Embedding 和向量数据库:让机器真正"理解"语义
传统搜索匹配关键词,向量搜索匹配"意思"。当你问"怎么让电脑跑更快",它能找到"提升计算机性能的方法"------尽管两个句子没有一个词相同。这就是 Embedding 的魔法。
从一个尴尬的场景说起
你在自己的笔记里搜"编程":
搜索: "编程"
结果:
✅ "编程入门指南.txt"
✅ "编程语言对比.md"
✅ "Python 编程技巧.doc"
❌ "写代码的艺术.pdf" ← 没有"编程"两个字,搜不到
❌ "软件开发实践.md" ← 同样搜不到这就是关键词搜索的局限------它只匹配字符串,不理解语义。
但如果用 Embedding:
搜索: "编程"
结果:
✅ "编程入门指南.txt" 0.95
✅ "Python 编程技巧.doc" 0.92
✅ "写代码的艺术.pdf" 0.88 ← 语义匹配!
✅ "软件开发实践.md" 0.85 ← 语义匹配!
✅ "编程语言对比.md" 0.82Embedding 的核心能力:把"意思相近"的文字映射到"距离相近"的数学空间。
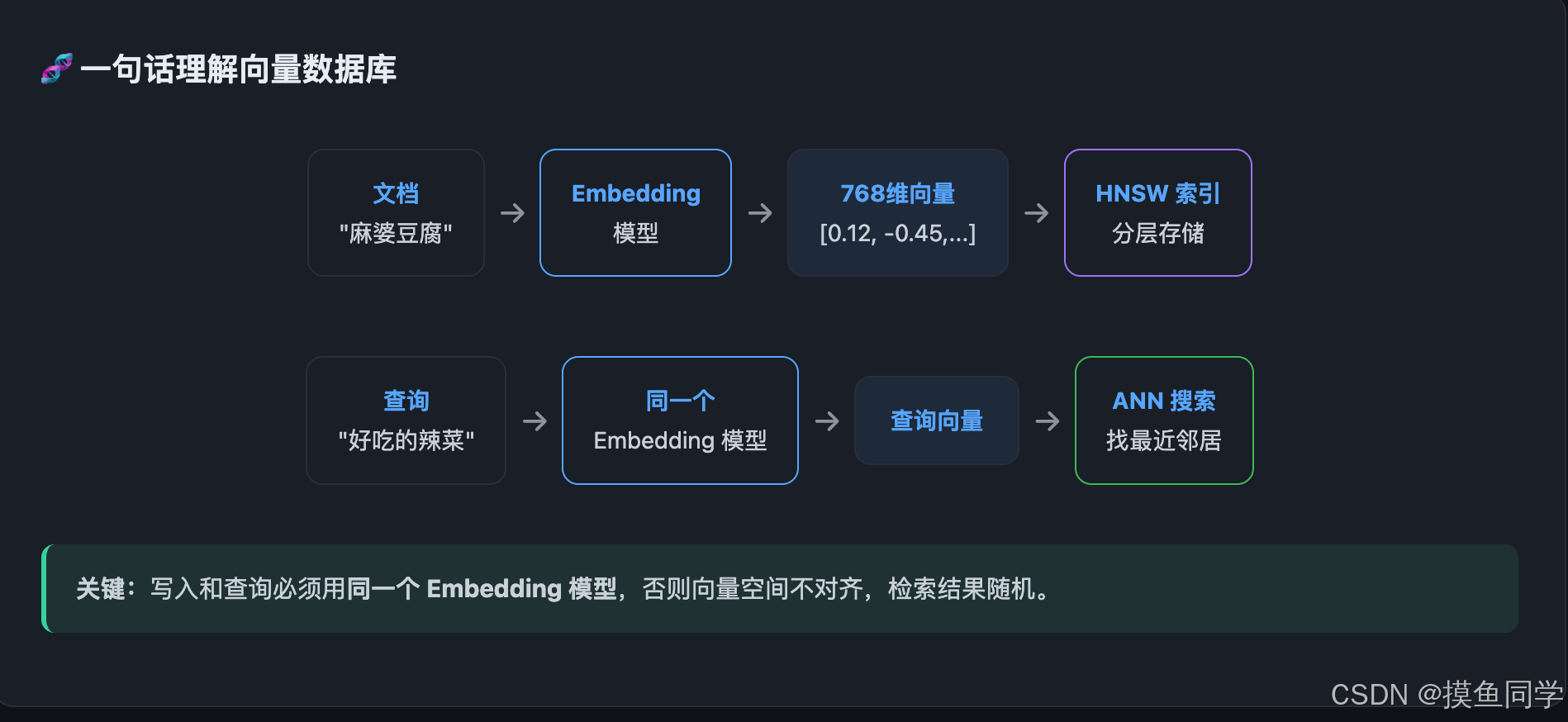
Embedding 到底是什么
一句话解释
Embedding = 把文字变成一串数字(向量),这串数字编码了文字的语义信息。
"猫" → [0.12, -0.34, 0.56, ..., 0.78] (768 个数字)
"猫咪" → [0.13, -0.32, 0.55, ..., 0.77] (和"猫"很接近)
"狗" → [0.11, -0.30, 0.40, ..., 0.60] (和"猫"有些距离)
"汽车" → [-0.45, 0.67, -0.23, ..., 0.12] (和"猫"距离很远)在 768 维空间中:
语义相近 = 向量距离近(余弦相似度接近 1)
语义无关 = 向量距离远(余弦相似度接近 0)
语义相反 = 向量方向相反(余弦相似度接近 -1)直观类比
把 Embedding 想象成给每段文字在地图上找一个坐标:
"汽车" ●
\
\
"猫" ● \ "钢琴" ●
"猫咪" ● \
\
"狗" ● \ "吉他" ●
\
\
"小提琴" ●- 猫和猫咪紧挨着(同义词)
- 猫和狗有一定距离但还在同一区域(都是宠物)
- 猫和汽车隔很远(语义无关)
- 钢琴、吉他、小提琴聚在一起(都是乐器)
这就是 Embedding 在做的事情------语义相近的文字,在高维空间里距离相近。
实战:三行代码生成 Embedding
python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2') # 轻量模型,免费本地跑
# 三行代码得到向量
texts = ["猫", "猫咪", "狗", "汽车"]
embeddings = model.encode(texts)
print(embeddings.shape) # (4, 384) --- 4 段文字,每段 384 个数字计算相似度:
python
from sklearn.metrics.pairwise import cosine_similarity
sim = cosine_similarity([embeddings[0]], [embeddings[1]])[0][0]
print(f'"猫" 和 "猫咪" 的相似度: {sim:.3f}') # → 0.892
sim = cosine_similarity([embeddings[0]], [embeddings[2]])[0][0]
print(f'"猫" 和 "狗" 的相似度: {sim:.3f}') # → 0.621
sim = cosine_similarity([embeddings[0]], [embeddings[3]])[0][0]
print(f'"猫" 和 "汽车" 的相似度: {sim:.3f}') # → 0.187不需要 GPU,不需要 API Key,本地就能跑。 就这么简单。
Embedding 的三大应用场景
场景 1:语义搜索
传统搜索:
用户输入 "怎么让程序跑更快"
→ 匹配包含 "程序" "更快" 的文档
→ 漏掉 "Python 性能优化指南"(没有 "程序" 也没有 "更快")
Embedding 搜索:
用户输入 "怎么让程序跑更快"
→ 将问题和所有文档都转成向量
→ 找向量距离最近的文档
→ 命中 "Python 性能优化指南" ✅这就是 RAG(检索增强生成)的基础------我们下篇会详细讲。
python
# 最简语义搜索实现
def semantic_search(query: str, documents: list[str], top_k: int = 3):
# 1. 把所有文档和查询都转成向量
doc_embeddings = model.encode(documents)
query_embedding = model.encode([query])
# 2. 计算相似度
similarities = cosine_similarity(query_embedding, doc_embeddings)[0]
# 3. 排序返回 top-k
ranked = sorted(
zip(documents, similarities),
key=lambda x: x[1],
reverse=True
)
return ranked[:top_k]场景 2:文本聚类
有了向量,你可以把大量文本自动分组------不需要人工打标签:
python
from sklearn.cluster import KMeans
# 把 1000 篇文档聚成 5 类
embeddings = model.encode(documents) # 1. 全部向量化
clusters = KMeans(n_clusters=5).fit_predict(embeddings) # 2. 聚类
# 每类的主题自动浮现
for i in range(5):
docs_in_cluster = [doc for j, doc in enumerate(documents) if clusters[j] == i]
print(f"类别 {i}: {docs_in_cluster[:3]}...")场景 3:推荐系统
"看了这篇文章的人还看了..."------不需要用户行为数据,纯靠内容相似度:
python
def recommend(current_article: str, candidates: list[str], top_k: int = 5):
current_vec = model.encode([current_article])
candidate_vecs = model.encode(candidates)
sims = cosine_similarity(current_vec, candidate_vecs)[0]
return [candidates[i] for i in sims.argsort()[-top_k:][::-1]]向量数据库:让 Embedding 可生产化
什么时候需要向量数据库
100 条数据 → NumPy 数组就行
10,000 条数据 → 还能用 NumPy,但开始慢了
100,000 条数据 → 需要向量数据库
1,000,000+ 条数据 → 必须用向量数据库向量数据库解决了三个 NumPy 搞不定的问题:
| 问题 | NumPy | 向量数据库 |
|---|---|---|
| 精确搜索速度(100万条) | 几秒 | 几毫秒 |
| 近似搜索 | 不支持 | 支持 ANN(近似最近邻) |
| 持久化 | 手工存文件 | 自动持久化 |
| 元数据过滤 | 手工 join | 内置("搜科技类文章中的...") |
| 增量更新 | 整个重建 | 支持增删改 |
ChromaDB 入门(5 分钟上手)
ChromaDB 是目前最轻量的向量数据库,Python 直接安装:
bash
pip install chromadb
python
import chromadb
# 1. 创建客户端(数据存本地)
client = chromadb.PersistentClient(path="./my_db")
# 2. 创建或获取集合
collection = client.get_or_create_collection(
name="my_notes",
metadata={"description": "我的学习笔记"}
)
# 3. 添加文档(自动 Embedding + 存储)
collection.add(
documents=[
"Python 装饰器是一种特殊的函数,用于修改其他函数的行为",
"FastAPI 基于 Starlette,支持异步处理和自动 API 文档生成",
"今天天气很好,适合出去跑步",
],
metadatas=[
{"topic": "python", "type": "note"},
{"topic": "python", "type": "note"},
{"topic": "life", "type": "diary"},
],
ids=["note_1", "note_2", "diary_1"],
)
# 4. 语义搜索
results = collection.query(
query_texts=["怎么修改函数的行为"],
n_results=2,
)
print(results["documents"]) # 第一个就是 "Python 装饰器..."
# 5. 带过滤的搜索
results = collection.query(
query_texts=["编程相关"],
where={"topic": "python"}, # 只搜 python 主题
n_results=5,
)ChromaDB 自动帮你做 Embedding,不需要手动调模型。 这在原型阶段非常方便。
Embedding 模型选型
| 模型 | 维度 | 速度 | 中文 | 适用场景 |
|---|---|---|---|---|
| all-MiniLM-L6-v2 | 384 | 极快 | 一般 | 英文为主,轻量部署 |
| text2vec-base-chinese | 768 | 快 | 好 | 中文语义搜索 |
| BGE-large-zh | 1024 | 中 | 很好 | 中文,精度优先 |
| OpenAI text-embedding-3 | 256-3072 | N/A (API) | 很好 | 省心,需要 API Key |
| Cohere embed-v3 | 1024 | N/A (API) | 好 | 多语言支持好 |
选择原则:
- 本地跑 → BGE-large-zh(中文)/ all-MiniLM(英文)
- 省心 → OpenAI text-embedding-3-small(便宜且够用)
- 生产环境 → 在目标数据集上做精度 Benchmark,不要只看排行榜
一个常见坑:Embedding 模型和生成模型不是一回事
很多初学者会搞混:
❌ 错误理解:
"我用 GPT-4 生成 Embedding"
✅ 正确理解:
Embedding 模型(如 BGE、text-embedding-3)→ 把文字变成向量
生成模型(如 GPT-4、Claude)→ 把文字变成另一段文字
它们是不同的模型,做不同的事。虽然有些生成模型能输出 Embedding(如 OpenAI 的 text-embedding-3),但它和 GPT-4 是完全不同的模型。
总结
Embedding 和向量数据库的"最小必要知识":
- Embedding = 把语义映射到向量空间 ------ 意思相近,距离相近
- 三行代码就能跑 ------
SentenceTransformer本地免费,不需要 GPU - 向量数据库 = Embedding 的生产化工具 ------ ChromaDB 5 分钟上手
- 选对模型很重要 ------ 中文用 BGE-large-zh,省心用 OpenAI API
- Embedding 是 RAG 的基础 ------ 下一篇的主角
有条件的同学可以去 github.com/barryness/cc-ai-learning 跑跑 003-embedding-learning 和 004-vector-db-learning 的 Demo,真实代码跑一遍比看什么都管用。