文章目录
- [一: 数据库约束](#一: 数据库约束)
-
- [1. 什么是数据库约束](#1. 什么是数据库约束)
- [2. 常见约束类型](#2. 常见约束类型)
-
- [(1) NOT NULL(非空约束)](#(1) NOT NULL(非空约束))
- [(2) UNIQUE(唯一约束)](#(2) UNIQUE(唯一约束))
- [(3) DEFAULT(默认约束)](#(3) DEFAULT(默认约束))
- [(4) PRIMARY KEY(主键约束)](#(4) PRIMARY KEY(主键约束))
- [(5) FOREIGN KEY(外键约束)](#(5) FOREIGN KEY(外键约束))
- [(6) CHECK(检查约束)](#(6) CHECK(检查约束))
- [二: 表关系](#二: 表关系)
-
- [1. 一对一](#1. 一对一)
- [2. 一对多(1 : N)](#2. 一对多(1 : N))
- [3. 多对多(M : N)](#3. 多对多(M : N))
- [4. 关系总结](#4. 关系总结)
- [三: 关系型数据库三大范式](#三: 关系型数据库三大范式)
- [四: 实际表设计流程](#四: 实际表设计流程)

文章作者:当战神遇到编程
文章专栏:MySQL
欢迎大家点赞👍评论📝收藏⭐文章



一: 数据库约束
1. 什么是数据库约束
数据库约束是对表中数据进行限制的规则 ,用于保证数据的正确性 、完整性 、一致性 。简单理解:防止插入错误数据。
2. 常见约束类型
| 约束名 | 作用 |
|---|---|
| NOT NULL | 字段不能为空 |
| UNIQUE | 字段值唯一,不能重复 |
| PRIMARY KEY | 主键,唯一且不能为空 |
| FOREIGN KEY | 外键,保证关联关系 |
| DEFAULT | 默认值 |
| CHECK | 检查数据是否满足条件 |
(1) NOT NULL(非空约束)
某列必须有值。
sql
student_name VARCHAR(10) NOT NULL表结构

(2) UNIQUE(唯一约束)
该列数据不能重复,但可以有一个或多个 NULL(不同数据库略有区别)。
sql
student_phone VARCHAR(20) UNIQUE表结构

(3) DEFAULT(默认约束)
插入数据时若未赋值,则使用默认值。
sql
student_gender VARCHAR(2) DEFAULT '男'表结构

(4) PRIMARY KEY(主键约束)
这一行/这一条记录的身份标识
sql
student_id INT PRIMARY KEY表结构

特点:
- 主键的值在表中是唯一的
- 不能为空:主键字段的值必须有内容,不能是空白或NULL
- 只能定义一个主键;主键可以是单列,也可以是多列组合(复合主键)。
sql
-- 复合主键例子
-- 规则: 只有当 student_name 和 class_id 同时相同时,才会被判定为重复。
CREATE TABLE student(student_name VARCHAR(10),class_id INT,PRIMARY KEY(student_name,class_id));表结构

- 当主键为整数类型时,通常建议开启 AUTO_INCREMENT(自增)属性,让数据库自动维护主键值,避免手动维护的麻烦。
sql
CREATE TABLE student(student_id INT PRIMARY KEY AUTO_INCREMENT,student_name VARCHAR(10),class_id INT);表结构
主键值交给数据库自动分配,插入时可以直接写 NULL,无需手动指定:
sql
INSERT INTO student VALUES(NULL,'张三',1);核心原理与特点
1.数据库内部维护了一个计数器,默认情况下,新值 = 上一次分配的值 + 1。
2.自增主键在开发中,特别常用,但对于分布式场景无法应对
(5) FOREIGN KEY(外键约束)
用于建立父表(主表)与子表(从表)之间的引用关系 ,保证数据的参照完整性,避免出现无效的 "孤儿数据"。
补充说明:父表中被关联的列必须带有索引(主键自带索引,因此外键通常引用父表的主键)。
sql
-- 1. 切换数据库
USE java118;
-- 2. 创建父表:班级表
CREATE TABLE class(
class_id INT PRIMARY KEY AUTO_INCREMENT,
class_name VARCHAR(10)
);
-- 插入班级数据
INSERT INTO class VALUES(NULL,'java110'), (NULL,'java111'), (NULL,'java112');
-- 3. 创建子表:学生表(class_id 列设置外键,引用 class 表的 class_id)
CREATE TABLE student(
student_id INT PRIMARY KEY AUTO_INCREMENT,
student_name VARCHAR(10),
class_id INT,
FOREIGN KEY (class_id) REFERENCES class(class_id)
);
-- 插入学生数据(外键值必须在父表中存在)
INSERT INTO student VALUES(NULL,'张三',1), (NULL,'李四',2), (NULL,'王五',3);外键的核心约束规则
-
子表约束(插入 / 修改限制):
如果父表中不存在对应的外键值,子表无法插入或修改该外键列。
例如:不能给学生插入一个不存在的班级 ID(如 class_id=99)。
-
父表约束(删除 / 修改限制):
如果父表中的数据正被子表引用,则该条数据无法直接删除或修改。
例如:不能直接删除还有学生关联的班级,否则会导致学生的 class_id 变成无效数据。
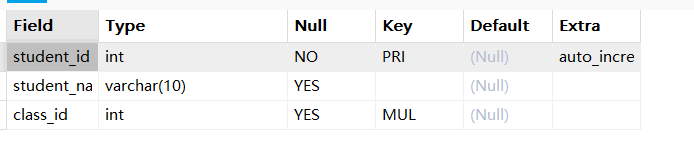
补充说明:查看外键约束
查看子表结构时,Key 列若显示为 MUL,就代表该列设置了外键约束:
外键实战:电商项目中的「逻辑删除」方案
在电商等实际项目中,外键的 "父表删除限制" 会带来一个典型矛盾,我们通常用逻辑删除来解决。
1.业务矛盾:外键约束 vs 商品下架
- 业务场景:商家想把 "衬衫" 下架(相当于删除商品),但订单表中已经有大量该商品的历史订单。
- 矛盾点:外键约束会禁止直接删除商品,否则订单表中的商品 ID 会变成无效数据,导致历史订单混乱。
2. 解决方案:逻辑删除
核心原理
不真正物理删除数据,而是通过一个 标记位(Flag) 来表示该数据的 "有效 / 失效" 状态,让数据 "假死" 而非消失。
实现步骤
(1) 给父表增加标记列
在商品表中新增一个状态字段,例如 isOk:
○ 1 表示商品有效(上架状态)
○ 0 表示商品失效(下架状态)
(2) 下架操作:改为更新标记位
不再执行 DELETE 删除语句,而是用 UPDATE 把标记位改成 0:
sql
-- 把商品id=1的商品标记为下架
UPDATE 商品表 SET isOk = 0 WHERE 商品id = 1;(3) 用户查询:过滤失效数据
查询商品列表时,只返回标记为有效的数据,用户感知不到 "已下架商品" 的存在:
sql
-- 只给用户展示未下架的商品
SELECT * FROM 商品表 WHERE isOk = 1;3.逻辑删除的核心优势
- 保留历史数据:已下架商品的历史订单记录依然完整可查,不会出现数据断裂。
- 数据安全可恢复:误操作下架后,只需把 isOk 改回 1 即可恢复商品,无需复杂的数据恢复流程。
- 兼容外键约束:无需删除数据,自然避开了外键对父表删除的限制,同时依然保证了数据的参照完整性。
(6) CHECK(检查约束)
限制字段取值范围。
例如年龄不能小于6。
sql
CREATE TABLE student(age INT CHECK(age > 6),name VARCHAR(20));二: 表关系
表与表之间常见有四种关系类型:
一对一(1 : 1)
一对多(1 : N)
多对多(M : N)
没关系
1. 一对一
含义:
一张表中的一条记录,只对应另一张表中的一条记录。
示例:
用户表 与 用户详情表
user(用户表)
| id | username |
|---|---|
| 1 | 张三 |
user_info(详情表)
| user_id | 身份证号 | 地址 |
|---|---|---|
| 1 | xxx | 北京 |
说明:
- 一个用户只有一份详情
- 一份详情只属于一个用户
一对一 (1:1) 实现代码
核心要点 : 在从表的外键上添加 UNIQUE 约束,确保一个主表记录只能被引用一次。
sql
-- 1. 创建用户主表
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(20)
);
-- 2. 创建用户详情表
CREATE TABLE user_info (
-- user_id 既是外键,也必须是唯一的,从而实现 1:1
user_id INT UNIQUE,
id_card VARCHAR(18),
address VARCHAR(100),
-- 建立外键关联
FOREIGN KEY (user_id) REFERENCES user(id)
);2. 一对多(1 : N)
含义:
一张表中的一条记录,对应另一张表中的多条记录。
示例:
学院表 与 学生表
college(学院表)
| id | 学院名 |
|---|---|
| 1 | 计算机学院 |
student(学生表)
| id | 姓名 | college_id |
|---|---|---|
| 1001 | 张三 | 1 |
| 1002 | 李四 | 1 |
说明:
- 一个学院有多个学生
- 一个学生只属于一个学院
一对多 (1:N) 实现代码
核心要点: 外键直接建立在"多"的一方(学生表)即可,不需要加 UNIQUE。
sql
-- 1. 创建学院表 (一)
CREATE TABLE college (
id INT PRIMARY KEY AUTO_INCREMENT,
college_name VARCHAR(20)
);
-- 2. 创建学生表 (多)
CREATE TABLE student (
id INT PRIMARY KEY AUTO_INCREMENT,
student_name VARCHAR(10),
college_id INT, -- 外键列
-- 多个学生可以关联同一个学院ID
FOREIGN KEY (college_id) REFERENCES college(id)
);3. 多对多(M : N)
含义:
两张表中的多条记录彼此对应多条记录。
示例:
学生表 与 课程表
- 一个学生可选多门课
- 一门课可被多个学生选
student
| id | 姓名 |
|---|
course
| id | 课程名 |
|---|---|
student_course(中间表)
| student_id | course_id |
|---|---|
| 1001 | C01 |
| 1001 | C02 |
| 1002 | C01 |
多对多 (M:N) 实现代码
核心要点: 必须创建一个独立的中间表,用来存放两个表的主键关联。
sql
-- 1. 创建学生表
CREATE TABLE student (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(10)
);
-- 2. 创建课程表
CREATE TABLE course (
id VARCHAR(10) PRIMARY KEY,
course_name VARCHAR(20)
);
-- 3. 创建中间表 (选课表)
CREATE TABLE student_course (
student_id INT,
course_id VARCHAR(10),
-- 建议:将两个外键设为联合主键,防止同一个学生重复选同一门课
PRIMARY KEY (student_id, course_id),
-- 分别建立外键关联
FOREIGN KEY (student_id) REFERENCES student(id),
FOREIGN KEY (course_id) REFERENCES course(id)
);4. 关系总结
| 关系类型 | 举例 | 实现方式 |
|---|---|---|
| 一对一 | 用户-详情 | 外键 + 唯一约束 |
| 一对多 | 学院-学生 | 多方加外键 |
| 多对多 | 学生-课程 | 建中间表 |
三: 关系型数据库三大范式
第一范式(1NF)列不可再分
核心要求:字段必须具有原子性(不可再分)
每一列 只能存一个值,不能存多个值。
不满足第一范式的例子:
| 学号 | 姓名 | 班级名 | 学校信息 |
|---|---|---|---|
| 101 | 张三 | Java一班 | 清华大学, 北京市海淀区, 010-8888 |
满足第一范式的例子(合格的表):
| 学号 | 姓名 | 班级名 | 学校名称 | 学校地址 | 学校电话 |
|---|---|---|---|---|---|
| 101 | 张三 | Java一班 | 清华大学 | 北京市海淀区 | 010-8888 |
注意:
- 数据库的"入场券": 第一范式是关系型数据库的最基本要求。如果不满足 1NF,则不能被称为真正的关系型数据库。
- 原子性的标准: 原子性不是绝对的,而是根据业务需求 决定的。
○ 例如: 如果业务只需要显示全名,那么 姓名 就是原子的;但如果业务需要区分"姓"和"名",那么 姓名 就得拆分为 姓 和 名 两列。
第二范式(2NF)消除部分依赖
核心定义:
在满足第一范式(1NF)的基础上,消除非主键字段对候选键的"部分函数依赖"。
1.必须要懂的底层概念 (术语拆解)
-
候选键 (Candidate Key) vs 主键 (Primary Key) :
○ 候选键 : 表中能唯一标识一行数据的列(或列组合)。
○ 主键 : 从候选键中选出来的"正职"班长。
○ 联合主键 : 由多个列共同组成的唯一主键。此时,单独的每一列只能叫"候选键",合在一起才叫"主键"。
-
函数依赖
○ 完全函数依赖 : 必须通过整个主键 才能确定某个数据。(2NF 要求 )
○ 部分函数依赖 : 只通过主键中的一部分列 ,就能确定某个数据。 ( 2NF 禁止)
2.案例剖析
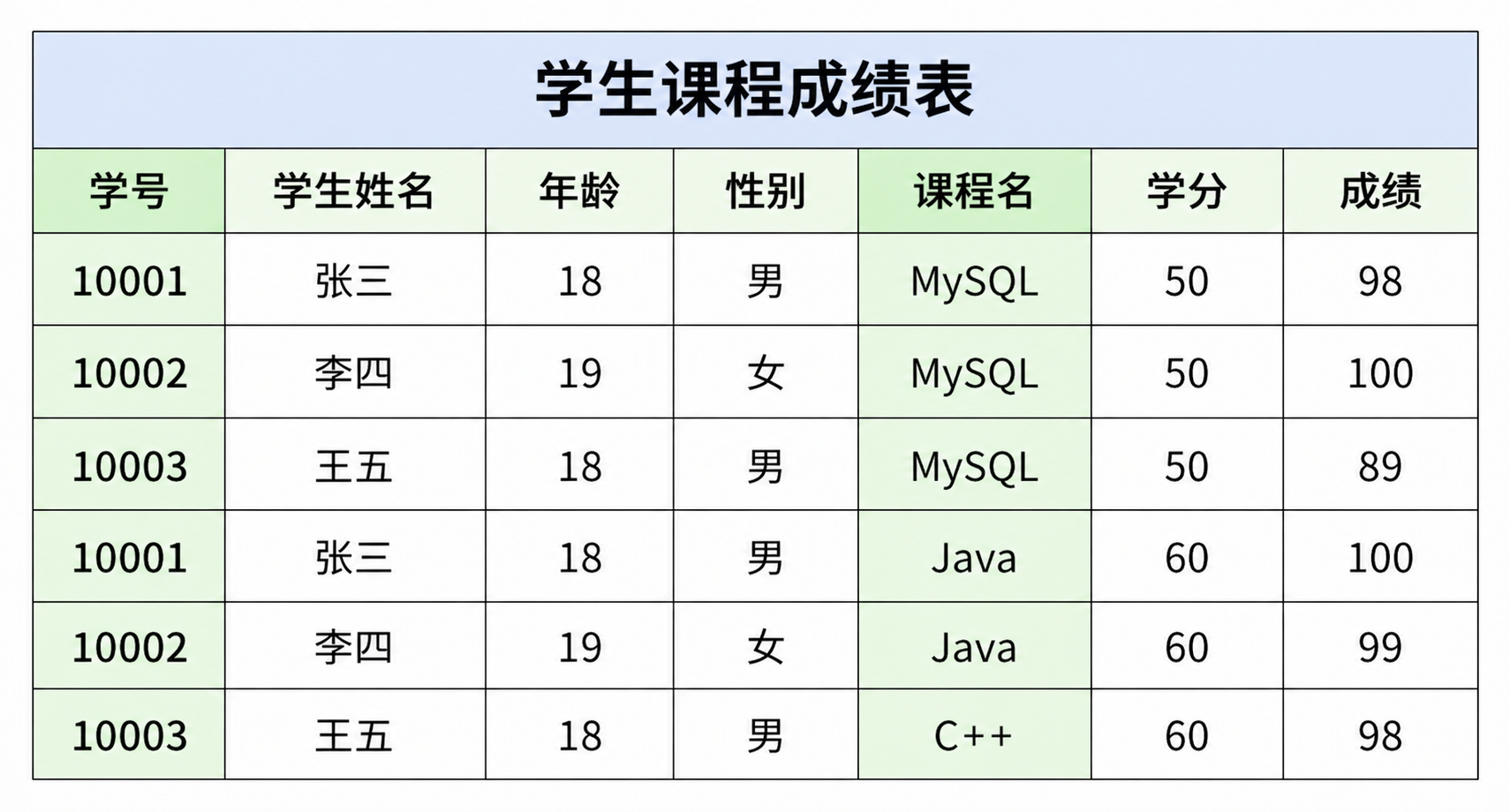
- 这张表中使用学号 + 课程名定义联合主键来唯一标识一个学生某门课程的成绩
- 这张表中学生姓名只 依赖于学号 ,不 依赖于课程名 ,学分只 依赖于课程名 ,不 依赖于学号,这两个非关键字段都不满足第二范式的核心定义
改正:拆成三个表
学生表
| Id | 学号 | 学生姓名 | 年龄 | 性别 |
|---|---|---|---|---|
| 1 | 10001 | 张三 | 18 | 男 |
| 2 | 10002 | 李四 | 19 | 女 |
| 3 | 10003 | 王五 | 18 | 男 |
课程表
| Id | 课程名 | 学分 |
|---|---|---|
| 1 | MySQL | 50 |
| 2 | Java | 60 |
| 3 | C++ | 60 |
成绩表
| 学生Id | 课程Id | 成绩 |
|---|---|---|
| 1 | 1 | 98 |
| 2 | 1 | 100 |
| 3 | 1 | 89 |
| 1 | 2 | 100 |
| 2 | 2 | 99 |
| 3 | 3 | 98 |
只有单列主键的表通常天然满足第二范式。
如果表没有满足第二范式,可能出现的问题有:
1.数据冗余 :学生的姓名,年龄学分都重复的出现,造成大量的数据冗余
-
更新异常 :假设需要调整MySQL的学分,就需要修改所有记录中关于MySQL的记录.如果部分记录更新失败,就会出现同一课程学分不一致的情况,表现为数据不一致
-
插入异常 :⽬前这样的设计,成绩与每⼀⻔课和学⽣都有对应关系,也就是说只有学⽣参加选修课程考试取得了成绩才能⽣成⼀条记录。当有⼀⻔新课还没有学⽣参加考试取得成绩之前,那么这⻔新课在数据库中是不存在的,因为成绩为空时记录没有意义。
-
删除异常:把毕业学⽣的考试数据全都删除,此时课程和学分的信息也会被删除掉,有可能导致⼀段时间内,数据库⾥没有某⻔课程和学分的信息。
第三范式(3NF)消除传递依赖
定义:在满⾜第⼆范式的基础上,消除非主键字段对非主键字段的依赖(消除传递依赖)。
一、先理解什么叫传递依赖
如果存在:
sql
主键 -> A -> B说明:
- A 依赖主键
- B 又依赖 A
那么 B 就是间接依赖主键,这叫传递依赖。
举个例子:
| 学号 | 姓名 | 年龄 | 所属学院 | 学院地址 | 学院电话 |
|---|
存在传递依赖:学号-> 所在学院-> 学院电话 ,存在传递依赖的表不满足第三范式。
改正:只需要拆分成两张表。
1.学院表
| 学院编号 | 学院名 | 学院电话 | 学院地址 |
|---|
2.学生表
| 学号 | 姓名 | 年龄 | 学院编号 |
|---|
这样设计后,两张表中的非主键字段都直接依赖各自主键;学生表通过外键(学院编号)与学院表建立关联关系。
四: 实际表设计流程
1. 需求分析(明确存什么)
- 理清业务: 搞清楚系统有哪些实体(如用户、商品、订单)以及它们之间的关系。
- 确定字段: 列出每个实体需要记录的信息(如用户有姓名、手机号、注册时间)。
2. 概念设计(画 E-R 图)
- 识别关系: 确定实体间是一对一(1:1)、一对多(1:N)还是多对多(N:N)。
- 绘图: 使用 E-R 图(实体-联系图)可视化表达,防止漏掉关键关联。
3.逻辑设计(定表结构)
- 表转换: 将实体转为表,字段转为列。
- 数据类型: 为每个字段选择合适的类型(如数字用 INT,短文本用 VARCHAR,时间用 DATETIME)。
- 主键设计: 每张表必须有一个唯一标识(通常是自增 ID 或 UUID)。
4. 范式约束(减少冗余)
- 遵循三范式(3NF):
○ 1NF: 字段不可再分(原子性)。
○ 2NF: 非主键字段必须完全依赖主键(消除部分依赖)。
○ 3NF: 非主键字段不能相互依赖(消除传递依赖,如:表里存了部门ID,就不应再存部门名称)。 - 注:有时为了性能会适当"反范式"(冗余少量字段减少连表)。
5. 物理优化(提升性能)
-
索引设计: 给高频查询的字段(如 username、order_sn)建立索引。
-
约束设置: 设置 NOT NULL(非空)、DEFAULT(默认值)、UNIQUE(唯一)。
-
存储引擎: 选择合适的引擎(如 MySQL 默认的 InnoDB)。
6. 评审与落地(产出 SQL)
- 设计评审: 与开发团队核对是否满足业务需求。
- 编写 DDL: 编写 CREATE TABLE 语句并执行。
- 维护文档: 更新数据库字典,方便后期维护。