项目地址 :github.com/lhz960904/c... 欢迎点个 star ⭐ 。
为什么做这个项目
过去很长一段时间我尝试使用了不少 Agent 框架------LangChain、Vercel AI SDK、Claude Agent SDK。感受是:这些工具封装得太好了,可以很快开发出 Agent 应用,但这反而让我对底层发生了什么产生很多疑惑和不安。所以促使我想从零自己实现一遍,真正去理解 ReAct 循环、工具调用、上下文压缩、沙箱隔离等等与 Agent 开发相关的技术细节。
code-artisan 就是这个「自己写一遍」的产物。它是一个参考 bolt.new / v0.dev 的 Web AI Coding Agent------可以在浏览器里用自然语言创建、编辑、运行代码,支持实时预览、PTY 终端、MCP 工具市场、内置 Skills。
从 2026-03-27 第一个 commit 到今天(2026-04-27),整整 31 天、215 个 commit。现在它开源了,整体架构还算简洁,希望对同样在探索 AI Agent 的朋友有参考价值。
它能做什么
- ReAct Agent 驱动:用自然语言描述需求,Agent 自主规划步骤、调用工具、执行命令、调试错误
- 完整工具链 :内置 9 个工具(
read_file/write_file/str_replace/bash/glob/grep/ls/web_search/web_fetch),Agent 可以像开发者一样操作代码库 - Skills 加速:内置全栈脚手架 Skill(Vite + React + Hono + Bun),告诉 Agent「搭一个全栈 demo」,它知道该怎么做
- MCP 工具市场:一键安装 MCP Server,Agent 下一轮自动获得新工具,能力可以持续扩展
- 实时预览 + PTY 终端 :代码跑在 E2B 沙箱里,
expose_port工具一键把端口暴露给浏览器 iframe;Agent 和用户共用一套真实的 PTY 终端 - 多模型支持 :Anthropic 原生 + 任意 OpenAI 兼容网关(DeepSeek、Kimi 等),通过
LLM_BASE_URL环境变量一键切换
技术架构全景
项目是一个 pnpm monorepo,分 5 个包,关注点彻底解耦:
| 包 | 职责 | 核心依赖 |
|---|---|---|
@code-artisan/agent |
核心 SDK:Agent 类、tool loop、middleware、Sandbox 接口 | @anthropic-ai/sdk、openai、zod |
@code-artisan/backend |
API 层:Hono server、SSE、E2BSandbox、PTY 管理 | hono、@e2b/code-interpreter、drizzle-orm |
@code-artisan/frontend |
UI 层:Vite + React + Tailwind + shadcn/ui + TanStack Router | react、@tanstack/router、zustand |
@code-artisan/cli |
终端版 Agent,纯 SDK 消费方 | ink |
@code-artisan/shared |
跨包共享类型 | zod |
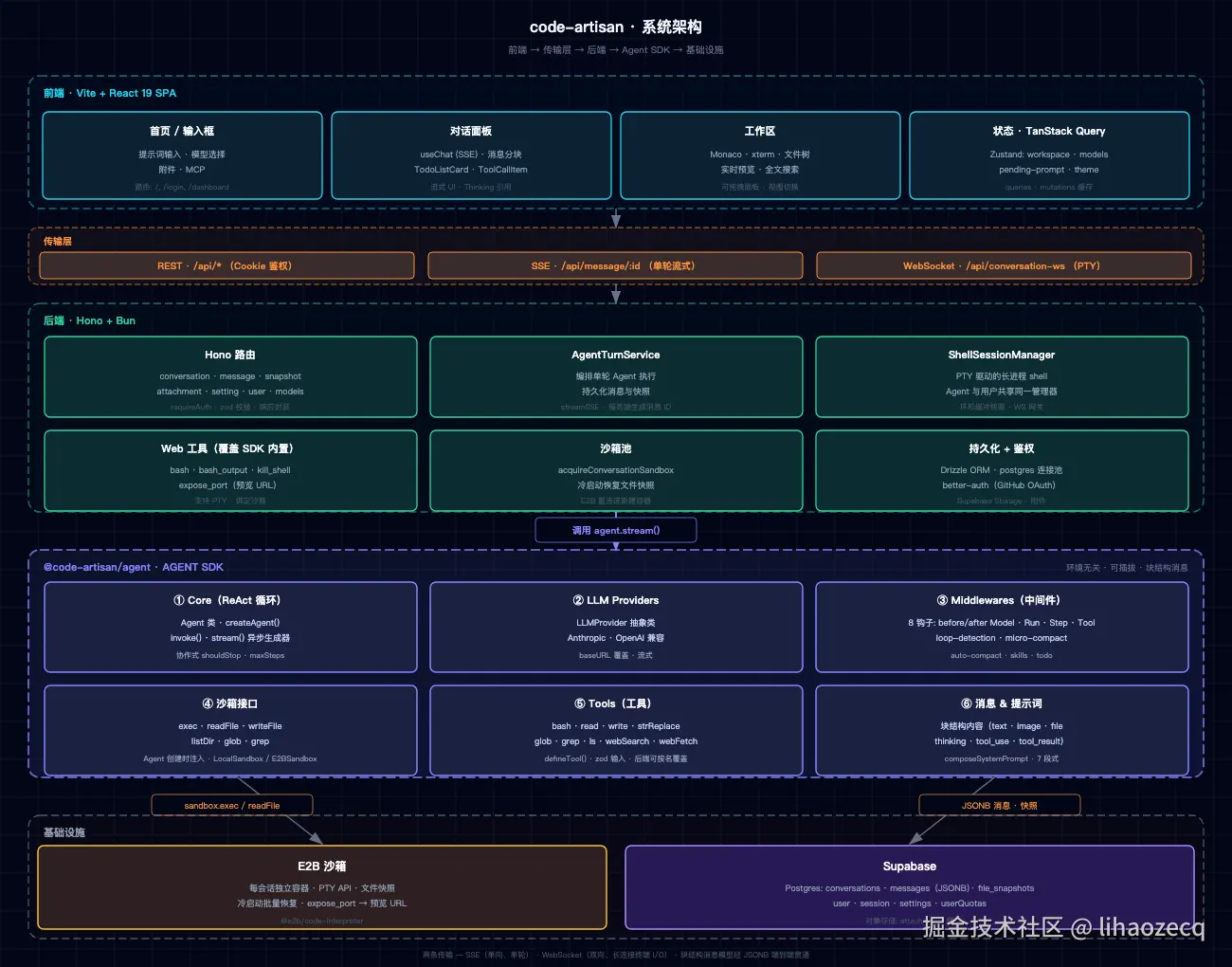
核心模块设计
一、ReAct Agent Loop & 多模型支持
ReAct(Reasoning + Acting)是目前 Coding Agent 的核心范式:模型先思考、再调用工具、再根据工具结果继续思考,循环直到任务完成或没有新的工具调用。
code-artisan 没有使用任何 Agent 框架,所以自己实现了这个循环------核心逻辑大约 340 行 TypeScript:
我也参考 LangChain 和 Vercel AI SDK 支持了多模型接入。目前主流的接口协议其实就两种------Anthropic 和 OpenAI 兼容协议,所以内置了两个 Provider,支持通过 LLM_BASE_URL 指向任意兼容网关(DeepSeek、Kimi、aihubmix 等)。
多模型支持通过 Provider 接口实现,只需实现两个方法:
typescript
interface LLMProvider {
invoke(params: InvokeParams): Promise<AssistantMessage>
stream(params: StreamParams): AsyncGenerator<AssistantMessage>
}stream() 是一个 AsyncGenerator,yield 两种事件:partial(流式增量)和 message(完整消息),消费方按需选择 mode: "token" 或 mode: "message"。
二、内置核心工具:让 Agent 变成 Coding Agent
一个普通的 ReAct Agent 只是个会用工具的聊天机器人。让它成为真正的 Coding Agent,需要一套完整的文件系统和 Shell 操作工具。code-artisan 内置了以下 9 个工具,全部通过 Sandbox 抽象层执行:
| 工具 | 用途 |
|---|---|
read_file |
读取文件内容(支持行范围) |
write_file |
写入文件,自动创建目录 |
str_replace |
在文件里做精确字符串替换(增量编辑) |
bash |
执行 bash 命令,支持 run_in_background 模式(见踩坑章节) |
ls |
列出目录 |
glob |
按 glob pattern 找文件 |
grep |
按正则在文件内容里搜索 |
web_search |
联网搜索 |
web_fetch |
抓取网页正文(搜索之后读完整内容) |
工具通过 defineTool() 注册,每个工具有 Zod schema 定义的入参和 invoke(input, ctx) 执行函数。ctx 里注入了 sandbox(执行环境)和 abortSignal(取消信号),工具本身不关心底层是本地还是云沙箱。
三、中间件设计:横切关注点的解耦
想要将 Agent 投入生产,往往需要很多额外的逻辑。如果都堆在主循环里,会让 Agent SDK 臃肿不可维护。所以参考 LangChain,我设计了 8 个生命周期钩子形成完整的中间件系统:
| 钩子 | 触发时机 | 典型用途 |
|---|---|---|
beforeAgentRun |
整个 Agent 任务开始前 | 初始化资源、注入 system prompt 片段 |
afterAgentRun |
整个 Agent 任务结束后 | 持久化结果、清理资源 |
beforeAgentStep |
每一轮 LLM 调用前 | 上下文压缩判断 |
afterAgentStep |
每一轮 LLM 调用后 | 死循环检测、日志埋点 |
beforeModel |
调用模型前最后一刻 | 修改 messages、prompt caching |
afterModel |
模型返回后最早 | 改写 assistant 消息 |
beforeToolUse |
每个工具调用前 | 权限检查、审计 |
afterToolUse |
每个工具调用后 | 文件追踪、增量同步 |
code-artisan 内置了 5 个开源社区已有共识的中间件:
- MicroCompact :上下文里堆积了大量
tool_result时,把最早的 N 条替换为占位符,从而降低 token 消耗 - AutoCompact:整个对话上下文超过 token 阈值时,调用廉价模型总结历史,插入一条总结 user message,之前内容不再传给模型
- LoopDetection :用 MD5 对
(toolName + input)哈希维护一个滑动窗口,检测重复调用------Agent 卡在同一个文件上反复操作时触发,设置shouldStop优雅退出 - Skills:按需加载 SKILL.md 元数据到 system prompt(详见模块五)
- Todo:让 Agent 写出可视化任务列表,支撑长任务
每个中间件都是一个普通函数,返回 Partial<AgentContext> 来修改上下文,互相独立,可组合。
四、沙箱设计:安全隔离的执行环境
让 Agent 在用户的机器上直接执行任意 Shell 命令是不现实的------安全隔离是 Web Coding Agent 的基本前提。每个对话都需要一个独立的执行环境,文件操作和命令执行必须限制在沙箱边界内。
code-artisan 把沙箱抽象成一个 6 方法的接口:
typescript
interface Sandbox {
exec(command: string, options?: ExecOptions): Promise<ExecResult>
readFile(path: string): Promise<string>
writeFile(path: string, content: string): Promise<void>
listDir(path: string): Promise<FileEntry[]>
glob(pattern: string, path: string): Promise<GlobResult>
grep(pattern: string, path: string): Promise<GrepResult>
}Agent SDK 本身完全不关心沙箱实现------本地调试用 LocalSandbox(直接跑 Node.js),线上用 E2BSandbox,通过依赖注入在 Agent 创建时传入。
为什么选 E2B,不用 WebContainers?
WebContainers 是在浏览器里跑一个虚拟 Linux,乍一看很酷,但实际尝试下来问题很多:文件系统 API 不是标准 POSIX,很多 npm 包和 Shell 命令跑不起来;网络访问受到浏览器安全策略限制;E2B 是云端真实 Linux 容器,启动快、API 完整、可以挂自定义模板(code-artisan 用了一个预装 Bun + Skills 的自定义模板)。这部分细节后面会单开一篇文章讲。
五、Skills 系统:可扩展的任务加速器
Agent 是通用的,但实际任务往往集中在少数场景。与其每次从零推理,不如把这些场景的"最佳实践"固化下来。
在 code-artisan 里,Skills 就是一组放在沙箱中的 SKILL.md 文件,带有 frontmatter 元数据 + 可执行指引。
是按需加载机制,而不是一股脑塞进 prompt。
createSkillsMiddleware 会在 beforeAgentRun 阶段扫描目录,抽取每个 Skill 的最小信息(name / description / path),注入到 system prompt:
text
<skill_system>
<skills>[ { name, description, path } ... ]</skills>
</skill_system>Agent 只拿到"技能目录",而不是完整内容。当它判断当前任务命中某个 Skill 时,才会通过 read_file 拉取对应的 SKILL.md,再按里面的步骤执行。
这样做有两个直接好处:
- 控制上下文体积:避免 prompt 被大量低相关内容污染
- 保持灵活性:Skill 可以随时扩展,不影响主流程
code-artisan 内置了一个全栈开发 Skill(hono-fullstack),覆盖"从 0 搭一个 Web 项目"的常见路径。Skills 存在于沙箱镜像(/opt/skills/)中,构建镜像时一并打包进去,运行时直接可用,没有额外加载成本。
六、MCP 支持:工具能力无限扩展
MCP(Model Context Protocol) 是 Anthropic 发布的开放协议,定义了 LLM 如何与外部工具交互的标准接口。越来越多的服务开始提供 MCP Server,意味着 Agent 的工具能力可以持续扩展,而不需要修改 Agent 本身的代码。
code-artisan 的实现思路:
- MCP 工具市场 :前端展示可用 MCP Server 目录(
mcp-registry.json),用户一键安装,配置存到用户 KV settings - Agent 启动时加载 :
McpToolSet读取用户已安装的 MCP Server 配置,通过StdioClientTransport建立连接,listTools()获取工具列表 - 工具包装 :每个 MCP 工具的 JSON Schema 通过
zod-from-json-schema转成 Zod schema,包装成标准的FunctionTool,与内置工具无缝混用 - Agent 自动感知:下一轮对话,新安装的工具就出现在 Agent 的工具列表里
期间踩过几个比较印象深刻的坑
1. 常驻进程(dev server)与 bash 超时冲突------Agent 无法感知服务是否启动
最初 bash 工具只有一条路:sandbox.exec(command) 同步等待命令退出。dev server 这类常驻进程永远不会退出,结果就是 Agent 一直卡在等 bash 返回,直到超时报错------但 timeout 之后 Agent 以为命令失败了,实际上服务可能已经成功启动。
更坏的情况:Agent 会尝试重启服务,多个 dev server 占用同一端口,然后全部报错,Agent 陷入死循环。
解决方案是参考 Claude Code 的设计,把 bash 工具拆成三个:
- bash :加
run_in_background参数。false走同步sandbox.exec;true开 PTY 会话,立即返回sessionId - bash_output :轮询指定会话的最新输出(带
offset游标),Agent 启动 dev server 后主动调用它来确认服务是否起来 - kill_shell:终止指定会话
system prompt 里加一条行为规则:run_in_background=true 后必须等 2 秒再调 bash_output 确认启动状态,如果 exitCode 非零,读 tail 自行诊断修复。Agent 从此可以「看着终端自己 debug」。
2. 终端输出没颜色、不能交互------从 SSE 桥接到 PTY + WebSocket 的重写
第一版终端实现用的是 spawn + SSE:命令输出通过 SSE 事件推给前端,前端把字符塞进 xterm.js。这个方案跑通了基本功能,但有三个致命问题:
- 颜色全失 :
spawn没有分配 TTY,进程检测到!process.stdout.isTTY后自动关闭 ANSI 输出。npm/vite/tsc 的彩色输出全变成灰白裸文本。前端只能手动在命令前后加颜色前缀,伪造一个「看起来像终端」的效果 - 无法交互 :SSE 是单向通道,用户输入无法传回沙箱。
Ctrl+C、Tab 补全、方向键历史全部失效 - Agent 感知不到进程状态:stdout/stderr 只推给了前端,没有进入 Agent 的 tool result,Agent 不知道服务有没有跑起来
最终完整重写:E2BSandbox 上增加私有 PTY API(sdk.pty.create),后端实现 ShellSessionManager 统一管理所有 PTY 会话(Agent 会话和用户会话共用一套),前端 terminal 通过独立 WebSocket 双向连接,原始 ANSI 字节直接透传给 xterm.js。
3. 性能问题:串行 I/O + 海外数据库 region,首屏 TTFB 高达 5 秒
测试过程中,我总感觉流式输出超级快(因为用的是国内模型),但每次等待第一条流式消息都要等很久,让我一度怀疑流式没有生效,更像是缓存后一次性 flush。埋点之后发现问题核心是 DB:
- DB 托管在 Supabase,默认部署在海外,单次 round-trip 700ms+
- 首屏链路是 5 步串行:
insertMessage→buildAgentMessages→acquireSandbox→checkQuota→ 调用 LLM - 五步串行下来 TTFB 轻松 4~5 秒
优化方向:
- 并行化 :
insertMessage、buildAgentMessages、acquireSandbox三件独立的事改成Promise.all并发执行 - fileTracker 增量扫描 :初始化时从 DB 快照预置文件清单,后续用
find -newer {mtime}增量 diff,跳过全量扫描 - quota 本地缓存 :
checkQuota加 LRU 内存缓存,DB 写入改 fire-and-forget
最终 TTFB 从 ~5s 降至 ~1s,效果非常明显。
4. 文件持久化 & 前端同步:只追踪 write_file 工具是不够的
最初的文件追踪逻辑只监听 write_file 工具的调用:每次 Agent 写文件,就把路径和内容存进 DB。测试过程频繁出现「Agent 跑完了,但有些文件没保存下来」的问题。
原因是 Agent 在很多情况下不用 write_file------它会直接用 bash 执行 echo "..." > file.ts、sed -i、mv、甚至 npm create 这类命令,生成大量文件,而这些完全绕过了工具层的监听。
解决方案是自己实现一个 mtime-based 文件 monitor:
- 基线:Agent run 开始时,记录所有文件的 sha256 + mtime 清单
- 增量 diff :每次工具执行后(
afterToolUse),如果是bash类工具,就跑find {workspaceRoot} -newer {lastCheckTime}找出变更文件 - 精确追踪 :
write_file这类直接文件工具,走路径直接追踪,不用 mtime - 推送 :变更文件通过
file_updateSSE 事件实时推给前端,文件树即时更新;run 结束后afterAgentRun做最终 diff,upsert 到 DB
5. 架构拆分不合理:用 CLI 场景做验证,理清楚了正确的包边界
早期开发图方便,把很多 web 特有的东西(PTY、run_in_background、spawn、ProcessHandle)直接塞进了 @code-artisan/agent 的 Sandbox 接口里。表面上看「功能能跑」,但架构上已经混乱了:一个「环境无关」的 Agent SDK 开始感知 PTY 和后台进程,LocalSandbox 里出现了一堆 web 才需要的实现。
真正的问题是缺少第二个消费场景来检验接口是否合理。
CLI 就是这把尺子 :我后来用 Ink 写一个终端版 Agent,只用 @code-artisan/agent,不依赖任何 backend 代码------CLI 用户本来就在真实 shell 里,根本不需要 PTY、不需要 bash_output、不需要 ShellSessionManager。用这个约束反推,Agent SDK 里的所有 PTY 相关代码都没有存在的理由,全部下沉到 backend 的 E2BSandbox 里,通过 createAgent({ tools: [...] }) 以注入方式传进来。
CLI 目前代码量非常轻,基础结构已经在,这也是一个很好的参与点------如果你对用 Ink 实现一个命令行 AI Agent 感兴趣,欢迎一起来做。
现在的包边界规则很简单:CLI 和 Web 都要用的,才放进 @code-artisan/agent;只有 Web 需要的,放进 @code-artisan/backend。
系列文章预告
这篇是开篇,后续我会按 6 个核心模块各开一篇深度展开:
- ReAct Agent Loop & 多模型支持------从 0 手写一个生产级 Agent 循环,以及 Provider 抽象怎么设计
- 内置工具链------工具注册机制、Zod schema 与工具调用、如何给 Agent 扩展自定义工具,如何在运行过程中主动提醒 Agent 调用工具
- 中间件系统------8 个钩子的设计哲学,MicroCompact / AutoCompact / LoopDetection 的实现细节
- 沙箱设计------为什么需要沙箱、E2B 接入全攻略、自定义沙箱模板、PTY API 实现
- Skills 系统------如何实现按需加载机制、如何让 Agent 真正「用好」Skills
- MCP 集成------MCP 协议原理、工具市场实现、如何把 MCP 工具无缝接入 Agent
最后
代码在 GitHub:github.com/lhz960904/c...
这是一个人在业余时间做的学习项目,代码不完美,欢迎提 PR 和建议。如果这个项目对你有帮助,欢迎点个 star ⭐。
也欢迎大家加我微信直接开聊,不限于该项目。
