文章目录
- Pre
- 一、问题背景:为什么需要"魔法关键词"?
- [二、整体架构:从 Prompt 到模式状态的五级流水线](#二、整体架构:从 Prompt 到模式状态的五级流水线)
-
- [2.1 在 Claude Code 钩子里的位置](#2.1 在 Claude Code 钩子里的位置)
- [2.2 五阶段检测流水线概览](#2.2 五阶段检测流水线概览)
- [三、阶段一:从多种 JSON 结构中提取 Prompt](#三、阶段一:从多种 JSON 结构中提取 Prompt)
- 四、阶段二:提示词清理------先消除一切"看上去像关键词"的噪音
-
- [4.1 `sanitizeForKeywordDetection()` 做了什么?](#4.1
sanitizeForKeywordDetection()做了什么?)
- [4.1 `sanitizeForKeywordDetection()` 做了什么?](#4.1
- [五、阶段三:信息性意图过滤------提到 ≠ 调用](#五、阶段三:信息性意图过滤——提到 ≠ 调用)
-
- [5.1 信息性意图模式](#5.1 信息性意图模式)
- [5.2 引用跨度隔离](#5.2 引用跨度隔离)
- [5.3 引用内容检测](#5.3 引用内容检测)
- [5.4 诊断意图检测](#5.4 诊断意图检测)
- [5.5 逐匹配粒度的 `hasActionableKeyword()`](#5.5 逐匹配粒度的
hasActionableKeyword())
- 六、阶段四:关键词匹配------多语言、类别化的触发模式
- 七、阶段五:冲突消解、状态写入与输出消息
-
- [7.1 去重与优先级排序](#7.1 去重与优先级排序)
- [7.2 有状态模式的文件写入](#7.2 有状态模式的文件写入)
- 八、关键词目录:从自然语言到技能的映射表
-
- [8.1 ralplan:只有"明确点名启用"才算调用](#8.1 ralplan:只有“明确点名启用”才算调用)
- [8.2 ai-slop-cleaner:精准瞄准"AI 生成垃圾"的清理需求](#8.2 ai-slop-cleaner:精准瞄准“AI 生成垃圾”的清理需求)
- [九、两类输出:行内模式消息 vs 技能调用](#九、两类输出:行内模式消息 vs 技能调用)
- 十、安全与防线:如何防止"跑飞"和"注入风险"?
-
- [10.1 Team worker 防护与 Hook 跳过](#10.1 Team worker 防护与 Hook 跳过)
- [10.2 Review 模板抑制](#10.2 Review 模板抑制)
- [10.3 Ralplan 快捷后续调用](#10.3 Ralplan 快捷后续调用)
- [10.4 故障开放与权限控制](#10.4 故障开放与权限控制)
- [十一、与整个 Hook 生态的协同:入口,而不是孤岛](#十一、与整个 Hook 生态的协同:入口,而不是孤岛)
- 十二、对开发者和集成者的启示
- 结语:从命令式交互到"语义即编排"
Pre
OMC - 01 用 19 个 Agent 打造你的 Claude Code"工程团队":oh-my-claudecode 深度解析与实战指南
OMC - 02 五分钟起步,走向多智能体协作:深入解析 oh-my-claudecode 快速开始与架构设计
OMC - 03 从 0 到高效:Oh My ClaudeCode 安装与实践全指南
OMC - 04 用好 Oh-My-ClaudeCode 的 30 个会话技能:从"帮我写点代码"到端到端自动交付
OMC - 05 从单人到多 Agent:Oh-my-claudecode 的插件架构解析
OMC - 06 从"大模型管家"到"十九人专家团队":oh-my-claudecode 的多 Agent 工程实践
OMC - 07 把「选模型」当成一门工程学:oh-my-claudecode 的三层模型路由实践
OMC - 08 在多 Agent 时代,如何优雅地「分工协作」:oh-my-claudecode 委托分类体系深度解读
OMC - 09 oh-my-claudecode 的多 Agent 编排实战
OMC - 10 从创意到"免看管生产力":深入解析 Oh-My-ClaudeCode 的 Autopilot 与 Ralph 模式
OMC - 11 跨供应商 CCG 合成:让 Claude、Codex、Gemini 一起给你"做代码评审"
OMC - 12 把 Claude Code 变成「可编程开发同事」:oh-my-claudecode 技能系统深度解析
OMC - 13 深入理解 Oh My ClaudeCode 的 Hooks 生命周期:为 AI 编排搭建"中枢神经系统"
OMC - 14 MCP 工具服务端:oh-my-claudecode 的中枢神经系统
在日常用 AI 写代码、跑 Agent 的过程中,你可能已经厌倦了各种「/命令」、「模式开关」和冗长说明。理想状态是什么?随口一句 "帮我端到端搞定这个应用",系统就自动切到正确的模式、拉起合适的技能,然后一路跑到收尾。
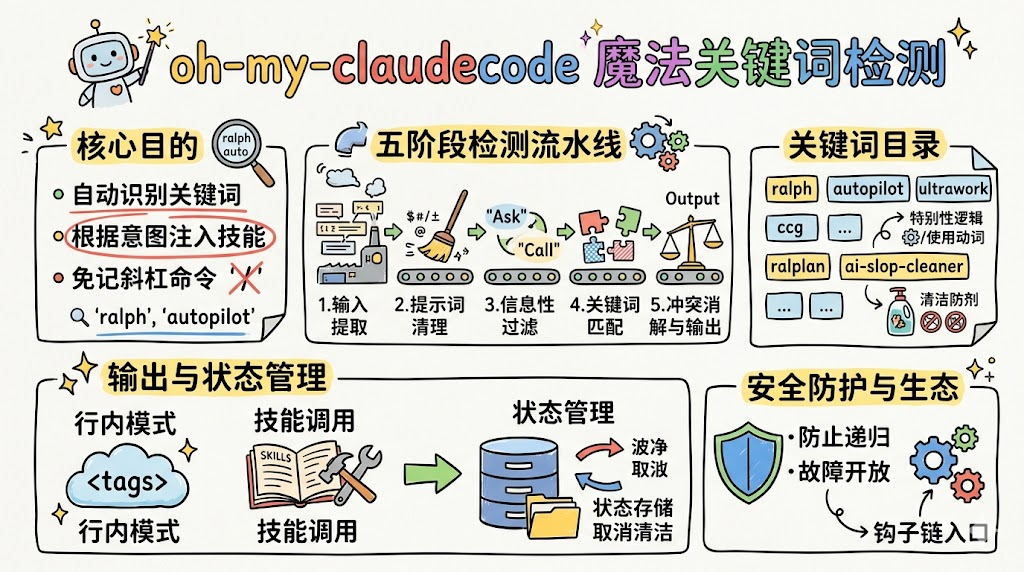
oh-my-claudecode 里的 Magic Keyword Detection(魔法关键词检测)系统,基本就是在解决这件事:它在每次用户输入时自动拦截提示词,识别是否包含可操作的"魔法关键词",并隐式注入对应的模式、技能和状态,做到「不需要记住任何斜杠命令,但整个系统依然高度可编排」。
一、问题背景:为什么需要"魔法关键词"?
从工程师视角看,"模式"和"技能"是把大模型变成专业开发助手的关键:
- 模式负责行为策略,例如长程规划的 ralph 、自动巡航的 autopilot 、高并发执行的 ultrawork 等。
- 技能负责具体能力,例如代码审查、深度搜索、重构清理等,可以看成针对特定任务的知识与工作流封装。
传统做法通常有两种:
- 通过 UI 开关切模式,比如界面里勾选「启用深度搜索」;
- 通过显式命令触发,比如输入
/tdd、/autopilot。
这两种方式在真实开发场景中都有明显问题:
- 记忆负担大:模式和技能一多,很难记得住每个命令;
- 语义割裂:你本来想自然描述需求,却不得不停下来想一行命令;
- 上下文易错位:模式开关和具体任务描述混在一起,很容易导致执行意图和系统状态不一致。
魔法关键词检测系统的出发点是一个简单但很现实的观察:开发者不应该需要记住斜杠命令。
取而代之的是:只要在自然语言里表达出类似"自动跑完整个流程"、"做一次安全审查"这类意图,系统就自动解析到模式与技能层,完成所有底层配置与状态管理。
二、整体架构:从 Prompt 到模式状态的五级流水线
2.1 在 Claude Code 钩子里的位置
在 Claude Code 里,每次用户提交 Prompt 都会经过一套 Hook 生命周期。魔法关键词检测器被挂载在 UserPromptSubmit 阶段,并且是整个 Hook 链条里最先跑的那个脚本,位置在技能注入器之前。
当用户输入一段提示词,流程大致如下:
- Claude Code 将完整的提示 JSON 通过
run.cjs这个垫片脚本传给keyword-detector.mjs。 run.cjs负责找到正确的 Node 二进制、处理 nvm/fnm/Windows 等差异,并强制执行一个配置好的超时时间(魔法关键词检测是 5 秒)。- 检测脚本返回结构化结果,通过
hookSpecificOutput.additionalContext回传给 Claude Code,其核心结构是:{ continue: true, hookSpecificOutput: { hookEventName: "UserPromptSubmit", additionalContext: "..." } }。
有几个关键设计点值得注意:
message字段刻意不使用,因为这并不是 Claude Code Hook API 的稳定接口的一部分,只用hookSpecificOutput做扩展。- 所有异常都遵循「故障开放」原则:失败时返回
continue: true, suppressOutput: true,绝不阻塞正常对话流程。
2.2 五阶段检测流水线概览
整个检测流水线是一个从"原始输入"到"模式状态与注入消息"的五段处理管线:
- 阶段 1:输入提取(解决 JSON 结构差异)
- 阶段 2:提示词清理(剥掉那些会制造误报的噪音)
- 阶段 3:信息性意图过滤(区分"提到"和"调用")
- 阶段 4:关键词匹配(多语言正则匹配类别化关键词)
- 阶段 5:冲突消解与输出(优先级排序、状态写入、消息注入)
这种设计极度工程化:前几个阶段集中在"减少误报",后面两个阶段才负责"决定具体算什么模式"和"如何把结果喂回系统"。
三、阶段一:从多种 JSON 结构中提取 Prompt
在 UserPromptSubmit Hook 中,输入并不总是一个简单的 { prompt: string }。为了兼容不同版本和不同调用方式,检测器使用一个 extractPrompt() 函数,支持三种变体:
{ prompt }{ message: { content } }{ parts: [{ type: "text", text }] }数组形式。
实现上的一个关键点是:
- 一旦解析失败(比如 JSON 非法、结构不在预期范围),会直接返回空字符串;
- 之后的整个检测流程看到空字符串,相当于"什么都没发生",不会触发任何模式或技能调用。
用一句话概括这个阶段的工程哲学:宁可不触发,也不能错触发。坏数据绝不能导致误调用。
四、阶段二:提示词清理------先消除一切"看上去像关键词"的噪音
在做任何关键词识别之前,系统会对用户提示做一次相当激进的清理。目标有两个:
- 避免对代码、日志、历史输出、URL 等进行误触发;
- 尽可能只对"真正面向系统的自然语言指令"做判断。
4.1 sanitizeForKeywordDetection() 做了什么?
核心清理函数会剥离以下几类内容:
- HTML/Markdown 注释;
- XML 风格标签块,例如多行
<...>里的内容; - 自闭合 XML 标签;
- 所有
http://和https://开头的 URL; - Markdown 引用与表格行(例如
> The autopilot mode is...); - Unix 风格的路径,如
src/tools/ralph/index.ts; - 围栏代码块
...; - 反引号包裹的行内代码,例如
ralph。
在这一步之前,还有一层 stripPastedCommandPayloads() 专门用来处理粘贴内容和系统输出:
- 角色边界的 XML 块(比如内部的一些
<system>、<assistant>) - Magic Keyword 的头部信息(
[MAGIC KEYWORDS DETECTED: ...]) - Shell 终端会话记录(如
$ ralph ...) - 用户请求回显(系统把之前用户说的话再打印一遍)
- 技能会话记录(
Skill: oh-my-claudecode:...) - Git diff 片段。
直接效果是:关键词检测器只"看"用户当前真实输入的自然语言意图,而不是它自己或别的系统之前的输出。 这在实际使用中极大降低了"贴个日志就把模式搞乱了"的情况。
五、阶段三:信息性意图过滤------提到 ≠ 调用
这是整个架构里最"聪明"的一层,也是防误报的核心所在。
一个典型的坑是:
"给我解释一下 ralph 模式和 autopilot 模式的区别。"
如果只是做简单正则匹配,这句里有两个关键词,系统会立刻打开两个模式。但真实意图显然只是"说明文档"。
为了解决"提到 vs 调用"的问题,系统在每次匹配关键词时都进行一个 80 字符范围的上下文窗口分析,具体采用四类策略:
5.1 信息性意图模式
通过一组多语言的触发词判断用户是在"问"还是在"用",例如:
- 英文:
what is、how to use; - 韩文:
뭐야; - 日文:
とは; - 中文:
什么是等。
只要这些模式出现在关键词附近,就倾向于把这次出现视为信息性提及,而非激活调用。
5.2 引用跨度隔离
如果关键词出现在引号或类似引用结构里,例如 "ralph",并且附近有问题词(如 why、how many、왜 等),系统会认为用户是在「引用这个词来讨论」,而不是在「执行这个模式」。
5.3 引用内容检测
还有一类更复杂的场景,比如对多种模式的横向比较文章。这里采用了一套复合启发式:
- 是否出现对比标记(
vs.、compared to等); - 是否出现解释性结构(
summary:、pros:、→); - 是否在一个提示里提到多个不同模式名称等。
系统要求至少满足两个以上的信号才把这次提及压制,避免单一特征判定导致误杀。
5.4 诊断意图检测
当用户说:"ralph 一直在循环"、"autopilot 有 bug"这样的句子时,真正意图是"报错/反馈",而不是"再开一次 ralph/autopilot"。这里通过匹配错误报告、bug 描述等语言模式,把这类用法排除在激活之外。
5.5 逐匹配粒度的 hasActionableKeyword()
实现上,hasActionableKeyword() 不是"在整段文本里搜索一次关键词",而是:
- 遍历每个匹配位置;
- 对每次出现分别用上述策略判断"有没有可操作意图"。
这种粒度让一个 Prompt 可以同时做到:
- 先引用一下 ralph 的概念;
- 然后在后面一句自然语言里真正"调用" ralph。
只有后者那一次会被视为可执行的激活。这很好地解决了早期版本里"只要提到名字就触发"的误报级联问题。
六、阶段四:关键词匹配------多语言、类别化的触发模式
在完成清理和意图过滤之后,系统会用一组按类别组织的正则模式进行关键词检测。
这些类别对应了具体的模式或技能,例如:
- ralph
- autopilot
- ultrawork
- ccg
- ralplan
- deep-interview
- ai-slop-cleaner
- tdd
- code-review
- security-review
- ultrathink
- deepsearch
- analyze
- wiki 等。
每个类别的模式集合都比较丰富:
- 英文全称与缩写(如
autopilot、auto pilot、ulw、uw); - 多语言变体(韩文、日文、中文等,例如
울트라워크、씨씨지); - 与自然语言表达结合的短语(如
build me an app、handle it all、end to end被视作 autopilot 的触发语境)。
这样设计的结果是:用户在不同语言、不同习惯下的表达,都有机会被统一映射到正确的模式或技能,而不必硬记英文关键词。
七、阶段五:冲突消解、状态写入与输出消息
当所有匹配收集完毕后,系统会进行最后的决策和输出构造。
7.1 去重与优先级排序
首先对名称去重,然后调用 resolveConflicts() 做优先级处理。
有一个硬规则:取消类关键词是排他的。
- 一旦检测到
cancelomc或stopomc与其他关键词同时出现,只执行取消逻辑; - 会清除所有活跃模式相关的状态文件,相当于对话中的"总刹车"。
其余关键词则按这条优先级链排序:
ralph → autopilot → ultrawork → ccg → ralplan → deep-interview → ai-slop-cleaner → tdd → code-review → security-review → ultrathink → deepsearch → analyze → wiki。
优先级的意义在于:当一个 Prompt 同时暗示多种模式时,决定谁先执行、谁在后续被组合进来。
7.2 有状态模式的文件写入
对于有状态模式(ralph、autopilot、ultrawork、ralplan),系统会把模式状态写入一组 JSON 文件,用于后续 Hook 和持久执行逻辑读取:
- 首选路径:
.omc/state/sessions/{sessionId}/{mode}-state.json(会话级别) - 兼容性回退:
.omc/state/{mode}-state.json(旧版路径) - 取消时顺带清理
~/.omc/state/{mode}-state.json等历史路径。
在这些状态里,系统会记录当前模式是否开启、一些额外参数,甚至跨模式的关联,例如:
- 当 ralph 在没有显式 ultrawork 的情况下被激活时,系统会自动为 ultrawork 写入状态并标记
linked_ultrawork: true,因为语义上 ralph 代表"最大化并行执行"。
八、关键词目录:从自然语言到技能的映射表
魔法关键词系统的另一块核心是完整的关键词目录,它定义了"看到怎样的语言,就应该触发怎样的模式或技能"。
下面用一张表简单整理几个重要条目(并非原表全部):
| 关键词 | 触发模式示例 | 激活要求 | 目标技能 / 模式 |
|---|---|---|---|
| cancelomc / stopomc | cancelomc、stopomc |
直接提及,无信息性过滤 | cancel(取消所有模式) |
| ralph | ralph、don't stop、must complete、until done 等 |
需有可操作意图 | ralph 模式 |
| autopilot | autopilot、auto pilot、build me an app、handle it all 等 |
需有可操作意图 | autopilot 模式 |
| ultrawork | ultrawork、ulw、uw、울트라워크 |
需有可操作意图 | ultrawork 模式 |
| ccg | ccg、claude-codex-gemini、씨씨지 |
需有可操作意图 | ccg 模式 |
| ralplan | ralplan、랄플랜 |
必须显式调用(命令或激活动词附近) | ralplan 规划模式 |
| deep-interview | deep interview、ouroboros、딥인터뷰 |
需有可操作意图 | deep-interview 技能 |
| ai-slop-cleaner | 反 slop 术语或(清理动词 + 坏味道词)组合 | 特殊复合逻辑 | ai-slop-cleaner 技能 |
| tdd | tdd、test first、red green、테스트 퍼스트 |
需有可操作意图 | tdd 技能 |
| code-review | code review、review code、코드 리뷰 |
可操作意图且不是 review 模板上下文 | code-review 技能 |
| security-review | security review、review security、보안 리뷰 |
可操作意图且不是 review 模板上下文 | security-review 技能 |
| ultrathink | ultrathink、think hard、think deeply、울트라씽크 |
需有可操作意图 | ultrathink 模式 |
| deepsearch | deepsearch、search the codebase、find in code 等 |
需有可操作意图 | deepsearch 模式 |
| analyze | deep-analyze、deepanalyze、딥 분석 |
需有可操作意图 | analyze 模式 |
| wiki | wiki this、wiki add、wiki query 等 |
需有可操作意图 | wiki 技能 |
其中,有两个类目拥有特别的激活语义:
8.1 ralplan:只有"明确点名启用"才算调用
ralplan 采用单独的 hasActionableRalplanKeyword() 函数,而不是通用的 hasActionableKeyword()。
它不接受模糊的提及,只认可以下上下文:
- 出现在斜杠前缀命令后,例如
/ralplan; - 出现在
force:前缀后; - 出现在
oh-my-claudecode:前缀后; - 与激活动词(
use、run、start、enable、activate、invoke、trigger、launch等)距离在 28 个字符以内。
因此类似 "我在文档里看到 ralplan" 这样的句子不会触发规划模式。这是对「规划是一件重大操作」的风险控制。
8.2 ai-slop-cleaner:精准瞄准"AI 生成垃圾"的清理需求
ai-slop-cleaner 用了一个很有意思的复合检测策略 isAntiSlopCleanupRequest():
- 条件 1:出现明确反 slop 词,如
ai slop、anti slop、deslop、de-slop; - 条件 2:出现清理动词(
clean、cleanup、refactor、simplify、dedupe、prune)同时伴随代码坏味道词(slop、duplicate、dead code、over-abstracted、wrapper layers、tech debt、ai-generated)。
只要满足其中之一,就会触发清理技能。这使得系统能较好地区分:
- "顺手帮我重构一下这段逻辑"(普通重构)
- "把这堆 AI 生成的垃圾代码整理干净"(AI slop 清理)
避免普通的"重构一下"就被自动当成 AI slop 清理的误判。
九、两类输出:行内模式消息 vs 技能调用
检测器根据关键词性质生成两种不同的输出形式。
9.1 行内模式消息:注入 XML 指令,不调用技能文件
对于 ultrathink、deepsearch、analyze、tdd、code-review、security-review 等,系统不会真正去加载某个技能文件,而是直接在对话上下文中插入一个结构化的 XML 块,用来指导模型的行为。
举个例子(伪格式说明):
- ultrathink 会注入一个块,要求模型在后续回答中进行更深入、更系统的思考,而不是给出表层答案;
- deepsearch 会注入另一个块,指示使用基于 Agent 的并行搜索策略,系统性地在代码库中查找信息。
这种做法有点类似"轻量级模式开关":没有重量级技能加载和工具调用,但对模型行为施加强约束。
9.2 技能调用消息:加载 SKILL.md 或回退到工具指令
对应完整技能目录的关键词则走另一套路径:
- 使用
createSkillInvocation()尝试通过loadSkillContent()从{omcRoot}/skills/{skillName}/SKILL.md加载技能描述; - 如果能找到,就把整个 SKILL.md 内容包装进
[MAGIC KEYWORD: {NAME}]结构,直接内联到对话上下文; - 如果找不到,就回退成
Skill: oh-my-claudecode:{skillName}这样的工具调用指令。
在多关键词场景下,系统会发出一条合并消息,将多个技能以编号段落的形式拼在一起,并明确要求 Claude 按顺序执行全部技能,末尾还会强调"IMPORTANT"以防模型忽略某些步骤。
这一套机制让"组合技能"成为可能:只要一句话同时触发多个关键词,系统就能自动形成一个 mini pipeline。
十、安全与防线:如何防止"跑飞"和"注入风险"?
任何自动化系统做到"听懂一点就自己跑",都绕不开一个问题:怎么防止跑飞? 魔法关键词检测在工程上设计了多层安全防护。
10.1 Team worker 防护与 Hook 跳过
- 当环境变量中设置
OMC_TEAM_WORKER时,检测器直接以suppressOutput: true退出,避免团队 Worker 在接收到包含 "team" 等词的提示时递归触发团队技能,导致无限生成循环。 - 设置
OMC_SKIP_HOOKS或DISABLE_OMC=1可以全局跳过检测器,这是调试 Hook 问题时的重要"逃生舱"。
10.2 Review 模板抑制
不少团队会把完整的代码审查模板直接贴进对话。为了避免就地触发 code-review 或 security-review,检测器在提示的前 20 行内统计审查标签:
- 如果出现两个以上不同的状态标签(比如
approve、request-changes、merge-ready、blocked等),就禁用这两个关键词的检测。
这让系统更容易区分"模板内容"与"真实调用"。
10.3 Ralplan 快捷后续调用
当某个 ralplan 周期已经完成并产出了经过批准的规划结果之后,系统允许使用"后续快捷方式"直接跳过标准门控,转而调用 team 或 ralph 执行计划。
这保证了:
- 第一次规划仍然严格受控(需要显式调用);
- 后续从"计划"到"执行"的衔接则变得顺滑,而不必每次再重复调用 ralplan。
10.4 故障开放与权限控制
- 主函数的任何未处理异常都会被抓住,返回
{ continue: true, suppressOutput: true },避免因为检测器自己的 bug 阻塞对话进程。 - 所有状态文件都用
0o600权限创建,仅文件所有者可读写; - 在写入路径前,会对 sessionId 做严格校验,要求匹配
/^[a-zA-Z0-9][a-zA-Z0-9_-]{0,255}$/,防止通过 sessionId 注入路径进行目录遍历攻击。
从安全视角看,这个系统实际上已经把"Prompt → 状态文件 → 后续 Hook"这条链路当成潜在攻击面来处理了,而不是简单工具脚本。
十一、与整个 Hook 生态的协同:入口,而不是孤岛
魔法关键词检测只是整个 Hook 生态中的入口点,后面还有一系列脚本会依赖它写下的状态继续工作:
常见的 Hook 阶段与脚本职责大致如下表:
| 钩子阶段 | 脚本 | 超时时间 | 职责说明 |
|---|---|---|---|
| UserPromptSubmit | keyword-detector.mjs |
5s | 关键词检测、状态激活、技能上下文注入 |
| UserPromptSubmit | skill-injector.mjs |
3s | 根据触发器注入学习/自定义技能 |
| PreToolUse | pre-tool-enforcer.mjs |
3s | 依据模式强制工具使用约束 |
| PostToolUse | post-tool-verifier.mjs |
3s | 根据模式预期验证工具输出 |
| PostToolUse | project-memory-posttool.mjs |
3s | 记录工具使用用于项目记忆 |
| Stop | persistent-mode.mjs |
10s | 为 ralph/autopilot 循环重新调用 Claude |
| Stop | context-guard-stop.mjs |
5s | 自动继续前进行上下文大小控制 |
关键词检测器在这条链路里负责:
- 决定"这个会话接下来应该在哪些模式下运行";
- 把模式状态写成可被后续脚本读取的 JSON;
- 注入必要的上下文提示,让后续 Hook 知道应该怎样审查工具输出、怎样控制自动继续等。
十二、对开发者和集成者的启示
从工程实践角度看,这套魔法关键词检测机制有几个非常值得借鉴的点:
-
"自然语言即 API" 的设计思路
通过多层过滤与多语言匹配,把自然语言意图可靠地映射到系统模式,让用户可以不要命令行式心智,只管把需求说清楚。
-
防误报优先于"功能炫技"
整个流水线从输入提取、提示清理,到信息性意图过滤,都强调宁可不触发,也不能错触发。这种偏保守的策略对开发工具类产品尤为重要。
-
模式状态持久化与 Hook 协同
使用文件状态(会话级 + 全局回退)把模式语义长期挂在对话生命周期上,让后续 Hook 能够统一感知当前模式,而不是每个脚本自说自话。
-
"显式调用"与"自然触发"的混合设计
对于风险更大或复杂度更高的模式(如 ralplan 规划),要求显式调用;而对更轻量的模式和技能则允许自然语言触发。两种机制在同一系统内共存,并通过关键词目录明确界限。
-
把 AI 编排系统当成"安全敏感系统"来设计
会话 ID 校验、文件权限、故障开放、团队 worker 防护、Hook 跳过 escape hatch,这些措施都在把关键词检测纳入安全体系,而不仅仅是一个"好用的小功能"。
结语:从命令式交互到"语义即编排"
魔法关键词检测为 oh-my-claudecode 提供了一条非常清晰的路径:
- 开发者只用自然语言描述目标和偏好;
- 系统一层层分析,从清理噪音到理解意图,再到做模式选择和技能组合;
- 最终把这些决策转化为持久状态与 Hook 协同,而不是暴露一堆命令和配置项。
如果你在构建自己的 AI 开发工具、Agent 编排平台或者智能 IDE,不妨把这套思路看作一个"语义驱动编排"的典型范式:
- 前端交互完全自然语言化;
- 后端通过关键词检测、意图过滤和优先级调度,把模糊的语言还原成精确的系统行为。
在这样的架构下,"魔法"其实只是工程上的严谨与细致堆出来的结果。
