
【作者主页】Francek Chen
【专栏介绍】⌈ ⌈ ⌈大数据技术原理与应用 ⌋ ⌋ ⌋专栏系统介绍大数据的相关知识,分为大数据基础篇、大数据存储与管理篇、大数据处理与分析篇、大数据应用篇。内容包含大数据概述、大数据处理架构Hadoop、分布式文件系统HDFS、分布式数据库HBase、NoSQL数据库、云数据库、MapReduce、Hadoop再探讨、数据仓库Hive、Spark、流计算、Flink、图计算、数据可视化,以及大数据在互联网领域、生物医学领域的应用和大数据的其他应用。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/BigData_principle_application。
文章目录
NoSQL 的三大基石包括 CAP、BASE 和最终一致性。
一、CAP
2000 年,美国著名科学家 Eric Brewer 教授指出了著名的 CAP 理论,后来美国麻省理工学院(Massachusetts Institute of Techonlogy,MIT)的两位科学家 Seth Gilbert 和 Nancy lynch 证明了 CAP理论的正确性。CAP 含义如下。
- C(Consistency):一致性。它是指任何一个读操作总是能够读到之前完成的写操作的结果,也就是在分布式环境中,多点的数据是一致的。
- A(Availability):可用性。它是指快速获取数据,且在确定的时间内返回操作结果。
- P(Tolerance of Network Partition):分区容忍性。它是指当出现网络分区的情况时(即系统中的一部分节点无法和其他节点进行通信),分离的系统也能够正常运行。
CAP 理论(见图1)告诉我们,一个分布式系统不可能同时满足一致性、可用性和分区容忍性这 3 个特性,最多只能同时满足其中 2 个,正所谓"鱼和熊掌不可兼得"。如果追求一致性,就要牺牲可用性,需要处理因为系统不可用而导致的写操作失败的情况;如果要追求可用性,就要预估到可能发生数据不一致的情况,比如系统的读操作可能不能精确地读取写操作写入的最新值。
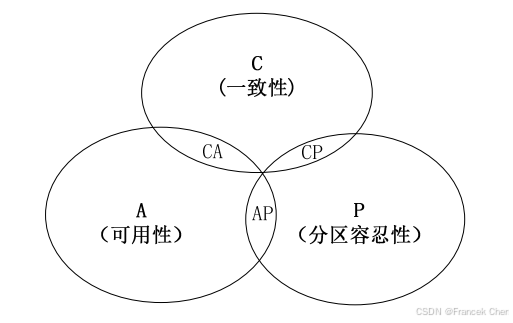
图1 CAP理论
下面给出一个牺牲一致性来换取可用性的实例。假设分布式环境下存在两个节点 M 1 M_1 M1 和 M 2 M_2 M2,一个数据 V V V 的两个副本 V 1 V_1 V1 和 V 2 V_2 V2 分别保存在 M 1 M_1 M1 和 M 2 M_2 M2 上,两个副本的值都是 v a l 0 val_0 val0。现在假设有两个进程 P 1 P_1 P1 和 P 2 P_2 P2 分别对两个副本进行操作,进程 P 1 P_1 P1 向节点 M 1 M_1 M1 中的副本 V 1 V_1 V1 写入新值 v a l 1 val_1 val1,进程 P 2 P_2 P2 从节点 M 2 M_2 M2 中读取 V V V 的副本 V 2 V_2 V2 的值。
当整个过程完全正常执行时,会按照以下过程进行(见图2)。
(1)进程 P 1 P_1 P1 向节点 M 1 M_1 M1 的副本 V 1 V_1 V1 写入新值 v a l 1 val_1 val1。
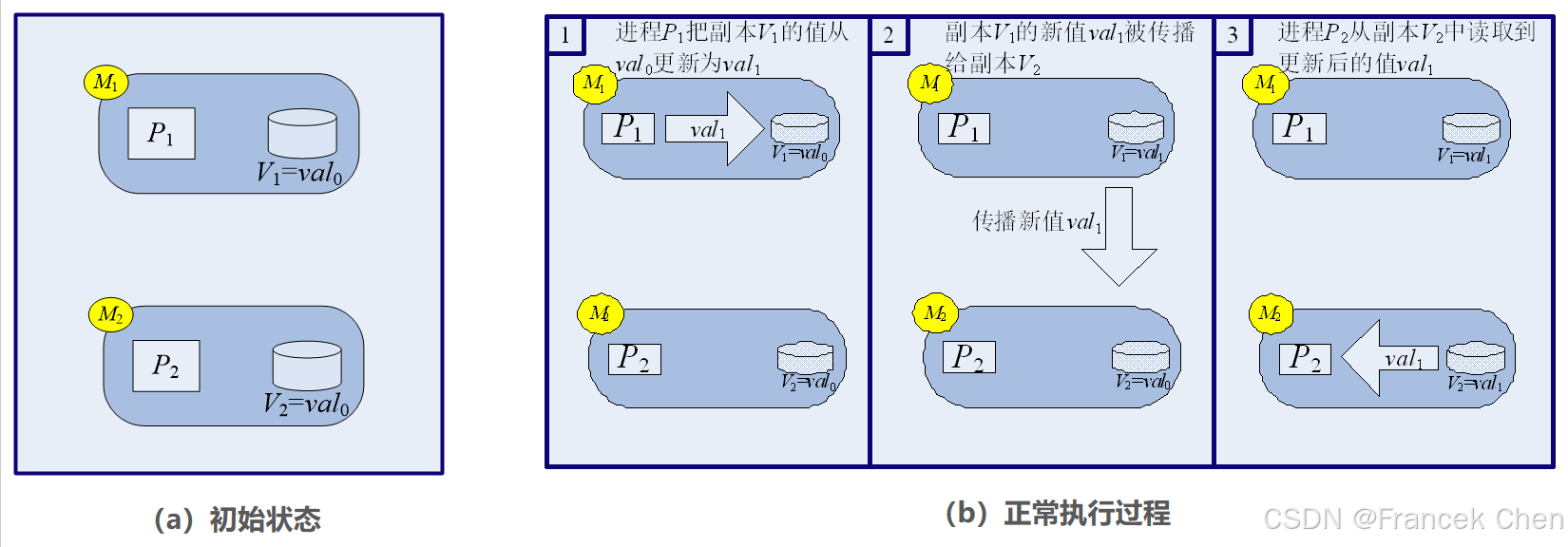
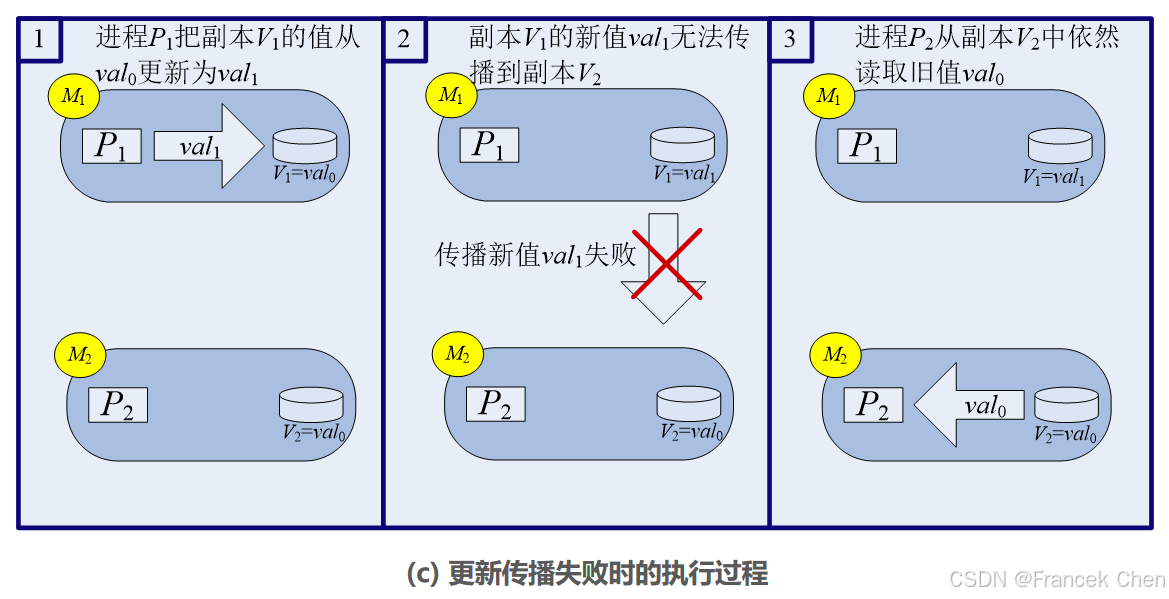
图2 一个牺牲一致性来换取可用性的实例
(2)节点 M 1 M_1 M1 向节点 M 2 M_2 M2 发送消息 MSG 以更新副本 V 2 V_2 V2 值,把副本 V 2 V_2 V2 值更新为 v a l 1 val_1 val1。
(3)进程 P 2 P_2 P2 在节点 M 2 M_2 M2 中读取副本 V 2 V_2 V2 的新值 v a l 1 val_1 val1。
但是当网络发生故障时,可能导致节点 M 1 M_1 M1 中的消息 MSG 无法发送到节点 M 2 M_2 M2,这时,进程 P 2 P_2 P2 在节点 M 2 M_2 M2 中读取的副本 V 2 V_2 V2 的值仍然是旧值 v a l 0 val_0 val0。由此产生了不一致性问题。
从这个实例可以看出,当我们希望两个进程 P 1 P_1 P1 和 P 2 P_2 P2 都实现高可用性,也就是能够快速访问到需要的数据时,就会牺牲数据一致性。
当处理 CAP 的问题时,可以有以下几个明显的选择,即不同产品在 CAP 理论下有不同的设计原则(见图3)。
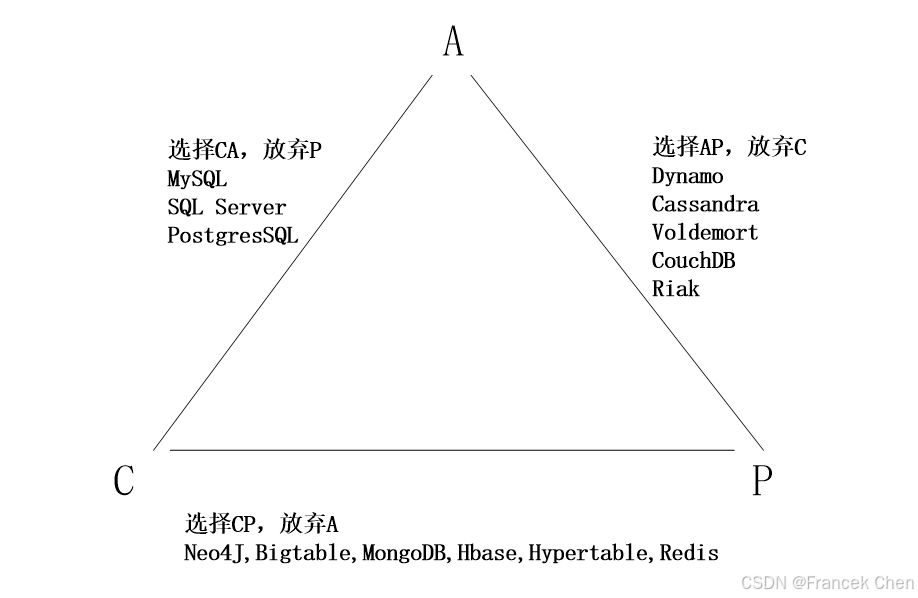
图3 不同产品在CAP理论下的不同设计原则
(1)CA。也就是强调一致性(C)和可用性(A),放弃分区容忍性(P)。最简单的做法是把所有与事务相关的内容都放到同一台机器上。很显然,这种做法会严重影响系统的可扩展性。传统的关系数据库(MySQL、SQL Server 和 PostgreSQL)都采用了这种设计原则,因此扩展性都比较差。
(2)CP。也就是强调一致性(C)和分区容忍性(P),放弃可用性(A)。当出现网络分区的情况时,受影响的服务需要等待数据一致,因此在等待期间就无法对外提供服务。Neo4J、BigTable 和 HBase 等 NoSQL 数据库都采用了 CP 设计原则。
(3)AP。也就是强调可用性(A)和分区容忍性(P),放弃一致性(C)。允许系统返回不一致的数据。这对于许多 Web 2.0 网站而言是可行的,这些网站的用户首先关注的是网站服务是否可用。当用户需要发布一条微博时,必须能够立即发布,否则,用户就会放弃使用,但是这条微博发布后什么时候能够被其他用户读到,则不是非常重要的问题,不会影响到用户体验。因此,对于 Web 2.0 网站而言,可用性与分区容忍性优先级要高于数据一致性,网站一般会尽量朝着 AP 的方向设计。当然,在采用 AP 设计时,也可以不完全放弃一致性,转而采用最终一致性。DynamoDB、Riak、CouchDB、Cassandra 等 NoSQL 数据库就采用了 AP 设计原则。
二、BASE
说起 BASE(Basically availble、Soft-state、Eventual consistency),不得不谈到 ACID。一个数据库事务具有 ACID 四性。
- A(Atomicity):原子性。它是指事务必须是原子工作单元,对于其数据修改,要么全都执行,要么全都不执行。
- C(Consistency):一致性。它是指事务在完成时,必须使所有的数据都保持一致状态。
- I(Isolation):隔离性。它是指由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。
- D(Durability):持久性。它是指事务完成之后,它对于系统的影响是永久性的,该修改即使出现致命的系统故障也将一直保持。
关系数据库系统中设计了复杂的事务管理机制来保证事务在执行过程中严格满足 ACID 四性要求。关系数据库的事务管理机制较好地满足了银行等领域对数据一致性的要求,因此得到了广泛的商业应用。但是,NoSQL 数据库通常应用于 Web 2.0 网站等场景中,对数据一致性的要求并不是很高,而是强调系统的高可用性,因此为了获得系统的高可用性,可以考虑适当牺牲一致性或分区容忍性。BASE 的基本思想就是在这个基础上发展起来的,它完全不同于 ACID 模型,BASE 牺牲了高一致性,从而获得可用性或可靠性,Cassandra 系统就是一个很好的实例。有意思的是,单从名字上就可以看出二者有点"水火不容",BASE 的英文意义是碱,而 ACID 的英文含义是酸。BASE 的基本含义是基本可用(Basically Available)、软状态(Soft-state)和最终一致性(Eventual consistency)。
(一)基本可用
基本可用是指一个分布式系统的一部分发生问题变得不可用时,其他部分仍然可以正常使用,也就是允许分区失败的情形出现。比如一个分布式数据存储系统由 10 个节点组成,当其中 1 个节点损坏不可用时,其他 9 个节点仍然可以正常提供数据访问,那么,就只有 10%的数据是不可用的,其余 90%的数据都是可用的,这时就可以认为这个分布式数据存储系统"基本可用"。
(二)软状态
"软状态"(Soft-state)是与"硬状态(Hard-state)"相对应的一种提法。数据库保存的数据是"硬状态"时,可以保证数据一致性,即保证数据一直是正确的。"软状态"是指状态可以有一段时间不同步,具有一定的滞后性。假设某个银行中的一个用户 A 转移资金给另外一个用户 B,这个操作通过消息队列来实现解耦,即用户 A 向发送队列中放入资金,资金到达接收队列后通知用户 B 取走资金。由于消息传输的延迟,这个过程可能会存在一个短时的不一致性,即用户 A 已经在队列中放入资金,但是资金还没有到达接收队列,用户 B 还没拿到资金,导致出现数据不一致状态,即用户 A 的钱已经减少了,但是用户 B 的钱并没有相应增加。也就是说,在转账的开始和结束状态之间存在一个滞后时间,在这个滞后时间内,两个用户的资金似乎都消失了,出现了短时的不一致状态。虽然这对用户来说有一个滞后,但是这种滞后是用户可以容忍的,甚至用户根本感知不到,因为两边用户实际上都不知道资金何时到达。当经过短暂延迟后,资金到达接收队列时,就可以通知用户 B 取走资金,状态最终一致。
(三)最终一致性
一致性的类型包括强一致性和弱一致性,二者的主要区别在于在高并发的数据访问操作下,后续操作是否能够获取最新的数据。对于强一致性而言,当执行完一次更新操作后,后续的其他读操作就可以保证读到更新后的最新数据;反之,如果不能保证后续访问读到的都是更新后的最新数据,那么就是弱一致性。而最终一致性只不过是弱一致性的一种特例,允许后续的访问操作可以暂时读不到更新后的数据,但是经过一段时间之后,用户必须读到更新后的数据。最终一致性也是 ACID 的最终目的,只要最终数据是一致的就可以了,而不是每时每刻都保持实时一致。
三、最终一致性
讨论一致性的时候,需要从客户端和服务端两个角度来考虑。从服务端来看,一致性是指更新如何复制分布到整个系统,以保证数据最终一致。从客户端来看,一致性主要指的是在高并发的数据访问操作下,后续操作是否能够获取最新的数据。关系数据库通常实现强一致性,也就是一旦一个更新完成,后续的访问操作都可以立即读取更新过的数据。弱一致性则无法保证后续访问都能够读到更新后的数据。
最终一致性的要求更低,只要经过一段时间后能够访问到更新后的数据即可。也就是说,如果一个操作 OP 往分布式存储系统中写入了一个值,遵循最终一致性的系统可以保证,如果后续访问发生之前没有其他写操作去更新这个值,那么,最终所有后续的访问都可以读取操作 OP 写入的最新值。从 OP 操作完成到后续访问可以最终读取 OP 写入的最新值,这之间的时间间隔称为"不一致性窗口",如果没有发生系统失败,这个窗口的大小依赖于交互延迟、系统负载和副本个数等因素。
最终一致性根据更新数据后各进程访问到数据的时间和方式的不同,又可以进行如下区分。
- 因果一致性。如果进程 A 通知进程 B 它已更新了一个数据项,那么进程 B 的后续访问将获得进程 A 写入的最新值。而与进程 A 无因果关系的进程 C 的访问,仍然遵守一般的最终一致性规则。
- "读己之所写"一致性。这可以视为因果一致性的一个特例。当进程 A 自己执行一个更新操作之后,它自己总是可以访问到更新过的值,绝不会看到旧值。
- 会话一致性。它把访问存储系统的进程放到会话(Session)的上下文中,只要会话还存在,系统就保证"读己之所写"一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统保证不会延续到新的会话。
- 单调读一致性。如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值。
- 单调写一致性。系统保证来自同一个进程的写操作顺序执行。系统必须保证这种程度的一致性,否则编程难以进行。
总结
NoSQL 三大基石为 CAP、BASE 和最终一致性。CAP 指出分布式系统无法同时满足一致性、可用性和分区容忍性,只能取其二。BASE 包括基本可用、软状态和最终一致性,牺牲高一致性获可用性或可靠性。最终一致性要求一段时间后能访问更新数据,有多种细分类型。
欢迎 点赞👍 | 收藏⭐ | 评论✍ | 关注🤗
