LlamaIndex v0.10+ 深度解析:RAG专属框架的组件化全景
一、框架定位:RAG领域的"专精王者"
在大模型应用开发生态中,LlamaIndex(最新稳定版v0.10.68 ,2026年4月更新)是专注于私有数据与LLM连接的RAG专用框架。区别于LangChain的"全栈全能",它的核心设计哲学是**"数据优先、检索为王"**------所有组件围绕"文档加载→处理→索引→检索→问答"的RAG全链路构建,智能体编排仅作为附属能力存在。
简单来说:LangChain是"什么都能做的瑞士军刀",LlamaIndex是"专做RAG的精密手术刀" 。它不追求多智能体协作的灵活性,而是把文档解析、索引算法、检索精度做到行业顶尖,是企业级知识库、文档问答系统的首选框架。
二、核心架构:模块化RAG全链路
LlamaIndex的架构高度模块化,核心分为5大核心层+1个扩展层 ,所有组件均在llama_index.core命名空间下(v0.10+版本重大重构,统一核心包结构):
llama_index.core
├── connectors/ # 数据加载层(Data Loaders)
├── node_parsers/ # 文档处理层(Chunking)
├── indices/ # 索引存储层(Indexes,核心)
├── retrievers/ # 检索引擎层(Retrievers)
├── query_engines/ # 问答引擎层(Engines)
├── agents/ # 智能体扩展层(弱能力)
└── storage/ # 存储适配层(向量库/文档库)三、核心组件详解(v0.10+ 官方标准实现)
1. 数据加载层(Connectors):全数据源统一接入
核心作用 :将PDF、Markdown、数据库、API等异构数据,统一转换为LlamaIndex标准的Document对象。
- 基础加载器(内置)
SimpleDirectoryReader(llama_index.core.SimpleDirectoryReader):本地文件夹批量加载,支持PDF/TXT/MD/DOCX,自动识别文件格式。PDFReader(llama_index.readers.file.PDFReader):专业PDF解析,支持分页、提取图片文字(需pypdf)。WebReader(llama_index.readers.web.WebReader):网页内容抓取,支持HTML解析、去噪。
- 扩展加载器(LlamaHub)
- 数据库:
DatabaseReader(MySQL/PostgreSQL,llama_index.readers.database)。 - 云文档:
NotionReader/GoogleDriveReader(llama_index.readers.notion)。
- 数据库:
2. 文档处理层(Node Parsers):长文档智能分块
核心作用 :将Document切割为适合LLM处理的Node(文本块,含元数据),平衡"上下文完整性"与"向量检索精度"。
- 标准分块器(内置)
SentenceSplitter(llama_index.core.node_parsers.SentenceSplitter,默认):语义分块 ,按句子边界切割,保留语义连贯性,支持chunk_size(默认1024)、chunk_overlap(默认200)参数。TokenSplitter(llama_index.core.node_parsers.TokenSplitter):按Token数量切割,适配LLM上下文限制(如GPT-3.5/4)。MarkdownSplitter(llama_index.core.node_parsers.MarkdownSplitter):Markdown专用,按标题层级分块,保留文档结构。
- 高级分块策略
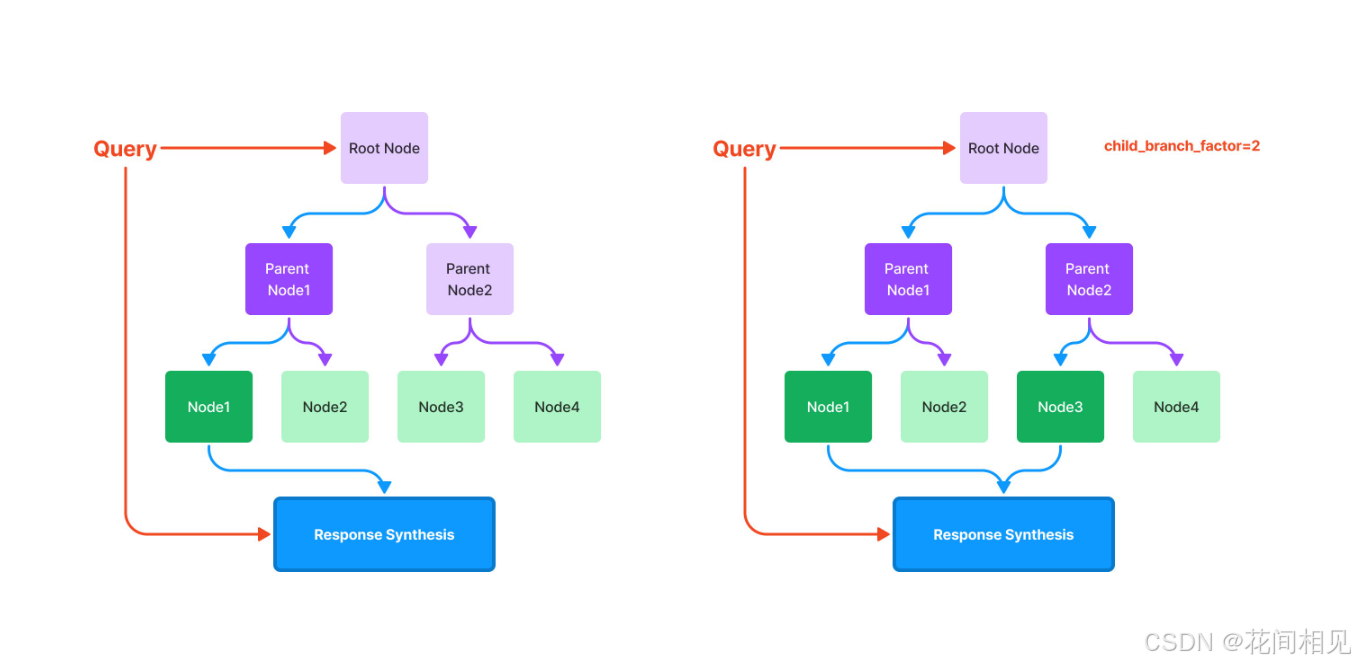
HierarchicalNodeParser:分层分块,生成"父块+子块"层级结构,适配超长文档(如书籍、报告)。
3. 索引存储层(Indices):LlamaIndex的"灵魂核心"
核心作用 :将Node转换为可高效检索的索引结构,支持7种官方索引类型,覆盖向量、关键词、图谱等全场景,是区别于其他框架的核心壁垒。
-
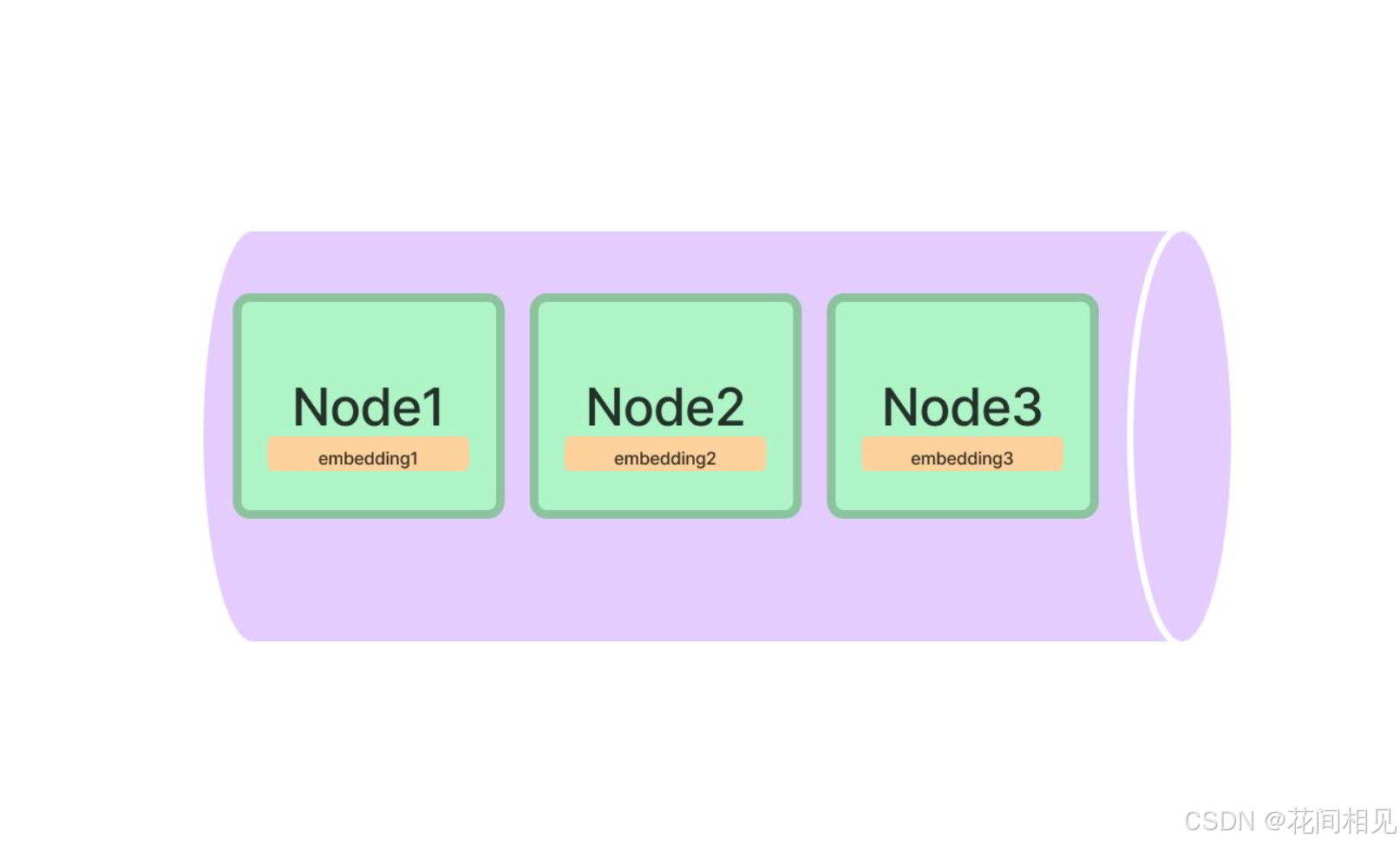
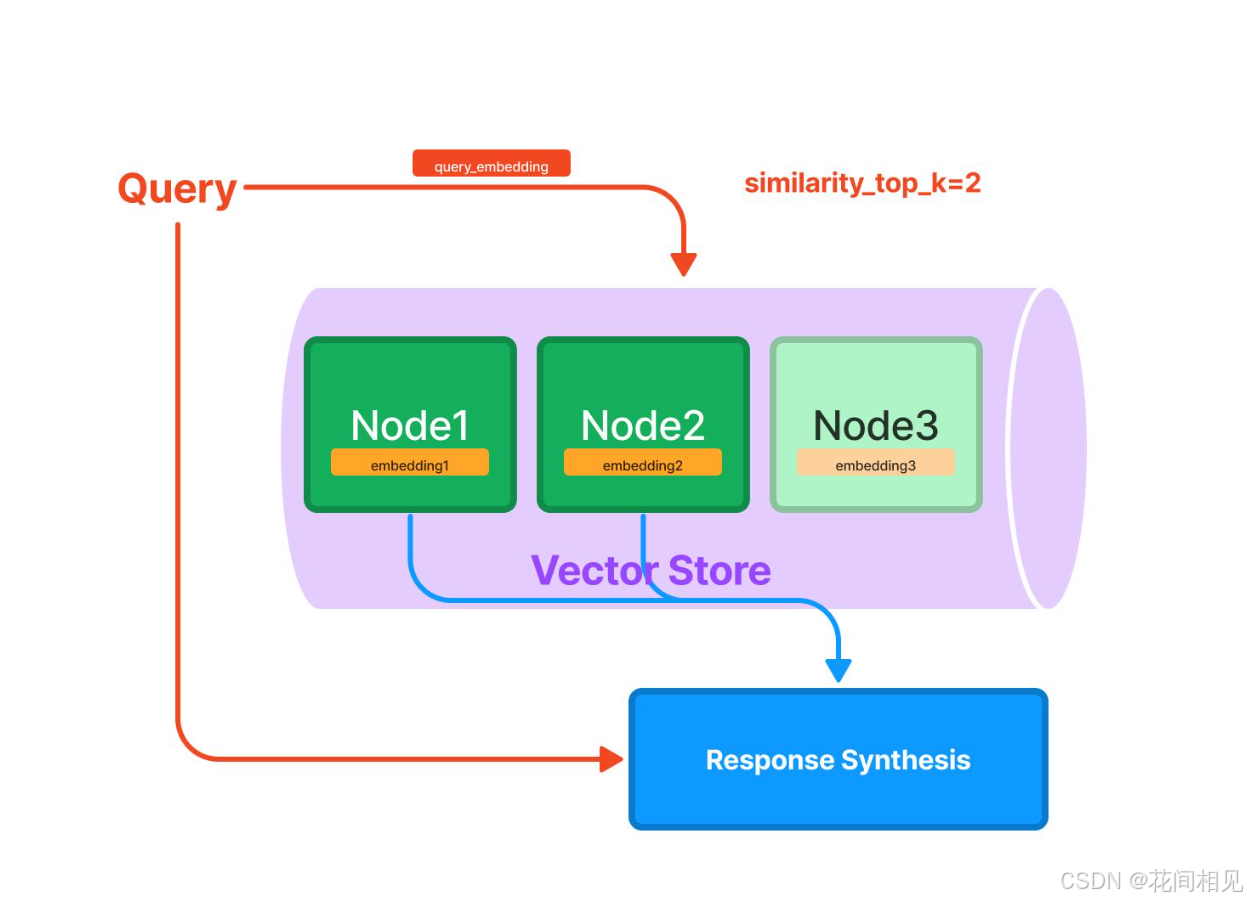
1. VectorStoreIndex(向量存储索引,最常用)
- 路径:
llama_index.core.indices.vector_store.VectorStoreIndex - 原理:将
Node通过Embedding模型(如BGE、text-embedding-ada-002)转为向量,存入向量库(FAISS/Chroma/Milvus),查询时做语义相似度匹配。 - 适用:通用RAG、文档问答、语义检索。
- 路径:
-
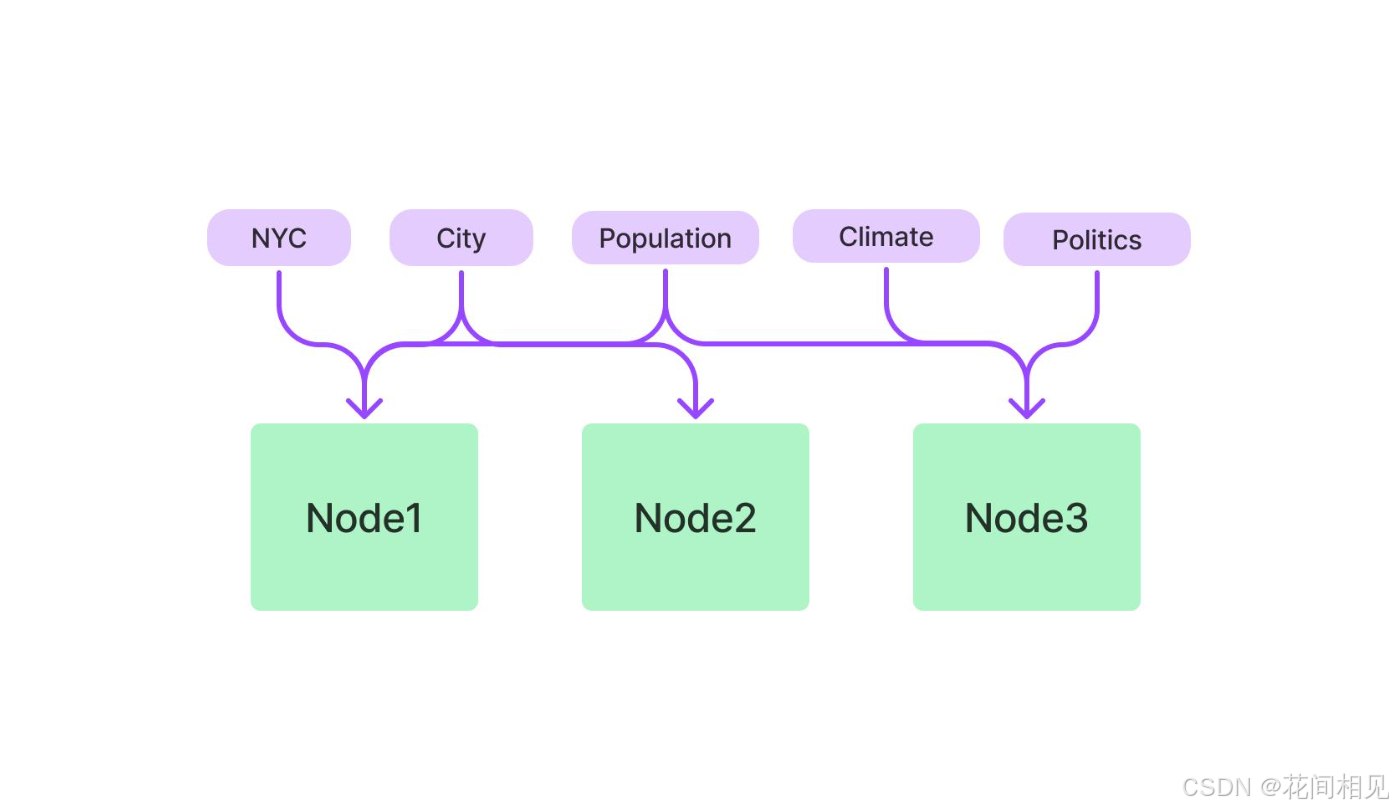
2. KeywordTableIndex(关键词索引)
- 路径:
llama_index.core.indices.keyword_table.KeywordTableIndex - 原理:提取
Node关键词,构建"关键词→Node"倒排索引,查询时做精确关键词匹配。 - 适用:含专有名词、代码、数值的精准查询。
- 路径:
-
3. SummaryIndex(摘要索引)
- 路径:
llama_index.core.indices.summary.SummaryIndex - 原理:为每个
Node生成LLM摘要,构建"全文摘要→原文"映射,查询时先匹配摘要再返回原文。 - 适用:长文档全局总结、快速概览。
- 路径:
-
4. TreeIndex(树形索引)
- 路径:
llama_index.core.indices.tree.TreeIndex - 原理:将
Node构建为层级树结构(根→父→子),查询时从根节点逐层遍历,定位相关子节点。 - 适用:书籍、手册等层级化文档 的深度问答。
- 路径:
-
5. PropertyGraphIndex(属性图谱索引,特色)
- 路径:
llama_index.core.indices.property_graph.PropertyGraphIndex - 原理:从文档中提取实体(节点)+关系(边),构建知识图谱,支持多跳关联查询。
- 适用:企业知识图谱、跨文档关联问答。
- 路径:
-
6. HybridIndex(混合索引,精度之王)
- 路径:
llama_index.core.indices.hybrid.HybridIndex - 原理:向量索引+关键词索引融合,同时做语义匹配与关键词精准匹配,结果加权融合。
- 适用:企业级高精度RAG,解决向量检索"语义漂移"问题。
- 路径:
4. 检索引擎层(Retrievers):精准定位相关上下文
核心作用 :从索引中召回最相关的Node,支持基础检索+高级重排,直接决定RAG问答的准确性。
- 基础检索器
VectorRetriever(llama_index.core.retrievers.VectorRetriever):向量检索,返回Top-K相似节点(默认k=2)。HybridRetriever(llama_index.core.retrievers.HybridRetriever):混合检索,融合向量与关键词结果。
- 高级检索优化(v0.10+ 内置)
RankerRetriever:重排检索,接入BGE-Rerank/Cross-Encoder模型,对初筛结果二次排序,过滤噪声。QueryRewriteRetriever:问题改写,将复杂问题拆解/优化,提升检索匹配度。
5. 问答引擎层(Query Engines):RAG能力的直接出口
核心作用 :封装"检索→上下文组装→LLM生成"全流程,提供开箱即用的问答接口,无需手动编排复杂逻辑。
-
1. QueryEngine(标准问答引擎,最常用)
-
路径:
index.as_query_engine()(llama_index.core.query_engine.QueryEngine) -
功能:一问一答RAG,输入自然语言问题,返回引用原文的精准答案。
-
代码示例:
pythonfrom llama_index.core import SimpleDirectoryReader, VectorStoreIndex documents=SimpleDirectoryReader("data").load_data() index=VectorStoreIndex.from_documents(documents) query_engine=index.as_query_engine() response=query_engine.query("LlamaIndex的核心索引有哪些?")
-
-
2. ChatEngine(对话引擎)
- 路径:
index.as_chat_engine()(llama_index.core.chat_engine.ChatEngine) - 功能:多轮对话RAG ,内置上下文记忆(
SimpleMemory),支持追问、上下文关联回答。
- 路径:
-
3. 高级查询引擎(复杂场景)
RouterQueryEngine:路由引擎,根据问题类型自动选择最优索引(如简单问题用关键词索引,复杂问题用向量索引)。SubQuestionQueryEngine:子问题引擎,将复杂问题拆解为多个子问题,并行检索后合成最终答案。
6. 智能体扩展层(Agents):弱能力附属模块
核心局限 :LlamaIndex的Agent仅支持单智能体+简单工具调用 ,无原生多智能体、角色分工、对话协作能力,不适合复杂Agent场景。
- 核心类:
ReActAgent(llama_index.core.agent.ReActAgent),支持调用知识库、代码解释器等工具。 - 适用:简单工具增强的RAG(如"查文档+计算数据"),复杂Agent优先选LangGraph/AutoGen。
7. 存储适配层(Storage):向量库全兼容
核心作用:统一适配主流向量数据库,支持本地离线部署(FAISS/Chroma)与云端托管(Milvus/Pinecone)。
- 内置支持:
FAISSVectorStore(本地轻量)、ChromaVectorStore(本地持久化)、MilvusVectorStore(企业级分布式)。 - 文档存储:
SimpleDocumentStore(JSON持久化)、RedisDocumentStore(高性能缓存)。
四、与LangChain核心差异(v0.10+ 对比)
| 维度 | LlamaIndex v0.10.68 | LangChain v0.2+ |
|---|---|---|
| 核心定位 | RAG专用框架,数据检索为王 | 全栈Agent框架,流程编排为王 |
| 索引系统 | 极强(7+索引类型,混合检索、知识图谱) | 基础简陋(仅向量/关键词,无高级索引) |
| 文档处理 | 专业级(语义分块、分层分块、Markdown适配) | 基础级(简单Token/字符切割) |
| 多智能体 | 极弱(无原生多Agent,仅单Agent工具调用) | 极强(LangGraph原生支持多Agent、角色分工) |
| 易用性 | RAG场景极简(3行代码搭基础RAG) | 学习曲线陡(概念多、配置繁琐) |
| 生产就绪 | ✅ 成熟(支持监控、评估、持久化) | ✅ 成熟(LangServe、LangSmith) |
五、适用场景总结
选LlamaIndex的场景
- ✅ 企业知识库、文档问答系统(PDF/Markdown/Word)
- ✅ 私有数据RAG(本地离线部署,数据不出境)
- ✅ 高精度检索需求(混合索引、知识图谱关联查询)
- ✅ 快速原型开发(极简API,开箱即用)
不选LlamaIndex的场景
- ❌ 多智能体协作(如"产品+开发+测试"AI团队)
- ❌ 复杂流程编排(分支、并行、循环逻辑)
- ❌ 非RAG类LLM应用(纯聊天机器人、工具调用Agent)
六、总结
LlamaIndex v0.10+ 是RAG领域的专精王者 ,核心优势在于极致的文档处理能力、丰富的索引算法、精准的检索优化,是构建企业级RAG系统的首选框架。它不擅长多智能体编排,但在"私有数据→知识库→问答"的全链路中,没有任何框架能与之匹敌。