文章目录
- 一、基础用法
-
- [1. 简述 SharedPreferences 整体使用流程,以及 apply 与 commit 核心区别和适用场景](#1. 简述 SharedPreferences 整体使用流程,以及 apply 与 commit 核心区别和适用场景)
- [2. 讲下 MMKV 的初始化、常规存取使用流程,日常开发基础使用有哪些注意点](#2. 讲下 MMKV 的初始化、常规存取使用流程,日常开发基础使用有哪些注意点)
- [3. 原生 SQLite 结合 SQLiteOpenHelper 的完整使用流程是什么,事务基础如何使用](#3. 原生 SQLite 结合 SQLiteOpenHelper 的完整使用流程是什么,事务基础如何使用)
- [4. 说明 Room 核心组件与整体使用流程,以及常规增删改查的基础使用方式](#4. 说明 Room 核心组件与整体使用流程,以及常规增删改查的基础使用方式)
- 二、选型对比
-
- [5. 键值存储和关系型数据库各自有什么短板,为什么业务中不能只用一种存储方案](#5. 键值存储和关系型数据库各自有什么短板,为什么业务中不能只用一种存储方案)
- [6. 实际开发中,你如何划分 MMKV 与 Room 的使用边界,阐述判断逻辑](#6. 实际开发中,你如何划分 MMKV 与 Room 的使用边界,阐述判断逻辑)
- [7. SP, MMKV, SQLITE, ROOM 数据库对比](#7. SP, MMKV, SQLITE, ROOM 数据库对比)
- [三、实战场景 & 业务落地](#三、实战场景 & 业务落地)
-
- [8. 项目中频繁读写配置、埋点临时数据,容易出现卡顿、ANR,根源是什么,怎么解决?](#8. 项目中频繁读写配置、埋点临时数据,容易出现卡顿、ANR,根源是什么,怎么解决?)
- [9. 需要本地缓存大量结构化列表数据,例如聊天记录、离线内容,用 Room 开发要注意什么?](#9. 需要本地缓存大量结构化列表数据,例如聊天记录、离线内容,用 Room 开发要注意什么?)
- [10. 业务迭代需要给数据库表新增字段、修改结构,Room 如何安全做版本迁移,实战怎么做兜底?](#10. 业务迭代需要给数据库表新增字段、修改结构,Room 如何安全做版本迁移,实战怎么做兜底?)
- [11. 大批量数据批量插入、批量更新时,使用 SQLite 或 Room 有哪些必做的性能优化手段?](#11. 大批量数据批量插入、批量更新时,使用 SQLite 或 Room 有哪些必做的性能优化手段?)
- [12. 多线程并发读写数据库会引发哪些问题,原生 SQLite 和 Room 分别如何规避处理?](#12. 多线程并发读写数据库会引发哪些问题,原生 SQLite 和 Room 分别如何规避处理?)
- [13. 如何通过 Room 实现数据实时监听,适用于哪些常见业务场景?](#13. 如何通过 Room 实现数据实时监听,适用于哪些常见业务场景?)
- [14. App 长期使用后本地数据库文件体积膨胀、冗余过多,实战中有哪些清理优化方案?](#14. App 长期使用后本地数据库文件体积膨胀、冗余过多,实战中有哪些清理优化方案?)
- [15. 项目同时混用 MMKV + Room 两套存储,日常开发如何保证本地数据一致性与维护性?](#15. 项目同时混用 MMKV + Room 两套存储,日常开发如何保证本地数据一致性与维护性?)
一、基础用法
1. 简述 SharedPreferences 整体使用流程,以及 apply 与 commit 核心区别和适用场景
- SP 通过 Context 获取实例,以 XML 文件持久化键值数据,通过 Editor 执行增删改,最终提交生效。
- commit():同步阻塞写入磁盘,有返回值,容易引发主线程卡顿、ANR,适合少量关键配置、需要结果校验的场景。
- apply():异步后台写入,无返回值,不会阻塞主线程,是日常开发默认推荐用法。
- SP 整体适合存储少量简单配置,不适合存大数据、JSON、频繁写入场景。
2. 讲下 MMKV 的初始化、常规存取使用流程,日常开发基础使用有哪些注意点
- Application 中完成全局初始化,指定根目录;后续直接通过 MMKV 实例完成 String、Int、Bool、二进制、JSON等类型存取
- 底层基于 mmap 内存映射,增量写入,无需全量序列化落地
- 日常注意:合理使用多进程模式、敏感数据开启加密、不存储超大单条数据、避免频繁大批量循环写入。
3. 原生 SQLite 结合 SQLiteOpenHelper 的完整使用流程是什么,事务基础如何使用
- 自定义类继承 SQLiteOpenHelper,在onCreate初始化建表语句,onUpgrade处理数据库版本升级;
- 通过 getWritableDatabase /getReadableDatabase 获取数据库实例,执行原生 SQL 完成增删改查。
- 事务通过 beginTransaction() 开启,操作完成后标记成功 setTransactionSuccessful(),最后 endTransaction() 提交或回滚;批量操作使用事务能大幅提升写入性能。
4. 说明 Room 核心组件与整体使用流程,以及常规增删改查的基础使用方式
- 三大核心:Entity 数据库实体映射表结构、Dao 数据访问层定义 CURD 注解方法、Database 数据库统一管理类,单例提供Dao 实例。
- 使用流程:定义实体类、编写 Dao 抽象方法、创建 Database 抽象类;
- 通过注解@Insert/@Update/@Delete/@Query实现常规查询与修改,结合协程、RxJava 或 Flow实现异步操作,规避主线程数据库操作限制。
二、选型对比
5. 键值存储和关系型数据库各自有什么短板,为什么业务中不能只用一种存储方案
- MMKV、SP 这类键值存储 ,无表结构、不支持联表、条件复杂查询、分页、索引,不适合海量结构化数据
- SQLite、Room 关系型数据库,使用成本更高,轻量化简单配置存储会过度重,启动和维护成本更高
- 业务数据类型不同:简单配置用键值库,结构化、关联、批量检索数据用关系型数据库,组合选型才能兼顾性能与开发效率。
6. 实际开发中,你如何划分 MMKV 与 Room 的使用边界,阐述判断逻辑
- 小型、独立、无关联、简单配置类数据:登录 Token、功能开关、个性化配置、简单缓存,使用 MMKV
- 结构化、存在关联关系、需要条件查询、分页、批量管理、海量离线数据:聊天记录、本地列表缓存、历史记录、离线业务数据,使用 Room
- 核心判断:是否需要复杂查询、数据量级、是否需要持久化批量管理。
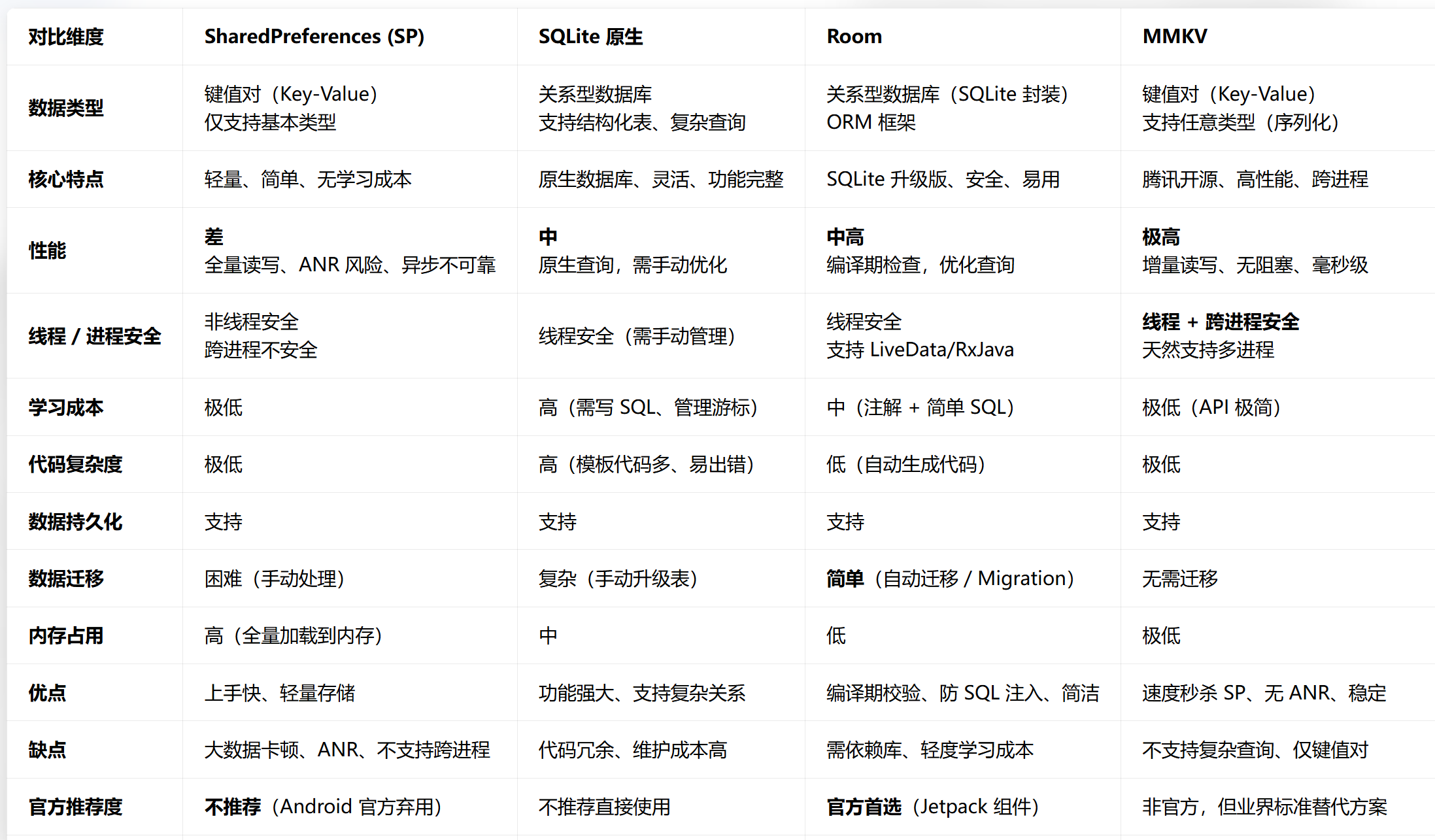
7. SP, MMKV, SQLITE, ROOM 数据库对比
三、实战场景 & 业务落地
8. 项目中频繁读写配置、埋点临时数据,容易出现卡顿、ANR,根源是什么,怎么解决?
- 根源主要是 SP 全量文件写入 + 主线程频繁调用 commit,造成磁盘 IO 阻塞
- 解决方案:全面替换为 MMKV、禁止主线程大批量循环写入、统一异步写入、合并高频零散埋点数据批量存储,规避频繁 IO 操作。
9. 需要本地缓存大量结构化列表数据,例如聊天记录、离线内容,用 Room 开发要注意什么?
- 合理设计表结构、拆分大字段、关键字段建立索引;
- 禁止一次性全量加载,使用分页查询;
- 大批量写入使用事务;
- 结合 Flow 做增量刷新;
- 定时清理过期无效数据,控制数据库体积。
10. 业务迭代需要给数据库表新增字段、修改结构,Room 如何安全做版本迁移,实战怎么做兜底?
- 升级数据库版本号,自定义 Migration 编写原生 SQL 完成增字段、改表操作,在 Database 注解中绑定迁移规则。
- 实战兜底:开发环境提前测试迁移逻辑、线上提供降级策略、异常捕获数据库打开异常,必要时允许清空本地缓存避免崩溃。
11. 大批量数据批量插入、批量更新时,使用 SQLite 或 Room 有哪些必做的性能优化手段?
- 统一使用数据库事务包裹批量操作,减少 IO 次数;
- 避免单条循环插入;
- 合理使用批量注解方法;
- 关闭不必要的日志和监听;
- 大批量操作放到子线程执行,避免 UI 卡顿。
12. 多线程并发读写数据库会引发哪些问题,原生 SQLite 和 Room 分别如何规避处理?
- 多线程并发会触发数据库锁、读写冲突、数据错乱、抛出数据库繁忙异常
- 原生 SQLite 需要手动加锁、控制单例数据库实例、限制并发操作
- Room 内部做了线程调度优化,结合协程单调度器、避免并发写入,配合事务降低冲突概率
13. 如何通过 Room 实现数据实时监听,适用于哪些常见业务场景?
- Dao 层查询方法返回 Flow 或 LiveData,可自动感知表数据变化,数据更新自动回调
- 适用场景:本地收藏列表、聊天会话列表、历史记录、离线缓存页面自动刷新,无需手动刷新页面。
14. App 长期使用后本地数据库文件体积膨胀、冗余过多,实战中有哪些清理优化方案?
- 定期清理过期、失效、已删除标记的冗余数据;
- 大字段单独拆分或文件存储;
- 定时执行数据库碎片整理;
- 限制本地缓存最大条数,自动淘汰老旧数据;
- 版本迭代中清理废弃数据表和字段
15. 项目同时混用 MMKV + Room 两套存储,日常开发如何保证本地数据一致性与维护性?
- 分层设计:配置层统一封装 MMKV 工具类,业务数据统一走 Room;
- 约定数据修改入口,禁止跨层随意读写;
- 关键联动数据修改时,同步更新两端缓存;
- 统一封装本地存储管理类,方便后期维护和替换;
- 制定开发规范,明确两类存储的使用边界。