💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
💪🏻 2. AI编程变现手册,从学会AI编程到实现变现都可以
😁 3. 毕业设计专栏,毕业季咱们不慌忙,几千款毕业设计等你选。
❤️ 4. DeepSeek+RPA提效从入门到变现实战❤️5. 欢迎访问我的免费工具站
❤️ 6. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
文章目录
-
- [AI应用开发 ≠ 调API](#AI应用开发 ≠ 调API)
- 两年干了什么?说说几个硬骨头
- Java程序员搞AI应用,靠谱吗?
- 接下来的事
大家好,我是码农飞哥。
写了8年Java,CRUD写到手指发麻,微服务拆到天昏地暗,分库分表搞到怀疑人生。2024年初,我做了一个决定------从传统Java后端,转去做AI应用开发。
也不是什么深思熟虑的结果。就是项目上需要有人把大模型落地成产品,领导问了一圈没人接,最后问到我头上。我琢磨了一晚上,想着反正CRUD也写腻了,干脆试试。
然后我的技术栈就从Spring Boot + MySQL,变成了RAG + Agent + MCP + LangChain4j + Elasticsearch向量检索。
两年了。今天想跟大家掏心窝子聊聊------AI应用开发到底在干嘛?Java程序员转这个方向靠不靠谱?
AI应用开发 ≠ 调API
先说一个最大的误解。
每次跟朋友说我在做AI应用开发,对面的反应基本都是:
"不就是调一下大模型的API,套个壳嘛?"
说实话,没做之前我也这么想。做了之后我只想说------你来试试?
一个能上线的AI应用,大概是这么个结构:
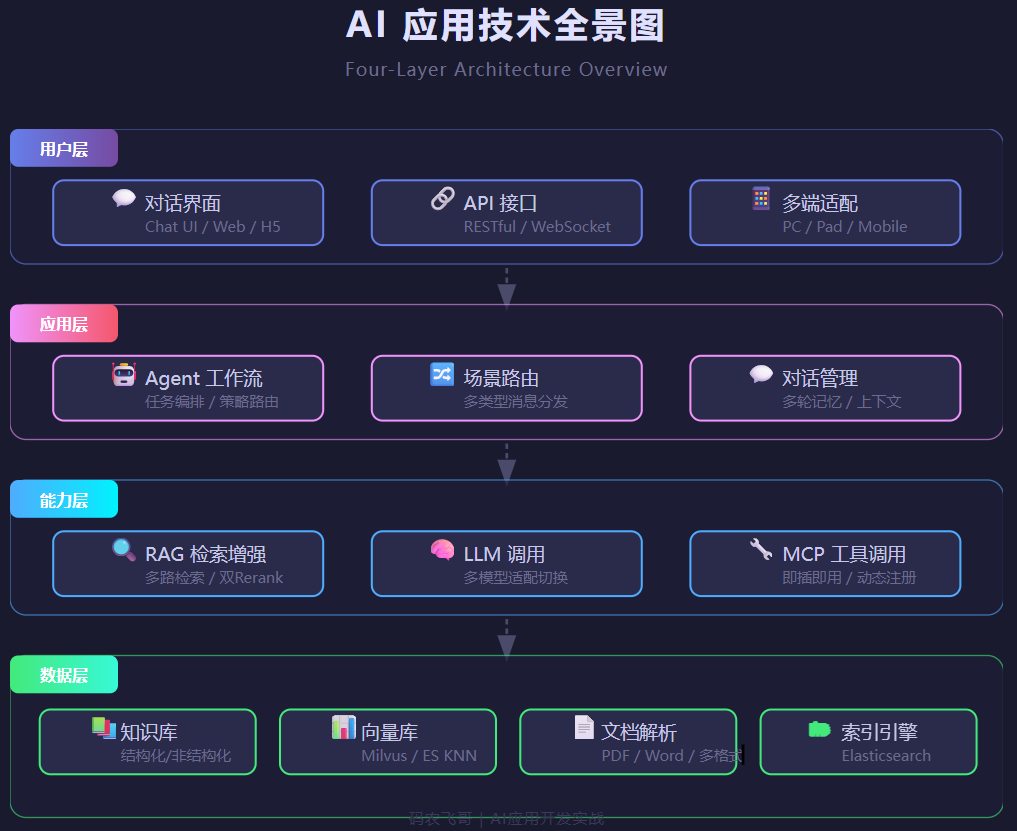
四层,每一层都是坑。
就说一个最常见的需求:"用户上传一个PDF,AI能回答里面的问题"。听起来不难吧?
背后的链路是这样的:文档格式识别 → 内容解析 → 文本切分 → 向量化 → 存入向量库 → 用户提问时检索 → 检索结果精排 → Prompt拼装 → 调LLM → 流式输出。十几个环节,哪个崩了用户体验都是灾难。
这不是写几行Python调LangChain就完事的,这是实打实的系统工程活。
而搞系统工程这件事,Java程序员还真不虚谁。
两年干了什么?说说几个硬骨头
RAG:看起来最简单,坑最深
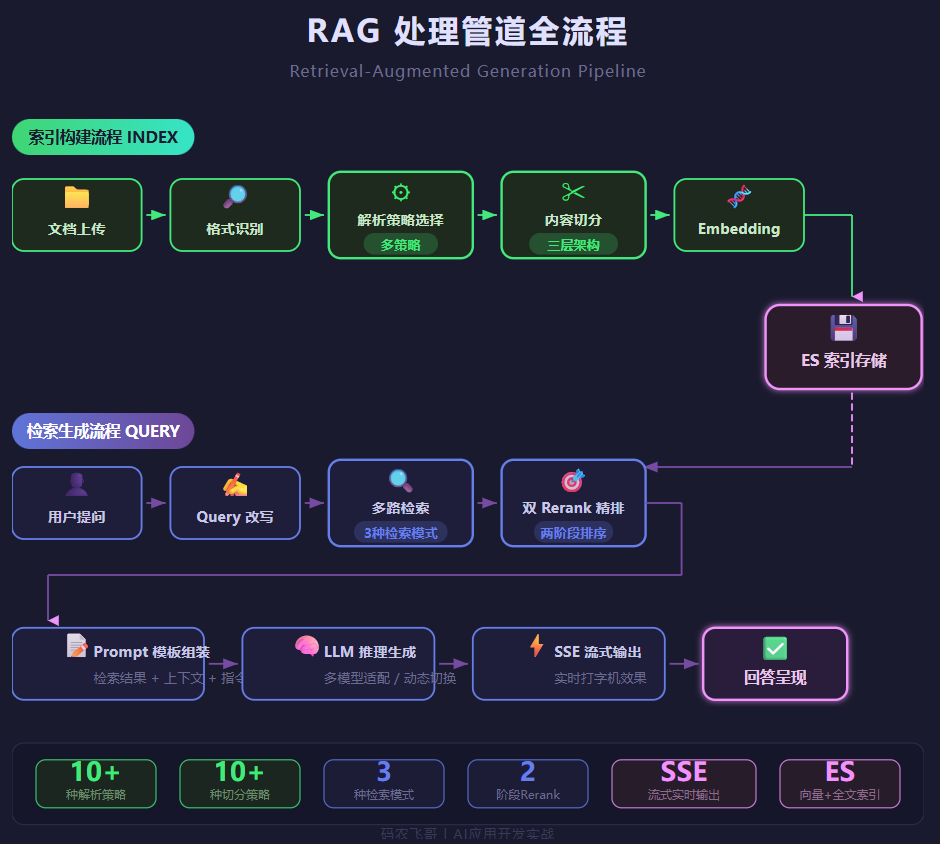
RAG这个词现在烂大街了------让AI回答问题之前先去知识库里翻翻,带着参考资料再回答。原理一句话就说清楚了,但做起来,真的想骂人。
文档解析这一关就差点把我干趴下。
用户传上来的文件什么妖魔鬼怪都有------PDF、Word、Excel、PPT、图片,甚至一些你听都没听过的格式。每种格式的解析方式完全不同。
PDF是重灾区。文字版的还好,有PDFBox能对付;但扫描件呢?纯图片,得上OCR。更离谱的是有些论文排版是两栏的,普通解析出来直接乱码------左边半句拼右边半句,读起来像密码电报。
搞到最后,光文档解析我就弄了十来种策略,用策略工厂模式管理。不同的文件格式、不同的内容特征,走不同的解析管道。这套东西调了将近一个月才稳定下来。
然后是切分。 文档解析完了是长文本,得切成小块才能检索。问题是------切多大?按什么维度切?
切太大,检索的时候不精准,一大坨文本里混着你要的和不要的;切太小,上下文全丢了,检索出来的片段看都看不懂。
我最后搞了一个分层的切分架构,十几种切分策略:固定长度、按段落、按句子、LLM语义切分、按目录结构切分......不同类型的文档用不同的策略组合。没有万能方案,全靠case by case地调。
最后是检索。 你以为做完Embedding存进向量库就完了?too young。
只用向量检索(余弦相似度)效果就那样------有些场景,传统的BM25关键词检索反而更准。最后我是三种检索模式并行跑(向量、全文、混合),再叠Rerank精排模型做二次排序,效果才勉强拉上来。
有人问RAG难不难,我的回答是:跑通Demo一周够了,做到能上线至少三个月。 中间全是细节上的死磕。
Agent:让AI不只是"你问我答"
RAG解决了"AI能回答知识库里的问题",但用户的需求远不止这个。
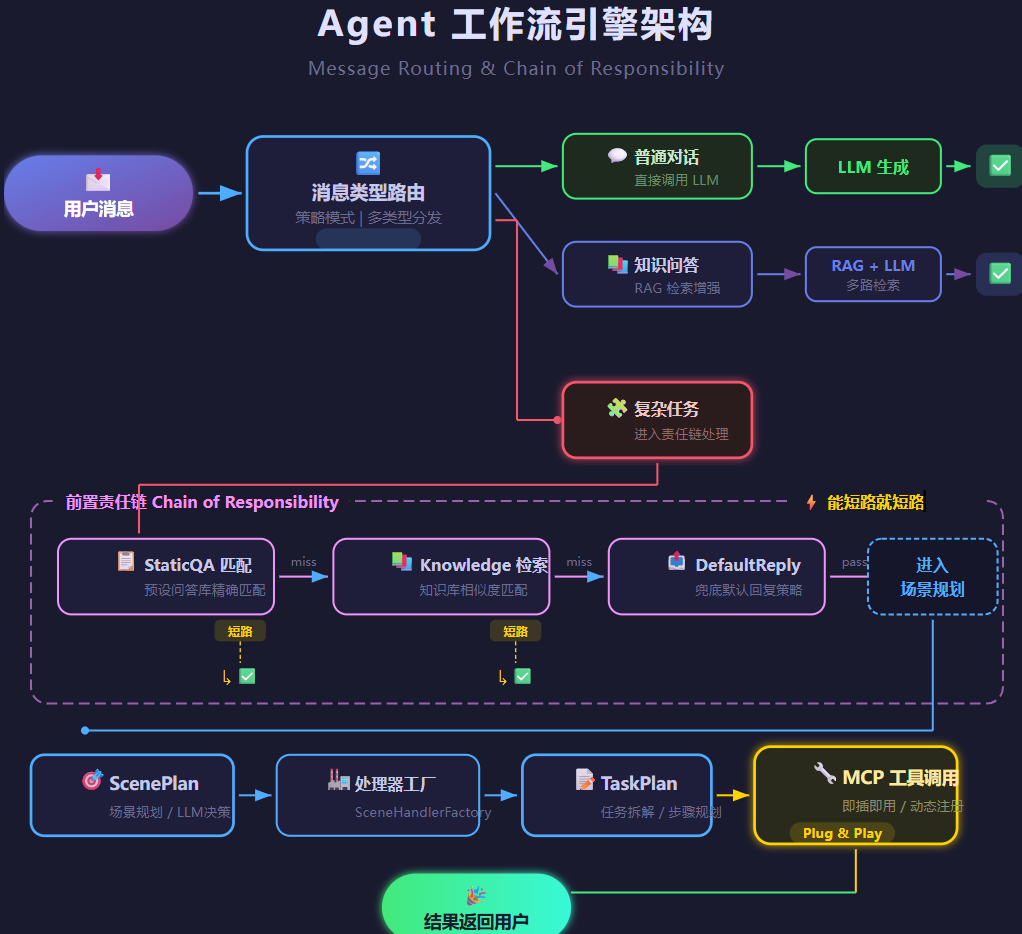
"帮我根据这份资料生成一套题目"------这就不是简单问答了,AI得能理解意图、规划步骤、调用工具、拼装结果。这就是Agent干的活。
我设计的思路是:不是所有请求都需要Agent,大部分普通对话直接调LLM就行,别杀鸡用牛刀。
所以我在调LLM之前加了一道前置过滤:先查静态问答库,再匹配知识库,如果这两步就能回答,直接返回,根本不用走到LLM那一步。这个机制上线之后,LLM调用量直接砍掉一大截,省了不少token费。(别问多少,问就是肉疼。)
真正需要Agent介入的复杂请求,才交给LLM做场景规划------判断用户意图,拆解成子任务,再分发到对应的处理器去执行。
说白了,Agent的核心思想就一句话:让LLM只干该干的事,能不调就不调。
MCP:让AI从"能说"变成"能做"
MCP(Model Context Protocol)是Anthropic搞的一个标准协议,你可以理解成AI世界的"USB接口"------不管什么外部工具,只要实现了这个协议,AI就能即插即用地调用。
在Java里集成MCP,核心就三件事:发现工具(listTools)、调用工具(callTool)、管好连接的生命周期。
概念不复杂,但生产环境里的坑不少。SSE长连接隔三差五断掉要做自动重连,工具调用超时了要有降级方案,不同场景需要动态切换MCP服务配置......这些东西不写到线上你根本不知道有多烦。
Java程序员搞AI应用,靠谱吗?
两年干下来,我的感受是:不光靠谱,某些方面还挺有优势的。
首先是工程化能力。策略模式、工厂模式、责任链------这些Java程序员写了好多年的东西,在AI应用里全都能用上。你让一个写Python的人从头搭一套策略工厂来管十几种文档解析方案,他大概率要抓狂。而Java程序员?这不就是我们的日常吗。
其次,真正的ToB项目、大厂的生产系统,后端几乎还是Java的天下。Python写个Demo确实快,但要扛并发、要上微服务、要保证7×24稳定运行------Java还是那个最稳的选择。
再加上LangChain4j这个框架现在已经比较成熟了,RAG、Agent、工具调用都支持,API设计也是Java程序员熟悉的风格,上手门槛不高。
当然我得说句公道话------AI生态这块,Python确实遥遥领先。 论文实现、模型库、数据处理的工具链,Python的丰富程度不是Java能比的。做算法研究、搞模型训练,Python是唯一选择,这没什么好争的。
但反过来想,Python做AI应用开发的教程满大街都是,Java的呢?你搜搜看,几乎找不到成体系的内容。
稀缺就是机会。这个坑,我来填。
接下来的事
从今天开始,这个号就干一件事:
不扯理论、不搬论文,只聊我在实际项目里踩过的坑和跑通的方案。
后面会持续更新这几个方向:
- RAG实战:文档解析、切分策略、检索方案、精排调优------每个环节怎么从"能用"到"好用"
- Agent实战:工作流引擎怎么设计、策略路由怎么做、任务规划和MCP集成的细节
- Java AI开发:LangChain4j怎么用、MCP SDK有哪些坑、跟Spring AI比怎么选
- AI编程提效:Claude Code、Cursor这些AI编程工具,在日常开发中到底能帮多少忙