
🎁个人主页:我滴老baby
🎉欢迎大家点赞👍评论📝收藏⭐文章
🔍系列专栏:AI


文章目录:
- ReAct推理模式深度解析:让智能体学会边思考边行动,推理准确率提升40%的秘密
-
- 一、ReAct是什么?
-
- [传统模式 vs ReAct模式](#传统模式 vs ReAct模式)
- 在这里插入图片描述
- 二、ReAct核心循环
- [三、从零实现ReAct Agent](#三、从零实现ReAct Agent)
-
- [3.1 定义工具集](#3.1 定义工具集)
- [3.2 ReAct Agent核心实现](#3.2 ReAct Agent核心实现)
- [3.3 运行效果](#3.3 运行效果)
- 四、ReAct进阶:自我反思机制
-
- [4.1 Reflexion:让Agent从错误中学习](#4.1 Reflexion:让Agent从错误中学习)
- 五、ReAct的性能优化
-
- [5.1 减少token消耗的策略](#5.1 减少token消耗的策略)
- [5.2 混合模型策略](#5.2 混合模型策略)
- [5.3 ReAct各实现方案对比](#5.3 ReAct各实现方案对比)
- 六、ReAct的实际应用场景
-
- [6.1 适用场景](#6.1 适用场景)
- [6.2 不适用场景](#6.2 不适用场景)
- 总结
ReAct推理模式深度解析:让智能体学会边思考边行动,推理准确率提升40%的秘密
斯坦福研究证明,结合推理和行动的Agent比纯推理Agent表现提升47%。本文从原理到代码,彻底搞懂ReAct。
一、ReAct是什么?
ReAct(Reasoning + Acting)是2023年由普林斯顿和Google提出的一种Agent范式,其核心思想是让大语言模型交替进行推理(Thought)和行动(Action)。
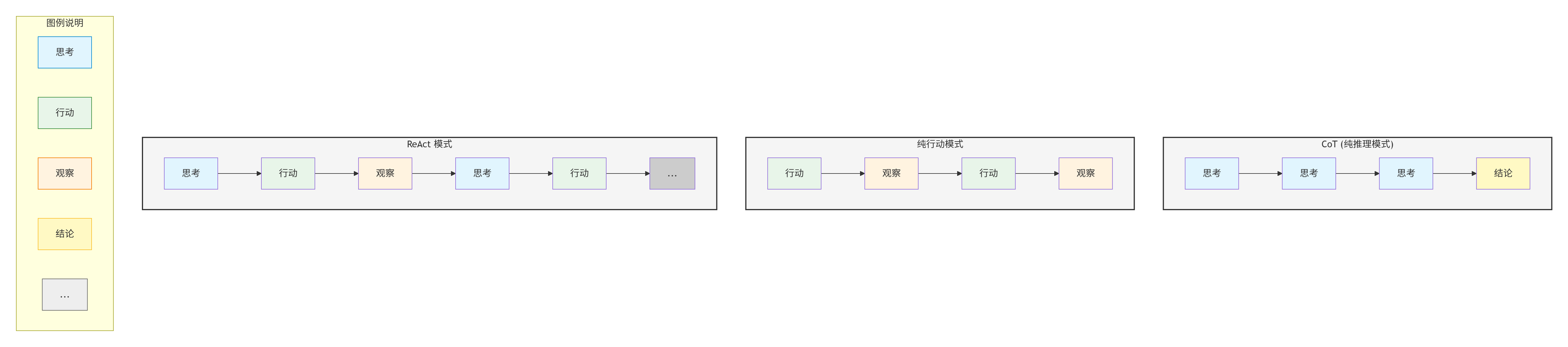
传统模式 vs ReAct模式
| 模式 | 流程 | 优势 | 劣势 |
|---|---|---|---|
| 纯推理(CoT) | 思考→思考→思考→结论 | 逻辑性强 | 无法获取外部信息 |
| 纯行动 | 行动→观察→行动→观察 | 信息丰富 | 缺乏规划 |
| ReAct | 思考→行动→观察→思考→... | 兼得推理和行动 | 消耗更多token |
二、ReAct核心循环
┌────────────────────────────────────────┐
│ ReAct 循环 │
│ │
│ Question(用户问题) │
│ ↓ │
│ Thought 1(分析问题,规划第一步) │
│ ↓ │
│ Action 1(执行工具调用) │
│ ↓ │
│ Observation 1(观察工具返回结果) │
│ ↓ │
│ Thought 2(分析结果,规划下一步) │
│ ↓ │
│ Action 2 / Final Answer │
│ ↓ │
│ ... 直到得出最终答案 │
└────────────────────────────────────────┘三、从零实现ReAct Agent
3.1 定义工具集
python
# react_agent/tools.py
import json
import math
from datetime import datetime
class ToolRegistry:
def __init__(self):
self.tools = {}
def register(self, name, description, func, parameters):
self.tools[name] = {
"description": description,
"function": func,
"parameters": parameters
}
def execute(self, name, **kwargs):
if name not in self.tools:
return f"错误:未知工具 '{name}'"
return self.tools[name]["function"](**kwargs)
def get_descriptions(self):
desc = "可用工具列表:\n"
for name, tool in self.tools.items():
params = ", ".join(tool["parameters"].keys())
desc += f"- {name}({params}): {tool['description']}\n"
return desc
# 注册工具
registry = ToolRegistry()
registry.register(
name="search",
description="搜索互联网获取信息",
func=lambda query: f"搜索'{query}'的结果:[模拟] AI Agent是一种能自主执行任务的系统...",
parameters={"query": "搜索关键词"}
)
registry.register(
name="calculate",
description="执行数学计算",
func=lambda expression: str(eval(expression)),
parameters={"expression": "数学表达式"}
)
registry.register(
name="get_time",
description="获取当前时间",
func=lambda: datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
parameters={}
)
registry.register(
name="lookup",
description="在本地知识库中查找信息",
func=lambda keyword: f"关于'{keyword}'的知识:[模拟] 这是一项重要的技术概念...",
parameters={"keyword": "查找关键词"}
)3.2 ReAct Agent核心实现
python
# react_agent/agent.py
import re
from openai import OpenAI
class ReActAgent:
REACT_PROMPT = """你是一个使用ReAct模式的智能助手。
对于用户的每个问题,你需要交替进行思考和行动。
{tools_description}
请严格按照以下格式回答:
Thought: [分析当前情况,思考下一步该做什么]
Action: [选择一个工具来执行,格式:工具名(参数)]
Observation: [这一步由系统自动填入工具的返回结果]
... (Thought/Action/Observation可以重复多次)
Thought: [我已经获得了足够的信息来回答问题]
Final Answer: [给出最终答案]
重要规则:
1. 每次只执行一个Action
2. 仔细分析Observation的结果再决定下一步
3. 如果信息已足够,直接给出Final Answer
4. 最多进行5轮Thought-Action循环
开始!
"""
def __init__(self, api_key: str, tools: ToolRegistry, model: str = "gpt-4o"):
self.llm = OpenAI(api_key=api_key)
self.tools = tools
self.model = model
self.max_iterations = 6
def run(self, question: str) -> str:
system_prompt = self.REACT_PROMPT.format(
tools_description=self.tools.get_descriptions()
)
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"Question: {question}"}
]
for i in range(self.max_iterations):
print(f"\n{'='*50}")
print(f"迭代 #{i+1}")
print(f"{'='*50}")
response = self.llm.chat.completions.create(
model=self.model,
messages=messages,
temperature=0,
stop=["Observation:"]
)
thought_and_action = response.choices[0].message.content
print(thought_and_action)
# 检查是否已经给出最终答案
if "Final Answer:" in thought_and_action:
final = re.search(r'Final Answer:\s*(.*)', thought_and_action, re.DOTALL)
return final.group(1).strip() if final else thought_and_action
# 提取Action
action_match = re.search(r'Action:\s*(\w+)\((.*)?\)', thought_and_action)
if not action_match:
messages.append({"role": "assistant", "content": thought_and_action})
messages.append({
"role": "user",
"content": "请按照格式提供Thought和Action。"
})
continue
tool_name = action_match.group(1)
tool_input = action_match.group(2) or ""
# 解析参数
params = {}
if tool_input:
# 简单解析 key=value 格式
for pair in tool_input.split(","):
if "=" in pair:
k, v = pair.split("=", 1)
params[k.strip()] = v.strip().strip('"').strip("'")
else:
params["query"] = tool_input.strip().strip('"')
break
# 执行工具
observation = self.tools.execute(tool_name, **params)
print(f"\nObservation: {observation}")
# 追加到对话
full_response = thought_and_action + f"\nObservation: {observation}"
messages.append({"role": "assistant", "content": full_response})
return "Agent未能完成任务(达到最大迭代次数)"3.3 运行效果
python
# main.py
agent = ReActAgent(
api_key="your-key",
tools=registry
)
result = agent.run("现在几点了?如果现在是2026年,那距离2030年还有几年?用计算器验证一下。")输出示例:
迭代 #1
Thought: 用户想知道当前时间,然后计算距离2030年的年数。
我需要先获取当前时间。
Action: get_time()
Observation: 2026-04-26 15:30:00
迭代 #2
Thought: 现在是2026年4月26日。距离2030年是 2030 - 2026 = 4 年。
用户要求用计算器验证。
Action: calculate(2030-2026)
Observation: 4
迭代 #3
Thought: 计算结果确认是4年。我现在有足够信息回答了。
Final Answer: 现在是2026年4月26日15:30。
距离2030年还有4年(已通过计算器验证:2030-2026=4)。四、ReAct进阶:自我反思机制
4.1 Reflexion:让Agent从错误中学习
python
# react_agent/reflexion.py
class ReflexionAgent(ReActAgent):
"""带自我反思的ReAct Agent"""
REFLEXION_PROMPT = """你之前的尝试失败了。请反思:
失败的尝试:
{trajectory}
失败原因分析:
{feedback}
请总结经验教训,避免犯同样的错误:
Lesson: [从失败中学到的教训]
"""
def run_with_reflexion(self, question: str, max_attempts: int = 3):
reflections = []
for attempt in range(max_attempts):
print(f"\n{'#'*60}")
print(f"尝试 #{attempt + 1}")
print(f"{'#'*60}")
# 添加之前的反思到提示中
enhanced_question = question
if reflections:
enhanced_question += "\n\n之前的经验教训:\n"
enhanced_question += "\n".join(reflections)
result = self.run(enhanced_question)
# 验证结果
is_correct, feedback = self._evaluate(question, result)
if is_correct:
return result
# 反思失败原因
reflection = self._reflect(question, result, feedback)
reflections.append(reflection)
print(f"\n📝 反思: {reflection}")
return result
def _evaluate(self, question: str, answer: str):
"""评估回答质量"""
prompt = f"""评估以下回答是否正确回答了问题:
问题: {question}
回答: {answer}
返回JSON: {{"correct": true/false, "feedback": "具体反馈"}}"""
response = self.llm.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
temperature=0
)
import json
result = json.loads(response.choices[0].message.content)
return result["correct"], result.get("feedback", "")
def _reflect(self, question, trajectory, feedback):
"""生成反思"""
prompt = self.REFLEXION_PROMPT.format(
trajectory=trajectory, feedback=feedback
)
response = self.llm.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
temperature=0.7
)
return response.choices[0].message.content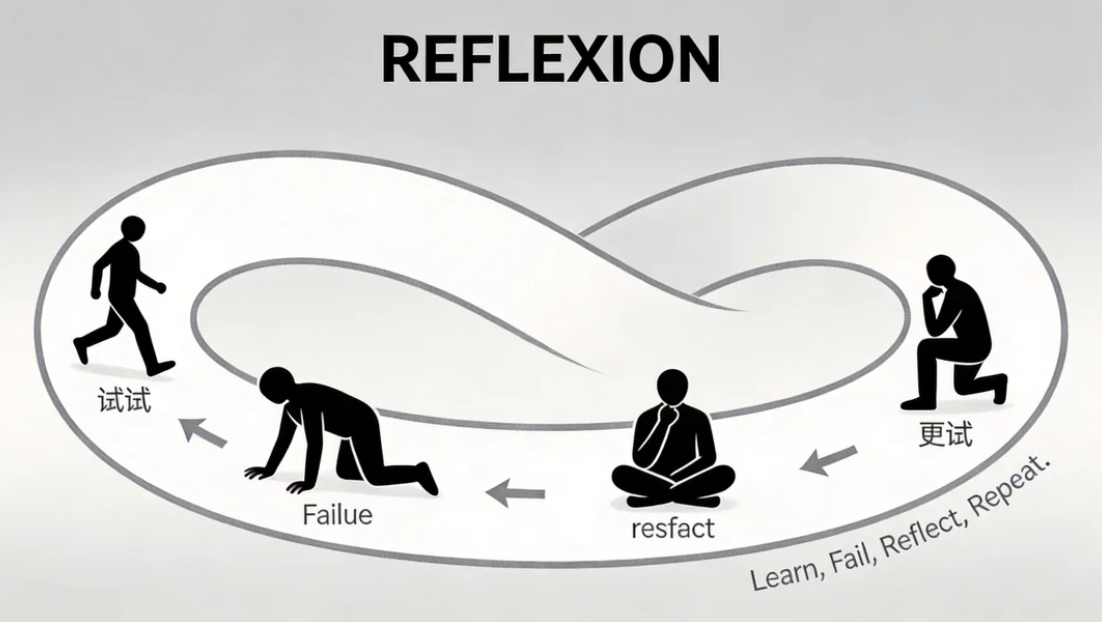
五、ReAct的性能优化
5.1 减少token消耗的策略
| 策略 | 说明 | token节省 |
|---|---|---|
| 压缩Observation | 截断过长的工具返回 | 30-50% |
| 缓存工具结果 | 相同查询不重复调用 | 20-40% |
| 提前终止 | 信息足够时立即回答 | 10-30% |
| 使用小模型 | 简单步骤用小模型 | 50-70%成本 |
5.2 混合模型策略
python
class AdaptiveReActAgent(ReActAgent):
"""自适应ReAct Agent - 根据任务复杂度选择模型"""
def _select_model(self, thought: str) -> str:
"""根据思考内容选择合适的模型"""
simple_indicators = ["计算", "查询时间", "简单的"]
complex_indicators = ["分析", "对比", "综合", "推理"]
for indicator in simple_indicators:
if indicator in thought:
return "gpt-4o-mini"
for indicator in complex_indicators:
if indicator in thought:
return "gpt-4o"
return "gpt-4o-mini" # 默认使用小模型5.3 ReAct各实现方案对比
| 实现方案 | 复杂度 | 灵活性 | 推荐场景 |
|---|---|---|---|
| 手写Prompt ReAct | 低 | 中 | 学习/原型 |
| LangChain ReAct | 中 | 高 | 生产项目 |
| LangGraph State | 高 | 极高 | 复杂工作流 |
| 自定义ReAct框架 | 高 | 极高 | 特定领域 |

六、ReAct的实际应用场景
6.1 适用场景
python
# 场景1:数据分析Agent
# Thought: 用户需要分析销售数据,我先查询数据库
# Action: query_database("SELECT * FROM sales WHERE quarter='Q1'")
# Observation: [返回Q1销售数据]
# Thought: 数据已获取,需要计算同比增长率
# Action: calculate("(500000-380000)/380000*100")
# Final Answer: Q1销售额50万,同比增长31.6%
# 场景2:客服Agent
# Thought: 用户反馈退款问题,先查订单状态
# Action: lookup_order(order_id="ORD-2026-001")
# Observation: 订单状态为"已发货,运输中"
# Thought: 订单还在运输中,需要查询退款政策
# Action: search_knowledge_base("运输中退款政策")
# Final Answer: 订单尚在运输中,根据政策需在签收后7天内申请退款...6.2 不适用场景
- 简单问答(直接回答更快)
- 确定性的流水线任务(用DAG更合适)
- 对延迟极度敏感的场景(ReAct需要多轮LLM调用)
总结
ReAct是AI Agent最重要的设计模式之一,核心要点:
- 交替推理与行动:不是纯思考或纯执行,而是两者结合
- 观察驱动:每一步行动后都观察结果,再决定下一步
- 自我反思:Reflexion让Agent从失败中学习
- 性能优化 :混合模型、缓存、提前终止