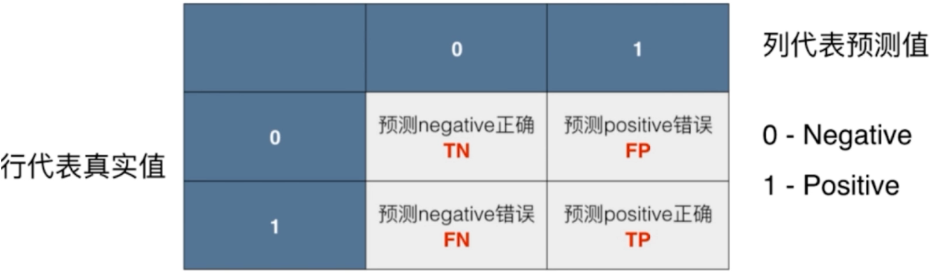
分类算法的评价指标

分类算法评价指标的意义
分类准确度存在的问题:对于极度偏斜(Skewed Data)的数据,只使用分类准确度远远
不够 例如:一个癌症预测系统,根据输入的体检信息,可以判断是否有癌症,预测准确度
可达到99.99%,但如果癌症发生的概率有0.01%,这意味着如果预测所有人都是健康,则准
确率都可达到99.99%
所以,针对极度偏斜(Skewed Data)的数据,分类算法就出现了更好的评价指标
精准率与召回率
- 精准率(precision)
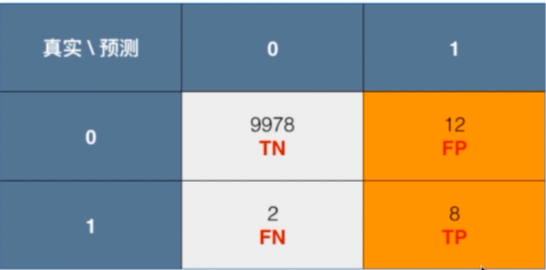
precision=TPTP+FP
精准率=真阳性 / (真阳性+假阳性)
对于股票预测更注重精准率(我只希望我买的股票大部分是涨的就行了,precision高,猜的越准越好)
- 召回率(recall)
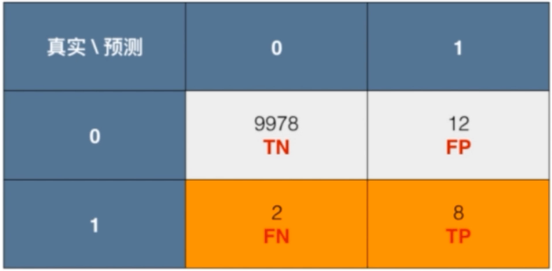
recall=TPTP+FN
召回率=真阳性 / (真阳性+假阴性)
对于新冠病毒的诊断更注重召回率(我们希望尽可能少漏报患病病例)
F1 Score
F1 Score是为了兼顾精准率与召回率,它描述的是精准率和召回率的调和平均值;
如果精准率与召回率二者极度不平衡,则F1 Score很低,只有两者都很高,则F1 Score的分
数才会很高
F1=2∗precision∗recallprecision+recall
注意:
F1 Score的取值范围是0到1,最好的F1 Score是1,最差的F1 Score是0
实战------sklearn计算精准率、召回率、F1 Score

在sklearn中计算精准率、召回率、F1 Score可以使用
from sklearn.metrics import precision_score,recall_score,f1_score
本节课的实战以sklearn中的手写数字识别数据集为例,将所有样本的标签变成0、1两种类型
python
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
# 将digits.target的拷贝传递给y变量,则修改y不会影响digits.target
y = digits.target.copy()
y[digits.target==9] = 1 # 原样本标签为9的变为1
y[digits.target!=9] = 0 # 原样本标签不为9的变为0KMeans聚类算法
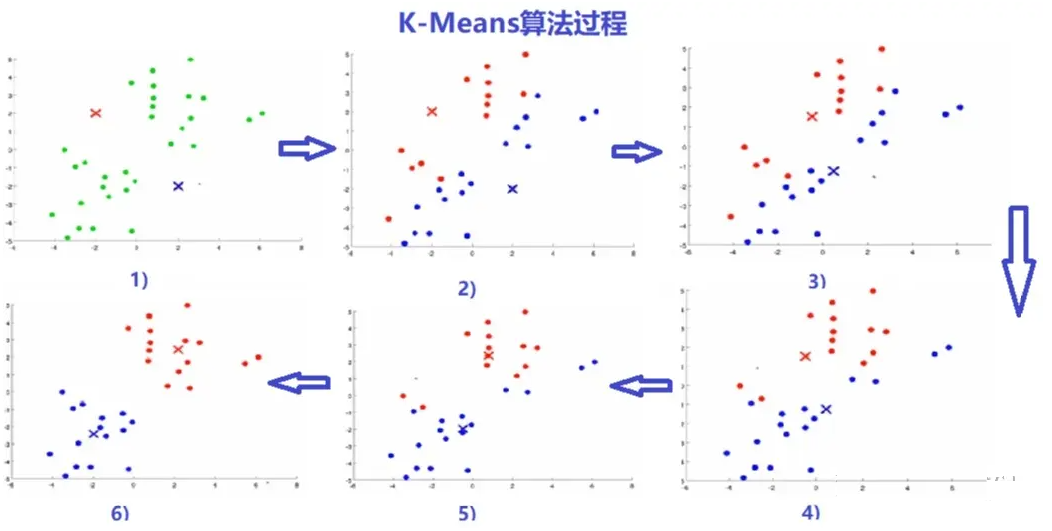
KMeans算法介绍
K-Means是聚类算法中最常用的一种,是一种迭代求解的聚类分析算法;聚类是一种
无监督学习,事先并不知道分类标签是什么,它能够将具有相似特征的对象划分到同一个集
合(簇)中。簇内的对象越相似,聚类算法的效果越好。
KMeans算法原理
-
从样本中随机选择K个点------聚类中心(也可以随机生成K个并不存在于原始数据中的样
本点作为初始聚类中心)
-
簇分配:遍历每个样本,然后根据每一个点是与红色聚类中心更近,还是与蓝色聚类中心更近,来将每个数据点分配给K个聚类中心之一
-
根据聚类结果,重新计算k个簇各自的平均值(Means)位置,将该平均值位置作为该簇新的聚类中心
-
不断重复迭代上述的(2)与(3)两个步骤,直到聚类中心点的变化很小,或者达到指定的迭代次数
KMeans损失函数
J(c(1),...,c(m),μ1,...,μK)=1m∑i=1m||x(i)−μc(i)||2
- KMeans损失函数是每个数据点与其所关联的聚类中心点之间的平均距离
- 最小化损失函数可以帮助k-means找到更好的簇
注意:
对于聚类数量的选择(参数K的选择),没有一个统一的选择方法,可以根据业务需要选择
KMeans的衡量指标
CH指标:同时考虑了各个簇之间的分离程度与簇内部的分离程度,来衡量聚类效果。CH分数越高,说明聚类效果越好
python
from sklearn.metrics import calinski_harabasz_score
# 分数越高,聚类效果越好
calinski_harabasz_score(X,y_pred)实战------KMeans聚类分析

- sklearn中使用sklearn.cluster.KMeans实现KMeans算法
- KMeans聚类效果衡量指标使用sklearn.metrics.calinski_harabasz_score
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# 生成数据样本
X,y = make_blobs(n_samples=1000,n_features=2,
centers=[[-1,-1],[0,0],[1,1],[2,2]],
cluster_std=[0.4,0.2,0.2,0.2],random_state=666)
plt.scatter(X[:,0],X[:,1])
plt.show()
# KMeans聚成2类观察
from sklearn.cluster import KMeans
km = KMeans(n_clusters=2,random_state=666) # 聚成两类
km.fit(X)
y_predict = km.predict(X) # 预测
plt.scatter(X[:,0],X[:,1],c=y_predict)
plt.show()
# 使用CH指标评价聚类效果(本题是在训练样本集上评价)
from sklearn.metrics import calinski_harabasz_score
calinski_harabasz_score(X,y_predict)
# 聚成4类观察
km2 = KMeans(n_clusters=4,random_state=666) # 聚成四类
km2.fit(X)
y_predict2 = km2.predict(X) # 预测
plt.scatter(X[:,0],X[:,1],c=y_predict2)
plt.show()
# 使用CH指标评价聚类效果
calinski_harabasz_score(X,y_predict2)银行客户分群模型

背景介绍
银行通常拥有海量的客户,对于不同的客户,银行需要进行不同的营销与工作开展策略,例如:
-
对于高收入且年龄大的客户,可以进行重点挖掘业务机会,例如可以给他推销一些收益
率高但周期相对较长的理财产品
-
对于低收入且年龄小的客户,则当前阶段可以较少投入营销
-
也可以根据其他特征进行客户分群,使用针对性的营销策略
因此对于银行来说,通常需要将客户进行分群处理,对于不同分群的客户进行不同的处
理。
分析步骤
- 读取数据
- 可视化展示
- 模型训练
- 建模效果可视化展示
代码实现
python
import pandas as pd
# 读取数据
data = pd.read_excel('客户信息.xlsx')
data.head()
# 可视化展示
import matplotlib.pyplot as plt
# 为防止绘图时中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
# 绘制散点图
plt.scatter(data['年龄(岁)'], data['收入(万元)'], c="green", marker='*')
plt.xlabel('年龄(岁)') # 添加x轴名称
plt.ylabel('收入(万元)') # 添加y轴名称
plt.show()
# 模型训练
from sklearn.cluster import KMeans
kms = KMeans(n_clusters=3, random_state=123)
kms.fit(data)
label = kms.labels_
print(label)
# 建模效果可视化展示
# 以红色圆圈样式绘制散点图并加上标签
plt.scatter(data[label == 0].iloc[:, 0], data[label == 0].iloc[:, 1], c="red", marker='o', label='class0')
# 以绿色星星样式绘制散点图并加上标签
plt.scatter(data[label == 1].iloc[:, 0], data[label == 1].iloc[:, 1], c="green", marker='*', label='class1')
# 以蓝色加号样式绘制散点图并加上标签
plt.scatter(data[label == 2].iloc[:, 0], data[label == 2].iloc[:, 1], c="blue", marker='+', label='class2')
plt.xlabel('年龄(岁)') # 添加x轴名称
plt.ylabel('收入(万元)') # 添加y轴名称
plt.legend() # 设置图例
plt.show()新闻聚类分群模型

背景介绍
新闻种类繁复多样,可以分为军事,政治,娱乐,财经,体育,科技,历史等等题材。
我们需要将每条新闻划分成合适的类别,匹配到正确的版面以便读者阅读,因此新闻的聚类
分群显得十分重要。
分析步骤
- 读取数据
- jieba分词
- 新闻标题文本向量化
- 将新闻标题向量化的结果组装成DataFrame
- 模型搭建与使用
注意:
- jieba是优秀的中文分词第三方库,本案例会使用jieba进行中文文本分词
- jieba安装方式:pip install jieba==0.42.1
代码实现
python
# 读取数据
import pandas as pd
df = pd.read_excel('新闻.xlsx')
df.head()
df.shape # 查看形状
# jieba分词
import jieba
words = [] # 创建一个空列表,用来存储每一行的标题分词结果
for i, row in df.iterrows():
word_list = jieba.lcut(row['标题']) # 分词
# 将分词结果变成一个字符串(空格分隔)
result = ' '.join(word_list)
words.append(result) # 存储每一行的分词结果
# 根据词频将所有的新闻标题进行文本向量化
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
X = vect.fit_transform(words)
X = X.toarray()
print(X)
# 将新闻标题向量化的结果组装成DataFrame
all_words_bag = vect.get_feature_names() # 查看所有新闻标题的词袋
df = pd.DataFrame(X, columns=all_words_bag)
df.head()
# 模型搭建与使用
from sklearn.cluster import KMeans
kms = KMeans(n_clusters=10, random_state=123)
k_data = kms.fit_predict(df)
print(k_data) # 查看预测的分类标签
import numpy as np
words_array = np.array(words)
print(words_array[k_data == 1]) # 查看分类1标签的新闻实战_PCA对红酒数据降维并可视化
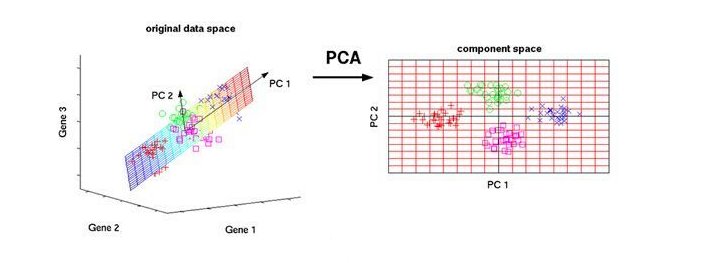
PCA降维原理
PCA(Principal Component Analysis),主成分分析是线性的数据降维技术,采用一
种数学降维的方法,在损失很少信息的前提下,找出几个综合变量作为主成分,来代替原来
众多的变量,使这些主成分能够尽可能地代表原始数据的信息,其中每个主成分都是原始变
量的线性组合,而且各个主成分之间不相关(即线性无关)。
sklearn中使用PCA
- 在sklearn中使用PCA降维要使用sklearn.decomposition.PCA
- PCA对象的explained_variance_表示PCA的解释方差得分
- 拟合使用fit方法,降维使用transform方法
实战_KPCA核主成分分析

KPCA降维原理
核主成分分析(Kernel Principal Component Analysis)对于输入空间中的矩阵X,先
用一个非线性映射把X中的所有样本映射到一个高维甚至是无穷维的空间(特征空间),使
其线性可分,然后在这个高维空间进行PCA降维。
sklearn中使用KPCA
- 在sklearn中使用PCA降维要使用sklearn.decomposition.KernelPCA
- KernelPCA对象的lambdas_表示KPCA的中心核矩阵特征值
- 拟合使用fit方法,降维使用transform方法
实战_t-SNE数据降维
t-SNE降维原理
TSNE是另一种常用的数据降维方法。由T和SNE组成,也就是T分布和随机近邻嵌入
(Stochastic neighbour Embedding)。其主要优势在于高维数据空间中距离相近的点投
影到低维空间中仍然相近。
t-SNE(TSNE)将数据点之间的相似度转换为概率。原始空间中的相似度由高斯联合概率
表示,嵌入空间的相似度由"学生t分布"表示。
简单解释t-SNE的降维原理:想要将二维数据点映射到一维,并且还要保存原来二维空间
中的聚类情况
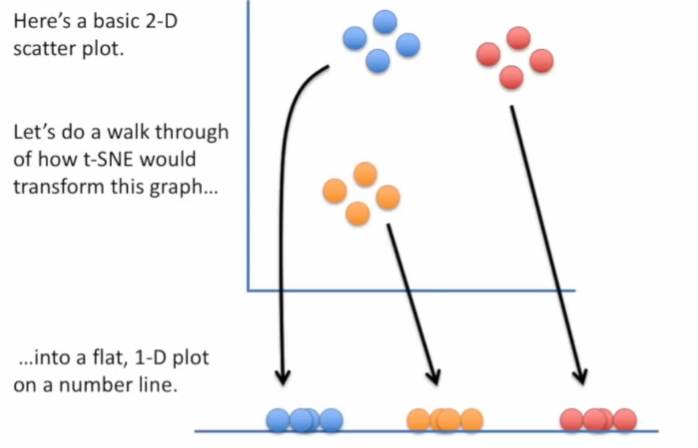
首先,将数据点随机排列在一维数字线上:
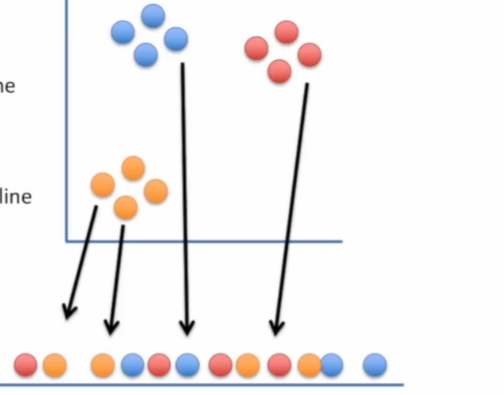
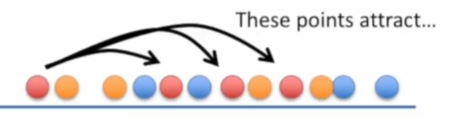
根据在原始数据空间中的相似度(距离),每个点在低维空间中向左或向右移动,目
的是找到它们的"同类"。
最终在低维空间的聚类:

sklearn中使用t-SNE
python
from sklearn.manifold import TSNE
tsne = TSNE(n_components=3,perplexity=25,
early_exaggeration=3,random_state=123)
'''
参数:
perplexity(困惑度):较大的数据集通常需要更大的perplexity
early_exaggeration(前期放大系数):控制原始空间中的自然簇在嵌入空间中的紧密程度以及它们之间的空间大小
'''决策树基础
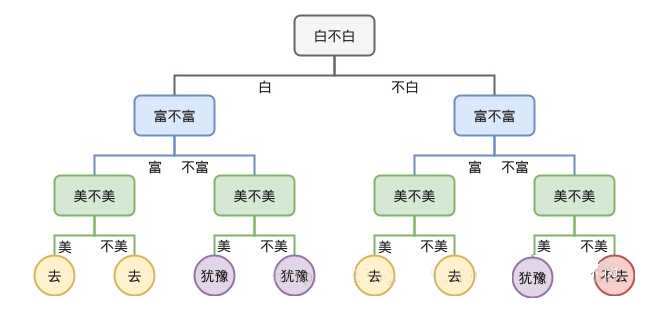
什么是决策树
决策树学习的算法通常是一个递归地选择最优特征(选择方法的不同,对应着不同的算
法),并根据该特征对训练数据进行分割,使得各个子数据集有一个最好的分类的过程。这
一过程对应着对特征空间的划分,也对应着决策树的构建。
- 决策树提供了一种展示类似在什么条件下会得到什么值这类规则的方法
- 决策树一般是自上而下生成的
- 决策树既可以解决分类问题,也可以解决回归问题
信息增益与信息增益比
- 熵(entropy)
熵(entropy)表示随机变量不确定性的度量。设X是一个取有限个值的离散随机变量,其
概率分布为
P(X=xi)=pi,i=1,2,...,n
则随机变量X的熵定义为
H(X)=−∑i=1npilogpi
- 信息增益
特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件
下D的经验条件熵H(D|A)之差,即
g(D,A)=H(D)−H(D|A)
信息增益大的特征具有更强的分类能力
举个例子:
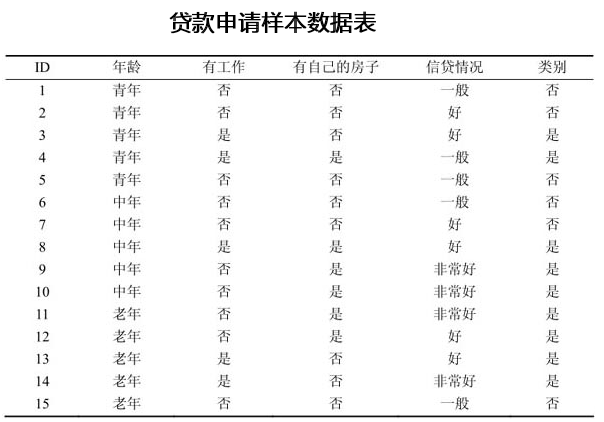

g(D,A~2~),g(D,A~3~),g(D,A~4~)的计算方法类似
- 信息增益比
信息增益值的大小是相对于训练数据集而言的,并没有绝对意义。当某个特征的取值种
类非常多时,会导致该特征对训练数据集的信息增益偏大。反之,信息增益值会偏小。使用
信息增益比(information gain ratio)可以对这一问题进行校正。这是特征选择的另一准
则。
特征A对训练数据集D的信息增益比g~R~(D,A)定义为其信息增益g(D,A)与训练数据集D关于
特征A的值的熵H~A~(D)之比,即
gR(D,A)=g(D,A)HA(D)
决策树的ID3和C4.5生成算法
- ID3算法生成决策树的核心是在决策树各个结点上应用信息增益准则选择特征,递归地构建决策树
- C4.5在生成决策树的过程中,用信息增益比来选择特征
注意:
决策树生成只考虑了对训练数据更好的拟合,可以通过对决策树进行剪枝,从而减小模型的复杂度,达到避免过拟合的效果
基尼指数与CART决策树

基尼指数(Gini index)
在分类问题中,假设有K个类,样本点属于第k类的概率为p~k~,则概率分布的基尼指数定义为
Gini(p)=∑k=1Kpk(1−pk)=1−∑k=1Kpk2
Gini指数越小表示集合的纯度越高,反之,集合越不纯
例如:有三个类别,它们所占的比例分别为{1/3,1/3,1/3},则基尼指数为
G=1-(1/3)^2^-(1/3)^2^-(1/3)^2^=0.666;
若三个类别所占的比例分别为{1/10,2/10,7/10},则基尼指数为
G=1-(1/10)^2^-(2/10)^2^-(7/10)^2^=0.46;
若三个类别所占的比例分别为{1,0,0},则基尼指数为
G=1-1^2^=0;
CART决策树
分类与回归树(classification and regression tree,CART)模型是应用广泛的决策树学习方法。CART既可以用于分类也可以用于回归。
CART分类树默认使用基尼指数选择最优特征
各类算法总结
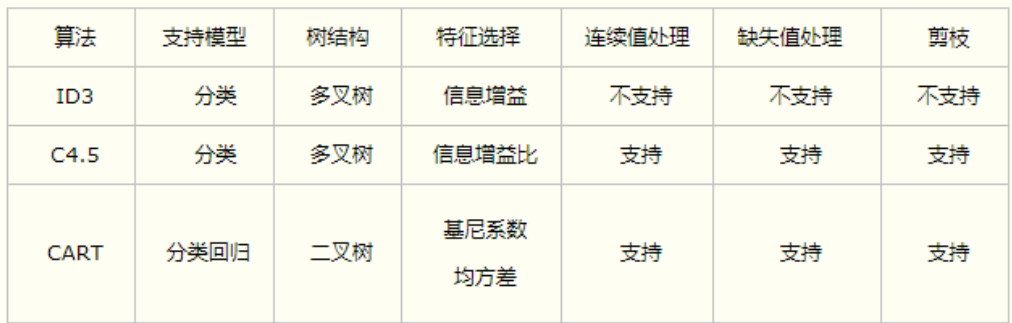
-
ID3:信息增益标示按某种特性分类后,剩余特性的信息熵的大小的衰减程度,信息熵越小,
证明已经分好的类别就更加的纯粹单一
-
C4.5:选择了信息增益比替代信息增益;由于ID3算法会倾向于选取特征值较多的特征
进行分类(因为这样会让信息增益很大),比如:区分每个学生的成绩采用学生的学号进行区分,那么每个学生对应一个学号,则按照学号分的话,每个分组中就只有一个样本,并且信息熵为0,显然这个不是我们想要的,因此我们引入了信息增益比,每次选择分类特性的时候,根据信息增益比进行选取
-
基尼系数:代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好
实战------CART分类树的sklearn实现

sklearn中使用sklearn.tree.DecisionTreeClassifier可以实现CART分类树,默认使用gini指数选择特征。
在使用DecisionTreeClassifier对训练数据集进行拟合后,可使用下面封装的绘图函数进行观察。
python
# 封装绘图函数
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)实战------决策树解决回归问题

sklearn中使用sklearn.tree.DecisionTreeRegressor可以实现CART回归树
python
from sklearn.tree import DecisionTreeRegressor
# DecisionTreeRegressor可以实现CART回归树
dt_reg = DecisionTreeRegressor()
dt_reg.fit(X_train,y_train) # 拟合训练数据集
print(dt_reg.score(X_test,y_test)) # 在测试集上查看R2指标客户违约预测模型

背景介绍
随着经济迅速发展,我国商业银行的客户违约现象也越来越多,这直接影响了社会生活
的各个方面,因此急需对客户的违约行为进行预测。传统的人工信用评审,耗时耗力,并且
正确率较低。构建高稳定性、高正确率的客户违约预测模型势在必行。
客户违约预测模型的目的是通过已有的客户信息和违约表现(数字1代表违约,数字0
代表未违约)来搭建合适的模型,从而预测之后的客户是否会违约。
分析步骤
- 读取数据
- 划分特征变量和目标变量
- 划分训练集和测试集
- 模型训练
- 模型评估
代码实现
python
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# 读取数据
df = pd.read_excel('客户信息及违约表现.xlsx')
# 划分特征变量和目标变量
X = df.drop(columns='是否违约')
y = df['是否违约']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# 模型训练
clf = DecisionTreeClassifier(max_depth=3,random_state=123)
clf = clf.fit(X_train, y_train)
# 模型预测及评估
y_pred = clf.predict(X_test)
print(y_pred)
# 查看模型预测准确度
from sklearn.metrics import accuracy_score
score = accuracy_score(y_test,y_pred)
print(score)
# 预测不违约&违约概率
y_pred_proba = clf.predict_proba(X_test)
'''打印看看预测的不违约&违约概率,此时获得y_pred_proba是个二维数组,共两 列,左列为不违约概率,右列为违约概率'''
print(y_pred_proba)
# 模型预测效果评估
# ROC曲线相关知识
from sklearn.metrics import roc_curve
fpr, tpr, thres = roc_curve(y_test.values, y_pred_proba[:, 1])
# 绘制ROC曲线,注意图片展示完要将其关闭才会执行下面的程序
import matplotlib.pyplot as plt
plt.plot(fpr, tpr)
plt.show()
# 求出AUC值
from sklearn.metrics import roc_auc_score
auc_score = roc_auc_score(y_test.values, y_pred_proba[:, 1])
print(auc_score)集成学习
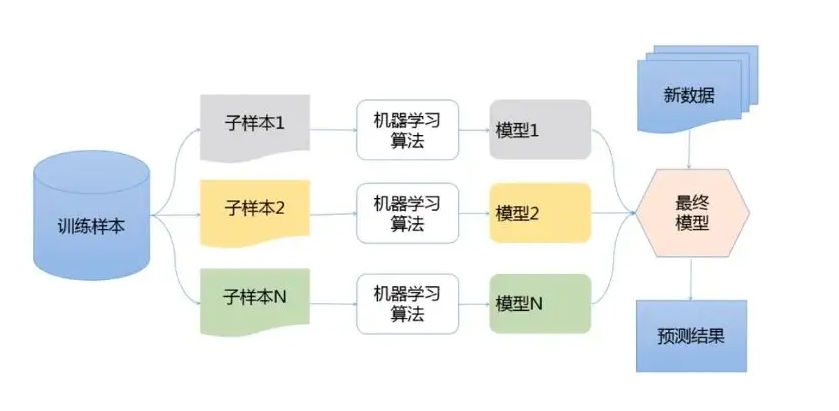
什么是集成学习
集成学习(ensemble learning)本身不是一个单独的机器学习算法,而是通过构建并结
合多个机器学习模型来完成学习任务------博采众长。集成学习很好的避免了单一学习模型带
来的过拟合问题。
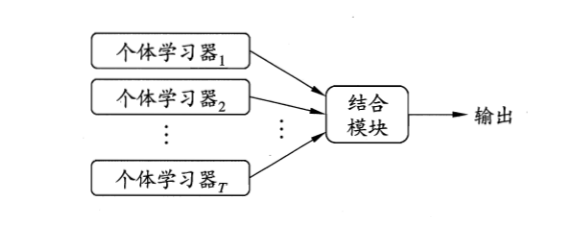
集成学习的类型
根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类:
- Bagging(个体学习器间不存在强依赖关系、可同时生成的并行化方法)
- Boosting(个体学习器间存在强依赖关系、必须串行生成的序列化方法)
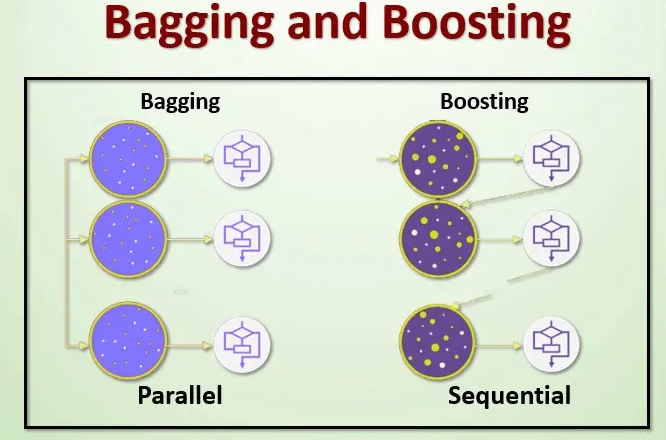
Bagging与随机森林
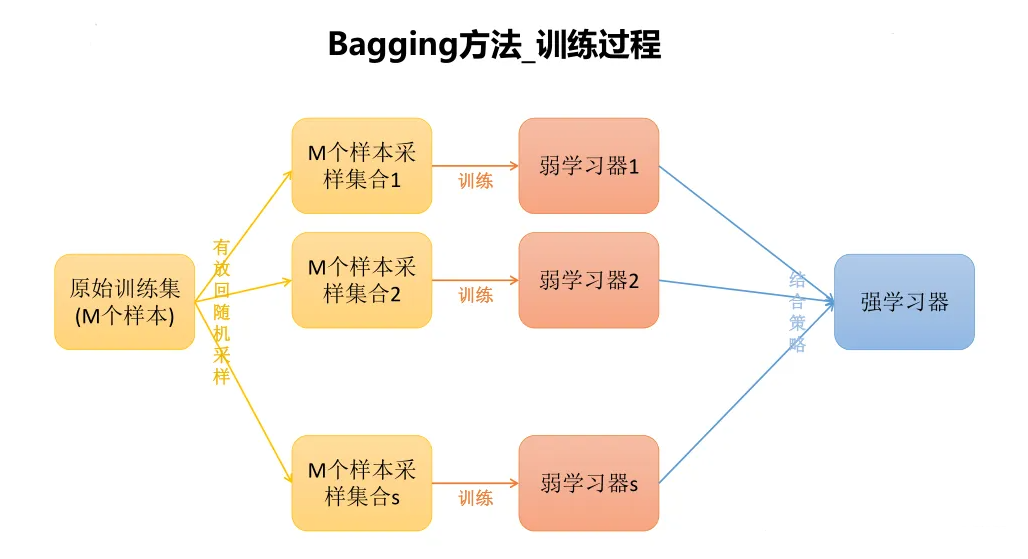
Bagging介绍
Bagging是并行式集成学习最著名的代表,它是基于自助采样法(bootstrap sampling)
自助采样法(bootstrap sampling):
给定包含m个样本的数据集,先随机取出一个样本放入采样集中并记录,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样,经过m次随机采样操作,我们得到含m个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则从未出现(平均37%没有取到)。
带外数据OOB(Out of Bag)
自助采样过程导致一部分样本可能没有取到(平均37%没有取到),这些未取到的样本称为
OOB(Out of Bag),可以使用这部分OOB的数据集作为测试集
Bagging的基本流程
基于每个采样集训练出一个基学习器,再将这些基学习器进行结合
- 对分类任务,使用简单投票法
- 对回归任务,使用简单平均法
随机森林
随机森林(Random Forest,简称RF)是Bagging的一个扩展变体。
RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。
具体来说,传统决策树在选择划分属性时是在当前结点的属性集合(假定有d个属性)
中选择一个最优属性;而在RF中,对基决策树的每个结点,先从该结点的属性集合中随机
选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。这里的参
数k控制了随机性的引入程度:若令k=d,则基决策树的构建与传统决策树相同;若令k=1,
则是随机选择一个属性用于划分;一般情况下,推荐值k=log~2~d。
实战------随机森林实现分类

在sklearn中,使用随机森林算法实现分类的功能使用的是RandomForestClassifier.
python
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, oob_score=True, random_state=666, n_jobs=-1)
rf_clf.fit(X, y) # 拟合
rf_clf.oob_score_ # 使用OOB数据测试Adaboost
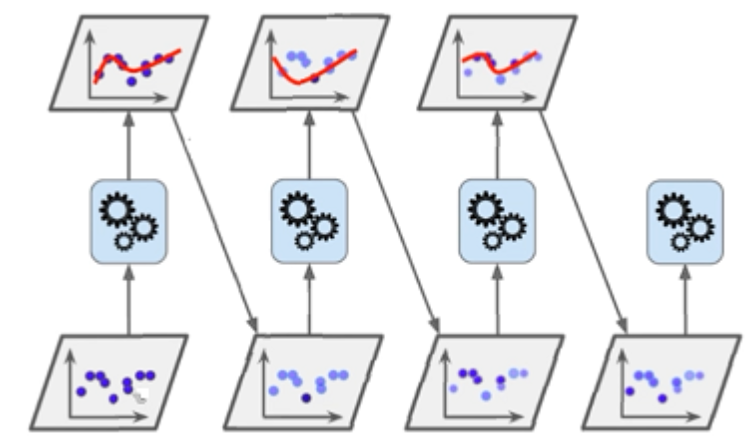
Adaboost的原理
以分类为例,Adaboost算法通过提高前一轮分类器分类错误的样本的权值,而降低那
些被分类正确的样本的权值。
需要注意的是,由于每个子模型要使用全部的数据集进行训练,因此 Adaboost算法中
没有oob数据集,在使用 Adaboost 算法前,需要划分数据集:train_test_split。
实战------Adaboost + 决策树

在使用Adaboost与决策树结合解决分类问题时,使用AdaBoostClassifier
python
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=2), n_estimators=500)
ada_clf.fit(X_train, y_train)
ada_clf.score(X_test, y_test)信用卡精准营销模型

背景介绍
当前经济增速下行,风控压力加大,各家商业银行纷纷投入更多资源拓展信用卡业
务,信用卡产业飞速发展。因为市场竞争激烈,信用卡产品同质化严重,商业银行需要采
用更快捷有效的方式扩大客户规模,实现精准营销,从而降低成本提高效益,增强自身竞
争力。
分析步骤
- 读取数据
- 划分特征变量和目标变量
- 划分训练集和测试集
- 模型训练
- 模型评估
代码实现
python
# 读取数据
import pandas as pd
df = pd.read_excel('信用卡精准营销模型.xlsx')
# 解决用Pandas处理csv,excel文件多出unnamed列问题
df = df.loc[:, ~df.columns.str.contains('Unnamed')]
df.head()
# 划分特征变量和目标变量
X = df.drop(columns='响应')
y = df['响应']
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
# 模型训练
from sklearn.ensemble import AdaBoostClassifier
clf = AdaBoostClassifier(random_state=123)
clf.fit(X_train, y_train)
# 模型评估
y_pred = clf.predict(X_test)
print(y_pred)
# 查看预测准确度
from sklearn.metrics import accuracy_score
score = accuracy_score(y_test,y_pred)
print(score)
# 查看预测分类概率
y_pred_proba = clf.predict_proba(X_test)
# 查看前5项,第一列为分类为0的概率,第二列为分类为1的概率
print(y_pred_proba[:5])
# 查看AUC值
from sklearn.metrics import roc_auc_score
score = roc_auc_score(y_test, y_pred_proba[:,1])
print(score)
# 查看特征重要性
print(clf.feature_importances_)
# 通过DataFrame的方式展示特征重要性
features = X.columns # 获取特征名称
importances = clf.feature_importances_ # 获取特征重要性
# 通过二维表格形式显示
importances_df = pd.DataFrame()
importances_df['特征名称'] = features
importances_df['特征重要性'] = importances
importances_df.sort_values('特征重要性', ascending=False)广告收益回归预测模型

背景介绍
投资商经常会通过多个不同渠道投放广告,以此来获得经济利益。在本案例中我们选
取公司在电视、广播和报纸上的投入,来预测广告收益,这对公司策略的制定是有较重要的
意义。
分析步骤
- 读取数据
- 划分特征变量和目标变量
- 划分训练集和测试集
- 模型训练
- 模型评估
代码实现
python
# 读取数据
import pandas as pd
df = pd.read_excel('广告收益数据.xlsx')
df.head()
# 划分特征变量和目标变量
X = df.drop(columns='收益')
y = df['收益']
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
# 模型训练
from sklearn.ensemble import AdaBoostRegressor
model = AdaBoostRegressor(random_state=123)
model.fit(X_train, y_train)
# 模型评估
print("自带的score方法得到R2:",model.score(X_test,y_test))
y_pred = model.predict(X_test)
print("r2_score函数得到R2:",r2_score(y_test,y_pred))
# 通过DataFrame的方式展示特征重要性
features = X.columns # 获取特征名称
importances = model.feature_importances_ # 获取特征重要性
# 通过二维表格形式显示
importances_df = pd.DataFrame()
importances_df['特征名称'] = features
importances_df['特征重要性'] = importances
importances_df.sort_values('特征重要性', ascending=False)Gradient Boosting

Gradient Boosting原理
和Adaboost不同,Gradient Boosting 在迭代的时候选择损失函数在其梯度方向下降
的方向不停地改进模型。
- 训练一个模型m1,产生错误e1
- 针对e1训练第二个模型m2,产生错误e2
- 针对e2训练第三个模型m3,产生错误e3...
- 最终预测结果是:m1+m2+m3+...
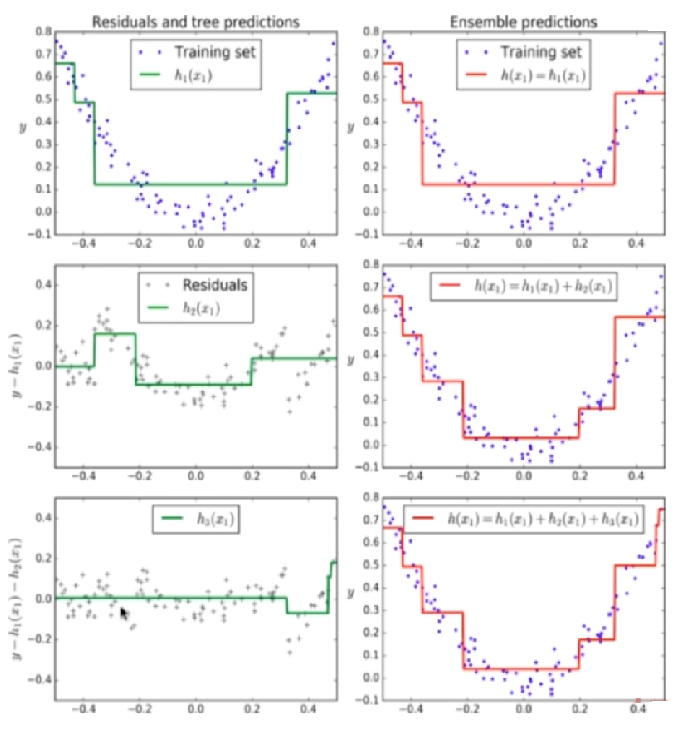
注意:
Adaboost和Gradient Boosting的区别主要在于从不同的角度实现对上一轮训练错误的数据更多关注,Adaboost主要对数据引入权重,训练后调整学习错误的数据的权重,从而使得下一轮学习中给予学习错误的数据更多的关注。
实战------GBDT及其代码实现

GBDT的组成部分
GBDT由GB(Gradient Boosting)和DT(Regression Decision Tree)组成
注意:
GBDT中的树是回归树(不是分类树),GBDT用来做回归预测,调整后也可以用于分类
我们通过以下例子来详解算法过程,希望通过训练提升树来预测年龄。训练集是4个人,
A、B、C、D年龄分别是14、16、24、26。样本中有购物金额、经常到百度知道提问等特
征。GBDT过程如下图所示:
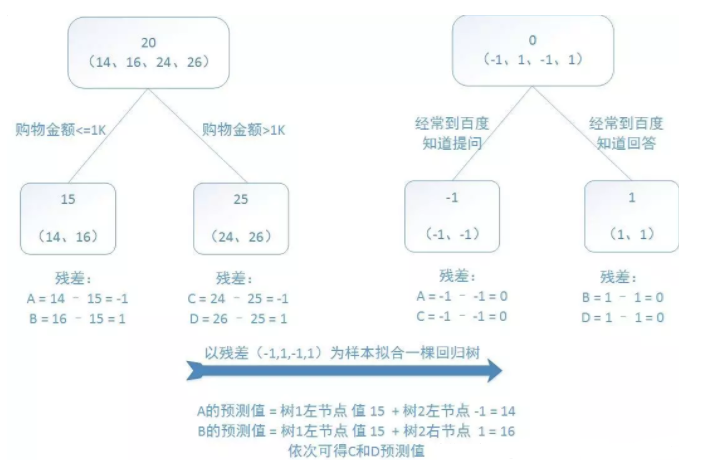
我们能够直观的看到,预测值等于所有树值的累加,如A的预测值=树1左节点(15)+树2
左节点(-1)=14。因此给定当前决策树模型,只需拟合决策树的残差,便可迭代得到提升树
LightGBM

LightGBM介绍
LigthGBM算法是Boosting集合模型中的新晋成员,由微软提供,它和XGBoost算法一
样是对GBDT的高效实现,原理上它和GBDT及XGBoost类似,都采用损失函数的负梯度作
为当前决策树的残差近似值,去拟合新的决策树。
LightGBM模型既可以做分类分析,也可以做回归分析,对应的模型分别为:
- LightGBM分类模型( LGBMClassifier )
- LightGBM回归模型( LGBMRegressor )
LightGBM原理
LightGBM使用的Leaf-wise策略,每次在当前叶子节点中,找出分裂增益最大的叶子节点进行分裂,而不是所有节点都进行分裂,这样可以提高精度。
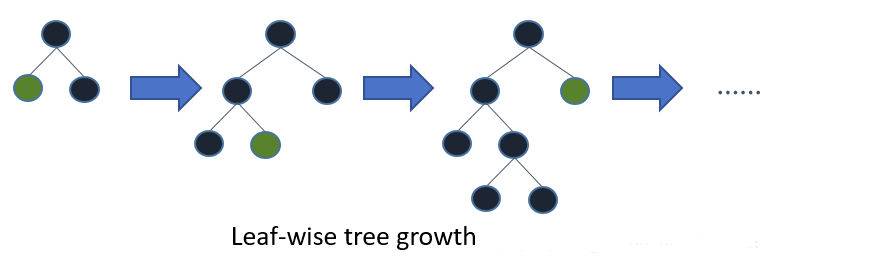
Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-
wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
LightGBM安装
- pip安装方式:pip install lightgbm==2.2.3
- 下载相关的whl文件进行安装(https://www.lfd.uci.edu/~gohlke/pythonlibs/#lightgbm)
XGBoost算法

XGBoost介绍
XGBoost全称是eXtreme Gradient Boosting,可译为极限梯度提升算法。它是GBDT的
高效实现,由陈天奇设计,致力于让提升树突破自身的计算极限,以实现运算快速,性能优
秀的工程目标。
XGBoost既可以做分类分析,也可以做回归分析,对应的模型分别为:
- XGBoost分类模型(XGBClassifier)
- XGBoost回归模型(XGBRegressor)
XGBoost原理
XGBoost作为GBDT的高效实现,在如下两个方面做了优化:
- 算法本身的优化
XGBoost算法的损失函数,除了本身的损失,还加上了正则化部分,可以防止过拟合,
泛化能力更强。XGBoost算法的损失函数是对误差部分采用二阶泰勒展开,相较于GBDT算
法的损失函数只对误差部分做负梯度(一阶泰勒)展开,更加准确。
1N∑i=1NL(yi,f(xi))+λJ(f)
其中λ是正则化系数, J(f)是正则项。
- 算法运行效率的优化
XGBoost构建树的分裂策略是 Level-wise,即同一层的叶子节点每次都一起分裂,容易
进行多线程优化,从而提升运行效率。
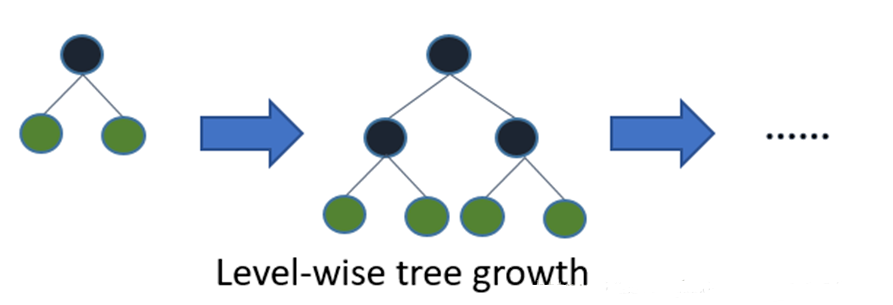
注意:
- XGBoost 构建树的分裂策略是Level-wise
- GBDT的另外一个经典实现LightGBM采用的分裂策略是Leaf-wise
XGBoost的安装
-
使用pip直接安装
pip install xgboost==1.5.1
-
下载相关的whl文件进行安装(https://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost)
实战------XGBoost的sklearn实现

XGBoost的安装
-
使用pip直接安装
pip install xgboost
-
下载相关的whl文件进行安装(https://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost)
sklearn中调用XGBoost接口
python
from xgboost import XGBClassifier
xgb = XGBClassifier(learning_rate=0.01,
n_estimators=10,
max_depth=4
)
xgb.fit(X_train,y_train) # 拟合
print(xgb.score(X_test,y_test)) # 在测试集上测试XGBoost实现广告收益预测模型

背景介绍
投资商经常会通过多个不同渠道投放广告,以此来获得经济利益。在本案例中我们选
取公司在电视、广播和报纸上的投入,来预测广告收益,这对公司策略的制定是有较重要的
意义。
分析步骤
- 读取数据
- 划分特征变量和目标变量
- 划分训练集和测试集
- 模型训练
- 模型评估
代码实现
python
# 读取数据
import pandas as pd
df = pd.read_excel('广告收益数据.xlsx')
# 划分特征变量和目标变量
X = df.drop(columns='收益')
y = df['收益']
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
# 模型训练
from xgboost import XGBRegressor
model = XGBRegressor() # 使用默认参数
model.fit(X_train, y_train)
# 模型评估
print(model.score(X_test, y_test)) # 计算R^2值
# 通过上一节讲过的feature_importances_属性,我们来查看模型的特征重要性:
features = X.columns # 获取特征名称
importances = model.feature_importances_ # 获取特征重要性
# 通过二维表格形式显示
importances_df = pd.DataFrame()
importances_df['特征名称'] = features
importances_df['特征重要性'] = importances
importances_df.sort_values('特征重要性', ascending=False)LightGBM
LightGBM介绍
LigthGBM算法是Boosting集合模型中的新晋成员,由微软提供,它和XGBoost算法一
样是对GBDT的高效实现,原理上它和GBDT及XGBoost类似,都采用损失函数的负梯度作
为当前决策树的残差近似值,去拟合新的决策树。
LightGBM模型既可以做分类分析,也可以做回归分析,对应的模型分别为:
- LightGBM分类模型( LGBMClassifier )
- LightGBM回归模型( LGBMRegressor )
LightGBM原理
LightGBM使用的Leaf-wise策略,每次在当前叶子节点中,找出分裂增益最大的叶子节点进行分裂,而不是所有节点都进行分裂,这样可以提高精度。
Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-
wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
LightGBM安装
- pip安装方式:pip install lightgbm==2.2.3
- 下载相关的whl文件进行安装(https://www.lfd.uci.edu/~gohlke/pythonlibs/#lightgbm)
信用评分模型

背景介绍
为了降低不良贷款率,保障自身资金安全,提高风险控制水平,银行等金融机构会根
据客户的信用历史资料构建信用评分模型给客户评分。根据客户的信用得分,可以估计客户
按时还款的可能,并据此决定是否发放贷款及贷款的额度和利率。
分析步骤
- 读取数据
- 划分特征变量和目标变量
- 划分训练集和测试集
- 模型训练
- 模型评估
python
# 读取数据
import pandas as pd
df = pd.read_excel('信用评分卡模型.xlsx')
df.head()
# 划分特征变量和目标变量
X = df.drop(columns='信用评分')
y = df['信用评分']
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
# 模型训练
from lightgbm import LGBMRegressor
model = LGBMRegressor()
model.fit(X_train, y_train)
# 模型评估
# 查看r2评分
model.score(X_test, y_test)
features = X.columns # 获取特征名称
importances = model.feature_importances_ # 获取特征重要性
# 通过二维表格形式显示
importances_df = pd.DataFrame()
importances_df['特征名称'] = features
importances_df['特征重要性'] = importances
importances_df.sort_values('特征重要性', ascending=False)