一、问题背景
应用频繁出现CPU飙升,导致服务接口响应超时,严重影响了测试环境的稳定性。测试人员反馈系统异常,两个服务节点均独立出现此现象。
二、初步排查(未果)
-
排除内存与对象问题
- 查看云监控,CPU在某时间点突然飙升。
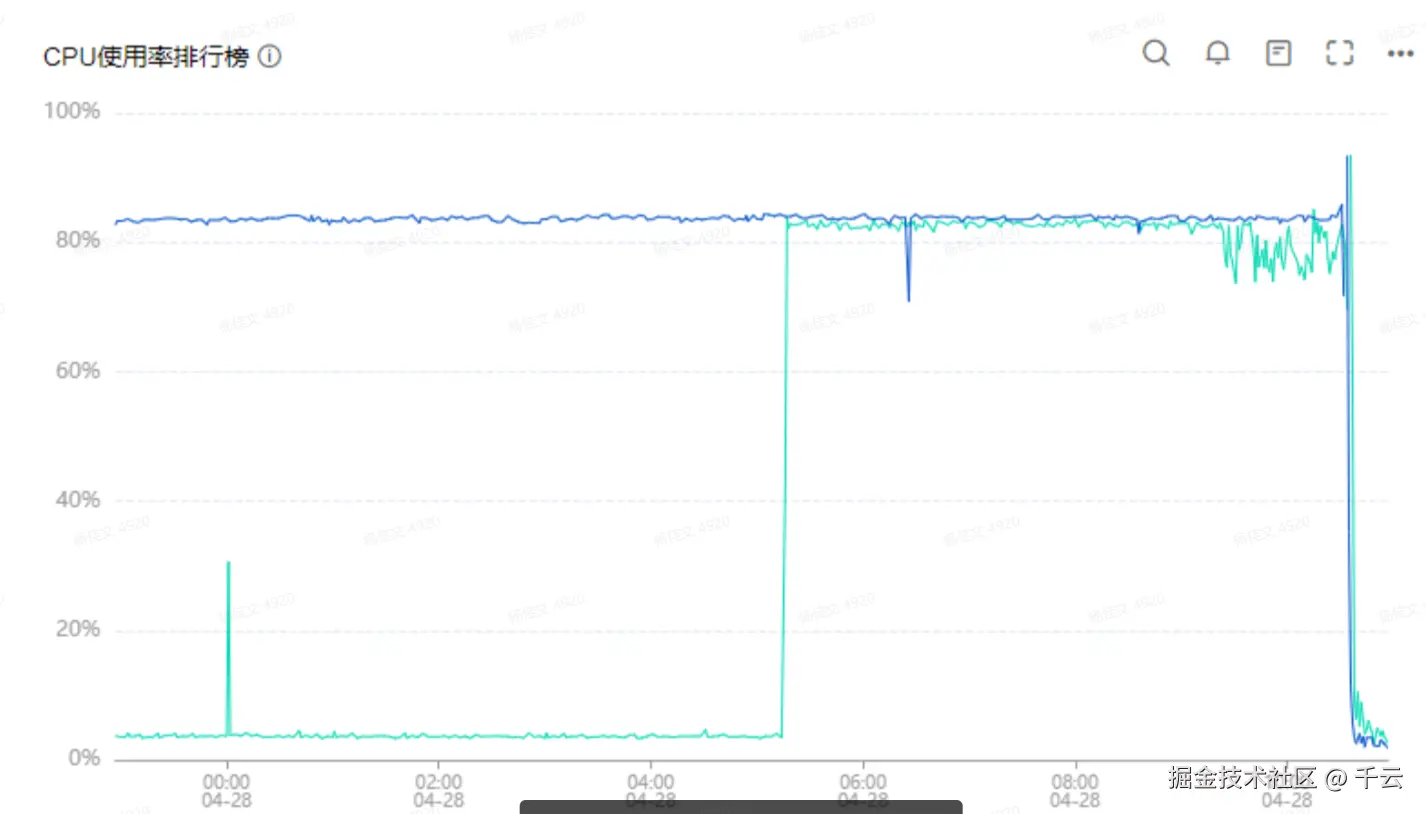
- 内存监控曲线平稳,无明显攀升,初步排除因堆内存溢出或大对象频繁GC导致CPU升高。
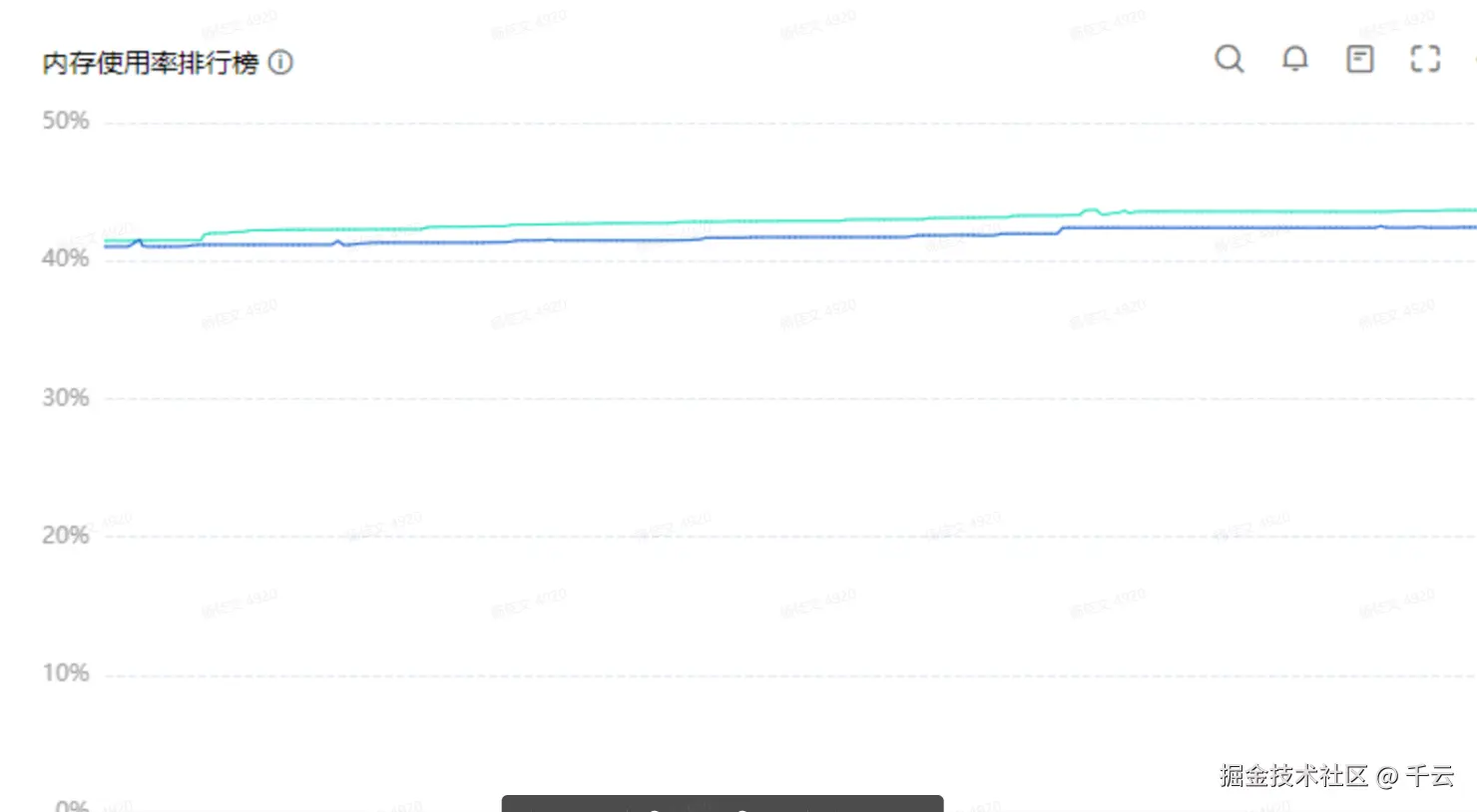
-
排除业务逻辑问题
- 对调用链分析发现,CPU飙升时所涉及的业务方法均为日常普通方法,未发现特殊或异常的高消耗操作。
-
排除线程阻塞问题
- 登录容器,使用
top定位高CPU进程,并用jstack导出线程日志。 
- 分析日志显示:无死锁,大量线程处于正常的等待状态(
WAITING/TIMED_WAITING)。 - 初步结论:应用"正常",未发现线程层面异常,这与实际故障现象矛盾。
- 登录容器,使用
三、深入诊断(定位根因)
由于常规手段未果,使用 Arthas 进行更深度的诊断。
-
Arthas启动报错
- 尝试连接应用时,Arthas抛出
java.lang.OutOfMemoryError: Metaspace异常。 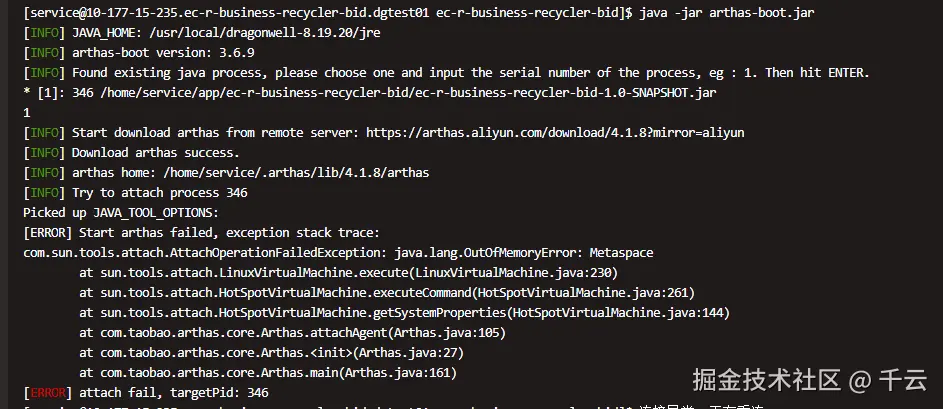
- 关键启示:Arthas本身运行需要JVM空间,此错误说明JVM的元空间(Metaspace)已满,无法再加载任何类(包括Arthas的Agent)。
- 尝试连接应用时,Arthas抛出
-
核对JVM参数
- 检查服务启动配置:
-XX:MaxMetaspaceSize=256m。 - 监控显示元空间使用已触及256MB上限。

- 检查服务启动配置:
-
验证时间点
- 对比应用日志,元空间内存溢出 (
OutOfMemoryError: Metaspace) 的时间与CPU飙升的时间完全吻合。 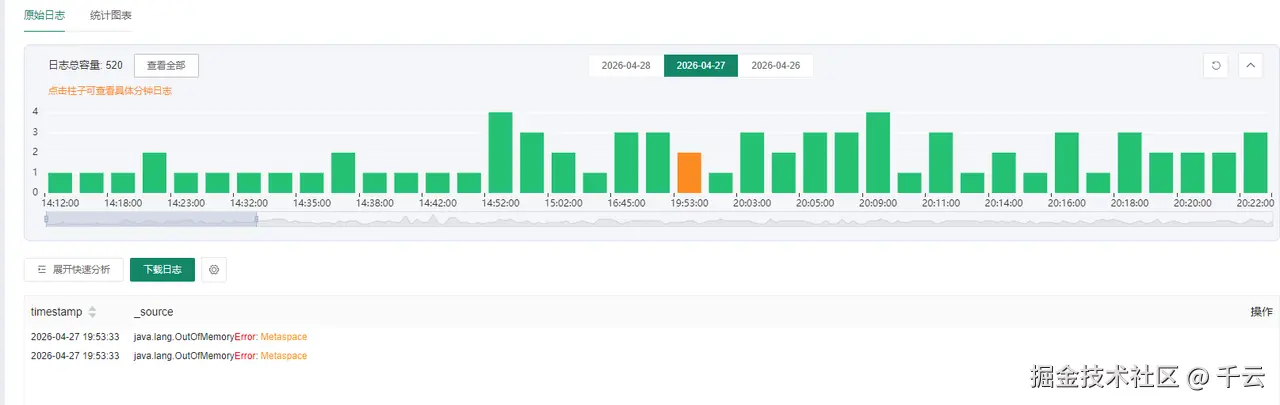
- 对比应用日志,元空间内存溢出 (
四、结论
问题的根本原因是:JVM元空间内存溢出 (Metaspace OOM)。
当元空间耗尽时,JVM无法加载新类,会频繁触发Full GC或执行大量的元空间清理操作,这两者都会大量消耗CPU资源,最终导致服务响应超时。
五、经验总结与反思
-
关注非堆内存:排查CPU问题时,除了堆内存、线程和业务逻辑,必须同时检查元空间等非堆内存区域。元空间溢出是导致CPU飙升的典型原因之一。
-
慎用
-XX:MaxMetaspaceSize:该参数用于限制元空间大小,设置不合理(尤其是过小)会直接引发溢出。- 建议:根据应用的类加载规模(如使用了Spring、动态代理、CGLIB等技术)合理设置。对于复杂应用,256MB可能偏小,建议结合实际监控数据(如通过
jstat -gc)调整为512MB甚至更高,或设置一个较大的初始值(-XX:MetaspaceSize)。
- 建议:根据应用的类加载规模(如使用了Spring、动态代理、CGLIB等技术)合理设置。对于复杂应用,256MB可能偏小,建议结合实际监控数据(如通过
-
善用Arthas利器:当常规监控和日志手段无法定位时,Arthas这类在线诊断工具能提供关键突破口。其启动报错本身就是一条极为有价值的线索。
-
完善监控体系:应将元空间的使用率和GC情况纳入监控告警范围,以便在问题发生前提前预警。