特斯拉(Tesla)作为纯视觉方案(Vision-only)的代表,其自动驾驶(FSD/Autopilot)的数据采集并不是像传统图商或自动驾驶公司那样,派出专门的测绘车满大街跑,而是依赖其全球数百万辆量产车组成的庞大车队来进行分布式、常态化的数据采集。
特斯拉实现高效、低成本且极具针对性的数据采集,核心依赖于其著名的"影子模式"(Shadow Mode)和数据闭环(Data Loop)体系。以下是具体的采集和筛选机制:
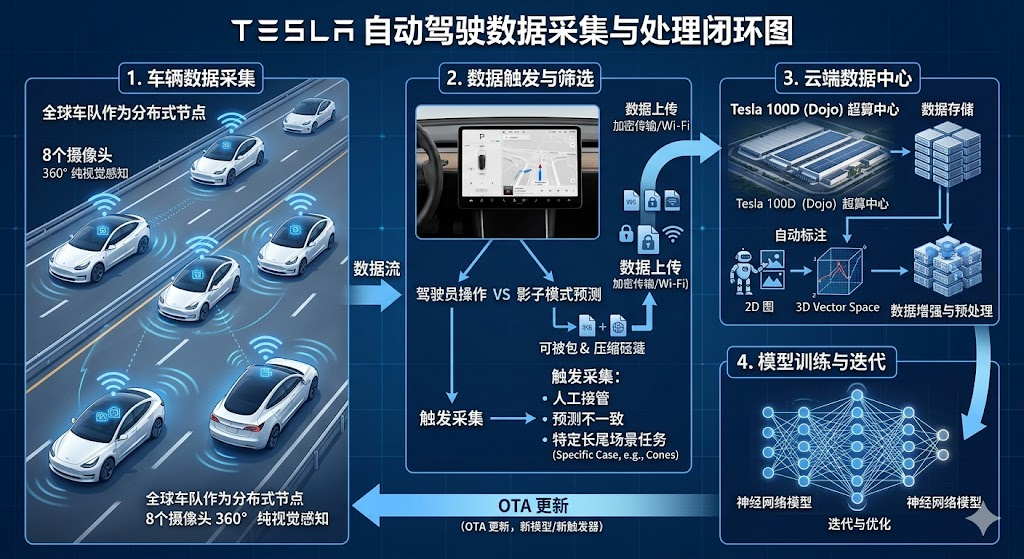
1. 触发机制:影子模式(Shadow Mode)
这是特斯拉数据采集的杀手锏。当车主在驾驶特斯拉时,即使没有开启自动驾驶辅助,车辆内置的 FSD 电脑依然在后台默默运行算法,并进行"模拟驾驶"。
系统会对比人类驾驶员的实际操作 与算法的预测操作,一旦两者出现不一致,就会触发数据采集。
- 人工接管(Disengagement): 比如自动驾驶开启时,人类突然踩了刹车或猛打方向盘接管了车辆。系统会立刻将接管前后的传感器数据(如视频、速度、转向角)打包。
- 预测不一致(Trigger): 影子模式预测这里应该减速,但人类却加速通过了;或者人类踩了急刹车(AEB触发触发)。这类"人类打脸算法"的数据对模型优化极具价值。
2. 定向采集:数据主动请求(Active Query / Fleet Learning)
特斯拉的云端(包含 Dojo 超算中心)不会盲目接收所有车辆的所有视频(那意味着无法承受的带宽和存储成本)。它采用"缺什么,向车队要什么"的定向采集模式:
- 长尾场景(Corner Cases)定向搜寻: 比如算法团队最近在训练"车辆如何识别路上的异物(如掉落的纸箱、倒下的交通锥)"或"复杂的施工区域"。
- 下发"通缉令": 云端会向全球车队下发一个轻量级的触发器(Trigger Vector)。
- 本地匹配与上传: 当全球任意一辆特斯拉在行驶中,摄像头捕捉到的画面符合这个"通缉令"的特征(例如检测到路边有奇怪造型的雕塑或罕见的极端天气),车辆就会在连接 Wi-Fi 或停放时,将这一小段(通常是十几秒)的匿名数据包上传到云端。
3. 硬件基础:无感知的分布式采集
每辆特斯拉量产车都是一个移动的"数据采集站",其硬件配置保证了数据的原生性:
- 传感器: 全车周身的 8 个摄像头提供 360 度的全景视野(处理速率极高),捕捉图像的语义信息。
- 全真数据: 由于特斯拉摒弃了激光雷达和高精地图,它采集的就是纯粹的视觉数据和车辆惯导数据(IMU、车速、轮速等)。这确保了训练集的数据源与实际车辆部署时的感知边界完全一致。
4. 负样本精细化采集(以最新版本为例)
随着端到端(End-to-End)大模型(如 FSD V12+)的落地,特斯拉对高质量"负样本"的需求更加迫切。在最新的策略中:
- 当用户发生强制接管(Forced Takeover)后,系统甚至会引入更细致的反馈机制(如提示车主选择接管原因:是因为路线选错、突然加塞还是舒适度不佳)。
- 这些被精确标记的接管数据,会直接作为"负样本"送进神经网络,告诉模型"这种操作在人类看来是错误的"。
5. 云端自动标注(Auto-Labeling)
采集上来的海量 2D 视频数据,会进入特斯拉的自动标注系统。
- 系统利用强大的云端算力,将不同车辆、不同时间经过同一路口的数据进行空间和时间上的对齐。
- 利用大模型和三维重建技术,将 2D 图像自动还原并标注为 3D 向量空间(Vector Space)下的真值(Ground Truth),直接喂给感知与规划网络进行迭代。
总结来说: 特斯拉的数据采集不是全量、盲目的上传,而是利用全球车队作为分布式算力节点 ,通过影子模式和特定触发器 进行"去粗取精"的定向采集。这种"车端发现异常 →\rightarrow→ 过滤打包 →\rightarrow→ 云端自动标注 →\rightarrow→ 模型训练 →\rightarrow→ OTA重回车端"的闭环,是其数据规模能够超越竞争对手的核心原因。