前面完成了元数据库的初始化同步,现在开始根据流程搭建agent。
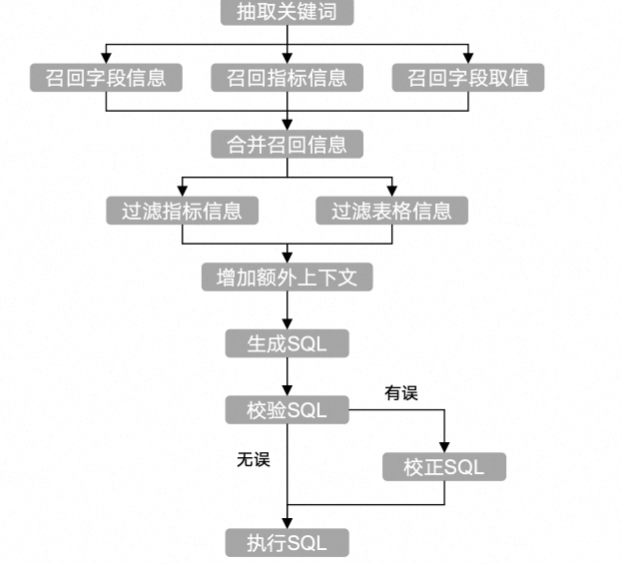
这是对应的流程,将其转为node节点。
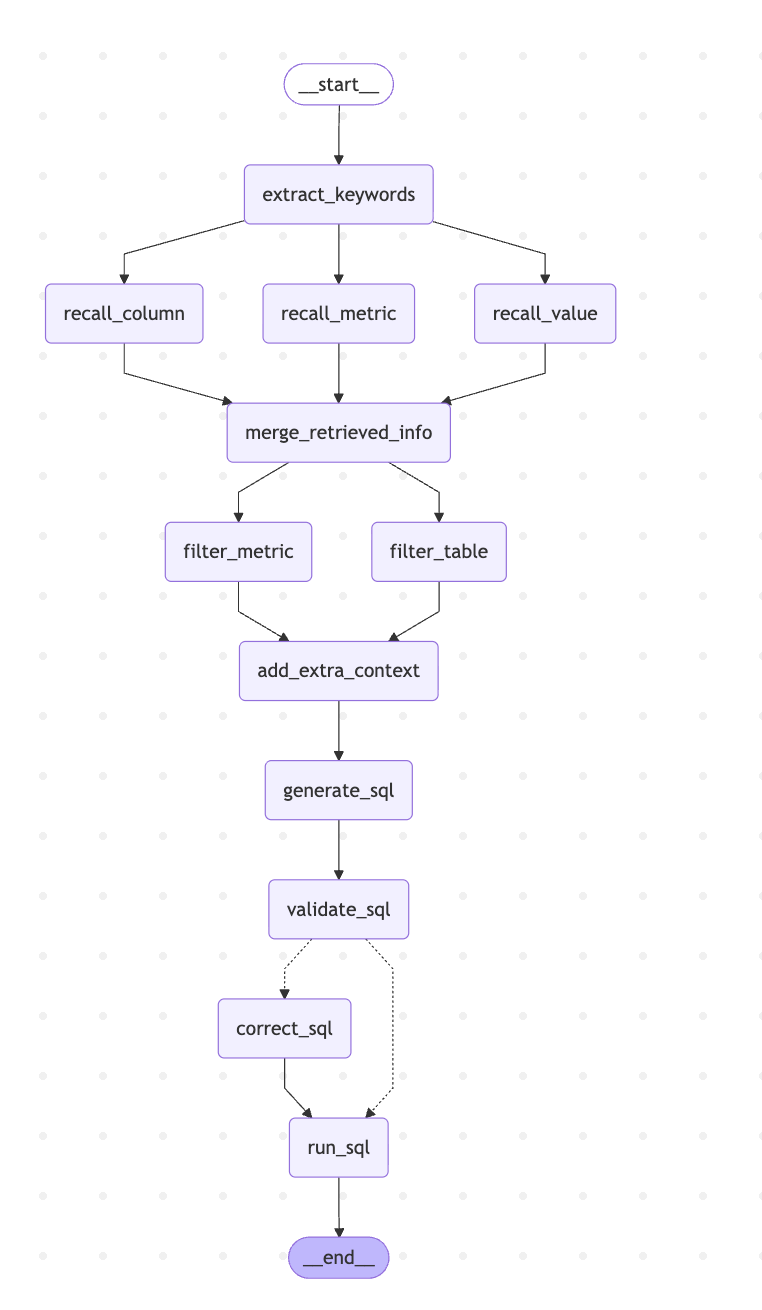
构建graph图
python
# 构建图
graph_builder = StateGraph(state_schema=DataAgentState, context_schema=DataAgentContext)
# 增加点
graph_builder.add_node("extract_keywords", extract_keywords)
graph_builder.add_node("recall_column", recall_column)
graph_builder.add_node("recall_value", recall_value)
graph_builder.add_node("recall_metric", recall_metric)
graph_builder.add_node("merge_retrieved_info", merge_retrieved_info)
graph_builder.add_node("filter_metric", filter_metric)
graph_builder.add_node("filter_table", filter_table)
graph_builder.add_node("add_extra_context", add_extra_context)
graph_builder.add_node("generate_sql", generate_sql)
graph_builder.add_node("validate_sql", validate_sql)
graph_builder.add_node("correct_sql", correct_sql)
graph_builder.add_node("run_sql", run_sql)
# 添加关系
graph_builder.add_edge(START, "extract_keywords")
graph_builder.add_edge("extract_keywords", "recall_column")
graph_builder.add_edge("extract_keywords", "recall_value")
graph_builder.add_edge("extract_keywords", "recall_metric")
graph_builder.add_edge("recall_column", "merge_retrieved_info")
graph_builder.add_edge("recall_value", "merge_retrieved_info")
graph_builder.add_edge("recall_metric", "merge_retrieved_info")
graph_builder.add_edge("merge_retrieved_info", "filter_table")
graph_builder.add_edge("merge_retrieved_info", "filter_metric")
graph_builder.add_edge("filter_table", "add_extra_context")
graph_builder.add_edge("filter_metric", "add_extra_context")
graph_builder.add_edge("add_extra_context", "generate_sql")
graph_builder.add_edge("generate_sql", "validate_sql")
# validate_sql到run_sql 和 validate_sql到correct_sql 已经由Command指定了
# 如果没有Command,就需要指定条件边
graph_builder.add_conditional_edges("validate_sql",
lambda state: "run_sql" if state["error"] is None else "correct_sql", {
"run_sql": "run_sql",
"correct_sql": "correct_sql",
})
graph_builder.add_edge("correct_sql", "run_sql")
graph_builder.add_edge("run_sql", END)
app = graph_builder.compile()
if __name__ == "__main__":
# 打印图结构(Mermaid 格式)
async def test():
state = DataAgentState(query="统计去年各地区的销售总额")
embedding_client_manager.init()
print(app.get_graph().draw_mermaid())
embedding_client = embedding_client_manager.client
context = DataAgentContext(embedding_client=embedding_client)
async for chunk in app.astream(input=state, context=context):
print(chunk)
asyncio.run(test())校验sql节点的流向有两种做法,一种是add_conditional_edges,条件边处理,一种是在节点里面使用Command对象,手动指定下一个节点流向何处。
可以看到,完全满足需求。
测试
python
if __name__ == "__main__":
# 打印图结构(Mermaid 格式)
async def test():
state = DataAgentState(query="统计去年各地区的销售总额")
dw_mysql_client_manager.init()
embedding_client_manager.init()
meta_mysql_client_manager.init()
qdrant_client_manager.init()
es_client_manager.init()
async with meta_mysql_client_manager.session_factory() as meta_session, dw_mysql_client_manager.session_factory() as dw_session:
# 这里操作数据库依然是repository层
meta_mysql_repository = MetaMySQLRepository(session=meta_session)
embedding_client = embedding_client_manager.client
column_qdrant_repository = ColumnQdrantRepository(client=qdrant_client_manager.client)
metric_qdrant_repository = MetricQdrantRepository(client=qdrant_client_manager.client)
value_es_repository = ValueEsRepository(client=es_client_manager.client)
dw_mysql_repository = DwMySQLRepository(session=dw_session)
context = DataAgentContext(embedding_client=embedding_client, meta_mysql_repository=meta_mysql_repository,
column_qdrant_repository=column_qdrant_repository,
metric_qdrant_repository=metric_qdrant_repository,
value_es_repository=value_es_repository,
dw_mysql_repository=dw_mysql_repository)
# stream_mode 打印自定义输出
async for chunk in app.astream(input=state, context=context, stream_mode=["custom"]):
print(chunk)
await meta_mysql_client_manager.close()
await qdrant_client_manager.close()
await es_client_manager.close()
await dw_mysql_client_manager.close()
asyncio.run(test())这里我们要初始化repository这些,然后将其作为上下文传入。流式返回我们使用custom格式化的数据,自己定义数据返回。
节点编写
抽取关键词
第一个节点:抽取关键词,这里使用了jieba中文分词器。

我们使用基于TF-IDF算法的关键词抽取
python
async def extract_keywords(state: DataAgentState, runtime: Runtime[DataAgentContext]):
writer = runtime.stream_writer
step = "抽取关键词"
try:
writer(StreamInfo(type="progress", step=step, status="running"))
query = state["query"]
# 对查询进行分词,只提取指定词性的词
allow_pos = (
"n", # 名词: 数据、服务器、表格
"nr", # 人名: 张三、李四
"ns", # 地名: 北京、上海
"nt", # 机构团体名: 政府、学校、某公司
"nz", # 其他专有名词: Unicode、哈希算法、诺贝尔奖
"v", # 动词: 运行、开发
"vn", # 名动词: 工作、研究
"a", # 形容词: 美丽、快速
"an", # 名形词: 难度、合法性、复杂度
"eng", # 英文
"i", # 成语
"l", # 常用固定短语
)
# 基于TF-IDF算法的关键词抽取
keywords = jieba.analyse.extract_tags(query, withWeight=False, topK=20, allowPOS=allow_pos)
# 去重
keywords = list(set(keywords + [query]))
writer(StreamInfo(type="progress", step=step, status="success"))
logger.info(f"抽取的关键词是 {keywords}")
return {"keywords": keywords}
except Exception as e:
writer({"type": "progress", "step": step, "status": "error"})
logger.error(f"抽取关键词报错: {str(e)}")
# 需要抛错误去
raise e对query进行分词得到关键词列表,去重。

可以看到正常处理。
召回字段信息
召回字段信息,主要就是根据对关键词进行向量化,然后去column_qdrant向量数据集中检索,得到相似度较高的数据,取其payload,也就是ColumnInfo,然后返回,最终得到一组list[ColumnInfo]
python
# 根据关键词向量检索召回,获取得到的ColumnInfo数组
async def recall_column(state: DataAgentState, runtime: Runtime[DataAgentContext]):
writer = runtime.stream_writer
step = "召回字段信息"
try:
writer(StreamInfo(type="progress", step=step, status="running"))
keywords = state["keywords"]
query = state["query"]
embedding_client = runtime.context["embedding_client"]
column_qdrant_repository = runtime.context["column_qdrant_repository"]
# 使用llm扩展关键词
prompt = PromptTemplate(template=load_prompt_template("extend_keywords_for_column_recall"),
input_variables=["query"])
output_str = JsonOutputParser()
chain = prompt | llm | output_str
async with llm_semaphore:
result = await chain.ainvoke({"query": query})
keywords = list(set(result + keywords))
# 使用扩展后的关键词召回字段信息
logger.info(f"召回信息扩展关键词: {keywords}")
# 去重
retrieved_columns_map: dict[str, ColumnInfo] = {}
for keyword in keywords:
# 转为向量,检索
embeddings = await embedding_client.aembed_query(keyword)
payloads: list[ColumnInfo] = await column_qdrant_repository.search(embeddings=embeddings)
for payload in payloads:
column_id = payload.id
if column_id not in retrieved_columns_map:
retrieved_columns_map[column_id] = payload
# 汇总 values返回的是远足
retrieved_columns = list(retrieved_columns_map.values())
logger.info(f"召回字段信息: {list(retrieved_columns_map.keys())}")
writer(StreamInfo(type="progress", step=step, status="success"))
return {
"retrieved_columns": retrieved_columns,
}
except Exception as e:
writer({"type": "progress", "step": step, "status": "error"})
logger.error(f"召回字段信息报错: {str(e)}")
raise e这里我们得到第一步抽取的关键词,然后再通过llm对问题再度进行关键词抽取,
这里的prompt大概是:

让其返回数组,然后通过链组成一个chain。得到关键词后进行去重。
接着,遍历关键词列表,对每一个关键词进行向量化,得到向量数组,然后调用column_qdrant_client.search
python
async def search(self, embeddings: list[float], score_threshold: float = 0.6, limit=5):
result = await self.client.query_points(
collection_name=self.collection_name,
query=embeddings,
# 相似度
score_threshold=score_threshold,
limit=limit,
)
# column向量检索数据存储 id,embeddings,payload,payload转为ColumnInfo格式
return [ColumnInfo(**point.payload) for point in result.points]通过query_points检索,score_threshold是相似度分数,这里大于0.6我们就返回,默认限制返回5条,将返回的数据取其payload然后拼成数组返回。
最后对column去重。得到

如上,关键词通过llm进行了扩展,然后通过向量检索得到了四个字段。
召回指标信息
跟召回字段信息类似
python
async def recall_metric(state: DataAgentState, runtime: Runtime[DataAgentContext]):
writer = runtime.stream_writer
step = "召回指标信息"
try:
writer(StreamInfo(type="progress", step=step, status="running"))
query = state["query"]
keywords = state["keywords"]
embedding_client = runtime.context["embedding_client"]
metric_qdrant_repository = runtime.context["metric_qdrant_repository"]
prompt = PromptTemplate(template=load_prompt_template("extend_keywords_for_metric_recall"),
input_variables=["query"])
output_str = JsonOutputParser()
chain = prompt | llm | output_str
# 扩展关键词
async with llm_semaphore:
result = await chain.ainvoke({"query": query})
keywords = list(set(result + keywords))
retrieved_metric_map: dict[str, MetricInfo] = {}
for keyword in keywords:
# 对关键词进行向量检索
embeddings = await embedding_client.aembed_query(keyword)
payloads: list[MetricInfo] = await metric_qdrant_repository.search(embeddings=embeddings)
for payload in payloads:
metric_id = payload.id
if metric_id not in retrieved_metric_map:
retrieved_metric_map[metric_id] = payload
retrieved_metric_infos = list(retrieved_metric_map.values())
logger.info(f"召回指标信息: {list(retrieved_metric_map.keys())}")
writer(StreamInfo(type="progress", step=step, status="success"))
return {
"retrieved_metrics": retrieved_metric_infos
}
except Exception as e:
writer({"type": "progress", "step": step, "status": "error"})
logger.error(f"召回指标信息报错: {str(e)}")
raise e先通过llm扩展关键词,然后向量召回,最后整合返回。
召回指标值数据
跟上面两个节点类似,只不过不是向量检索,是es检索
python
async def recall_value(state: DataAgentState, runtime: Runtime[DataAgentContext]):
writer = runtime.stream_writer
step = "召回字段取值"
try:
writer(StreamInfo(type="progress", step=step, status="running"))
query = state["query"]
keywords = state["keywords"]
value_es_repository = runtime.context["value_es_repository"]
prompt = PromptTemplate(template=load_prompt_template("extend_keywords_for_value_recall"),
input_variables=["query"])
output_str = JsonOutputParser()
chain = prompt | llm | output_str
# 扩展关键词
async with llm_semaphore:
result = await chain.ainvoke({"query": query})
keywords = list(set(result + keywords))
logger.info(f"keywords==: {keywords}")
values_map: dict[str, ValueInfo] = {}
for keyword in keywords:
values = await value_es_repository.search(keyword=keyword)
for value in values:
if value.id not in values_map:
values_map[value.id] = value
retrieved_values: list[ValueInfo] = list(values_map.values())
logger.info(f"召回字段取值:{list(values_map.keys())}")
writer(StreamInfo(type="progress", step=step, status="success"))
return {
"retrieved_values": retrieved_values
}
except Exception as e:
writer({"type": "progress", "step": step, "status": "error"})
logger.error(f"召回字段取值报错: {str(e)}")
raise e
async def search(self, keyword: str, limit=5, score_threshold: float = 0.6):
# es 存储的数据是 id value column_id
resp = await self.client.search(
index=self.index_name,
query={
"match": {
"value": keyword,
}
},
size=limit,
min_score=score_threshold,
)
return [ValueInfo(**hit["_source"]) for hit in resp["hits"]["hits"]]通过llm扩展后,根据es搜索召回
合并召回信息
合并召回信息,主要是将得到的column_infos,指标信息metric_infos,以及es取到的value_infos
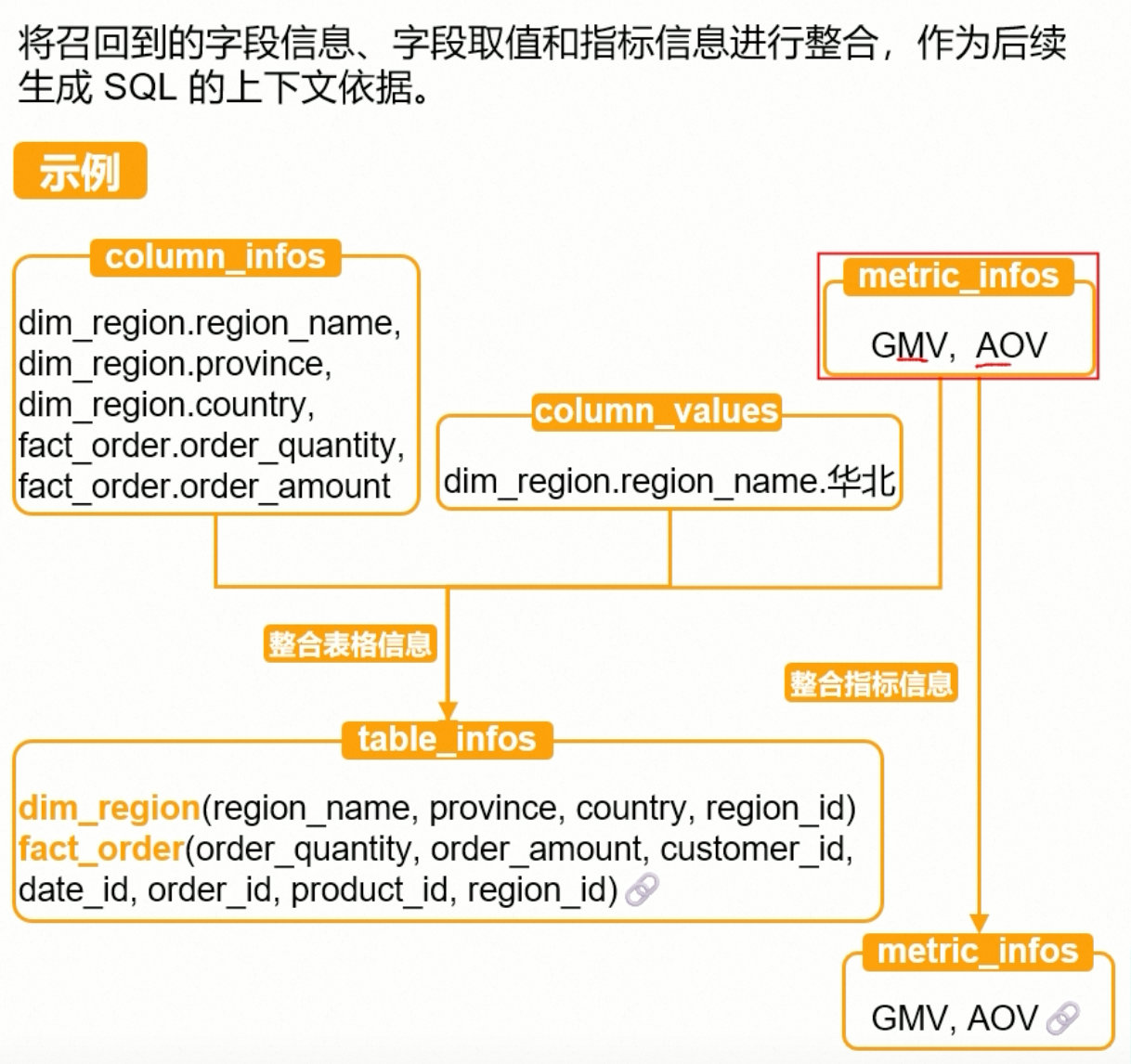
python
# 合并找回信息,首先,将得到的ColumnInfo,ValueInfo数组,合并为table_infos表信息,将MetricInfo合并为metric_infos表信息
# columnInfo 有多少表格,然后整合,valueInfo,判断是哪个表格哪个字段的,将value放到examples中,如果没有的话,就得新增table或者column,metricInfo,GMV/AOV都有对应的column.id,也需要同步
# metricInfo整合得到对应元数据库中metric_info的数据
async def merge_retrieved_info(state: DataAgentState, runtime: Runtime[DataAgentContext]):
writer = runtime.stream_writer
step = "合并召回信息"
try:
writer(StreamInfo(type="progress", step=step, status="running"))
retrieved_columns = state["retrieved_columns"]
retrieved_metrics = state["retrieved_metrics"]
retrieved_values = state["retrieved_values"]
meta_mysql_repository = runtime.context["meta_mysql_repository"]
retrieved_columns_map = {retrieved_column.id: retrieved_column for retrieved_column in retrieved_columns}
# 合并指标信息到column中
for retrieved_metric in retrieved_metrics:
for column_id in retrieved_metric.relevant_columns:
if column_id not in retrieved_columns_map:
# 不存在已有的column列表,需要添加,meta元数据库的column_info的id就是表名.列名
column_info = await meta_mysql_repository.get_column_info_by_id(column_id)
retrieved_columns_map[retrieved_metric.id] = column_info
# 将字段取值同步到字段信息列表中examples字段
for retrieved_value in retrieved_values:
column_id = retrieved_value.column_id
if column_id not in retrieved_columns_map:
column_info = await meta_mysql_repository.get_column_info_by_id(column_id)
retrieved_columns_map[column_id] = column_info
if retrieved_value.value not in retrieved_columns_map[column_id].examples:
retrieved_columns_map[column_id].examples.append(retrieved_value.value)
# 整合column为table_infos
table_to_column_map: dict[str, list[ColumnInfo]] = {}
for column in retrieved_columns_map.values():
table_id = column.table_id
if table_id not in table_to_column_map:
table_to_column_map[table_id] = []
table_to_column_map[table_id].append(column)
# 每个表的主外键 描述可能不够清晰,不可以很好的召回,给用到的每个表都显式添加主外建信息,后面过滤信息的时候再过滤
for table_id in table_to_column_map.keys():
# 查询主键字段
column_infos = await meta_mysql_repository.get_key_columns_by_table_id(table_id=table_id)
# 当前表已有的所有列的ID
column_ids = [column.id for column in table_to_column_map[table_id]]
for column_info in column_infos:
if column_info.id not in column_ids: # 主外建不存在
table_to_column_map[table_id].append(column_info)
table_infos: list[TableInfoGraphState] = []
# 将table_id -> columnInfo 映射,专程我们的 list[TableInfoGraphState]表数组数据
for table_id, column_infos in table_to_column_map.items():
table: TableInfo = await meta_mysql_repository.get_table_info_by_id(table_id=table_id)
# 收集table的columns
columns = [
# 不需要id和table_id
ColumnInfoGraphState(
name=column.name,
type=column.type,
role=column.role,
examples=column.examples,
description=column.description,
alias=column.alias,
)
for column in column_infos
]
table_infos.append(
# 不需要id和新增columns列表
TableInfoGraphState(
columns=columns,
name=table.name,
role=table.role,
description=table.description,
)
)
# 至此,table_infos的数据整合完毕
# 整合指标信息
metric_infos: list[MetricInfoGraphState] = [
MetricInfoGraphState(
name=metric_info.name,
description=metric_info.description,
relevant_columns=metric_info.relevant_columns,
alias=metric_info.alias
) for metric_info in retrieved_metrics
]
logger.info(f"合并召回信息,收集到表数据: {[table['name'] for table in table_infos]}")
logger.info(f"合并召回信息,收集到指标表数据: {[metric_info['name'] for metric_info in metric_infos]}")
writer(StreamInfo(type="progress", step=step, status="success"))
return {
"table_infos": table_infos,
"metric_infos": metric_infos,
}
except Exception as e:
writer({"type": "progress", "step": step, "status": "error"})
logger.error(f"合并召回信息报错: {str(e)}")
raise e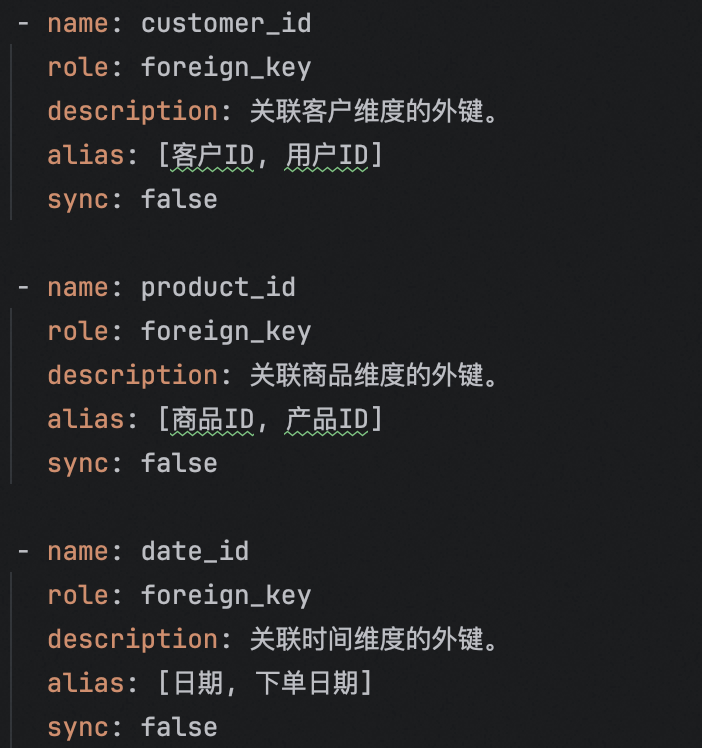
其中,主外键的描述可能不够清晰,会导致召回不到,所以这里先显式加上所有的主外键,后续过滤的时候过滤掉没用的。
过滤表信息节点
借助LLM将合并到的数据进行过滤。
python
async def filter_table(state: DataAgentState, runtime: Runtime[DataAgentContext]):
writer = runtime.stream_writer
step = "过滤表格信息"
try:
writer(StreamInfo(type="progress", step=step, status="running"))
table_infos = state["table_infos"]
query = state["query"]
prompt = PromptTemplate(template=load_prompt_template("filter_table_info"),
input_variables=["query", "table_infos"])
output_parser = JsonOutputParser()
chain = prompt | llm | output_parser
async with llm_semaphore:
result = await chain.ainvoke({
"query": query,
"table_infos": yaml.dump(table_infos, allow_unicode=True, sort_keys=False) # 将list数组转为yaml格式,方便llm查看
})
# 利用模型输出过滤table_infos
# {
# 'fact_order':['order_amount', 'region_id'],
# 'dim_region':['region_id', 'region_name']
# }
# 将大模型觉得不合理的去掉
for table_info in table_infos[:]:
if table_info["name"] not in result:
table_infos.remove(table_info)
else:
for column in table_info["columns"][:]:
if column["name"] not in result[table_info["name"]]:
table_info["columns"].remove(column)
logger.info(f"过滤后的表格信息: {[table["name"] for table in table_infos]}")
writer(StreamInfo(type="progress", step=step, status="success"))
return {
"table_infos": table_infos
}
except Exception as e:
writer({"type": "progress", "step": step, "status": "error"})
logger.error(f"过滤表格信息报错: {str(e)}")
raise e让大模型过滤一些没有用的字段,然后再去掉。
过滤指标信息
过滤指标信息跟过滤表格信息一样
python
async def filter_metric(state: DataAgentState, runtime: Runtime[DataAgentContext]):
writer = runtime.stream_writer
step = "过滤指标信息"
try:
writer(StreamInfo(type="progress", step=step, status="running"))
metric_infos = state["metric_infos"]
query = state["query"]
prompt = PromptTemplate(template=load_prompt_template("filter_metric_info"),
input_variables=["query", "metric_infos"])
output_parser = JsonOutputParser()
chain = prompt | llm | output_parser
async with llm_semaphore:
result = await chain.ainvoke({
"query": query,
"metric_infos": yaml.dump(metric_infos, allow_unicode=True, sort_keys=False) # 将list数组转为yaml格式,方便llm查看
})
# 利用模型输出过滤metric_infos ["x"]
# 将大模型觉得不合理的去掉
for metric_info in metric_infos[:]:
if metric_info["name"] not in result:
metric_infos.remove(metric_info)
logger.info(f"过滤后的指标信息: {[metric_info["name"] for metric_info in metric_infos]}")
writer(StreamInfo(type="progress", step=step, status="success"))
return {
"metric_infos": metric_infos
}
except Exception as e:
writer({"type": "progress", "step": step, "status": "error"})
logger.error(f"过滤指标信息报错: {str(e)}")
raise e只不过大模型返回的指标数据是数组。
增加额外上下文 节点
只需要增加数据仓库的信息+当前询问的日期信息
python
async def add_extra_context(state: DataAgentState, runtime: Runtime[DataAgentContext]):
writer = runtime.stream_writer
step = "增加额外上下文"
try:
writer(StreamInfo(type="progress", step=step, status="running"))
dw_mysql_repository = runtime.context["dw_mysql_repository"]
# 增加当前时间/季度,数据库相关信息
today = datetime.today()
date = today.strftime("%Y-%m-%d")
weekday = today.strftime("%A")
quarter = f"Q{(today.month - 1) // 3 + 1}"
date_info = DateInfoState(date=date, weekday=weekday, quarter=quarter)
# 数仓环境信息
db_info = await dw_mysql_repository.get_db_info()
logger.info(f"额外上下文信息: 数据库信息-{db_info}, 日期信息-{date_info}")
writer(StreamInfo(type="progress", step=step, status="success"))
return {
"db_info": db_info,
"date_info": date_info
}
except Exception as e:
writer({"type": "progress", "step": step, "status": "error"})
logger.error(f"增加额外上下文报错: {str(e)}")
raise e生成sql 节点
我们已经具备所有信息了,可以将其交给大模型生成sql了
python
async def generate_sql(state: DataAgentState, runtime: Runtime[DataAgentContext]):
writer = runtime.stream_writer
step = "生成SQL"
try:
writer(StreamInfo(type="progress", step=step, status="running"))
query = state["query"]
table_infos = state["table_infos"]
metric_infos = state["metric_infos"]
db_info = state["db_info"]
date_info = state["date_info"]
prompt = PromptTemplate(template=load_prompt_template("generate_sql"),
input_variables=["query", "table_infos", "metric_infos", "db_info", "date_info"])
output_parser = StrOutputParser()
chain = prompt | llm | output_parser
async with llm_semaphore:
sql = await chain.ainvoke({
"query": query,
"table_infos": yaml.dump(table_infos),
"metric_infos": yaml.dump(metric_infos),
"db_info": yaml.dump(db_info),
"date_info": yaml.dump(date_info),
})
logger.info(f"生成的SQL: {sql}")
writer(StreamInfo(type="progress", step=step, status="success"))
return {
"sql": sql
}
except Exception as e:
writer({"type": "progress", "step": step, "status": "error"})
logger.error(f"生成SQL报错: {str(e)}")
raise e如上,将query,召回的表信息table_infos,召回的metric_infos,还有数仓信息,当前日期信息一起交给大模型。生成sql返回。
校验sql 节点
python
async def validate_sql(state: DataAgentState, runtime: Runtime[DataAgentContext]):
writer = runtime.stream_writer
step = "校验SQL"
try:
writer(StreamInfo(type="progress", step=step, status="running"))
sql = state["sql"]
dw_mysql_repository = runtime.context["dw_mysql_repository"]
try:
await dw_mysql_repository.validate_sql(sql)
logger.info(f"SQL验证成功")
writer(StreamInfo(type="progress", step=step, status="success"))
return {"error": None}
except Exception as ex:
logger.error(f"SQL验证失败: {str(ex)}")
writer(StreamInfo(type="progress", step=step, status="success"))
return {"error": str(ex)}
except Exception as e:
writer({"type": "progress", "step": step, "status": "error"})
logger.error(f"校验SQL报错: {str(e)}")
raise e直接使用explain spl来判断当前sql有没有问题。
有问题,直接返回error:xx到重新生成sql节点,没问题的话,可以直接到执行sql节点。
修正sql
python
async def correct_sql(state: DataAgentState, runtime: Runtime[DataAgentContext]):
writer = runtime.stream_writer
step = "修正SQL"
try:
writer(StreamInfo(type="progress", step=step, status="running"))
sql = state["sql"]
error = state["error"]
query = state["query"]
table_infos = state["table_infos"]
metric_infos = state["metric_infos"]
db_info = state["db_info"]
date_info = state["date_info"]
prompt = PromptTemplate(template=load_prompt_template("correct_sql"),
input_variables=["sql", "error", "query", "table_infos", "metric_infos", "db_info",
"date_info"])
output_parser = StrOutputParser()
chain = prompt | llm | output_parser
async with llm_semaphore:
result = await chain.ainvoke({
"sql": sql,
"query": query,
"error": error,
"table_infos": yaml.dump(table_infos),
"metric_infos": yaml.dump(metric_infos),
"db_info": yaml.dump(db_info),
"date_info": yaml.dump(date_info)
})
logger.info(f"修正后的SQL: {result}")
writer(StreamInfo(type="progress", step=step, status="success"))
return {
"sql": result
}
except Exception as e:
writer({"type": "progress", "step": step, "status": "error"})
logger.error(f"修正SQL报错: {str(e)}")
raise e修正sql节点主要是将生成的sql+错误信息+所有数据,都交给大模型让他重新生成。
执行sql节点
python
async def run_sql(state: DataAgentState, runtime: Runtime[DataAgentContext]):
writer = runtime.stream_writer
step = "执行SQL"
try:
writer(StreamInfo(type="progress", step=step, status="running"))
sql = state["sql"]
dw_mysql_repository = runtime.context["dw_mysql_repository"]
result = await dw_mysql_repository.execute_sql(sql)
logger.info(f"执行SQL结果: {result}")
writer(StreamInfo(type="progress", step=step, status="success"))
return {"result": result}
except Exception as e:
writer({"type": "progress", "step": step, "status": "error"})
logger.error(f"执行SQL报错: {str(e)}")
raise e
async def execute_sql(self, sql):
result = await self.session.execute(text(sql))
# mappings将每一行转为{id:xx,name:xx,}这种数据,否则默认是 (xx,xx,xx)
# 将返回的数据转为dict数据
return [dict(row) for row in result.mappings().fetchall()]执行sql就是直接exeute(text(sql)),然后将结果返回即可。
执行结果:
集成FastApi
fastapi,中间件,生命周期跟express差不多。
也有DI依赖注入的概念,只不过fastapi的依赖注入不是单例,他只是在一个请求里面是单例。
python
# 这是一个示例 Python 脚本。
import uuid
from fastapi import FastAPI, Request
from app.api.routers.query_router import query_router
from app.core.context import request_id_ctx_var
from app.core.lefespan import lifespan
# 添加生命周期函数
app = FastAPI(lifespan=lifespan)
# 注册路由,类似于app.use
app.include_router(query_router)
# 中间件
@app.middleware("http")
async def add_process_time_header(request: Request, call_next):
# 调用路径函数之前,往每个请求注入独立变量
request_id_ctx_var.set(uuid.uuid4())
# 调用路径函数
response = await call_next(request)
# 调用路径函数之后
return response
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)我们需要使用FastAPI创建一个app,然后在app启动之前和之后做一些实例的初始化和关闭。
python
@asynccontextmanager
async def lifespan(app: FastAPI):
# FastAPI启动前执行
embedding_client_manager.init()
qdrant_client_manager.init()
es_client_manager.init()
meta_mysql_client_manager.init()
dw_mysql_client_manager.init()
# 启动状态
yield
# FastApi关闭前运行
await qdrant_client_manager.close()
await es_client_manager.close()
await meta_mysql_client_manager.close()
await dw_mysql_client_manager.close()然后中间件主要是在调用函数之前,为每个请求注入唯一的id,在py中,每个请求就是一个协程,类似于java每个请求是一个线程一样,py可以使用
python
from contextvars import ContextVar
request_id_ctx_var = ContextVar("request_id", default="1")ContextVar为每个请求注入单独的request_id,类似于java的Thread。
最后则是注册路由
python
@query_router.post("/api/query")
async def query(
query: QueryDTO,
# Depends依赖注入,每一个请求都会通过get_query_service创建一个新的实例
query_service: QueryService = Depends(get_query_service),
):
# 流式返回
return StreamingResponse(
query_service.query(query.query), media_type="text/event-stream",
)这里使用StreamingResponse流式返回,然后使用Depends依赖注入,每个单独的请求,都会调用get_query_service创建QuerySerivce实例,java则是单一实例。
甚至可以使用嵌套注入
python
async def get_metric_qdrant_repository():
return MetricQdrantRepository(qdrant_client_manager.client)
async def get_meta_mysql_repository(session: AsyncSession = Depends(get_meta_session)):
return MetaMySQLRepository(session)
async def get_dw_mysql_repository(session: AsyncSession = Depends(get_dw_session)):
return DwMySQLRepository(session)
async def get_query_service(
# # 嵌套依赖注入
embedding_client: HuggingFaceEndpointEmbeddings = Depends(get_embedding_client),
column_qdrant_repository: ColumnQdrantRepository = Depends(get_column_qdrant_repository),
value_es_repository: ValueEsRepository = Depends(get_value_es_repository),
metric_qdrant_repository: MetricQdrantRepository = Depends(get_metric_qdrant_repository),
meta_mysql_repository: MetaMySQLRepository = Depends(get_meta_mysql_repository),
dw_mysql_repository: DwMySQLRepository = Depends(get_dw_mysql_repository)
) -> QueryService:
return QueryService(
embedding_client=embedding_client,
column_qdrant_repository=column_qdrant_repository,
value_es_repository=value_es_repository,
metric_qdrant_repository=metric_qdrant_repository,
meta_mysql_repository=meta_mysql_repository,
dw_mysql_repository=dw_mysql_repository,
)如上,get_query_service又依赖get_embedding_client这些。
这里实现的是controller层,我们还需要实现逻辑Service层。
python
class QueryService:
def __init__(self,
embedding_client: HuggingFaceEndpointEmbeddings,
column_qdrant_repository: ColumnQdrantRepository,
value_es_repository: ValueEsRepository,
metric_qdrant_repository: MetricQdrantRepository,
meta_mysql_repository: MetaMySQLRepository,
dw_mysql_repository: DwMySQLRepository):
self.embedding_client = embedding_client
self.column_qdrant_repository = column_qdrant_repository
self.value_es_repository = value_es_repository
self.metric_qdrant_repository = metric_qdrant_repository
self.meta_mysql_repository = meta_mysql_repository
self.dw_mysql_repository = dw_mysql_repository
async def query(self, query: str):
context = DataAgentContext(
embedding_client=self.embedding_client,
column_qdrant_repository=self.column_qdrant_repository,
value_es_repository=self.value_es_repository,
metric_qdrant_repository=self.metric_qdrant_repository,
meta_mysql_repository=self.meta_mysql_repository,
dw_mysql_repository=self.dw_mysql_repository
)
state = DataAgentState(query=query)
try:
async for chunk in app.astream(input=state, context=context, stream_mode=["custom"]):
# SSE发送格式: \n\n, yield每次都会往前端推数据
print("chunk==", chunk)
yield f"data: {json.dumps(chunk, ensure_ascii=False, default=str)}\n\n"
except Exception as e:
# 接收每个节点的报错
yield f"data: {json.dumps({"type": "error", "message": str(e)}, ensure_ascii=False, default=str)}\n\n"因为我们是流式输出,这里需要使用yield返回数据,约定数据格式为{type:xx}这样。
这样一个简单的接口就做好了。
前端实现
因为使用sse
SSE 原理
SSE(Server-Sent Events)是一种单向的服务器推送协议,建立在普通 HTTP 之上。
关键特性:
连接由客户端发起,之后服务端持续往里写数据,连接不关闭
基于 text/event-stream MIME 类型
天然支持断线重连(浏览器自动重试)
只能服务端 → 客户端,不能反向
前端的实现方式:
原生 EventSource(只支持 GET)
js
const es = new EventSource('/api/query')
es.addEventListener('custom', (e) => {
const event = JSON.parse(e.data)
// { type: 'progress', step: '...', status: '...' }
})
es.onerror = () => es.close()局限:只能 GET,不能携带 body,无法传查询参数,实际项目中用得少。
方式二:fetch + ReadableStream(本项目用的)
js
const response = await fetch('/api/query', {
method: 'POST',
body: JSON.stringify({ query: text }),
})
const reader = response.body!.getReader()
const decoder = new TextDecoder()
let buffer = ''
while (true) {
const { done, value } = await reader.read() // ① 分块读取二进制
if (done) break
buffer += decoder.decode(value, { stream: true }) // ② 解码,stream:true 处理跨块 UTF-8
const lines = buffer.split('\n')
buffer = lines.pop() ?? '' // ③ 最后一行可能不完整,留到下次拼接
for (const line of lines) {
if (!line.startsWith('data:')) continue // ④ 跳过 event:/id:/空行
const raw = line.slice(5).trim()
const parsed = JSON.parse(raw) // ⑤ 解析 JSON
yield parsed[1] // ⑥ 本项目后端包了一层数组
}
}stream: true 是关键:TCP 包边界不一定在字符边界,一个中文字可能被截成两个 chunk,TextDecoder 需要知道"还没结束"才能正确解码。
效果:
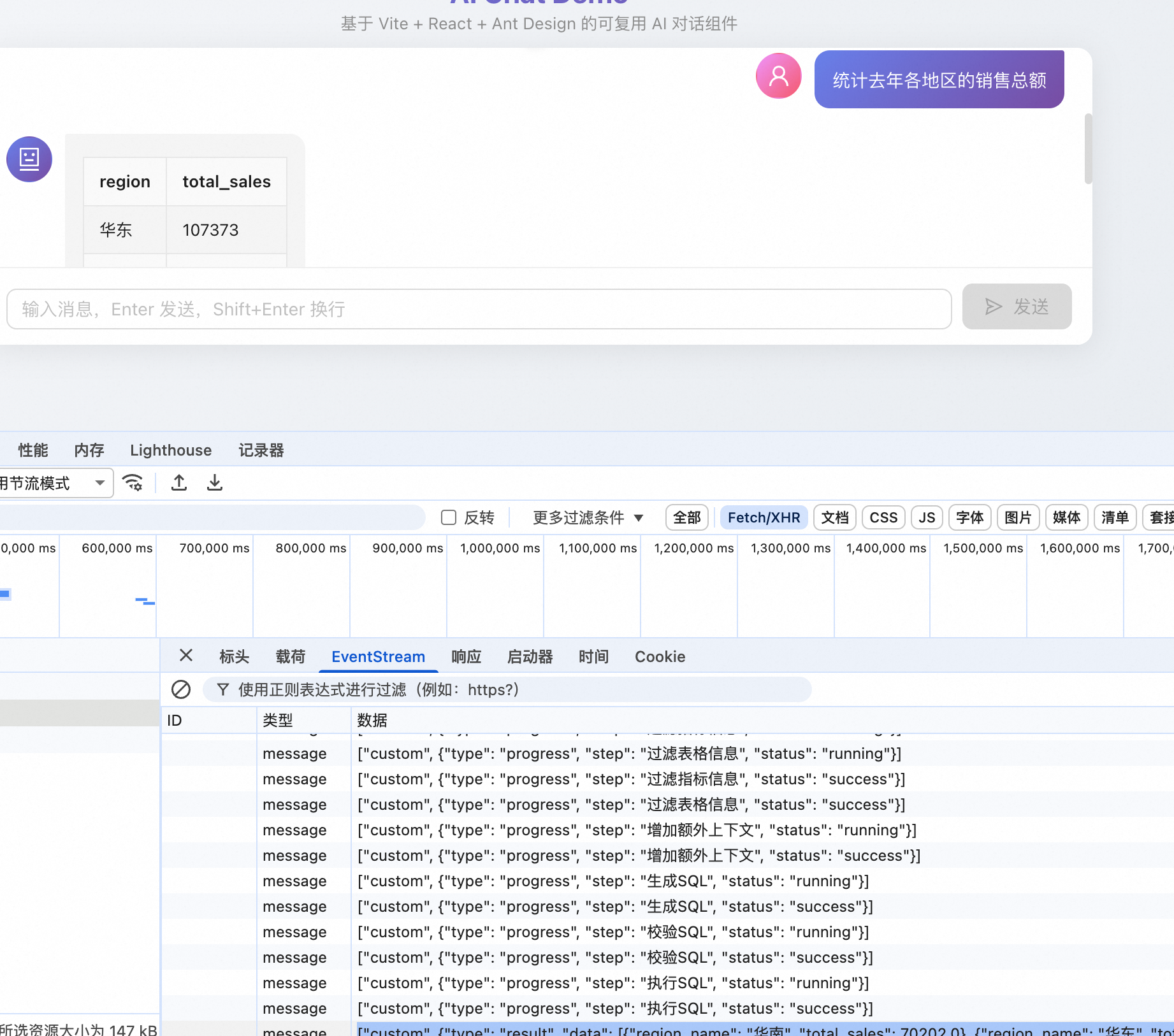
下面是一条一条推送的,所以我们展示的时候也是一步骤一步骤展示的。
这个项目还需要做很多扩展,比如
- 记忆模式
- 节点错误重试
- 问题召回
- ...
后续有空继续研究