TPAMI 2026 | Semi-DETR++:基于检测 Transformer 的高效半监督目标检测
文章目录
- [1 论文信息](#1 论文信息)
- [2 论文主要贡献](#2 论文主要贡献)
- [3 论文创新点](#3 论文创新点)
- [4 方法](#4 方法)
-
- [4.1 整体框架](#4.1 整体框架)
- [4.2 阶段式混合匹配](#4.2 阶段式混合匹配)
- [4.3 重解码查询一致性训练](#4.3 重解码查询一致性训练)
- [5 实验分析](#5 实验分析)
-
- [5.1 对比实验](#5.1 对比实验)
- [5.3 消融实验](#5.3 消融实验)
- [6 个人声明](#6 个人声明)
1 论文信息
论文题目:Toward Efficient Semi-Supervised Object Detection With Detection Transformer
论文作者:Jiacheng Zhang, Jiaming Li, Xiangru Lin, Wei Zhang, Xiao Tan, Hongbo Gao, Jingdong Wang, Guanbin Li
发表单位:中山大学、百度公司、中国科学技术大学、南洋理工大学、鹏城实验室
发表会议期刊:IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2026, Vol.48, No.3)
代码链接:https://github.com/JCZ404/Semi-DETR
2 论文主要贡献
本文针对半监督目标检测领域中现有方法主要基于传统 CNN 检测器、而 DETR 类端到端检测器的半监督学习研究不足的问题,系统分析了将 DETR 应用于半监督任务的两大核心挑战:**DETR 固有的一对一匈牙利匹配对噪声伪标签高度敏感,以及基于查询的解码器架构难以建立有效的一致性正则化。**为此提出了 Semi-DETR++ 框架,通过阶段式混合匹配策略结合一对多和一对一匹配的优势,在抵抗伪标签噪声的同时保留了 DETR 的 NMS-free 推理特性;并基于解码器逐层解码的局部性观察,设计了重解码查询一致性训练方法,无需复杂的查询匹配即可实现高效的一致性正则化。在 MS-COCO 和 PASCAL VOC 基准上的大量实验表明,Semi-DETR++ 在所有数据设置下均显著超越现有方法,建立了新的 SOTA 性能,同时该框架还能自然扩展到半监督实例分割和语义分割任务,展现出极强的通用性和泛化能力。
3 论文创新点
- 系统研究了检测 Transformer 在半监督目标检测中的核心挑战,提出了首个专门为 DETR 架构设计的端到端半监督目标检测框架,填补了该领域的研究空白。
- 提出阶段式混合匹配策略,在训练早期采用抗噪声的一对多分配缓解伪标签噪声带来的优化冲突,训练后期平滑过渡到标准的一对一匹配,既提升了训练效率又完整保留了 DETR 的 NMS-free 推理优势。
- 提出重解码查询一致性方法,利用解码器逐层解码的局部性特性,通过二次解码过程建立隐式的查询对应关系,无需复杂的候选框选择和 ROIAlign 操作,实现了更简单高效且效果更好的一致性正则化。
4 方法
4.1 整体框架
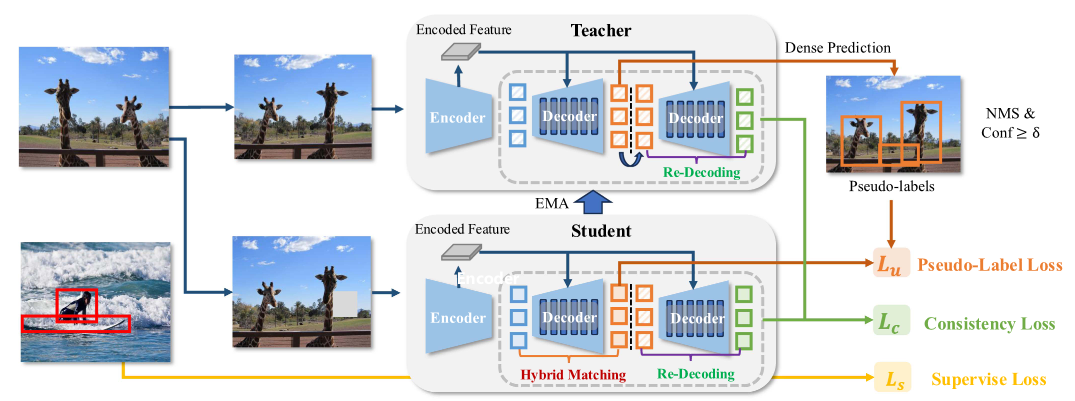
Semi-DETR++ 整体框架如图所示,基于经典的 Mean-Teacher 师生架构构建。输入图像分别经过弱增强和强增强后送入教师模型和学生模型,教师模型生成伪标签用于监督学生模型的训练。框架包含两个核心创新模块**:阶段式混合匹配 (Stage-wise Hybrid Matching, SHM) 和重解码查询一致性 (Re-decode Query Consistency, RQC)。**前者解决伪标签噪声导致的训练低效问题,后者解决查询式解码器的一致性训练难题。两个模块协同工作,实现了高效的端到端半监督目标检测,推理阶段无需任何后处理步骤。
4.2 阶段式混合匹配
该模块针对 DETR 一对一匹配对噪声敏感的问题设计,将训练过程分为两个阶段。在训练早期,伪标签质量较低,采用一对多分配策略为每个伪标签分配多个正样本,以覆盖可能的正确匹配,其匹配公式为:
σ ^ o 2 m = { arg min σ i ∈ C N M ∑ j = 1 M C m a t c h ( y ^ i , y σ i ( j ) ) } i = 1 ∣ y ^ ∣ \hat{\sigma}{o2m} = \left\{ \underset{\sigma_i \in C_N^M}{\arg\min} \sum{j=1}^M \mathcal{C}{match}\left( \hat{y}i, y{\sigma_i(j)} \right) \right\}{i=1}^{|\hat{y}|} σ^o2m={σi∈CNMargminj=1∑MCmatch(y^i,yσi(j))}i=1∣y^∣
匹配代价综合考虑分类得分和 IoU 重叠度:
C m a t c h ( y ^ i , y j ) = − s i j α ⋅ u i j β \mathcal{C}{match}\left( \hat{y}i, y_j \right) = -s{ij}^{\alpha} \cdot u{ij}^{\beta} Cmatch(y^i,yj)=−sijα⋅uijβ
同时设计了质量加权的损失函数,抑制低质量正样本的影响:
L c l s o 2 m = ∑ j = 1 N p o s ∣ m ^ j − s j ∣ γ B C E ( s j , m ^ j ) + ∑ j = 1 N n e g s j γ B C E ( s j , 0 ) \mathcal{L}{cls}^{o2m} = \sum{j=1}^{N_{pos}} \left| \hat{m}j - s_j \right|^{\gamma} BCE\left( s_j, \hat{m}j \right) + \sum{j=1}^{N{neg}} s_j^{\gamma} BCE\left( s_j, 0 \right) Lclso2m=j=1∑Npos∣m^j−sj∣γBCE(sj,m^j)+j=1∑NnegsjγBCE(sj,0)
L r e g o 2 m = ∑ j = 1 N p o s m ^ j L G I o U ( b j , b ^ j ) + ∑ j = 1 N p o s m ^ j L L 1 ( b j , b ^ j ) \mathcal{L}{reg}^{o2m} = \sum{j=1}^{N_{pos}} \hat{m}j \mathcal{L}{GIoU}\left( b_j, \hat{b}j \right) + \sum{j=1}^{N_{pos}} \hat{m}j \mathcal{L}{L1}\left( b_j, \hat{b}_j \right) Lrego2m=j=1∑Nposm^jLGIoU(bj,b^j)+j=1∑Nposm^jLL1(bj,b^j)
当训练进行到一定步数后,伪标签质量显著提升,模型平滑过渡到标准的一对一匈牙利匹配,最终实现 NMS-free 的推理能力。
4.3 重解码查询一致性训练
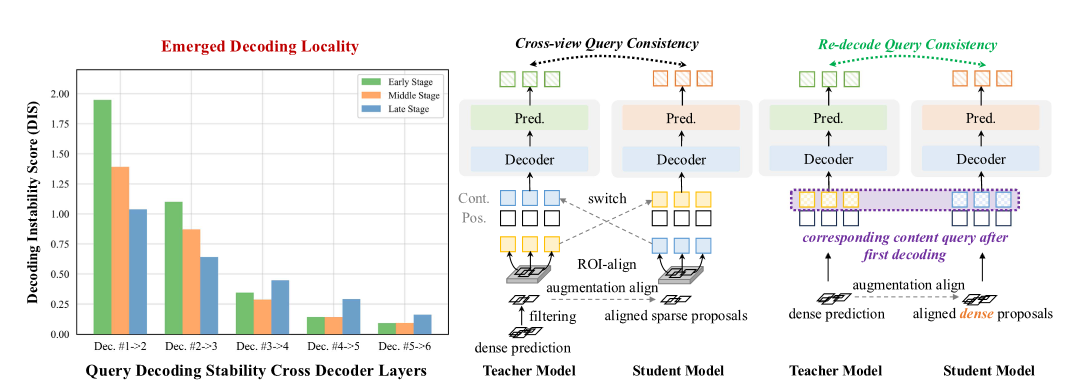
DETR 的查询在逐层解码过程中会逐渐聚焦于特定的图像区域,表现出强烈的局部解码特性 。基于此设计了重解码一致性训练方法,首先对原始查询进行一次常规解码,然后使用教师模型最后一层输出的边界框重新初始化位置查询,保留内容查询不变,进行第二次解码过程:
o ~ t = D t ( q t c + q ~ t p , F t ∣ A ) , o ~ s = D s ( q s c + q ~ t p , F s ∣ A ) \tilde{o}_t = D_t\left( q_t^c + \tilde{q}_t^p, F_t | A \right), \quad \tilde{o}_s = D_s\left( q_s^c + \tilde{q}_t^p, F_s | A \right) o~t=Dt(qtc+q~tp,Ft∣A),o~s=Ds(qsc+q~tp,Fs∣A)
在两次解码的输出之间施加 KL 散度作为一致性损失,仅对高置信度的前景查询进行监督:
w i = I ( max c ∈ 0 , K p t ( y c ∣ o ~ t i ) > η ) w_i = \mathcal{I}\left( \max_{c \in 0,K} p^t\left( y_c | \tilde{o}_{t_i} \right) > \eta \right) wi=I(c∈0,Kmaxpt(yc∣o~ti)>η)
模型的一致性损失组成:
L u n s u p c o n = ∑ i = 0 ∣ o ~ t ∣ w i L K L ( p s ( y c ∣ o ~ s i ) | p t ( y c ∣ o ~ t i ) ) \mathcal{L}{unsup}^{con} = \sum{i=0}^{|\tilde{o}t|} w_i \mathcal{L}{KL}\left( p^s\left( y_c | \tilde{o}{s_i} \right) \middle| p^t\left( y_c | \tilde{o}{t_i} \right) \right) Lunsupcon=i=0∑∣o~t∣wiLKL(ps(yc∣o~si) pt(yc∣o~ti))
总损失为:
L t o t a l = L l a b e l + L u n s u p c o n s \mathcal{L}{total} = \mathcal{L}{label} + \mathcal{L}_{unsup}^{cons} Ltotal=Llabel+Lunsupcons
5 实验分析
5.1 对比实验
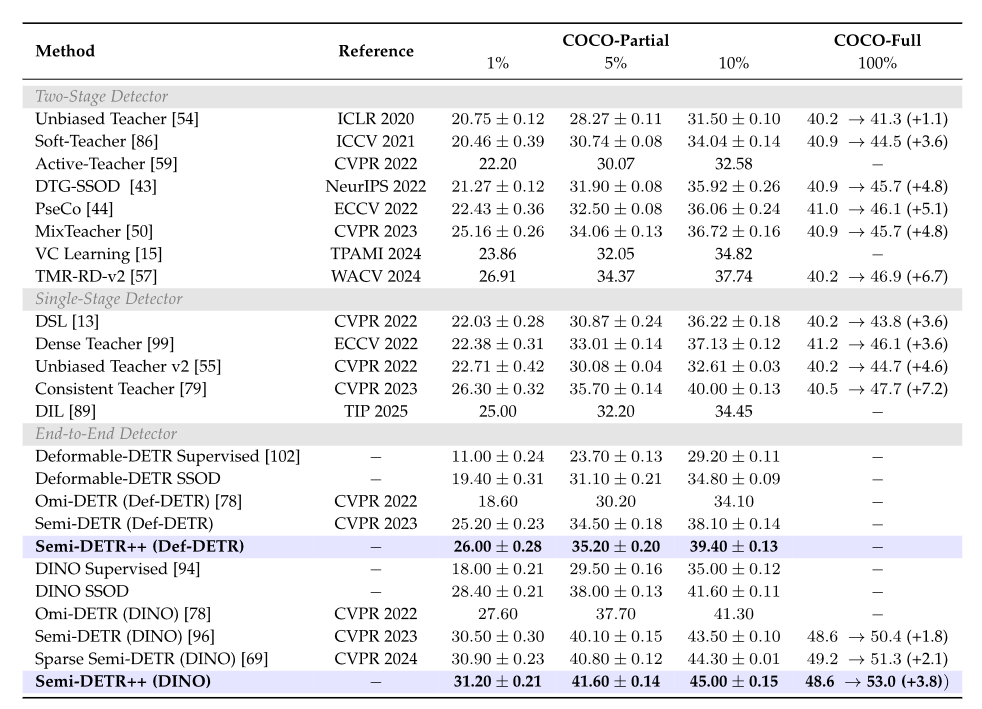
实验在 MS-COCO 基准上进行,涵盖 1%、5%、10% 标注数据的 Partial 设置和全标注数据的 Full 设置。结果显示,Semi-DETR++ 在所有数据比例下均建立了新的 SOTA 性能。基于 DINO 骨干的 Semi-DETR++ 在 1%、5%、10% 标注数据下分别达到 31.2、41.6 和 45.0 mAP,相比之前的最优方法 Sparse Semi-DETR 分别提升 0.3、0.8 和 0.7 mAP。在全标注数据设置下,Semi-DETR++ 将 DINO 监督基线从 48.6 mAP 提升至 53.0 mAP,提升幅度达 3.8 个点,显著超过了所有基于 CNN 和 DETR 的半监督方法。
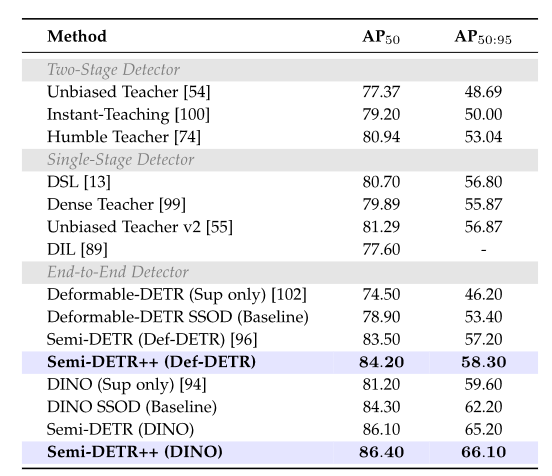
在 PASCAL VOC 基准上,Semi-DETR++ 同样取得了最优性能。基于 Deformable-DETR 骨干的模型达到 84.2 AP50 和 58.3 AP50:95,基于 DINO 骨干的模型进一步提升至 86.4 AP50 和 66.1 AP50:95,全面超越了所有两阶段和单阶段 CNN 检测器,验证了端到端半监督检测框架的优越性。
5.3 消融实验
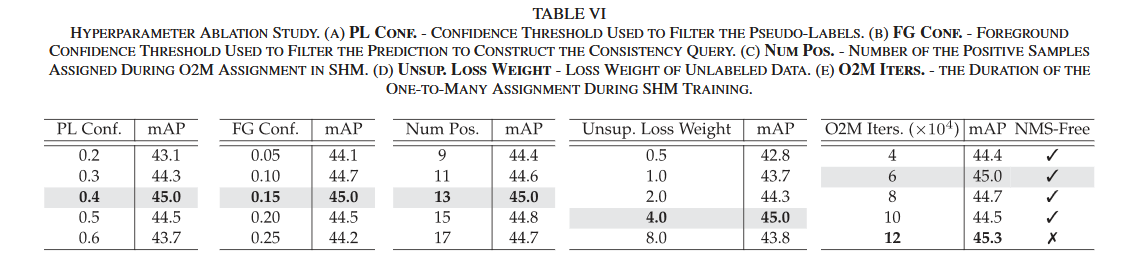
实验在 COCO 10% 标注数据设置下进行,结果表明阶段式混合匹配 (SHM) 和重解码查询一致性 (RQC) 两个模块均对性能有显著贡献。单独引入 SHM 可带来 2.4 mAP 的提升,单独引入 RQC 可带来 1.9 mAP 的提升,两者结合使用时产生协同效应,最终达到 45.0 mAP 的性能。

对一致性查询来源和损失形式的消融实验表明:重解码查询 (RD) 显著优于随机查询和之前的跨视图查询 (CV),仅使用分类一致性损失比同时使用分类和回归损失效果更好。最优配置为使用教师模型的重解码查询作为位置引导,学生模型使用相同的位置查询进行重解码,仅施加分类一致性损失,最终达到 45.0 mAP 的性能。
6 个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本文立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。