关于多GPU相关的内容目前还没发实践哩,自己的电脑只有1个GPU,实验室服务器is working~~~
📈 等空闲了再看吧~~~
1 理论线性
1.1 数据增广
在深度学习中,数据增广(Data Augmentation)是一种通过对现有训练数据进行各种"变换",从而人工生成更多多样化样本的技术。
其核心目的在于:提高模型的泛化能力,防止过拟合。
在课程中主要讲解的是对图像数据做增广------ 简单来说,就是让模型在看到由于光照、角度、遮挡等产生的变体时,依然能认出目标。

下面是一个由于模型的泛化能力弱导致出现误差的案例。对于语音识别也是一样,室内、室外,不同的音色可能都会对初始模型的测试效果造成影响。

在训练集中需要尽可能考虑到实际测试时遇到的各种场景,提高模型的泛化性能。
(个人觉得此处不太严谨,下面的操作应该是++数据增广++------侧重于"广度"的扩张,让模型看到更多样化的样本空间,扩大数据的分布范围;而++数据增强++带有"质量提升"的意味)

一般的做法是加载原始数据后,在线随机生成扩展后的数据用于训练(注意不是一次生成后存储到本地用作新数据),可以认为是一个正则项,在测试的时候不会对数据做增广。
1.2 常见图像增广方式
注意:上下翻转不总是可行,要保持处理后的图像至少是合理的。
使用PS工具处理进行变形处理通常结合实际测试集可能出现的情况。




2 代码实现
2.1 常用的图像增广方式
python
%matplotlib
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
d2l.set_figsize()
img = d2l.Image.open("img/cat.jpg")
d2l.plt.imshow(img)//输出:
这里的 aug 表示增广处理的方式:
python
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):
Y = [aug(img) for _ in range(num_rows * num_cols)]
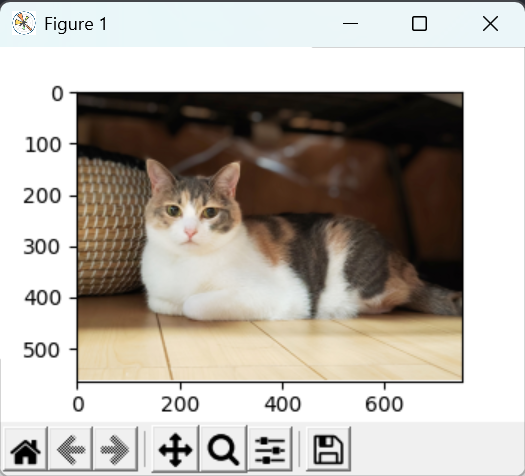
d2l.show_images(Y, num_rows=num_rows, num_cols=num_cols, scale=scale)(1) 水平翻转和垂直翻转
python
apply(img, torchvision.transforms.RandomHorizontalFlip())
python
apply(img, torchvision.transforms.RandomVerticalFlip())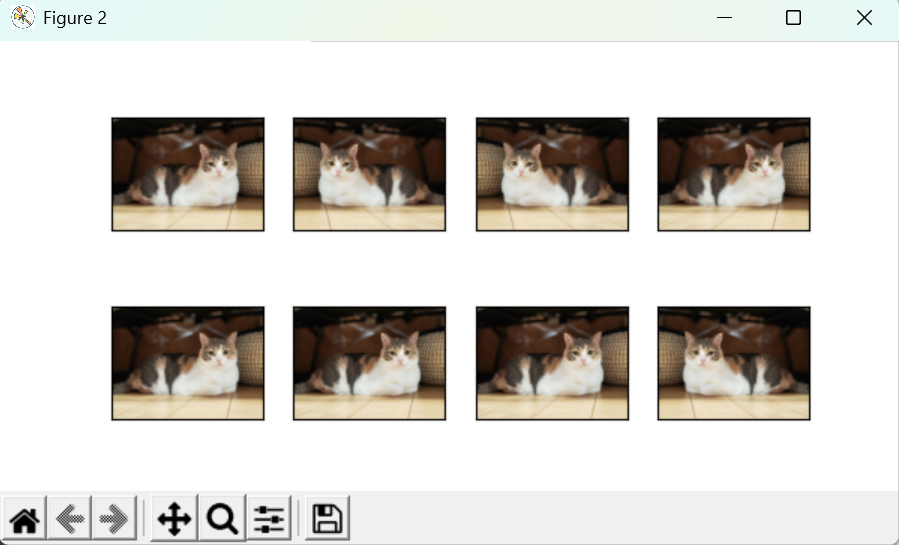
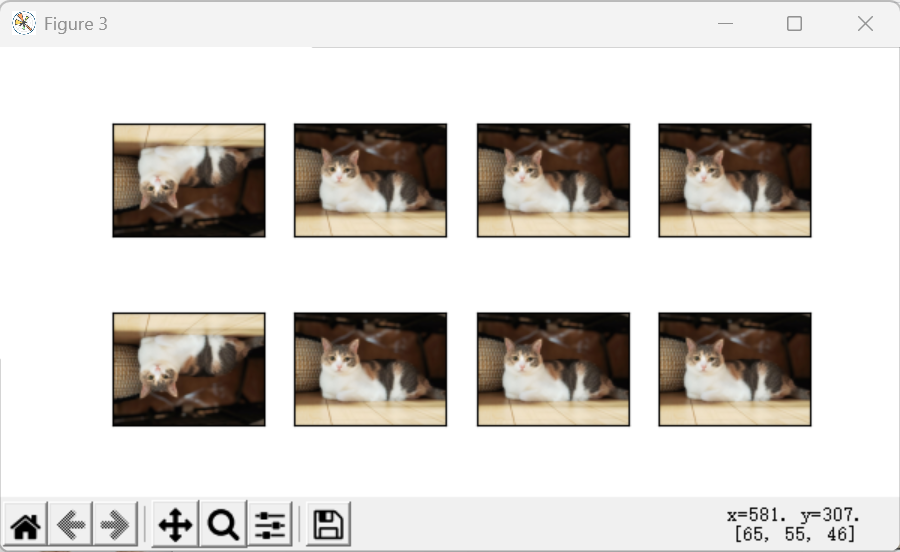
(2) 尺寸重置
python
shape_aug = torchvision.transforms.RandomResizedCrop(
(200, 200), scale=(0.1, 1), ratio=(0.5, 2)
)
apply(img, shape_aug)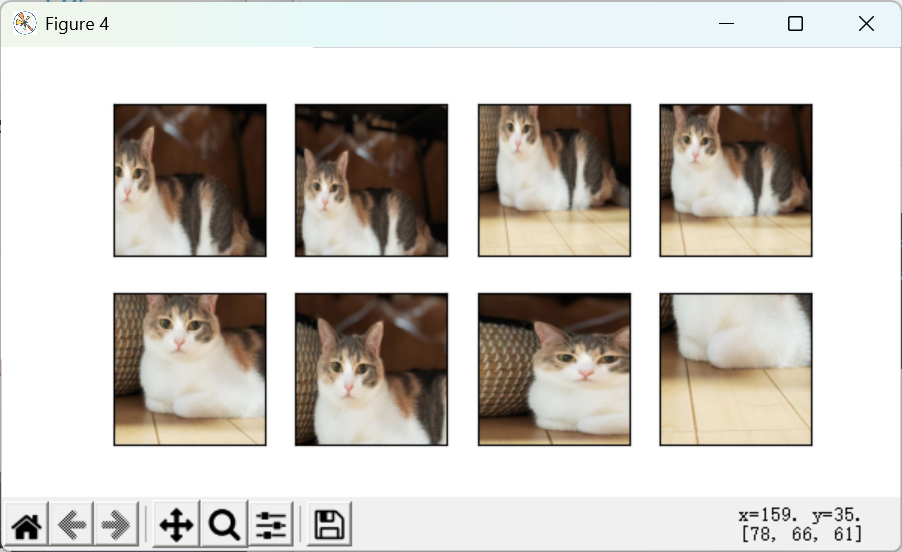
(3) 亮度与色调修改(分别)
python
apply(img, torchvision.transforms.ColorJitter(
brightness=0.5, contrast=0, saturation=0, hue=0))
python
apply(img, torchvision.transforms.ColorJitter(
brightness=0, contrast=0, saturation=0, hue=0.5))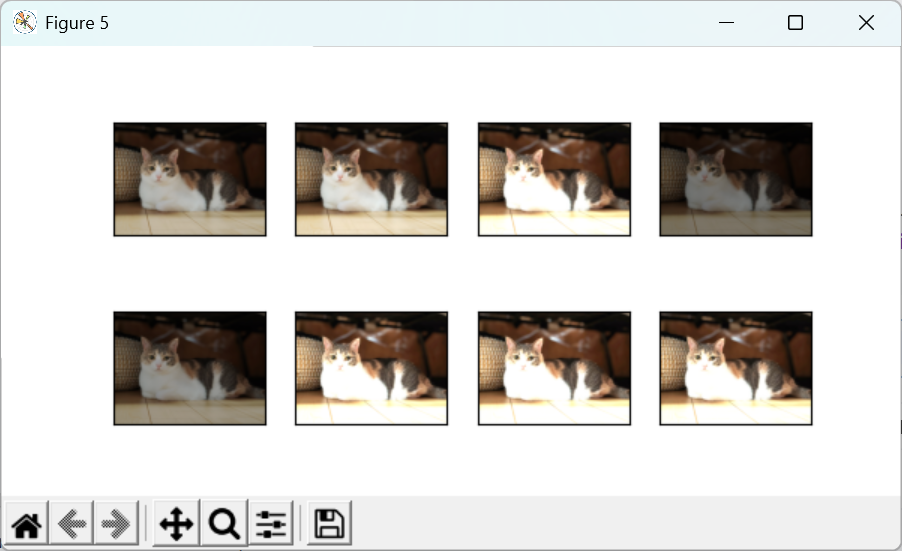
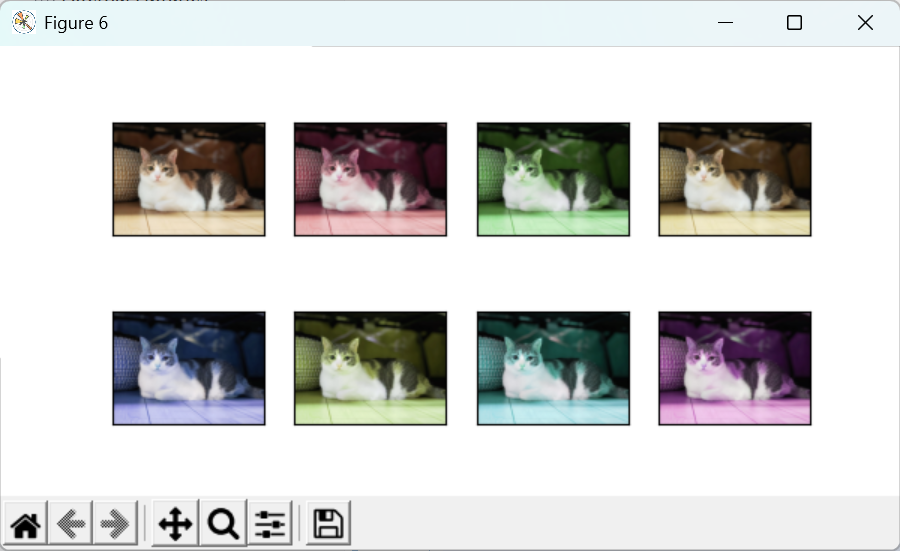
亮度、对比度、饱和度、色调同时修改:
python
color_aug = torchvision.transforms.ColorJitter(
brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)
apply(img, color_aug)
(4) 结合多种图像增广方法
python
augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),
color_aug, shape_aug])
apply(img, augs)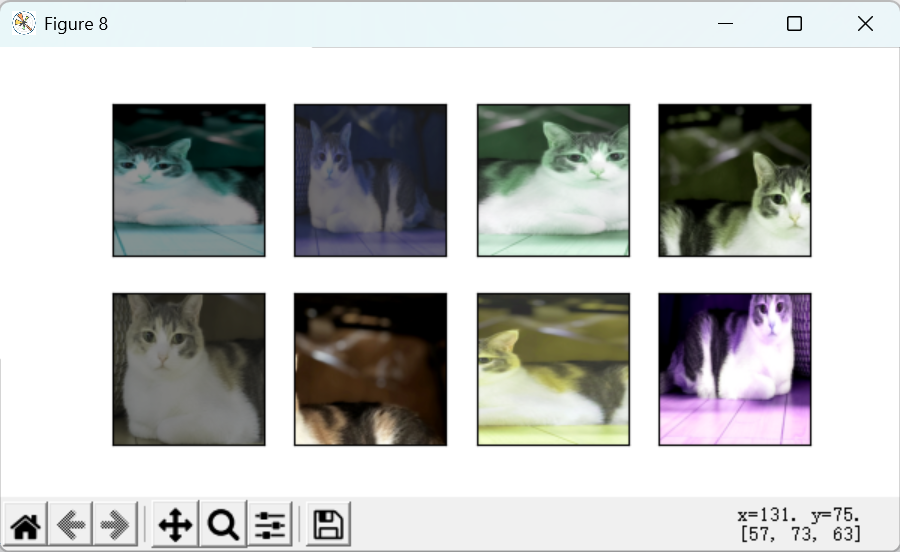
2.2 使用图像增广进行训练
CIFA10数据集是ImageNet采样了10个类,入门数据集,比FashionMNIST稍微难一点点。
(download=True通过代码下载可能很慢,可以科学上网下载之后到本地指定文件夹下打开)
下载链接:https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
python
all_images = torchvision.datasets.CIFAR10(
train=True, root='./data', download=False)
d2l.show_images([
all_images[i][0] for i in range(32)], 4, 8 , scale=0.8)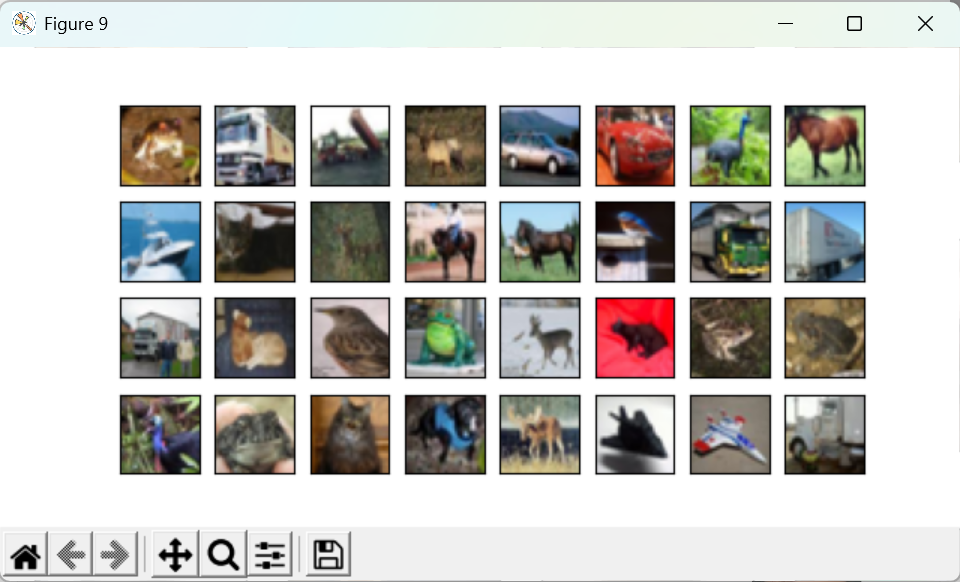
由于测试集和训练集是比较相似的,所以不要做太狠的图像增广,否则可能得到不好的效果。这里只做最简单的随机左右翻转。
python
# 训练增广:水平翻转
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor()])
# 测试集不处理
test_augs = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()])定义一个辅助函数,以便于读取图像和应用图像增广。
python
def load_cifar10(is_train, augs, batch_size):
dataset = torchvision.datasets.CIFAR10(
root="./data", train=is_train, transform=augs
)
# 对于图像做增广,最好多开几个进程,因为对于图像的处理是一件比较贵的事情,计算量大
dataloader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, shuffle=is_train, num_workers=4)
return dataloader我们在CIFAR-10数据集上训练ResNet-18模型。 接下来定义一个函数,使用多GPU对模型进行训练和评估。(代码比较好理解,但是太繁琐主包直接Copy书上的代码了,电脑上只有单个GPU没关系,d2l.try_allgpu()会返回只包含一个GPU的列表,不会报错)
python
#@save
def train_batch_ch13(net, X, y, loss, trainer, devices):
"""用多GPU进行小批量训练"""
if isinstance(X, list):
# 微调BERT中所需
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
#@save
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices=d2l.try_all_gpus()):
"""用多GPU进行模型训练"""
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
# 4个维度:储存训练损失,训练准确度,实例数,特点数
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch_ch13(
net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(devices)}')训练设置:
Adam优化器
Adam(Adaptive Moment Estimation)是目前深度学习中的最常用的的优化算法之一。它结合了Momentum(动量法) 和 RMSProp(自适应学习率) 的优点,能够为不同的参数动态调整学习率。
🐩 🐩 🐩 (具体的内容单独开一节来说吧~)
(1) 数学原理
Adam的核心在于维护两个变量:一阶矩(梯度的均值)和二阶矩(梯度的未中心化方差)。假设
是 第 t 步的梯度,其更新公式如下:
(2) Adam 的主要特点
- **自适应步长:**对于梯度较大的数,Adam会减小其学习率;对于梯度较小的参数,Adam会增加其学习率;
- 超参数鲁棒性:默认设置通常就能表现得很好。
- 高效性:内存需求第,计算开销与梯度更新成正比,非常适合处理大规模数据和高维参数空间。
(3) 与其他优化器的对比
优化器 核心特点 优缺点 SGD 每次只选一个样本 计算快,但容易在鞍点徘徊,收敛慢。 Momentum 引入惯性 加快收敛,减少震荡,有助于越过局部极小值。 RMSProp 自适应学习率 解决了深度学习中学习率消失或过快的问题。 Adam Momentum + RMSProp 集大成者,收敛快,适合大多数复杂模型(如 Transformer, CNN)。 🎯 (4) 什么时候不该用 Adam?
虽然 Adam 几乎是"万能"的,但在某些特定场景下需要谨慎:
泛化性: 在某些纯计算机视觉任务中,经过精细调优的 SGD with Momentum 有时能获得比 Adam 更好的测试集泛化性能。
权重衰减(Weight Decay): 传统的 Adam 在处理


python
# 批量大小,GPU设备,网络设置(10,3分别表示类别数量和通道数)
batch_size, devices, net = 256, d2l.try_all_gpus(), d2l.resnet18(10, 3)
# 使用 xavier 初始化权重
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
def train_with_data_aug(train_augs, test_augs, net, lr=0.001):
# 增广的训练集
train_iter = load_cifar10(True, train_augs, batch_size)
# 正常测试集
test_iter = load_cifar10(False, test_augs, batch_size)
# 交叉熵
loss = nn.CrossEntropyLoss(reduction="none")
# 设置 Adam 优化器
trainer = torch.optim.Adam(net.parameters(), lr=lr)
# 训练-绘图函数
train_ch13(net, train_iter, test_iter, loss, trainer, 10, devices)训练:
python
# 训练集图像增广
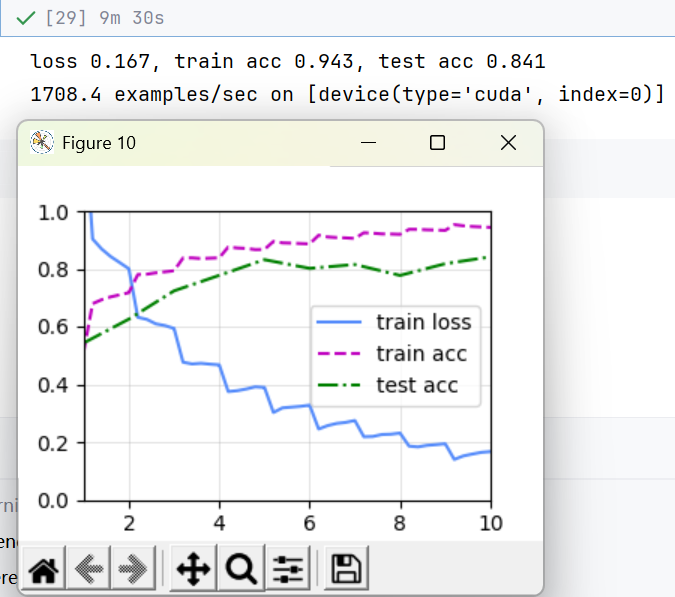
train_with_data_aug(train_augs, test_augs, net)
python
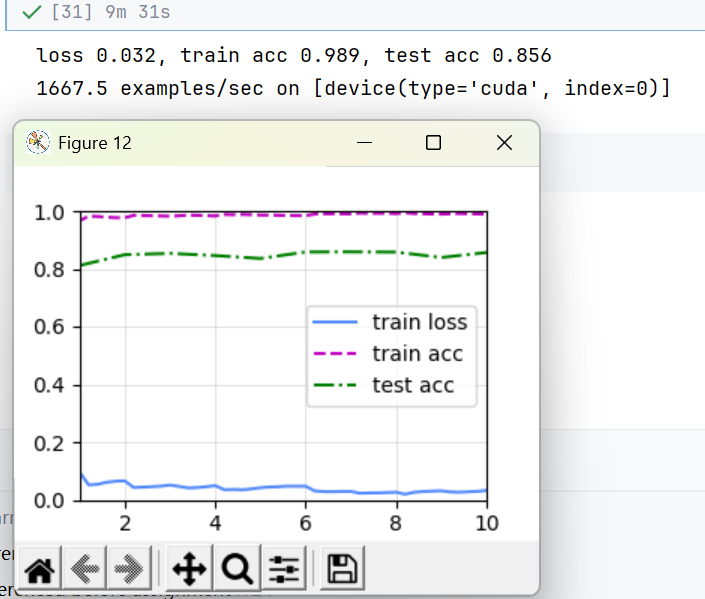
# 训练集无图像增广(用测试的test_augs)
train_with_data_aug(test_augs, test_augs, net)//输出:可以看到训练集不作增广之后,出现了非常明显的过拟合!train loss从一开始就很低,不过测试精度却变高了一点,个人认为本身训练集和训练集是比较相近的,所以精度才会更高。
总结
数据增广通过变形数据来获取多样性从而是的模型泛化性能更好,可以用在各种数据上,常见图片增广包括反转、切割、变色等。