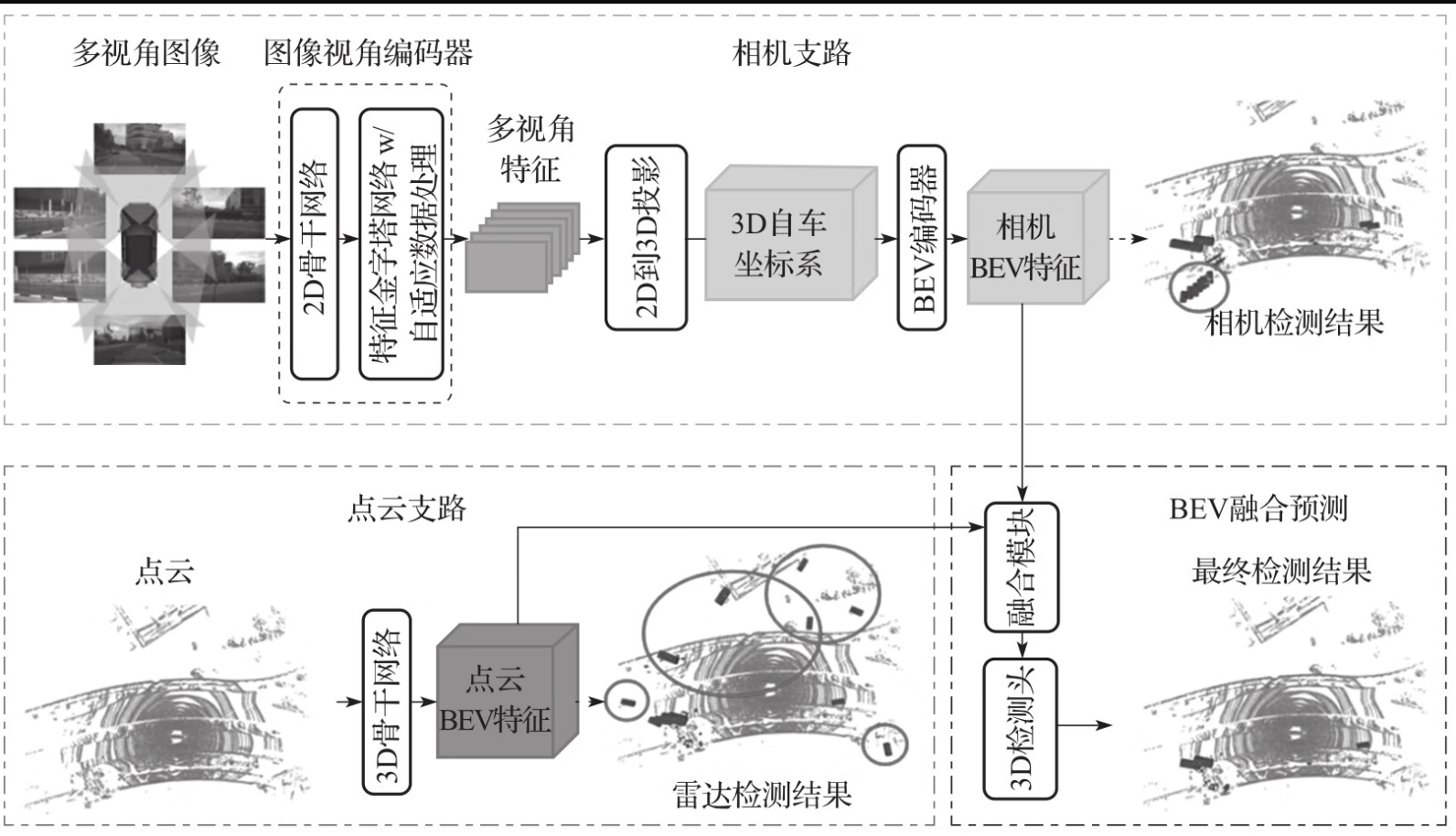
这是一个基于 BEV(鸟瞰图) 的多模态融合感知框架(类似于 BEVFusion 架构)的完整流程图。这个架构的核心思想是:将不同传感器的特征统一转换到同一个三维物理空间(BEV空间)下,再进行融合,从而解决了传统融合方法中特征对齐困难的问题。
下面我将按照数据流向,为您深入剖析这个流程的每一个细节:
第一阶段:相机支路------从"2D像素"到"3D物理空间"的跨越
这一路的核心难点在于如何从一张平面的照片中恢复出三维的空间信息。
1. 输入:多视角图像
- 细节:系统接收来自车身周围多个摄像头(通常是6个:前、后、左、右、前左、前右)的原始图像数据。
- 目的:获取环境的纹理、颜色、语义信息(如交通标志、车道线颜色)。
2. 图像视角编码器
这是特征提取的第一步,包含两个关键子模块:
- 2D骨干网络 :
- 作用:通常使用成熟的2D图像分类网络(如 ResNet, Swin Transformer)作为骨干。
- 细节 :它负责从每张 2D 图像中提取高维语义特征。此时,特征仍然是"图像视角"的,即具有 (H ,W ,C) 的维度,代表高度、宽度和通道数。
- 特征金字塔网络 + 自适应推理处理 :
- 作用:用于处理多尺度特征。
- 细节 :
- 特征金字塔网络:融合不同层级的特征图,既能看到大物体(如车),也能看到小物体(如锥桶)。
- 自适应推理处理:这通常指一种轻量级的注意力机制或卷积模块,用于增强特征的表达能力的同时,减少计算量,让网络更关注关键区域。
3. 多视角特征
- 状态:经过编码器后,我们得到了一组包含丰富语义信息的 2D 特征图,但它们仍然挂在各自的相机坐标系下,彼此是割裂的。
4. 2D到3D投影(核心黑科技)
这是整个流程中最具技术含量的一步,通常采用 Lift-Splat-Shoot 或类似的深度估计方法。
- Lift(提升):网络预测每个像素点的深度分布。它将 2D 图像特征"拉伸"到 3D 空间中,形成一系列沿着射线分布的"体素"或"点"。
- Splat(涂抹/投影):将这些 3D 点云特征"拍"到一个预定义的 3D 栅格(即 BEV 网格)中。
- 3D自车坐标系 :所有的图像特征现在都被统一到了以车辆为中心的 3D 坐标系 (X ,Y ,Z) 中。
5. BEV编码器
- 作用:将投影后稀疏且杂乱的 BEV 特征进行规整和进一步提取。
- 细节 :通常使用 2D 卷积(因为在 BEV 视角下,高度 Z 往往被压缩或池化,只剩下 X ,Y 平面)来融合空间上下文信息。
- 产出 :相机BEV特征 。这是一个在鸟瞰视角下的特征图,每一个像素点都对应地面上的一块区域(例如 0.5m ×0.5m ),且包含了图像的语义信息。
6. 相机检测结果(辅助任务)
- 细节:图中显示相机支路也可以独立输出检测结果。这通常作为一种辅助监督,帮助图像支路训练得更好,或者在雷达失效时作为降级方案。
第二阶段:点云支路------原生的3D感知
这一路处理的是激光雷达数据,它的优势在于天生具备精确的几何深度信息。
1. 输入:点云
- 细节 :激光雷达扫描得到的原始数据,是一组无序的 (reflectivity)(x ,y ,z,reflectivity) 坐标点。
2. 3D骨干网络
- 作用:处理稀疏的 3D 数据。
- 常用技术 :通常使用 VoxelNet (体素化)或 PointNet++ (点操作)或 Sparse Convolution(稀疏卷积)。
- 流程:
将点云体素化(划分成小方块)。
通过 3D 卷积提取特征。
将 3D 特征沿高度轴 Z 进行压缩(高度池化),生成 点云BEV特征。
3. 雷达检测结果(辅助任务)
- 细节:点云支路也可以独立输出检测结果。激光雷达对距离和形状的感知非常精准,但缺乏语义(不知道是红灯还是绿灯)。
第三阶段:融合与预测------"1+1 > 2"的质变
当相机和雷达的特征都变成了 BEV特征(即都是在同一个鸟瞰图网格下,且空间对齐)时,融合就变得非常简单且高效。
1. 融合模块
- 操作 :
- 输入:相机BEV特征 + 点云BEV特征。
- 融合方式:最常见的是 逐元素相加 或 逐元素拼接,后面接几个卷积层。
- 深入分析 :
- 为什么在BEV层融合好?因为此时两者处于完全相同的物理坐标系。图像特征提供了"这是什么"(语义),点云特征提供了"它在哪里"(精确几何)。
- 例如:图像看到了红色的色块,雷达看到了立体的形状。融合后,系统就知道"那里有一个红色的立体物体(可能是车或红绿灯)",且位置极其精确。
2. 3D检测头
- 作用:这是最终的决策网络。
- 输入:融合后的 BEV 特征。
- 输出 :最终检测结果。
- 细节 :检测头通常包含两个分支:
- 分类分支:预测每个网格内物体的类别(车、人、骑行者)。
- 回归分支:预测物体的 3D 边界框(长、宽、高、3D中心坐标、偏航角、速度)。
这张图展示了一个******"双流-统一空间-融合"******的先进感知架构:
相机支路:负责"看懂"世界,通过深度估计将2D语义提升到3D空间。
点云支路:负责"测量"世界,利用原生3D数据构建精确的几何底座。
融合:在BEV空间下,将语义与几何完美结合,输出鲁棒性极强的3D检测结果。
这种架构是目前自动驾驶量产(如华为、小鹏、理想等)和学术界(如BEVFusion论文)的主流方向,因为它既克服了纯视觉的深度不确定性,又弥补了纯雷达的语义缺失。
BEVFusion 融合模块流程详解
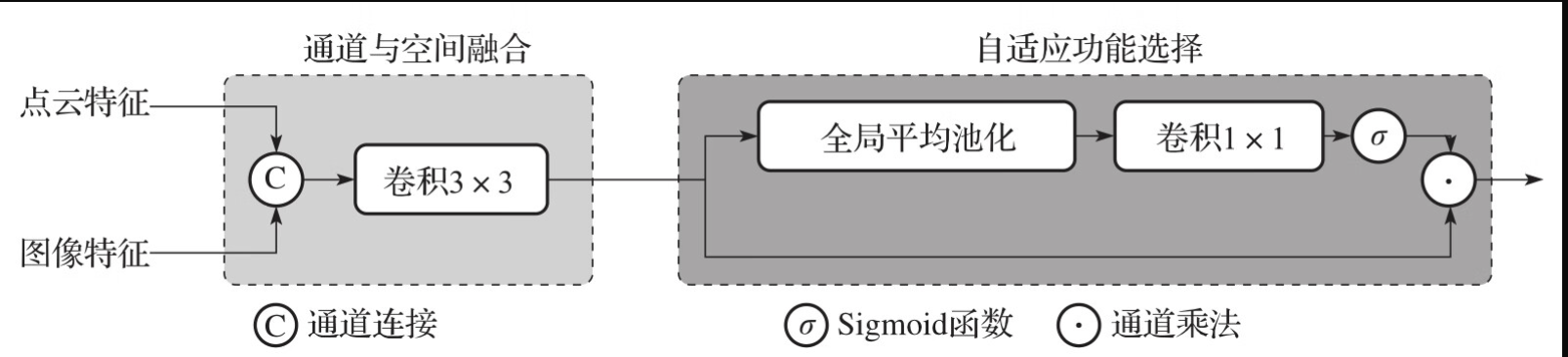
该模块的核心目标是将点云特征 与图像特征在 BEV(鸟瞰图)空间下进行高效融合。整个流程主要包含"通道与空间融合"和"自适应功能选择"两个阶段。
输入层
流程始于两个并行的输入分支:
- 点云特征:源自雷达支路,富含几何结构信息。
- 图像特征:源自相机支路,富含语义纹理信息。
阶段一:通道与空间融合
这一阶段旨在将两种不同模态的特征进行物理层面的结合与初步处理。
特征拼接
- 操作:将点云特征与图像特征在通道维度上进行直接拼接。
- 原理:假设点云特征维度为 Clidar ,图像特征维度为 Cimage ,拼接后的特征维度变为Clidar+Cimage 。这一步保留了所有原始信息,未做任何加权筛选。
卷积处理
- 操作:使用 3×3 卷积核对拼接后的特征进行处理。
- 作用 :
- 空间融合 :通过 3×3 的感受野,聚合周围邻域的信息,有助于平滑特征并减少噪声。
- 通道混合:将拼接后的高维通道映射到新的特征空间,实现图像与点云信息的初步交互。
阶段二:自适应功能选择
这一阶段位于右侧虚线框内,引入了注意力机制,旨在让网络自动判断"哪些特征更重要"。
全局平均池化
- 操作 :对卷积后的特征图进行全局平均池化。
- 作用 :将每个通道的空间信息( H ×W )压缩为一个标量,从而获得全局的统计信息。
权重生成
- 操作 :通过 1×1 卷积层进一步处理池化后的特征。
- 作用 :学习每个通道的重要性权重,生成初步的注意力图。
Sigmoid 激活
- 操作 :使用 Sigmoid 函数将数值归一化到 0 到 1 之间。
- 作用 :生成最终的通道注意力权重。接近 1 的权重表示该通道特征重要,接近 0 则表示不重要。
通道乘法
- 操作 :将生成的注意力权重与"阶段一"中卷积处理后的特征图进行逐通道相乘。
- 结果 :实现特征的自适应重标定,增强关键特征,抑制无效或噪声特征。
输出层
经过上述所有步骤处理后,模块最终输出融合后的特征。这些特征既包含图像的语义信息,又保留了点云的几何精度,且经过了注意力机制的优化,可直接用于后续的 3D 检测头进行物体检测。