位图
在处理海量数据(如 40 亿个整数)时,传统的哈希表、set容器等等会消耗大量内存,这显然是不划算的。如果能用40亿个比特位 来表示从0到40亿是否存在 (0不存在,1存在),就能节省大量空间,这就涉及到了位图
所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常用于判断某个数据是否存在。
位图原理
我们通常使用一个int数组来实现位图。一个 int 有 32 个比特位,所以1个int可以表示32个数字的状态。于是可按下面方式进行映射。
- 第 0 个 int (
bits[0]) :负责管理数字 0 ~ 31 - 第 1 个 int (
bits[1]) :负责管理数字 32 ~ 63 - 第 N 个 int (
bits[N]):负责管理数字 **N*32 ~ (N+1)*32 - 1**
关键算法:定位与操作
按上述方式,若要在位图中增删数字 x,还得解决两个问题:
- 它在数组的哪个下标? (确定是第几个
int) - 它在 int 的第几个比特位?(确定是第几位)
这就用到了简单的数学运算:
数组下标 :i = x / 32 ,比特位 :j = x % 32, 比如78应被下标2上的数字表示,位于第12个比特位。
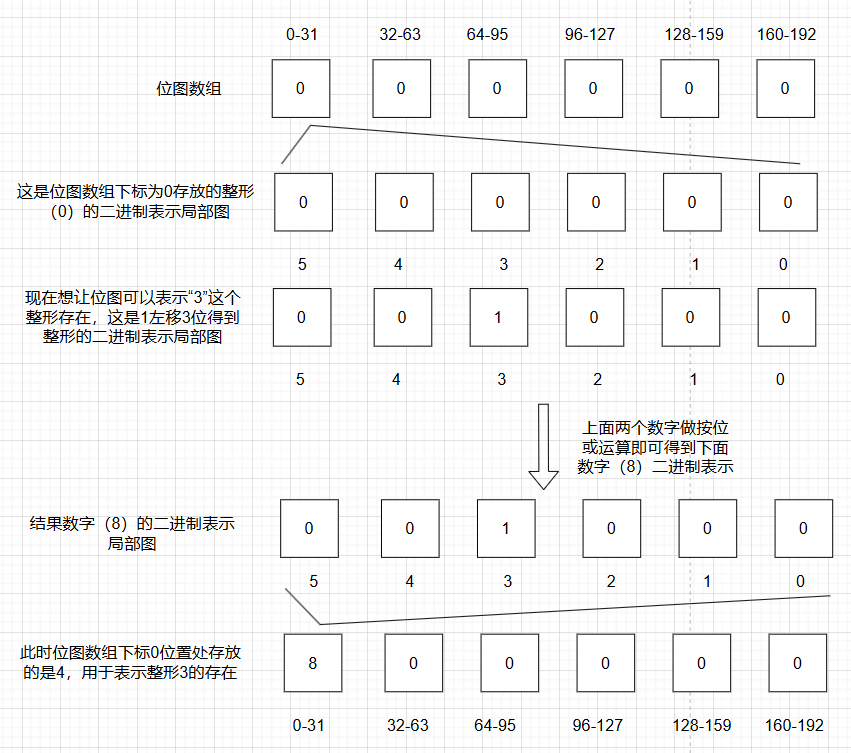
确定第几位后,实际中还需要通过位移和位运算实现更改,下面演示在位图中插入3
- 定位 :
- 数组下标:
3 / 32 = 0,所以操作bits[0]。 - 比特位置:
3 % 32 = 3,所以操作第 3 位。
- 数组下标:
- 操作 :
- 将数字
1左移 3 位:0000...00001000 - 与
bits[0]进行**按位或(|)**运算。
- 将数字
- **结果:**位图数组下标0位置处变成了8,用于表示0-31中只有3存在。
操作流程简略图:
插入函数的代码实现
cpp
void set(size_t input) {
//确认在数组的的哪个位置
size_t pos = input / 32;//
//确认在第几个比特位,同时进行或等运算
_table[pos] |= (1 << (input % 32));
}如果要在位图中删除某数字 ,定位方法和插入一致,但1左移后要取反 ,再用取反的结果和原数据做按位与运算,从而保证其它数字的状态不被改变

删除代码的函数实现
cpp
void reset(size_t input) {
size_t pos = input / 32;
_table[pos] &= ~(1 << (input % 32));
}如果要查询位图中某个数字是否存在,定位方法不变,根据按位与运算得到的结果是否为0判断
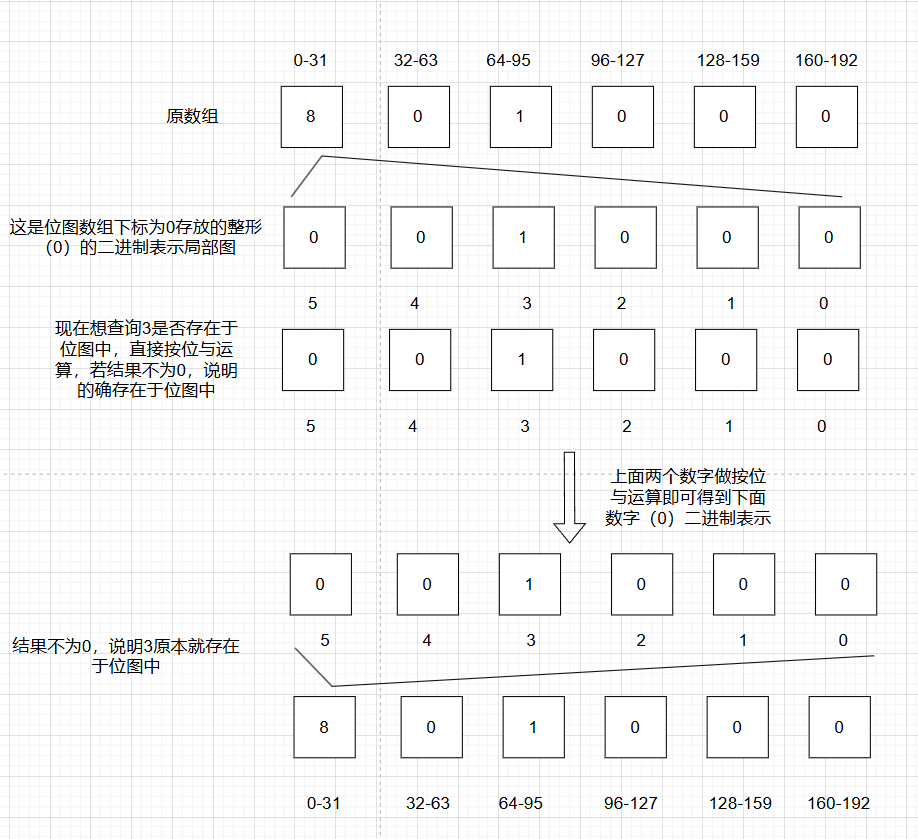
检查是否存在的函数实现
cpp
bool test(size_t input) {
size_t pos = input / 32;
size_t temp = _table[pos];
if (temp & (1 << (input % 32))) {//如果不为0说明存在
return true;
}
return false;
}位图应用:
找出整形数组中仅出现一次的数:
用两个位图A,B表示数据存在状况,遍历数组并做以下操作:
- 数据第一次在数组中被找到时,在位图A中插入该数字,位图B不做变动
- 第二次出现时,将位图A中删除该数字,在位图B中插入该数字
- 第三次及以后出现不做任何改动
最后在位图A中存在的数字表明只出现过一次,下面给出解决方案
cpp
//找仅出现一次的数
template< size_t N>
class twoBitmap {
public:
twoBitmap(const vector<size_t>& input) {
_input = input;
}
void set(size_t input){
//判断数据在两个位图中的标记状态,从而进行状态更改
if (!_bm1.test(input) && !_bm2.test(input)) {
_bm1.set(input);
}
else if (_bm1.test(input) && !_bm2.test(input)) {
_bm1.reset(input);
_bm2.set(input);
}
else {
return;
}
}
//所有答案要输出到一个数组里面
void test() {
for (auto i : _input) {
if (_bm1.test(i) && !_bm2.test(i)) {
cout << i << endl;
}
}
}
private:
vector<size_t>_input;
Bitmap<N> _bm1;
Bitmap<N> _bm2;
};寻找两个数组的交集:
将两个数组分别映射到两个位图上,然后遍历这两个位图,如果都为1说明在这两个数组中都存在
布隆过滤器
位图针对整数操作,而布隆过滤器则是以位图为底层的,可将多种类型存入到位图中的一种结构
实现原理:
布隆过滤器需要用户指定哈希函数,通过哈希函数将数据转换成关键码,再将关键码存入位图中即可。
如何能避免两个不同数据关键码相同时引发的误判?(如下图所示)
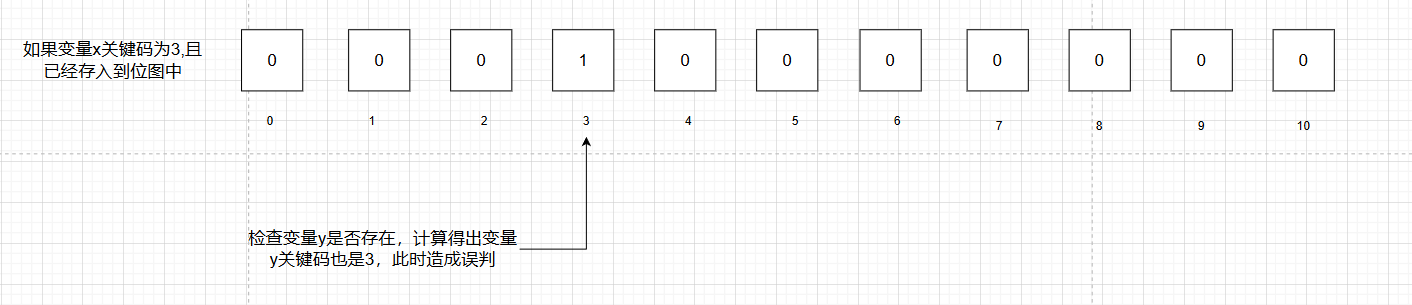
解决方法,使用三个哈希函数把同一个数据转换成三个关键码,再将关键码在位图中分别标记,在判断是否存在时,如果检测到位图这三个关键码下标存放的都是1,说明该数据存在。下图演示一个非整形如何存放到布隆过滤器中。
注意,这种方法不能完美解决 重复的问题,但大幅降低重复的概率 (三个哈希函数对不同数据计算出相同的三个关键码概率低)通过增加哈希函数的数量可进一步减小误判的概率。
此外,使用布隆过滤器验证数据的存在,有可能引发误判,但验证数据不存在是完全没有问题的。
布隆过滤器的实现:
以string类型为例,给出三个针对string的哈希函数
cpp
1. DJB2 Hash
//公式 hash = hash * 33 +
struct DJB2Hash {
size_t operator()(const std::string& str) const {
unsigned long hash = 5381; // 初始种子值
for (char c : str) {
// hash * 33 可以写成 (hash << 5) + hash,位运算更快
hash = ((hash << 5) + hash) + c;
}
return hash;
}
};
// 2. SDBM Hash
// 公式 hash = hash * 65599 + c (65599 是一个质数)
struct SDBMHash {
size_t operator()(const std::string& str) const {
unsigned long hash = 0;
for (char c : str) {
hash = c + (hash << 6) + (hash << 16) - hash;
// 等价于 hash = c + hash * 65599
}
return hash;
}
};
// 3. BKDR Hash
// 公式 hash = hash * 131 + c
struct BKDRHash {
size_t operator()(const std::string& str) const {
unsigned long long hash = 0;
const int seed = 131;
for (char c : str) {
hash = hash * seed + c;
}
return (size_t)(hash & 0x7FFFFFFF); // 确保返回非负数(视具体需求而定)
}
};下面给出针对string类型的布隆过滤器的不完全实现:
注:布隆过滤器有固定大小 ,而关键码计算结果可能远大于这个大小,所以每次得到的关键码需要模大小。
cpp
template<size_t N,class T =string,class hash1=DJB2Hash,class hash2=SDBMHash,class hash3=BKDRHash>
class Bloomfilter {
public:
//思路
//在位图中分别标记相应的关键码
void set(const T& input) {
_bloomfilter.set(hash1()(input) % N) ;
_bloomfilter.set(hash2()(input) % N) ;
_bloomfilter.set(hash3()(input) % N) ;
}
//在位图中分别删除相应的关键码,实际上这样行不通,见下文
void reset(const T& input) {
_bloomfilter.reset(hash1()(input) % N) ;
_bloomfilter.reset(hash2()(input) % N) ;
_bloomfilter.reset(hash3()(input) % N) ;
}
//若要检测某个值存在与否,在位图中分别检测相应的关键码,全在则该值存在
bool test(const T& input) {
if(_bloomfilter.test(hash1()(input) % N)
&& _bloomfilter.test(hash2()(input) % N)
&& _bloomfilter.test(hash3()(input) % N)
) {
return true;
}
return false;
}
private:
Bitmap<N> _bloomfilter;
};注意,上面代码的删除其实并不正确:比如a和b都映射到了位图上同一个位置,删除a的时候导致b的映射也被删除了!真正的删除需要用计数器记录位图每个位置被标记了几次,但计数本身需要占用内存,又和位图减少内存消耗的初衷相悖。这里不做代码演示。
关于布隆过滤器的容量设置
已知布隆过滤器一个数据要在位图上标注三个位置,容量不大的情况下,误判概率高,如下图所示
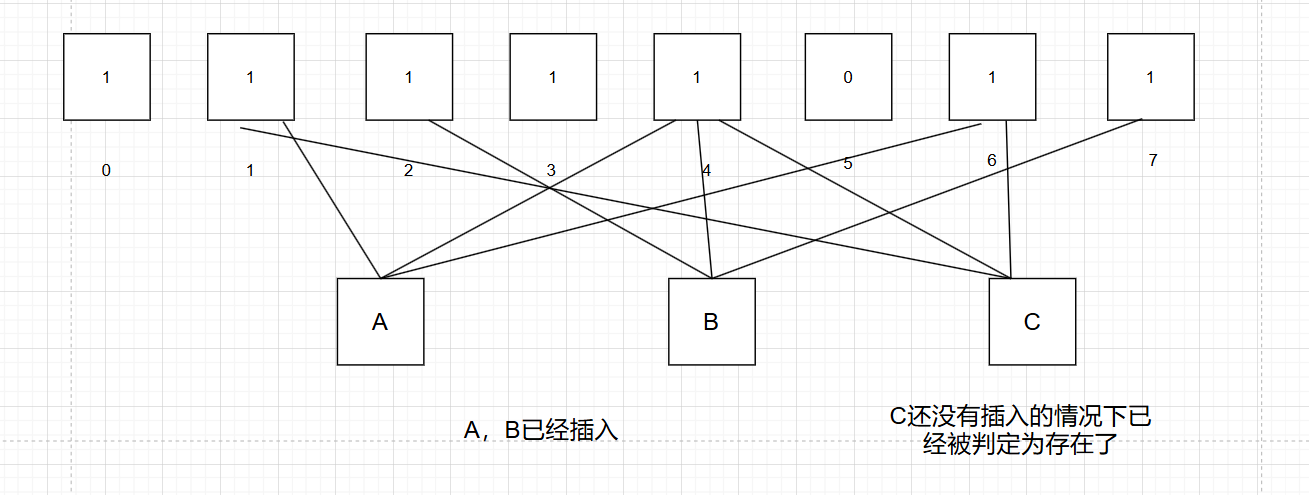
于是有人研究了位图容量和数据量的大小指定多少较优,一般来说,大小是元素个数的五倍左右误判的概率大幅降低。