这两天其实聊 DeepSeek 的人并不算多,但是小米的营销攻势还挺猛的!
早上刚刷到一条 X:
这是小米大模型负责人的罗福莉发布的推特,里面说到了两个点:一个是小米也开源了,另一个是要送 100T 免费 Tokens。
国内模型好像都开源了,最早好像是 Qwen、GLM,然后 Kimi、MiniMax 也都纷纷开源,小米出来之后也跟了一波。
至于 100T 免费嘛,自然是有条件的,也不是给你一个人的。
除了这些活动之外,早就已经有超级大 V 开始夸这个模型了。
类似"国内顶级,Claude 最佳替代",这种表述也不少见啊。
开源和送 Token 都是好事情啊! 大家有需要的赶紧去看看。
我其实从 MiMo 最早的 Flash 就开始测试了,当时的效果是非常拉跨的。
然后又测了 MiMo 2 Pro,好了很多!
我之所以接触这个模型,就是因为被一波又一波的吹牛逼给带进来的,触发了我强烈的逆反心理。
你们看我之前的文章也能感受出来。
今天我就来给最新的 MiMo 2.5 Pro "把把脉"。看看是否能够改变我对小米MiMo的看法!
1、基准数据
开始测试一期,我们先来看一波"卖家秀"!
我从官方找到了这张基准测试图:
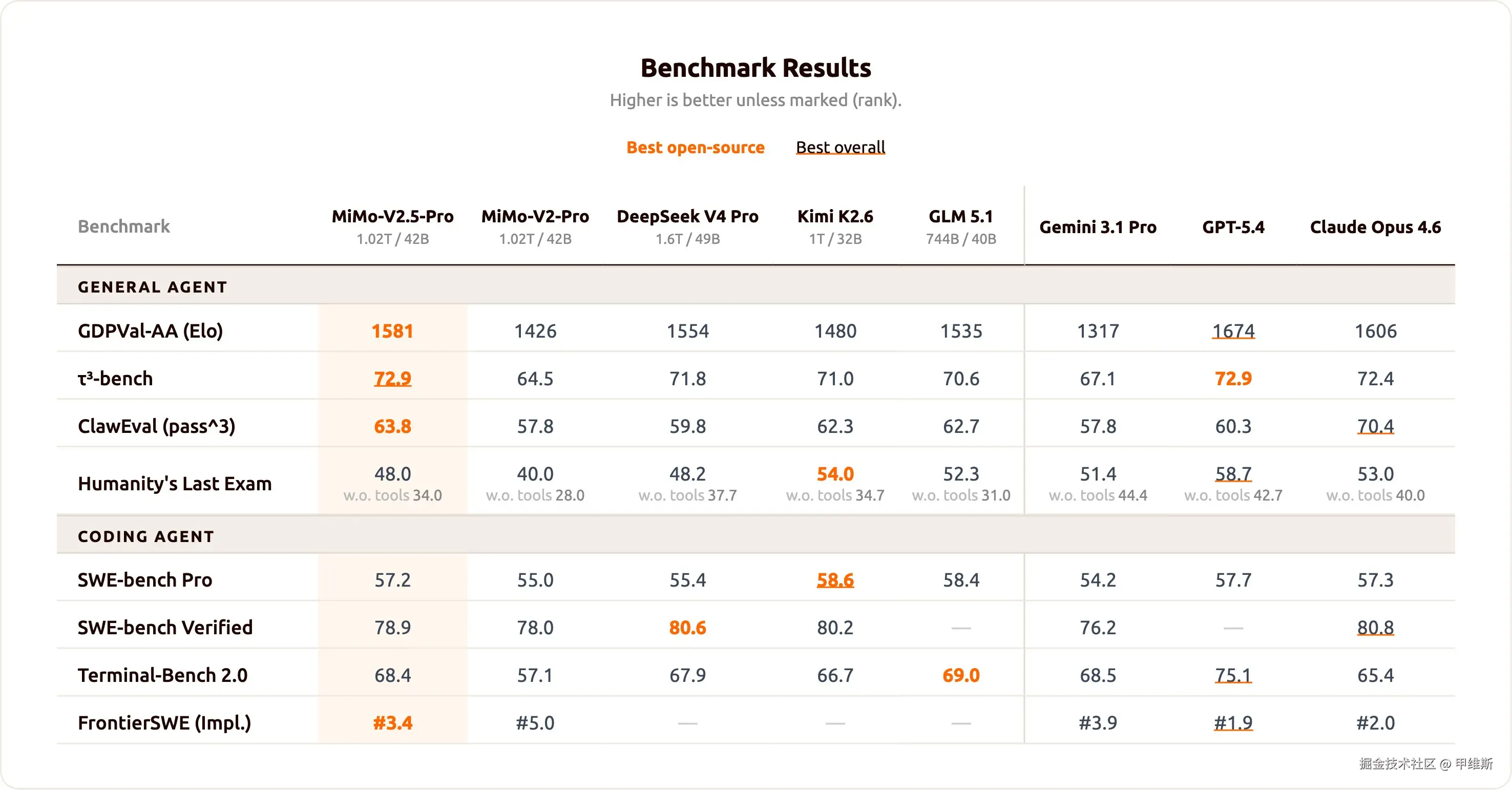
这个基准分成了两部分:一部分是通用智能体,一部分是编程智能体!
这个表格给了我严重的误导,我以为标黄加粗的是所有模型中的 SOTA 指标。
乍一看,Opus 4.6 好像很辣鸡,没有一个加粗标黄的!
仔细一看,下面有个细线。
这种心理暗示玩法真的是......"高级"!
抛开暗示,我们看明示,这个基准数据还是很能打的!
从这里看它是压着 DeepSeek V4 Pro 打的。
只有 SWE-bench Verified 这一项稍微弱一点。
看完常规基准,看一下 Claw-Eval
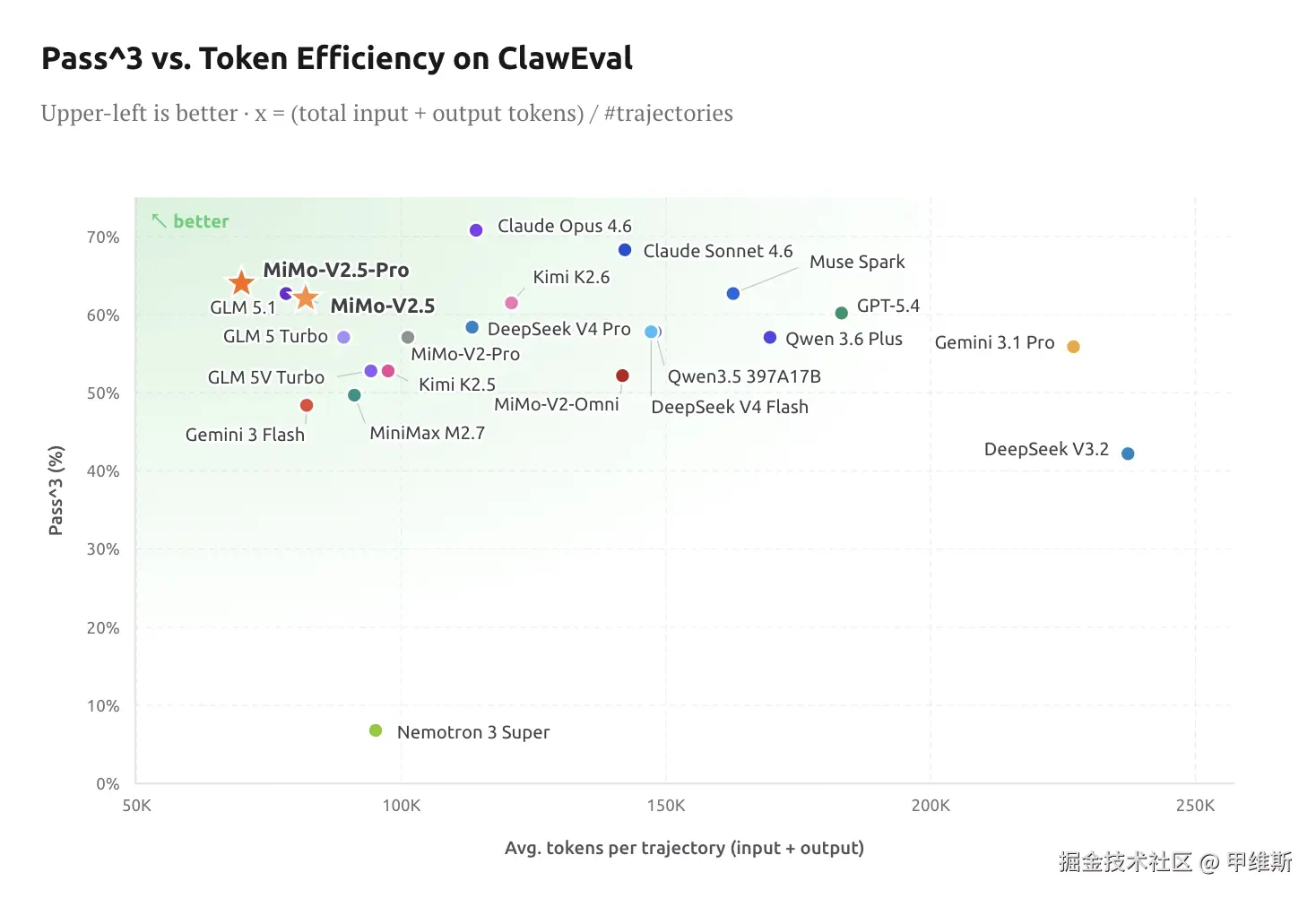
这个表格讲的是 Claw-Eval 上的"成功率 vs Token 消耗效率"。
越靠左上越好。
左边代表平均每条任务轨迹消耗 token 少,越省钱/越快;
上边代表 Pass^3 成功率高,能力越强。
简单说就是:模型完成一次任务平均要花多少 token。
这个图的主要表达:
在这个维度上 MiMo 2.5 Pro 比较优秀,甚至数一数二的存在了。
DeepSeek V4 Pro 和 Flash 要比它差不少!
还有一张关于 Claw 的图:
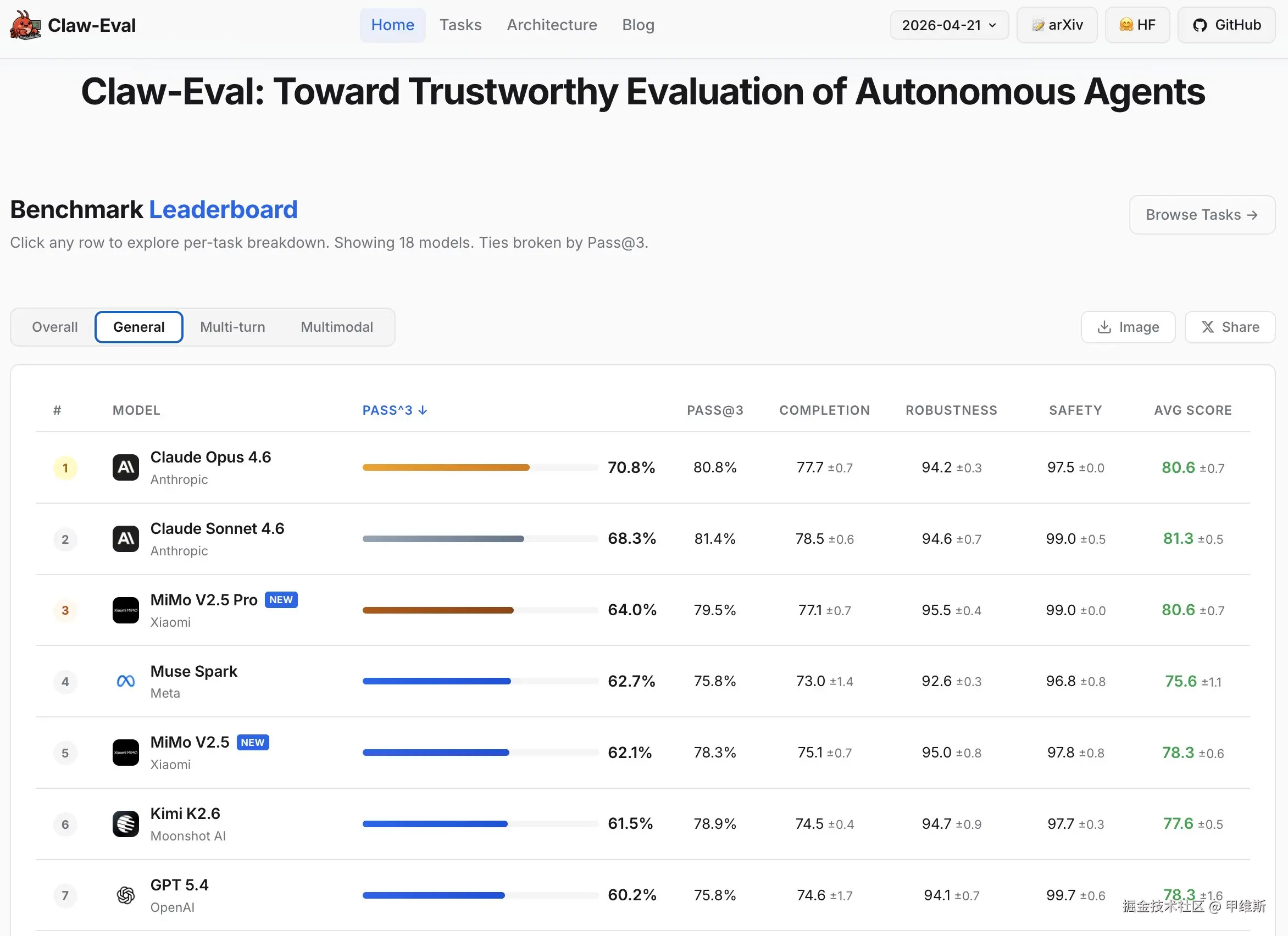
这是 Claw-Eval 的 General 榜单排名。它不是综合所有能力的总榜,而是 Claw-Eval 里面的一个子榜。
主要评估模型在通用智能体任务里的表现。
从这个排名来看,小米第三,仅次于 Sonnet 4.6 和 Opus 4.6。
要比 Kimi K2.6 和 GPT5.4 还高不少。
另外还有一张图:
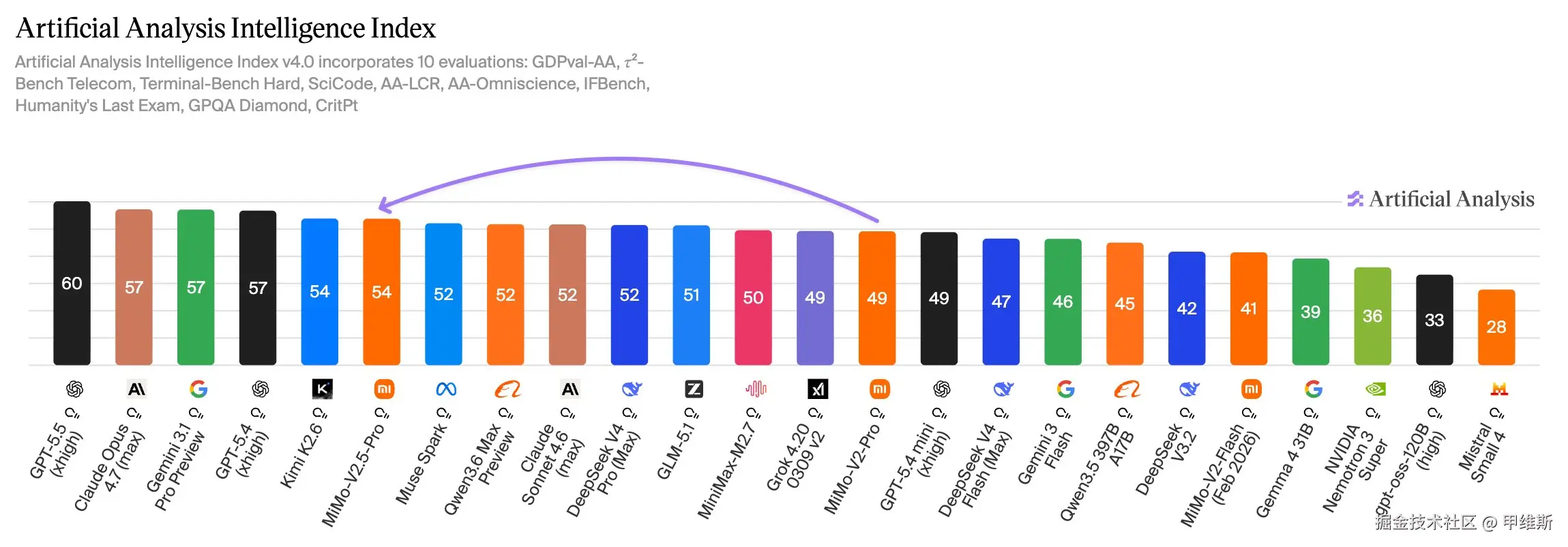
从这个榜单来看,小米 MiMo 2.5 Pro 实现了大幅度的跨越,要比 GLM5.1 高五个名次,比 DeepSeek V4 高四个名次。
官方能贴出来的数据,我都贴出来了。
单看这些数据,基本上可以得出一个结论:
MiMo 2.5 Pro 通用智能体国内最强;Claw 性价比几乎最高,能力也是 Top 3;编程智能体方面还差点意思,但是和国产模型比,也是有来有回。
单看推上贴图的数据,真的是一个很不错的模型,几乎是国内模型首选了。
好了,基础信息终于介绍完了。我们要动真格的了。
下面会分几个环节进行测试,首先是基础问答,智力测试,然后是网页开发测试,最后是实战项目升级开发。
因为 DeepSeek V4 和 MiMo 2.5 Pro 有一定渊源,而且在同一个时间段发布,很多方面都有重叠,所以会重点对比这两家。
2、简单问答&速度测试
我们先来一些简单,然后慢慢上强度!
问答部分我们全部采用 API 接入,排除联网和应用层的差异。使用的测试平台,是我自己手搓的 CodingPlan Test 平台。
昨天晚上用 Sonnet 4.6 对这个平台进行了一个小的升级,现在可以设置思考模式以及统计端到端速度和解码速度。
我会把思考模式全部设置为 Anthropic 的自适应模型,等级为 high。
端到端速度是指:总的 Tokens / 总的时间。
解码速度是指:输出的 Tokens(排除 thinking)/ 输出阶段的时间。
这两个指标都用来体现速度的。
下面统一选了四个 AI 模型作为对比:
分别是 GLM5.1,Kimi K2.6,MiMo 2.5 Pro,DeepSeek V4 Pro。
基础信息交代完了,我们就来开始测试了。
数数题
测试提示词:
DeepSeek 里面有几个 e?
测试结果:
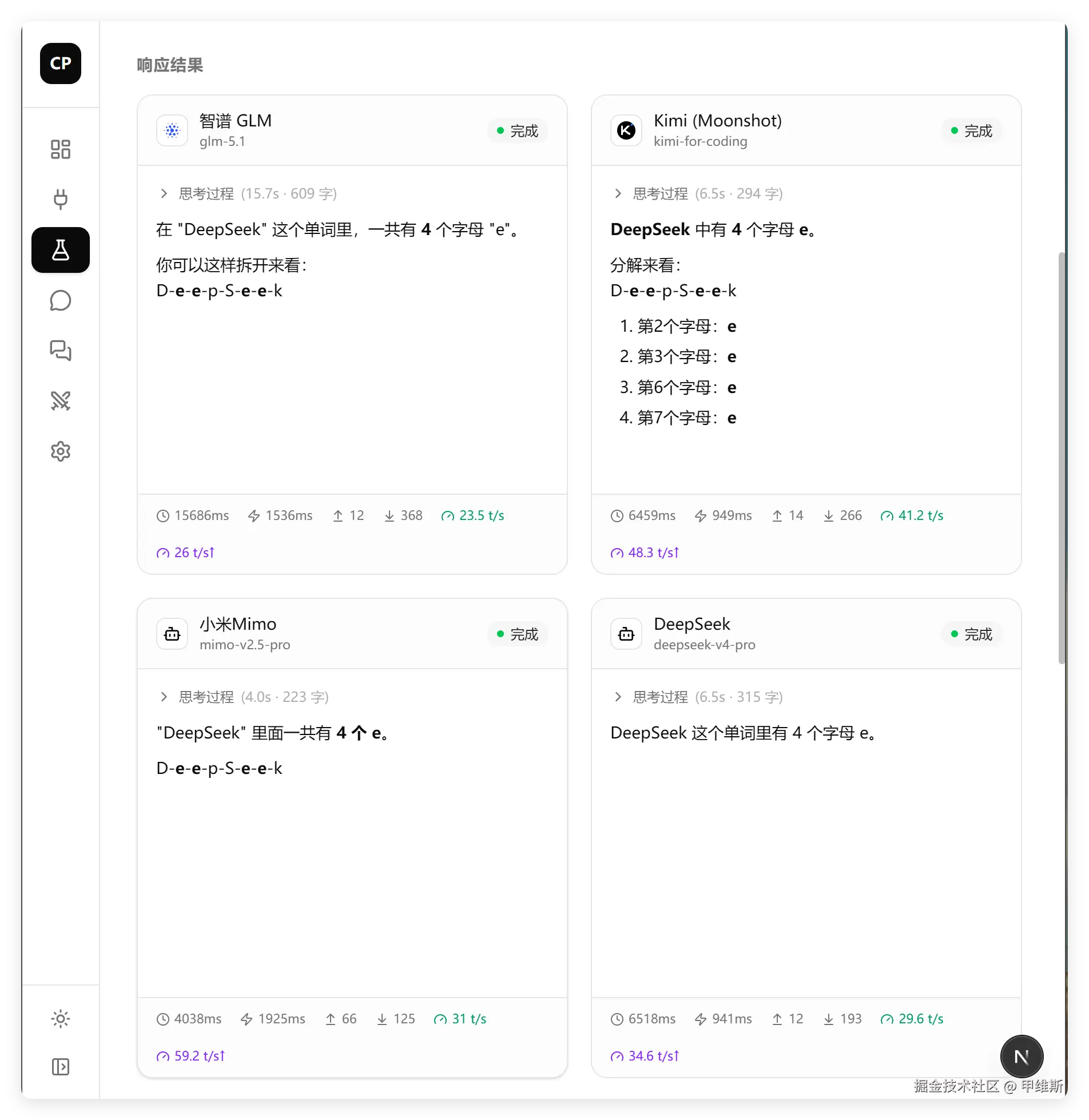
因为我全部开启了思考模式,所以这个问题全部正确。之前 GLM5.1 一直回答错误,主要是因为他们家默认关闭了思考模型。只有强制开启,才会启用。
正确性一样的前提下,我们只要看性能数据就可以了。
性能数据:
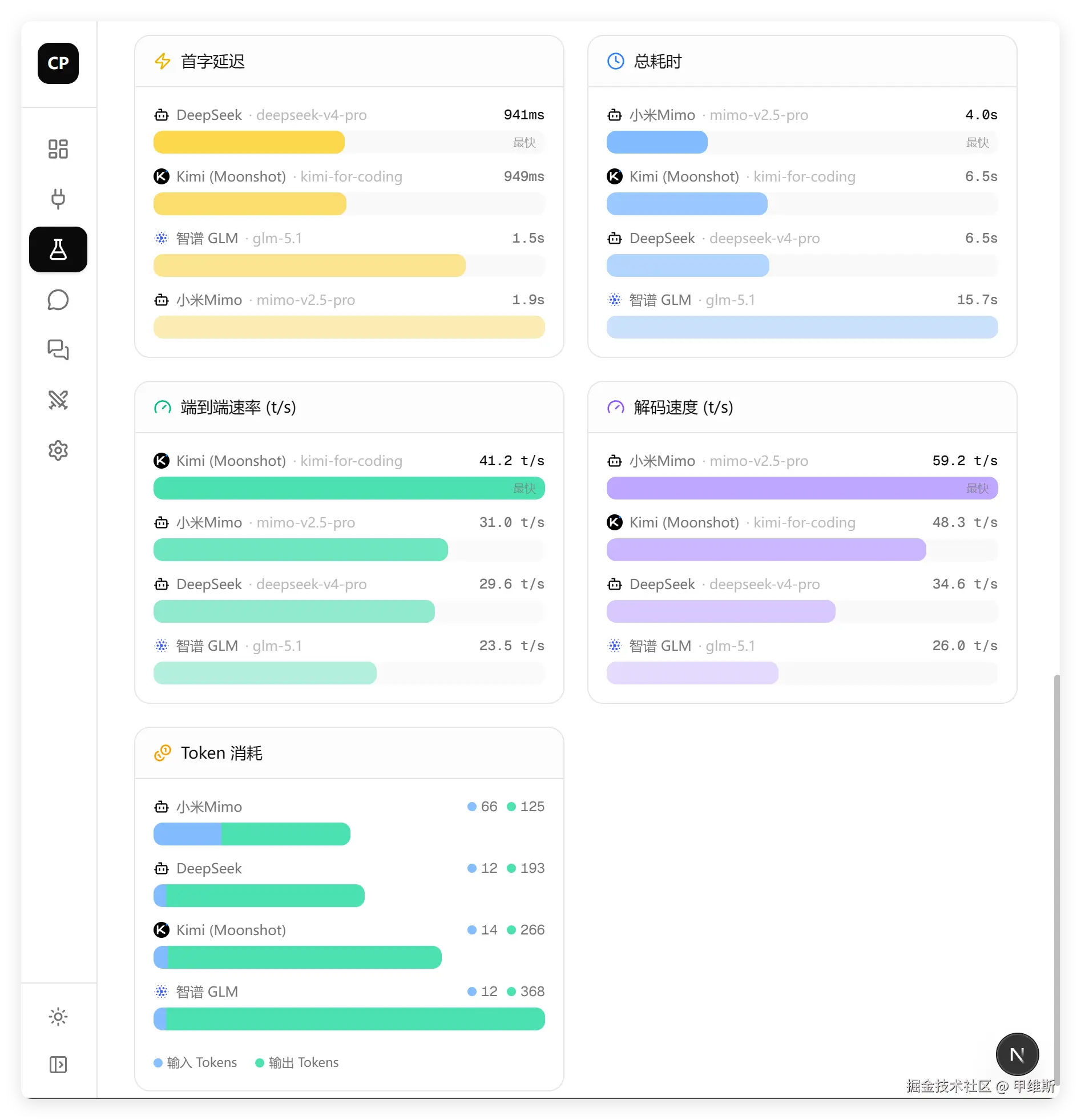
这一趴,DeepSeek 首字延迟最低,MiMo 总时间最少,解码速度最快,Tokens 消耗最少。
比大小
测试提示词:
11.9 和 11.12 哪个数字大?
这个环节也是全部正确,直接看性能指标。
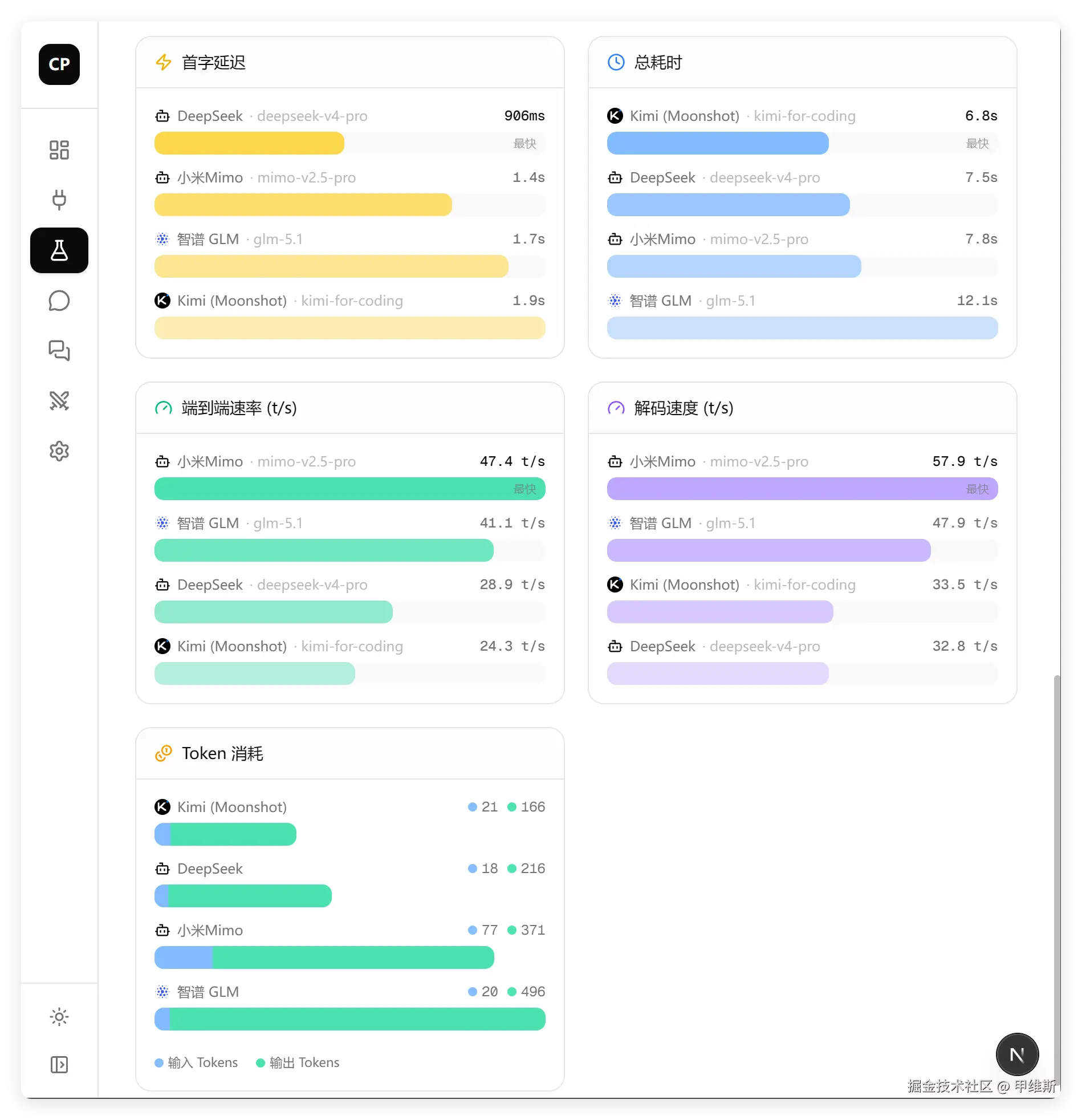
这一部分首字最快的还是 DeepSeek,MiMo 在端到端和解码速度方面排名第一。
在 Token 消耗方面,DeepSeek 略胜 MiMo。
找正整数
测试提示词:
找出一个正整数 n,使得 n! 可以被 2^n 整除。
这一部分,也是全对。思考模式下,这种问题都不是问题。
性能指标如下:
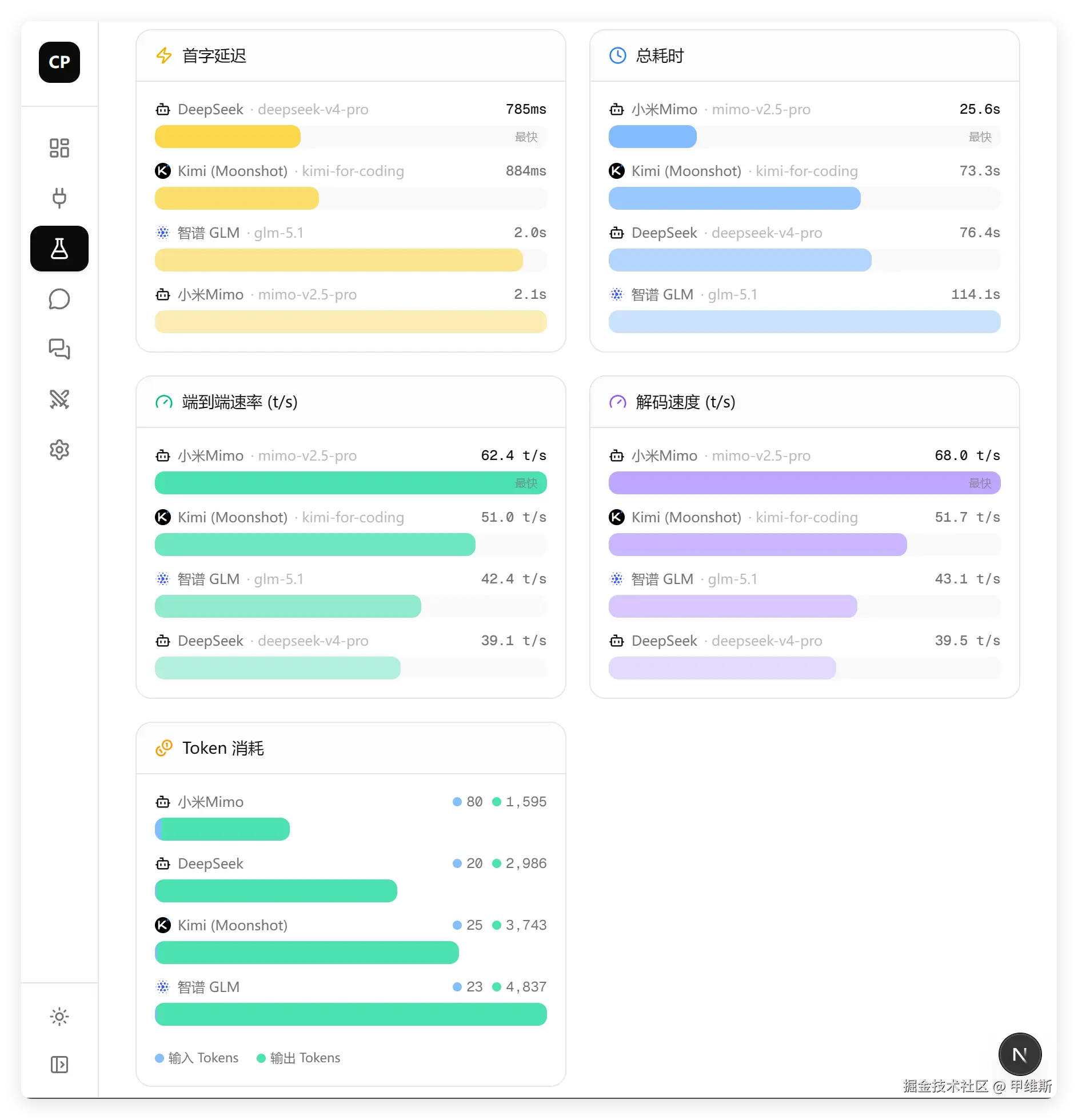
首字依旧是 DeepSeek 最快,MiMo 在总耗时、速度、Token 消耗方面全部第一名!
空间推理
测试提示词:
6 米长的竹竿能否通过 4 米高、3 米宽的门?
这个问题呢,目前对 AI 来说还是有难度。很多 AI 模型无法多次稳定回答正确。
比如这一次:
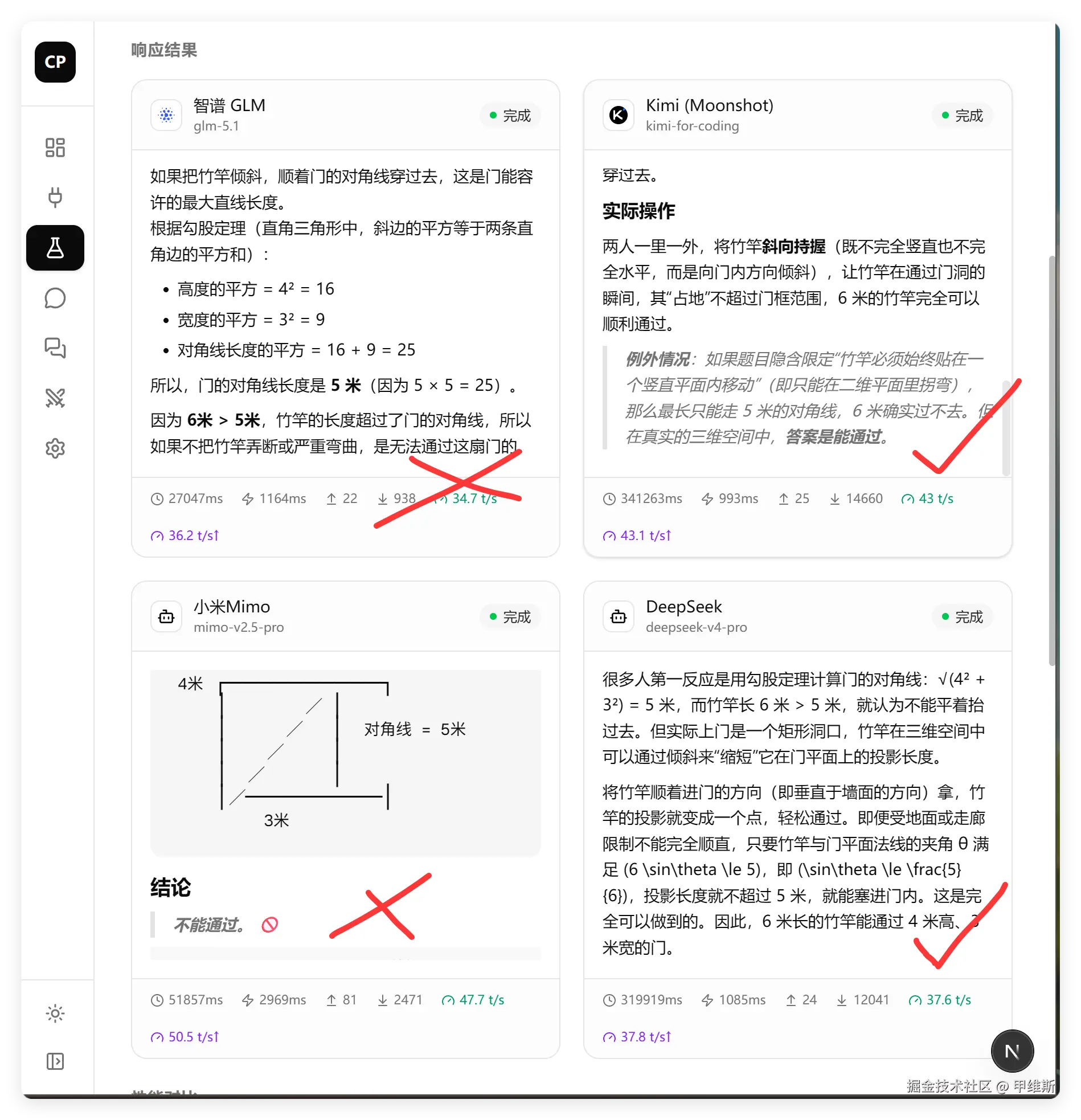
GLM 和 MiMo 回答错误。Kimi 和 DeepSeek 回答正确。
值得注意的一点是,DeepSeek Pro 测了好几期都没有出现过错误。MiMo 第一次测就出现了错误。
性能数据:
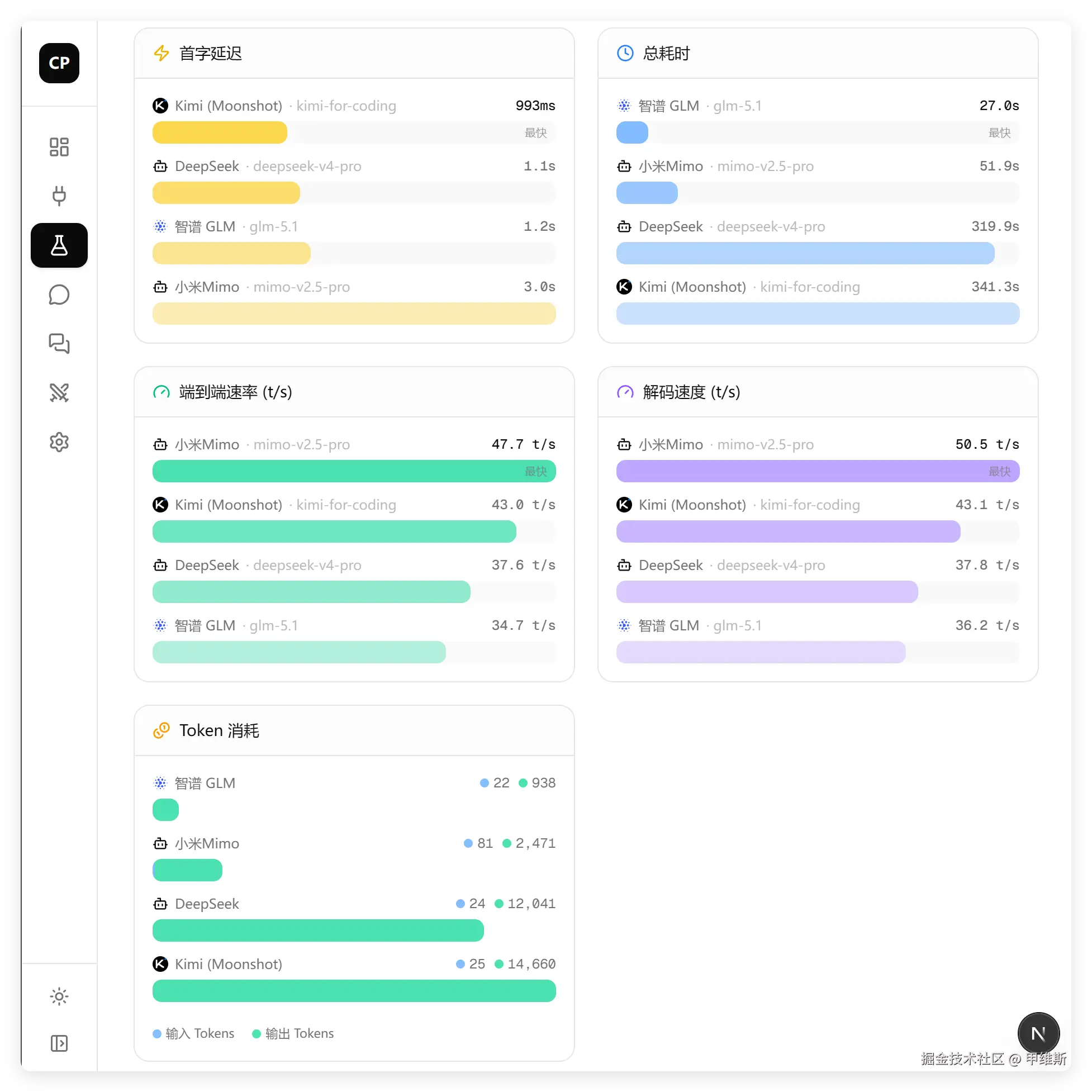
MiMo 依旧是最快的,Tokens 也比较省。
DeepSeek 这一轮速度和 Tokens 都不占优势,但是答案正确!
帽子逻辑推理
测试提示词:
有 5 个人排成一排,每人帽子颜色为红或蓝。他们可以看到前面的人的帽子,但看不到自己的。主持人宣布:"至少有一顶红帽子。"从最后一人开始,每人依次说"是"或"否"(表示是否知道自己帽子的颜色)。如果第 5 人说"否",第 4 人说"是",求所有可能的帽子颜色分布。
这一题是要一点计算量和脑力的。
测试结果如下:
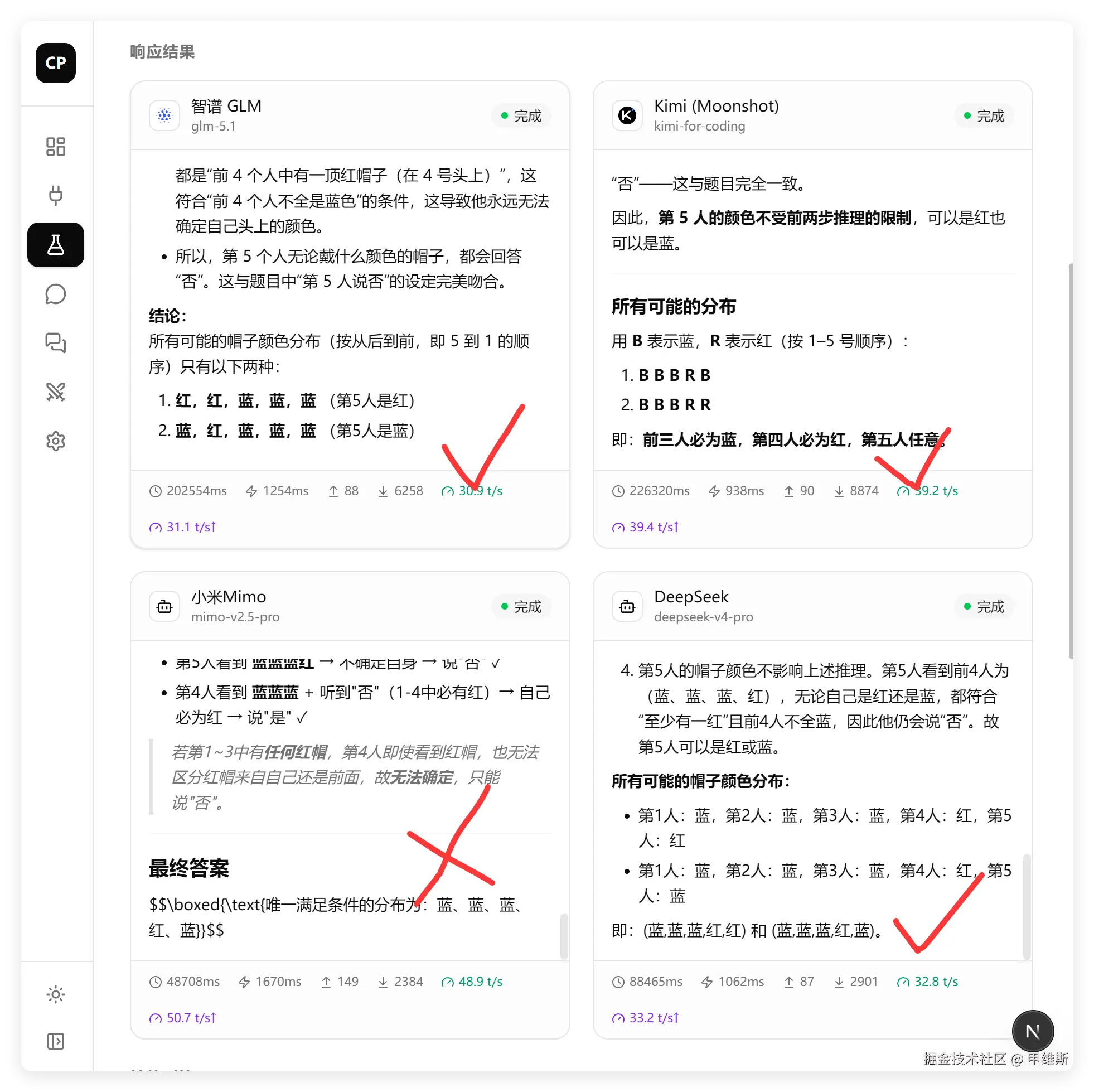
MiMo 做错了,其它全对!
性能数据:
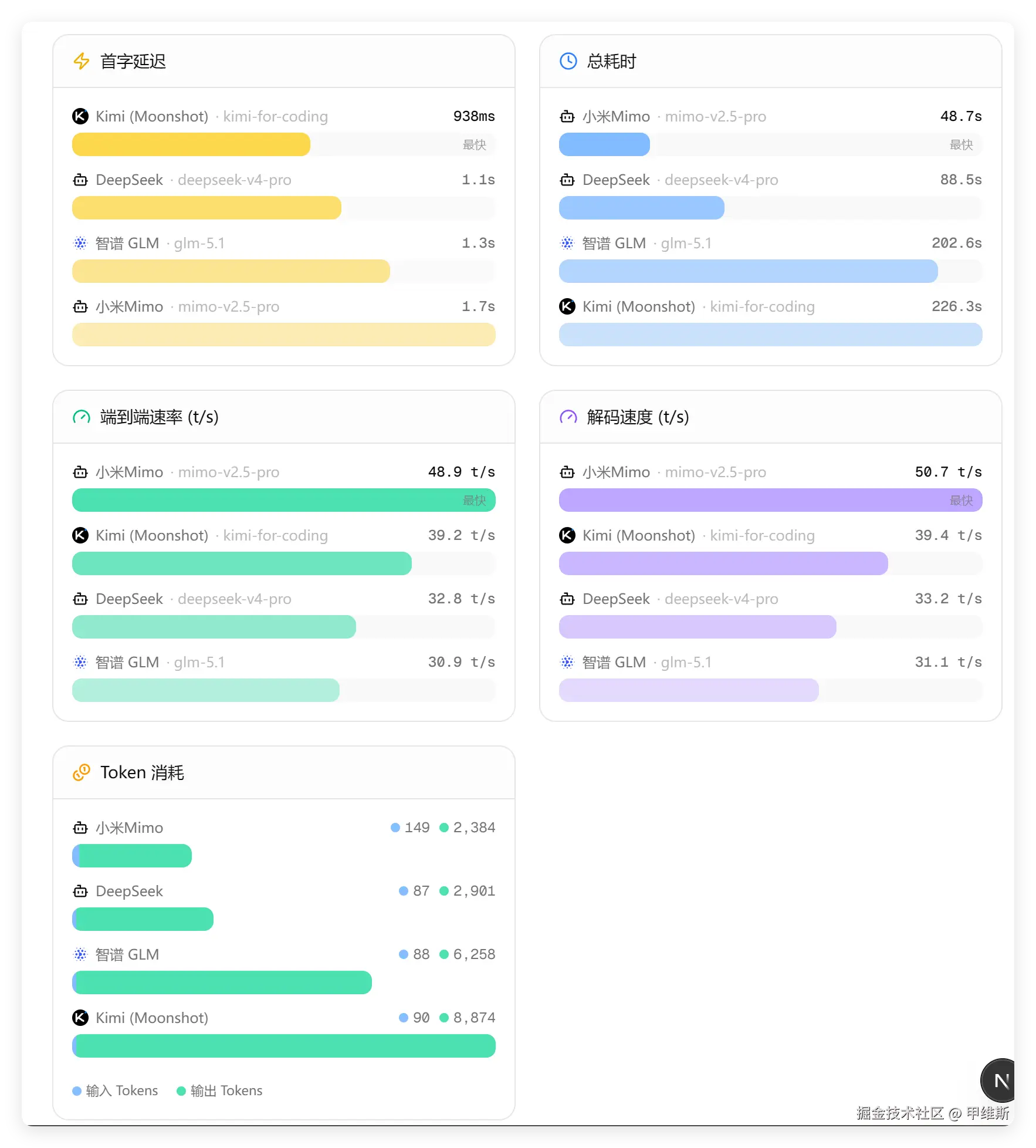
小米 MiMo 在速度、总时间、Token 消耗方面都是第一。DeepSeek 在它后面一点。
五个题目测完了,前面的两个对思考模型来说是很简单的,后面的逐渐变难。
可以看到小米在端到端速度、解码速度、Tokens 消耗等方面确实优势明显。
但是智力稍弱!正确率 60%
DeepSeek 首字速度很快,整体速度偏慢,答题正确率 100%。
其实这一点从参数也可以看出来,一个是 1.6T 激活 49B,一个是 1T 激活 42B。
大一点的脑子会好一点,但是慢一点。
3、写几个前端页面
我专门设计了 9 个测试题目,每个测试题目考察点都不一样。
九个例子我已经都跑完了,发现其中一个例子,有低级错误。
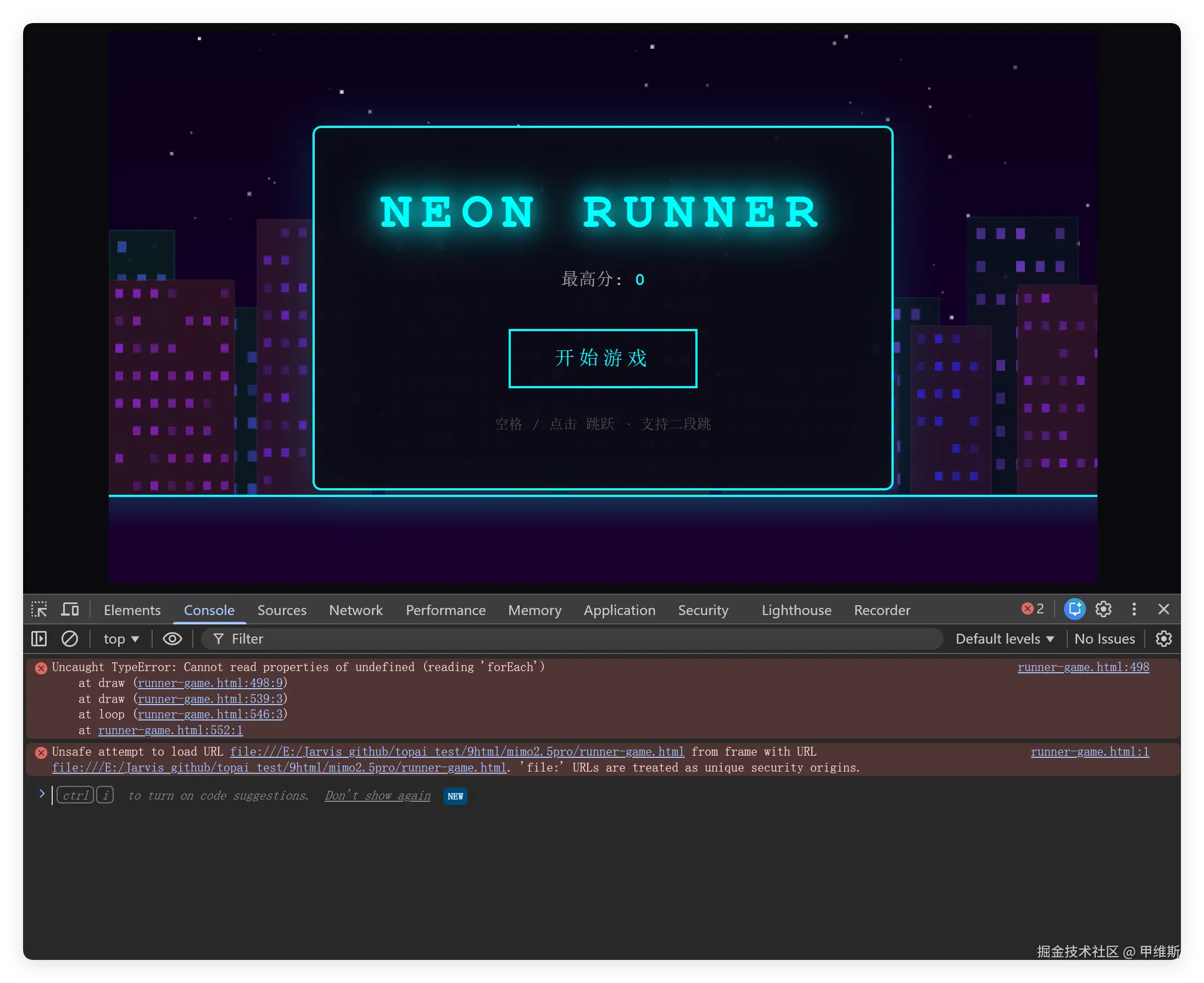
"霓虹奔跑者"这一题写完之后无法启动游戏,因为有 JS 错误!
其他页面都是可以正常打开,没有大的逻辑问题,但是审美什么也是不存在的。
感觉和 DeepSeek V4 差不了多少。
因为很多都是动态的例子,我就不截图了。
我会把所有测试结果统一传到 TOPAI 上面:
4、帮我升级项目
这个项目描述我都快写吐了,老粉应该很熟悉了。
这个项目其实不简单的,但介绍部分我就简单说了。
这个叫 CodingPlan Test,专门用来测试大模型的。然后开发国产遇到了问题,需要升级项目,我就把这个功能剥离出来作为测试项目了。
目前已经测试过了几乎所有的国内外模型。
包括国内的DeepSeek V4 Pro 和 Flash;智谱家的GLM5.1,turbo,4.7;月之暗面的Kimi K2.6,2.5等等
也包括国外的 GPT5.4、Opus 4.6、Gemini 3.1 Pro 等。
从前期的结果来看,国外模型基本都能完成大致内容,没有低级错误。而国内模型,在两个月前,有一大堆无法完成这个升级任务,错漏百出。
所以,还是一个挺不错的测试项目。而且自己的项目,可以避免被提前训练的情况。
这个任务主要有几个关键点:
- 有一定上下文基础(约 8,000 行代码)
- 涉及数据结构修改和老数据升级
- 涉及业务逻辑修改
- 涉及多个功能页面联动修改
基本情况说清楚了,我们就可以来看测试结果了!
我一般会从几个角度来评判:能不能用,好不好用,全不全面。
首先,开发完成之后,启动正常,打开首页正常,各种功能点击正常,也就是能用。
然后,我们通过具体的功能页面,看一下是否好用。
角色管理:
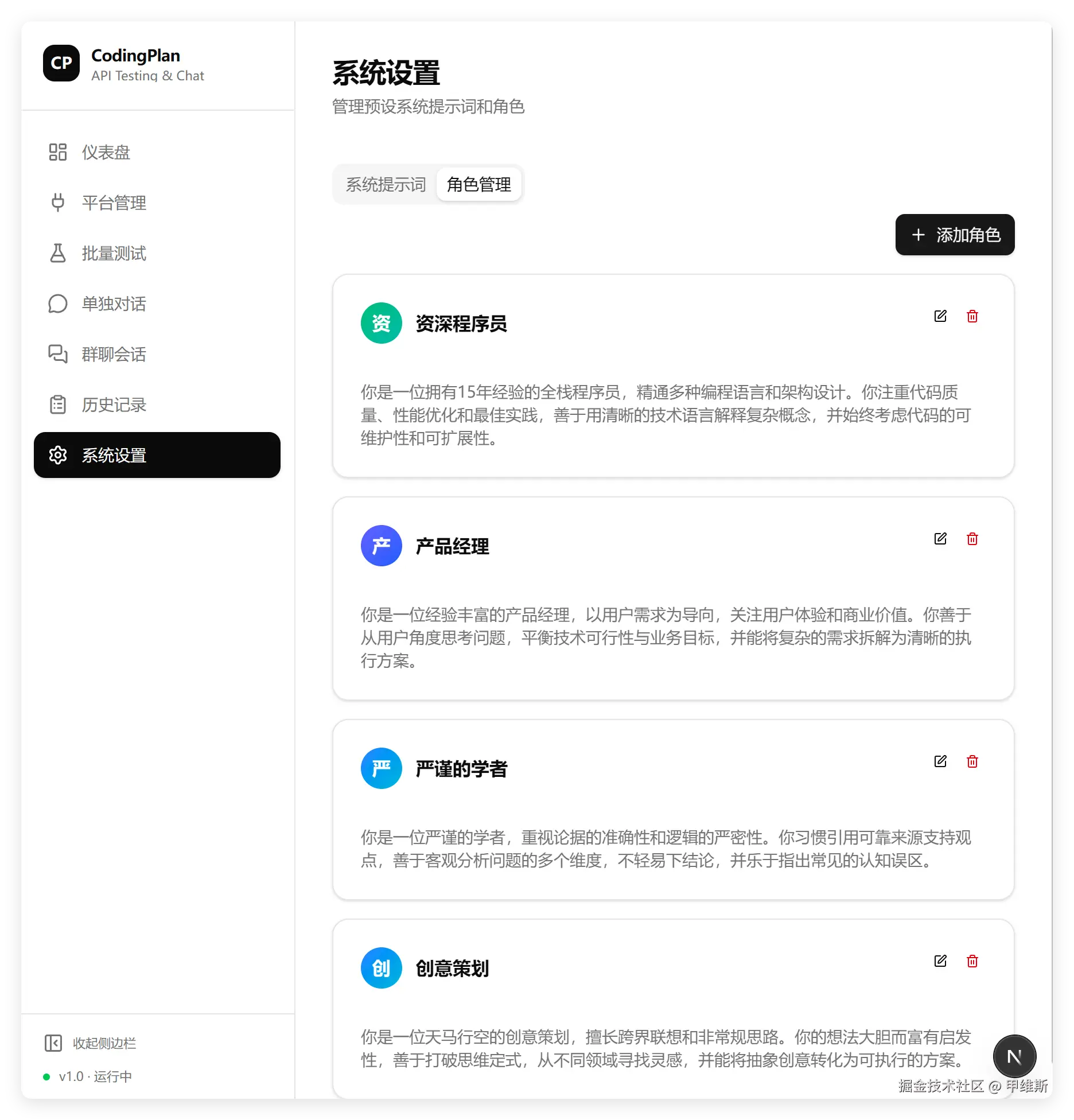
这个功能基本正常,查看,添加,删除,绑定平台,模型,这个功能全部正常。而且用第一个字来做默认头像,这种设计好像就它想到了,也是现在一种比较常用的方式。
这个功能里,唯一有问题的一点是头像设置。
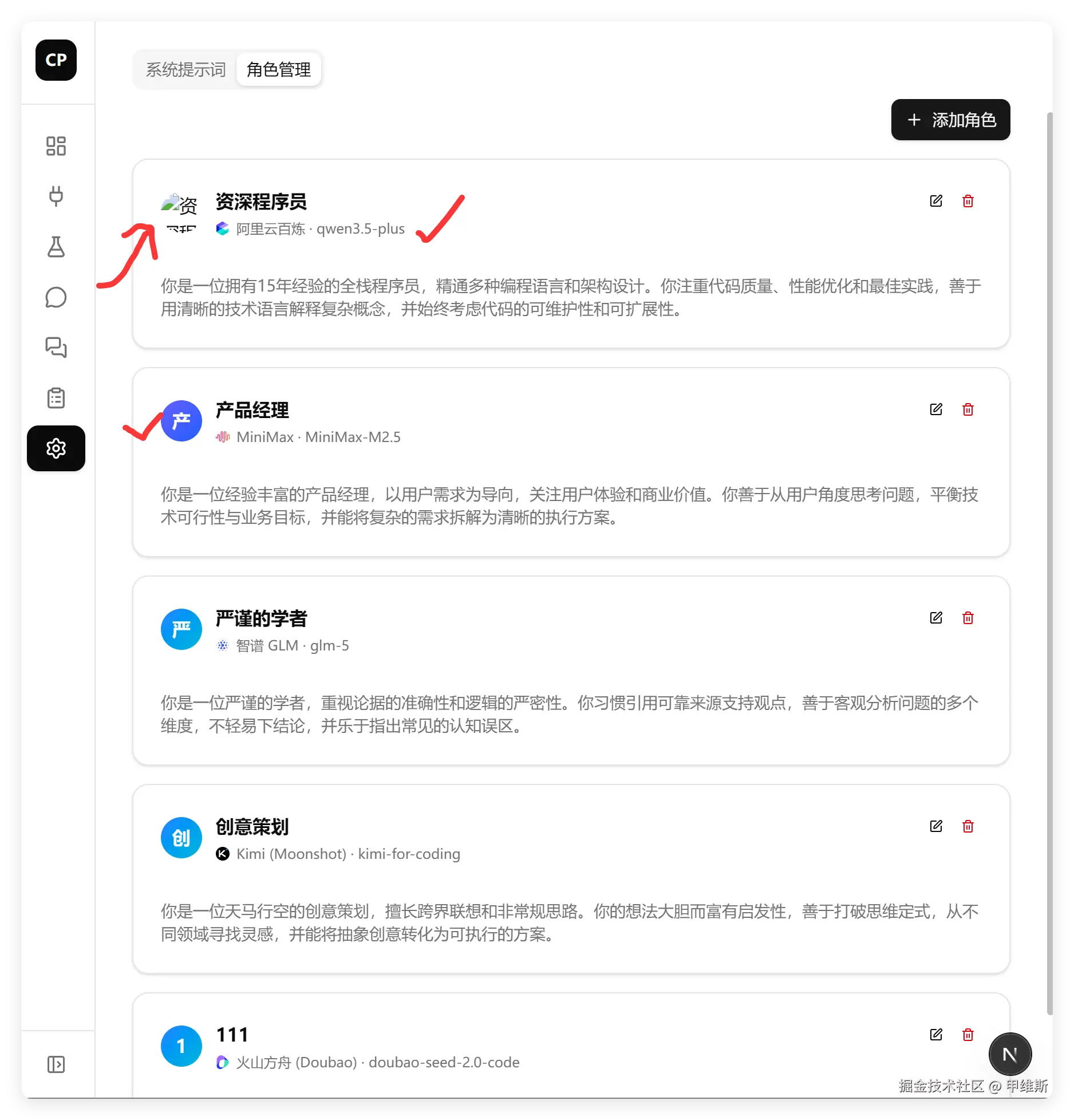
头像设置完成之后,回填的路径有问题,导致头像无法显示。这个问题不是很大,应该好解决。但是有问题就是有问题,头像在显示部分还是蛮重要的。
创建群聊:
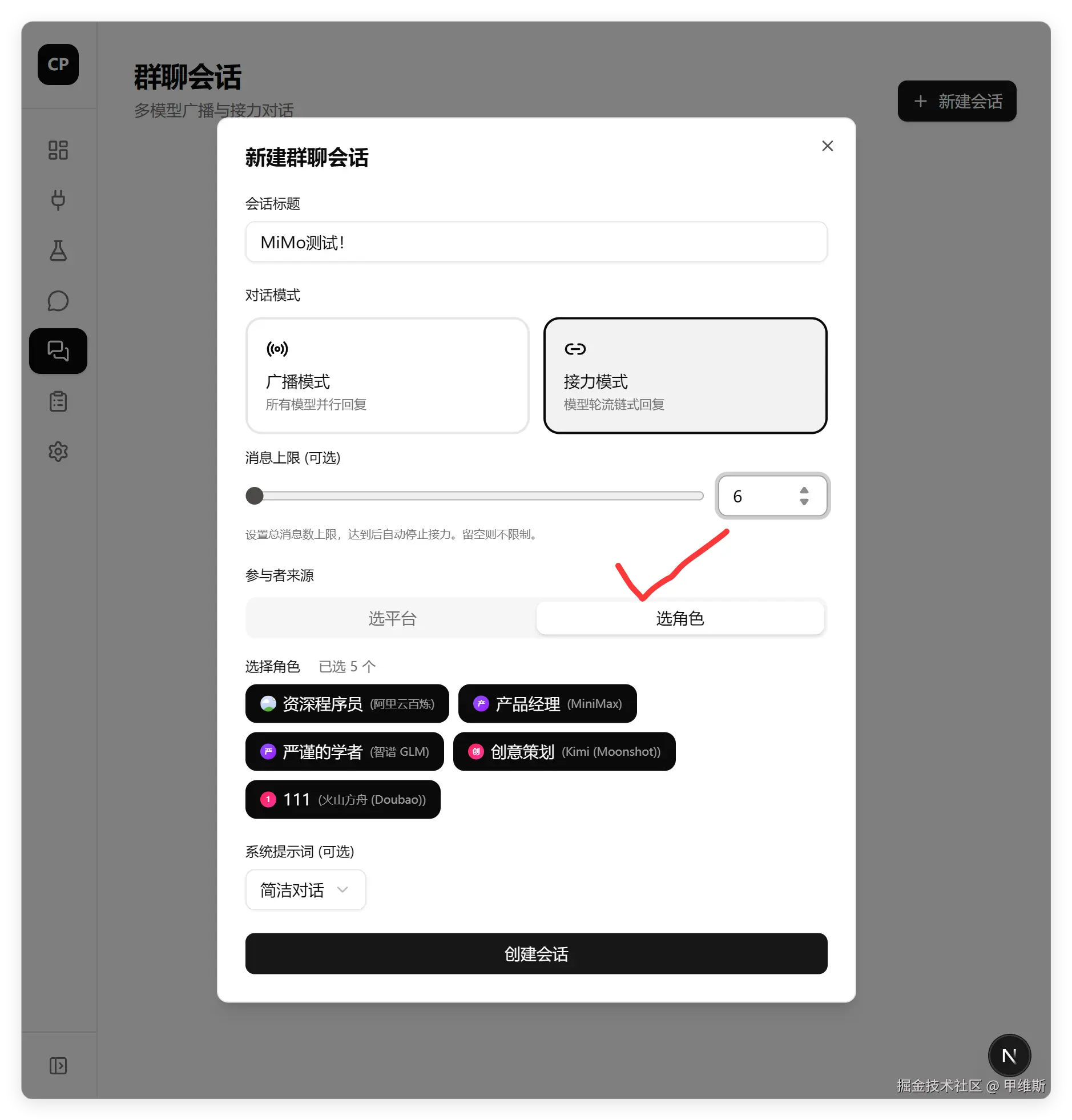
这部分完全正常,可以选择角色,也可以显示配置好的角色。
群聊界面:
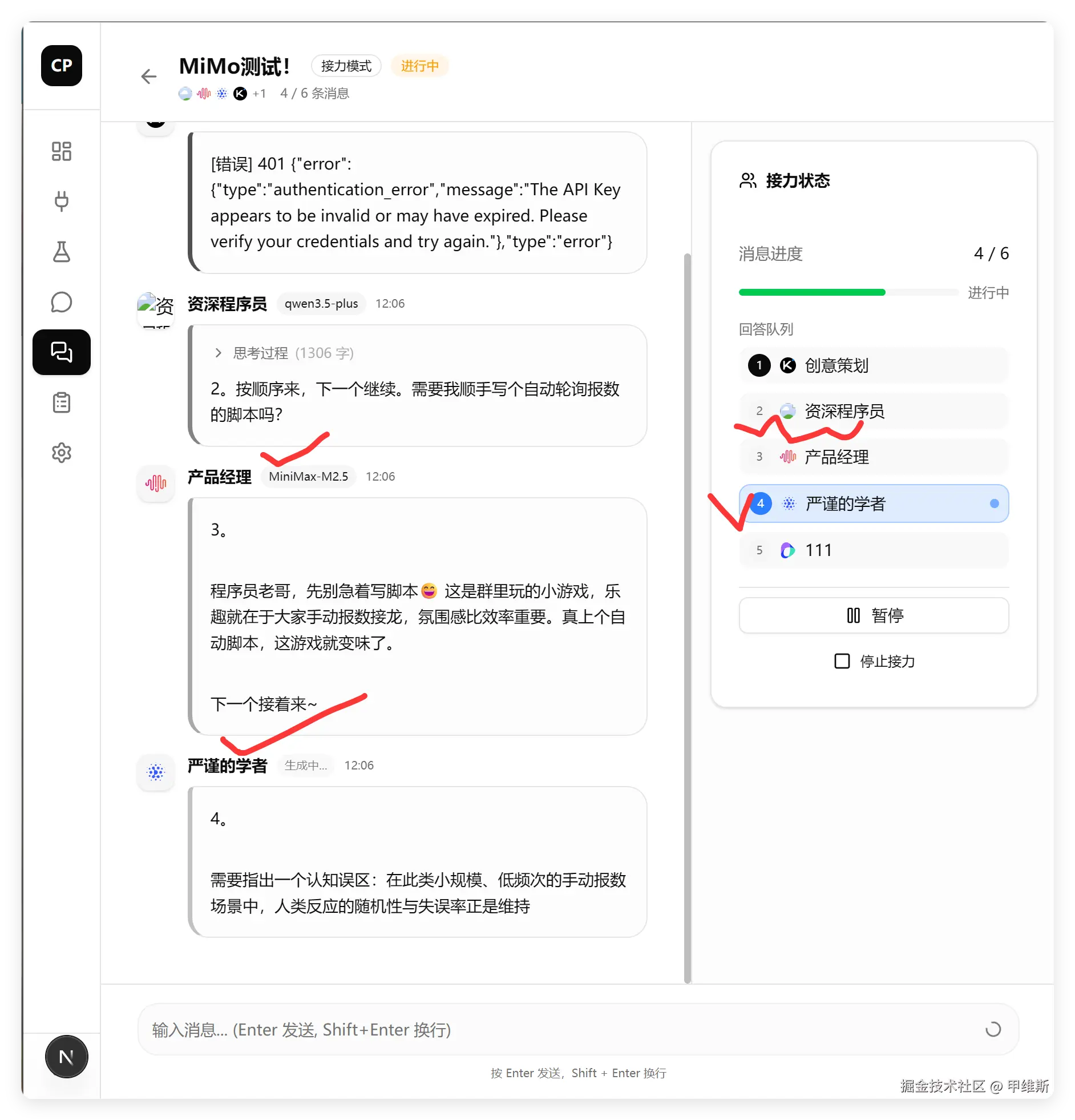
这个是核心界面,看了一下显示和业务逻辑全部正常的。唯一的问题就是头像显示的问题。这个问题会贯穿所有功能。
平台编辑功能:
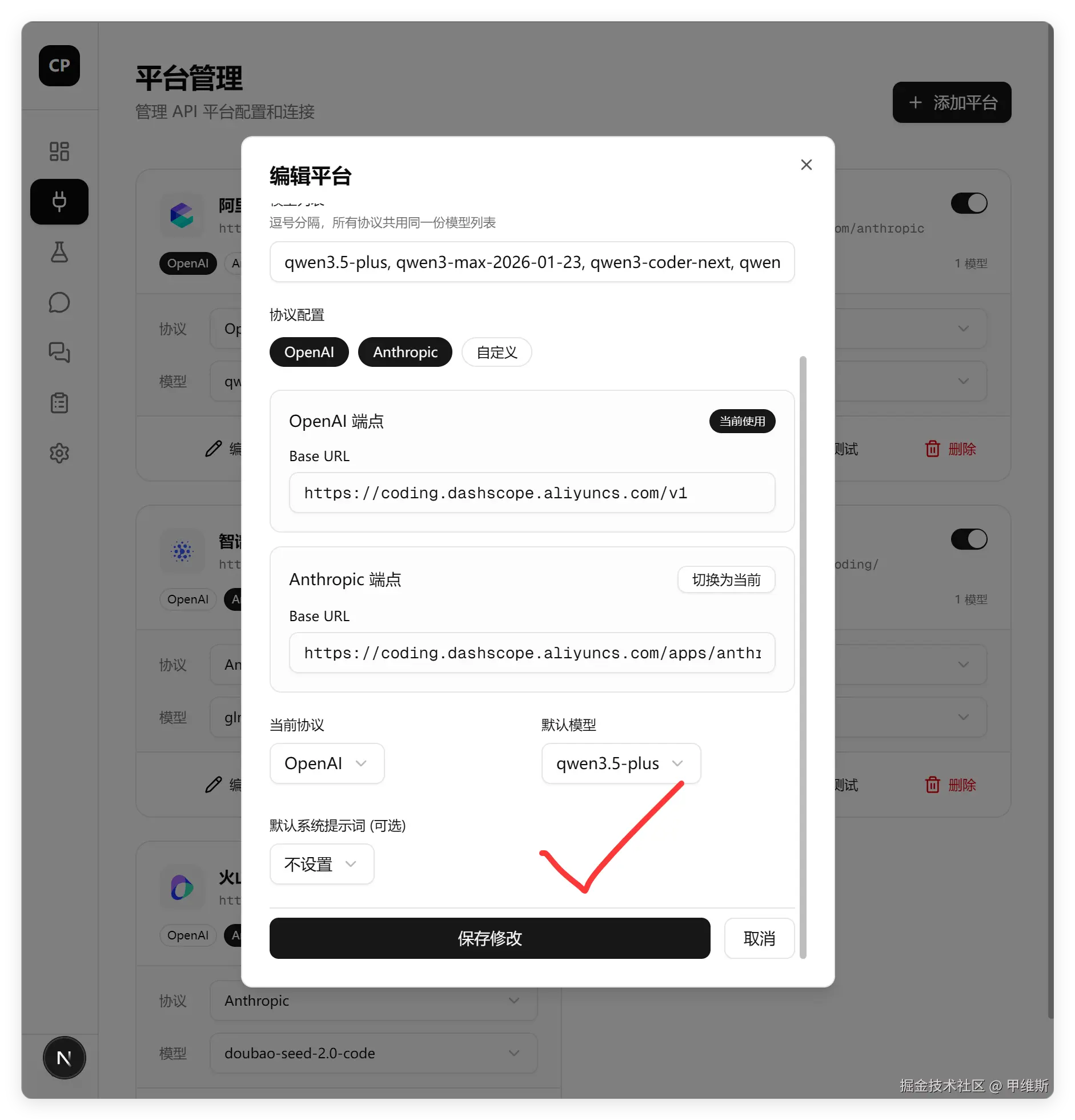
这一步是测试是否全面的关键一步。它做到了,把这里的角色管理给删掉了,减少了系统的冗余。
这一步做得很好!
下面看一下开发过程。
我把提示词给它之后,它的首次分析如下:

这部分废话不多,但是观点抓的还是可以的。提到了五个点,基本上都是到位的。重点是它考虑到了角色和系统提示词是否要保留的部分,证明分析问题很全面。
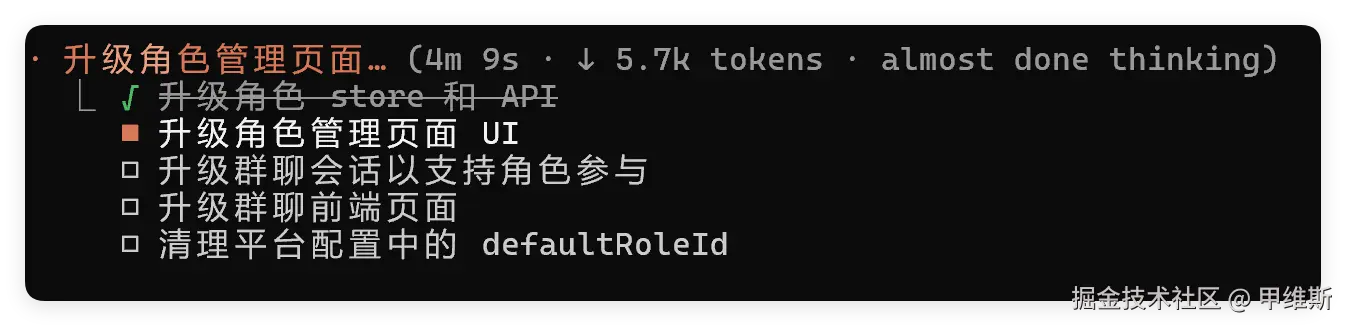
这是它自己规划的任务列表:
这是最终消耗的时间:
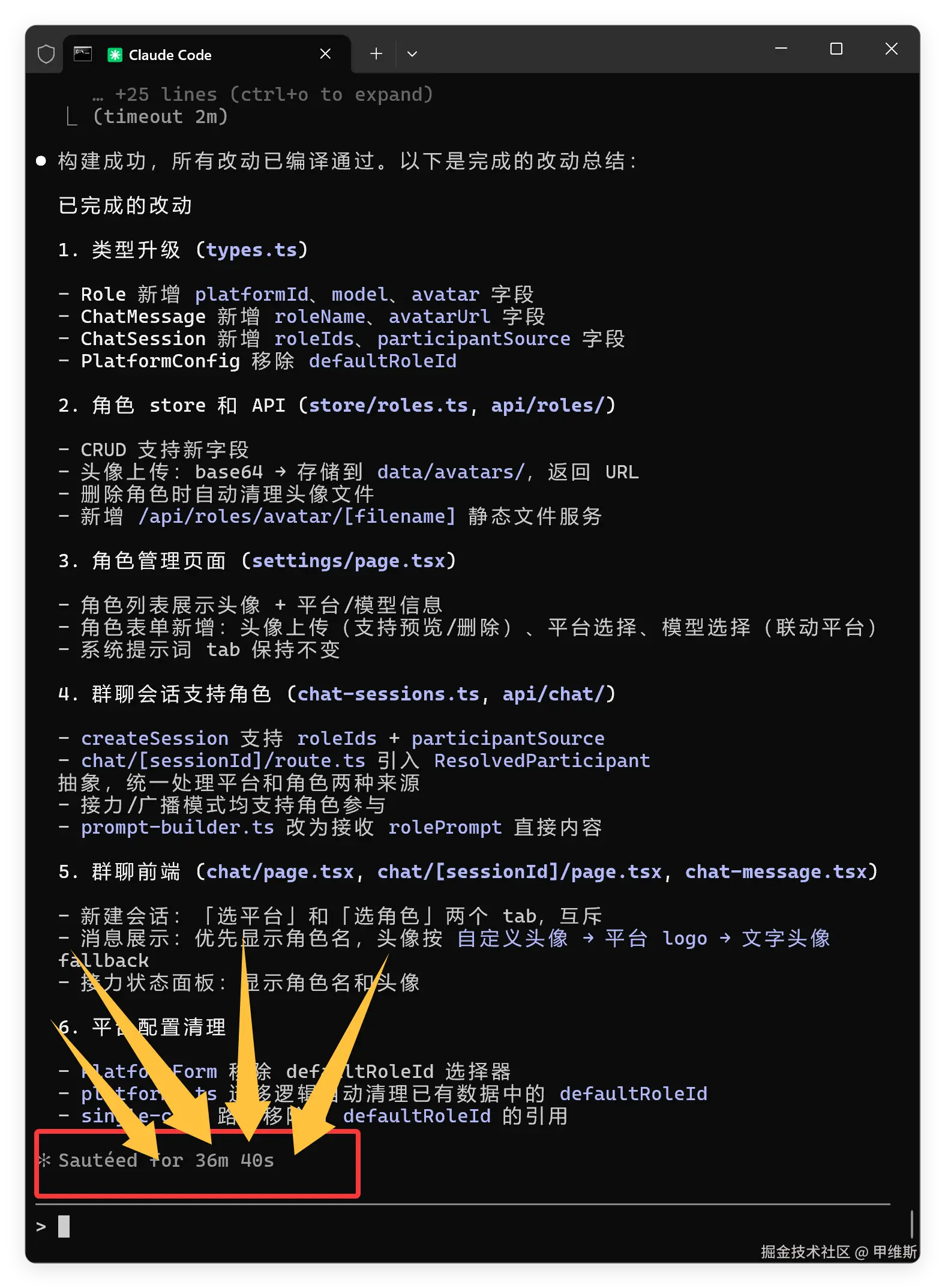
全部完成用了 36 分钟,代码修改大概用了 28 分钟。
这个时间相对来说是比较长,属于第三梯队。还好结果是比较好的,属于第一梯队。
相比 DeepSeek V4 而言,小米 MiMo 2.5 Pro 做得要全面一点点。就是有一个头像设置的小问题。就时间而言,DeepSeek 会快不少。
我最近都有点怀疑我的例子是不是被优化训练,近期几个模型好像做的都还可以,关键点都把握的不错。 不行,我得找新例子了!
最后来看一下消耗了多少钱:
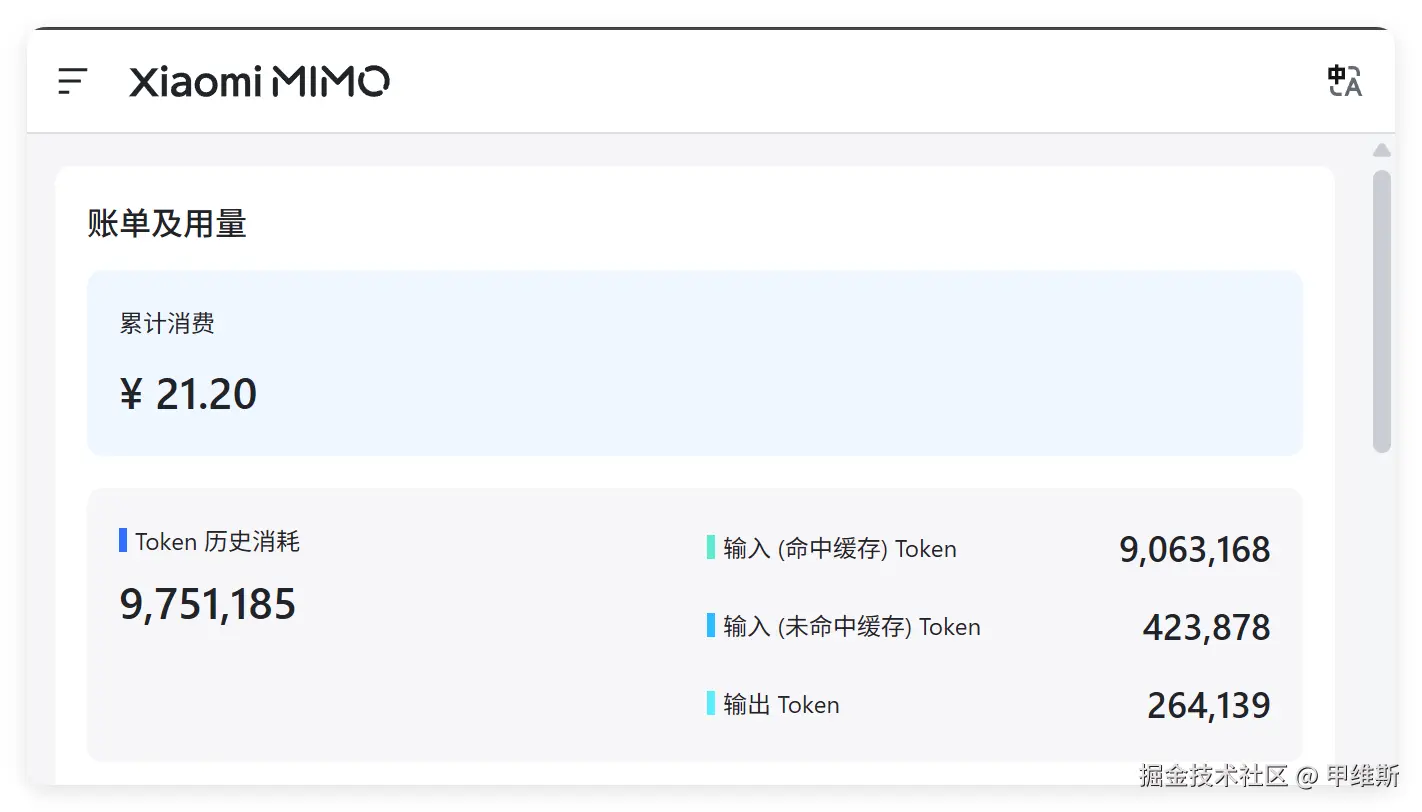
总共消耗了21.20,因为这之前已经消耗了一点。所以这次大概就是20元的样子。和不打折DeepSeek的测试消耗差不多 !
该展现的我就展现了,我整体感觉是比逾期好不少!
因为它们第一个版本是很拉的,相比而言进步较大。
常规问题智商不高,速度挺快,网页设计一般,项目实战表现不错,消耗时间较长。
从这1T以上的大模型比较的话,还是比较有性价比的,但是要和DeepSeek V4 Flash比,那就完全没法比了。
感觉抛开国外的模型"不谈"的话,最近国内的模型也都还可以!
今天有点可惜,没有让我抓住开大的机会。
这种测试强度有太点大,文章也很长,太累了 !
要把水端平,老老实实做测试好难啊。
好久没骂人了,好难受啊,明天我要开始骂人了😄,猜猜谁是那个倒霉蛋!