教材来源 :《大数据平台架构》
章节 :第4章 Hadoop 分布式文件系统 (HDFS)
主编 :吕欣、黄宏斌
关键词:NameNode, DataNode, 倒排索引, 纠删码, HA
文章目录
- [4.1 HDFS 概述:大数据存储的基石](#4.1 HDFS 概述:大数据存储的基石)
-
- [4.1.1 设计背景与核心目标](#4.1.1 设计背景与核心目标)
- [4.1.2 局限性](#4.1.2 局限性)
- [4.2 HDFS 体系架构:主从模式的经典实现](#4.2 HDFS 体系架构:主从模式的经典实现)
-
- [4.2.1 NameNode](#4.2.1 NameNode)
- [4.2.2 DataNode](#4.2.2 DataNode)
- [4.2.3 Secondary NameNode](#4.2.3 Secondary NameNode)
- [4.3 关键机制:高可靠与高性能的保障](#4.3 关键机制:高可靠与高性能的保障)
-
- [4.3.1 数据块(Block)与副本策略](#4.3.1 数据块(Block)与副本策略)
- [4.3.2 机架感知(Rack Awareness)](#4.3.2 机架感知(Rack Awareness))
- [4.3.3 读写流程中的一致性保障](#4.3.3 读写流程中的一致性保障)
- [4.4 HDFS 高级特性(Hadoop 2.x/3.x)](#4.4 HDFS 高级特性(Hadoop 2.x/3.x))
-
- [4.4.1 高可用性(High Availability, HA)](#4.4.1 高可用性(High Availability, HA))
- [4.4.2 联邦机制(Federation)](#4.4.2 联邦机制(Federation))
- [4.4.3 纠删码(Erasure Coding, EC)](#4.4.3 纠删码(Erasure Coding, EC))
- [4.5 本章总结](#4.5 本章总结)
4.1 HDFS 概述:大数据存储的基石
4.1.1 设计背景与核心目标
Hadoop 分布式文件系统(HDFS)是 Google File System (GFS) 的开源实现,旨在解决单机文件系统在容量和吞吐量上的物理瓶颈。其核心设计理念是在廉价的商用硬件(Commodity Hardware)上构建高容错系统。
HDFS 的架构建立在以下四个核心假设之上:
- 硬件故障是常态:集群包含成百上千台服务器,磁盘损坏或节点宕机是大概率事件。系统必须具备自动检测故障并快速恢复的能力(如心跳机制、副本自动补全)。
- 流式数据访问 :HDFS 专为批处理(Batch Processing)设计,侧重于高吞吐量(Throughput)而非低延迟。它遵循 一次写入,多次读取(Write-Once-Read-Many) 的模型。
- 处理超大文件:支持 GB 到 TB 级别的大文件存储。
- 移动计算 :为了减少网络带宽消耗,HDFS 提供了数据位置接口,允许计算框架(如 MapReduce)将任务调度到数据所在的节点运行(即数据本地性)。
4.1.2 局限性
尽管 HDFS 是大数据存储的事实标准,但教材也明确指出了其不适用的场景:
- 低延迟数据访问:HDFS 不适合毫秒级的实时查询(应使用 HBase)。
- 大量小文件存储:NameNode 将文件系统的元数据存储在内存中。海量小文件(如亿级数量的 KB 级文件)会耗尽 NameNode 内存,限制集群扩展能力。
- 并发写入与随机修改 :同一文件在同一时刻仅允许一个客户端写入,且仅支持追加(Append),不支持在文件任意位置进行修改。
4.2 HDFS 体系架构:主从模式的经典实现
HDFS 采用标准的 Master/Slave(主/从) 拓扑结构,主要包含以下组件。
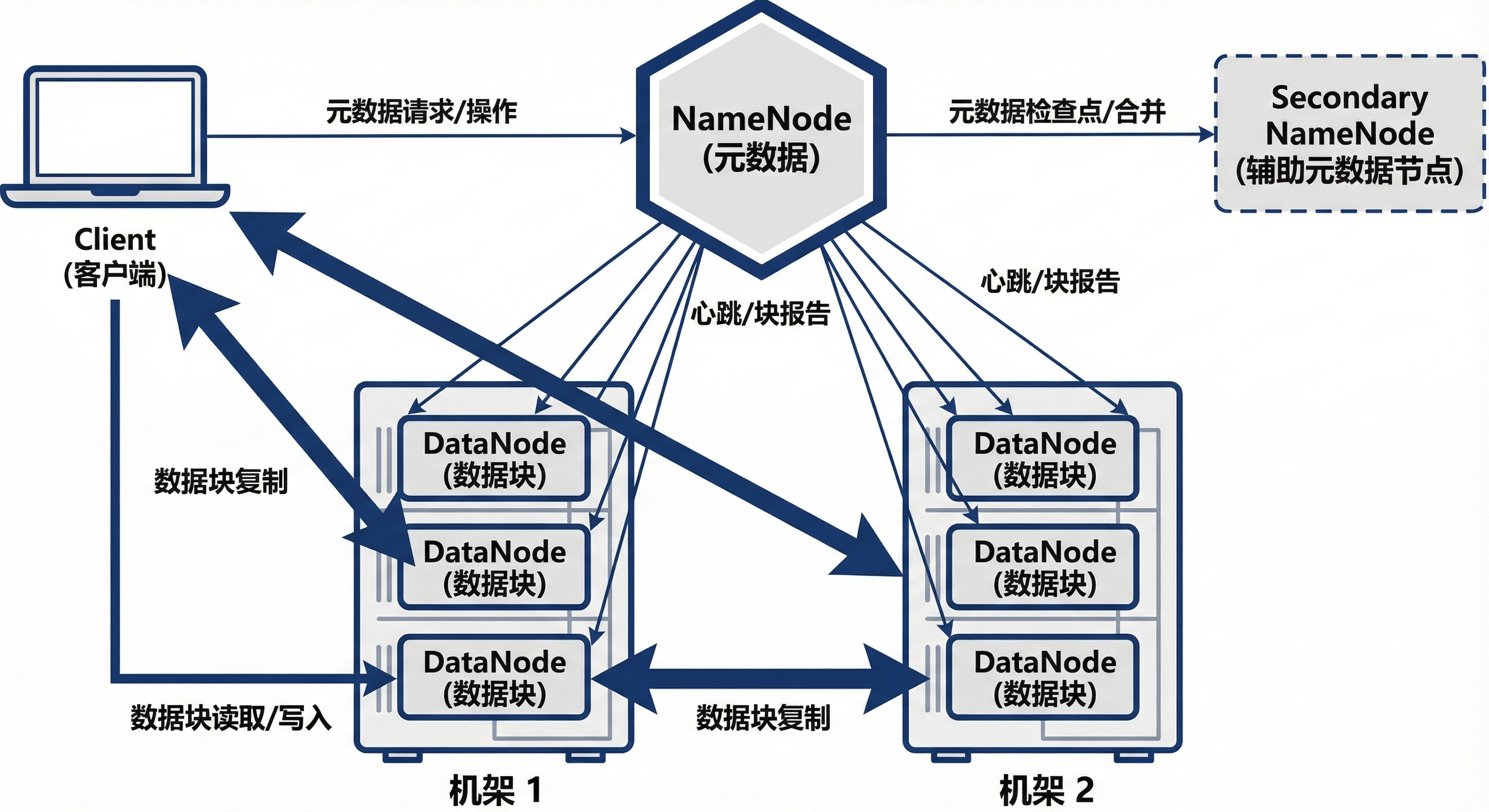
图4-1 HDFS 体系架构概览
4.2.1 NameNode
NameNode 是 HDFS 的"大脑",负责管理文件系统的命名空间(Namespace)和元数据(Metadata)。
- 元数据管理:维护文件目录树、文件到数据块(Block)的映射关系。这些数据驻留在内存中以提供高性能访问。
- 持久化机制 :
- FsImage(镜像文件):文件系统元数据的完整快照,存储在磁盘上。
- EditLog(编辑日志):记录所有对元数据的写操作(如创建、删除、重命名)。NameNode 启动时会加载 FsImage 并回放 EditLog。
4.2.2 DataNode
DataNode 是 HDFS 的"躯干",负责存储实际的数据。
- 块存储 :数据以 Block 为单位存储在本地文件系统(如 Ext4, XFS)中。
- 汇报机制 :
- 心跳(Heartbeat):默认每 3 秒向 NameNode 发送一次,证明存活。
- 块报告(Block Report):定期(默认 6 小时)汇报本地所有数据块的校验和与状态。
4.2.3 Secondary NameNode
注意 :Secondary NameNode 不是 NameNode 的热备份(Standby)。
- 核心职责(Checkpoint) :它的主要作用是定期(默认 1 小时)从 NameNode 拉取 FsImage 和 EditLog,在本地合并生成新的
FsImage.ckpt,然后推回给 NameNode。 - 价值:防止 NameNode 的 EditLog 无限膨胀,缩短 NameNode 重启时的恢复时间。
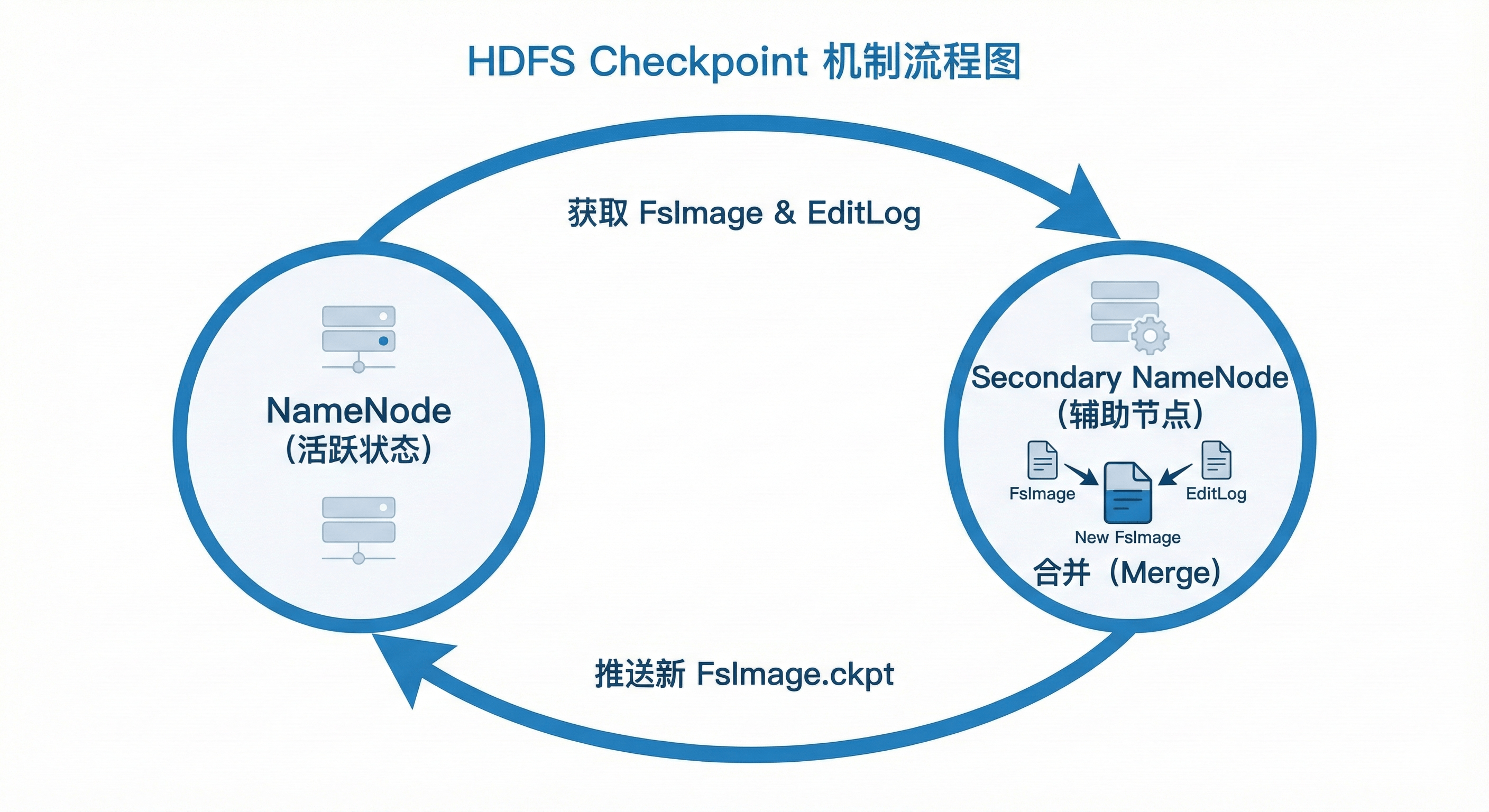
图4-2 Secondary NameNode 检查点机制
4.3 关键机制:高可靠与高性能的保障
4.3.1 数据块(Block)与副本策略
HDFS 将文件物理切割为固定大小的 Block (Hadoop 2.x/3.x 默认 128MB)。
- 大块设计的意义:最小化寻址开销(Seek Time),使磁盘传输时间显著大于寻址时间,从而逼近磁盘的理论最大传输速率。
副本机制(Replication) :默认每个 Block 有 3 个副本。
4.3.2 机架感知(Rack Awareness)
为了在容灾能力 (Data Reliability)和网络带宽(Network Bandwidth)之间取得平衡,HDFS 采用特定的副本放置策略(以 3 副本为例):
- 第 1 副本:放置在写入客户端所在的节点(如果客户端在集群内);否则随机选择负载较低的节点。
- 第 2 副本 :放置在与第 1 副本不同机架 的随机节点上。(防机架故障)
- 第 3 副本 :放置在与第 2 副本相同机架 的另一个节点上。(节约跨机架带宽)
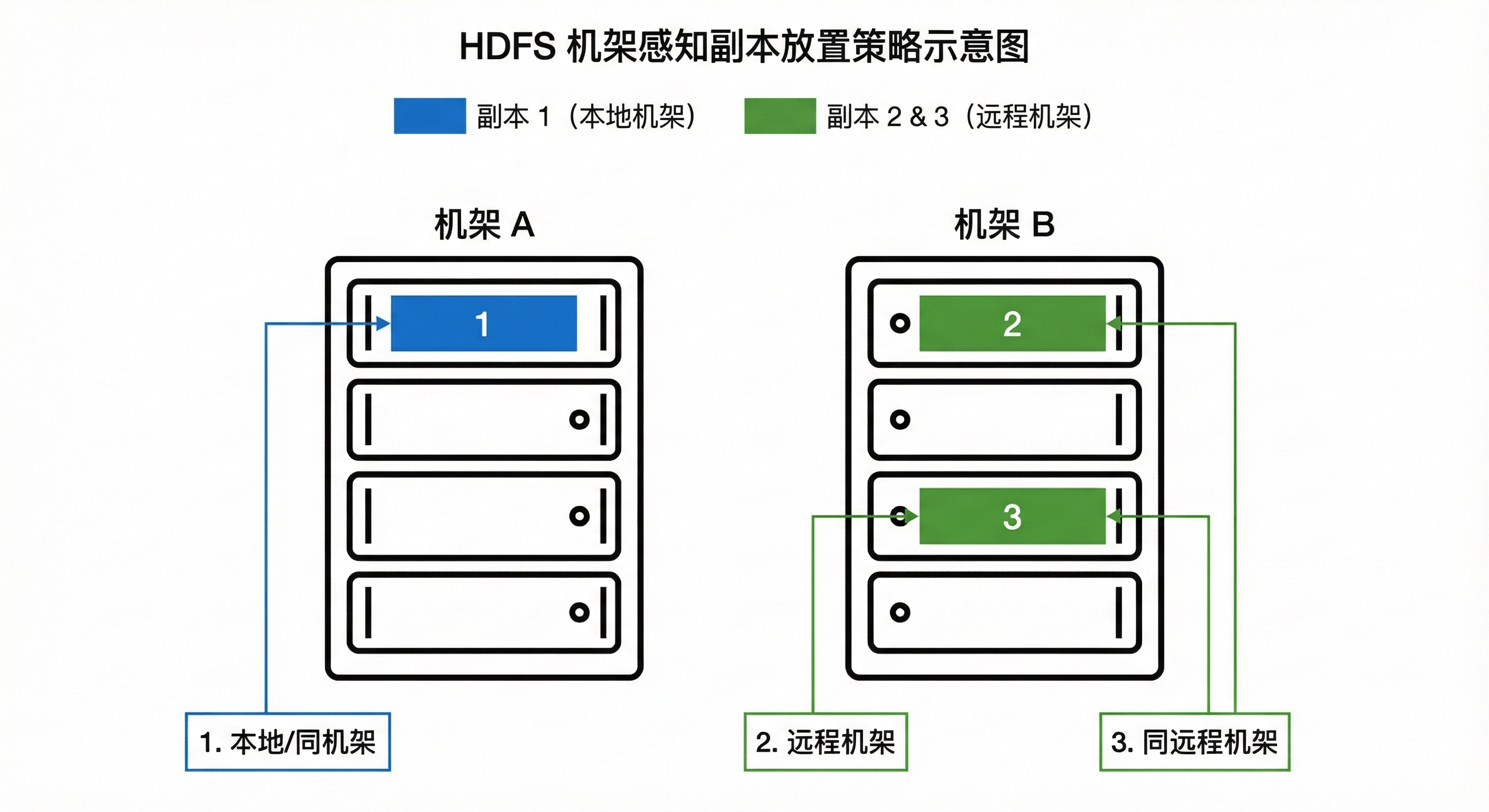
图4-3 机架感知副本放置策略
4.3.3 读写流程中的一致性保障
- 写数据流水线(Pipeline) :
客户端将数据切分为 Packet(64KB),建立流式管道(Client -> A -> B -> C)。数据包在管道中依次传递,而确认包(ACK)则逆序回传。只有当所有副本都确认写入成功,该 Block 才被视为已提交。 - 租约机制(Lease) :
NameNode 维护文件的写租约。只有持有租约的客户端才能写入文件,防止多客户端并发写入导致数据混乱。
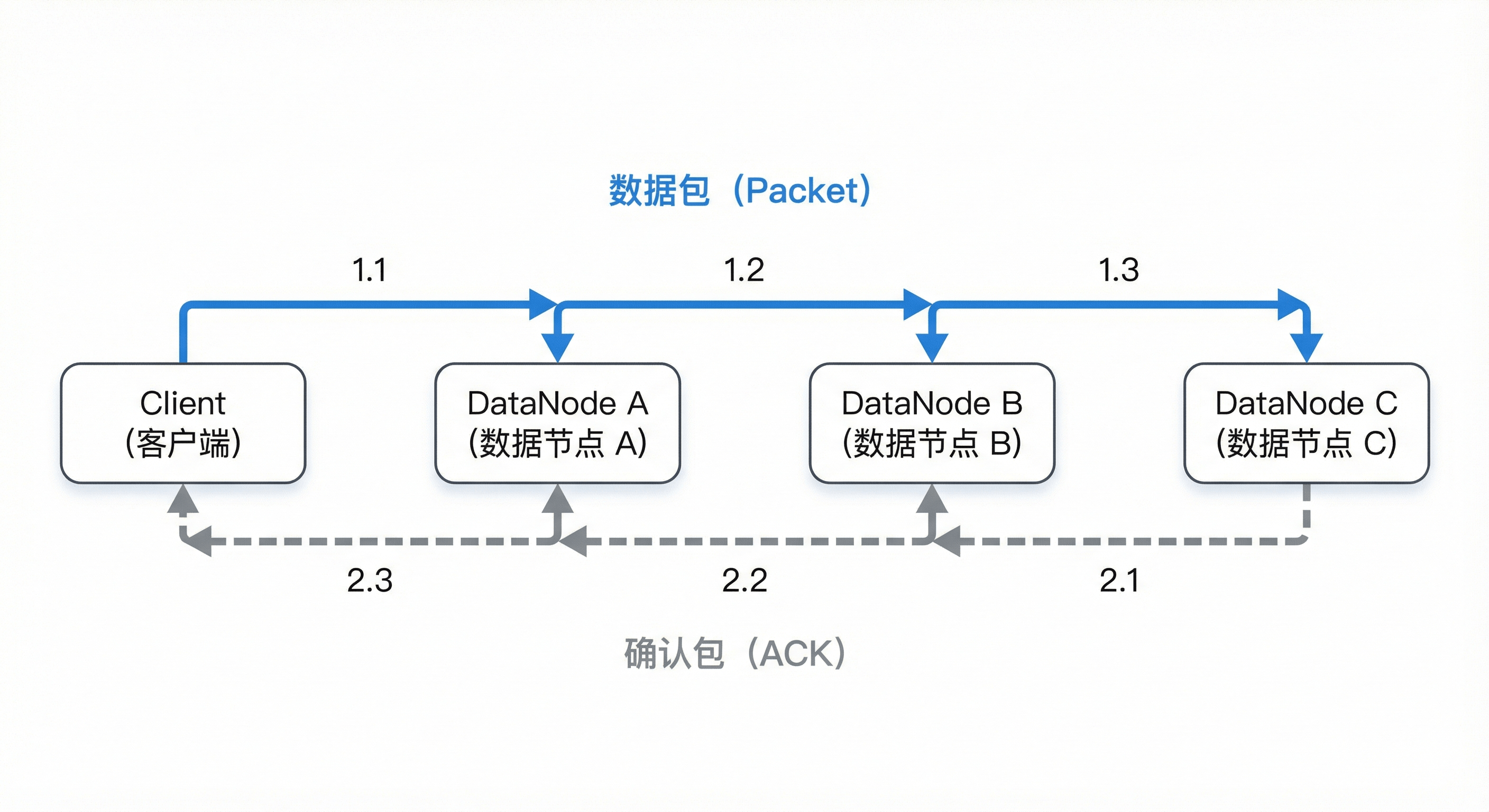
图4-4 写数据流水线:基于 Pipeline 的数据包传输与 ACK 确认机制
4.4 HDFS 高级特性(Hadoop 2.x/3.x)
4.4.1 高可用性(High Availability, HA)
解决了 NameNode 单点故障(SPOF)问题。
- 架构 :引入 Active NameNode (活跃)和 Standby NameNode(热备)。
- 共享存储(QJM) :利用 JournalNodes 集群共享 EditLog。Active 节点写入,Standby 节点实时读取并同步内存状态。
- 故障自动切换 :利用 ZooKeeper 和 ZKFC (ZK Failover Controller) 监控节点状态。当 Active 宕机时,ZKFC 自动将 Standby 提升为 Active。
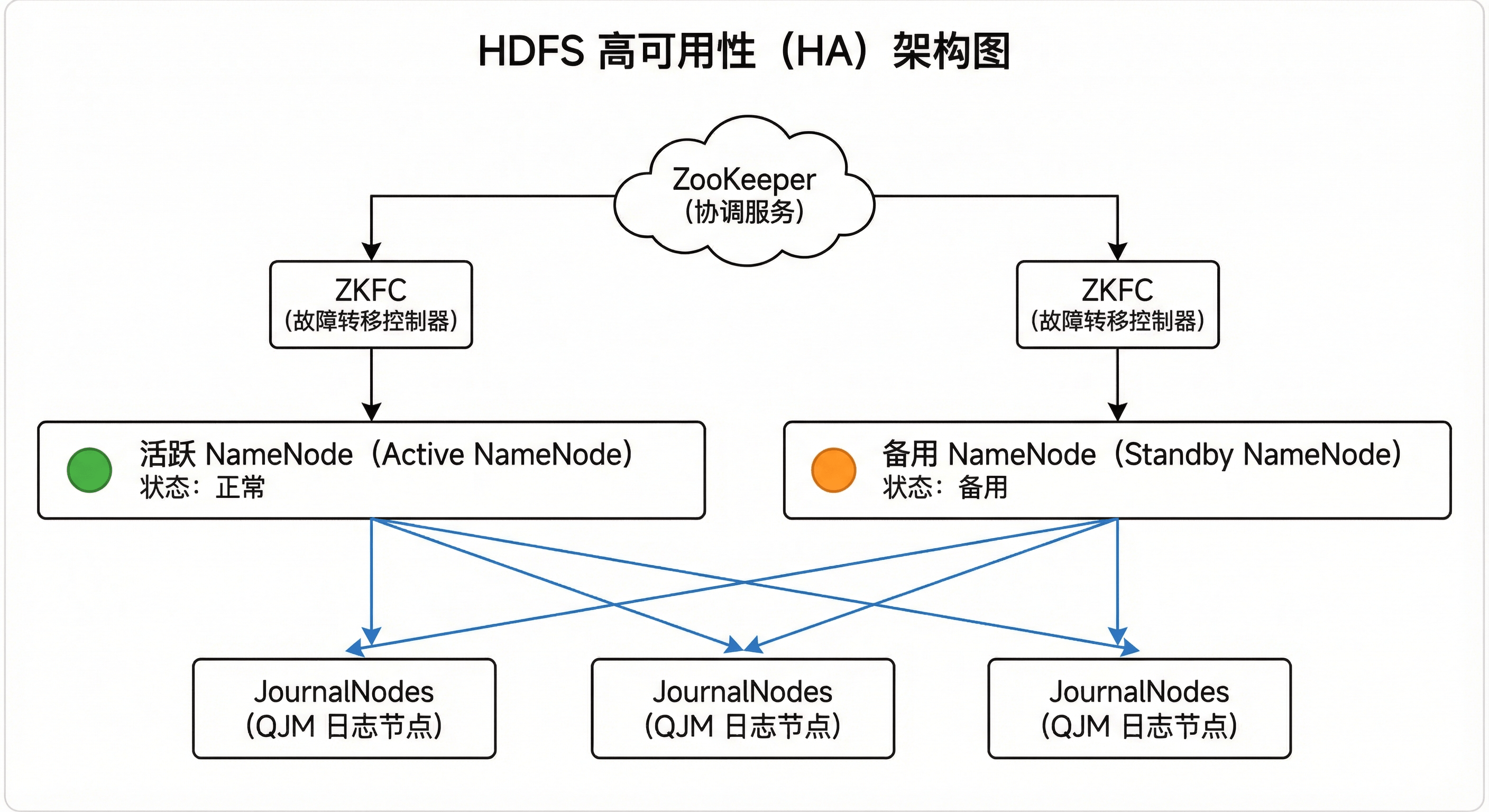
图4-5 HDFS 高可用(HA)架构
4.4.2 联邦机制(Federation)
解决了单 NameNode 内存受限导致的集群扩展瓶颈。
- 原理 :允许集群中有多个独立的 NameNode,分别管理不同的命名空间(Namespace) (例如:NameNode A 管理
/user,NameNode B 管理/data)。 - 共享存储层:所有的 NameNode 共享底层的 DataNode 资源池。
4.4.3 纠删码(Erasure Coding, EC)
Hadoop 3.x 引入的重要特性,用于冷数据存储。
- 原理:类似于 RAID 5/6,通过计算校验块(Parity Block)来替代简单的多副本。
- 优势 :将存储冗余度从 200% (3副本)降低到 约 50%(如 RS-6-3 编码),显著节省存储成本。
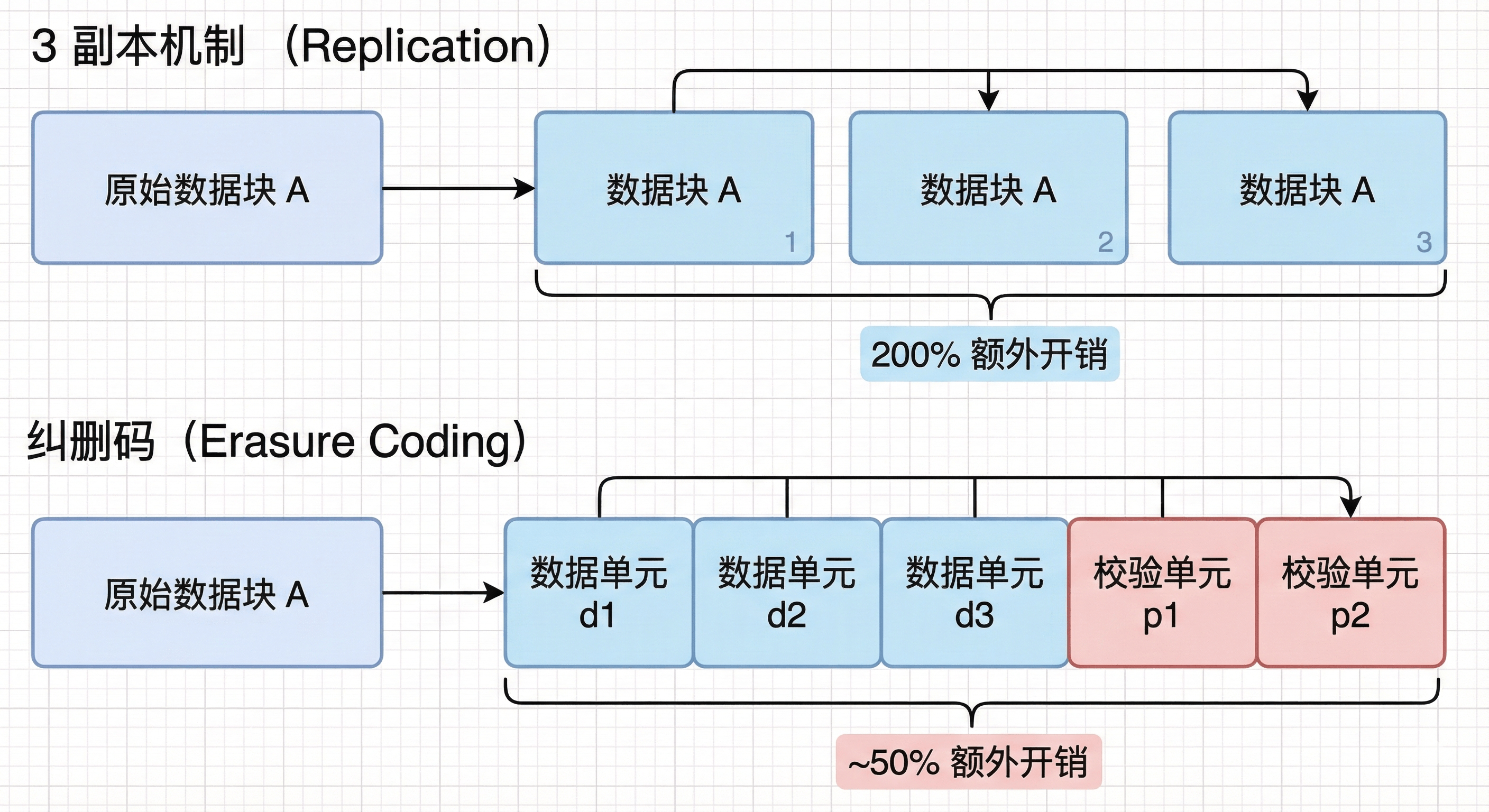
图4-6 纠删码原理对比
4.5 本章总结
HDFS 通过精妙的架构设计,在不可靠的硬件上实现了可靠的存储服务:
- 分块与副本解决了大文件存储和数据容错问题。
- 机架感知优化了网络拓扑,兼顾了安全与性能。
- HA 与联邦打破了早期版本的可用性与扩展性天花板。
作者:栗子同学