文章目录
一、工具调用的核心链路
python
# 工具调用的核心数据结构
# LLM 输出的 tool_call 格式(以 OpenAI function calling 为例)
tool_call = {
"id": "call_abc123",
"type": "function",
"function": {
"name": "search_insurance_contract", # 工具名称
"arguments": '{"query": "等待期", "doc_id": "contract_2024_001"}' # JSON 参数
}
}
# 框架层执行工具并返回结果
tool_result = {
"tool_call_id": "call_abc123",
"role": "tool",
"content": "等待期为30天,自保单生效日起计算。"
}这个链路里有三个地方会出问题:
LLM 生成的参数不合法------参数格式错误、必填字段缺失、参数类型不对。比如工具要求 doc_id 是整数,LLM 却传了字符串 "001"。
工具执行本身失败------数据库连接超时、API 限流、外部服务返回 500。这类错误跟 LLM 无关,是基础设施的问题。
工具返回了结果但结果无用------工具执行成功,但返回了空结果或错误数据(比如数据库查询没有命中、API 返回了 {"status": "no_data"})。
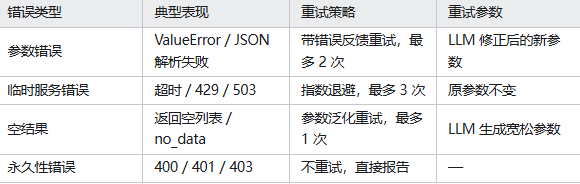
这三类失败的处理策略完全不同,混在一起用同一套重试逻辑,是大多数 Agent 工程实现的第一个坑。
二、LLM生成的参数不合法
特征:工具返回 ValueError、TypeError、参数校验失败,或者 JSON 解析报错。根本原因是 LLM 对工具 schema 理解有偏差,生成了格式不对或语义错误的参数。
处理方式:
- 带错误反馈的重试(Error-Informed Retry)------把错误信息连同原始 tool_call 一起送回给 LLM,让它自己修正参数,而不是无脑重试原参数。关键是错误信息要够具体,告诉 LLM 哪里错了、期望是什么。
python
import json
import time
from typing import Any, Optional
class ToolExecutor:
"""
带错误分类和重试策略的工具执行器
区分参数错误、临时服务错误、空结果、永久性错误四类
"""
# 需要指数退避重试的状态码(临时服务错误)
TRANSIENT_HTTP_CODES = {429, 500, 502, 503, 504}
# 永久性错误,直接终止
PERMANENT_HTTP_CODES = {400, 401, 403, 404}
def execute_with_retry(
self,
tool_call: dict,
tools: dict,
llm,
conversation_history: list,
max_retries: int = 3
) -> dict:
tool_name = tool_call["function"]["name"]
tool_fn = tools.get(tool_name)
if not tool_fn:
return {"error": f"工具 {tool_name} 不存在", "recoverable": False}
for attempt in range(max_retries):
try:
# 解析 LLM 生成的参数
args = json.loads(tool_call["function"]["arguments"])
except json.JSONDecodeError as e:
# JSON 解析失败 → 参数错误,让 LLM 修正
if attempt < max_retries - 1:
tool_call = self._request_param_fix(
tool_call, f"参数JSON格式错误:{e}", llm, conversation_history
)
continue
return {"error": "参数格式持续错误", "recoverable": False}
try:
result = tool_fn(**args)
# 检查空结果
if self._is_empty_result(result):
if attempt == 0: # 只给一次参数泛化机会
tool_call = self._request_param_generalize(
tool_call, result, llm, conversation_history
)
continue
return {"result": result, "warning": "查询无结果"}
return {"result": result, "success": True}
except ValueError as e:
# 参数值不合法 → 让 LLM 修正
if attempt < max_retries - 1:
tool_call = self._request_param_fix(
tool_call, f"参数值错误:{e}", llm, conversation_history
)
except TimeoutError:
# 超时 → 指数退避重试(参数不变)
wait = 2 ** attempt
time.sleep(wait)
except PermissionError as e:
# 永久性错误 → 立即终止
return {"error": str(e), "recoverable": False}
return {"error": f"工具 {tool_name} 在 {max_retries} 次重试后仍失败", "recoverable": False}
def _request_param_fix(
self,
original_call: dict,
error_msg: str,
llm,
history: list
) -> dict:
"""
把错误信息反馈给 LLM,让它修正工具参数
关键:错误信息要具体,告诉 LLM 哪里错了、期望什么
"""
fix_messages = history + [
{
"role": "tool",
"tool_call_id": original_call["id"],
"content": f"工具调用失败:{error_msg}\n请检查参数格式并重新调用。"
}
]
# 让 LLM 基于错误反馈重新生成 tool_call
response = llm.generate(fix_messages, tools=..., tool_choice="required")
return response.tool_calls[0]
def _is_empty_result(self, result: Any) -> bool:
if result is None:
return True
if isinstance(result, (list, dict, str)) and len(result) == 0:
return True
if isinstance(result, dict) and result.get("status") in ("no_data", "not_found"):
return True
return False核心思路是:把错误信息结构化地放回对话历史,让 LLM 理解自己哪里出错了,然后重新生成 tool_call。
- 错误处理是补救,更好的方式是在源头减少 LLM 生成错误参数的概率------这取决于工具 Schema 的质量。
python
# 差的 Schema(过于简洁,LLM 容易猜错)
{
"name": "query_contract",
"description": "查询合同信息",
"parameters": {
"type": "object",
"properties": {
"id": {"type": "string"},
"type": {"type": "string"}
}
}
}LLM 不知道 id 是什么格式、type 有哪些合法值,于是各种乱传------id 传了合同名称的文本、type 传了"意外险"(实际上应该是枚举值)。
python
# 好的 Schema(类型约束 + 枚举值 + 示例 + 说明)
{
"name": "query_contract",
"description": "按合同编号查询保险合同的详细条款信息。仅支持通过合同编号查询,不支持模糊搜索。",
"parameters": {
"type": "object",
"properties": {
"contract_id": {
"type": "string",
"description": "合同编号,格式为 INS-YYYY-NNNN,例如 INS-2024-0023",
"pattern": "^INS-\\d{4}-\\d{4}$" # 正则约束
},
"insurance_type": {
"type": "string",
"description": "险种类型,只能从以下值中选择",
"enum": ["accident", "health", "life", "property"], # 枚举约束
"enumDescriptions": {
"accident": "意外伤害险",
"health": "健康险(含重疾险)",
"life": "人寿险",
"property": "财产险"
}
}
},
"required": ["contract_id"] # 明确必填字段
}
}改了 Schema 之后,参数错误率从 23% 降到了 8%。几乎不需要改任何 LLM 调用逻辑,只是把工具描述写清楚了。Schema 质量是工具调用可靠性的第一道防线。
三、临时服务错误(基础设施问题)
特征:网络超时、HTTP 429(限流)、HTTP 503(服务不可用)、数据库连接中断。这类错误跟 LLM 生成的参数无关,是底层服务的短暂不可用。
处理方式:指数退避重试(Exponential Backoff)------第 1 次失败等 1 秒重试,第 2 次等 2 秒,第 3 次等 4 秒。重试时用完全一样的参数,因为问题出在服务端,不在参数。
四、空结果或无用结果(工具逻辑问题)
特征:工具执行成功(HTTP 200),但结果是空列表、null、no_data。这意味着查询条件没有命中数据,而不是服务故障。
处理方式:参数泛化重试------把 LLM 召回来,告诉它"查询没有命中结果,请尝试用更宽泛的条件重新查询",让 LLM 生成一个调整过参数的新 tool_call。
五、永久性错误(不可恢复)
特征:HTTP 400(请求本身有根本性错误)、HTTP 401/403(权限问题)、工具不存在等。这类错误重试没有任何意义。
处理方式:立即终止,向上报告------停止当前工具调用链,生成一个对用户友好的错误说明,让 LLM 基于当前已有信息给出力所能及的回答。
五、工具调用的可观测性:出了问题能看到在哪里
Agent 系统在生产环境里最大的挑战之一是调试困难------一个任务跑了十几步工具调用,中间某一步失败了,如果没有完整的调用链日志,根本找不到在哪里出的问题。
关键观测指标:
工具级别: 每个工具的调用次数、成功率、平均延迟、错误分布(参数错误 vs 服务错误 vs 空结果)。如果某个工具的错误率突然升高,可能是 Schema 不够清晰(LLM 理解偏了)或者后端服务出了问题。
任务级别: 每个 Agent 任务的总步数、工具调用总次数、重试次数、最终成功/失败。重试次数多的任务往往说明工具 Schema 有问题,或者 LLM 在这类任务上的工具选择不稳定。
LLM 决策质量: 工具选择的合理性(LLM 有没有调用不该调用的工具)、参数错误率(LLM 生成错误参数的频率)。这两个指标可以帮你判断是 Schema 问题还是 LLM 能力问题。
python
import time
from functools import wraps
from dataclasses import dataclass, field
from typing import Optional
@dataclass
class ToolCallRecord:
"""工具调用记录,用于可观测性"""
tool_name: str
arguments: dict
start_time: float
end_time: Optional[float] = None
success: bool = False
error_type: Optional[str] = None # param_error / transient / empty / permanent
retry_count: int = 0
result_summary: Optional[str] = None # 结果摘要,不存原始结果(可能很大)
@property
def latency_ms(self):
if self.end_time:
return (self.end_time - self.start_time) * 1000
return None
def track_tool_call(tool_name: str):
"""
工具调用追踪装饰器
自动记录调用时间、成功/失败、错误类型
"""
def decorator(fn):
@wraps(fn)
def wrapper(*args, **kwargs):
record = ToolCallRecord(
tool_name=tool_name,
arguments=kwargs,
start_time=time.time()
)
try:
result = fn(*args, **kwargs)
record.success = True
record.result_summary = str(result)[:100] # 只记录摘要
return result
except Exception as e:
record.error_type = classify_error(e)
raise
finally:
record.end_time = time.time()
# 推送到监控系统(如 Prometheus / Datadog / 内部日志)
metrics.record(record)
return wrapper
return decorator
# 使用方式
@track_tool_call("query_contract")
def query_contract(contract_id: str, insurance_type: str = None):
# 工具实现
...总结:
在 Agent 开发中,工具调用失败不能笼统处理,按四类场景拆分,针对性治理:
- 第一类,参数错误。属于大模型生成问题,比如参数缺失、格式错误、枚举越界、入参不合理。
- 第二类,临时服务异常。属于基建问题,比如接口超时、限流、网络波动、服务短暂不可用。
- 第三类,空结果返回。查询类工具正常执行,但无数据命中,不是报错,是业务无结果。
- 第四类,永久性错误。比如权限不足、资源不存在、非法操作,属于不可恢复问题。
针对四类问题,采用差异化重试策略,严格区分修正重试和无脑重试:
- 参数错误:采用错误反馈式重试,把接口报错、字段校验失败信息原样回传给大模型,让模型自主修正入参后二次调用;
- 临时服务错误:使用指数退避重试,不修改任何参数,只错开瞬时波动;
- 空结果场景:触发参数泛化重试,放宽检索条件、精简关键词,扩大查询范围;
- 永久错误:直接终止流程、上报异常,禁止无效重试,避免死循环和资源浪费。
同时,从源头通过 Schema 优化降错。通过完善工具入参描述、增加枚举约束、正则校验、字段必填说明、补充调用示例,强约束模型输出。
最后,配套完整可观测性体系做长效治理:
搭建工具维度的调用成功率、失败类型大盘监控,结合任务级调用链路追踪,快速定位高频失败场景、模型倾向性问题,持续沉淀 bad case、反哺优化提示词与工具描述,形成闭环迭代,长期稳定工具调用成功率。