要知道栈为什么适合做这种类似于爱消除的操作,因为栈帮助我们记录了 遍历数组当前元素时候,前一个元素是什么。
题目链接:https://leetcode.cn/problems/remove-all-adjacent-duplicates-in-string/ 视频讲解:https://www.bilibili.com/video/BV12a411P7mw
一、看到题目的第一想法
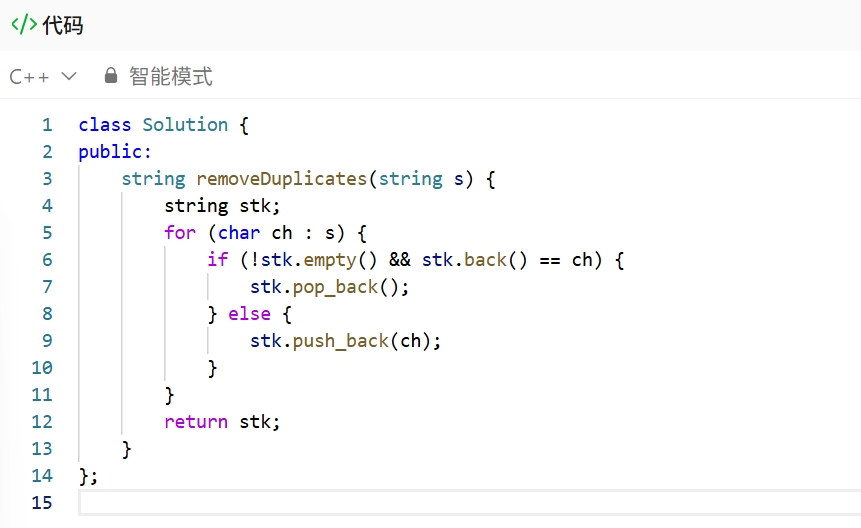
- 题目要求理解 :给定一个字符串
s,重复删除两个相邻且相同的字符,直到字符串中没有这样的相邻重复项为止,返回最终的字符串。比如"abbaca"最终会变成"ca"。 - 核心思路 :这道题是典型的栈 应用场景,栈的 "后进先出" 特性正好可以处理相邻匹配的问题:
- 遍历字符串,把每个字符依次压入栈中;
- 每次压栈前,先检查栈顶元素是否和当前字符相同:如果相同,说明是相邻重复项,直接弹出栈顶(相当于删除这对重复字符);如果不同,就把当前字符压入栈中;
- 遍历结束后,栈中剩下的字符就是没有相邻重复项的字符串。
- 初步实现念头 :
- 直接用
string模拟栈操作,用back()取栈顶、pop_back()出栈、push_back()入栈,非常方便。 - 遍历每个字符,先判断栈非空且栈顶等于当前字符,是则出栈,否则入栈,最后直接返回栈字符串。
- 直接用
二、实现过程中遇到的困难
- 栈空判断的遗漏
- 一开始写
if (stk.back() == ch)时,忘记加!stk.empty()的判断,当栈为空时访问stk.back()会导致程序崩溃,后来才补上了栈非空的前置条件。
- 一开始写
- 逻辑顺序搞反
- 一开始错误地把入栈操作写在了前面,再判断是否相等出栈,导致重复字符还是被压入了栈中,比如
"aa"会被压入两个'a',后来才纠正了顺序:先判断是否匹配,再决定出栈还是入栈。
- 一开始错误地把入栈操作写在了前面,再判断是否相等出栈,导致重复字符还是被压入了栈中,比如
- 对 "重复删除" 规则的理解偏差
- 一开始误以为只需要删除一次相邻重复项,而不是重复删除直到没有为止。比如
"abba",一开始以为处理后会变成"aa",后来才意识到继续处理会变成空字符串,而栈的方式天然支持连续删除,因为每次出栈后,新的栈顶会和下一个字符继续比较。
- 一开始误以为只需要删除一次相邻重复项,而不是重复删除直到没有为止。比如
- 边界情况的处理
- 一开始没考虑空字符串、单个字符的情况,后来发现代码天然处理了这些场景:空字符串直接返回,单个字符会直接入栈,不会触发任何删除操作。
三、今日收获心得
- 栈在 "相邻匹配 / 消除" 问题中的通用解法这道题让我深刻体会到,栈不仅能处理括号匹配,还能处理所有 "相邻元素需要成对消除" 的场景。核心思想就是用栈顶元素和当前元素做比较,匹配则消除,不匹配则保留,这种模式可以推广到很多类似的题目中。
- 用
string模拟栈的便捷性 学会了用string来模拟栈操作,比使用std::stack更方便,因为它本身就支持back()、pop_back()、push_back()操作,最后还能直接作为结果返回,省去了栈转字符串的步骤,代码更简洁。 - 对算法 "一次遍历" 特性的理解这道题的时间复杂度是 \(O(n)\),每个字符最多入栈和出栈各一次,不需要额外的循环来回处理字符串,这种一次遍历的解法,比暴力的多次扫描删除要高效得多,也让我理解了栈在优化这类问题中的作用。
- 边界条件的重要性栈空判断是这类栈应用题目中最容易遗漏的细节,通过这次实现,我养成了 "访问栈顶元素前先判断栈是否为空" 的习惯,避免了程序崩溃的问题。
- 对 "消除类" 问题的思维拓展 原来以为 "重复消除" 需要多次遍历字符串,现在发现用栈可以一次遍历完成所有消除操作,这种思路也启发了我对后续类似题目(比如消除相邻相同字符、字符串匹配)的思考,学会了用栈来简化复杂的重复处理逻辑。