 图1:JVM运行时数据区全景图
图1:JVM运行时数据区全景图
作者:洛水石
标签:#Java面试 #JVM #内存模型 #GC算法 #垃圾回收 #JVM调优
一、这道题为什么常问?
JVM 是 Java 程序员绕不开的核心知识,也是面试中的高频考点。中高级岗位通常会从以下几个维度考察:
- JVM 内存区域划分及其作用
- 对象创建与内存分配机制
- 垃圾回收算法(标记清除、复制、标记整理)
- 分代收集理论(年轻代、老年代)
- 主流垃圾收集器(G1、ZGC、Shenandoah)
- JVM 调优实战(参数、工具)
这篇文章帮你把高频题一次性讲透,面试能直接用。
二、JVM 内存区域划分
图1:JVM运行时数据区全景图
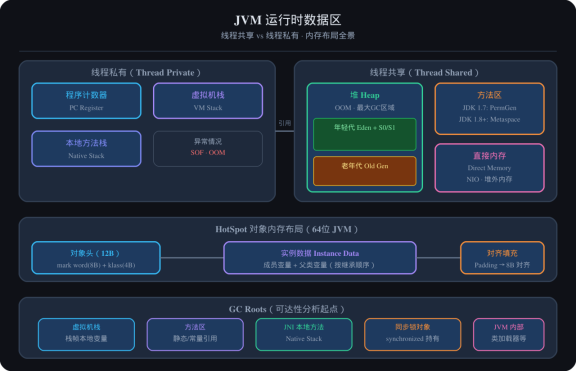
2.1 运行时数据区全景图
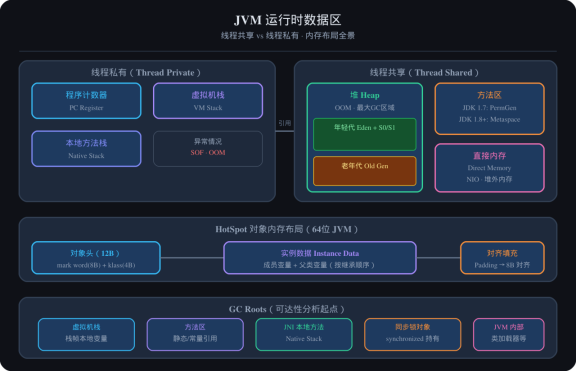 图1:JVM运行时数据区全景图
图1:JVM运行时数据区全景图
JVM 运行时数据区
├── 线程共享
│ ├── 方法区(MetaSpace)--- 类信息、常量、静态变量、JIT编译产物
│ ├── 堆(Heap)--- 对象实例、数组、字符串常量池
│ └── 直接内存(Direct Memory)--- NIO使用,堆外内存
│
└── 线程私有
├── 虚拟机栈(VM Stack)--- 方法调用栈帧,局部变量表/操作数栈/动态链接
├── 本地方法栈(Native Stack)--- Native 方法调用
└── 程序计数器(PC Register)--- 当前线程执行的字节码行号
2.2 各区域核心作用
|--------|------------|-------------|--------------------------|
| 区域 | 线程共享? | 存储内容 | 异常 |
|---|---|---|---|
| 程序计数器 | 私有 | 字节码指令地址 | 无(唯一无OOM区域) |
| 虚拟机栈 | 私有 | 方法栈帧,局部变量 | StackOverflowError / OOM |
| 本地方法栈 | 私有 | Native 方法 | StackOverflowError / OOM |
| 堆 | 共享 | 对象实例、数组 | OOM |
| 方法区 | 共享 | 类信息、常量、静态变量 | OOM(MetaspaceSize可调) |
2.3 面试高频追问:方法区和永久代/元空间的关系
JDK 1.7 及之前:方法区 ≈ 永久代(PermGen)
- 字符串常量池在永久代
- -XX:PermSize / -XX:MaxPermSize 控制大小
JDK 1.8+:方法区迁移至元空间(Metaspace)
- 字符串常量池移至堆
- 使用本地内存(OS内存),不再受 JVM 堆大小限制
- -XX:MetaspaceSize / -XX:MaxMetaspaceSize 控制大小
为什么这么改?
永久代有固定大小上限(默认 82MB),容易出现 java.lang.OutOfMemoryError: PermGen space。元空间使用本地内存,理论上只受 OS 内存限制,更灵活。
2.4 对象的内存布局
 图1:JVM运行时数据区全景图
图1:JVM运行时数据区全景图
一个对象在堆中的结构:
| 对象头(Object Header) | mark word(8B,存储哈希码、GC年龄、锁信息)|
| | klass pointer(4B,指向类元数据的指针) |
| 实例数据(Instance Data) | 成员变量 + 父类成员变量(按继承顺序排列) |
| 对齐填充(Padding) | 8字节对齐,补齐至 8 的倍数 |
三、对象的创建与内存分配
 图1:JVM运行时数据区全景图
图1:JVM运行时数据区全景图
3.1 对象创建全流程
-
检测类是否加载
└─ 未加载 → 执行类加载(加载→验证→准备→解析→初始化) -
分配内存
├─ 指针碰撞(Bump the Pointer):规整的堆(Serial/ParNew)
└─ 空闲列表(Free List):不规整的堆(CMS、G1)
└─ CAS + 失败重试 保证线程安全 -
初始化零值
└─ 分配后赋默认值(0/false/null) -
设置对象头
-
执行构造函数(<init>)
3.2 内存分配算法
栈上分配(Stack Allocation)
标量替换:当一个对象只持有基本类型或不可变引用,不需在堆分配,直接在栈上拆解。
// 可以栈上分配
class Point {
int x; // scalar
int y; // scalar
}
// JIT 编译时可能直接拆解为两个 int 局部变量,不创建对象
TLAB(Thread Local Allocation Buffer)
每个线程在堆中预分配一小块区域,专门用于对象分配,避免多线程竞争。
堆内存
├── TLAB Zone A ← 线程A专用,分配指针只在本区移动
├── TLAB Zone B ← 线程B专用
├── TLAB Zone C ← 线程C专用
└── Eden Space ← 共享区域
参数控制:-XX:+UseTLAB 开启(默认开启),-XX:TLABSize 调整大小。
四、垃圾回收核心算法
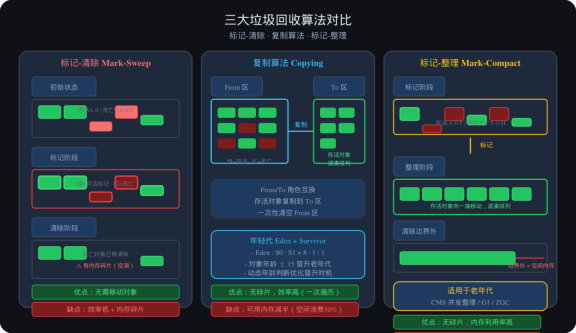 图2:三大GC算法对比
图2:三大GC算法对比
4.1 引用计数法(Reference Counting)
每个对象有个引用计数器,引用+1,失效-1。计数器为0则回收。
优点:判定简单,回收及时
缺点:无法处理循环引用;维护计数器有额外开销
❌ Java 不用此算法(但 Python/Objective-C 用)
4.2 可达性分析算法(Reachability Analysis)
从 GC Roots 出发,通过引用链遍历,能到达的对象是活的,到不了的就是垃圾。
GC Roots 包括:
- 虚拟机栈(栈帧本地变量表)中引用的对象
- 方法区静态属性引用的对象
- 方法区常量引用的对象
- 本地方法栈 JNI(Native)引用的对象
- JVM 内部引用(类加载器、异常对象、系统类加载器)
- 同步锁持有的对象(synchronized 关键字)
- JVM 内部的 JMXBean、回调方法等
4.3 四种引用类型
// 1. 强引用(Strong Reference)
Object obj = new Object(); // 只要强引用存在,永不回收
obj = null; // 断开引用后,才可能被回收
// 2. 软引用(Soft Reference)
SoftReference<byte\[\]> cache = new SoftReference<>(new byte10\*1024\*1024);
// 内存不足时回收,适合缓存场景
// 3. 弱引用(Weak Reference)
WeakReference<Object> ref = new WeakReference<>(new Object());
// 每次 GC 都会回收,不管内存是否充足,适合 ThreadLocal Map key
// 4. 虚引用(Phantom Reference)
PhantomReference<Object> phantom = new PhantomReference<>(obj, referenceQueue);
// 无法通过虚引用获取对象,仅用于 GC 时收到通知
// 配合 ReferenceQueue 跟踪对象回收,用于堆外内存管理(NIO DirectByteBuffer)
4.4 标记-清除算法(Mark-Sweep)
步骤:
- 标记:遍历所有对象,标记存活对象
- 清除:遍历堆内存,清除未标记对象
缺点:
- 效率低(两次遍历)
- 产生内存碎片(不连续的空闲空间)
4.5 复制算法(Copying)
将内存分为两块(From / To),每次只用一块
工作流程:
- From 区存活对象复制到 To 区
- 一次性清空整个 From 区
- From / To 角色互换
优点:无碎片,效率高
缺点:可用内存减半,空间浪费
实际应用:年轻代 Eden + Survivor(8:1:1)
- 每次 Minor GC,Eden + From Survivor 存活对象 → To Survivor
- 对象年龄 > 15 → 进入老年代
- Survivor 空间不足 → 直接进入老年代(分配担保)
4.6 标记-整理算法(Mark-Compact)
步骤:
- 标记:标记所有存活对象
- 整理:让存活对象向一端移动,紧凑排列
- 清除:清理边界外的内存
优点:无碎片,适合老年代
缺点:移动对象成本高,STW 时间长
实际应用:老年代收集(CMS 并发标记-整理、G1、ZGC)
五、分代收集理论
5.1 为什么需要分代?
经验观察:
- 大多数对象朝生夕死(80%以上)
- 熬过多次 GC 的对象通常存活更久
分代策略:
- 年轻代(Young Generation):对象创建频繁,频繁 Minor GC
└─ Eden + Survivor × 2(From + To) - 老年代(Old / Tenured Generation):长寿对象,长期存活
└─ Major GC / Full GC,频率低但停顿长 - 永久代/元空间:类信息,不参与常规 GC
5.2 对象年龄(Age)与晋升
对象头中的 age 计数器:
- 每经历一次 Minor GC,age + 1
- age >= 15(默认阈值)→ 晋升老年代
- -XX:MaxTenuringThreshold 可调整(最大15)
动态年龄判断:
Minor GC 时,如果 Survivor 空间中相同年龄所有对象总和 > Survivor 空间的 50%,
则 age >= 该年龄的对象全部晋升老年代。
六、主流垃圾收集器
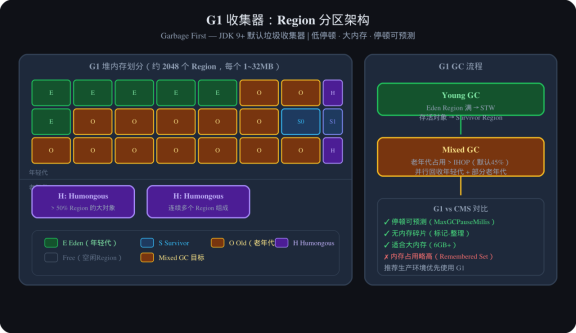 图3:G1收集器Region架构
图3:G1收集器Region架构
6.1 组合关系图
年轻代:
┌──────────────────────────────────────────────┐
│ Serial GC ──→ ParNew ──→ Parallel Scavenge │
└──────────────────────────────────────────────┘
老年代:
Serial Old ←── Parallel Old
CMS ←─(并发收集,与用户线程并发执行)
全新收集器(不分代):
G1 ──→ ZGC(低延迟)──→ Shenandoah
整体趋势:Serial → Parallel → CMS → G1 → ZGC
6.2 各收集器特点对比
|-------------------|-------------------------|-----------|----------------|
| 收集器 | 线程模型 | STW | 适用场景 |
|---|---|---|---|
| Serial | 单线程 | 长 | 客户端,小内存,单核 |
| ParNew | 多线程并行 | 较长 | 服务端,年轻代,配合 CMS |
| Parallel Scavenge | 多线程并行 | 较长 | 吞吐量优先,后台批处理 |
| Serial Old | 单线程 | 长 | 客户端,老年代 |
| Parallel Old | 多线程并行 | 较长 | 吞吐量优先 |
| CMS | 并发(初始标记→并发标记→重新标记→并发清除) | 短(可并发) | 追求低停顿,老年代 |
| G1 | 并发(标记→引用处理→记忆集构建→并发清理) | 可控停顿 | 大内存,服务端,可预测停顿 |
| ZGC | 并发(着色指针+读屏障) | 极短(<1ms) | TB级内存,极低延迟 |
| Shenandoah | 并发(转发指针,无写屏障) | 极短 | OpenJDK,低延迟 |
6.3 CMS 收集器(Concurrent Mark Sweep)
CMS 是老年代收集器,主打低停顿,但已被 G1 逐渐取代。
GC 阶段:
- 初始标记(Initial Mark):STW,只标记 GC Roots 直接引用的对象(快)
- 并发标记(Concurrent Mark):用户线程并发执行,从 GC Roots 遍历整个对象图
- 重新标记(Remark):STW,修正并发标记期间产生的变动(比初始标记慢)
- 并发清除(Concurrent Sweep):用户线程并发执行,清除死亡对象
缺点:
- 对 CPU 敏感(并发阶段占用 CPU)
- 无法处理浮动垃圾(并发期间新产生的垃圾,只能下次 GC)
- 产生内存碎片(标记-清除算法,无整理)
- 默认老年代达到 75% 触发(-XX:CMSInitiatingOccupancyFraction=75)
- "并发模式失败":CMS 运行期间老年代不够用,触发 Serial Old(STW很长)
6.4 G1 收集器(Garbage First)
G1 是 JDK 9+ 的默认垃圾收集器,适合大内存(6GB+)服务。
核心思想:把堆划分为多个大小相等的 Region(1MB~32MB),每个 Region 可以是 Eden/Survivor/Old/Humongous(大对象专用)。G1 跟踪每个 Region 的回收价值(回收获得的空间 + 回收所需时间),优先回收价值最高的 Region。
G1 关键参数:
-XX:MaxGCPauseMillis=200 ← 目标最大停顿时间(软目标)
-XX:G1HeapRegionSize=1~32MB ← Region 大小,自动计算
-XX:InitiatingHeapOccupancyPercent=45 ← 堆占用 45% 时触发 Mixed GC
G1 GC 流程:
- Young GC:年轻代 Region 满了 → STW,将年轻代 Region 存活对象复制到 Survivor
- Mixed GC:老年代占用超过阈值 → STW + 并发,并行回收年轻代 + 部分老年代
- Full GC(尽量避免):G1 无法回收时,串行单线程收集(JDK 10+ 已优化)
6.5 ZGC(Z Garbage Collector)
 图4:垃圾收集器演进对比
图4:垃圾收集器演进对比
JDK 11 引入,JDK 15 正式生产可用,主打亚毫秒级停顿。
核心技术:
- 着色指针(Colored Pointers):在对象头 64 位中用几位标记 GC 状态,不再依赖对象头
- 读屏障(Load Barrier):读取对象时检测并修正指针颜色,代价极低
- 并发执行:所有阶段几乎与用户线程并发运行
参数:
-XX:+UseZGC -Xmx16g
特点:
- 停顿时间 < 1ms(与堆大小无关)
- 吞吐量影响 < 15%
- 支持 TB 级内存
- 不分代(JDK 15+ 已支持分代 ZGC)
七、面试高频真题解答
Q1:对象一定在堆内存分配吗?
不一定。满足以下条件时可栈上分配或标量替换:
- 对象足够小(逃逸分析判断)
- 方法内创建的对象,方法外无引用(未逃逸)
- JIT 编译时可标量替换为局部变量
Q2:Minor GC 和 Full GC 的区别?
|----------------|---------------|----------------------------------|
| Minor GC | Full GC | |
|---|---|---|
| 触发区域 | 年轻代 Eden 满 | 老年代满 / Metaspace 满 / System.gc() |
| 频率 | 频繁(几秒~几十秒一次) | 低(几小时~几天一次) |
| 停顿时间 | 短(几十毫秒) | 长(几百毫秒~几秒) |
| 是否StopTheWorld | 是(但短) | 是(通常较长) |
Q3:为什么 CMS 用标记-清除而不是标记-整理?
CMS 追求低停顿,如果用标记-整理(需要移动存活对象),STW 时间反而更长。标记-清除虽然有碎片,但可以接受,碎片由下一次的 Full GC 或并发失败后的 Serial Old 整理。
Q4:G1 和 CMS 的区别是什么?
|--------|----------------|---------------------------|
| CMS | G1 | |
|---|---|---|
| 目标 | 老年代收集器 | 全堆收集器(逻辑分代) |
| 碎片问题 | 有内存碎片(标记-清除) | 整体无碎片(标记-整理) |
| 停顿可预测性 | 不可预测(并发阶段可能停顿) | 可设定停顿目标(MaxGCPauseMillis) |
| 大内存表现 | 停顿长 | 更稳定 |
| 分代 | 物理分代 | 逻辑分代(Region) |
Q5:JVM 常用调优参数有哪些?
堆大小
-Xms4g -Xmx4g # 初始/最大堆大小(建议设为相同值避免动态扩展)
-XX:NewRatio=2 # 年轻代:老年代 = 1:2
-XX:SurvivorRatio=8 # Eden:Survivor = 8:1
元空间(替代永久代)
-XX:MetaspaceSize=256m
-XX:MaxMetaspaceSize=512m
GC 收集器
-XX:+UseG1GC # 使用 G1(推荐,JDK 9+ 默认)
-XX:MaxGCPauseMillis=200 # G1 最大停顿目标
-XX:+UseZGC # 使用 ZGC(低延迟场景)
-XX:+UseSerialGC # 使用 Serial GC(客户端/测试)
GC 日志
-Xlog:gc*:file=gc.log:time,uptime:filecount=5,filesize=10M
OOM 时导出堆 dump
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/heap.hprof
逃逸分析(默认开启)
-XX:+DoEscapeAnalysis
八、调优实战:如何定位 GC 问题?
8.1 常用工具
|-------------------------------------------------|-----------------------|
| 工具 | 用途 |
|---|---|
| `jstat -gcutil <pid> 1000` | 实时监控 GC 统计(堆使用率、各区容量) |
| `jmap -heap <pid>` | 查看堆配置与使用情况 |
| `jmap -histo <pid>` | 统计对象数量和内存占用(Top N) |
| `jmap -dump:format=b,file=heap.hprof <pid>` | 导出堆 dump(OOM 时自动触发) |
| `jconsole` / `jvisualvm` | GUI 监控工具 |
| `GCViewer` / `GCEasy` | 分析 GC 日志(可视化) |
8.2 典型 GC 问题与解决方案
问题1:GC 频繁,Minor GC 后大量对象进入老年代
现象:Minor GC 很频繁,对象年龄快速增加
原因:
- 短生命周期对象被长期持有(集合未清理、静态集合持有对象引用)
- 大对象直接进入老年代(-XX:PretenureSizeThreshold 设置过大)
- Survivor 空间太小,对象提前晋升
解决:
- jmap -histo 查看大对象来源
- 检查代码中集合的使用方式
- 调整 Survivor 比例:-XX:SurvivorRatio=6
- 设置 -XX:TargetSurvivorRatio=60(提高 Survivor 使用率)
问题2:Full GC 停顿超过 2 秒
原因:老年代碎片化 + 大对象分配失败
解决:
- 切换到 G1 收集器(-XX:+UseG1GC)
- 设置 -XX:MaxGCPauseMillis=200 控制目标停顿
- 如果内存足够,增大堆大小
- 分析 GC 日志,定位 Full GC 触发原因
问题3:ZGC 吞吐量下降
原因:读屏障开销 + 并发线程竞争
解决:
- 确认 ZGC 并发线程数:-XX:ConcGCThreads=N(默认 CPU 核数/4)
- 如果 CPU 资源充足,可适当增加并发线程
- 对于超大堆(1TB+),ZGC 依然是最佳选择
九、面试速记思维导图
JVM 内存结构
├── 线程私有
│ ├── PC寄存器(无OOM,唯一私有)
│ ├── 虚拟机栈(StackOverflow / OOM)
│ └── 本地方法栈
│
└── 线程共享
├── 堆(OOM,最主要GC区域)
│ ├── 年轻代 → Eden + Survivor×2
│ └── 老年代
└── 方法区(1.7 PermGen → 1.8 Metaspace)
└── 字符串常量池(1.8 移至堆)
GC 算法
├── 引用计数(❌ Python用,Java不用)
├── 可达性分析(✅ GC Roots出发)
├── 标记-清除(CMS用,有碎片)
├── 复制算法(年轻代,内存减半)
└── 标记-整理(老年代,无碎片)
分代策略
├── 年轻代:Minor GC(频繁,快速)
└── 老年代:Full GC(低频,停顿长)
收集器演进
Serial → Parallel → CMS → G1 → ZGC
核心矛盾:吞吐量 vs 停顿时间 vs 内存占用
调优核心:
- 选对收集器(G1/ZGC 优先)
- 设定停顿目标(MaxGCPauseMillis)
- 合理堆大小(建议物理内存的 50~75%)
- 监控 + 日志分析
十、总结
JVM 内存管理和 GC 是 Java 工程师的核心内功。面试中要能讲清楚:
- 内存区域:线程共享 vs 私有,堆 vs 方法区的演进
- 对象创建:分配方式、TLAB、逃逸分析
- 垃圾回收:三种算法原理及优缺点
- 分代理论:为什么分代,Minor/Full GC 区别
- 收集器:CMS(标记-清除,有碎片)vs G1(分区,停顿可控)vs ZGC(着色指针,亚毫秒)
- 调优实践:参数配置 + 问题定位方法
记住一个核心矛盾:吞吐量和低停顿不可兼得,根据业务场景选择合适的收集器才是关键。
如果觉得有用,欢迎**点赞收藏**,关注「洛水石」获取更多 Java 面试干货 ��