书目信息 :《大数据平台架构》
章节 :第2章 分布式理论基础
主编 :吕欣、黄宏斌
关键词:SMR, CAP, PACELC, Paxos, Raft, PBFT, 视图切换
文章目录
- [2.1 分布式系统概述:架构的范式转移](#2.1 分布式系统概述:架构的范式转移)
-
- [2.1.1 集中式与分布式的物理博弈](#2.1.1 集中式与分布式的物理博弈)
- [2.1.2 分布式系统的核心模型](#2.1.2 分布式系统的核心模型)
- [2.2 分布式存储理论:不可靠网络下的权衡](#2.2 分布式存储理论:不可靠网络下的权衡)
-
- [2.2.1 CAP 定理与 PACELC 的补充](#2.2.1 CAP 定理与 PACELC 的补充)
- [2.2.2 BASE 理论:柔性事务的实践](#2.2.2 BASE 理论:柔性事务的实践)
- [2.3 分布式共识:状态机复制(SMR)](#2.3 分布式共识:状态机复制(SMR))
-
- [2.3.1 Paxos 算法:共识的基石](#2.3.1 Paxos 算法:共识的基石)
- [2.3.2 Raft 算法:可理解性的胜利](#2.3.2 Raft 算法:可理解性的胜利)
- [2.3.3 PBFT 算法:拜占庭容错](#2.3.3 PBFT 算法:拜占庭容错)
- [2.4 本章总结](#2.4 本章总结)
2.1 分布式系统概述:架构的范式转移
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
2.1.1 集中式与分布式的物理博弈
计算机系统的演进史,本质上是算力需求与物理极限博弈的历史。在早期,数据处理主要依赖于集中式系统(Centralized System),即所有的硬件、软件及业务逻辑都高度集中在单一的中央服务器上。这种架构的优势在于设计简单、数据天然一致。然而,随着互联网数据的爆炸式增长,集中式系统遭遇了难以逾越的瓶颈:
- 扩展性瓶颈:垂直扩展(Scale-up)的边际成本呈指数级上升。
- 单点故障:中央节点的瘫痪意味着整个服务的彻底中断。
为了解决这一问题,分布式系统(Distributed System)应运而生。其核心思想是通过水平扩展(Scale-out),利用廉价的商用硬件构建集群,以数量换取性能。教材明确指出,分布式系统是由一组通过网络进行通信、为了完成共同任务而协调工作的计算机节点组成的系统。
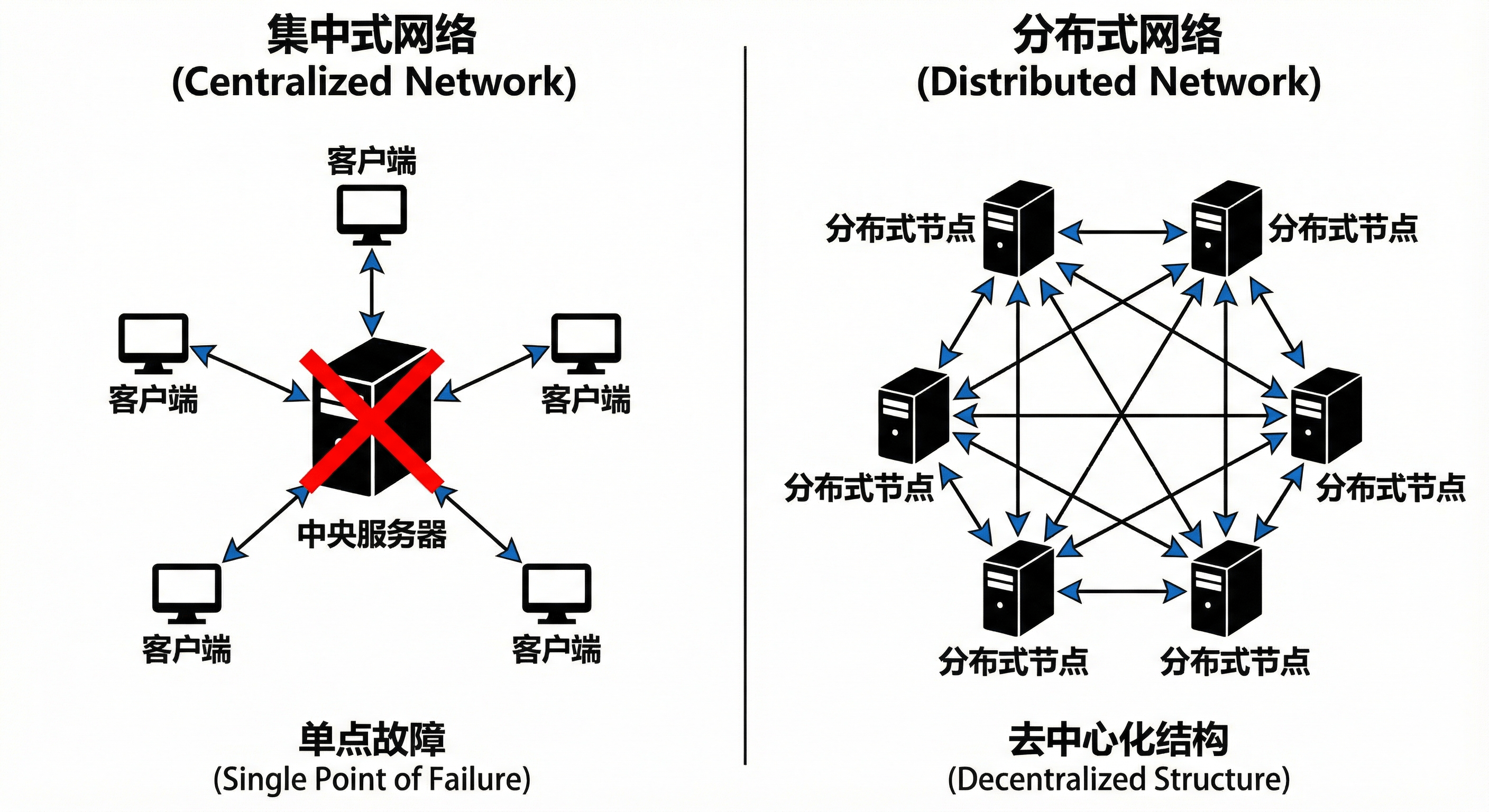
图2-1 集中式架构与分布式架构的拓扑对比
2.1.2 分布式系统的核心模型
在深入算法之前,教材构建了分布式系统的抽象模型,主要包含以下维度:
- 网络链路模型 :
- 公平损失链路:这是对现实网络的抽象。消息可能丢失,但如果无限次重传,最终会被接收。这是 Paxos 和 Raft 等算法运行的基础环境。
- 拜占庭链路:消息可能被恶意篡改,对应 PBFT 算法的应用场景。
- 时序模型 :
- 异步系统 :这是最复杂的环境,消息延迟没有上限。教材引出的 FLP 不可能定理 指出,在异步系统中,只要有一个节点崩溃,就不存在确定性的共识算法。这提示我们在工程实践中,必须引入**超时机制(Timeout)**将系统假设为"半同步"模型,才能解决共识问题。
2.2 分布式存储理论:不可靠网络下的权衡
分布式存储的核心矛盾在于:如何在不可靠的物理网络(异步、丢包)之上,构建可靠的数据一致性服务。这需要依赖数据分片 和数据复制技术,并遵循以下理论限制。
2.2.1 CAP 定理与 PACELC 的补充
CAP 定理 指的是一个分布式系统无法同时满足一致性(Consistency) 、可用性(Availability)和分区容错性(Partition Tolerance) 。由于网络分区(P)在广域网中是客观存在的必然,架构师只能在 CP (如 HBase,牺牲可用性保一致性)和 AP (如 Cassandra,牺牲一致性保可用性)之间做选择。
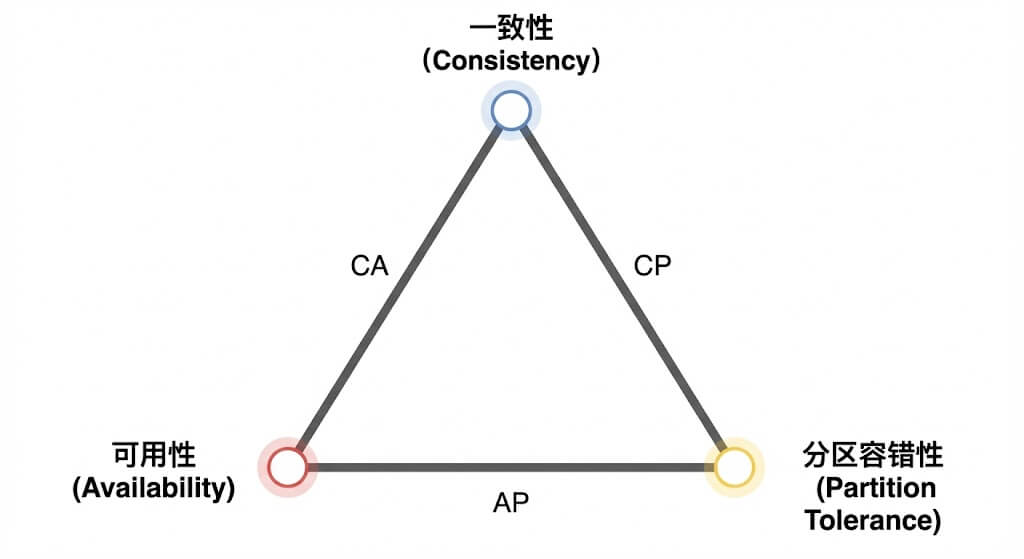
图2-2 CAP 定理
教材进一步引入了 PACELC 定理 对 CAP 进行补充。它指出:
- 如果有分区 §:在 A 和 C 之间选。
- 否则 (E, Else) :即使网络正常,系统也需要在 延迟 (Latency, L) 和 一致性 (Consistency, C) 之间选。
- 案例 :为了追求极低的写入延迟(L),许多数据库采用异步复制,但这必然牺牲了强一致性(C)。
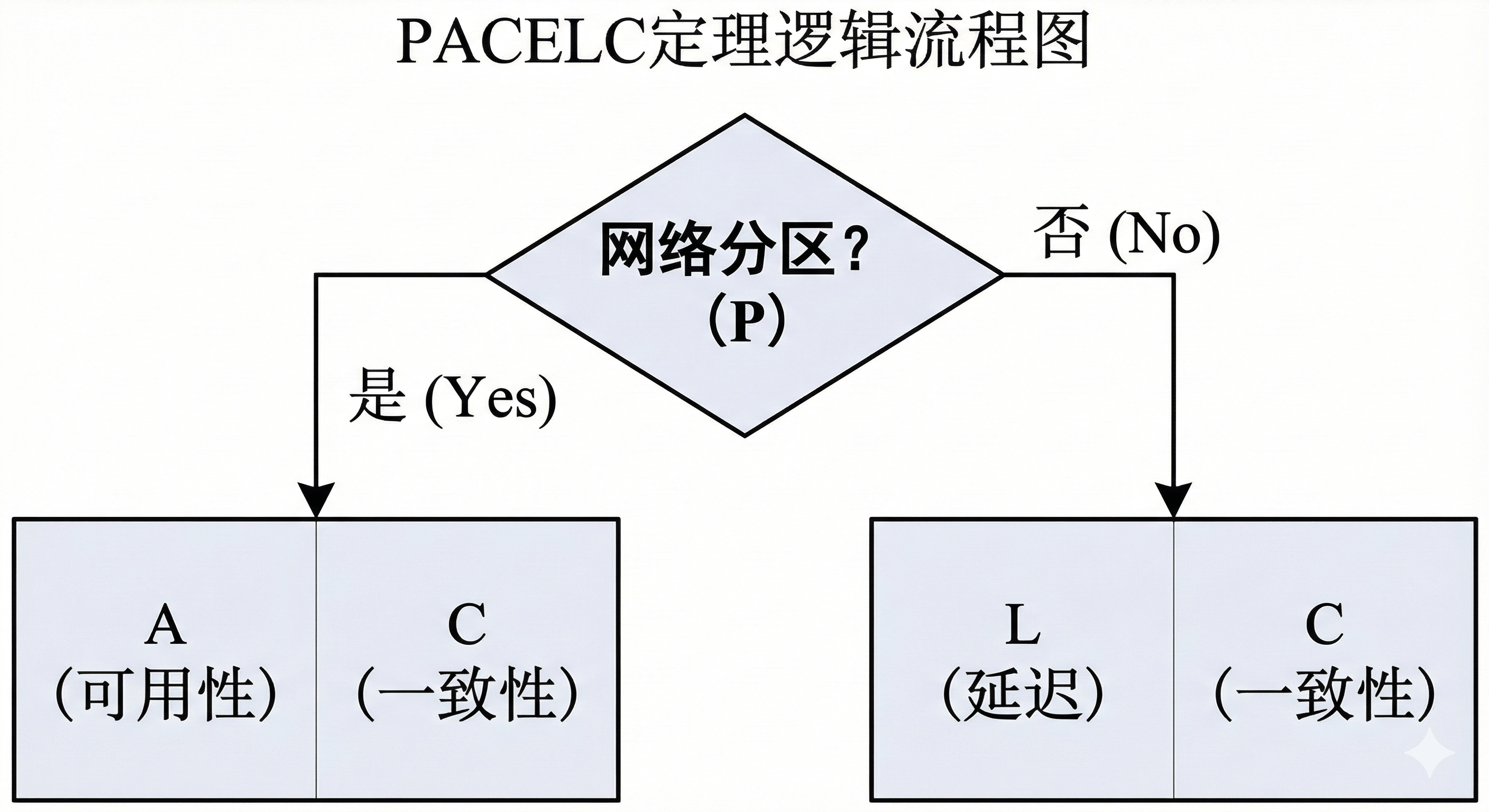
- 案例 :为了追求极低的写入延迟(L),许多数据库采用异步复制,但这必然牺牲了强一致性(C)。
图2-3 PACELC 定理流程图
2.2.2 BASE 理论:柔性事务的实践
为了适应互联网的高并发,eBay 架构师提出了 BASE 理论,作为对 ACID 的妥协:
- BA (Basically Available):基本可用。允许系统在故障时损失部分响应时间或功能。
- S (Soft state):软状态。允许数据存在中间状态(如"处理中")。
- E (Eventually consistent) :最终一致性。保证在经过一段时间的同步后,所有副本最终达到一致。
2.3 分布式共识:状态机复制(SMR)
分布式共识(Consensus)的核心目标是实现状态机复制(State Machine Replication, SMR):如果多个节点从相同的初始状态开始,按相同的顺序执行相同的命令(日志),那么它们最终会达到相同的状态。
2.3.1 Paxos 算法:共识的基石
Paxos 是解决非拜占庭故障的标准算法。它通过两阶段提交(Prepare/Promise -> Accept/Accepted)来达成一致。
- 活锁问题:Basic Paxos 存在活锁(Livelock)风险------当两个提议者不断以更高的编号抢占提案权时,谁也无法成功提交。
- 解决方案 :引入随机超时(Randomized Timeout) ,让出竞争机会。而在工程中,通常使用 Multi-Paxos ,通过选举唯一的 Leader 来避免竞争。
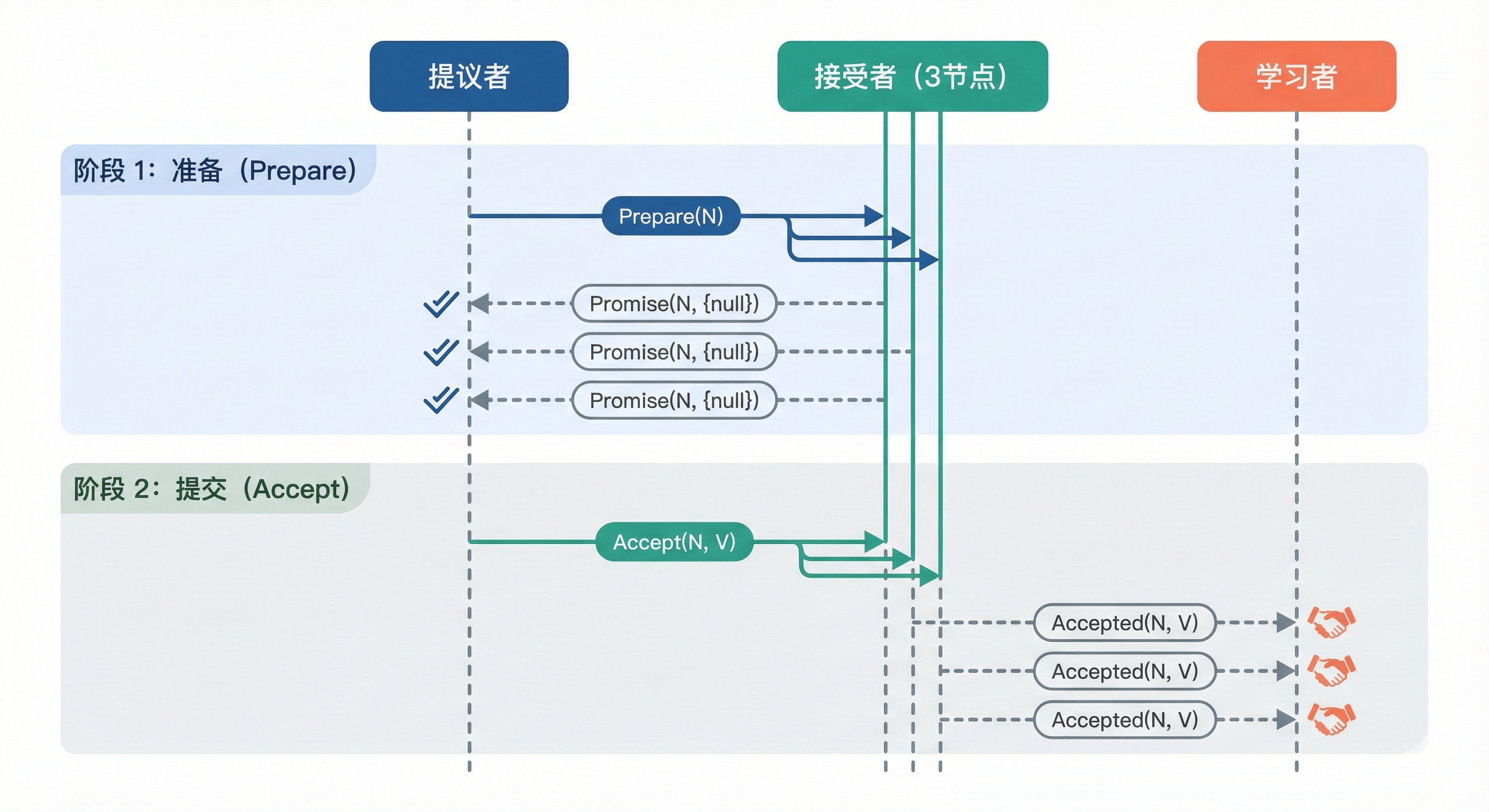
图2-4 Paxos 算法
2.3.2 Raft 算法:可理解性的胜利
为了降低 Paxos 的实现难度,Raft 算法将共识拆解为三个子问题。
1. 领导者选举(Leader Election)
Raft 使用心跳机制来维持 Leader 的权威。
- Leader 会定期向 Follower 发送心跳 (即空的
AppendEntries消息)。 - 如果 Follower 在选举超时时间(Election Timeout)内未收到心跳信号,则认为 Leader 已死,转为 Candidate 发起选举。
- 随机超时 :为了避免多个 Candidate 同时发起选举导致选票瓜分的死锁,Raft 要求节点随机选择选举超时时间(通常在 T, 2T 区间)。这保证了总有一个节点能先发起选举并胜出。
2. 日志复制(Log Replication)
Leader 接收客户端请求,将其写入本地日志,并并行复制给所有 Follower。只有当日志被大多数节点复制后,Leader 才会提交(Commit)该条目。
3. 安全性(Safety)
Raft 保证了拥有最新日志的节点才能当选 Leader,从而确保了已提交的数据绝对不会丢失。
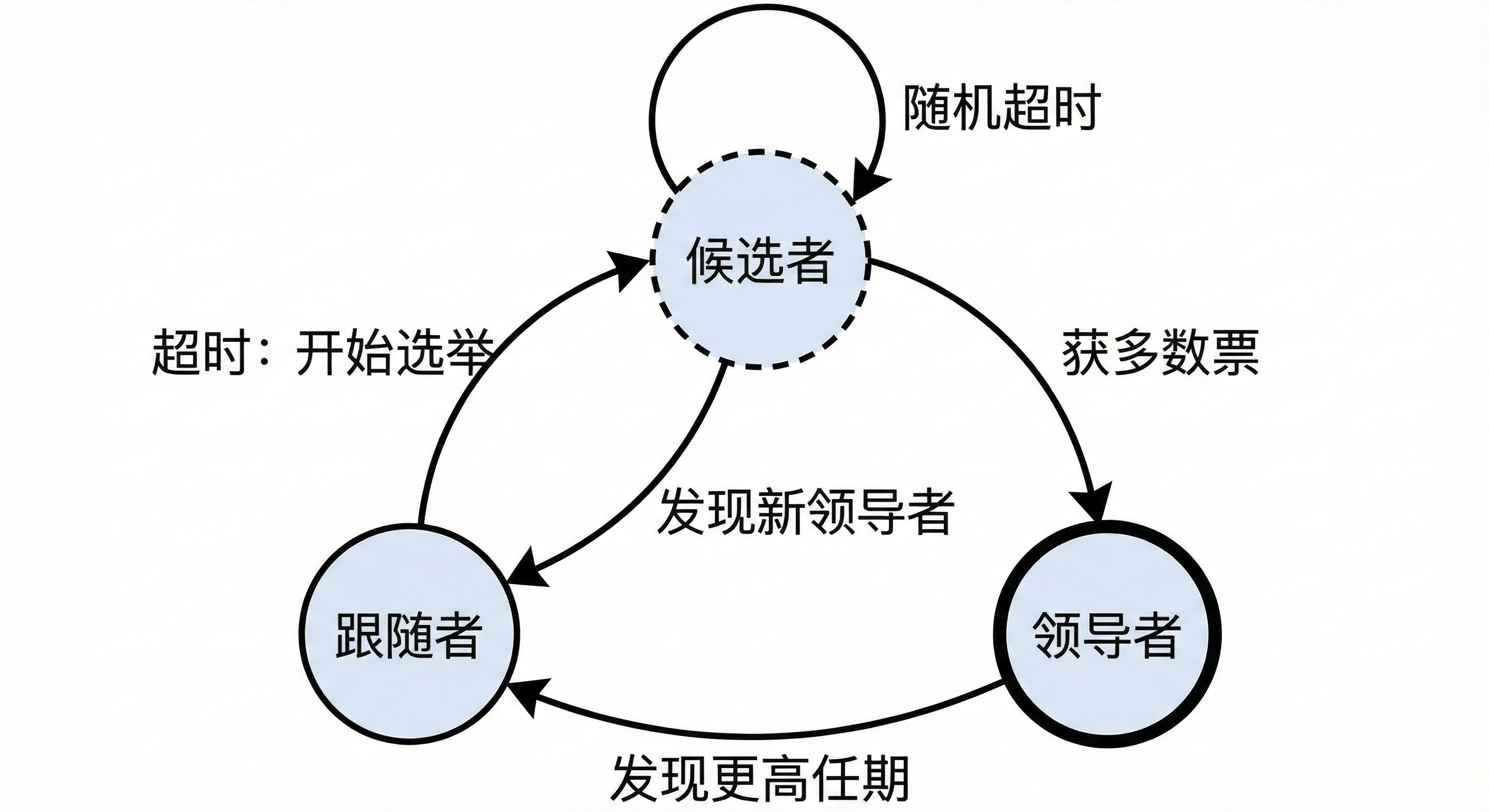
图2-5 Raft 算法
2.3.3 PBFT 算法:拜占庭容错
针对存在恶意节点的拜占庭故障 环境,教材详细介绍了 PBFT(实用拜占庭容错) 。该算法要求系统节点数 N ≥ 3 f + 1 N \ge 3f + 1 N≥3f+1( f f f 为恶意节点数)。
1. 三阶段协议
PBFT 通过 Pre-Prepare 、Prepare 、Commit 三个阶段的消息广播,确保在有恶意节点干扰的情况下,诚实节点仍能达成一致。其中 Prepare 和 Commit 阶段需要全网广播(All-to-All),通信复杂度较高。
2. 视图切换(View Change)
这是 PBFT 保证活性(Liveness)的关键机制。
- 触发条件:当从节点检测到主节点请求超时或行为异常时。
- 流程 :节点广播
<VIEW-CHANGE>消息。当新主节点收到足够多的视图切换请求后,广播<NEW-VIEW>,系统迁移到新视图继续运行。这防止了恶意主节点通过"不作为"来卡死系统。
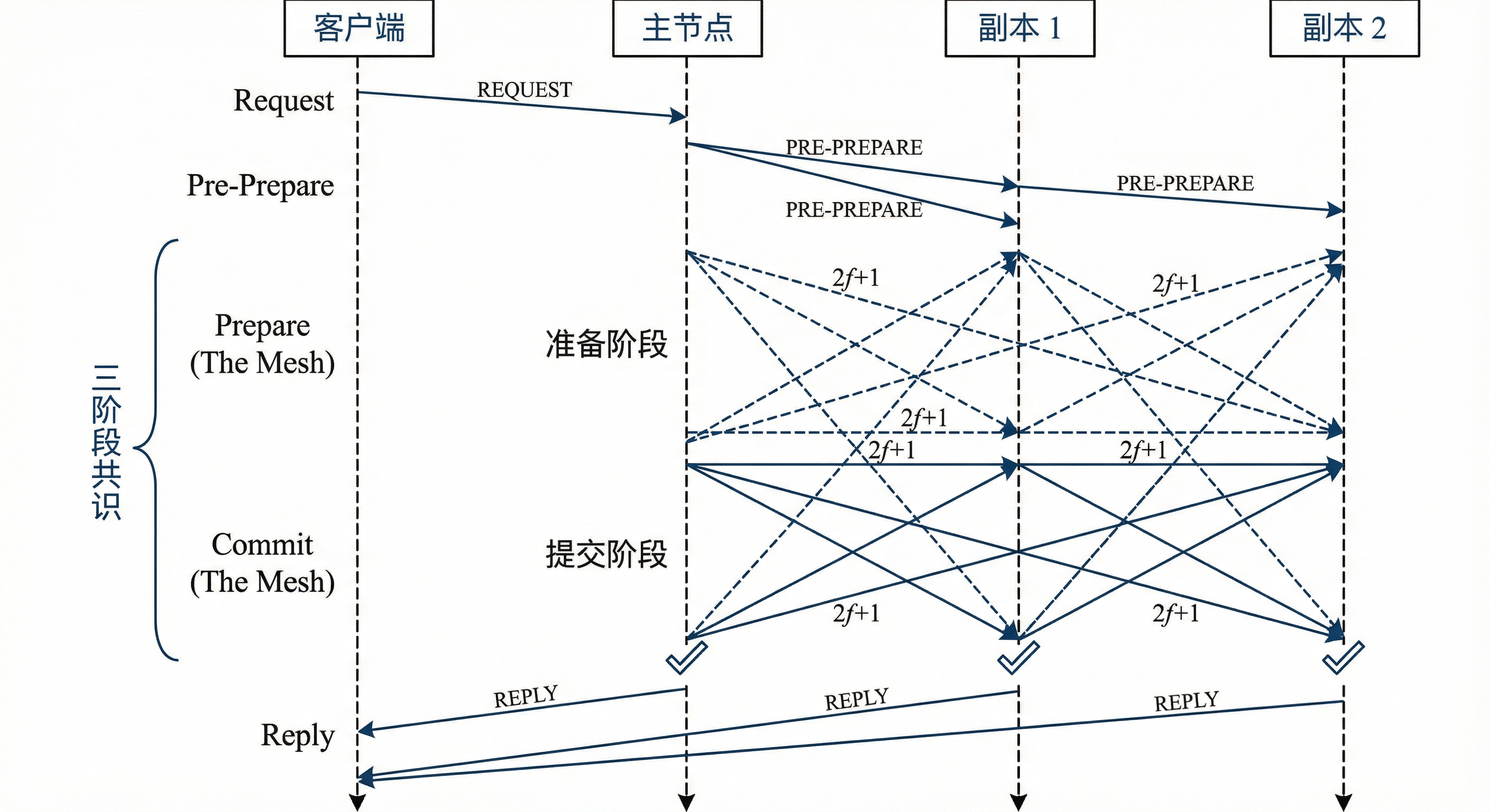
图2-6 PBFT 算法
2.4 本章总结
本章构建了大数据架构的理论地基:
- 权衡观:通过 CAP 和 PACELC,我们理解了在分布式设计中,"完美"是不存在的,只有根据业务场景的权衡。
- 非拜占庭环境 :Paxos 和 Raft 提供了可靠链路下的共识解法,是 Hadoop (ZooKeeper), Etcd 等组件的核心。
- 拜占庭环境 :PBFT 解决了不可信环境下的共识,是区块链技术的基石。
理解这些底层算法,是掌握后续章节中 Hadoop HDFS 的副本机制和 ZooKeeper 的 ZAB 协议的前提。
作者:栗子同学