目录
[五、tool calling](#五、tool calling)
一、ChatClient
ChatClient 基于ChatModel进行了封装提供了通用的 API,它适用所有的大模型, 使用ChatClient可以让你面向SpringAi通用的api 而无需面向为每一种不同的模型的api来进行编程, 虽然您仍然可以使用 ChatModel 来实现某些模型更加个性化的操作(ChatModel更偏向于底层),但 ChatClient 提供了灵活、更全面的方法来构建您的客户端选项以与模型进行交互: 比如系统提示词、格式式化响应、聊天记忆 、tools 都更加易用和优雅,所以除非ChatClient无法实现,否则我们优先考虑用ChatClient。
二、提示词类型
SYSTEM系统角色:引导AI的行为和响应方式,设置AI如何解释和回复输入的参数或规则。这类似于在发起对话之前向AI提供指令。
USER用户角色:代表用户的输入------他们向AI提出的问题、命令或语句。这个角色至关重要,因为它构成了AI响应的基础。
ASSISTANT助手角色:AI 对用户输入的响应。它不仅仅是一个答案或反应,对于维持对话的流畅性至关重要。通过追踪 AI 之前的响应(其"助手角色"消息),系统可以确保交互的连贯性以及与上下文的相关性。助手消息也可能包含功能工具调用请求信息。它就像 AI 中的一项特殊功能,在需要执行特定功能(例如计算、获取数据或其他不仅仅是对话的任务)时使用。
TOOL工具/功能角色:工具/功能角色专注于响应工具调用助手消息返回附加信息。
java
public enum MessageType {
USER("user"), // 用户(显示)
ASSISTANT("assistant"), // AI回复
SYSTEM("system"), // 系统 (隐式)
TOOL("tool"); // 工具
...
}三、Advisor对话拦截
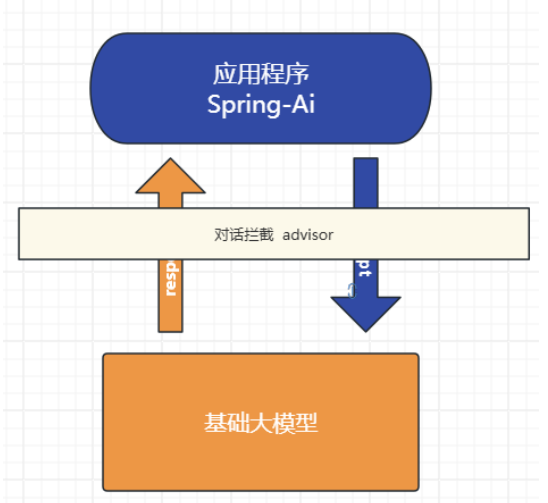
1.日志拦截:由于整个对话过程是一个"黑盒", 不利于我们调试, 可以通过SimpleLoggerAdvisor拦截对话记录可以帮助观察我们发了什么信息给大模型便于调试。设置defaultAdvisors
java
@SpringBootTest
public class AdvisorTest {
ChatClient chatClient;
@BeforeEach
public void init(@Autowired
DeepSeekChatModel chatModel) {
chatClient = ChatClient
.builder(chatModel)
.defaultAdvisors(
new SimpleLoggerAdvisor()
)
.build();
}
@Test
public void testChatOptions() {
String content = chatClient.prompt()
.user("Hello")
.call()
.content();
System.out.println(content);
}
}2.自定义拦截
四、对话记忆
大型语言模型 (LLM) 是无状态的,这意味着它们不会保留先前交互的信息。
SpringAi提供了一个ChatMemory的组件用于存储聊天记录,允许您使用 LLM 跨多个交互存储和检索信息。并且可以为不同用户的多个交互之间维护上下文或状态。
可以在每次对话的时候把当前聊天信息和模型的响应存储到ChatMemory, 然后下一次对话把聊天记录取出来再发给大模型。
但是这样做未免太麻烦! 能不能简化? 思考一下!
用我们之前的Advisor对话拦截是不是就可以不用每次手动去维护了。 并且SpringAi早已体贴的为我提供了ChatMemoryAutoConfiguration自动配置类
SpringAi提供了PromptChatMemoryAdvisor 专门用于对话记忆的拦截
java
@SpringBootTest
public class ChatMemoryTest {
ChatClient chatClient;
@BeforeEach
public void init(@Autowired
DeepSeekChatModel chatModel,
@Autowired
ChatMemory chatMemory) {
chatClient = ChatClient
.builder(chatModel)
.defaultAdvisors(
PromptChatMemoryAdvisor.builder(chatMemory).build()
)
.build();
}
@Test
public void testChatOptions() {
String content = chatClient.prompt()
.user("我叫超梦 ?")
.advisors(new ReReadingAdvisor())
.call()
.content();
System.out.println(content);
System.out.println("--------------------------------------------------------------------------");
content = chatClient.prompt()
.user("我叫什么 ?")
.advisors(new ReReadingAdvisor())
.call()
.content();
System.out.println(content);
}
}五、tool calling
tool calling也可以直接叫tool(也称为function-call), 主要用于提供大模型不具备的信息和能力:
信息检索:可用于从外部源(如数据库、Web 服务、文件系统或 Web 搜索引擎)检索信息。目标是增强模型的知识,使其能够回答无法回答的问题。例如,工具可用于检索给定位置的当前天气、检索最新的新闻文章或查询数据库以获取特定记录。 这也是一种检索增强方式。
采取行动:例如发送电子邮件、在数据库中创建新记录、提交表单或触发工作流。目标是自动执行原本需要人工干预或显式编程的任务。例如,可以使用工具为与聊天机器人交互的客户预订航班,在网页上填写表单等。
六、MCP
问题:
-
当有服务商需要将tools提供外部使用(比如高德地图提供了位置服务tools, 比如百度提供了联网搜索的tools...)
-
或者在企业级中, 有多个智能应用,想将通用的tools公共化
怎么办?
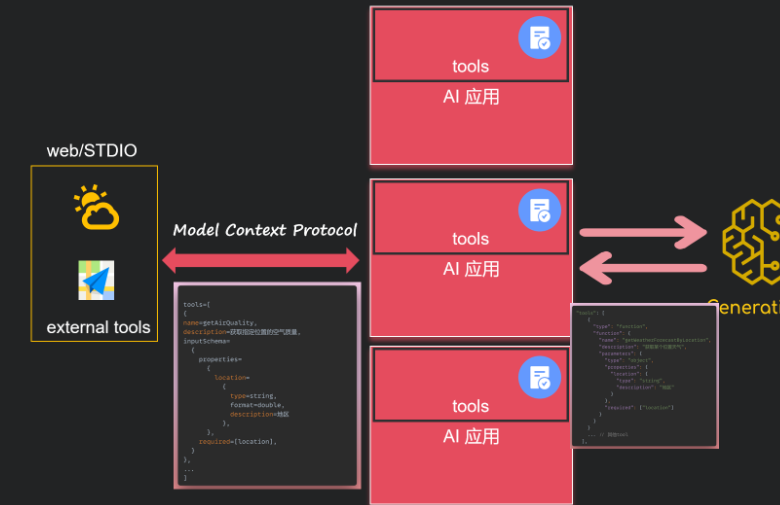
可以把tools单独抽取出来, 由应用程序读取外部的tools。 那关键是怎么读呢? 怎么解析呢? 如果每个提供商各用一种规则你能想象有多麻烦! 所以MCP就诞生了, 他指定了标准规则, 以jsonrpc2.0的方式进行通讯。
那问题又来了, 以什么方式通讯呢? http? rpc? stdio? mcp提供了sse和stdio这2种方式。
七、RAG简介
检索增强生成(Retrieval-augmented Generation)
对于基础大模型来说, 他只具备通用信息,他的参数都是拿公网进行训练,并且有一定的时间延迟, 无法得知一些具体业务数据和实时数据, 这些数据往往在各种文件中(比如txt、word、html、数据库...)
虽然function-call、SystemMessage可以用来解决一部分问题
但是它只能少量,并且针对的场景不一样
如果你要提供大量的业务领域信息, 就需要给他外接一个知识库:
比如
-
我问他退订要多少费用
-
这些资料可能都由产品或者需求编写在了文档中,所以需要现在需求信息存到向量数据库(这个过程叫Embedding, 涉及到文档读取、分词、向量化存入)
-
去向量数据库中查询"退订费用相关信息"
-
将查询到的数据和对话信息再请求大模型
-
此时会响应退订需要多少费用