线程池
- 为什么要使用线程池?
- 线程池的核心实现:ThreadPoolExecutor
-
- 核心构造参数⭐
-
- 核心线程数:corePoolSize
- 最大线程数:maximumPoolSize
- 非核心线程空闲存活时间:keepAliveTime
- [统一表示时间的单位: unit](#统一表示时间的单位: unit)
- 工作队列:workQueue
- 线程工厂:threadFactory
- [拒绝策略: handler⭐](#拒绝策略: handler⭐)
- 任务执行流程⭐
- 常用的线程池类型
-
- [Executor 框架继承层级](#Executor 框架继承层级)
- [Executors 提供的工厂方法](#Executors 提供的工厂方法)
- [submit() 方法](#submit() 方法)
-
- [submit(Runnable task)](#submit(Runnable task))
- [submit(Runnable task, T result)](#submit(Runnable task, T result))
- [submit(Callable<T> task) ⭐ 最常用](#submit(Callable
task) ⭐ 最常用) - 三种方式的对比
- [submit() vs execute()](#submit() vs execute())
- [submit() 执行流程](#submit() 执行流程)
- [为什么阿里规范不建议使用 Executors 创建线程池?⭐](#为什么阿里规范不建议使用 Executors 创建线程池?⭐)
- 手撕线程池
为什么要使用线程池?
在Java EE应用中,如果每次需要执行任务时都创建一个新线程,会带来以下问题:
- 资源消耗大:线程的创建和销毁都需要消耗系统资源
- 稳定性差:无限制创建线程会导致系统资源耗尽
- 管理困难:无法统一管理线程的状态和生命周期
线程池通过复用线程解决了这些问题,能够有效控制并发线程数量,提高系统响应速度。
线程池的核心实现:ThreadPoolExecutor
Java提供了java.util.concurrent.ThreadPoolExecutor作为线程池的标准实现。
核心构造参数⭐
java
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 空闲线程存活时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 任务队列
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略
)核心线程数:corePoolSize
线程池初始化时会创建的核心线程数量 。这些线程会一直存活(除非显式设置 allowCoreThreadTimeOut=true,允许核心线程空闲时被销毁)。当有任务提交时,优先由核心线程执行;核心线程全忙时,任务才会进入工作队列。
最大线程数:maximumPoolSize
线程池能容纳的最大线程数 (核心线程 + 非核心线程)。当工作队列满了,且当前线程数小于最大线程数时,线程池会创建非核心线程 来处理任务;非核心线程在空闲时会被销毁(由 keepAliveTime 控制),实现线程数量的自适应调整。
非核心线程空闲存活时间:keepAliveTime
非核心线程在空闲状态 下允许存活的最长时间。超过该时间,非核心线程会被销毁,回收资源(核心线程默认不因空闲被销毁,除非开启 allowCoreThreadTimeOut)。
统一表示时间的单位: unit
TimeUnit unit 通过枚举定义时间单位 ,让 keepAliveTime(或其他时间参数)的语义更明确,避免因时间单位歧义导致的逻辑错误(比如误将"毫秒"当"秒"用,导致线程存活时间过短/过长)。
NANOSECONDS:纳秒(1秒 = 10⁹ 纳秒)MICROSECONDS:微秒(1秒 = 10⁶ 微秒)MILLISECONDS:毫秒(1秒 = 10³ 毫秒)SECONDS:秒(最常用)MINUTES:分钟(1分钟 = 60秒)HOURS:小时(1小时 = 60分钟)DAYS:天(1天 = 24小时)
工作队列:workQueue
用于存放待执行任务的阻塞队列 。当核心线程都在处理任务时,新提交的任务会进入队列等待;队列满了,才会触发非核心线程的创建。线程池本质是生产者-消费者模型 (submit/execute 任务是"生产者",线程是"消费者",队列是缓冲区)。
线程工厂:threadFactory
作用 :用于创建线程的工厂类,可自定义线程属性(如线程名称、优先级、是否为守护线程等),方便调试和监控线程池中的线程(如给线程命名"pool-1-thread-1"便于定位问题)。
拒绝策略: handler⭐
作用 :当线程池和队列都满了(即达到 maximumPoolSize 且队列满),新提交的任务会被拒绝 ,handler 定义了拒绝时的处理逻辑(如抛异常、由调用者执行任务、丢弃任务等)。
常见策略:
AbortPolicy(默认):抛RejectedExecutionException异常。CallerRunsPolicy:由提交任务的线程(调用者)执行任务。DiscardPolicy:直接丢弃任务。DiscardOldestPolicy:丢弃队列中最老的任务,尝试加入新任务。
任务执行流程⭐
当向线程池提交一个任务时,执行顺序如下:
可视化入口
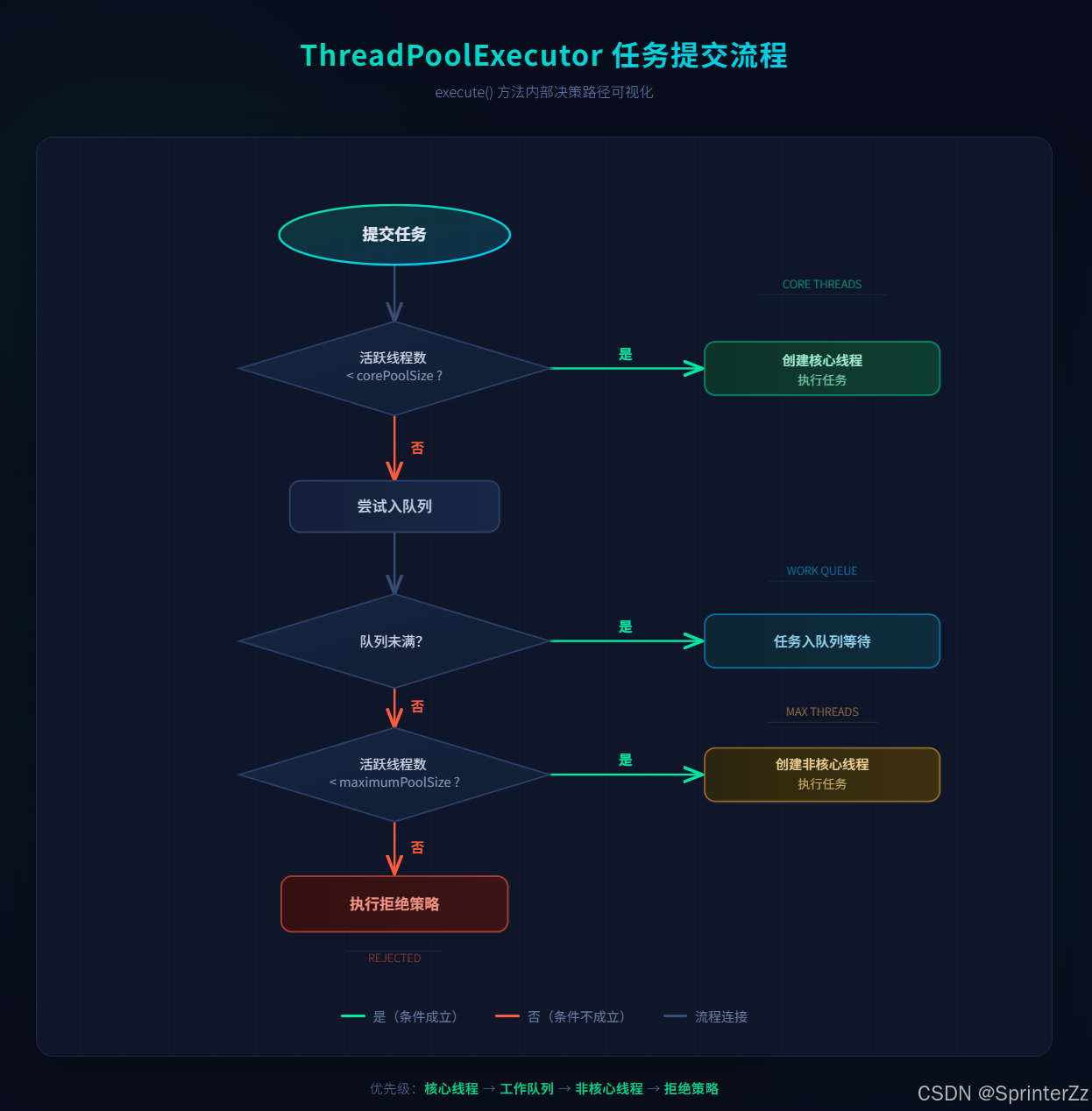
常用的线程池类型
Java标准库通过 Executors 工具类,基于工厂设计模式 对 ThreadPoolExecutor 进行了封装,简化了线程池的创建和使用。
Executor 框架继承层级

Executors 提供的工厂方法
| 工厂方法 | 返回类型 | 特点 | 隐藏风险 |
|---|---|---|---|
newFixedThreadPool(int n) |
ThreadPoolExecutor | 固定线程数,使用无界队列 | 队列无界,任务积压可能导致 OOM |
newCachedThreadPool() |
ThreadPoolExecutor | 线程数动态增长,空闲线程存活60秒 | 最大线程数无限制,高并发时创建大量线程可能导致 OOM 或系统崩溃 |
newSingleThreadExecutor() |
ThreadPoolExecutor | 单线程串行执行 | 同样使用无界队列,任务积压风险 |
newScheduledThreadPool(int n) |
ScheduledThreadPoolExecutor | 支持定时/延迟任务 | 同样存在无界队列风险 |
FixedThreadPool⭐
java
ExecutorService pool = Executors.newFixedThreadPool(5);- 核心线程数 = 最大线程数,线程数量固定
- 使用无界队列
LinkedBlockingQueue - 适用:负载较重的服务器
CachedThreadPool⭐
java
ExecutorService pool = Executors.newCachedThreadPool();- 核心线程数为0,最大线程数为Integer.MAX_VALUE
- 空闲线程存活60秒
- 使用同步队列
SynchronousQueue - 适用:大量短生命周期的任务
SingleThreadExecutor
java
ExecutorService pool = Executors.newSingleThreadExecutor();- 只有一个核心线程,所有任务串行执行
- 适用:保证任务按顺序执行的场景
ScheduledThreadPool
java
ScheduledExecutorService pool = Executors.newScheduledThreadPool(3);- 支持定时和周期性任务执行
- 适用:延迟任务、定时任务
submit() 方法
submit() 是 ExecutorService 接口中定义的核心方法,用于向线程池提交任务并返回一个 Future 对象,便于获取任务执行结果或跟踪任务状态。
java
// 提交 Runnable 任务,返回 Future<?>,get() 返回 null
Future<?> submit(Runnable task);
// 提交 Runnable 任务,并指定返回结果
<T> Future<T> submit(Runnable task, T result);
// 提交 Callable 任务,返回 Future<T>,get() 返回计算结果
<T> Future<T> submit(Callable<T> task);submit(Runnable task)
java
ExecutorService pool = Executors.newFixedThreadPool(2);
Future<?> future = pool.submit(() -> {
System.out.println("执行任务...");
// 模拟耗时操作
Thread.sleep(1000);
});
// get() 返回 null,因为 Runnable 没有返回值
Object result = future.get(); // result = null
System.out.println("任务完成,结果:" + result);特点:
- 返回
Future<?>,泛型类型是Void future.get()返回null- 主要用途:等待任务执行完成,而非获取结果
submit(Runnable task, T result)
java
ExecutorService pool = Executors.newFixedThreadPool(2);
// 定义一个结果对象
String resultObj = "初始值";
// 提交任务,并指定返回的结果
Future<String> future = pool.submit(() -> {
System.out.println("执行任务...");
// 注意:Runnable 内部无法修改 resultObj 的引用指向,
// 但可以修改 resultObj 对象的内部状态
}, resultObj);
// get() 返回的是传入的 resultObj 对象
String result = future.get();
System.out.println("结果:" + result); // 结果:初始值典型使用场景 :需要知道哪个任务完成了,配合一个可变的容器对象使用:
java
ExecutorService pool = Executors.newFixedThreadPool(3);
List<Future<AtomicInteger>> futures = new ArrayList<>();
for (int i = 0; i < 10; i++) {
AtomicInteger counter = new AtomicInteger(i);
Future<AtomicInteger> future = pool.submit(() -> {
// 模拟业务处理
Thread.sleep(100);
// 注意:这里可以修改 counter 的内部状态
counter.set(counter.get() * 2);
}, counter);
futures.add(future);
}
for (Future<AtomicInteger> future : futures) {
AtomicInteger result = future.get();
System.out.println("处理结果:" + result.get());
}submit(Callable task) ⭐ 最常用
java
ExecutorService pool = Executors.newFixedThreadPool(2);
Future<Integer> future = pool.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
// 执行计算,可以返回结果
int sum = 0;
for (int i = 1; i <= 100; i++) {
sum += i;
}
return sum;
}
});
// Lambda 写法
Future<Integer> future2 = pool.submit(() -> {
int sum = 0;
for (int i = 1; i <= 100; i++) {
sum += i;
}
return sum;
});
Integer result = future.get(); // 阻塞直到获取结果
System.out.println("1+2+...+100 = " + result); // 5050特点:
Callable有返回值,且可以抛出受检异常Future.get()返回计算结果- 企业开发中最常用的方式
三种方式的对比
| 方法签名 | 返回值获取 | 异常处理 | 适用场景 |
|---|---|---|---|
submit(Runnable) |
get() 返回 null |
通过 Future.get() 捕获 |
只需要等待完成,不需要结果 |
submit(Runnable, T) |
get() 返回传入的对象 |
通过 Future.get() 捕获 |
需要标识完成的任务 |
submit(Callable<T>) |
get() 返回计算结果 |
通过 Future.get() 捕获 |
需要异步计算结果的场景 |
submit() 让代码有了跟踪和控制异步任务的能力,这是 execute() 无法做到的。在实际企业开发中,优先使用 submit(Callable) 来处理异步任务。
submit() vs execute()
| 特性 | execute(Runnable) |
submit(Runnable/Callable) |
|---|---|---|
| 返回值 | void |
Future<T> |
| 获取执行结果 | ❌ 不支持 | ✅ 支持 |
| 捕获异常 | 需在任务内捕获 | ✅ 可通过 Future.get() 捕获 |
| 取消任务 | ❌ 不支持 | ✅ 支持 |
| 判断任务完成状态 | ❌ 不支持 | ✅ 支持 |
submit() 执行流程
text
提交任务
↓
┌─────────────────────────────────────────┐
│ submit(Runnable) / submit(Callable) │
└─────────────────────────────────────────┘
↓
将 Runnable/Callable 包装成 RunnableFuture
↓
添加到工作队列,等待线程执行
↓
线程执行任务,捕获异常或计算结果
↓
任务完成,结果/异常存储在 Future 中
↓
调用 future.get() 获取结果(阻塞)为什么阿里规范不建议使用 Executors 创建线程池?⭐
《阿里巴巴Java开发手册》中明确提到:
【强制】 线程池不允许使用
Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
原因一目了然:
Executors.newFixedThreadPool和newSingleThreadExecutor使用的队列是LinkedBlockingQueue,默认容量为Integer.MAX_VALUE,高并发下任务积压会导致 内存溢出Executors.newCachedThreadPool和newScheduledThreadPool最大线程数为Integer.MAX_VALUE,可能创建大量线程导致 CPU 和内存耗尽
| 方式 | 优点 | 缺点 |
|---|---|---|
Executors 工厂类 |
代码简洁,使用方便 | 存在 OOM 风险,参数不透明 |
手动 new ThreadPoolExecutor |
参数可控,安全性高 | 代码稍显冗长 |
生产环境一定要手动创建 ThreadPoolExecutor,显式指定队列大小和拒绝策略。开发测试或简单场景可以酌情使用 Executors。
手撕线程池
MyThreadPool核心设计思想
这个线程池主要由两部分组成:
- 任务队列(BlockingQueue):负责存放待执行的任务。
- 工作线程 :负责从队列中取出任务并执行。
MyThreadPool是消费者,main方法(提交任务的代码)是生产者。
MyThreadPool的导入与属性
java
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
class MyThreadPool {
private BlockingQueue<Runnable> queue = null;- 为什么用
BlockingQueue? 它是线程安全的。普通集合(如ArrayList)在多线程下需要手动加锁,而BlockingQueue内部已经处理好了并发问题。 - 为什么用
ArrayBlockingQueue? 这是一个有界队列(指定容量为1000)。使用有界队列可以防止任务无限堆积导致内存溢出(OOM)。用别的也是OK的。
构造方法:创建工作线程
java
public MyThreadPool(int n) {
queue = new ArrayBlockingQueue<>(1000);
for (int i = 0; i < n; i++) {
Thread t = new Thread(() -> {
try {
while (true) {
Runnable task = queue.take(); // 核心点1
task.run(); // 核心点2
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t.start();
}
}- 核心点1
queue.take():如果队列里没有任务,take()方法会让当前线程阻塞等待,不会占用 CPU 资源。一旦有任务放入队列,线程会被自动唤醒。 - 核心点2
task.run():注意这里是直接调用run()方法,而不是start()。这意味着任务是在当前的工作线程中同步执行的,并没有创建新的线程。 while (true):让工作线程一直存活,不断拉取任务,实现线程复用。
提交任务方法:submit()
java
public void submit(Runnable task) throws InterruptedException {
queue.put(task);
}queue.put(task):将任务放入队列。如果队列已满(达到了1000),put()方法也会阻塞,直到队列有空闲位置。
测试
java
public static void main(String[] args) throws InterruptedException {
MyThreadPool pool = new MyThreadPool(10); // 创建10个工作线程
for (int i = 0; i < 100; i++) {
int id = i; // 核心点3
pool.submit(() -> {
System.out.println(Thread.currentThread().getName() + " id=" + id);
});
}
}- 核心点3
int id = i;:Lambda 表达式内部使用的外部变量必须是事实上的 final (effectively final)。在 for 循环中i是一直在变化的,如果直接在 Lambda 里写i,编译会报错。通过int id = i;创建了一个局部变量,每次循环id都没有被重新赋值,满足了 final 的要求,从而可以安全地在 Lambda 中使用。