后面就以这个代码为例子
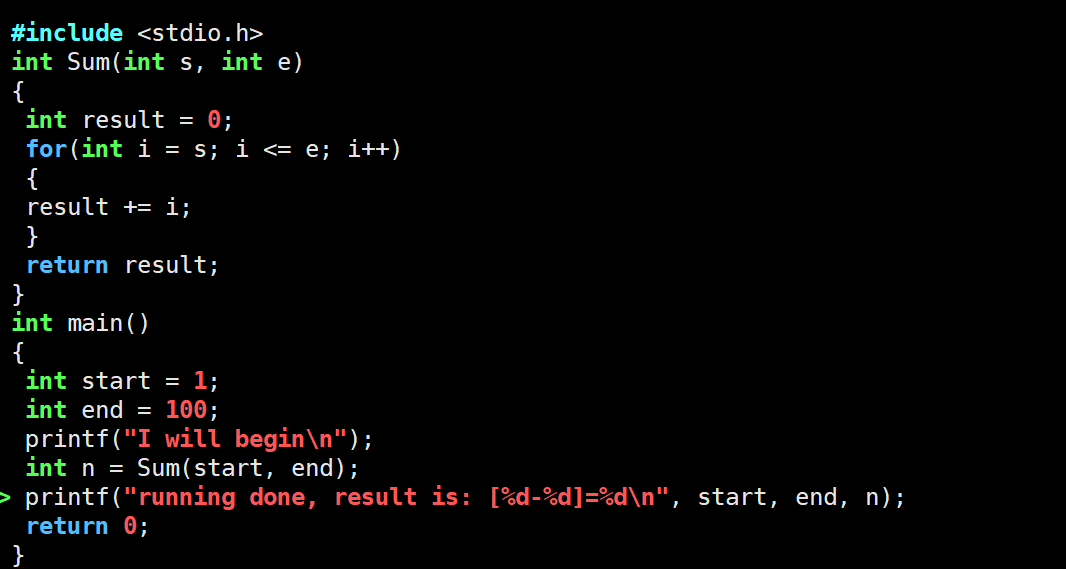
一.指令汇总
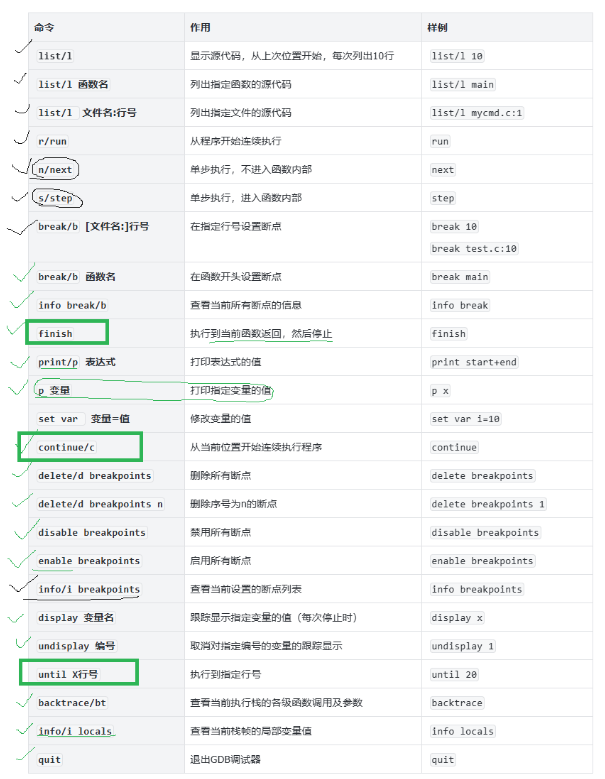
二.调试的相关指令具体运用
1.断点的使能(disable和able)
断点的使能能够保留历史断点痕迹方便下次能够找到
(info b就能看到断点的使能情况)
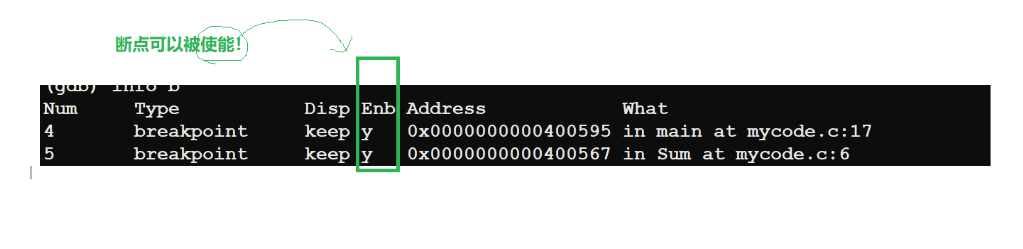
Enb为y表示断点为打开状态。enable和disable+断点编号不是行数。

bt看调用栈
a.找到问题 b.命令查看代码上下文 c.你解决问题
1.找到问题的命令:
断点1 -->断点2 -->断点3.....即断点本质把代码进行块级别划分,以块为单位进行快速地位区域
(二分查找debug)
进入到函数内部如果确定该函数没有bug可以直接finish执行完这个函数的代码。所以finish可以确定问题是不是在函数内部。
如果遇到循环想快速执行完循环内容并且跳过循环,可以直接until+行数即局部区域快速执行
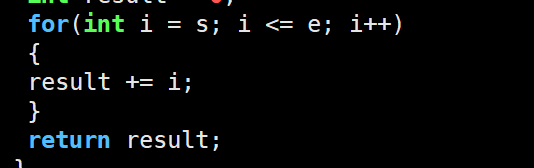
p+变量名 可以短暂看到变量的值,如果想要达到像vs上监视的效果就需要
display和undisplay
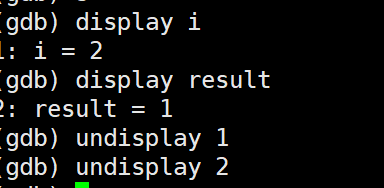
如果不想要再监视就undisplay+编号不是变量名
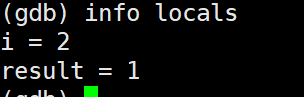
info locals就能看到函数内部所有的局部变量的值
watch
执⾏时监视⼀个表达式(如变量)的值。如果监视的表达式在程序运⾏期间的值发⽣变化,GDB会暂 停程序的执⾏,并通知使⽤者(和断点删除方式一样)
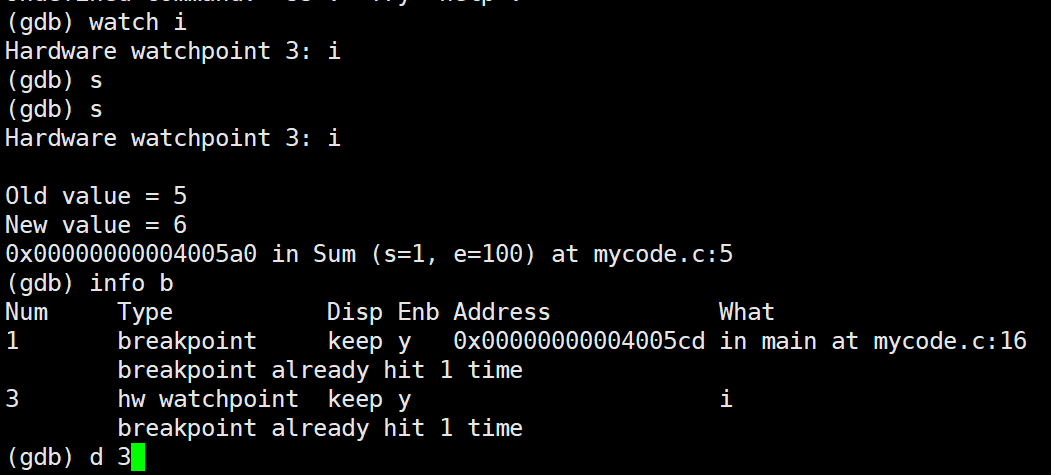
重要的是如果你有⼀些变量不应该修改,但是你怀疑它修改导致了问题,你可以watch它,如 果变化了,就会通知你。
set var
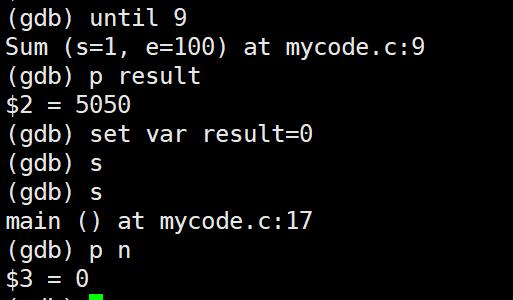
本来返回的result为5050,在set var result=0后n接受到返回的result就为0了
条件断点
eg:b+行号+判断条件
eg:b 7 if i==10
给已有的断点添加条件
eg:condition 2 i==6, 2为断点编号没有if
cgdb的Esc和i和vim类似ESC 进入代码屏, i 回到 gdb 屏
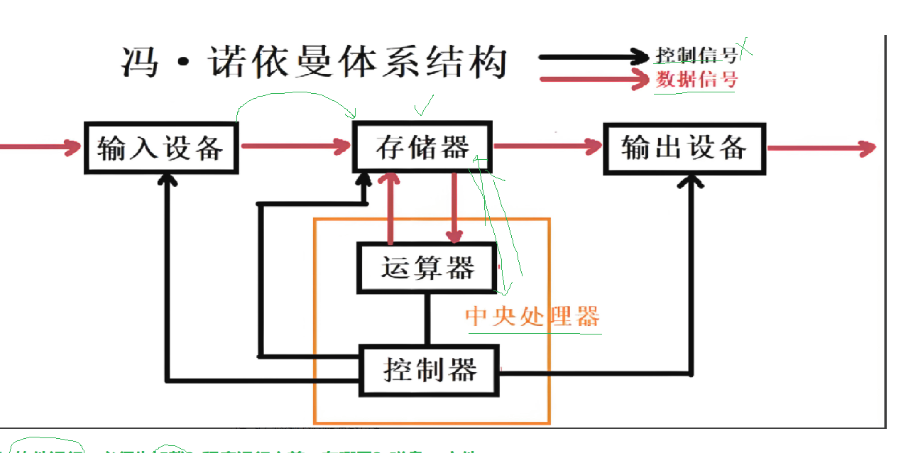
三.红诺伊曼计算机结构
CPU=运算器+控制器。
外设由输入设备和输出设备组成
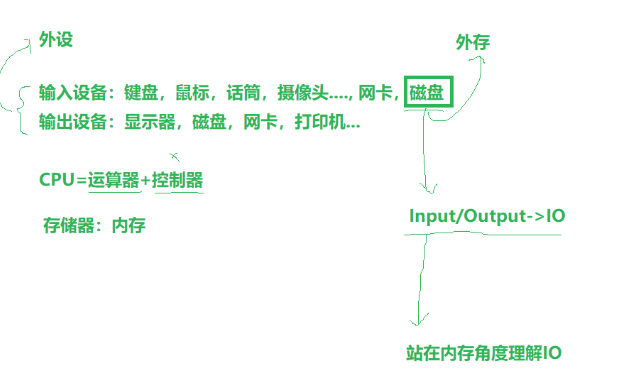
IO(Input/Output)操作是计算机系统中数据输入输出的核心机制,涉及与外部设备(如磁盘、网络、键盘等)的数据交互。
站在内存角度理解
读文件:磁盘数据->内存 (Input)
写文件:内存->磁盘(ouput)
1.软件(程序)运行为什么必须先加载内存?
首先cpu获取数据只能从内存中获取,软件运行时需要cpu执行我们的代码,访问数据,但代码和数据放在程序文件当中,即磁盘里,cpu不能直接访问磁盘,所以得把程序从外设加载到内存才能被被cpu访问。(体系结构规定)
加载本质就是把外设数据input到寄存器(内存)无论是输入设备到存储器还是存储器到cpu到存储器到输出设备数据都是从一个设备拷贝到另一个设备,所以体系结构的效率由设备的拷贝效率决定
cpu只和内存打交道,外设也只和内存打交道
2.为什么要有内存?
无内存: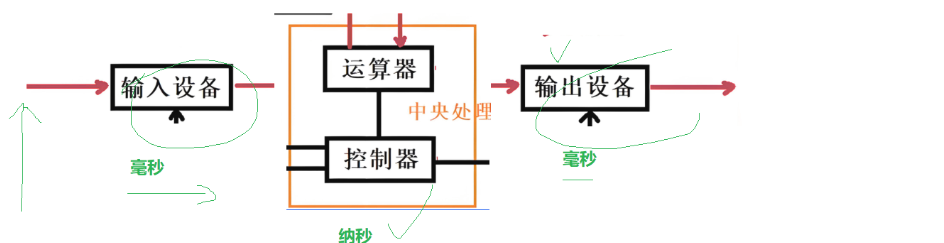
当外设把数据给cpu后,cpu快速处理就给输出设备,但输出设备输出慢,cpu就得等着输出设备把数据处理好后再能把数据给输出设备,同样输入设备慢cpu又不能及时获得数据。那么整体体系效率就由外设设备来定了
但如果计算机体系结构所有设备都放寄存器虽然可行但成本会太高了,所以为了价格和效率的平衡引入了内存,有了内存后输入设备就可以提前把数据放到内存里,减少了处理器直接访问慢速存储设备(如硬盘)的需要。而且将常用数据和指令保存在高速的内存中,计算机的整体执行效率得到显著提升,能让cpu与外设速度的不匹配做一定的适配,让内存来决定效率,效率大大提高
所以也可以说当代计算机是性价比的产物
3.理解数据流动
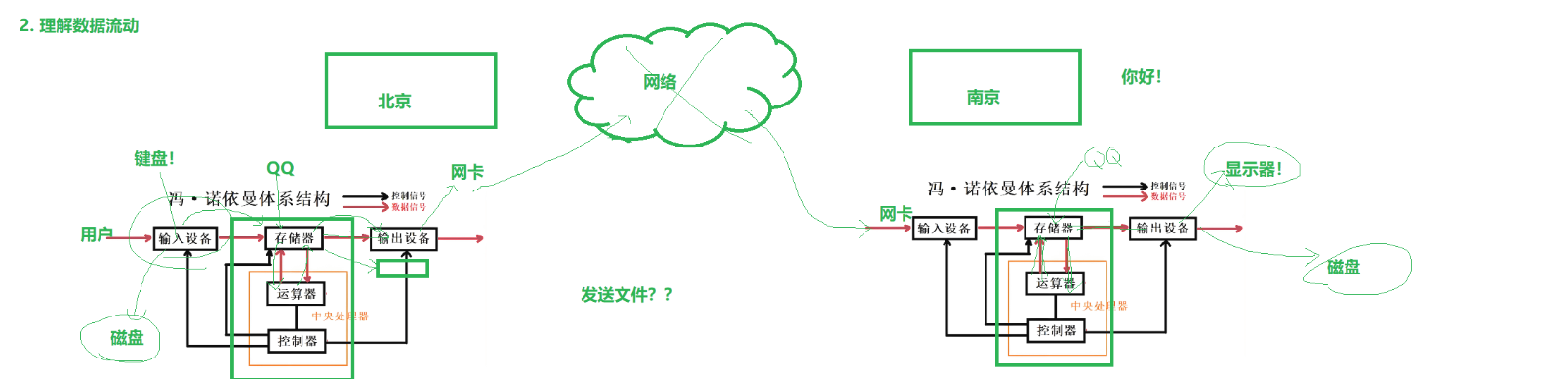
当我们登录qq就是把qq的执行程序加载到内存,在我们从键盘输入我们要发的消息时,数据由输入设备流向内存,与cpu做加密和封包等操作,再返回给内存,最后数据到输出设备(网卡)通过网路发送到对方的输入设备(网卡)接受,再到内存和运cpu做解密等操作后流向输出设备(显示器)上显示出来。
聊天就是把数据从用户键盘经过体系结构转发到对方显示器
发送文件就是把文件从我的磁盘经过体系结构拷贝到对方磁盘
四.操作系统

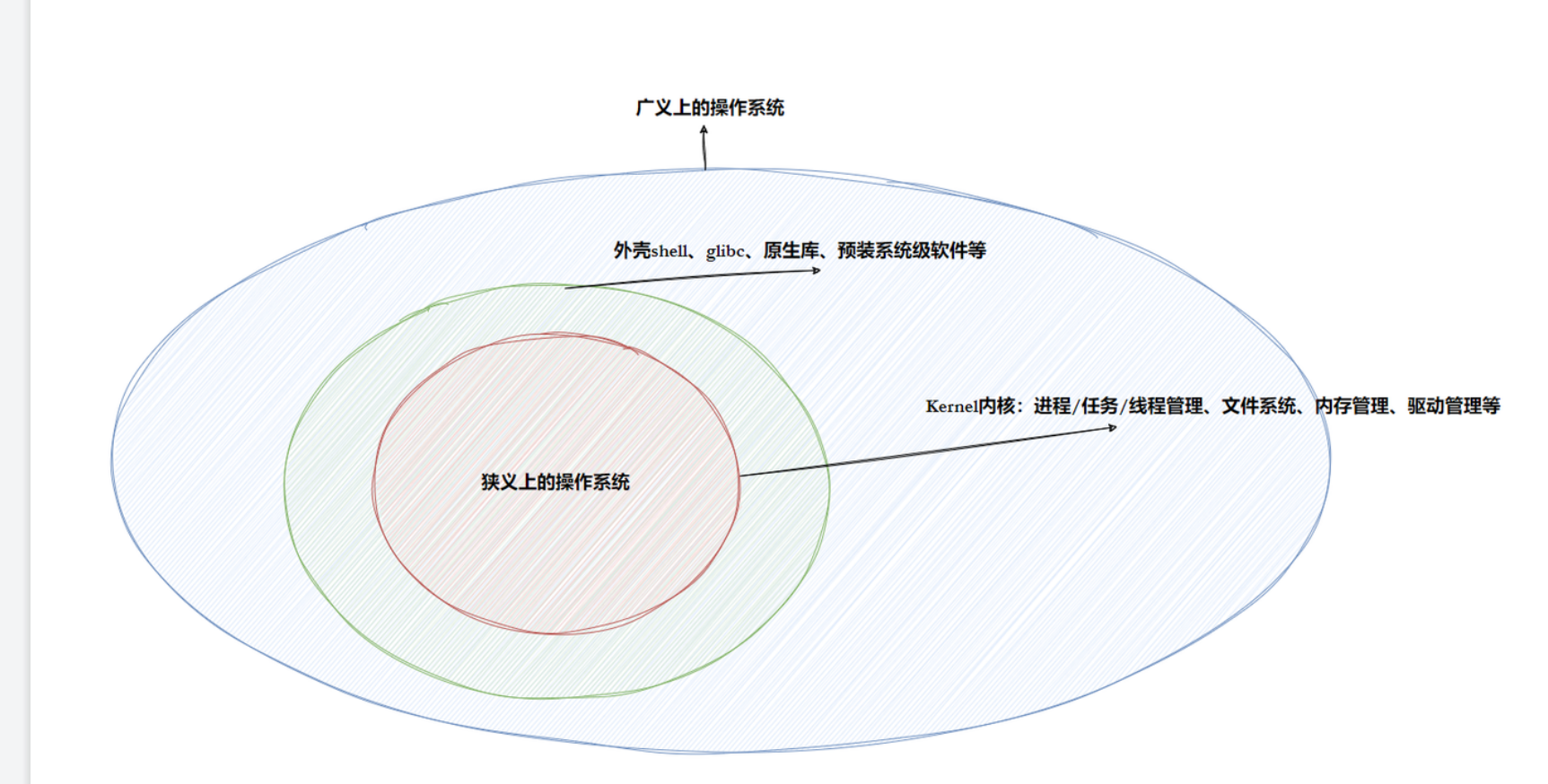
1.设计操作系统(OS)的目的
因为不同的硬件设备有自己个性化的读取方式,则访问各种硬件就要配上对应的驱动程序,如果没有操作系统去管理就会导致许多问题让用户体验变差。
(1)向下与硬件交互,管理所有的软硬件资源。
(2)向上对用户程序(应用程序)提供一个良好的执行环境
2.高内聚低耦合,层状结构
高内聚指模块内部元素(如函数、类、组件)的功能相关性高,共同完成单一明确的任务。低耦合指模块间依赖关系弱,修改一个模块时对其他模块影响小。这一原则在软件和硬件设计中均有体现。
软硬件体系结构从硬件到用户整个过程为一个层状结构,在软硬件上都遵从高内聚低耦合,例如在软件上我们学的c++中的继承,封装和多态,main函数内部调用有多个函数,一个函数只负责一项任务(高内聚),函数之间的接口隔离(低耦合)。硬件上芯片设计将特定功能集成到独立模块,各模块专注自身任务,各个模块之间依赖关系弱(或者这样理解,电脑的某一个部位坏了可以单独更换这个部位,不可能说直接换整个电脑吧)
3.不能直接访问操作系统
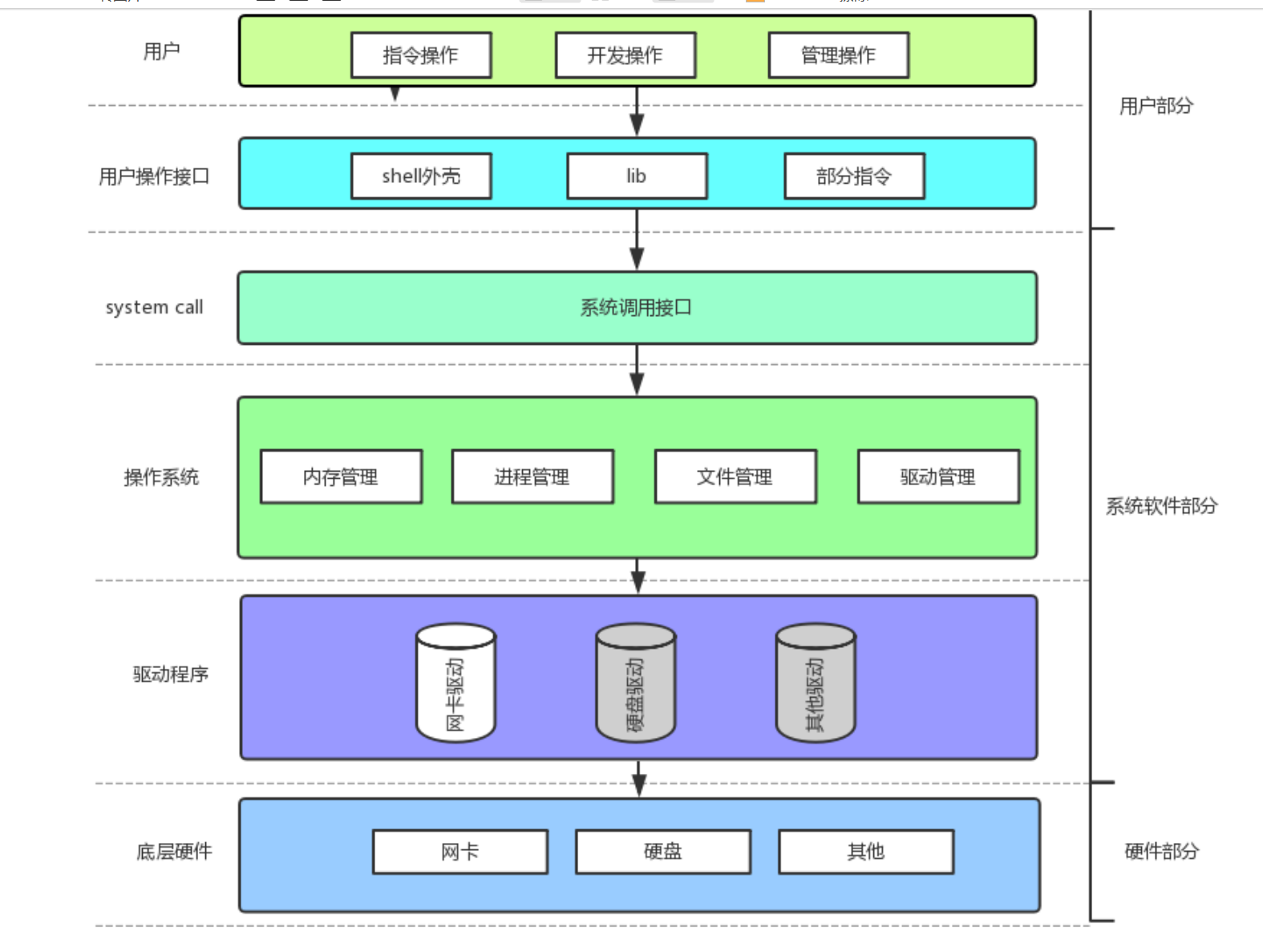
访问操作系统必须使用系统调用接口(其实就是函数调用只不过是系统提供)操作系统不允许用户直接访问内存管理,通信管理,文件管理和驱动管理。
4.访问硬件就得访问整个体系结构
我们的程序只要你判断出访问了硬件那么它必须贯穿整个软硬件体系结构。比如printf打印内容到显示器就访问了显示器硬件,其步骤为那么我们写的c程序(开发操作)-->lib(有c标准库方法)找到printf的库函数,其底层封装了系统调用接口,再通过操作系统的驱动管理进行访问-->驱动程序最后交到硬件显示器上。(库在底层封装了系统调用接口)
2.理解操作系统(OS)
一个例子:
OS(校长)驱动(辅导员)硬件(学生)
1.要管理,管理者和被管理者可以不需要见面 ,那么管理者通过什么方式管理被管理者?
管理者和被管理者见面不是目的,重要的是获取到被管理者的数据,根据数据进行管理。就好比校长管学生不用和学生见面,只要用学生的各项数据就可以了。
2.既然不能见面怎么得到数据?
通过中间层(驱动程序获取)。就好比辅导员这个中间人来获得学生数据然后给校长
所以OS管理硬件是基于数据,而数据由驱动程序获取
3.校长1.0
校长通过excel表格数据管理学生
如果校长想找一个最高的人参加篮球比赛就从excel表格中寻找,如果校长想开除成绩最低的1个人也是通过excel表格找到成绩最低的那个人。所以就转换为对excel表格的增删查改。
但如果学生人数太多管理不过来怎么办?
校长2.0
通过结构体管理
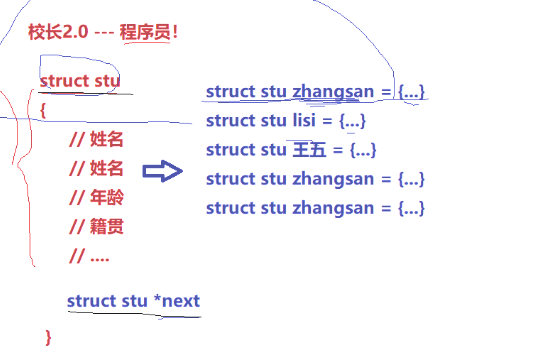
结构体存放*next,形成链表
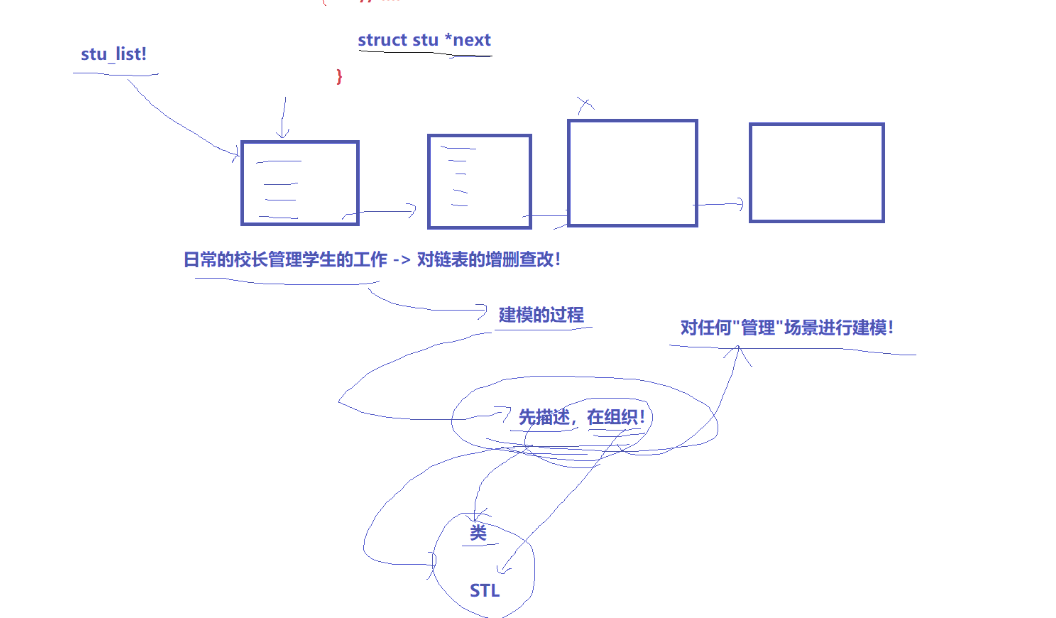
所以OS也是通过先描述再组织的方式管理,OS内部把网卡,硬盘.....使用struct device定义一个类
类中包含这些硬件的相关属性(相当于学生信息),管理硬件就通过管理包含硬件信息的类的增删查改
os对进程也类似,首先对每个进程定义struct对象,把进程的相关属性放到结构体,用链表结点相连,管理进程就转换为对链表的增删查改
所以c++的类解决描述问题,stl解决组织问题