其实我自己每个月在 AI 上花的钱不少,Claude、GPT、GLM 都有订阅。但其实有很大一部分预算其实是花在处理生活琐事上的------记账、外卖归类、做一个消费数据分析。这种活差不多每天都得跑一遍,所以token 烧得也不少,尤其是有时候开了深度思考的模型反而更容易给错数据。
后来我才反应过来,手里订阅一个不少,结果我一直在拿 Opus 的钱让它当我的计算器。有点奢侈了,所以我准备切换思路看看有没有节省token的办法。
一、我发现一个反直觉的事
在日常生活当中,我的直觉一直是有钱就上好的贵的效果肯定更好。Claude 4.7 Opus、GPT-5.5、深度思考模式,能切就切。
但是在我每天真正在干的活,尤其是一些琐事的数据整理计算:
-
把这个月的外卖订单按时间段算个总和
-
信用卡账单按"餐饮 / 打车 / 订阅"分一下类
-
一份消费明细 CSV 导进去问几个问题(这个月在哪吃得最多 / 哪几笔有点过了)
-
报销之前把几张发票的金额加一加
这些活其实顶配模型也都能干。Claude、GPT 我都试过,最后都跑出来了。问题是跑得不太对劲。
最直观的就是慢。一份几百行的消费明细,开了思考模式之后我能看着它"思考 6 秒""思考 11 秒"------其实本质只是这些数据相加而已没有很复杂的内容。

核心教训:简单数据 + 量大 + 重复,顶配模型在这种场景反而碍事。
二、在 OpenClaw 里试了百灵两个模型,最后选了 flash
我现在配模型的入口是 OpenClaw(之前文章写过怎么搭)。这次把蚂蚁百灵的两个挂上去对比着用:
-
Ling-2.6-1T:1 万亿总参数,每个 token 激活约 63B。属于真要分析事情那一档
-
Ling-2.6-flash:总参数 104B,每次只激活 7.4B
flash 这个有点意思。MoE 架构让它每次推理只激活 7.4B,跑起来体感像 7B 那种快模型,但参数底子是 104B。日常活里我反而怕真小模型给我幻觉,flash 这种"激活小、底子不算薄"的,挺合我口味。
1T 我本来打算直接挂日常用,跑了两次发现没必要。它适合干"给一份消费明细做分析"这种事------告诉我钱花在哪、有什么模式、要不要调整。但我每天 60% 以上的活其实是"把这份 csv 分组求和" / "把这五笔订单加起来"------结果对就行,不需要它思考。
所以选了 flash 跑日常,1T 留给我月底真想看一眼数据规律的时候切。
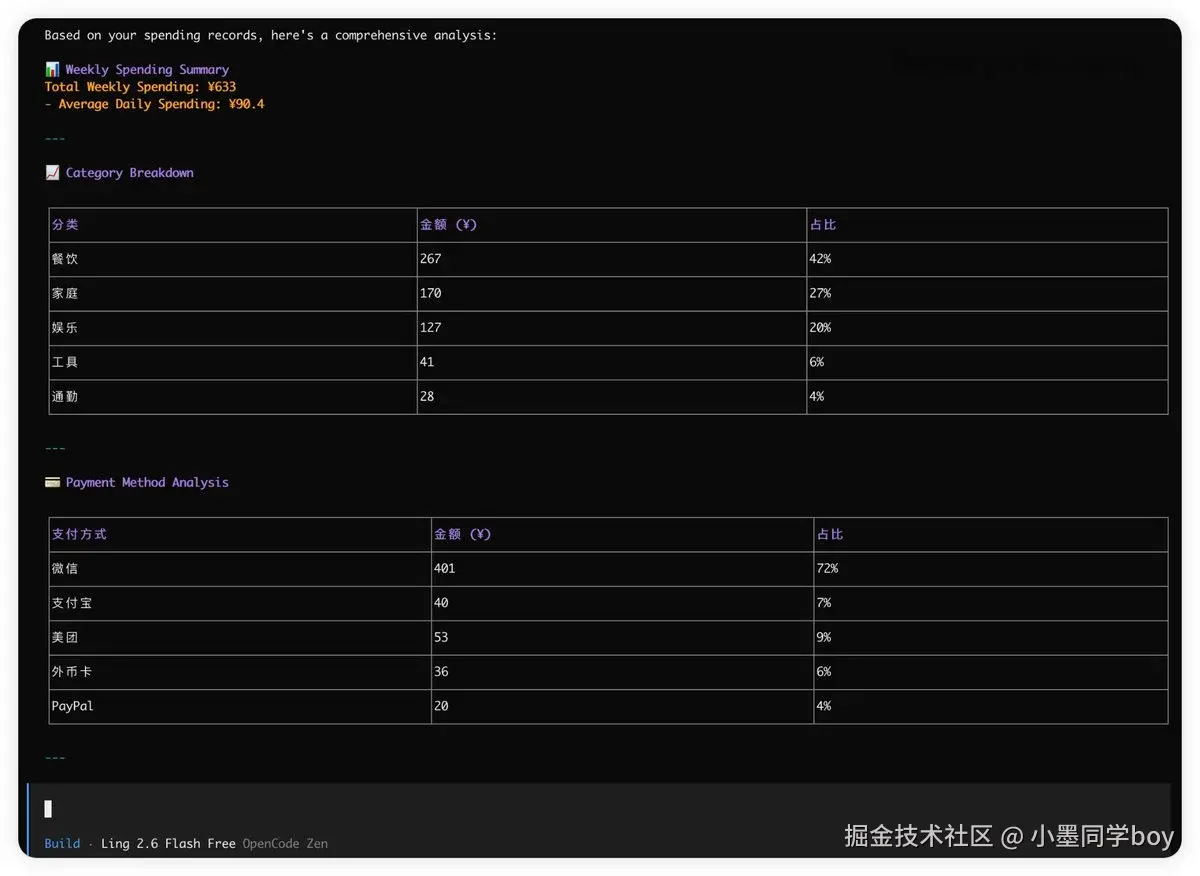
注意:Ling-2.6-flash 现在还在免费期,可以畅快的使用。
三、把一份数据导进去跑了一遍
这一节我会真实演示使用小模型完成我日常任务的情况------大致路线是把一份消费明细 txt 导进 OpenClaw,选择使用 Ling-2.6-flash,给他一段标准化的 prompt(按月份分组求和 / 按类别归类 / 找出最大几笔),然后看具体的结果。
第一步导入数据
这里我是导入了我自己一个月的数据,说多不多说少不少,而且我也是用了Claude去做数据审核,发展AI骗我做双层验证。
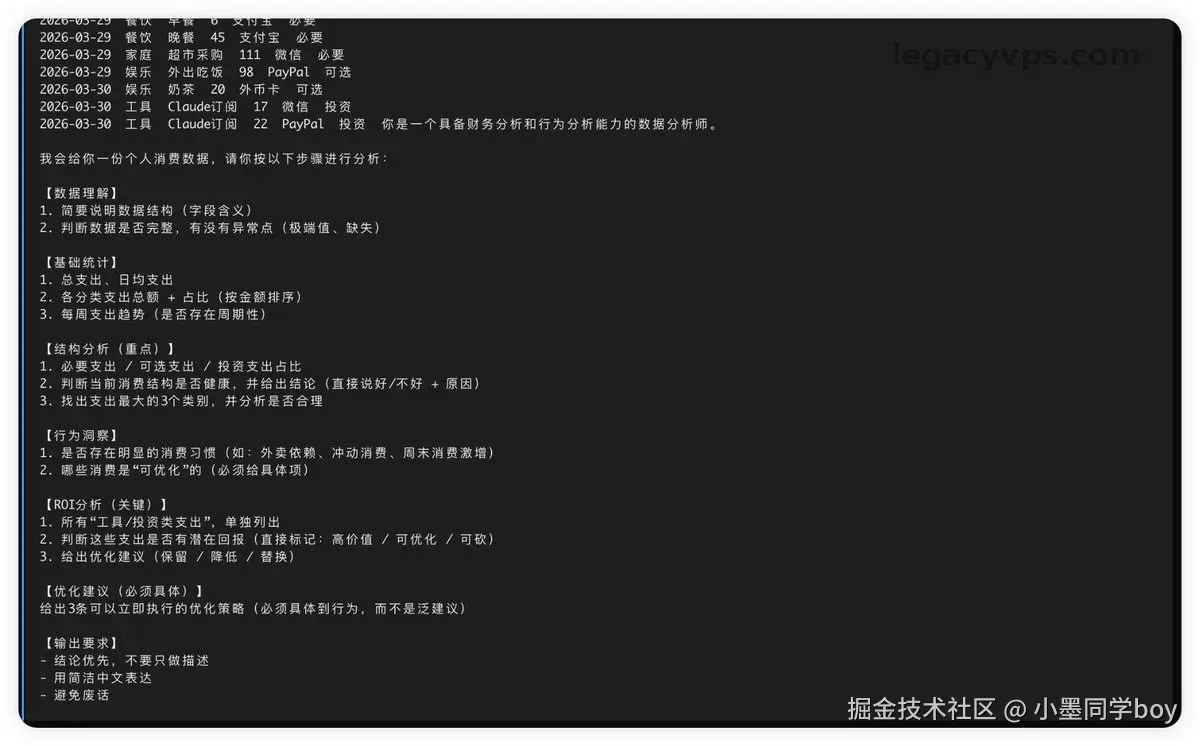
第二步给提示词
这是我自己习惯用的提示词,可能内容有点多,你们如果有相关的需要也可以去做修改,毕竟每个人的需求都不一样。
bash
你是一个具备财务分析和行为分析能力的数据分析师。
我会给你一份个人消费数据,请你按以下步骤进行分析:
【数据理解】
1. 简要说明数据结构(字段含义)
2. 判断数据是否完整,有没有异常点(极端值、缺失)
【基础统计】
1. 总支出、日均支出
2. 各分类支出总额 + 占比(按金额排序)
3. 每周支出趋势(是否存在周期性)
【结构分析(重点)】
1. 必要支出 / 可选支出 / 投资支出占比
2. 判断当前消费结构是否健康,并给出结论(直接说好/不好 + 原因)
3. 找出支出最大的3个类别,并分析是否合理
【行为洞察】
1. 是否存在明显的消费习惯(如:外卖依赖、冲动消费、周末消费激增)
2. 哪些消费是"可优化"的(必须给具体项)
【ROI分析(关键)】
1. 所有"工具/投资类支出",单独列出
2. 判断这些支出是否有潜在回报(直接标记:高价值 / 可优化 / 可砍)
3. 给出优化建议(保留 / 降低 / 替换)
【优化建议(必须具体)】
给出3条可以立即执行的优化策略(必须具体到行为,而不是泛建议)
【输出要求】
- 结论优先,不要只做描述
- 用简洁中文表达
- 避免废话第三部验证结果
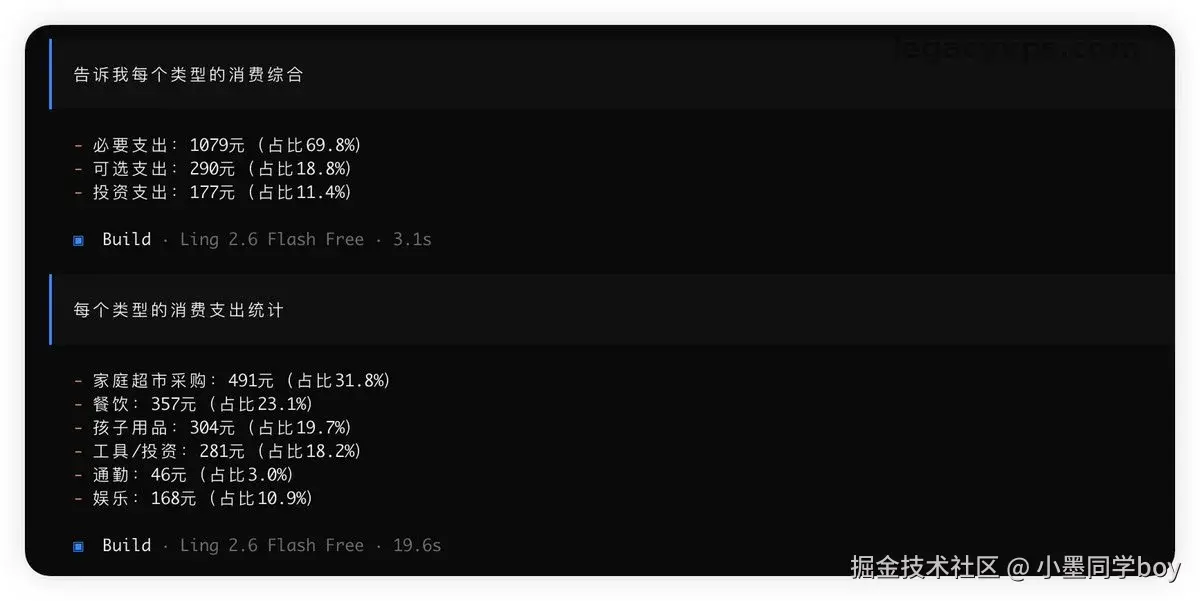
整体跑下来还是非常快的,只用了22s就得出了结论,比我那深度思考跑了五六分钟的GPT得出的结果还是差不多的,只是说细节问题是有些出入。
如果你也想跟一遍,重点要注意这三件事:
-
数据怎么导。flash 长上下文够用,但一次别塞太多,太多了任何模型都会飘
-
prompt 怎么写。简单数据不要多说话,直接告诉它要什么结果(分组、求和、整理成表)
-
怎么验证。flash 跑完直接拿原数据自己抽样复核,别全信。

避坑提示:让模型干"算"这件事,永远要自己抽样对一下。这跟模型贵不贵没关系,是 AI 的通病。
四、跑完之后我才确认这条路对了
我跑了几天才得出的结论,不然怕自己只是新鲜感。这一周里我把日常那几类活全部切到 Ling-2.6-flash 上,深度模型只在我真要分析"我钱花得怎么样"的时候才开。
直观感受有几个:
-
速度真的快。深度模型的"思考时间"经常拉到 10 秒往上,flash 几乎不等
-
数据对得上。我抽样核了三天,没出过"它脑补一个不存在的字段"或者"分组算错"
-
token 烧得少。其实多也没关系因为现在是免费使用,我跑了很多次都没有达到限额。
至于 1T,我这一周也切回去用过两次。一次是月底我想看一下"我这个月花钱的模式有什么变化",一次是我对着一份消费数据想让它给我提点建议。这两种活 flash 也能给结果,但味道偏机械------给的是对的答案,缺少"针对你这份数据"的判断感。
核心教训:分活别按贵不贵分,按要不要思考分。需要思考的,1T 的脑子值这个钱。只要结果的,flash 够了。
收尾
不同的工作要分给不同的模型。你下次让 AI 干的活是什么?发我看看,没准你也用不上那么贵的脑子。
如果你也每天用 AI 算账、做数据、整理表格,可以照下面这个最小路径试试:
-
在你现在用的入口(OpenClaw / 或者你自己的 API 渠道)挂上 Ling-2.6-flash
-
把你日常最重复的那一类活,从顶配模型切过去试一周
-
中间出来某个数据让你想多问一句"为什么",那个时候再切回旗舰
我也好奇大家自己是怎么分的。你最近一次让 AI 干的活是哪种?是真该上 1T,还是其实 flash 就够?发我看看,咱俩对一下。