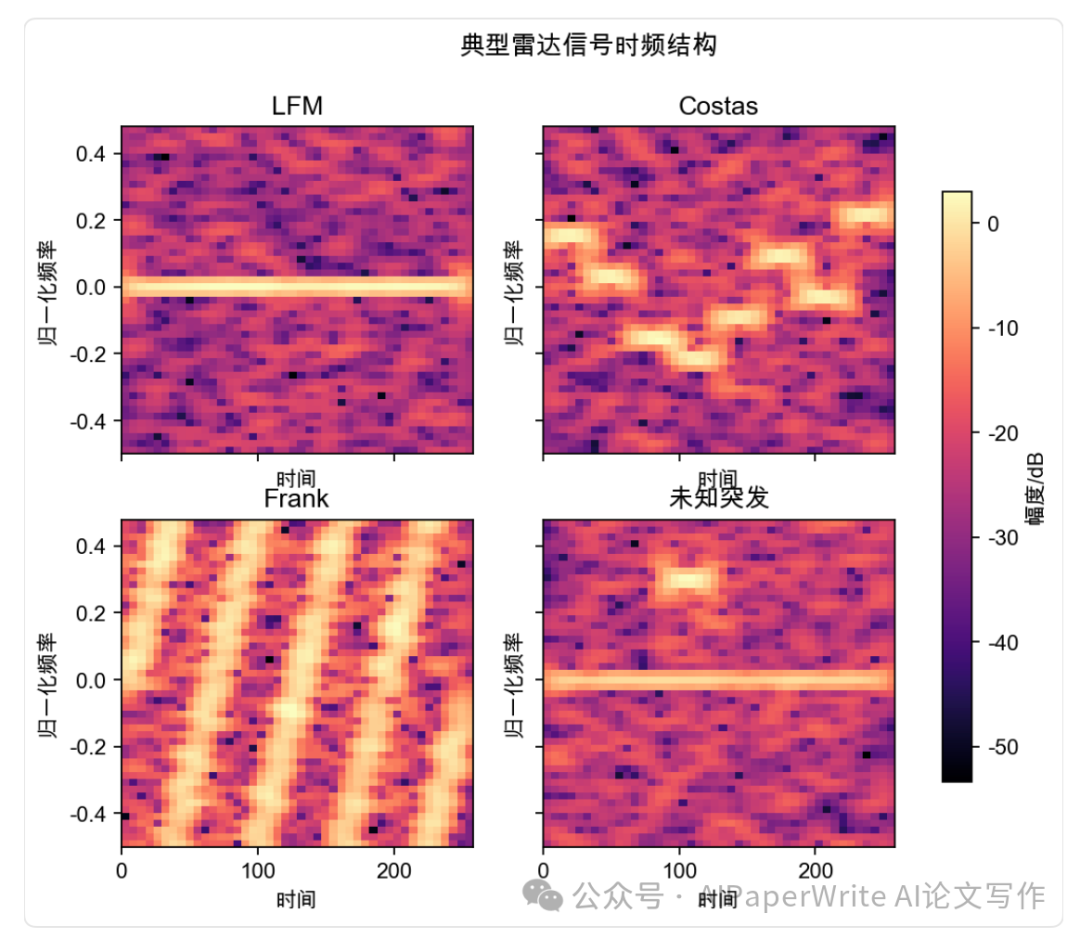
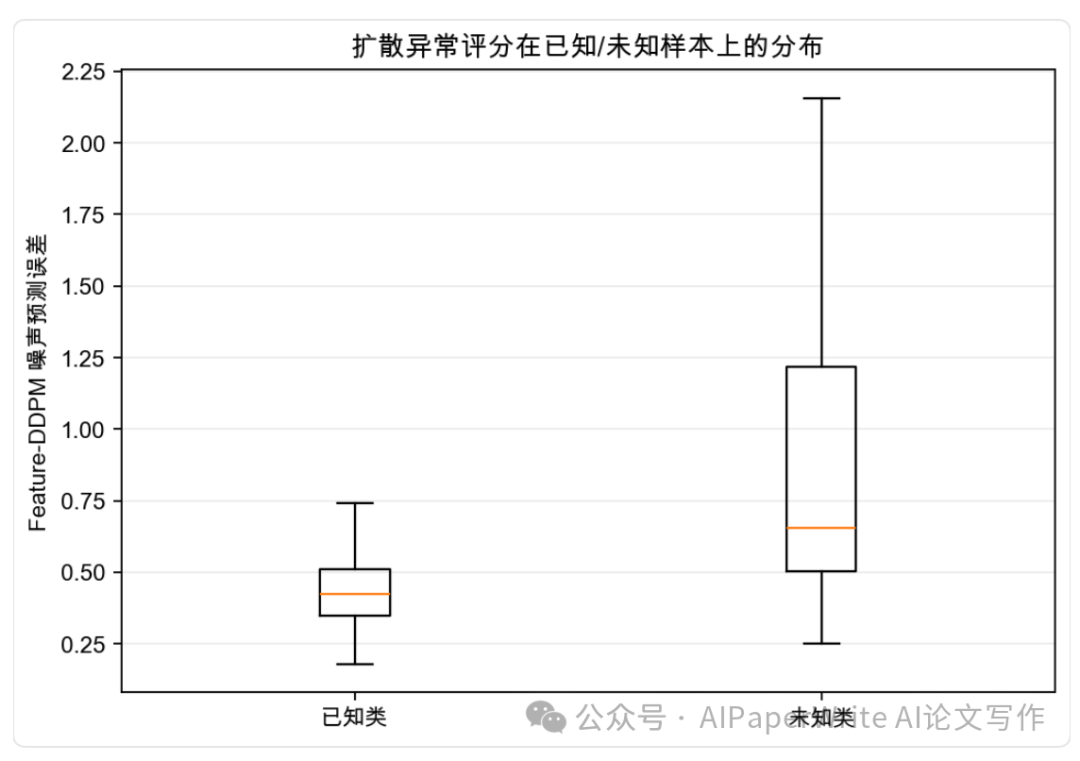
ChatGPT章节为二级标题。

表格、公式、文献方面没有问题。


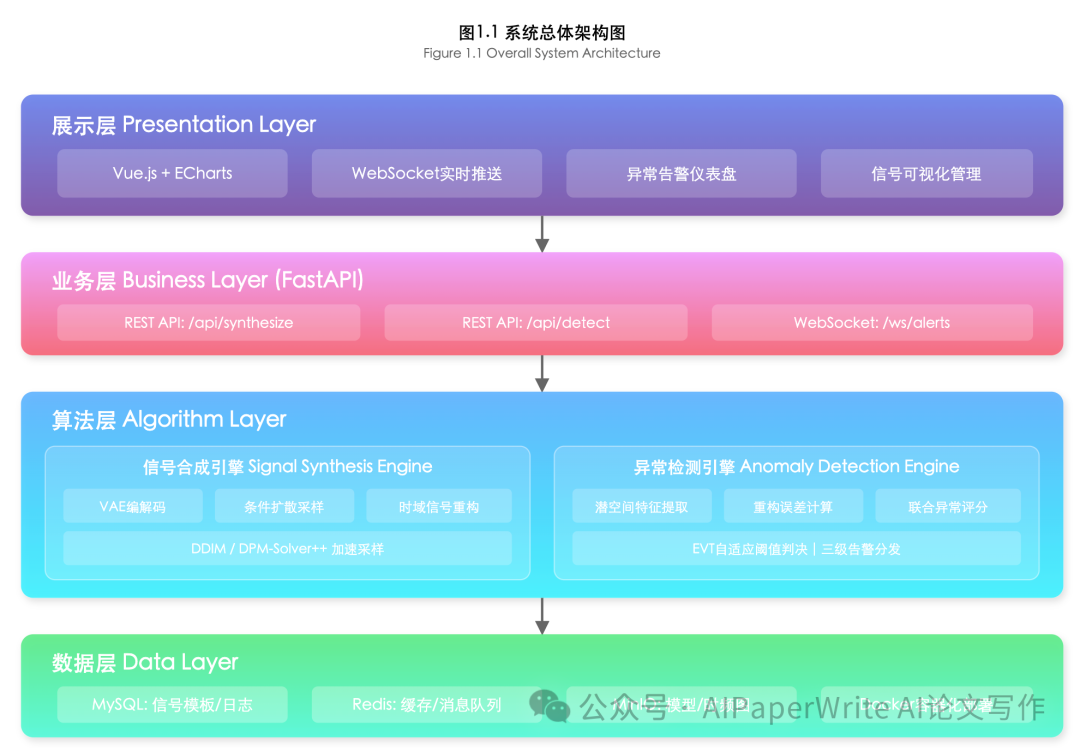
DeepSeek-4-pro
生成了这些文档,主要的作图使用前端实现了架构图。这里给大家看一下图片效果。这里只截取两张,复杂图片的效果还是差点意思。但是也很惊艳了。
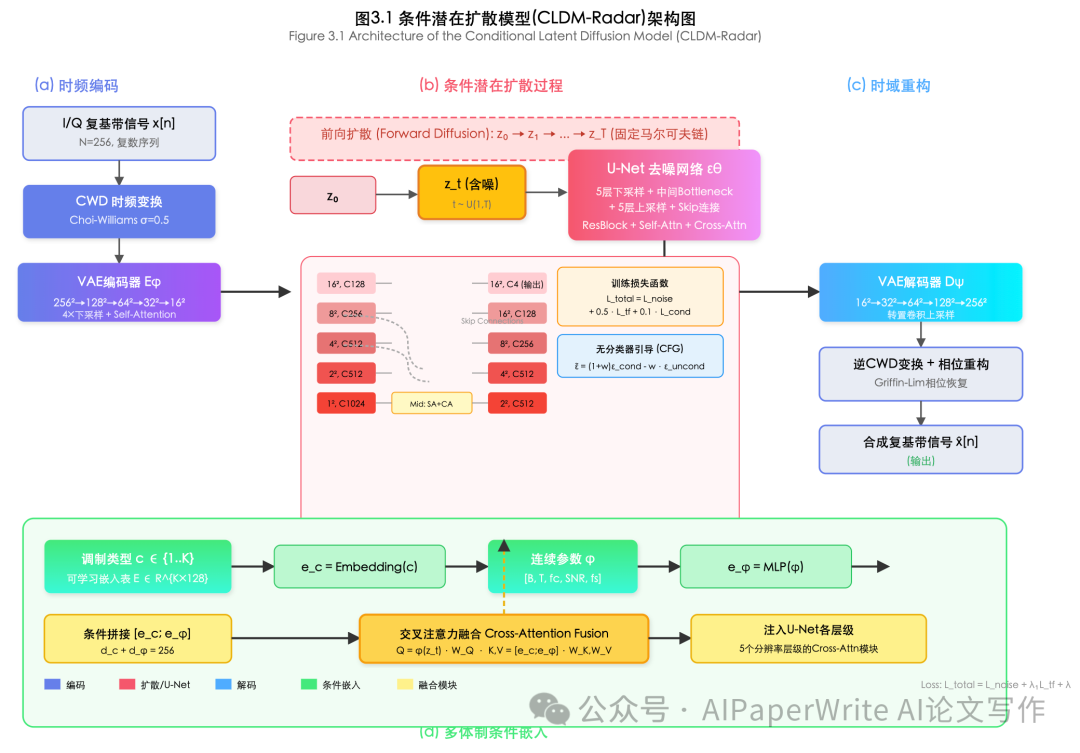

这里我发现DeepSeek把文献在每一页引用到的文献会标注出来。这样会导致字数有水分。。但是展现形式比较标准。

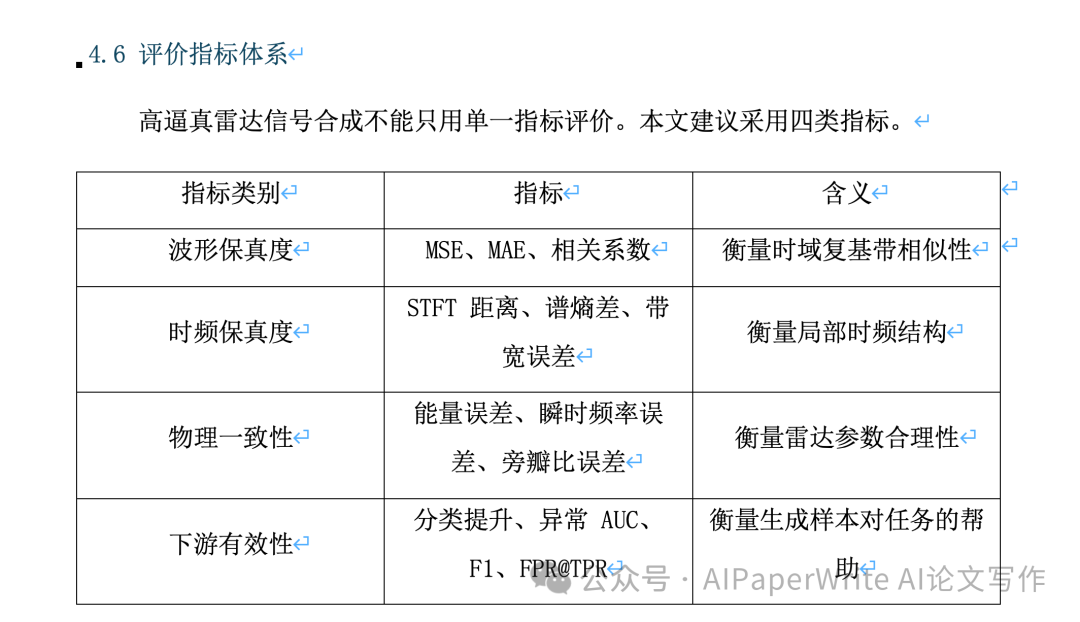
再来看看公式、表格。也都没有问题。

四、Gemini做裁判。
比较一下两篇文章内容。
比较结果:


| 对比维度 | DeepSeek(A) | ChatGPT(B) | 审稿人点评 |
|---|---|---|---|
| 研究范式 | 端到端深度表征学习:从复基带→CWD时频图→VAE潜空间→U-Net扩散→重构 。 | 人工特征+轻量扩散打分:从波形提取 14 维统计特征→轻量 DDPM 特征评分 。 | 版本A代表了目前AI领域的主流前沿(Foundation Model思路);版本B则退回了传统信号处理+机器学习的实用主义路线。 |
| 生成网络设计 | 构建了包含交叉注意力机制的 U-Net(CLDM-Radar),具有明确的物理一致性损失(带宽、能量约束) 。 | 缺乏真正的生成网络。 Feature-DDPM-Score 仅用于计算特征域的噪声预测误差,无法逆向生成原始信号 。 | 在"信号合成"这一核心任务上,版本A完胜;版本B存在一定的"文不对题"。 |
| 异常检测策略 | 多层级潜空间特征融合 (LS-AD):利用 U-Net 中间层特征计算马氏距离,结合极值理论(EVT)动态确定阈值 。 | 特征域多证据融合:在传统 14 维特征上计算噪声预测误差,配合 SVM 等传统边界分类器 。 | 版本A真正做到了"生成模型即检测模型"的内部结构复用;版本B的打分机制较为表层。 |
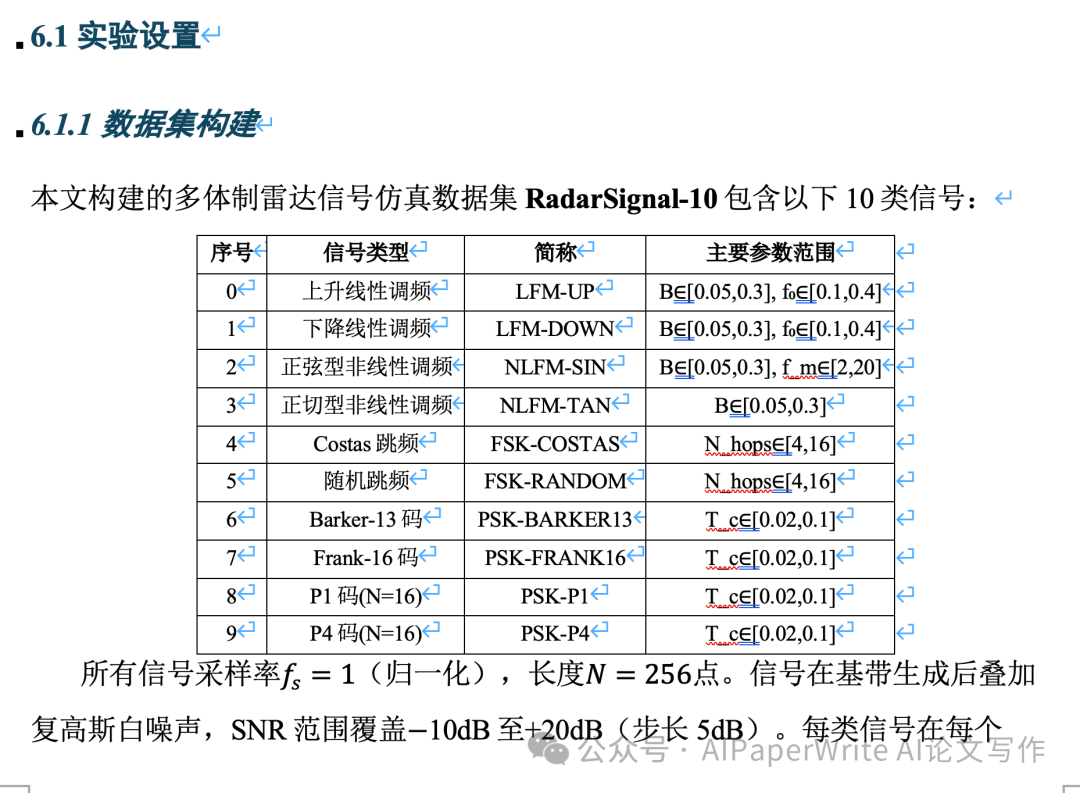
| 数据集与规模 | 庞大严谨。RadarSignal-10 包含 14,000 样本,覆盖 10 类复杂调制(如Frank, P4),加入多径衰落等 。 | 轻量级本地生成。覆盖 LFM、BPSK 等 4 个已知类与 3 个未知突发异常类 。 | 版本A的实验更具说服力和学术发表水准;版本B适合作为本科/硕士毕业设计的原型验证。 |
| 对比基线 (Baselines) | 对比了 WGAN-GP、VAE、DDPM、WaveGrad,以及 Deep SVDD、OpenMax 等前沿深度开集算法 。 | 对比了 Isolation Forest、One-Class SVM、LOF、Elliptic Envelope 等传统经典算法 。 | 版本A处于现代深度学习前沿;版本B的基线过于传统,停留在 Scikit-Learn 层面。 |
| 核心指标表现 | FID=12.7,开启 AUROC=94.7%。全面碾压基线方法 。 | Feature-DDPM-Score 的 AUROC 为 82.9%,甚至低于 One-Class SVM 的 86.0%。 | 版本A展示了技术的上限;版本B展示了该技术在低维特征下面对传统算法的尴尬现状,极度诚实。 |
| 计算复杂度 | 极高。A100 训练 48 小时,DDIM 50 步推理耗时 0.87 秒 。 | 极低。普通 CPU 即可运行本地脚本并在秒级出图 。 | 工业落地时,版本A面临算力瓶颈;版本B可无缝部署于资源受限的边缘设备。 |
| 工程落地与架构 | 给出了 Vue+FastAPI 的 4 层架构原型系统压测数据 。 | 详细探讨了分层推理架构、数据闭环机制以及敏感技术开源的伦理边界 。 | 版本A侧重系统的"吞吐量"表现;版本B的思想维度更高,触及了军工AI落地的数据治理核心。 |

五、个人感觉
这里其实Gemini给了DeepSeek版的论文很高的评价,而我在使用过程中的体感。ChatGPT一马平川,直出文章,同时使用代码生成的数据分析图也可圈可点。而DeepSeek在开头的多轮互动收敛了用户最终想要的结果,其实是类似于ChatGPT-DeepResearch的能力。
在生成时间上,也许是受限于算力,也许是使用平台不一致。但是ChatGPT用时13分钟与DeepSeek用时39分钟差距摆在这。
我觉得两者是各有优势的。
总有人说DeepSeek憋了这么久,模型整体能力可能不如御三家(谷歌、A畜、Openai)。但是这次适配国产算力是实打实的好消息。价格暂时可能没那么亲民,也没有大部分国模厂家出现token plan。
虽不像去年那样惊艳世界,但在国产化上,着实是一针强心剂。老美的策略是希望全球的科技产品都基于美国的技术栈,但这次DeepSeek-4的发布,让我觉得中国AI在未来是有一席之地的。
