分析Pytorch和vLLM
作业要求:
- 分析框架提供的功能和相关原理
- 分析框架的能力边界
- 分析框架对嵌入式算法部署的支撑/短板
一、功能
1.1pytorch功能
PyTorch 是一个开源深度学习框架,专为研究的灵活性和模块化而设计,同时具备生产部署所需的稳定性和支持。

PyTorch 是一个开源机器学习框架,旨在加速从研究原型到生产部署的过程。PyTorch 专为提供最大的灵活性和速度而构建,支持动态计算图,使研究人员和开发人员能够快速、直观地进行迭代。其符合 Python 风格的设计以及与原生 Python 工具的深度集成,使其成为构建和大规模训练深度学习模型的一个易用且强大的平台。
PyTorch 在学术界和工业界被广泛采用,已成为尖端研究和商业 AI 应用的首选框架。通过丰富的库、工具和集成生态系统,它支持广泛的用例------从自然语言处理和计算机视觉到强化学习和生成式 AI。PyTorch 还针对 CPU、GPU 和定制硬件加速器进行了性能优化,包括支持分布式训练,以及在云平台和移动设备上的部署。
PyTorch 是一个相对全面的库,其三个主要组成部分:
- PyTorch 作为张量库:在 NumPy 基于数组运算的编程库基础上进行功能拓展,新增了 GPU 加速计算能力,从而实现了 CPU 与 GPU 之间的无缝切换。
- PyTorch 作为自动微分引擎(即 autograd):能够自动计算张量运算的梯度,从而简化反向传播与模型优化流程。
- PyTorch 作为深度学习库,通过提供模块化、灵活且高效的构建组件(包含预训练模型、损失函数与优化器),为各类深度学习模型的设计与训练提供支持,同时兼顾研究者和开发者的需求。
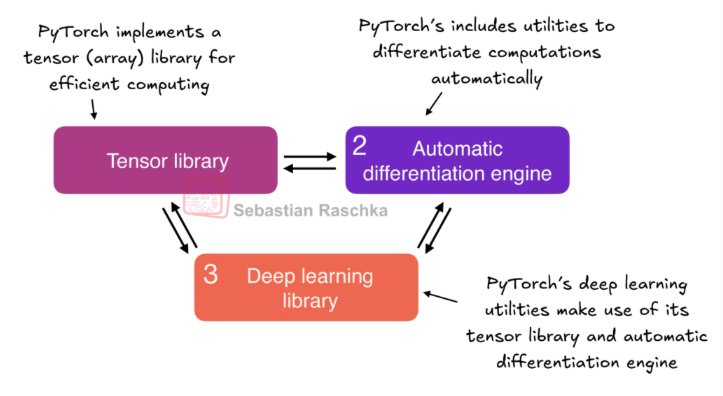
张量库(像 NumPy 一样操作张量)
NumPy 的核心设计完全基于 CPU(中央处理器),它依赖的是针对 CPU 优化的底层数学库(如 BLAS 和 LAPACK).
NumPy:NumPy 的数据存储在内存(RAM)中,计算全靠 CPU
python
import numpy as np
import time
# 1. 创建数据 (在 CPU 内存中)
# 创建一个 2000x2000 的随机矩阵
np.random.seed(42)
a_np = np.random.rand(2000, 2000)
b_np = np.random.rand(2000, 2000)
# 2. 计算 (CPU 运算)
start_time = time.time()
# 矩阵乘法
c_np = np.dot(a_np, b_np)
np_time = time.time() - start_time
print(f"NumPy (CPU) 耗时: {np_time:.4f} 秒")
print(f"数据类型: {type(c_np)}")Pytorch:PyTorch 的张量(Tensor)将从 CPU 内存"搬"到 GPU 显存中进行计算
python
import torch
# 检查是否有 GPU (NVIDIA 显卡 + CUDA 驱动)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"当前设备: {device}")
# 1. 创建数据 (默认在 CPU)
a_torch = torch.rand(2000, 2000)
b_torch = torch.rand(2000, 2000)
# 2. 将数据"搬家"到 GPU (如果在 CPU 上运行,这步无效)
a_gpu = a_torch.to(device)
b_gpu = b_torch.to(device)
# 3. 计算 (GPU 并行运算)
# 这里的 .to(device) 是关键,它把数据放进了显存
start_time = time.time()
c_gpu = torch.matmul(a_gpu, b_gpu)
torch_time = time.time() - start_time
print(f"PyTorch (GPU) 耗时: {torch_time:.4f} 秒")
print(f"数据类型: {type(c_gpu)}")可以充分利用GPU的大规模并行计算架构和超高显存带宽
自动微分引擎(让你无需手动推导和编写复杂的梯度计算公式,从而能专注于模型结构的设计)
核心功能可以概括为两个阶段:前向传播构建计算图和反向传播计算梯度
前向传播构建计算图
python
import torch
# 1. 创建需要追踪梯度的张量 (叶子节点)
x = torch.tensor(2.0, requires_grad=True)
w = torch.tensor(3.0, requires_grad=True)
b = torch.tensor(1.0, requires_grad=True)
# 2. 执行前向计算
# PyTorch 会动态构建计算图:y = w * x + b
y = w * x + b
# y 不仅包含了计算结果 7.0,还通过 grad_fn 记录了它的"身世"
print(f"y 的值: {y}") # 输出: y 的值: 7.0
print(f"y 的生成函数: {y.grad_fn}") # 输出: y 的生成函数: <AddBackward0 object at ...>反向传播计算梯度
python
# 3. 执行反向传播
# 对 y (标量) 调用 backward(),触发梯度计算
y.backward()
# 4. 查看计算出的梯度
# dy/dx = w = 3.0
print(f"Gradient of x: {x.grad}") # 输出: Gradient of x: 3.0
# dy/dw = x = 2.0
print(f"Gradient of w: {w.grad}") # 输出: Gradient of w: 2.0
# dy/db = 1 = 1.0
print(f"Gradient of b: {b.grad}") # 输出: Gradient of b: 1.0深度学习库(提供了一个完整且高度模块化的"工具箱",让你能够像搭积木一样,高效地构建、训练和部署复杂的神经网络模型。)
torch.nn 模块是构建神经网络的基石,它提供了大量预定义的"积木块",你无需从零开始编写底层数学公式。
-
网络层 (Layers):
包含了构成各种神经网络架构的核心组件。
- 全连接层 (
nn.Linear): 用于构建基础的多层感知机。 - 卷积层 (
nn.Conv2d): 计算机视觉任务的核心,用于提取图像特征。 - 循环神经网络层 (
nn.LSTM,nn.GRU): 处理文本、语音等序列数据的利器。
- 全连接层 (
-
损失函数 (Loss Functions):
用于衡量模型预测值与真实值之间的差距,指导模型优化方向。
- 均方误差 (
nn.MSELoss): 常用于回归任务。 - 交叉熵损失 (
nn.CrossEntropyLoss): 分类任务的标准配置。
- 均方误差 (
-
激活函数 (Activation Functions): 如
nn.ReLU、nn.Sigmoid等,为网络引入非线性,使其能够拟合复杂的函数。
python
import torch
import torch.nn as nn
# 1. 定义一个简单的神经网络
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
# 定义网络层
self.hidden = nn.Linear(10, 5) # 隐藏层
self.output = nn.Linear(5, 1) # 输出层
self.relu = nn.ReLU() # 激活函数
def forward(self, x):
# 定义数据流向 (前向传播)
x = self.hidden(x)
x = self.relu(x)
x = self.output(x)
return x
# 2. 实例化模型
model = SimpleNet()
print(model)随着社区和第三方库:PyTorch Geometric (PyG) 、Deep Graph Library (DGL)、TorchVision、TorchAudio等的流行,共同形成了如今PyTorch 庞大而活跃的生态系统
功能总结:
torch: 提供了最底层的张量(Tensor)计算功能,类似于 NumPy,但支持 GPU 加速和自动微分,是所有上层建筑的地基。torch.nn: 提供了模型结构(Linear)和损失函数(MSELoss)。torch.optim: 提供了优化算法(SGD),帮你自动更新参数。torch.autograd: 提供了自动微分引擎,能够自动记录计算过程并计算梯度,省去了手动推导反向传播公式的繁琐工作。torch.utils.data: 提供了数据加载工具(Dataset和DataLoader),用于高效地读取、预处理和分批输送数据,解决了大规模数据"喂"给模型的问题。
1.2 vLLM功能
vLLM 是一个用于大语言模型(LLM)的高吞吐量、内存高效的推理和服务的高性能框架。专门设计用于解决运行大模型AI模型运行所带来的速度和内存挑战

vLLM 是一个开源库,旨在实现快速、易用的大语言模型推理与服务。它利用 PagedAttention、分块预填充(chunked prefill)、多 LoRA 以及自动前缀缓存(automatic prefix caching)等创新技术,对各种数据中心硬件(NVIDIA 和 AMD GPU、Google TPU、AWS Trainium、Intel CPU)上的数百种语言模型进行了优化。它专为承载大规模生产流量而设计,提供与 OpenAI 兼容的服务器接口和离线批量推理功能,并可扩展至多节点推理。作为一个社区驱动的项目,vLLM 与基础模型实验室、硬件供应商及人工智能基础设施公司合作,共同开发前沿功能。
批处理请求:分为离线批量推理和在线 API 服务
在线 API 服务:将大模型部署为一个持续运行的网络服务器,使其能够像网站或微服务一样,实时接收并处理来自客户端的请求。
离线批量推理:通过 Python 脚本进行离线、批量的文本处理和生成任务。这种使用方式直接体现了其作为高性能推理引擎的核心功能。
python
# -*- coding: utf-8 -*-
from vllm import LLM, SamplingParams
def main():
# 1. 初始化 vLLM 推理引擎
# 这里以 Qwen2.5-7B-Instruct 模型为例,你可以替换为任何其他 Hugging Face 模型
print("正在加载模型...")
llm = LLM(
model="Qwen/Qwen2.5-7B-Instruct",
dtype="float16", # 使用 float16 精度,节省显存
gpu_memory_utilization=0.9, # 预分配 90% 的显存
trust_remote_code=True # 信任远程代码,某些模型需要
)
print("模型加载完成!")
# 2. 准备批量提示词
prompts = [
"请为我规划一份成都的三日美食旅游攻略。",
"杭州有哪些适合春季游玩的文化景点?请列出三个并简述理由。",
"介绍一下西安兵马俑的历史背景和参观建议。",
"请写一首关于大海的现代诗。",
"将"人工智能正在改变世界"这句话翻译成英文和法文。"
]
# 3. 配置采样参数
# 这些参数控制文本生成的随机性和风格
sampling_params = SamplingParams(
temperature=0.7, # 温度,值越高越有创造性
top_p=0.9, # 核采样概率
max_tokens=1024, # 生成的最大 token 数
stop=["<|im_end|>"] # 设置停止词,Qwen 模型特有
)
# 4. 执行批量推理
print(f"\n开始对 {len(prompts)} 个请求进行批量推理...")
outputs = llm.generate(prompts, sampling_params)
# 5. 打印结果
print("\n" + "="*60)
print("推理完成,结果如下:")
print("="*60)
for i, output in enumerate(outputs):
prompt_text = output.prompt
generated_text = output.outputs.text.strip()
print(f"\n【请求 {i+1}】")
print(f"输入: {prompt_text}")
print(f"输出: {generated_text}")
print("-" * 60)
if __name__ == "__main__":
main()分布式与量化部署:
当一个模型(例如 700 亿参数的 Llama-2-70B)的体积远超单张 GPU 的显存容量时,我们可以将这个庞大的模型"切分"成多个部分,然后分配到多台机器或多张显卡上协同计算。vLLM 主要通过张量并行 (Tensor Parallelism) 技术来实现这一点,它能够将模型的权重矩阵在多个 GPU 之间进行切分和并行计算,使得推理超大模型成为可能。
在启动服务时,可以通过添加 --tensor-parallel-size <GPU数量> 参数,轻松实现模型在多个 GPU 上的并行计算。例如,--tensor-parallel-size 4 可以将一个大模型拆分到 4 块 GPU 上运行,这体现了其对超大规模模型的部署能力。
同时,模型在训练时通常使用 16 位浮点数(FP16)来存储参数,精度很高但占用空间大。量化技术则是在尽量不影响模型效果的前提下,将这些参数转换为占用空间更小的格式,例如 8 位整数(INT8)甚至 4 位整数(INT4)。使显存占用大幅降低,同时推理速度也能得到显著提升。
vLLM 能够直接加载经过 GPTQ、AWQ 等格式量化的模型。这使得 7B 或 13B 级别的模型可以在单张消费级显卡(如 RTX 4090)上流畅运行,显著降低了对硬件的要求和部署成本。
python
# -*- coding: utf-8 -*-
from vllm import LLM, SamplingParams
def main():
# 1. 初始化 vLLM 推理引擎
print("正在加载量化模型...")
llm = LLM(
# 模型:指定 Hugging Face 上的量化模型
model="Qwen/Qwen3-14b-int4-awq",
# 量化:关键参数!指定量化格式为 AWQ
quantization="awq",
# 分布式:设置为 1 表示在单张 GPU 上运行
# 如果有多张 GPU,可以设置为 GPU 数量以启用张量并行
tensor_parallel_size=1,
# 显存管理:预分配 90% 的显存给模型和 KV 缓存
gpu_memory_utilization=0.9,
# 上下文长度:限制模型处理的最大 token 数
max_model_len=4096,
trust_remote_code=True
)
print("量化模型加载完成!")
# 2. 准备提示词
prompts = [
"请用简单的语言解释什么是量子计算。",
"写一首关于秋天的五言绝句。"
]
# 3. 配置采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=512
)
# 4. 执行推理
print(f"\n开始对 {len(prompts)} 个请求进行推理...")
outputs = llm.generate(prompts, sampling_params)
# 5. 打印结果
print("\n" + "="*60)
print("推理结果如下:")
print("="*60)
for i, output in enumerate(outputs):
prompt_text = output.prompt
generated_text = output.outputs.text.strip()
print(f"\n【请求 {i+1}】")
print(f"输入: {prompt_text}")
print(f"输出: {generated_text}")
print("-" * 60)
if __name__ == "__main__":
main()多模态推理 :vLLM 已经集成了对 LLaVA、Qwen-VL 等视觉语言模型的支持。开发者可以通过其 Python API 传入图像和文本的组合,模型能够进行"看图说话"或视觉问答。官方提供了 vision_language.py 等示例脚本,指导用户如何构建多模态输入并进行推理,这表明其多模态功能已经具备了可用的成熟度,不再仅仅是实验性特性。
python
# vLLM 特有的多模态输入格式
outputs = llm.generate(
{
"prompt": prompt,
"multi_modal_data": {"image": image}
},
sampling_params
)vLLM 的多模态能力还在不断扩展(即 vLLM-Omni 计划),除了图片,它还将逐渐支持:
- 视频推理:将视频拆分为多帧图像输入,模型可以理解动态过程(如"视频里的人在做什么运动?")。
- 音频理解:结合 Whisper 等模型,直接处理音频波形,实现语音问答。
二、相关原理
2.1 PyTorch原理
1、tersor张量、stroage存储与strides步长
tensor是包含若干个标量(标量可以是各种数据类型如浮点型、整形等)的n-维的数据结构。我们可以认为tensor包含了数据和元数据(metadata),元数据用来描述tensor的大小、其包含内部数据的类型、存储的位置(CPU内存或是CUDA显存?)
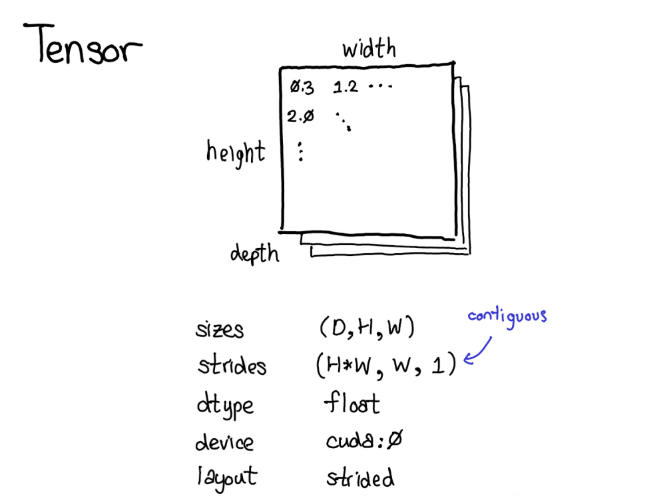
通常我们需要定义一种物理存储方式。最常见的表示方式是将Tensor中的每个元素按照次序连续的在内存中铺开(这是术语contiguous的来历),将每一行写到相应内存位置里。如下图所示,假设tensor包含的是32位的整数,因此每个整数占据一块物理内存,每个整数的地址都和上下相邻整数相差4个字节。为了记住tensor的实际维度,我们需要将tensor的维度大小记录在额外的元数据中。那么,元数据里步长在物理表示中的作用是什么呢?
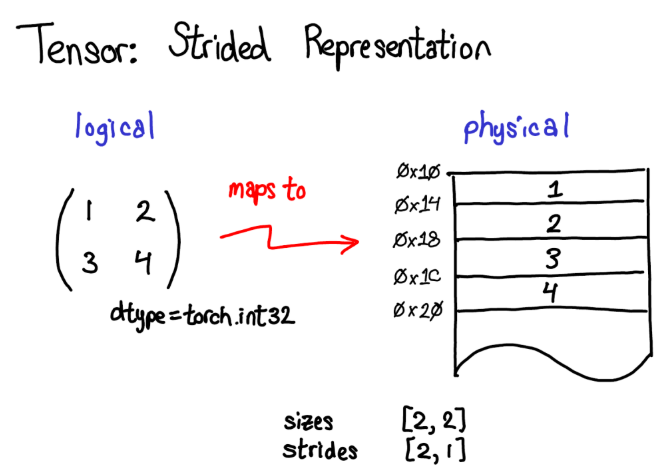
假设我想要访问位于tensor 1, 0位置处的元素,如何将这个逻辑地址转化到物理内存的地址上呢?步长就是用来解决这样的问题:当我们根据下标索引查找tensor中的任意元素时,将某维度的下标索引和对应的步长相乘,然后将所有维度乘积相加就可以了。在上图中我将第一维(行)标为蓝色,第二维(列)标为红色,因此你能够在计算中方便的观察下标和步长的对应关系。求和返回了一个0维的标量2,而内存中地址偏移量为2的位置正好储存了元素3。
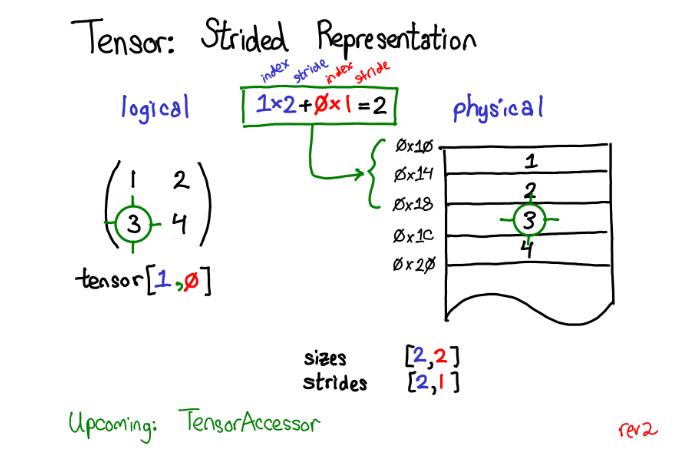
在下文会讨论TensorAccessor,一个方便的类来处理下标到地址的计算。当你使用TensorAccessor而不是原始的指针的时候,这个类能隐藏底层细节,自动帮助你完成这样的计算)步长是实现PyTorch视图(view)的根基。例如,假设我们想要提取上述tensor的第二行:使用高级索引技巧,我只需要写成tensor1, : 来获取这一行。重要的事情是:这样做没有创建一个新的tensor;相反,它只返回了原tensor底层数据的另一个视角。这意味着如果我编辑了这个视角中的数据,变化也会反应到原tensor上。在这个例子中,不难看出该视角是怎么做的:3和4存储在连续的内存中,我们所要做的是记录一个偏移量(offset),用来表示新的视图的数据开始于原tensor数据自顶向下的第二个。(每一个tensor都会记录一个偏移量offset,但是大多数时候他们都是0,我在图片中忽略了这样的例子)
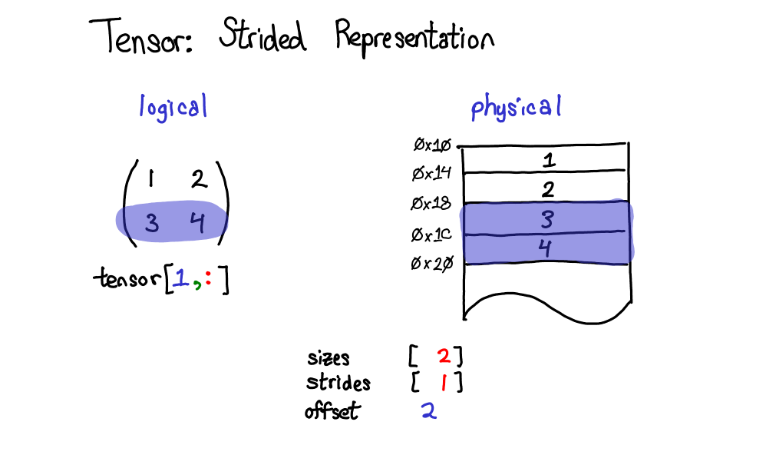
一个更有趣的例子是假设我想要拿第一列的数据:物理内存中处于第一列的元素是不连续的:每个元素之间都隔着一个元素。这里步长就有用武之地了:我们将步长指定为2,表示在当前元素和下一个你想访问的元素之间, 你需要跳跃2个元素(跳过1个元素)。步长表示法能够表示所有tensor上有趣的视图,如果你想要进行一些尝试,见下图步长可视化。
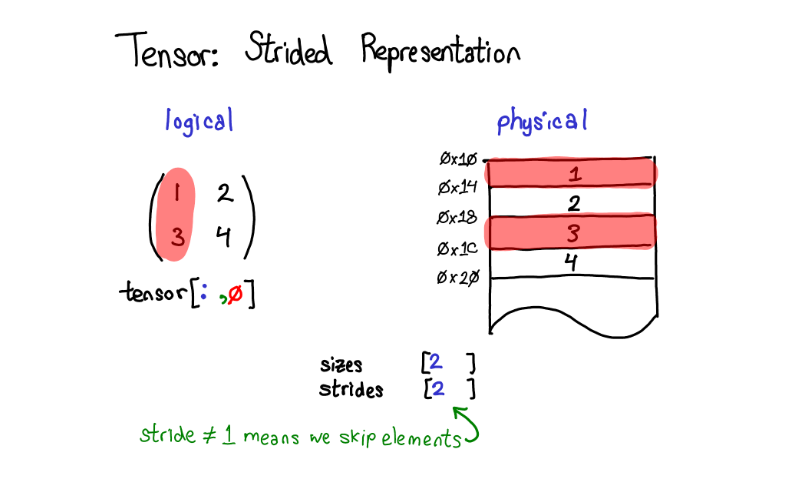
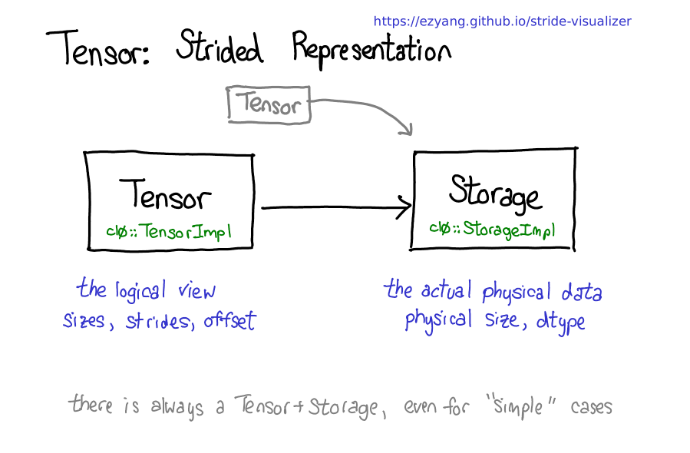
让我们退一步想想如何实现这种机制。要取得tensor上的视图,我们得对tensor的的逻辑概念和tensor底层的物理数据(称为存储 storage)进行解耦。
可以看到一个存储可能对应多个tensor。存储定义了tensor的数据类型和物理大小,而每个tensor记录了自己的大小(size),步长(stride)和偏移(offset),这些元素定义了该tensor如何对存储进行逻辑解释。值得注意的是即使对于一些不需要用到存储的"简单"的情况(例如,通过torch.zeros(2,2)分配一个内存连续的tensor),也总是存在着Tensor-Storage对。
下图中的箭头表示 Tensor 内部持有一个指向 Storage 的指针。这意味着多个不同的 Tensor 变量(例如一个矩阵和它的一个切片视图)可以共享同一块底层 Storage,只是它们的逻辑视图(尺寸、步幅)不同。即使是一个简单的标量或普通数组,在框架底层也是由这两部分组成的。
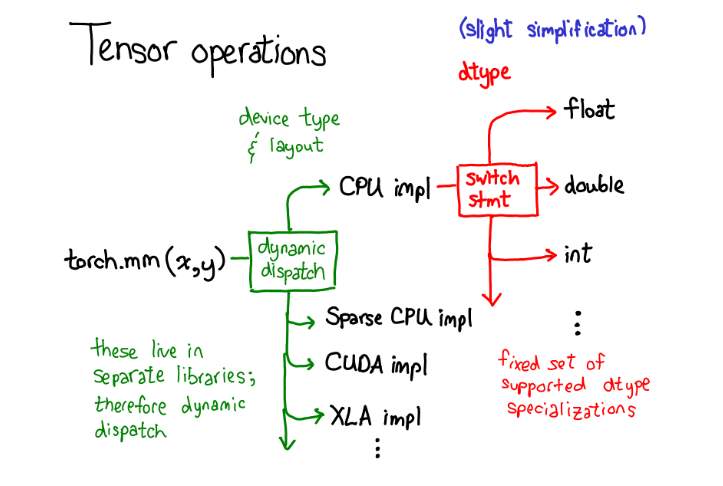
我们对于tensor的数据布局(data layout)做了相当多的讨论,(有人会说,如果你能够将数据底层表示搞清楚,剩下的一切就顺理成章了)。但是我觉得还是有必要简要的探讨一下tensor上的操作(operations)是如何实现的。抽象来说,当你调用torch.mm的时候,会产生两种分派(dispatch):
第一种分派基于设备类型(device type)和tensor的布局(layout of a tensor),例如这个tensor是CPU tensor还是CUDA tensor;或者,这个tensor是基于步长的(strided) tensor 还是稀疏tensor。这是一种动态分派的过程:使用一个虚函数调用实现(虚函数的细节将在教程的后半部分详述)。这种动态分派是必要的因为显然CPU和GPU实现矩阵乘法的方式不同。这种分派是动态的因为对应的kernels(理解为具体的实现代码)可能存在于不同的库中(e.g. libcaffe2.so 或 libcaffe2_gpu.so),如果你想要访问一个没有直接依赖的库,你就得动态的分派你的函数调用到这些库中。
第二种分派基于tensor的数据类型(dtype) 。这种依赖可以通过简单的switch语句解决。稍稍思考,这种分派也是有必要的:CPU 代码(或者GPU代码)实现float类型矩阵乘法和int类型矩阵乘法也会有差异,因此每种数据类型(dtype)都需要不同的kernels。如果你想要理解operators在PyTorch中是如何调用的,上面这张图也许最应该被记住。当讲解代码的时候我们会再回到这张图。
2、张量扩展的分类:layout布局、device设备与dtype数据类型

既然我们一直在讨论Tensor,我还想花点时间讨论下tensor扩展(extension)。毕竟,日常生活中遇到的tensor大部分都并不是稠密的浮点数tensor。很多有趣的扩展包括XLA tensors,quantized tensors,或者MKL-DNN tensors。作为一个tensor library我们需要考虑如何融合各种类型的tensors。
(PS:上图分别是Sparse tensors (稀疏张量):用于高效存储和计算包含大量零值的数据(如推荐系统、图网络)、Quantized tensors (量化张量):使用低精度整数(如 int8)代替浮点数来存储数据,以压缩模型体积并加速推理。Encrypted tensors (加密张量):用于隐私计算,允许在加密数据上直接进行计算。MKLDNN tensors:特指针对 Intel MKL-DNN(现称 oneDNN)库优化的张量格式,用于加速 CPU 上的深度学习运算。TPU tensors:针对 Google TPU 硬件优化的张量格式(通常涉及特殊的内存布局以最大化矩阵乘法单元的利用率)。Batch tensors (批量张量):可能指专门用于处理批量数据的特殊视图或结构。)
目前来说PyTorch的扩展模型提供了4种扩展方法。首先,能够唯一确定Tensor类型的"三要素"是:
- 设备类型(The device) 设备类型描述了tensor的到底存储在哪里,比如在CPU内存上还是在NVIDIA GPU显存上,在AMD GPU(hip)上还是在TPU(xla)上。不同设备的特征是它们有自己的存储分配器(allocator),不同设备的分配器不能混用。
- 内存布局(The layout) 描述了我们如何解释这些物理内存。常见的布局是基于步长的tensor(strided tensor)。稀疏tensor有不同的内存布局,通常包含一对tensors,一个用来存储索引,一个用来存储数据;MKL-DNN tensors 可能有更加不寻常的布局,比如块布局(blocked layout),这种布局难以被简单的步长(strides)表达。
- 数据类型(The dtype) 数据类型描述tensor中的每个元素如何被存储的,他们可能是浮点型或者整形,或者量子整形。
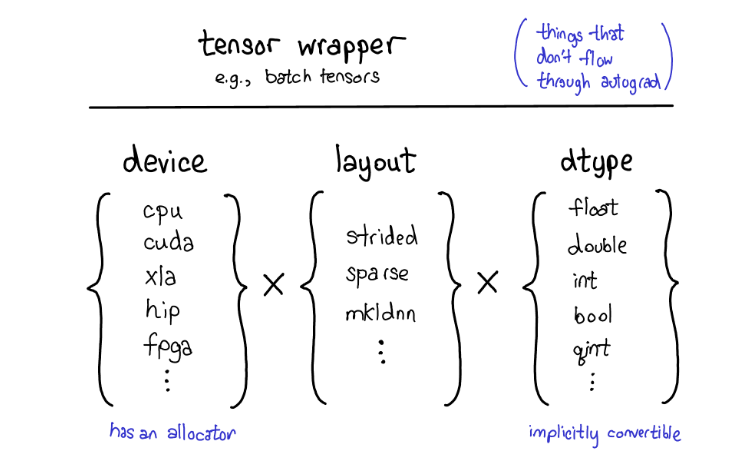
如何你想要增加一种PyTorch tensor类型,你应该想想你要扩展上面提到的哪一个决定张量类型的因素("三要素")。目前为止,并不是所有的组合都有对应的kernel(比如FPGA上稀疏量子张量的计算就没有现成的kernel),但是原则上来说大部分的组合都可能是道理的,因此至少在一定程度上我们支持它们。
还有一种方法可以用来扩展Tensor,即写一个tensor的wrapper类,实现你自己的对象类型(object type)。听起来很显然,但是很多人却在该用wrapper扩展的时候却选择了扩展上述三种要素。wrapper类扩展的一个非常好的优点是开发非常简单。什么时候我们应该写一个tensor wrapper或者扩展PyTorch tensor?一个至关重要的测试是8在反向自动求导的过程中你是否需要传递该tensor。例如通过这样的测试,我们就可以知道应该通过扩展PyTorch的方式实现稀疏tensor,而不是建立一个包含索引tensor和值tensor的Python对象(wrapper方式):因为当在一个包含Embedding的网络上做优化的时候,我们希望生成的梯度也是稀疏的。
下面是一个简单的用 Wrapper 实现自己的对象类型的例子,在这个例子中,MyComplexTensor是tensor的一个wrapper类,它包装了两个真实的 Tensor,可以快速组合现有的 Tensor 来实现复杂的数据结构(比如图神经网络中的图结构,可能包含节点特征 Tensor 和 边索引 Tensor),但是这个类Autograd 无法识别,即无法传递梯度,因为PyTorch 的自动求导引擎(Autograd)只认识原生的 torch.Tensor
python
import torch
# 这就是一个 Wrapper 类
class MyComplexTensor:
def __init__(self, real_part, imag_part):
# 包装器内部持有两个标准的 PyTorch Tensor
self.real = real_part
self.imag = imag_part
def __repr__(self):
return f"ComplexTensor({self.real} + {self.imag}j)"
# 使用 Wrapper
t1 = torch.tensor([1.0, 2.0])
t2 = torch.tensor([3.0, 4.0])
# 创建包装后的对象
my_tensor = MyComplexTensor(t1, t2)
print(my_tensor)
# 输出: ComplexTensor(tensor([1., 2.]) + tensor([3., 4.])j)我们关于tensor扩展的哲学也对tensor自身的数据布局产生着一定的影响。我们始终希望tensor结构能有个固定的布局:我们不希望一些基础的operator(这些operator经常被调用),如size of tensor需要一个虚分派 (virtual dispatches)。因此当你观察Tensor实际的布局的时候(定义在 TensorImpl 结构体中),一些被我们认为是所有类型tensor都会有的字段定义在前面,随后跟着一些strided tensors特有的字段(我们也认为它们很重要),最后才是特定类型tensor的独有字段,比如稀疏tensor的索引和值。

3、Autograd原理
上面讲述的都是tensor相关的东西,不过如果Pytorch仅仅提供了Tensor,那么它不过是numpy的一个克隆。PyTorch 发布时一个区别性的特征是提供了自动微分机制(现在我们有了其他很酷的特性包括TorchScript;但是当时,自动微分是仅有的区别点)自动微分到底做了什么呢?自动微分是训练神经网络的一种机制:

下面列出了哪些东西值得关注:
- 首先请忽略掉那些红色和蓝色的代码。PyTorch实现了reverse-mode automatic differentiation (反向模式自动微分),意味着我们通过反向遍历计算图的方式计算出梯度。注意看变量名:我们在红色代码区域的最下面计算了loss;然后,在蓝色代码区域首先我们计算了grad_loss。loss 由 next_h2计算而来,因此我们计算grad_next_h2。严格来讲,这些以grad_开头的变量其实并不是gradients;他们实际上是Jacobian矩阵左乘了一个向量,但是在PyTorch中我们就叫它们grad,大部分人都能理解其中的差异。
- 即使代码结构相同,代码的行为也是不同的:前向(forwards)的每一行被一个微分计算代替,表示对这个前向操作的求导。例如,
tanh操作符变成了tanh_backward操作符(如上图最左边的绿线所关联的两行所示)。前向和后向计算的输入和输出颠倒过来:如果前向操作生成了next_h2,那么后向操作取grad_next_h2作为输入。
概述之,自动微分做了下图所示的计算,不过实质上没有生成执行这些计算所需的代码。PyTorch 自动微分不会做代码到代码的转换工作(即使PyTorch JIT确实知道如何做符号微分(symbolic differentiation))。
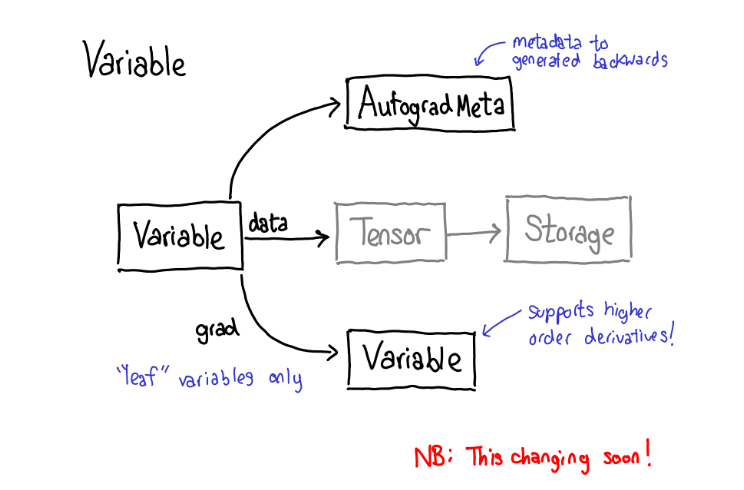
为了实现这个,当我们在tensor上调用各种operations的时候,一些元数据(metadata)也需要被记录下来。让我们调整一下tensor数据结构的示意图:现在不仅仅单单一个tensor指向storage,我们会有一个封装着这个tensor和更多信息(自动微分元信息(AutogradeMeta))的变量(variable)。这个变量所包含的信息是用户调用loss.backward()执行自动微分所必备的。顺便我们也更新下分派的图:
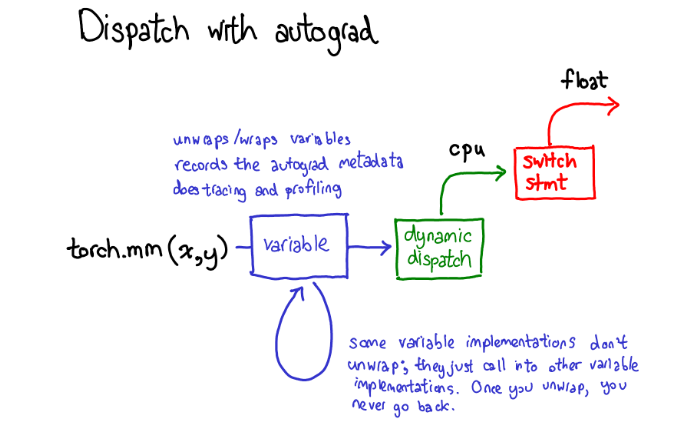
注:从 PyTorch 0.4.0 版本开始,Variable 类被废弃,Tensor 类直接继承了自动微分的功能 ,现在的 PyTorch(1.0+):torch.mm 不再需要先经过一个单独的 Variable 包装器类。Tensor 类内部直接包含了 Autograd Meta 字段。现在的流程:torch.mm -> ATen 分发 -> 具体内核。自动求导的逻辑被更紧密地集成在了 C++ 后端(Autograd Engine),而不是像图中这样在 Python/C++ 边界有一个显式的 Variable 壳。
在将计算分派到CPU或者CUDA的具体实现之前,变量也要进行分派,这个分派的目的是取出变量内部封装的分派函数的具体实现(上图中绿色部分),然后再将结果封装到变量里并且为反向计算记录下必要的自动微分元信息。当然也有其他的实现没有unwrap操作;他们仅仅调用其他的变量实现。你可能会花很多时间在变量的调用栈中跳转。然后,一旦某个变量unwrap并进入了非变量的tensor域,变量调用栈就结束了,你不会再回到变量域,除非函数调用结束并且返回。
4、源码结构
PyTorch的源码包含许多文件目录,CONTRIBUTING 文件里给这些目录做了详细的解释,不过实话说,你只需要关注4个目录:
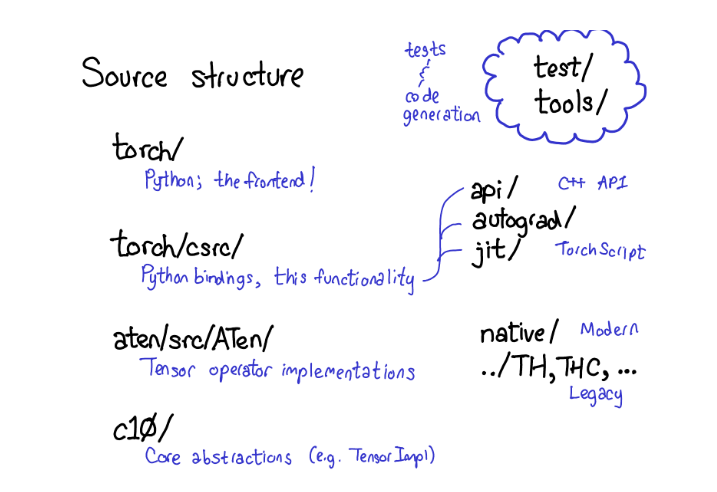
- 首先,
torch/包含了你最熟悉的部分:你在代码中引入并使用的Python 模块(modules),这里都是Python代码,容易修改起来做各种小实验,然后,暗藏在这些表层代码的下面是: torch/csrc/,这部分C++代码实现了所谓的PyTorch前端(the frontend of PyTorch)。具体来说,这一部分主要桥接了Python逻辑的C++的实现,和一些PyTorch中非常重要的部分,比如自动微分引擎(autograd engine)和JIT编译器(JIT compiler)。aten/,是"A Tensor Library"的缩写,是一个C++库实现了Tensor的各种operations。如果你需要查找一些实现kernels的代码,很大几率上他们在aten/文件夹里。ATen 内对operators的实现分成两类,一种是现代的C++实现版本,另一种是老旧的C实现版本,我们不提倡你花太多的时间在C实现的版本上。c10/,是一个来自于Caffe2 和 A"Ten"的双关语(Caffe 10),其中包含了PyTorch的核心抽象,Tensor和Storage数据结构的实际实现部分。
有如此多的地方看源码,我们也许应该精简一下目录结构,但目前就是这样。如果你做一些和operators相关的工作,你将花大部分时间在aten上。
下面我们来看看实践中这些分离的代码分别用在那些地方:

当你调用一个函数比如torch.add的时候,会发生哪些事情?如果你记得我们之前讨论过的分派机制,你的脑海中会浮现一个基本的流程:
- 我们将会从Python 代码转到 C++代码(通过解析Python调用的参数) (PyTorch 使用工具(如
cwrap或pybind11的前身)自动生成这部分代码,负责解析 Python 传入的参数,THPVariable_add 在 python_torch_functions.cpp) - 处理变量分派(VariableType到Type),顺便说一下,这里的Type和程序语言类型没有关系,只是在分派中我们这么叫它) (在旧版 PyTorch 中,支持自动求导的张量被封装在
Variable类中。调用会先路由到VariableType类,处理计算图的构建(即记录操作以便反向传播VariableType::add) - 处理 设备类型/布局 分派(Type) (这是 ATen 库中的动态分发层。根据张量的具体类型(如 CPU 浮点型、CUDA 张量等),调用会被分发到具体的实现类,TypeDefault::add 或具体类型的实现如 CPUFloatType)
- 找到实际上的kernel,可能是一个现代的函数(modern native funciton),可能是一个老旧的函数(legacy TH funciton, TH 后面会解释) 。原生函数 (Native function):这里进入了 ATen 的"原生"实现层。这一层通常包含算子的数学逻辑实现,或者是调用更底层库的胶水代码。对应代码:
at::native::add在BinaryOps.cpp中。TH 函数 (TH function):这是最底层的张量库(Torch TH 库),通常是用 C 语言编写的,负责实际的内存操作和计算。THTensor_(add)是一个宏,会根据数据类型展开为具体的函数名(如THTensor_float_add
每一个步骤具体对应到一些代码。让我们剖析这一部分代码:

上面的C++代码展示了分派具体怎样实现的,我们以一个C实现的Python function为例子 (即下面的THPVariable_add),这种实现在Python代码中我们会通过类似这样语句调用:torch._C.VariableFunctions.add.THPVariable_add。要强调的是上面这段代码是自动生成的。你不会在GitHub repository中搜索到它们,因此你必须得从源码构建PyTorch才能查看到它们。另一个重要的事实是,你不需要深入地了解这段代码干了什么;简单的扫一遍代码并且对大概的思路有个了解就足够了。如上图,我用蓝色标注了一些最重要的部分:如你所见,PythonArgParser class 用来从Python的 args和kwargs中生成C++ parser对象,然后我们调用**dispatch_add**函数(上图红色所示),它释放了Python的全局解释器锁(global interpreter lock) 然后调用一个一般方法作用到C++ tensor self上。当这个方法返回时,我们重新将Tensor封装回Python object。
从 Python 调用进入 C++ 后的具体处理步骤:
- 参数解析 :
- 使用
PythonArgParser类。 - 作用是从 Python 传入的
args(位置参数)和kwargs(关键字参数)中提取数据,并解析为 C++ 能够处理的对象。
- 使用
- 分发与计算 :
- 调用
dispatch_add函数(即图中的分发逻辑)。 - 释放 GIL:在执行具体的 C++ Tensor 运算之前,代码会释放 Python 的全局解释器锁。这允许 Python 的其他线程在当前计算进行时继续执行,避免阻塞。
- 调用
- 结果封装 :
- 当 C++ 的计算方法执行完毕并返回结果后,代码会将得到的 C++ Tensor 对象重新封装成 Python Object。
- 最终将这个 Python 对象返回给调用者。
当我们调用C++ Tensor类的add方法时候,虚分派还未发生。然而,一个内联(inline)函数会在"Type"对象上调用一个虚函数。在这个例子里,这个虚函数调用被分派到TypeDefault的类的add实现上,原因是我们提供了一个add的实现,这种实现在任何一种设备类型上(包括CPU和CUDA)都一致;假如我们对不同的设备有具体的实现,可能会调用类似于CPUFloatType::add这样的函数,意味着虚函数add最后将实际的add操作分派到的CPU上浮点数相加的具体kernel代码上。
如下图所示:
inline Tensor Tensor::add这里的 type() 返回的是一个抽象类型对象。add 是一个虚方法,不同的张量类型(子类)提供自己的实现。例如,如果这是一个 CUDA 张量,type() 就会返回 CUDAFloatType,后续调用就会跳转到 CUDA 的实现;如果是 CPU 张量,就会调用 CPUFloatType 的实现。
Tensor TypeDefault::add这是 add 算子的一个通用或默认的实现路径。当没有更特化的实现时,就会走到这里。OptionalDeviceGuard device_guard(device_of(self)); 的作用是设置当前的"活动设备"为计算设备。
Tensor add这才是真正执行加法运算的地方。TensorIterator负责处理张量运算中的通用逻辑,比如广播(broadcasting)和类型转换(type promotion),add_stub 是一个"桩函数"或"分发器"。它会根据 iter->device_type()(例如 CPU 或 CUDA)再次进行分发,最终调用针对特定设备优化的底层计算函数(这些函数通常在 .cu 或 .cpp 文件中实现,并使用了 SIMD 或 CUDA 核心)。

值得一提的是,所有的代码,直到对于具体kernel的调用,都是自动生成的。从 Python 接口到具体 Kernel 之间漫长的调用栈,包括参数解析、分发逻辑、类型检查等使用了大量的代码生成技术(Code Generation)。这些生成的代码逻辑重复、枯燥且难以阅读。所以一旦你对执行流程的大方向有一定的了解,我建议你直接跳到kernels的部分。
PyTorch为kernels编写者提供了许多实用的工具。在这一节里,我们将会简要了解他们之中的一部分。但是首先,一个kernel包含哪些东西?
5、内核及相关工具
PyTorch为kernels编写者提供了许多实用的工具。在这一节里,我们将会简要了解他们之中的一部分。但是首先,一个kernel包含哪些东西?
Error checking (错误检查) 、Output allocation (输出分配) 、Dtype dispatch (数据类型分发) 、Data access (数据访问) 、Parallelization (并行化)

我们通常上认为一个kernel包含如下部分:
- 首先,我们为kernel写了一些元数据(metadata),这些元数据驱动了代码生成,让你不用写一行代码就可以在Python中调用kernel。
- 一旦你访问了kernel,意味着你经过了设备类型/布局类型的虚函数分派流程。首先你要写的一点是错误检测(error checking),以保证输入tensors有正确的维度。(错误检测非常重要!千万别跳过它们!)
- 然后,一般我们会给输出tensor分配空间,以将结果写入进去
- 接下来是编写合适的kernel。到这里,你应该做数据类型分发(第二种分派类型dtype),以跳转到一个为特定数据类型编写的kernel上。(通常你不用太早做这个,因为可能会产生一些重复的代码,比如说一些逻辑在任何case上都适用)
- 许多高效的kernel需要一定程度上的并行,因此你需要利用多核(multi-CPU)系统。(CUDA kernels 暗含着并行的逻辑,因为它的编程模型是建立在大量的并行体系上的)
- 最后,你需要访问数据并做希望做的计算!
PyTorch提供的一些工具帮助你实现上述步骤。
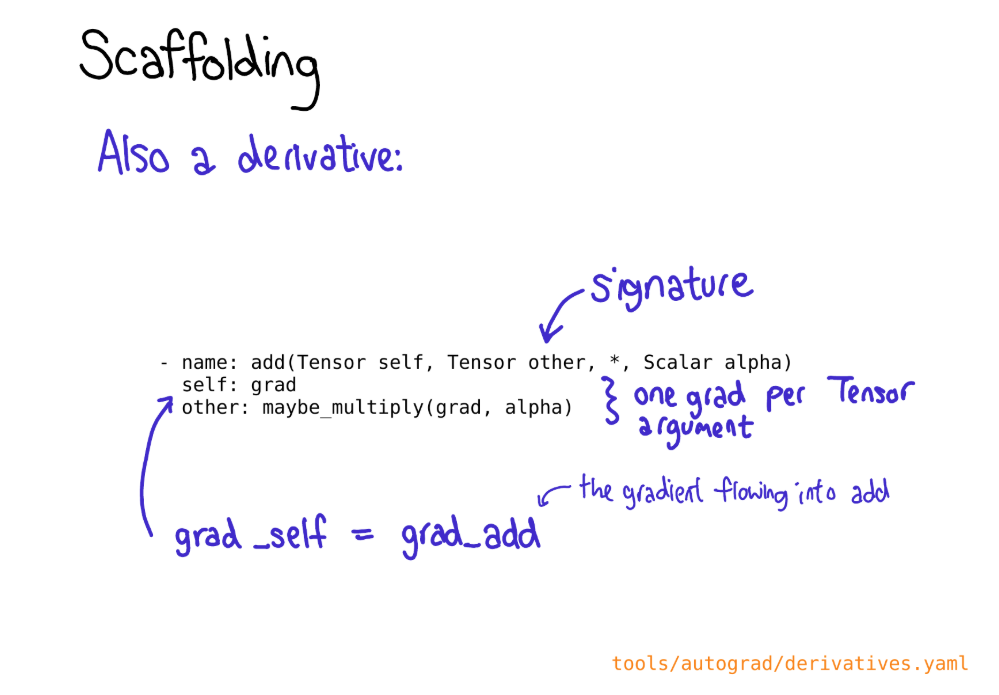
为了充分利用PyTorch带来的代码生成机制,你需要为operator写一个schema(模式)。这个schema需要给定你定义函数的签名(signature),并且控制是否我们生成Tensor方法(比如 t.add())以及命名空间函数(比如at::add())。你也需要在schema中指明当一个设备/布局的组合给定的时候,operator的哪一种实现需要被调用。具体格式细节查看README in native。
下图是add算子的yaml配置文件
其中签名 (Signature)
func: add(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor
定义了算子的函数原型(参数、返回类型)。
变体(Variants)
variants: function, method
- 这控制着 API 的暴露方式。
function:意味着你可以通过torch.add(...)这样的函数形式调用。method:意味着你可以通过tensor.add(...)这样的成员方法形式调用。
分发 (Dispatch)
定义了多态的具体实现,如果输入张量在 CPU 上,就调用 add 函数;如果在 CUDA(GPU)上,也调用 add 函数...

This schema controls our code generation(这个模式控制着我们的代码生成):基于这个 YAML 文件,PyTorch 的构建脚本会自动生成我们在前几张图中看到的:
- Python 绑定代码(让 Python 能识别参数)。
- C++ 分发函数(Dispatch Functions)。
- 头文件声明。
- 注册逻辑。
你也可能要在 derivatives.yaml 定义operation的求导操作
错误检测既能通过底层API也能通过高层API来实现。
底层API如宏(macro):TORCH_CHECK,输入一个boolean表达式,跟着一个字符串,如果根据Boolean表达式判断结果为false,这个宏就会输出字符串。这个宏比较好的地方是你能将字符串和非字符串数据混合起来输出,所有的变量都通过他们实现的<<操作符格式化,PyTorch中大多数重要的数据类型都预定义了<<操作符。
高层API 能够帮你避免写重复的错误提示。它的工作方式是首先你将每个Tensor封装进TensorArg中,TensorArg包含这个Tensor的来源信息(比如,通过它的参数名)。然后它提供了一系列封装好的函数来做各种属性的检测;比如,checkDim()用来检测是否tensor的维度是一个固定的数。如果它不是,这个函数会基于TensorArg中的元数据提供一个可读性好的错误提示。

Pytorch中编写operator的另一件值得注意的事情是,通常对一个operator,你需要编写三种版本:abs_out这个版本把输出存储在(out= 这个关键字参数中),abs_这个版本会就地修改输入,abs这个是常规版本(返回输出,输入不变)。在大多数情况下,我们实现的是abs_out版本,然后通过封装的方式实现abs和abs_,但是也有给每个函数实现一个单独版本的时候。
abs_out(复用) :这个函数不负责申请新的内存。它要求你传入一个已经存在的 result 张量作为容器。
abs(新建) :这个函数内部会调用 at::empty(...) 申请一块全新的内存。并创建了一个全新的变量来存结果,完全不影响输入 self。
abs_(覆盖) :它把输入张量 self 同时也当作输出容器传给了 _out 函数.计算结果会直接覆盖掉输入张量原本的数据。

为了做数据类型分派(dtype dispatch),你应当使用AT_DISPATCH_ALL_TYPES宏。这个宏的输入参数是Tensor的type,和一个可以分派各种的type类型的lambda表达式,通常情况下,这个lambda表达式会调用一个模板帮助函数。这个宏不仅"做分派工作",它也决定了你的kernel将会支持哪些数据类型。严格来说,这个宏有几个不同的版本,这些版本可以让你选择处理哪些特定的dtype子集。大多数情况下,你会使用AT_DISPATCH_ALL_TYPES,但是一定要留心当你只想要分派到特定类型的场景。关于在特定场景如何选择宏详见Dispatch.h


在我们需要访问数据的时候,PyTorch提供了不少选择。
- 如果你仅仅想拿到存储在特定位置的数值,你应该使用
TensorAccessor。tensor accessor类似于tensor,但是它将维度(dimensionality)和数据类型(dtype)硬编码(hard codes)成了模板参数(template parameters 译注:代码里的x.accessor<float, 3> 表示数据类型是float, 维度是3)。当你通过x.accessor<float, 3>()得到一个accessor实例,PyTorch 会做一个运行时检测(runtime test)来保证tensor确实是这样的形式(format,译注:形式指数据类型和维度),但是在那之后,每一次访问都不会再检查。Tensor accessors能够正确的处理步长(stride),因此当你做些原始指针(raw pointer)访问的时候你应当尽量用它们 (不幸的是,一些老旧的代码并没有这样)。PyTorch里还有一个PackedTensorAccessor类,被用来在CUDA加载过程中传输accessor,因此你能够在CUDA kernel 内访问accessors。(小提示:TensorAccessor默认是64-bit索引的,在CUDA中要比32-bit索引要慢很多) - 如果你编写的operator需要做一些规律性的数据访问,比如,点乘操作,强烈建议你用高层API比如
TensorIterator。这个帮助类自动帮你处理了广播(broadcasting)和类型提升(type promotion),非常方便。(译注:广播和类型提升可以参考numpy相关的描述) - 为了在CPU上执行得尽量快,也许你需要使用向量化的CPU指令(vectorized CPU instructions)来编写kernel。我们也提供了工具!
Vec256类表示一个向量,并提供了一系列的方法以对其向量化的操作(vectorized operations)。帮助函数比如binary_kernel_vec让你更加容易得运行向量化的操作,以处理原始的CPU指令不容易处理的向量化的场景。同时,这个类还负责针对不同的指令集编译不同的kernel,然后在运行时对你CPU所支持的指令集做测试,以使用最合适的kernel。

PyTorch 中的许多kernel仍然由古老的TH类型的代码实现(顺便说一下,TH代表TorcH。缩写固然很好,但是太常见了,如果你看到了TH,就把它当做老旧的就好了)。下面详细解释下什么是老旧的TH类型:
- 它由C代码编写,没有(或者极少)用到C++
- 它是由手动引用计数的(当不再使用某个tensor的时候,通过手工调用
THTensor_free方法来减少引用计数) - 它存在于
generic/文件夹中,意味着我们需要通过定义不同的#define scalar_t来多次编译。
这些代码是很"疯狂"的,我们也不愿意维护它们,所以请不要再向里面添加东西了。你可以做的更有意义的事情是,如果你喜欢编程但是不熟悉关于kernel的编写,你可以尝试着移植这些TH函数到ATen里面去。

作为总结,我想要讨论一些关于高效扩展PyTorch的技巧。如果说庞大的PyTorch C++代码库是第一道阻止很多人贡献代码到PyTorch的门槛,那么工作效率就是第二道门槛。如果你试着用写Python的习惯编写C++代码,你将会花费大量的时间,因为重新编译PyTorch太耗时了,你需要无尽的时间来验证你的改动是否奏效。如何高效的改动PyTorch可能需要另一场专门的talk,但是这个PPT总结了一些常见的"误区":

- 如果你编辑了一个头文件,尤其是那种包含许多源文件(尤其是包含了CUDA文件),那么你可能会需要一个非常长时间的重新编译。为了避免这个,尽量保持只修改cpp文件,尽量少修改头文件!
- 我们的CI(指一个pytorch官方云端的已配置好的环境)是一个非常好的,不需要任何配置的环境来测试你的修改是否会奏效。但是在你得到结果之前估计需要1到2小时。如果你的修改需要大量的实验验证,把时间花在设置一个本地开发环境上吧。同样,如果你遇到了一个特别难以debug的问题,在本地环境中测试它。你可以下载并且使用我们的Docker镜像 download and run the Docker images locally
- 如何贡献的文档详述了如何设置
ccache,我们强烈推荐这个,因为很多情况下它会在你修改头文件时帮助你节省重新编译的时间。它也能帮助你避免一些我们编译系统的bugs,比如重新编译了一些不该重新编译的文件。 - 我们有大量的C++代码,推荐你在一个有着充足CPU和RAM资源的服务器上编译。强烈不建议你用自己的笔记本编译CUDA,编译CUDA是特特特特别慢的,笔记本不具备快速编译的能力。
2.2 vLLM原理
1、前言:KV Cache的来源
LLM中, 生成文本是自回归的,即生成第 N个词时,需要依赖前面 1到 N−1个词的信息。
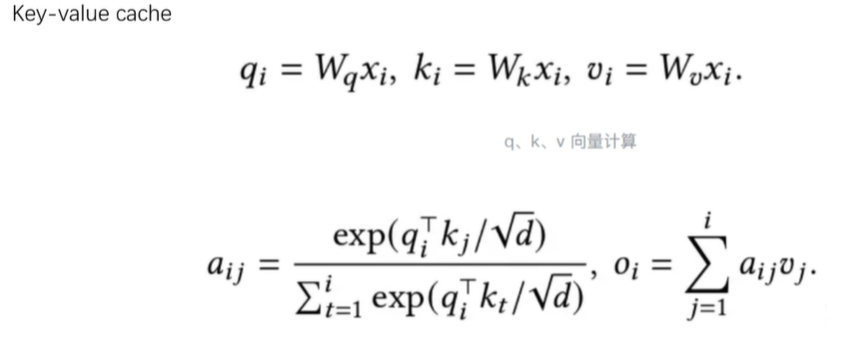
而在 Transformer 的注意力机制(Attention)中,每个词都会被转化为三个向量:
- Query (Q):查询向量(我想找什么信息?)
- Key (K):键向量(我包含什么信息标签?)
- Value (V):值向量(我具体的内容是什么?)
随着句子变长,大量的计算资源被浪费在重复计算已经处理过的词的 K 和 V 向量上 。计算复杂度会随着序列长度呈平方级 O(N2)O (N 2) 增长,导致生成速度极慢。
KV Cache 提出思想非常直观:既然前面词的 K 和 V 向量不会改变,那为什么不把它们存起来呢?
- 预填充阶段 (Prefill):处理输入提示词(Prompt)时,一次性计算所有词的 K 和 V,并存入显存(即 KV Cache)。
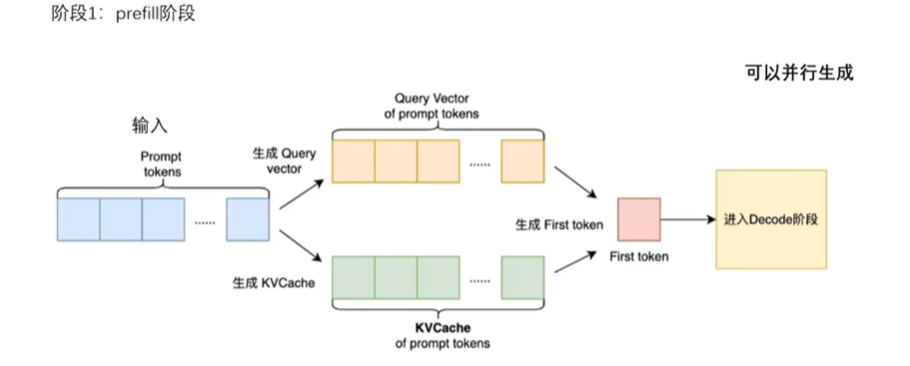
- 解码阶段 (Decode) :生成新词时,直接从显存中读取之前所有词的 K 和 V,只计算当前新词的 K 和 V。
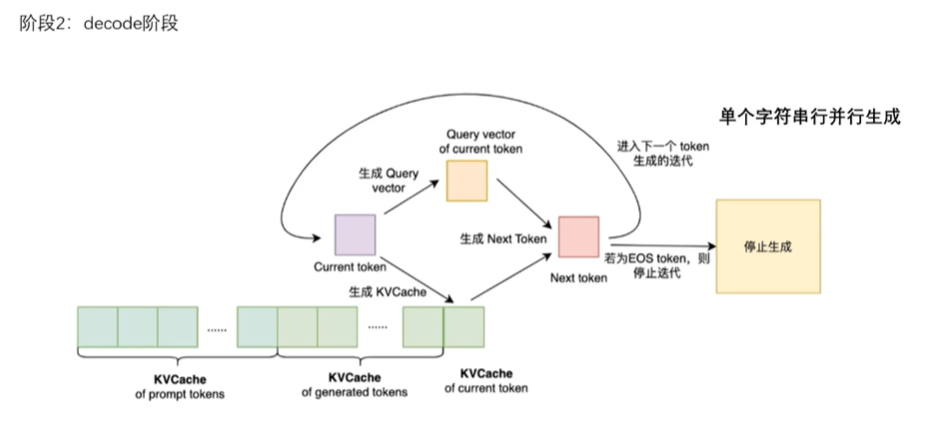
这样,每一步的计算复杂度就从 O(N2)O (N 2) 降低到了 O(1)O(1) ,推理速度大幅提升。
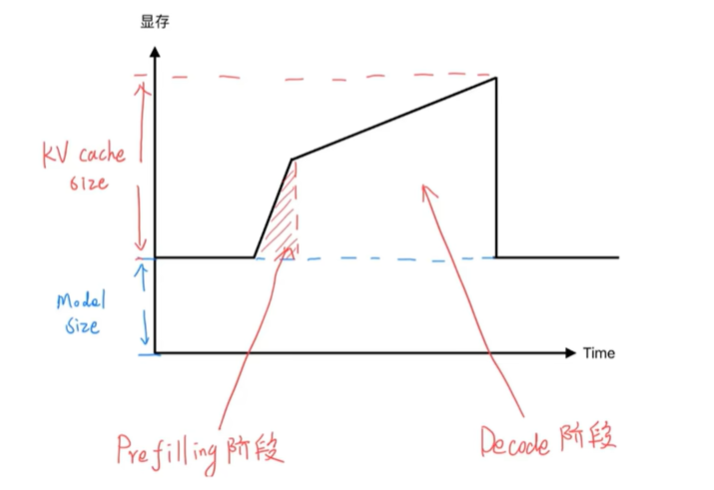
虽然 KV Cache 极大地提升了速度,但它也带来了新的问题:显存占用巨大。在Prefille阶段,模型可以按照输入prompt的token数申请所需的显存空间,但在Decoder阶段,模型无法预测生成文本的最终长度,但又要保证生成时KVCache在显存中的连续性,因此会提前开辟足够大的显存空间(甚至会按照单次请求对应的最大长度),这就造成了大量的显存空间浪费。
2、vLLM解决方案与原理:
1、 PagedAttention策略
使用 PagedAttention 高效管理 Attention Key 和 Value 内存,这是一种受操作系统中虚拟内存和分页经典思想启发的注意力算法。与传统的注意力算法不同,PagedAttention 允许在非连续的内存空间中存储连续的键和值。具体而言,PagedAttention 将每个序列的 KV 缓存划分为块,每个块包含固定数量 token 的键和值。在注意力计算期间,PagedAttention 内核可以高效地识别并获取这些块。

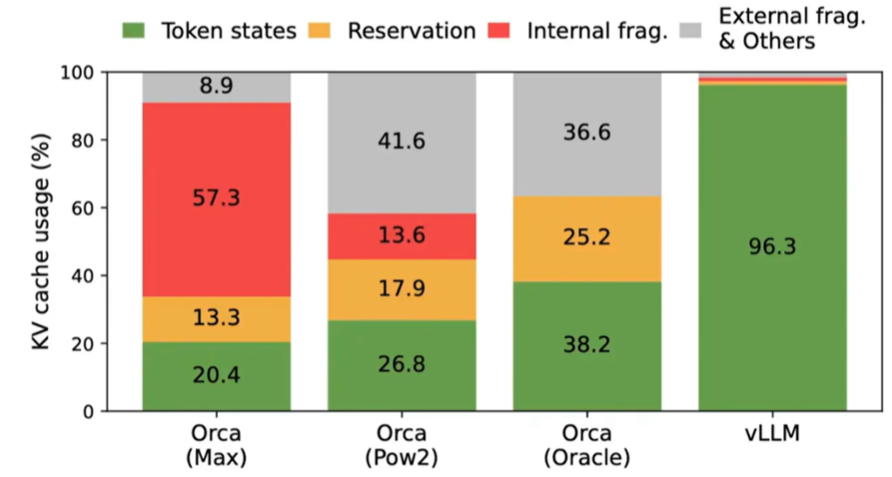
由于块不需要在内存中连续,我们可以像操作系统中的虚拟内存一样以更灵活的方式管理键和值:可以将块视为页面,token 视为字节,序列视为进程。序列的连续 逻辑块 通过块表映射到非连续的 物理块。物理块随着新 token 的生成按需分配。
在 PagedAttention 中,内存浪费仅发生在序列的最后一个块中。在实践中,这实现了近乎最优的内存利用率,浪费率不足 4%。这种内存效率的提升非常有益:它允许系统将更多序列组合在一起,提高 GPU 利用率,从而如上述性能结果所示,显著提高吞吐量。
同时提高了KVCache的复用性:在并行采样中,同一个提示词 (prompt) 会生成多个输出序列。在这种情况下,提示词的计算和内存可以在输出序列之间共享。
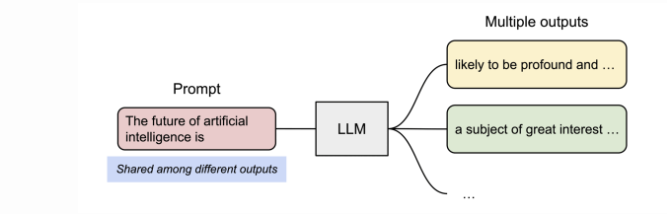
此时只用在回答分叉的时候开辟新的block就可以存储新的KVCache继续处理生成,而前面相同的KVCache可以进行block的共享,共享的部分只用存储一份,这个技术也叫做前缀缓存,可以避免了重新计算多个提示词在开头共享的token
如果没有前缀缓存,每次处理一个新的请求时,我们都会重新计算前面的所有token。
使用前缀缓存时,这些token只计算一次(其 KV 存储在 KV 缓存分页内存中),然后重复使用,因此只需处理新的提示token。这加快了预填充请求的速度(虽然对解码没什么帮助)。
2、Batching策略
静态的Batching(也叫Static Batching ) 是一种传统的大模型推理调度策略,其核心特点是:一旦构建了一个 batch,其中的所有请求将统一执行,直到全部完成后才释放资源并加入新的请求。这意味着由于批次中不同序列的生成长度与该批次最大生成长度不同,GPU的利用率较低。
下图展示了使用 Static Batching 完成 4 个推理请求的过程。在第一轮(图左),每个请求根据提示词(黄色)生成一个 token(蓝色)。经过多轮迭代后(图右),每个请求的生成长度不同,因为它们在不同轮次生成了结束标记(红色)。尽管请求 3 在第二轮就已完成,Static Batching 仍要求整个 batch 等待最慢的请求完成(此例中为第六轮的请求 2),这导致 GPU 在后续迭代中无法被充分利用。
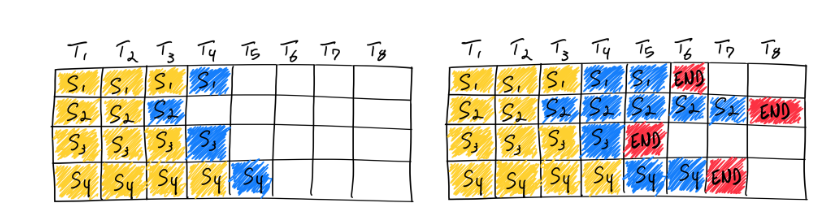
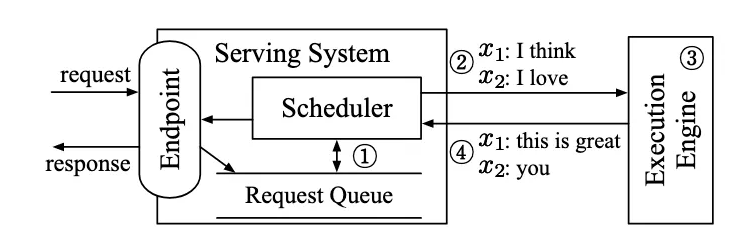
这是因为Static Batching 采用的是固定的调度流程:调度器(Scheduler)每次从请求队列中取出一组请求(例如图中的 x1 和 x2),组成一个新的 batch,并交由执行引擎(Execution Engine)统一进行推理。只有当执行引擎完成该 batch 中所有请求的推理后,调度器才会开始处理下一轮 batch。由于 batch 中的所有请求必须一起行动,我们管这种调度策略叫 request-level schedule。
以下是 Static Batching 的伪代码实现:

意识到传统方法存在效率低下的问题,vLLM引入动态批处理技术(Continuous Batching ),不再等到批次中每个序列都完成生成后再进行,而是每轮迭代动态决定 batch 大小。这样一来,batch 中的某个序列一旦完成生成,就可以立即被替换为新的请求,从而相比 Static Batching 显著提升了 GPU 的利用率。
下图展示了使用 Continuous Batching 完成 7 个推理请求的过程。左图展示的是第一轮迭代后的 batch,右图展示的是多轮迭代后的情况。一旦某个请求生成了结束标记(EOS token),就将其替换为一个新的请求(例如 S5、S6 和 S7)。这种方式避免了等待所有请求完成后再处理新请求的情况,因此能显著提升 GPU 的利用率。
下展示了 ORCA 采用迭代级调度(iteration-level scheduling)时的系统架构与整体工作流程:
- ① 调度器首先决定下一步要运行哪些请求。
- ② 然后调用引擎对四个选中的请求(x₁, x₂, x₃, x₄)进行推理。对于首次被调度的请求,调度器会提供其输入 token 给引擎处理。本例中,x₃ 和 x₄ 尚未进行过任何迭代,因此调度器为 x₃ 提供了 (x₃₁, x₃₂),为 x₄ 提供了 (x₄₁, x₄₂, x₄₃)。
- ③ 接着,引擎对这四个请求执行了一轮模型推理。
- ④ 并返回每个请求生成的一个输出 token(x₁₅, x₂₃, x₃₃, x₄₄)。
一旦某个请求完成推理,请求池会移除该请求,并通知终端返回响应。
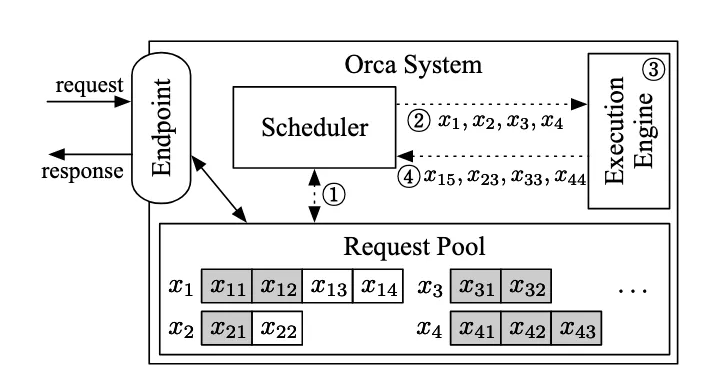
3、vLLM工程原理
引擎的主要组件包括:
- vLLM 配置(vLLM config)(包含用于配置模型、缓存、并行度等的所有旋钮)
- 处理器(processor)(通过验证、分词和处理,将原始输入 → EngineCoreRequests)
- 引擎核心客户端(engine core client)(在我们的运行示例中,我们使用 InprocClient,它基本上等同于 EngineCore;我们将逐步构建到支持大规模服务的 DPLBAsyncMPClient)
- 输出处理器(output processor)(将原始的 EngineCoreOutputs → 用户看到的 RequestOutput)
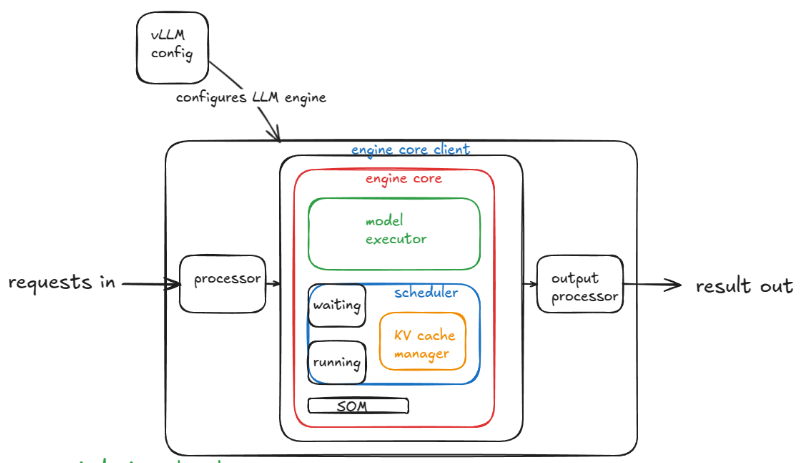
其中在引擎核心中由几个子组件组成:
- 模型执行器(Model Executor)(驱动模型的前向传播,我们目前处理的是 UniProcExecutor,它在单个 GPU 上有一个单一的 Worker 进程)。我们将逐步构建到支持多 GPU 的 MultiProcExecutor。
- 结构化输出管理器(Structured Output Manager)(用于引导式解码------我们稍后会讨论这个)。
- 调度器(Scheduler)(决定哪些请求进入下一个引擎步进)------它进一步包含:
- 策略设置------可以是 FCFS(先来先服务)或 priority(高优先级请求优先服务)。
- 等待(waiting)和运行(running)队列。
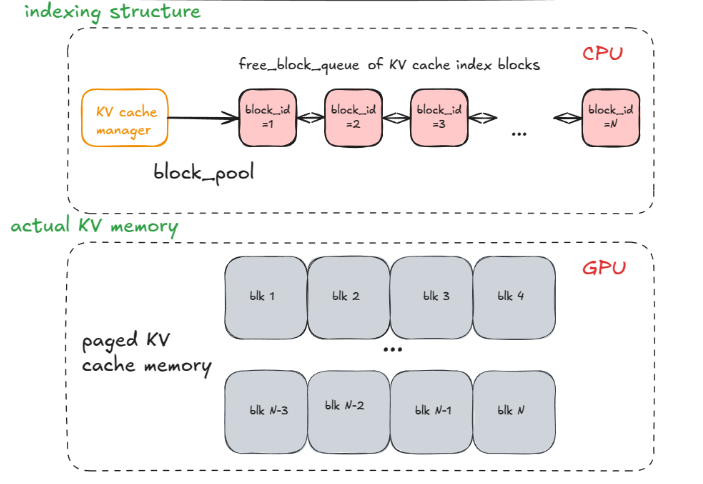
- KV 缓存管理器(KV cache manager)------分页注意力(PagedAttention)的核心 。
KV 缓存管理器维护一个 free_block_queue------这是一个可用 KV 缓存块的池(通常在数十万个量级,取决于 VRAM 大小和块大小)。在分页注意力期间,这些块充当索引结构,将token(tokens)映射到它们计算出的 KV 缓存块。
步骤一:初始化引擎
在模型执行器构建过程中,会创建一个对象,并执行三个关键过程。
- 启动设备:
- 将一个CUDA设备(例如"cuda:0")分配给工作者,并检查模型dtype是否被支持(例如bf16)
- 确认有足够的显存,且根据要求(例如占总显存的80%→0.8)
gpu_memory_utilization - 设置分布式设置(DP / TP / PP / EP 等)
- 实例化a(存储采样器、KV缓存和前向缓冲区,如、、等)
model_runner``input_ids``positions - 实例化一个对象(存储CPU端的前向缓冲区、用于KV缓存索引的块表、采样元数据等)
InputBatch
- 负载模型:
- 实例化模型架构
- 加载模型权重
- 调用 model.eval()(PyTorch 的推理模式)
- 可选:在模型上调用 torch.compile()
- 初始化KV缓存
- 获取每层的KV缓存规范。历史上这一直是(均质变换器),但随着混合模型(滑动窗口、像Jamba这样的变压器/SSM)变得更复杂
- 运行一个虚拟/分析前向扫描,并对GPU内存进行快照,计算可用显存中能容纳多少KV缓存块
- 分配、重塑并绑定KV缓存张量到注意力层
- 准备注意力元数据(例如将后端设置为FlashAttention),这些元数据在前向传递过程中被内核调用
- 除非提供,否则对每个预热批处理大小都做一次虚拟运行并捕获CUDA图。CUDA图会将GPU工作的完整序列记录到DAG中。在前驱传递过程中,我们会启动/重放预烘焙的图,减少内核启动开销,从而提高延迟。
--enforce-eager
我在这里抽象了许多低层次细节------但这些是我现在要介绍的核心部分,因为我将在后续章节反复引用它们。
现在引擎已初始化,接下来进入生成函数。
第二步:验证请求并输入引擎
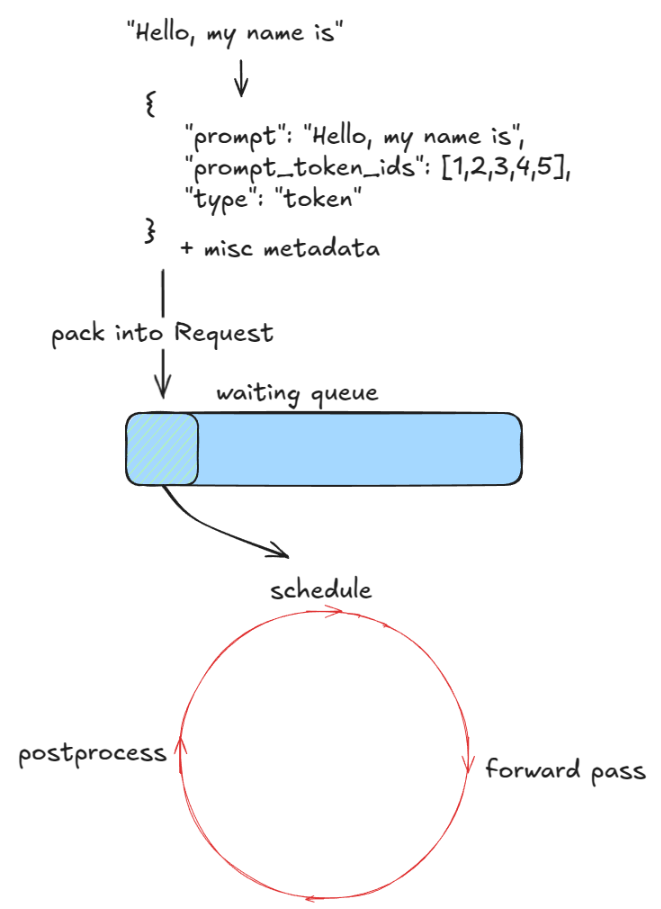
对于每个提示,我们:
- 创建一个唯一的请求ID,并记录其到达时间
- 调用一个输入预处理器,对提示词进行分词,返回包含 、 、 和 (文本、token、嵌入等)的字典
prompt``prompt_token_ids``type - 将这些信息打包到一个添加优先级、采样参数和其他元数据中
EngineCoreRequest - 将请求传递到引擎核心,核心将其包裹在对象中并设置状态为 。该请求随后被添加到调度队列中(如果是 FCFS 则添加,优先级则是堆推送)
Request``WAITING``waiting
接下来,只要有处理请求,引擎就会反复调用其函数。每个步骤包含三个阶段:step()
- 调度:选择在这一步中执行的请求(解码和/或(分块)预填充)
- 前向传递:运行模型和样本token
- 后处理:在每个标记上附加采样tokenID,去token化,并检查停止条件。如果请求已完成,清理(例如将其KV缓存块返回到),并提前返回输出
第三步:调度器决策
推理引擎主要处理两种类型的工作负载:
- 推理引擎处理的工作负载主要有两种类型:
- 预填充(Prefill)请求 ------ 对所有提示词token进行一次前向传播。这些通常是计算受限型(compute-bound)(阈值取决于硬件和提示词长度)。最后,我们从最后一个token位置的概率分布中采样出一个token。
- 解码(Decode)请求 ------ 仅对最近的一个token进行一次前向传播。之前所有的 KV 向量都已被缓存。这些是内存带宽受限型(memory-bandwidth-bound),因为我们仍需加载所有 LLM 权重(和 KV 缓存)仅为了计算一个token。
调度器优先处理解码请求 ------ 即那些已经在**运行(running)**队列中的请求。对于每个此类请求,它会:
- 计算要生成的新token数量(由于投机采样和异步调度,并不总是 1 )。
- 调用 KV 缓存管理器的 allocate_slots 函数(详见下文)。
- 通过减去第 1 步中的token数量来更新token预算。
在此之后,它处理来自等待(waiting)队列的预填充请求,它会:
- 检索已计算块的数量(如果禁用前缀缓存则返回 0 ------ 我们稍后会介绍)。
- 调用 KV 缓存管理器的 allocate_slots 函数。
- 从等待队列中弹出请求并将其移动到运行队列,将其状态设置为 RUNNING。
- 更新token预算。
现在让我们看看 allocate_slots 做了什么,它会:
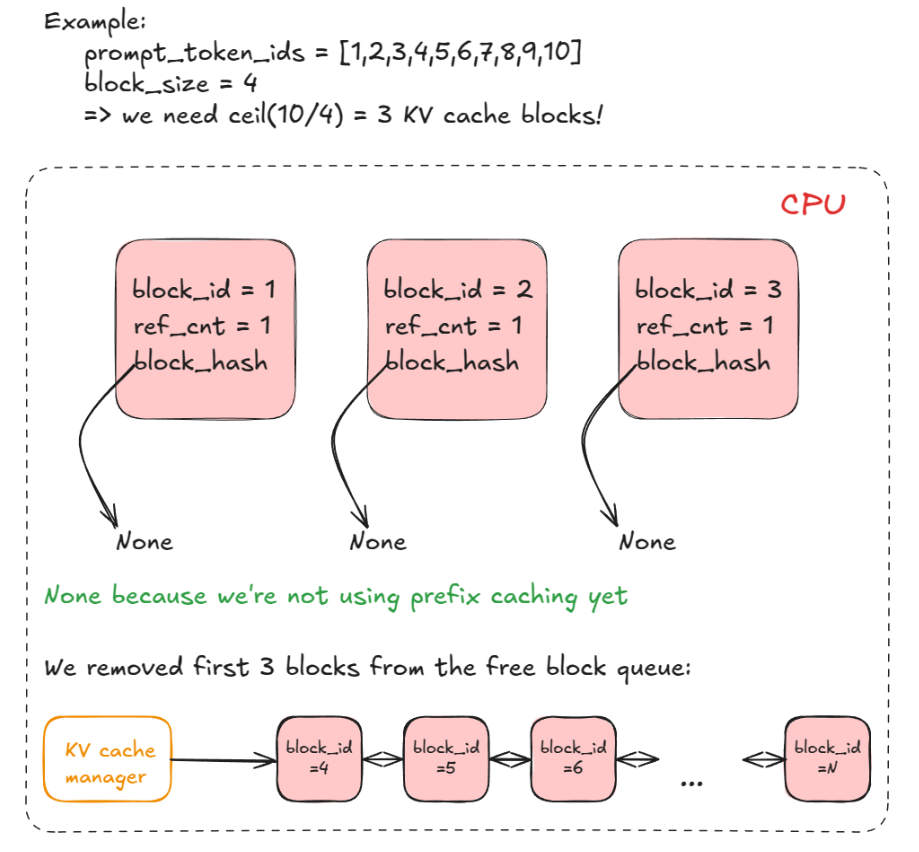
- 计算块数量 ------ 确定必须分配多少个新的 KV 缓存块 (n)。默认情况下,每个块存储 16 个token。例如,如果一个预填充请求有 17 个新token,我们需要ceil(17⁄16) = 2个块。
- 检查可用性 ------ 如果管理器池中没有足够的块,则提前退出。根据是解码还是预填充请求,引擎可能会尝试通过驱逐低优先级请求来进行重计算抢占(recompute preemption)(V0 支持交换抢占),即调用 kv_cache_manager.free 将 KV 块归还至块池;或者它可能会跳过调度并继续执行。
- 分配块 ------ 通过 KV 缓存管理器的协调器,从块池(前面提到的 free_block_queue 双向链表)中获取前 n个块。存储到 req_to_blocks 中,该字典将每个 request_id 映射到其 KV 缓存块列表。
如下图所示,假设有一个请求其 Prompt 被分词后包含 10 个 Token ID([1, 2, ..., 10]),系统设定的每个内存块容量为 4 个 Token(block_size = 4)系统需要计算存储这 10 个 Token 需要多少个块,这个计算发生在CPU侧,由CPU 维护逻辑上的块表(包含元数据),而实际的物理显存块从全局空闲池中分配。
步骤四:前向传播与计算 (Forward Pass)
我们调用模型执行器的 execute_model,它委托给 Worker,而 Worker 又进一步委托给模型运行器(model runner)。
以下是主要步骤:
- 更新状态 ------ 从 input_batch 中剪除已完成的请求;更新与前向传播相关的各类元数据(例如,每个请求对应的 KV 缓存块,这些块将用于索引分页 KV 缓存内存)。
- 准备输入 ------ 将缓冲区从 CPU 复制到 GPU;计算位置信息;构建 slot_mapping(详见后续示例);构建注意力元数据。
- 前向传播 ------ 使用自定义的分页注意力内核运行模型。所有序列被展平并拼接成一个长的"超级序列"。位置索引和注意力掩码确保每个序列仅关注自身的token,从而在无需右填充(right-padding)的情况下实现连续批处理。
- 收集最后token状态 ------ 提取每个序列最后位置的隐藏状态并计算逻辑值(logits)。
- 采样 ------ 根据采样配置(贪婪采样、温度采样、top-p、top-k 等)从计算出的逻辑值中采样token。
前向传播步骤本身有两种执行模式:
- 急切模式(Eager mode) ------ 当启用急切执行时,运行标准的 PyTorch 前向传播。
- "捕获"模式("Captured" mode) ------ 当未强制使用急切模式时,执行/回放预先捕获的 CUDA 图(记得我们在引擎构建期间的"初始化 KV 缓存"过程中捕获了这些图)。
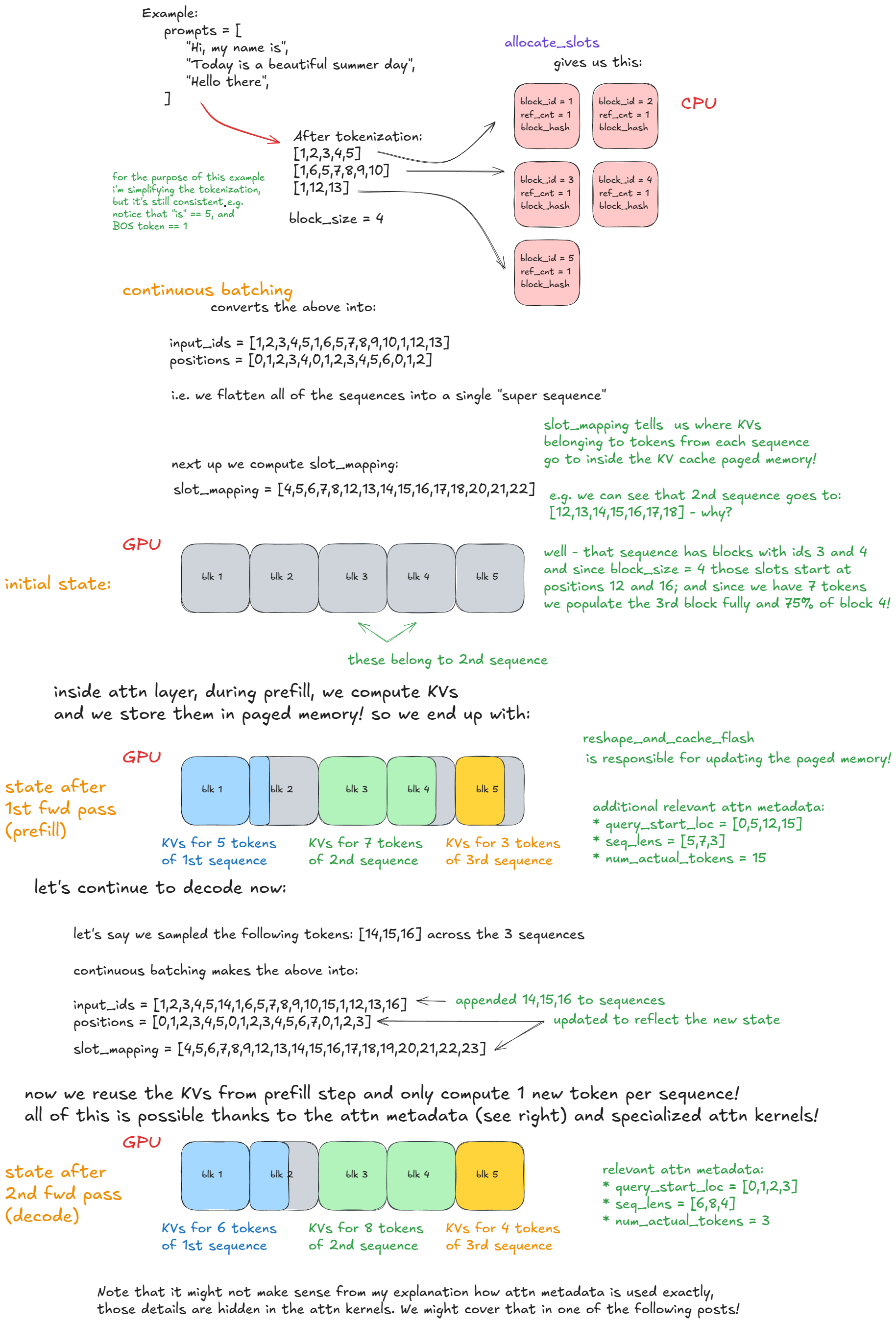
这里有一个具体示例,清晰解释了上文说到的的连续批处理和分页注意力原理的应用:
步骤五:后处理与状态更新 (Post-processing)
计算完成后,引擎更新状态以准备下一步。
- 结果附加:将采样得到的新 Token ID 附加到对应请求的序列中。
- 停止条件检查:
- 是否生成了结束符(EOS)?
- 是否超过了最大长度限制?
- 是否匹配了特定的停止字符串?
- 清理与回收:
- 如果请求完成,将其从
running队列移除,并将其占用的 KV 缓存块(Blocks)返还给free_block_queue,供新请求使用。 - 如果未完成,更新请求状态,等待下一次调度。
- 如果请求完成,将其从
步骤六:输出与流式传输 (Output)
- 去 Token 化:将 Token ID 转换回人类可读的文本。
- 返回结果:在同步模式下直接返回;在异步/流式模式(Streaming)下,将中间 Token 实时推送给客户端。
三、能力边界
3. 1 PyTorch能力边界
1、系统性瓶颈定位
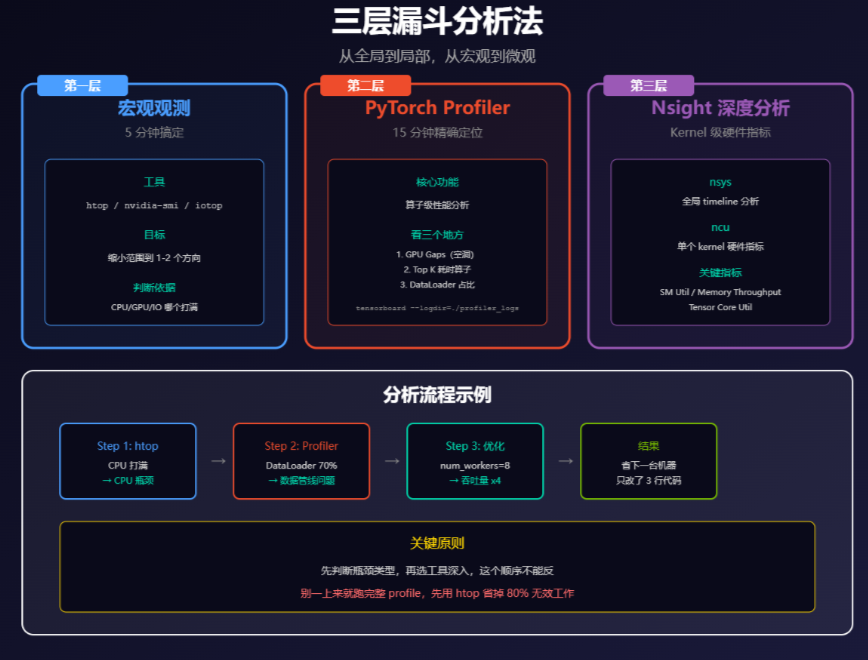
第一层:系统工具先扫一遍
上 profiler 之前,先用系统工具看一眼。这一步花不了几分钟,但能帮你排除掉大部分方向性的误判。
watch -n 1 nvidia-smi
htop
sudo iotopGPU 满载且显存快撑爆了,进入第二层深挖计算效率。GPU 空闲但 CPU 满的,问题在数据管线,重点看 DataLoader。磁盘读写高的,考虑换 SSD 或者把数据预加载到内存。多卡不均衡的,看通信和负载分配。
第二层:torch.profiler
方向确定了,就该上 torch.profiler 了。这东西能精确定位到算子级别,哪个操作吃了多少时间、占了多少内存,一目了然。
PyTorch Profiler --- PyTorch Tutorials 2.11.0+cu130 文档 - PyTorch 文档
python
import torch
from torch.profiler import profile, schedule, ProfilerActivity
with profile(
activities=[
ProfilerActivity.CPU,
ProfilerActivity.CUDA,
],
schedule=schedule(
wait=2, # 前 2 步不记录(跳过 warmup)
warmup=2, # 接下来 2 步 warmup
active=6, # 正式记录 6 步
repeat=1
),
record_shapes=True, # 记录 tensor 形状
profile_memory=True, # 记录内存分配
with_stack=False, # 一般不需要,只在需要定位 Python 调用栈时开
on_trace_ready=torch.profiler.tensorboard_trace_handler("./profiler_logs")
) as prof:
for step, batch in enumerate(train_loader):
train_step(model, batch, optimizer)
prof.step() # 每步推进 profiler跑完用 TensorBoard 看 trace:
bash
tensorboard --logdir=./profiler_logs跑完之后看 trace,主要盯几个地方。
在 Chrome Trace Viewer 里看 GPU Gaps,也就是 GPU 空洞。CUDA stream 上如果出现大段空白,说明 GPU 在等。等什么呢?往上翻 CPU 那条 timeline,空白对应的位置 CPU 在干啥,答案基本就在那儿。
然后看 Top K 耗时算子。按 self_cuda_time_total 排序,排在前面的 Attention、matmul、layernorm 都正常。但如果你发现 aten::copy_、aten::to 跑到了前面,那就是数据传输在吃时间,GPU 大量功夫花在搬数据上了。
还有个容易忽略的点,用 torch.profiler.record_function 手动标记一下关键阶段,看看 DataLoader 到底占了多少时间:
python
with torch.profiler.record_function("data_loading"):
batch = next(iter(loader))
with torch.profiler.record_function("forward"):
output = model(batch)
with torch.profiler.record_function("backward"):
loss.backward()
with torch.profiler.record_function("optimizer_step"):
optimizer.step()data_loading 的时间占比要是超过 forward 加 backward 的一半,那瓶颈就在数据管线,不在模型本身。
第三层:Nsight
瓶颈确定在 GPU 计算效率上,需要看 kernel 级别的硬件指标了,才轮到 Nsight 出场。Nsight Systems(nsys)看全局 timeline,Nsight Compute(ncu)看单个 kernel 的硬件指标。两个工具各管一层,别搞混了。
先用 nsys 收集全局 trace:
bash
nsys profile \
--trace=cuda,nvtx,osrt,cudnn,cublas \
--capture-range=cudaProfilerApi \
--stop-on-range-end=true \
--cudabacktrace=true \
-o ./nsys_report \
python train.py有个事得提醒一下:一定要用 NVTX 标记你的代码阶段,否则 nsys 的 trace 里全是看不懂的 kernel 名字,跟看天书一样。
python
import torch.cuda.nvtx as nvtx
for batch in loader:
nvtx.range_push("forward")
output = model(batch)
nvtx.range_pop()
nvtx.range_push("backward")
loss = criterion(output, target)
loss.backward()
nvtx.range_pop()
nvtx.range_push("optimizer")
optimizer.step()
optimizer.zero_grad()
nvtx.range_pop()加了 NVTX 之后,nsys 的 timeline 上会清晰标注出 forward、backward、optimizer 三个区域,一眼就能看出哪个阶段 GPU 空闲、哪个阶段通信密集。
nsys 帮你找到最耗时的 kernel 之后,再用 ncu 深入分析:
bash
ncu --target-processes all \
--set full \
--kernel-name "regex:at::native::.*" \
-o ./ncu_report \
python train.pyncu 里指标很多,不用全看。抓住几个关键的就行。
SM Utilization 看流处理器利用率,低于 60% 说明 kernel 没喂饱 GPU。Memory Throughput 看显存带宽利用率,接近理论带宽说明受限于内存了。Achieved Occupancy 看实际占用率,低了通常因为寄存器或者共享内存分配太多。Warp Stall Long Scoreboard 这个指标高,说明 warps 在等长延迟操作,基本就是等内存。Tensor Core Utilization 看 Tensor Core 用没用上,低的话可能没开混合精度。
实战中怎么判断呢?Memory Throughput 快到天花板了但 Compute Throughput 很低,那你的 kernel 是 memory-bound,瓶颈在数据搬运上,优化方向是算子融合、减少中间 tensor。反过来,Compute Throughput 高但 Memory Throughput 低,那是 compute-bound,得想想 Tensor Core、混合精度,或者换个更高效的算法。
每次遇到训练慢的问题,按这个顺序走,别跳步。
先花 5 分钟用 htop、nvidia-smi、iotop 扫一遍,判断瓶颈在哪个方向。这三板斧下去,基本就清楚了。
方向确定了就上 torch.profiler,跑个 scheduled profile,导出 trace 到 TensorBoard。看 GPU Gaps 判断是否在等 CPU,看 Top K 算子找热点,看 DataLoader 占比判断数据管线有没有拖后腿。
需要深入的话再上 Nsight。NVTX 标记好代码阶段,nsys 看全局 timeline,ncu 分析热点 kernel 的硬件指标。这一层只在确定问题出在 GPU 计算效率时才用,别一上来就搞。
找到问题之后对症下药。CPU 瓶颈就调 num_workers、增大 prefetch_factor、把预处理 offload 到 GPU。I/O 瓶颈就换 SSD、预加载数据到内存、用 NVIDIA DALI。GPU 计算瓶颈就做算子融合、上 torch.compile、开混合精度。通信瓶颈就上梯度压缩、通信计算重叠。框架开销就减少 Python 调用、用 TorchScript 或者 C++ 扩展。
多卡多节点训练额外多一个问题:通信。
DDP 模式下每个 step 结束要做 AllReduce 同步梯度。模型小还好,通信量不大。模型一大、网络带宽又不够,通信时间能占到总时间的 30% 到 50%。你在 profiler 里看 NCCL 相关操作,aten::allreduce 或 ncclAllReduce 要是排进 Top 3,基本就是通信在拖。
怎么优化呢?
梯度压缩是最直接的,torch.distributed 自带这个功能,开起来就行。通信计算重叠也得注意,DDP 默认会做 backward 和 AllReduce 的重叠,但前提是模型结构得合理,让不同 layer 的梯度计算和通信能交错起来。混合精度加 DDP 也能帮上忙,FP16 的梯度同步量直接减半。实在不行就上 FSDP 或者 ZeRO,把模型参数分片,单卡的显存压力和通信量都能降下来。
说到底,性能分析就是拿工具代替瞎猜。直觉这东西十次有八次是错的。
htop 看 CPU,nvidia-smi 看 GPU,torch.profiler 看算子,nsys 看 timeline,ncu 看 kernel 指标。从粗到细,把 AI Workload 的性能问题都覆盖了。不用成为 GPU 架构专家,就记住一件事:先搞清楚瓶颈在哪,再选对工具去看。
2、训练部署痛点
总结:千万级脏数据、分布式训练的梯度同步问题、毫秒级推理延迟要求
差异一:数据规模与质量------从"小而干净"到"大而杂乱"
实验室Demo表现
用1k-10k级别的小批量数据,标注100%准确(甚至是公开数据集如MNIST、COCO的子集),数据分布单一,无需做清洗、去重、校验,直接丢进模型训练即可。
工业级核心痛点
数据规模动辄千万级,甚至亿级(比如安防场景的监控视频帧、电商场景的商品图片);
数据"脏":标注错误(人工标注的漏标、错标)、数据重复、噪声干扰(如流水线图像的反光、监控图像的模糊)、样本分布极端不平衡(比如缺陷检测中缺陷样本占比不足1%);
数据格式不统一:不同产线、不同设备采集的数据格式混乱,需做标准化处理。
解决方案
- 数据分层清洗与校验(PyTorch+OpenCV实现):先写自动化脚本过滤无效数据(模糊、重复、标注越界),再人工复核关键样本,以下是工业级数据校验核心代码(以目标检测为例):
python
import cv2
import numpy as np
import os
from tqdm import tqdm
from skimage.metrics import structural_similarity as ssim
def check_image_quality(img_path, blur_threshold=30):
"""校验图像清晰度(模糊图像直接过滤)"""
img = cv2.imread(img_path, 0)
laplacian = cv2.Laplacian(img, cv2.CV_64F).var()
return laplacian > blur_threshold
def remove_duplicate_images(img_dir, sim_threshold=0.95):
"""去除重复图像(SSIM相似度阈值过滤)"""
img_paths = [os.path.join(img_dir, f) for f in os.listdir(img_dir) if f.endswith((".jpg", ".png"))]
keep_paths = []
for i, path1 in enumerate(tqdm(img_paths)):
if not check_image_quality(path1):
continue
is_duplicate = False
img1 = cv2.imread(path1, 0)
img1 = cv2.resize(img1, (224, 224))
for path2 in keep_paths:
img2 = cv2.imread(path2, 0)
img2 = cv2.resize(img2, (224, 224))
sim = ssim(img1, img2)
if sim > sim_threshold:
is_duplicate = True
break
if not is_duplicate:
keep_paths.append(path1)
return keep_paths
# 工业级实操:先过滤模糊图,再去重,最后人工复核标注
valid_imgs = remove_duplicate_images("/industrial_data/raw_imgs")
print(f"原始数据{len(os.listdir('/industrial_data/raw_imgs'))}张,清洗后有效数据{len(valid_imgs)}张")- 样本平衡策略:针对极端不平衡数据,用"数据增强+加权损失"组合方案------对少数类样本做针对性增强(如小目标缺陷的裁剪、缩放),训练时在损失函数中给少数类加权:
python
# PyTorch实现加权损失(以交叉熵损失为例)
class_weights = torch.tensor([1.0, 10.0, 10.0, 10.0]).cuda() # 正常样本权重1,缺陷样本权重10
criterion = nn.CrossEntropyLoss(weight=class_weights)- 数据管道优化 :千万级数据不用普通的
Dataset加载,改用torch.utils.data.DataLoader结合多进程(num_workers)+ 内存映射(mmap),避免IO瓶颈:
python
# 工业级数据加载配置
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=64,
shuffle=True,
num_workers=16, # 工业服务器多核心,拉满进程数
pin_memory=True, # 锁页内存,加速GPU数据传输
prefetch_factor=2 # 预取数据,减少等待
)差异二:训练架构------从"单卡跑通"到"分布式高效训练"
实验室Demo表现
用单张显卡(比如RTX 3090),batch_size设为8/16,训练几小时到几天,不管训练效率,能收敛就行。
工业级核心痛点
千万级数据单卡训练耗时数月,完全不现实;
多卡训练时梯度同步方式错误、学习率未适配,导致训练不收敛;
训练过程中断(服务器宕机、网络波动),之前的训练进度丢失
工业级解决方案
- 分布式训练配置(PyTorch DDP):实验室Demo几乎不用DDP,但工业级必须上,以下是可直接复用的DDP启动代码和核心配置:
python
# 工业级DDP训练主脚本(train_ddp.py)
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
def setup_ddp():
dist.init_process_group(backend="nccl") # 多卡用nccl后端,CPU分布式用gloo
local_rank = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(local_rank)
return local_rank
def main():
local_rank = setup_ddp()
# 1. 加载模型
model = YOLO26().cuda(local_rank)
model = DDP(model, device_ids=[local_rank], find_unused_parameters=True)
# 2. 优化器与学习率(工业级:学习率随卡数线性缩放)
base_lr = 0.001
world_size = dist.get_world_size() # 总卡数
optimizer = torch.optim.Adam(model.parameters(), lr=base_lr * world_size)
# 3. 训练过程(略)
# 4. 断点续训(工业级必加)
if os.path.exists("/industrial_ckpt/latest_ckpt.pth"):
checkpoint = torch.load("/industrial_ckpt/latest_ckpt.pth", map_location=f"cuda:{local_rank}")
model.load_state_dict(checkpoint["model_state_dict"])
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
start_epoch = checkpoint["epoch"]
# 5. 保存检查点(只在主卡保存,避免冲突)
if local_rank == 0:
torch.save({
"epoch": epoch,
"model_state_dict": model.module.state_dict(), # DDP模型要取module
"optimizer_state_dict": optimizer.state_dict()
}, "/industrial_ckpt/latest_ckpt.pth")
if __name__ == "__main__":
main()启动命令(8卡训练,工业服务器实操):
shell
# 用torchrun启动,自动分配rank,比mpirun更稳定
torchrun --nproc_per_node=8 train_ddp.py- 混合精度训练:开启PyTorch AMP(自动混合精度),在不损失精度的前提下,将训练速度提升30%-50%:
python
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
# 训练循环中启用AMP
for data in train_loader:
optimizer.zero_grad()
with autocast(): # 自动混合精度
outputs = model(data)
loss = criterion(outputs, labels)
scaler.scale(loss).backward() # 梯度缩放,避免FP16下溢
scaler.step(optimizer)
scaler.update()-
训练监控 :工业级训练必须加日志(
logging)+ 可视化(TensorBoard),实时监控损失、精度、GPU利用率,避免训练异常:from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("/industrial_logs/tensorboard")训练中记录关键指标(主卡记录即可)
if local_rank == 0:
writer.add_scalar("train/loss", loss.item(), global_step)
writer.add_scalar("train/mAP", mAP, global_step)
writer.add_scalar("lr", optimizer.param_groups[0]["lr"], global_step)
差异三:推理性能------从"不管延迟"到"毫秒级达标"
实验室Demo表现
推理时直接用训练好的模型model.eval(),输入单张图片,不管推理时间,能出结果就行。
工业级核心痛点
工业场景要求推理延迟毫秒级(比如安防实时检测要求<50ms,自动驾驶要求<20ms);
实验室模型未做优化,推理时冗余计算多、内存占用高;
批量推理时性能波动大,无法稳定达标。
工业级解决方案
- 模型优化三板斧:
第一步:模型量化(PyTorch量化工具),将FP32转INT8,推理速度提升40%+,精度损失<3%:
python
# PyTorch静态量化(工业级常用,精度更可控)
from torch.quantization import quantize_fx
# 1. 准备量化模型(先融合卷积+BN层,提升量化效果)
model.eval()
model.fuse_model() # 自定义模型需实现fuse_model方法,融合Conv-BN-ReLU
# 2. 校准(用100-200张真实场景图片校准)
calib_data_loader = DataLoader(calib_dataset, batch_size=32)
def calibrate(model, data_loader):
model.eval()
with torch.no_grad():
for data in data_loader:
model(data.cuda())
# 3. 量化
qconfig = torch.quantization.get_default_qconfig("fbgemm") # CPU量化用fbgemm,GPU用qnnpack
model_prepared = quantize_fx.prepare_fx(model, qconfig)
calibrate(model_prepared, calib_data_loader)
model_quantized = quantize_fx.convert_fx(model_prepared)
# 4. 保存量化模型
torch.jit.save(torch.jit.trace(model_quantized, torch.randn(1,3,640,640).cuda()), "yolo26_quantized.pt")第二步:算子融合+模型编译(torch.compile
python
# 编译模型,推理速度提升20%-30%
model = torch.compile(model, mode="max-autotune") # 自动调优编译策略第三步:ONNX导出+TensorRT优化(GPU推理极致提速):
python
# 导出动态尺寸ONNX(适配工业场景不同输入尺寸)
torch.onnx.export(
model.module if isinstance(model, DDP) else model,
torch.randn(1,3,640,640).cuda(),
"yolo26_industrial.onnx",
input_names=["input"],
output_names=["output"],
dynamic_axes={"input": {2: "height", 3: "width"}},
opset_version=12,
do_constant_folding=True # 常量折叠,减少计算量
)
# TensorRT转换(工业级GPU推理命令)
trtexec --onnx=yolo26_industrial.onnx --saveEngine=yolo26_trt.engine --fp16 --workspace=16-
推理管道优化:
预处理/后处理用OpenCV GPU版(cv2.cuda),替代CPU预处理,减少数据传输耗时;
批量推理:工业场景用batch_size=32/64批量推理,比单张推理效率提升数倍;
预热模型:推理前先跑10-20轮空推理,让GPU/CPU完成算子编译,避免首帧延迟过高。
差异4:模型鲁棒性------从"固定场景"到"复杂真实环境"
实验室Demo表现
训练和测试数据来自同一分布(比如都是实验室拍摄的清晰图片),模型在测试集上精度90%+,但放到真实场景就"失效"。
工业级核心痛点
真实场景存在光照变化、视角偏移、设备噪声(如流水线相机的畸变);
模型泛化能力差,遇到未见过的场景就漏检、错检;
极端情况(如夜间监控、强光反射)模型完全失效。
工业级解决方案
- 鲁棒性数据增强:实验室只用简单的翻转、裁剪,工业级需加真实场景的噪声模拟:
python
from torchvision import transforms
# 工业级数据增强组合(模拟真实场景干扰)
train_transforms = transforms.Compose([
transforms.RandomResizedCrop((640,640), scale=(0.8, 1.2)), # 尺度变化
transforms.RandomHorizontalFlip(p=0.5),
transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4), # 光照变化
transforms.RandomGrayscale(p=0.1), # 灰度化(模拟夜间)
transforms.GaussianBlur(kernel_size=(3,3), sigma=(0.1, 2.0)), # 模糊(模拟噪声)
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])-
测试集设计:工业级测试集必须包含"边缘场景样本"(如极端光照、小目标、模糊图),而非仅用实验室干净数据;
-
模型正则化:除了Dropout/L2正则,工业级还会用"早停+模型集成"------早停避免过拟合,集成提升鲁棒性:
python
# 工业级早停实现
class EarlyStopping:
def __init__(self, patience=10, min_delta=0.001):
self.patience = patience
self.min_delta = min_delta
self.best_loss = float('inf')
self.counter = 0
def __call__(self, val_loss):
if val_loss < self.best_loss - self.min_delta:
self.best_loss = val_loss
self.counter = 0
return False
else:
self.counter += 1
if self.counter >= self.patience:
return True
return False
# 训练中使用
early_stopping = EarlyStopping(patience=10)
for epoch in range(100):
# 训练步骤(略)
val_loss = validate(model, val_loader)
if early_stopping(val_loss):
print("早停触发,停止训练")
break差异5:部署落地------从"跑Demo"到"多端稳定上线"
实验室Demo表现
部署=在训练机上运行model.predict(),不管部署环境、依赖、兼容性。
工业级核心痛点
部署环境多样(GPU服务器、CPU服务器、嵌入式设备),实验室代码依赖冲突、无法运行;
无异常处理,部署后遇到异常数据直接崩溃;
无法监控部署后的模型性能(精度漂移、推理延迟)。
工业级解决方案
-
环境封装:用Docker封装部署环境,避免依赖冲突,以下是工业级PyTorch部署Dockerfile:
工业级PyTorch部署镜像(适配CUDA 11.8)
FROM nvidia/cuda:11.8.0-cudnn8-runtime-ubuntu22.04
安装基础依赖
RUN apt update && apt install -y python3 python3-pip libgl1-mesa-glx
设置pip源
RUN pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
安装固定版本依赖(工业级必须锁版本)
RUN pip3 install torch==2.2.0 torchvision==0.17.0 opencv-python==4.7.0.72 onnx==1.14.1 tensorrt==8.6.0
复制模型和推理代码
COPY yolo26_trt.engine /app/
COPY infer.py /app/启动推理服务
WORKDIR /app
CMD ["python3", "infer.py"] -
异常处理:推理代码必须加完整的异常捕获,避免崩溃:
工业级推理代码(infer.py)
import cv2
import torch
import tensorrt as trtdef infer_image(img_path, engine_path):
try:
# 1. 加载图像(异常处理:文件不存在、格式错误)
if not os.path.exists(img_path):
return {"code": -1, "msg": "文件不存在", "result": None}
img = cv2.imread(img_path)
if img is None:
return {"code": -1, "msg": "图像格式错误", "result": None}
# 2. 预处理(异常处理:图像尺寸异常)
if img.shape[0] == 0 or img.shape[1] == 0:
return {"code": -1, "msg": "图像尺寸异常", "result": None}
# 3. 推理(略)
# 4. 返回结果
return {"code": 0, "msg": "成功", "result": det_result}
except Exception as e:
# 工业级:记录异常日志,返回友好提示
print(f"推理异常:{str(e)}")
return {"code": -2, "msg": f"推理失败:{str(e)}", "result": None} -
模型监控:部署后加性能监控,检测"模型漂移"(数据分布变化导致精度下降),定期用真实数据评估模型精度,若精度下降超过阈值,触发重新训练。
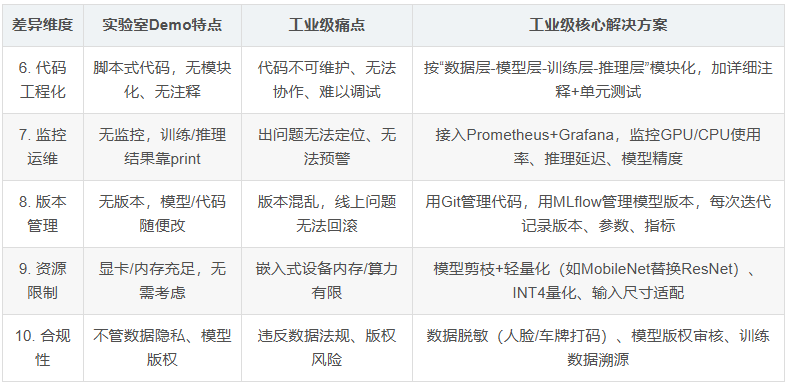
其余痛点:
3.2 vLLM能力边界
vLLM 的设计使其在特定场景下几乎触及了当前硬件和算法下的性能上限。vLLM官方提供了基准测试代码库 10,其的benchmarks套件通过模块化设计提供一站式性能评估解决方案,支持从基础算子到端到端服务的全链路测试,覆盖90%以上的LLM部署场景。
1、测试套件架构概览
2、核心测试模块功能矩阵
| 模块文件 | 主要功能 | 关键指标 | 适用场景 |
|---|---|---|---|
| benchmark_latency.py | 首token延迟/每token延迟测试 | TTFT, TPOT, P99延迟 | 实时交互应用 |
| benchmark_throughput.py | 并发请求吞吐量测试 | RPS, 令牌生成速率 | 批量推理任务 |
| benchmark_serving.py | 端到端服务性能测试 | QPS, 系统资源占用 | 生产环境部署验证 |
| benchmark_prefix_caching.py | 前缀缓存效率测试 | 缓存命中率, 加速比 | 对话式应用优化 |
| benchmark_moe.py | MoE架构性能测试 | 专家路由效率, 显存占用 | 多专家模型评估 |
- TTFT (Time to First Token): 首token响应时间
- TPOT (Time per Output Token): 后续token生成时间
- E2EL (End-to-End Latency): 请求全程延迟
3、测试环境
- 系统要求:Linux (Ubuntu 20.04+)
- 硬件:
- GPU: NVIDIA 4060(laptop)
- 内存: 8GB
- CUDA: V12.6
- 模型选择:Qwen2.5-0.5B
4、测试
这里是测得benchmark_serving.py,vllm_test.py如下
python
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="Qwen/Qwen2.5-0.5B", gpu_memory_utilization=0.8)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")服务器:
bash
vllm serve Qwen/Qwen2.5-0.5B --disable-log-requests --gpu-memory-utilization 0.8客户端:
bash
python3 /home/zzh/work/code/vllm/benchmarks/benchmark_serving.py --backend vllm --model Qwen/Qwen2.5-0.5B --endpoint /v1/completions --dataset-name sharegpt --dataset-path ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 1000 --min-p 0.2 --top-k 10 --top-p 0.8 --temperature 1.2得到结果
num-prompts=10
bash
============ Serving Benchmark Result ============
Successful requests: 10
Benchmark duration (s): 5.19
Total input tokens: 1374
Total generated tokens: 2521
Request throughput (req/s): 1.93
Output token throughput (tok/s): 485.37
Total Token throughput (tok/s): 749.91
---------------Time to First Token----------------
Mean TTFT (ms): 79.82
Median TTFT (ms): 83.42
P99 TTFT (ms): 85.15
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 6.92
Median TPOT (ms): 6.95
P99 TPOT (ms): 7.28
---------------Inter-token Latency----------------
Mean ITL (ms): 6.79
Median ITL (ms): 6.74
P99 ITL (ms): 9.01
==================================================num-prompts=100
bash
============ Serving Benchmark Result ============
Successful requests: 100
Benchmark duration (s): 9.83
Total input tokens: 23260
Total generated tokens: 18033
Request throughput (req/s): 10.17
Output token throughput (tok/s): 1834.70
Total Token throughput (tok/s): 4201.21
---------------Time to First Token----------------
Mean TTFT (ms): 708.66
Median TTFT (ms): 826.79
P99 TTFT (ms): 835.11
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 20.92
Median TPOT (ms): 19.40
P99 TPOT (ms): 56.72
---------------Inter-token Latency----------------
Mean ITL (ms): 16.54
Median ITL (ms): 16.78
P99 ITL (ms): 25.85
==================================================num-prompts=1000
bash
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 69.64
Total input tokens: 217393
Total generated tokens: 153054
Request throughput (req/s): 14.36
Output token throughput (tok/s): 2197.64
Total Token throughput (tok/s): 5319.09
---------------Time to First Token----------------
Mean TTFT (ms): 19720.16
Median TTFT (ms): 15706.85
P99 TTFT (ms): 50199.03
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 113.72
Median TPOT (ms): 109.38
P99 TPOT (ms): 305.22
---------------Inter-token Latency----------------
Mean ITL (ms): 95.92
Median ITL (ms): 85.33
P99 ITL (ms): 258.58
==================================================四、对嵌入式算法部署的支撑/短板
4.1 PyTorch对于嵌入式的支撑/短板
支撑
PyTorch 生态通过一系列创新,给嵌入式设备的部署提供强力有效的技术支撑
1、高效的端侧大模型架构支撑
- 模型压缩与参数共享方面
在资源受限设备上高效部署大语言模型,通常需要在不显著牺牲性能的前提下减小模型大小。模型压缩和参数共享 技术在实现这种平衡中发挥关键作用。
AWQ即激活值感知的权重量化(Activation-aware Weight Quantization),是一种针对LLM的低比特权重量化的硬件友好方法。AWQ是一种仅权重量化方法,专注于大语言模型中权重的重要性。AWQ保护了一小部分关键权重(0.1%-1%),减少量化损失,保持模型泛化能力。与传统方法不同,AWQ不需要反向传播或重建,从而保持效率和性能。提出的TinyChat推理框架实现了AWQ,在服务器和移动GPU上相比传统FP16实现获得显著加速(高达3倍)。MobileLLM通过深而窄架构,解决了移动设备上高效大语言模型的需求。关键技术包括嵌入共享、分组查询注意力和分块立即权重共享。MobileLLM相比之前最先进的模型实现了显著的准确度提升(例如,125M和350M模型分别提高2.7%和4.3%的准确度)。增强版MobileLLM-LS进一步提高了准确度,同时保持较小的模型大小,非常适合设备端应用。这些为提高资源受限环境中大语言模型的性能和可访问性做出了重要贡献。
- 协作和分层模型方法方面
在资源受限设备上部署语言模型面临重大挑战,如有限的内存和计算能力。协作和分层模型方法通过分配计算负载并利用具有不同能力的多个模型,为克服这些限制提供创新解决方案。
EdgeShard引入了EdgeShard框架,将大型大语言模型分割成更小的分片,并战略性地将它们分布在边缘设备和云服务器上。这种方法通过同时利用多个设备的计算能力来减少延迟并提高吞吐量。动态规划算法优化分片放置,平衡计算负载并最小化通信开销。实验结果显示,与传统基于云的方法相比,延迟减少(高达50%)和吞吐量提高(高达2倍)。LLMCad提出了一种结合较小内存驻留模型和更大更准确模型的推理引擎。较小的模型生成候选token,而较大的模型验证和纠正这些token。这种"生成然后验证"方法利用了较小模型的效率,并保持了较大模型的准确性。LLMCad在不影响准确性的情况下token生成加速高达9.3倍。WDMoE提出了在无线通信系统中部署大语言模型的新范式。通过执行MoE层分解,在基站部署门控网络,并将专家网络分布在移动设备上,以优化性能并减少延迟。此外,提出的专家选择策略基于无线信道条件动态调整专家选择,以确保最佳性能。协作和分层模型方法,如EdgeShard和LLMCad提出的方法,为在资源受限设备上部署大语言模型的挑战提供了有效解决方案。通过在多个设备之间分配计算负载,并使用较小的模型进行初步任务,这些方法提高了大语言模型推理的可扩展性和效率。EdgeShard框架展示了协作边缘-云计算的优势,而LLMCad展示了分层模型协作在保持准确性和提高推理速度方面的潜力。这些方法对于在移动和边缘设备上实现先进的人工智能能力至关重要,提供实时性能和高效资源利用。
- 内存和计算效率方面
高效的内存和计算资源利用对于在移动和边缘设备上部署大型语言模型至关重要。
三星电子的研究人员提出了创新的内存解决方案,以解决大语言模型部署中的内存瓶颈,包括内存内处理(PIM)和近内存处理(PNM)技术:
Aquabolt-XL和LPDDR-PIM: 这些PIM设备在内存核心中嵌入逻辑,提高内部内存带宽并支持高性能计算任务,包括大语言模型加速。
AXDIMM和CXL-PNM: 这些PNM解决方案将计算逻辑放置在内存核心附近,增强内存带宽和容量。CXL-PNM将计算逻辑集成到CXL内存控制器中,显著提高内存容量和性能。
实验结果表明,与传统内存架构相比,这些内存解决方案实现了高达4.5倍的性能提升和71%的能耗降低。MELTing Point引入了MELT基础设施,促进在移动设备上执行和评估大语言模型。MELT框架支持Android、iOS和Nvidia Jetson设备,并提供详细的性能、能耗指标和内存使用详情。MELT论文验证了模型量化对性能和准确性的影响,表明虽然量化减少了内存需求,但会牺牲一定的准确性。结果强调了在内存和计算效率与性能之间平衡的重要性。
内存和计算效率对于在移动和边缘设备上部署大语言模型至关重要。三星的内存解决方案(如PIM和PNM)显著提高了内存带宽和容量,实现高效的大语言模型推理。MELT基础设施提供了全面的评估框架,提供了性能、能效和内存使用之间权衡的宝贵见解。这些进展对确保大语言模型能够在资源受限设备上有效运行至关重要,为移动和边缘环境中更实用、高效的人工智能应用铺平了道路。
- 混合专家架构方面
混合专家(MoE)架构通过利用稀疏激活和动态路由来提高效率,为在边缘设备上部署大语言模型提供了一种有前景的方法。
EdgeMoE引入了一个在边缘设备上高效执行MoE模型的框架。通过专家级位宽自适应,使每通道线性量化以最小的准确性损失减小专家权重的大小。利用新颖的专家管理方法,将专家权重预加载到计算-I/O管道中,以减少I/O交换开销。实验结果表明,与基线解决方案相比,推理速度提高了高达2.78倍。
LocMoE引入了路由策略和通信优化方案,以提高基于MoE的大语言模型训练效率。采用正交门控权重方法来降低计算成本并促进明确的路由决策。此外,引入基于局部性的专家正则化,鼓励局部专家竞争,减少通信时间并避免训练不足。另外,还使用分组All-to-All和通信重叠,通过将计算与通信重叠来优化All-to-All操作,以掩盖延迟。
LLMaaS范式将大型语言模型作为系统服务集成到移动设备上。在他们提出的设计中,有状态执行允许系统在多次调用中保持持久状态(KV缓存)以提高性能。统一接口通过将大语言模型及其基础设施作为系统功能暴露给移动应用,有助于减少内存使用。他们还引入了诸如分块KV缓存压缩和交换等技术,以最小化上下文切换开销。
JetMoE提出使用稀疏门控混合专家(SMoE)架构对大型语言模型进行高效训练。将稀疏激活应用于注意力和前馈层,显著降低计算成本同时保持高性能。JetMoE-8B使用1.25T个token和30,000个H100 GPU小时训练,成本不到10万美元,性能超过了Llama2-7B,且JetMoE-8B-Chat优于Llama2-13B-Chat。该模型总共80亿参数,每个输入token仅激活20亿参数,与Llama2-7B相比,减少了约70%的推理计算。
MoE架构为在边缘设备上部署大语言模型提供了创新解决方案。这些方法利用稀疏激活和动态路由来提高计算效率和资源利用率。
- 通用效率与性能改进方面
在边缘设备上高效部署大语言模型涉及一系列旨在提高整体性能同时管理计算和内存约束的策略。以下回顾引入提高设备端大语言模型效率和有效性的关键研究工作。
任意精度大语言模型(Any-Precision LLM) 提出了一种内存效率高的方法,部署具有不同精度的各种大语言模型。任意精度模型将任意精度深度神经网络扩展到大语言模型,允许单个n位量化模型支持多个低至3位的低位宽模型。这在不显著损失性能的情况下减少了内存使用。训练后量化(PTQ)创建低位模型并将其逐步升级到更高位宽。这避免了每种精度的多次训练阶段,节省了时间和资源。针对任意精度支持优化的新软件引擎管理内存带宽并提高服务效率,确保大语言模型在边缘设备上的实际部署。实验结果表明,内存节省和服务效率显著提高。
LCDA框架探索了在软硬件协同设计中使用大语言模型来优化内存计算(CiM)深度神经网络(DNN)加速器的开发。LCDA框架将大语言模型集成到硬件和软件的设计过程中,利用其在多样化数据集上的广泛训练来加速协同设计。通过结合预训练大语言模型的启发式知识,该框架绕过了冷启动问题,能更快地收敛到最优解。与最先进的方法相比,该框架在设计过程中显示出25倍的加速,同时在设计高效DNN模型和硬件架构方面保持了相当的性能水平。这种方法突显了大语言模型在增强协同设计过程中的潜力,同时改善了先进人工智能应用的软件和硬件效率。
通用效率和性能改进对于大语言模型在边缘设备上的部署至关重要。本小节回顾提高内存效率、计算速度和整体性能d的研究工作。任意精度大语言模型方法为部署具有不同精度的多个大语言模型提供了灵活且内存高效的解决方案,而LCDA框架则展示了将大语言模型整合到协同设计过程中以优化软件和硬件的好处。这些进展有助于使大语言模型在资源受限环境中更易获得且更有效,使移动和边缘设备上的人工智能应用范围更广。
2、端侧大模型压缩和优化技术支撑
- 量化
量化是将神经网络中的高精度(浮点)权重和激活值转换为低位宽(整数)的过程。这种技术显著减少了模型大小和计算需求,实现了更快的推理和更低的内存消耗,同时保持了准确性。
- 训练后量化(PTQ): PTQ在模型训练后应用,无需重新训练,因此比量化感知训练 (QAT) 更快,资源消耗更少。有几种值得注意的PTQ方法。
(a) 仅权重量化 :在仅权重量化中,只对神经网络的权重进行量化。这种方法简化了量化过程,当激活值范围变化不大或计算资源严重受限时特别有效。
(b) 权重-激活联合量化 :权重和激活值都进行量化,进一步降低计算复杂度。由于高效的矩阵乘法,这种方法在硬件实现中具有优势,对神经计算至关重要。BitNet b1.58对每个参数使用三元量化(-1、0、1),显著改善了延迟、内存、吞吐量和能耗指标。
-
GPTQ:GPTQ利用二阶信息进行误差补偿,有效地将每个权重的位宽降至3或4位。该方法保持了高准确性,困惑度仅略微增加,使OPT-175B等语言模型能够在单个高端GPU上运行。
-
激活感知权重量化 (AWQ):AWQ基于观察到一小部分(0.1%-1%)权重对大语言模型的性能至关重要。通过有选择地跳过对这些关键权重的量化,AWQ显著减少了量化损失。
-
量化感知训练(QAT) :QAT将量化直接纳入训练过程,使模型能够本质上适应降低精度的约束。这种集成通常会在量化后产生更高的准确性,因为模型在训练阶段主动学习补偿潜在的量化误差。
-
剪枝
神经网络中的剪枝涉及有选择地移除权重或神经元,以减少复杂性并提高计算效率,同时保持性能不显著下降。
- 结构化剪枝 :移除整个参数子集,如层、通道或滤波器,由于更规则的内存访问模式和简化的计算,有利于硬件优化。"LLM-Pruner"采用结构化剪枝,基于梯度数据消除非必要groups,从而保持关键功能。它还通过LoRA等技术促进性能恢复,允许以最少的数据进行高效恢复。
- 非结构化剪枝 :移除模型中的单个权重,提供更细粒度的控制和更高压缩率。然而,这种方法通常会导致稀疏矩阵 ,可能与传统硬件架构不太兼容,影响计算效率。它最适合需要最大压缩而不受结构保留约束的情况。
- 上下文剪枝 :根据模型的操作上下文进行剪枝,仅保留特定条件下或特定任务中相关的权重或神经元。上下文剪枝确保减少与模型操作需求动态一致,从而在最重要的地方保持性能。
- 知识蒸馏
知识蒸馏 (KD) 是将大型模型(教师)的知识转移到较小模型(学生)的过程,使大型语言模型的能力浓缩而不显著影响性能。
- 黑盒知识蒸馏 :学生模型仅从教师模型的输出中学习 ,而不访问其内部机制或参数。当教师模型的细节是专有的或当教师和学生模型的架构显著不同时,此方法尤为有用。例如,Gu等人(2023)证明,黑盒KD可以有效地仅使用ChatGPT等LLM API的输出数据来训练模型。学生模型训练以模仿教师的输出分布,基于输入-输出对,这个过程虽然有效,但将学习限制在外部行为上,而不能深入教师的内部状态。
- 白盒知识蒸馏 :相比之下,白盒知识蒸馏允许学生模型访问教师的内部状态和工作原理,促进更深入、更精确的学习过程。这种方法使学生不仅能够模仿输出,还包括教师的内部状态分布,提高学习效果和深度。对教师详细工作的增加访问有助于指导学生的学习,产生更准确和健壮的模型。然而,这种技术需要谨慎地对齐模型架构以确保有效的知识转移,实现通常更为复杂。
- 低秩分解
低秩分解 (LRF) 是将矩阵分解为更小组件的技术,显著降低计算复杂度而不影响模型准确性。利用矩阵中普遍存在的内在低秩结构,LRF通过低秩因子的积来近似这些矩阵,这在图像处理、机器学习模型的降维和数据压缩等应用中已证明不可或缺。这种方法不仅保持了基本的数据特征,还确保了高效的存储和处理。进一步扩展其应用,Yao等人(2024b)的研究将LRF与大型语言模型中的训练后量化(PTQ)相结合。这种创新方法,称为低秩补偿(LoRC),通过显著减少模型大小并保持准确性来提高模型效率,有效缓解了激活量化的不利影响。LRF和PTQ的这种结合展示了在维持复杂模型性能的同时优化计算效率的重大进展。
3、框架支撑
1、仅边缘框架
(a) Llama.cpp
- 描述:由Google开发的MediaPipe是一个用于构建和部署涉及视频、音频和其他时间序列数据的多模态机器学习管道的框架。
- 训练:没有内置的训练功能。
- 推理:支持包括Android、iOS、macOS、Windows和Linux在内的多个平台,利用CPU和GPU资源。
(b) MNN
- 描述:ExecuTorch是PyTorch Edge生态系统的一部分,适用于在移动设备和可穿戴设备上高效部署PyTorch模型。
- 训练:没有内置的训练功能。
- 推理:利用包括CPU、NPU和DSP在内的全部硬件功能,适用于各种计算平台。
© PowerInfer
- 描述:PowerInfer和PowerInfer2是一个高速推理引擎,针对在配备消费级GPU的PC上部署大语言模型进行了优化,采用以局部性为中心的设计。
- 训练:没有内置的训练功能。
- 推理:支持包括x86-64 CPU和Apple M芯片在内的各种计算平台,针对Windows和Linux进行了优化。
(d) ExecuTorch
- 描述:MNN利用移动神经网络技术进行高效推理,优化了具有动态输入和多模态交互的移动设备。
- 训练:支持设备上的全尺寸微调和LORA微调。
- 推理:支持ONNX和MNN格式的模型部署,适用于CPU、CUDA和OpenCL等多种后端。
(e) MediaPipe
- 描述:这是一个C/C++库,专为在多种硬件平台上高效推理大语言模型而设计,支持整数量化、GPU加速和CPU+GPU混合推理。
- 训练:支持设备上的LORA适配器微调。
- 推理:支持跨ARM和x86架构的CPU和CPU+GPU混合推理。
2、边缘-云框架
(a) MLC-LLM
- 描述:OpenLLM使各种开源大语言模型能够部署为与OpenAI兼容的API端点,针对高吞吐量和精简云部署进行了优化。
- 训练:没有内置的训练功能。
- 推理:兼容各种模型架构和后端实现,适用于生产环境中的高效部署。
(b) VLLM
- 描述:针对边缘-云环境进行了优化,支持高级量化方法,以在推理过程中高效管理key和value。
- 训练:没有内置的训练功能。
- 推理:支持多个GPU平台,并集成Vulkan、CUDA、Metal和WebGPU技术。
© OpenLLM by BentoML
- 描述:是一个机器学习编译器和高性能部署引擎,支持在边缘设备和云环境中部署大语言模型。
- 训练:没有内置的训练功能。
- 推理:支持ARM和x86架构的CPU和GPU上的推理。
短板
- 硬件资源约束与模型兼容性限制
在嵌入式人工智能(Edge AI)系统开发中,开发者常面临一个关键瓶颈:为何训练完成后无法自由选择目标模型进行部署?这一现象的根本原因在于硬件资源约束 与模型兼容性限制之间的错配。传统深度学习模型通常在GPU服务器上训练,依赖高内存带宽和复杂算子支持,而嵌入式设备如MCU、低功耗SoC等则受限于存储容量(通常仅几十KB至几MB)、计算能力(<1 GOPS)以及功耗预算。
| 设备类型 | 典型RAM | 典型Flash | FLOPS能力 | 适用推理引擎 |
|---|---|---|---|---|
| STM32系列MCU | 64KB - 512KB | 256KB - 2MB | <0.1 GOPS | TFLite Micro, CMSIS-NN |
| ESP32 | 520KB | 4MB (外挂) | ~0.5 GOPS | TFLite Micro |
| NVIDIA Jetson Nano | 4GB | eMMC/SD | 47 GOPS | TensorRT, ONNX Runtime |
- 模型训练与部署的断层分析
-
动态图 vs 静态图:PyTorch默认使用动态计算图(eager execution),而大多数嵌入式推理引擎要求静态图结构以便提前优化和内存分配。
-
高级算子不可移植:例如自定义Attention机制、稀疏卷积或非标准激活函数,在TFLite或ONNX Runtime Tiny中可能无对应实现。
-
权重精度不匹配:FP32训练模型需量化为INT8甚至Binary格式以适应MCU,但某些架构对量化敏感,导致性能下降严重。
示例:PyTorch模型导出ONNX时常见报错
import torch
import torch.onnxclass CustomModel(torch.nn.Module):
def forward(self, x):
return torch.fft.fft2(x) # FFT算子在多数嵌入式引擎中不被支持model = CustomModel()
x = torch.randn(1, 3, 224, 224)
try:
torch.onnx.export(model, x, "custom_model.onnx")
except Exception as e:
print(f"导出失败:{e}") # 输出:Unsupported operator: aten::fft_fft2
- 兼容性限制的技术根源
graph TD A原始训练模型 --> B{是否使用受限算子?} B -->|是| C转换失败 B -->|否| D尝试模型量化 D --> E{目标平台支持INT8?} E -->|否| F降级为FP16或模拟量化 E -->|是| G生成轻量推理模型 G --> HTFLite / ONNX-Runtime-Tiny H --> I{是否存在MCU编译后端?} I -->|否| J无法部署 I -->|是| K成功运行
从流程图可见,即使模型通过了算子兼容性检查,仍需面对编译工具链缺失的问题。例如ARM Cortex-M系列虽可通过CMSIS-NN加速卷积,但若未提供针对特定NPU(如Ethos-U)的编译插件,则无法发挥硬件潜力。
4.2 vLLM对于嵌入式的支撑/短板
支撑
1、vLLM 支持的主流嵌入式平台
vLLM已验证支持以下物联网硬件架构:
- ARMv8/AArch64(如NVIDIA Jetson AGX Orin、Raspberry Pi 5)
bash
sudo apt-get update && sudo apt-get install -y --no-install-recommends \
build-essential \
libopenblas-dev \
python3-pip \
nvidia-container-toolkit- RISC-V(实验性支持,需通过cmake/cpu_extension.cmake手动编译)
注:这里写 RISC-V 是因为我在 17 看到,有人在官方 vllm 仓库提交了一个提供 RISC-V 标量支持的 PR,且该 PR 已被合并,但没有去验证以及实验,也没有相关博客说明。
- x86_64(如Intel NUC、UP Squared)
x86主机上为ARM设备编译时,需配置QEMU模拟环境:
bash
# 注册QEMU静态处理器
docker run --rm --privileged multiarch/qemu-user-static --reset -p yes
# 构建ARM64镜像
DOCKER_BUILDKIT=1 docker build . \
--file docker/Dockerfile \
--target vllm-openai \
--platform "linux/arm64" \
-t vllm-iot:arm64 \
--build-arg torch_cuda_arch_list="8.7" # Jetson Orin的GPU架构2、vLLM 支持的主流计算架构平台如下:
-
GPU 加速器
- NVIDIA GPU (CUDA):支持最成熟、性能优化最完善的平台。
- AMD GPU (ROCm):为开源生态提供了替代选择,例如针对 MI300 系列芯片有专门优化。
- Intel GPU (XPU):支持 Arc 系列 GPU,可利用统一内存架构进行高效推理。
- Google TPU:专注于云原生解决方案,提供高效的模型部署能力。
- 其他:还包括对 Gaudi、AWS Trainium/Inferentia 等专用AI芯片的支持。
-
CPU 架构
- Intel/AMD CPU:支持带有 AVX-512 等高级指令集的 x86 处理器。
- ARM CPU:除了边缘设备,也包括服务器级的 ARM 处理器。
- PowerPC CPU:支持 IBM Power 系统。
-
NPU 架构
- 华为昇腾 (Ascend):vLLM 已推出专门的 vLLM-Ascend插件(开源项目),实现了与 CUDA 版本对等的核心功能。(核心硬件:已验证支持 Ascend 910B 等高性能 NPU)
-
暂不支持TPU架构
部署
1、轻量化部署
选择适合嵌入式场景的小参数模型(通常≤7B)
python
from vllm import LLM, SamplingParams
# 加载4-bit量化模型
llm = LLM(
model="Qwen/Qwen2-0.5B",
quantization="awq",
gpu_memory_utilization=0.85, # 限制显存占用率
max_num_batched_tokens=512, # 适配嵌入式设备的批处理大小
)2、分布式/集群部署模式
Kubernetes示例
MiniKube测试环境:
bash
minikube start --driver=docker --cpus=4 --memory=8g
kubectl apply -f https://raw.githubusercontent.com/vllm-project/vllm/main/kubernetes/deployment.yaml
kubectl port-forward svc/vllm-service 8000:8000生产环境YAML配置:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-cluster
spec:
replicas: 3
template:
spec:
containers:
- name: vllm
image: vllm/vllm-openai:latest
args:
- "--model=Qwen/Qwen1.5-7B-Chat"
- "--tensor-parallel-size=2"
resources:
limits:
nvidia.com/gpu: 2
memory: 32Gi
volumeMounts:
- name: model-storage
mountPath: /models
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: vllm-model-pvc
---
apiVersion: v1
kind: Service
metadata:
name: vllm-lb
spec:
type: LoadBalancer
ports:
- port: 8000
targetPort: 8000
selector:
app: vllm详细见vllm/docs/deployment · vl/vllm - AtomGit | GitCode
3、边缘/端侧部署模式
在嵌入式设备上运行容器:
bash
docker run -d --name vllm-iot \
--runtime nvidia \
--memory=4g \
--cpus=2 \
-p 8000:8000 \
vllm-iot:arm64 \
--quantization awq \
--max_num_seqs 8 # 限制并发序列数项目提供了OpenAI兼容的API服务,可直接通过HTTP调用:
python
import requests
response = requests.post(
"http://localhost:8000/v1/completions",
json={
"prompt": "物联网设备状态监测: ",
"max_tokens": 128,
"temperature": 0.3
}
)
print(response.json()["choices"][0]["text"])API规范详情见docs/serving/openai_compatible_server.md
4、容器化部署方案
针对物联网场景优化的Dockerfile示例:
bash
FROM arm64v8/python:3.10-slim
# 安装系统依赖
RUN apt-get update && apt-get install -y --no-install-recommends \
libgomp1 \
&& rm -rf /var/lib/apt/lists/*
# 安装vLLM(使用国内源加速)
RUN pip install vllm -i https://pypi.tuna.tsinghua.edu.cn/simple
# 配置推理服务
COPY iot_inference.py /app/
WORKDIR /app
# 启动命令(限制CPU核心与内存)
CMD ["python", "iot_inference.py", "--model", "Qwen/Qwen2-0.5B", "--port", "8000"]完整Docker部署指南见docs/deployment/docker.md
短板
1、在v0.6.0版本之前,vllm中cpu和gpu的调度是串行的,导致cpu计算时候gpu是闲置的,这也会让吞吐变差。又因为vllm里合入了太多功能,这个情况又更加严重了,vllm高负载下gpu利用率甚至会降低到50%左右。而推动vllm去优化这一块也是因为看到sglang在吞吐的性能上远超于他,才会在v0.6.0里着重优化了这一部分。
2、vllm里被合入的功能实在是太多了,代码非常臃肿复杂,导致二次开发变得非常困难。月之暗面的mooncake引擎就是基于vllm早期版本的二次开发,不确定他们是固定在那个版本不再同步更新,还是说花了大量工作来保持vllm的同步升级。总之如果你要对开源引擎大改,sglang会是比vllm更好的一个选择。
3、我在知乎上看到有个佬对vllmprofile后做了一些算子优化,结果可以达到下表的提升(未验证)
| num-prompts | ori | opt | diff |
|---|---|---|---|
| 10 | 749.91 | 796.99 | 6.2% |
| 100 | 4201.21 | 5681.58 | 35.2% |
| 1000 | 5319.09 | 9324.61 | 75.3% |
我大概看了一下其技术博客,大概思想是把vLLM 的Sampler采样算子替换自己开发的一个名为 flashsampler的高性能采样算子了,但是可惜没有开源,但是证明了vLLM在算子这方面还是有操作空间的
优化
参考知乎另一个佬19列出的优化方向,大致有
- pagedattn
- kv cache
- Continous Batching
- Flash Attention
- Prefix Caching
- Speculative Decoding
- 量化
- kv cache 压缩
- prefill-decode 分离架构
- chunked Prefill
- constrained decoding
- CUDA Graph
- FlashInfer
- 多模态推理
- 大模型RAG
- function call
- 多卡推理
五、总结
首先我得致歉,因为花费时间很短所以这篇文章可能写的很浅,这几天基本是一边翻各种技术博客一边学习一边写的,但总体写下来还是挺开心的。虽然有时候觉得纸上谈兵没啥用,但是在我学习与书写这篇文章时,我发现大模型是生成不了我认知之外的东西的(后续师兄指出是context不足),所以还是要多去了解,多去看佬的博客,如果原理完全理解了还是觉得感兴趣,那就去看源码,争取哪天提交一个 PR,成为项目的贡献者之一。
二编:被师兄骂了,说我太浮躁,看东西既不验证也不思考,纯接收,别人说什么是什么,太快就ending一条分支了,也不深究,一直在做加法,看似学了很多,但都浮在表面一点也不深入。这个课程只是一个开始,三年还是太短,学海无涯,学不完啊,真的学不完,珍惜时间,加油啊。
参考
-
Inside vLLM: Anatomy of a High-Throughput LLM Inference System - Aleksa Gordić
-
[Roadmap vLLM Roadmap Q1 2026 · Issue #32455 · vllm-project/vllm](https://github.com/vllm-project/vllm/issues/32455)
-
[硬件RISC-V黄zhengx 添加RISC-V架构CPU推理支持·拉取请求 #20292 ·VLLM-project/VLM](https://github.com/vllm-project/vllm/pull/20292)
-
PyTorch Profiler --- PyTorch Tutorials 2.11.0+cu130 文档 - PyTorch 文档
-
[硬件RISC-V黄zhengx 添加RISC-V架构CPU推理支持·拉取请求 #20292 ·VLLM-project/VLM](https://github.com/vllm-project/vllm/pull/20292)
-
PyTorch Profiler --- PyTorch Tutorials 2.11.0+cu130 文档 - PyTorch 文档
-
验证真实性,复现,求真求实
-
带有思考的去学习,记录下问题
-
解决问题,记录深挖问题中发现的问题