
引言
现有的代码评测基准(HumanEval、SWE-bench)几乎清一色面向 Python。而 Android 开发的复杂性导致了这些通用基准根本覆盖不了:
- Kotlin/Java 双语言共存
- Jetpack Compose 与传统 View 体系并行
- Gradle 构建配置
- 设备碎片化 ...
今天,Google 终结了这个局面 :正式发布了 Android Bench ------ 首个专门针对 Android 开发的 LLM 评测基准。它直接回答了一个开发者最关心的问题:
我到底该用哪个 AI 来写 Android 代码?
核心解析:Android Bench 到底测什么?

1. 覆盖真实开发场景、直击痛点
Android Bench 不搞 LeetCode 那套。它的任务全部来源于 GitHub 上 500+ Star 的真实开源 Android 项目 ,从 38,989 个已合并的 Pull Request 中精选出 100 道题。
每道题都是开发者日常会真正遇到的痛点,如
- 修复 Android 版本升级带来的破坏性变更(Breaking Changes)
- 将项目从旧版 Jetpack Compose 迁移到最新版本
- 解决 Room 数据库迁移、Hilt 依赖注入配置等工程问题 ...
2. 覆盖了哪些技术栈?
涵盖Android 开发的"全科考试"
| 考察维度 | 具体内容 |
|---|---|
| 语言分布 | Kotlin (71%) / Java (25%) |
| UI 框架 | Jetpack Compose (41%) / 传统 View (59%) |
| 异步编程 | Coroutines & Flows |
| 数据持久化 | Room |
| 依赖注入 | Hilt |
| 页面导航 | Navigation |
| 构建配置 | Gradle |
| 设备特性 | Camera / Media / 可折叠设备适配 |
这套考卷的设计非常讲究 :
- 71% Kotlin + 25% Java 的比例精准反映了当前 Android 生态向 Kotlin 迁移的现状;
- 41% Compose + 59% View 则兼顾了新旧两套 UI 体系。
3. 任务难度分级
- 小改动(< 27 行代码变更):46%
- 中等改动(27 - 136 行):33%
- 大改动(> 136 行,最大单一变更达 435 行):21%
中位数任务大小为 32 行代码 。看似不多,但每一行都涉及对复杂代码库的上下文理解、依赖关系追踪和框架 API 的精准使用。
3. 如何评分?
流程清晰,逻辑严谨:
- 输入:向模型提供项目代码库 + Issue 描述
- 推理:模型阅读代码库,理解问题,生成补丁(Patch)
- 验证 :通过单元测试 + Android 设备/模拟器的 Instrumentation 测试自动判定
- 统计 :每个模型独立运行 10 次,取平均通过率
技术实现上,Android Bench 基于修改版的 SWE-bench 测试工具 ,搭配定制的 Docker 镜像 (内置 Android 构建环境),配合 mini SWE agent 作为推理代理。
4. 如何保证公平、公正?
Google 对评测进行了防作弊的三重保险:
- Canary 字符串:在数据集中植入 BIG-BENCH 标准金丝雀标记,劝阻模型厂商在训练数据中纳入评测题目
- 轨迹审查:人工审核模型的完整推理路径,排除"奖励黑客"(Reward Hacking)和死记硬背
- 全面开源:评测方法论、数据集、实验配置全部公开,支持独立复现
实际测评结果

截至 2026 年 4 月 7 日 ,Android Bench选择了市面上最热门的11 大模型横向对比 ,排行榜最新数据如下: 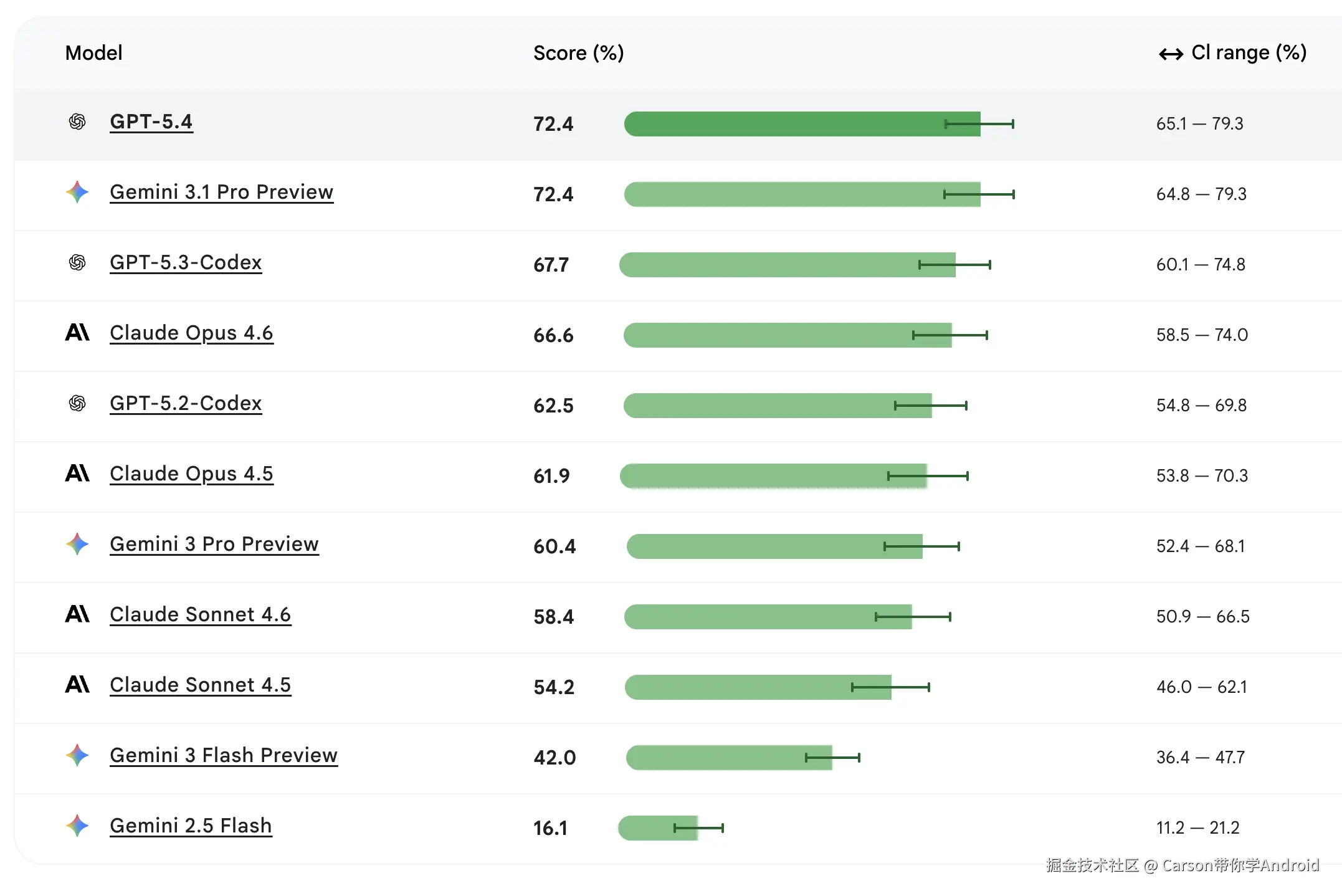
结论一:双王并立,72.4% 并列登顶
GPT-5.4 和 Gemini 3.1 Pro Preview 以完全相同的 72.4% 通过率并列第一。这是最新排行榜上最戏剧性的一幕 ------ OpenAI 的最新旗舰成功追平了 Google 的"主场选手"。
结论二:三大阵营,格局清晰
排行榜自然分成了 三个梯队:
- 第一梯队(65%+):GPT-5.4、Gemini 3.1 Pro、GPT-5.3-Codex、Claude Opus 4.6
- 第二梯队(50%-65%):GPT-5.2-Codex、Claude Opus 4.5、Gemini 3 Pro、Claude Sonnet 4.6、Claude Sonnet 4.5
- 第三梯队(<50%):Gemini 3 Flash、Gemini 2.5 Flash
结论三:最强与最弱,差距高达 4.5 倍
排名第一的 72.4% 与垫底的 16.1%,差距达到惊人的 4.5 倍 。这充分说明:在垂直领域,通用基准上"看起来差不多"的模型,实际表现可能天差地别。
硬核剖析:为什么ta强?为什么ta弱?

剖析一:🏆 冠军组 = GPT-5.4 & Gemini 3.1 Pro
为什么他们能达到惊人的72.4%?
Gemini 3.1 Pro 的"主场优势"
Gemini 是 Google 的亲儿子,而 Android 也是 Google 的。这意味着 Gemini 在训练数据中对 Android SDK、Jetpack 库、Android 官方文档 有着天然的深度覆盖。它对 Compose 的声明式 UI 模式、Hilt 的注解处理逻辑、Gradle KTS 构建脚本的理解,有着其他模型难以复制的底层优势。
GPT-5.4 的"逆袭追平"
OpenAI 最新旗舰 GPT-5.4 以"外来者"身份追平 Gemini,含金量极高。这说明:
- GPT-5.4 在代码理解与生成的通用能力 上已经足够强大,即使没有"主场优势",也能通过强大的长上下文推理 和跨文件代码关联能力弥补领域知识差距
- OpenAI 显然在编程领域进行了大量的定向优化
两者的核心共性:
- 强大的代码库导航能力
- 精准的依赖关系理解
- 对 Android 框架 API 的深度掌握
剖析二:🥈 Claude 阵营,稳定输出的"六边形战士"
Claude 系列在这份榜单上表现极为稳健:
- Claude Opus 4.6(66.6%)稳居第四,紧咬第一梯队
- Claude Opus 4.5(61.9%)排名第六
- Claude Sonnet 4.6 (58.4%)和 Sonnet 4.5(54.2%)在轻量级模型中表现优异
Anthropic 的模型虽然没有 Google/OpenAI 的顶尖爆发力,但胜在版本间表现一致、衰减幅度小 。Opus 4.6 与 Opus 4.5 之间仅差 4.7 个百分点 ,Sonnet 4.6 与 Sonnet 4.5 之间差 4.2 个百分点。
这意味着 Claude 的代码推理能力在迭代中保持了稳定的进步节奏,没有出现大的波动。
剖析三:⚠️ 败者之鉴,Gemini 2.5 Flash 为何垫底?
16.1% 的通过率,与自家 Gemini 3 Flash(42.0%)相差 2.6 倍,与 Gemini 3.1 Pro(72.4%)更是差距悬殊。
这里最重要的发现是:架构升级的影响远超参数堆叠。
- Gemini 2.5 Flash 到 Gemini 3 Flash 的跨代升级带来了 +25.9 个百分点 的巨幅提升
- 而同代的 Flash 到 Pro 的升级(42.0% → 72.4%)也有 +30.4 个百分点。
这说明 Gemini 2.5 Flash 在以下方面存在严重短板:
- 复杂代码库的上下文窗口不足:无法有效追踪跨文件的依赖关系
- 框架 API 知识不够深入:在 Compose、Hilt 等现代 Android 框架面前频繁"翻车"
- 代码生成精度差:可能产生语法正确但逻辑错误的补丁,无法通过严格的 Instrumentation 测试
这也给所有开发者一个警示:不要迷信"轻量级"模型能在复杂工程任务上替代旗舰模型。
剖析四:📊 OpenAI Codex 系列的进化曲线
GPT-5.2-Codex(62.5%)→ GPT-5.3-Codex(67.7%)→ GPT-5.4(72.4%)
三代产品在 Android Bench 上呈现出清晰的线性增长:
- 5.2 → 5.3:+5.2 个百分点
- 5.3 → 5.4:+4.7 个百分点
每一代提升约 5 个百分点,说明 OpenAI 在代码模型上的迭代策略稳定且高效,没有出现"挤牙膏"或"大跃进后回退"的情况。
总结
基于 Android Bench 最新数据,如果你只能选一个模型来辅助 Android 开发,结论如下:
- 首选 Gemini 3.1 Pro:72.4% 通过率 + Google 原生生态优势 + 与 Android Studio 的深度整合,是当前 Android 开发场景的最优解
- 等量替代 GPT-5.4:同样 72.4%,如果你的工作流更偏向 OpenAI 生态(如 ChatGPT、Cursor),它是同样出色的选择
- 性价比之选 Claude Opus 4.6:66.6% 的得分仅落后第一名 5.8 个百分点,且 Anthropic 的 API 定价通常更有竞争力
- 轻量级场景用 Claude Sonnet 4.6:58.4% 在 Sonnet 级别模型中表现最佳,适合对延迟和成本敏感的场景
- 避坑 Gemini 2.5 Flash:16.1% 的得分不适合任何严肃的 Android 开发任务
更多的启发

1. 通用基准正在失去意义
当各家旗舰模型在 HumanEval 上都能跑出 90%+ 的成绩时,垂直领域基准才是真正拉开差距的战场。
Android Bench 证明了这一点 ------ 即使是同一厂商的不同模型,在 Android 领域的表现也可以相差 4.5 倍。
2. 垂直评测将成为趋势
Android Bench 打了第一枪。可以预见,iOS Bench、Flutter Bench、React Native Bench 等垂直评测基准将陆续涌现。
未来,开发者选择 AI 工具的依据将不再是"通用跑分",而是"在我的技术栈上它到底行不行"。
3. 排行榜将倒逼模型进化
公开排行榜的最大价值在于形成正向飞轮:排名靠后的模型厂商将被迫针对性优化 Android 领域的训练数据和微调策略,从而推动整个生态的进步。
📎 相关链接
- Android Bench 官网:developer.android.com/bench
- 评测方法论详解:developer.android.com/bench/metho...
- GitHub 开源仓库:github.com/android-ben...