很多人第一次写 Skill,容易把它写成一份"给人看的说明文档":有背景介绍、有设计理念、有版本记录,甚至还有一大段"请保持专业、友好、严谨"的原则。
这些内容对人类读者也许有帮助,但对 AI 来说,往往不够有效。
Skill 的核心不是"解释一个能力是什么",而是用最少的上下文,告诉 AI 三件事:
- 什么时候该用它
- 该按什么步骤执行
- 出错时该怎么处理
换句话说,Skill 不是一段 Prompt,也不是一篇说明文,而是一份面向 AI Agent 的可执行操作手册。
系统讲清楚:什么是好的 Skill、为什么 Skill 容易写坏,以及如何用工程化方式设计、验证和迭代一个稳定的 Skill。
推荐的skills:(一个创建,一个评分进化)
skill-creator 使用: https://github.com/anthropics/skills/tree/main/skills/skill-creator
达尔文skills进化:https://github.com/alchaincyf/darwin-skill
一、Skill 到底是什么?
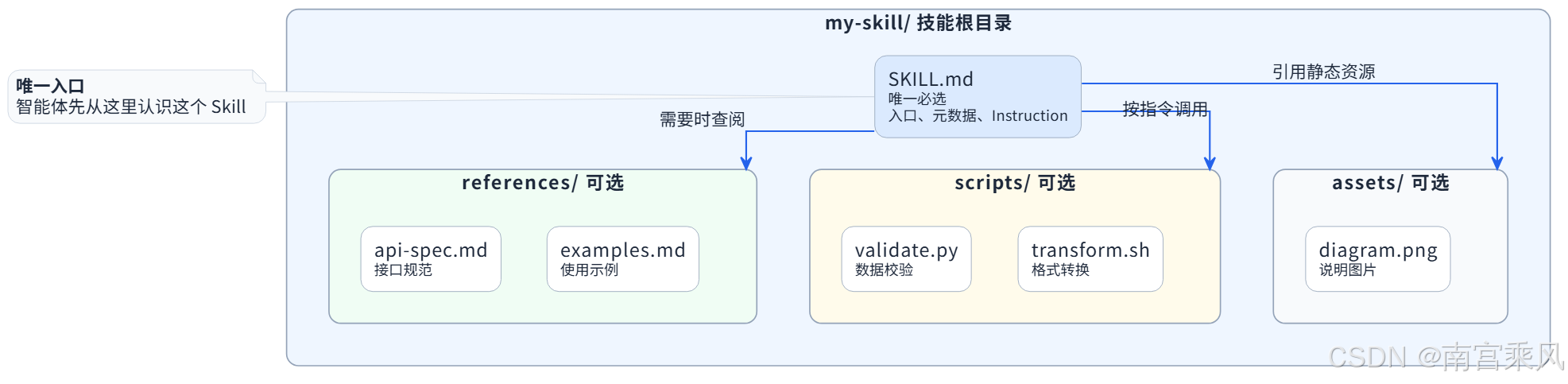
最小形态下,一个 Skill 可以只有一个文件:
text
my-skill/
└── SKILL.md但从能力模型上看,Skill 更像是一个"能力插件"。它可以包含:
text
skill-name/
├── SKILL.md
├── agents/
│ └── openai.yaml
├── scripts/
├── references/
└── assets/不同目录承担不同职责:
| 目录 | 作用 | 典型场景 |
|---|---|---|
SKILL.md |
Skill 入口,包含触发条件和执行步骤 | 告诉 AI 什么时候用、怎么做 |
scripts/ |
可执行脚本 | 处理格式校验、文件转换、确定性任务 |
references/ |
参考资料 | 放 API 文档、数据库 schema、领域知识 |
assets/ |
产出物资源 | 模板、图片、字体、样板代码 |
agents/openai.yaml |
面向 UI 的元信息 | 展示名称、简介、默认提示 |
这里最容易误解的一点是:Skill 不是把所有资料塞给 AI。
恰恰相反,好的 Skill 要控制信息进入上下文的时机。AI 的上下文窗口就像一张工作台,系统提示、对话历史、用户请求、其他 Skill 的元数据都已经占了空间。你的 Skill 越臃肿,AI 真正执行任务时可用的空间就越少。
所以 Skill 设计的第一原则不是"写全",而是"写准"。
二、Skill 不是 Prompt,也不是人类文档
我们先看一个坏例子:
markdown
---
name: code-review
description: 代码审查技能
---
# Code Review Skill
## 背景
本技能基于团队多年代码审查经验总结而成,旨在提升代码质量和团队协作效率。
## 审查原则
- 保持专业、建设性的语气
- 关注代码质量而非个人风格
- 平衡严格性和灵活性
## 使用方式
当用户提交代码时,对代码进行全面审查,给出改进建议。这份文档看起来很像一份合格的团队规范,但它不是一个好 Skill。
原因有几个:
description太模糊,AI 不知道"帮我看看这段代码"是否应该触发它。- "专业、建设性"是人类能理解的软约束,AI 执行时会有很大随机性。
- "全面审查"没有执行顺序,AI 不知道先看安全性、正确性还是可维护性。
- 背景和版本信息对 AI 当前执行任务没有帮助,只是在消耗 token。
Skill 的读者不是人,而是另一个 AI Agent。它需要的不是故事,而是边界、步骤、输入、输出和失败策略。
一个更好的写法应该类似这样:
markdown
---
name: code-review
description: >-
Review code for correctness, security, maintainability, and test coverage.
Use when the user asks to evaluate a code diff, pull request, implementation,
refactor, or potential bug.
---
## Review Workflow
1. Inspect correctness risks first, including edge cases and state handling.
2. Check security-sensitive logic, especially input validation and permissions.
3. Review maintainability issues that may cause future bugs.
4. Identify missing or weak tests only when they materially affect regression risk.
5. Report findings ordered by severity, with file and function references.
6. If no findings are found, state that explicitly and mention residual risks.这份 Skill 不解释"为什么代码审查重要",而是直接告诉 AI:
- 什么场景触发
- 审查顺序是什么
- 输出重点是什么
- 没发现问题时怎么说
这就是"写给 AI"的区别。
三、触发准确率取决于 frontmatter
SKILL.md 的 frontmatter 是 Skill 被发现和触发的入口:
yaml
---
name: my-skill
description: >-
Describe what this skill does and when to use it.
---其中最关键的是 description。
很多人会把"什么时候使用这个 Skill"写在正文里,例如:
markdown
## When to Use This Skill
当用户需要处理 PDF 文件时使用本技能。这其实已经晚了。
因为正文只有在 Skill 被触发后才会加载。AI 决定是否触发 Skill 时,只能看到 frontmatter。也就是说,触发条件必须写进 description,不能藏在 body 里。
好的 description 通常包含两类信息:
- 能力:这个 Skill 能做什么
- 触发:用户在什么场景下需要它
例如:
yaml
---
name: pdf-editor
description: >-
Edit, rotate, split, merge, and extract content from PDF files.
Use when the user needs to modify PDF documents, inspect PDF structure,
or automate PDF processing workflows.
---注意,这里没有写成:
yaml
description: PDF 处理技能因为"PDF 处理技能"太泛了。AI 不知道"提取 PDF 文本""合并两个 PDF""检查 PDF 页数"是否都应该触发它。
Skill 的命中率,很多时候不是取决于正文写得多好,而是取决于 description 是否足够具体。
四、信息要分层:别把所有东西都塞进 SKILL.md
好的 Skill 通常遵循三级加载模型:
是
需要参考
需要确定性操作
需要产出资源
L1: Frontmatter
是否触发 Skill
L2: SKILL.md Body
是否需要更多信息
L3: references
L3: scripts
L3: assets
这三个层级的职责不同:
| 层级 | 内容 | 加载时机 | 设计目标 |
|---|---|---|---|
| L1 | name + description |
始终在上下文中 | 帮 AI 判断是否触发 |
| L2 | SKILL.md 正文 |
触发后加载 | 提供核心工作流 |
| L3 | scripts/、references/、assets/ |
按需使用 | 承载复杂资料和确定性能力 |
SKILL.md 不应该变成一个巨大的知识库。它更适合作为"入口"和"导航"。
比如一个 BigQuery Skill,不应该把所有业务表结构都写进 SKILL.md。更好的方式是:
text
bigquery-skill/
├── SKILL.md
└── references/
├── finance.md
├── sales.md
├── product.md
└── marketing.md当用户问销售指标时,AI 只需要读取 sales.md;当用户问财务收入时,才读取 finance.md。
这样做有两个好处:
- 避免无关信息污染上下文
- 降低后续维护成本
一个简单判断标准是:如果某段信息不是每次执行都需要,就不要放进 SKILL.md 主体里。
五、给 AI 多大自由度,取决于任务有多"脆弱"
Skill 设计里有一个很实用的判断框架:自由度光谱。
text
任务越脆弱,越应该交给脚本
任务越开放,越适合交给 AI所谓"脆弱任务",不是指任务复杂,而是指它做对只有一种方式,做错却有很多种方式。
比如生成 openai.yaml:
yaml
display_name: Code Review
short_description: Review code quality and correctness如果字段长度有限制、大小写有要求、不能包含某些字符,那么让 AI 每次自由生成就很容易出错。这个任务就应该用脚本锁死格式。
相反,写一篇技术博客、做一次代码审查、分析一个架构方案,通常有很多合理结果。这类任务适合用文字原则引导,而不是用脚本限制每句话怎么写。
可以用两个问题判断:
| 问题 | 判断 |
|---|---|
| 做错后果严重吗? | 越严重,越需要低自由度 |
| 正确做法有多少种? | 越多,越适合高自由度 |
典型分配方式如下:
| 任务 | 自由度 | 推荐实现 |
|---|---|---|
| 理解用户需求 | 高 | 文字工作流 |
| 编写博客、方案、总结 | 高 | 原则 + 示例 |
| 生成配置模板 | 中 | 模板 + 参数 |
| 初始化目录结构 | 低 | 脚本 |
| 校验 frontmatter | 低 | 脚本 |
| 命名规范转换 | 低 | 脚本 |
一个成熟的 Skill,往往不是把 AI 限制死,而是把"容易错、必须准"的部分交给脚本,把"需要理解、判断和表达"的部分留给 AI。
六、失败策略必须写清楚
很多 Skill 不稳定,不是因为成功路径没写清楚,而是失败路径没有设计。
AI 在遇到失败时很容易自由发挥:猜测路径、跳过校验、编造结果、继续执行本该停止的流程。
所以 Skill 必须显式写出失败策略。
例如:
yaml
On Failure:
- Validation fails:
Return the validation error and ask the user for corrected input.
- Required file is missing:
Stop execution and report the missing file path.
- Script execution fails:
Capture stderr, summarize the failure, and do not retry more than once.
- External service is unavailable:
Report the service status and suggest retrying later.这里的关键不是"失败时要友好提示",而是要明确:
- 哪些失败必须停止
- 哪些失败可以重试
- 重试次数是多少
- 返回什么信息
- 不能做什么
对于依赖脚本的 Skill,脚本输出也要自解释:
text
CHECK FAILED: Node.js version mismatch
- Required: >= 18.0.0
- Detected: 16.14.0
VALID OPTIONS:
1. Upgrade Node.js to a supported version
2. Switch to a compatible build image这样的输出对 AI 很友好。它不需要猜发生了什么,也不需要从异常堆栈里推理下一步该怎么做。
七、用评测驱动 Skill,而不是凭感觉堆规则
写 Skill 最容易犯的错误,是一上来就想覆盖所有情况。
结果通常是:规则越来越多,正文越来越长,触发越来越混乱,AI 执行时反而更不稳定。
更好的方法是"评测驱动、失败优先"。
流程可以这样走:
通过
失败
无 Skill 基线测试
记录失败和不稳定行为
设计 3-5 个评测用例
编写最小 Skill
运行评测
补充边界条件
简化或修正 Skill
真实使用
收集新失败样本
第一步不是写 Skill,而是先观察没有 Skill 时 AI 会怎么失败。
例如:
- 会不会在不该触发时主动触发?
- 会不会遗漏关键文件?
- 会不会把参考资料读错?
- 会不会输出格式不稳定?
- 会不会在失败时继续编造结果?
这些失败点,就是评测用例的来源。
每个评测用例都应该有明确判定标准:
text
Case: 用户只想查看测试报告
Expected: 不触发 running-tests Skill
Pass: AI 只解释报告,不运行测试
Fail: AI 主动执行测试命令当评测存在后,再写最小 Skill。不要一开始追求完整,只写刚好能解决当前失败问题的规则。
新增规则也要有对应评测。没有评测支撑的规则,通常只是噪音。
八、一个好 Skill 的检查清单
写完一个 Skill 后,可以用下面这份清单做快速 Review。
| 检查项 | 判断标准 |
|---|---|
触发条件是否在 description 中 |
不依赖正文里的 "When to use" |
name 是否规范 |
小写、数字、连字符,语义明确 |
| 职责是否单一 | 一个 Skill 只解决一个核心任务 |
| 输入输出是否结构化 | 明确需要什么、返回什么 |
| 步骤是否可执行 | 使用指令式语言,而不是抽象原则 |
| 失败策略是否完整 | 明确停止、重试、报错、降级逻辑 |
| 资源是否分层 | 细节放 references,确定性逻辑放 scripts |
| 是否避免重复 | 同一信息不要同时出现在 SKILL.md 和 references |
| 是否有评测用例 | 至少覆盖黄金路径和误触发场景 |
| 是否去掉无关文档 | 不放 README、安装指南、更新日志等噪音 |
如果只能记住三条,我建议记这三条:
- 触发条件写进
description - 脆弱操作交给
scripts - 每条规则都要能对应一个失败场景
九、反模式:这些内容最好别写进 Skill
Skill 不是越详细越好。下面这些内容经常让 Skill 变差。
| 反模式 | 问题 | 更好的做法 |
|---|---|---|
| 写大量背景故事 | 消耗上下文,执行无帮助 | 只保留任务必要信息 |
| 使用模糊形容词 | AI 执行不稳定 | 改成可检查的行为约束 |
| 把触发条件放正文 | 触发前 AI 看不到 | 放进 frontmatter description |
| 把参考资料塞进正文 | SKILL.md 膨胀 |
拆到 references/ |
| 手写确定性格式 | 容易出错 | 用脚本生成和校验 |
| 混用术语 | 增加理解成本 | 统一命名 |
| 提供太多选项 | 增加决策成本 | 给默认路径和例外条件 |
| 包含时效性规则 | 容易过期 | 放 deprecated 或版本化参考文件 |
一个很有用的技巧是"反转测试"。
如果你写了一条正面原则:
text
保持专业、温暖、有洞察力。试着把它改成反模式:
text
不要使用空泛鼓励。
不要在没有具体证据时给结论。
不要连续使用多个抽象形容词。后者通常更适合 AI 执行,因为它更具体、更容易检查。
十、总结:Skill 是 AI Agent 的工程化接口
好的 Skill,是在 AI 的不确定性和工程系统的确定性之间搭桥。
它不是一段更长的 Prompt,也不是一份更详细的人类文档,而是一套面向 Agent 的工程化接口:
- 用
description控制触发 - 用
SKILL.md控制工作流 - 用
references/承载领域知识 - 用
scripts/锁死脆弱操作 - 用
assets/提供产出资源 - 用评测持续约束行为边界
最后回到一句话:
Skill 是给 AI 写的操作手册。用最少的 token,在正确的层级,给 AI 最精准的约束,让它在边界内自由发挥。