前言: 哈哈,其实还有一章"文件"的知识没有讲,实在没时间了,暂时搁置,我们直接来看IPC。在 Linux 的哲学里,进程是资源分配的最小单位。由于虚拟地址空间 的隔离,每一个进程都像是一座悬浮在深海中的"孤岛"。但孤岛不应成为死地。我们要如何让两座孤岛安全地交换物资?是修一条狭窄但有序的管道 ?还是划出一片公共的海域(共享内存) ?亦或是通过信号灯来建立某种默契的秩序?下面,正式进入学习!
目录
[1. 引入](#1. 引入)
[2. 目的](#2. 目的)
[3. 本质](#3. 本质)
[4. 常见通信标准与分类](#4. 常见通信标准与分类)
[1. 使用匿名管道的方法](#1. 使用匿名管道的方法)
[2. 管道的本质](#2. 管道的本质)
[3. 管道读写常见的4种情况](#3. 管道读写常见的4种情况)
[4. 进程池实现](#4. 进程池实现)
[(2)FD 的"遗传"问题](#(2)FD 的“遗传”问题)
[5. 匿名管道的特点](#5. 匿名管道的特点)
[1. 命名管道的创建](#1. 命名管道的创建)
[2. 阻塞机制](#2. 阻塞机制)
[3. 从内核简单理解](#3. 从内核简单理解)
[4. 对比匿名管道](#4. 对比匿名管道)
[5. Client & Server通信](#5. Client & Server通信)
[四、system V共享内存](#四、system V共享内存)
[1. 共享内存的特点](#1. 共享内存的特点)
[(1)最快 IPC](#(1)最快 IPC)
[2. 使用方法](#2. 使用方法)
[(1)ftok ------ 生成唯一 Key](#(1)ftok —— 生成唯一 Key)
[(2)shmget ------ 创建/获取共享内存](#(2)shmget —— 创建/获取共享内存)
[(3)shmat ------ 挂接(Attach)](#(3)shmat —— 挂接(Attach))
[(4)shmdt ------ 去关联(Detach)](#(4)shmdt —— 去关联(Detach))
[(5)shmctl ------ 控制/删除](#(5)shmctl —— 控制/删除)
[3. 结合FIFO进行有原子性的急速通信](#3. 结合FIFO进行有原子性的急速通信)
[五、system V消息队列(略讲)](#五、system V消息队列(略讲))
[1. 特点](#1. 特点)
[2. 使用方法](#2. 使用方法)
[六、system V信号量(略讲)](#六、system V信号量(略讲))
[1. 并发编程的核心概念(多线程铺垫)](#1. 并发编程的核心概念(多线程铺垫))
[2. 信号量的理解](#2. 信号量的理解)
[① P 操作(申请资源 / 减 1)](#① P 操作(申请资源 / 减 1))
[② V 操作(释放资源 / 加 1)](#② V 操作(释放资源 / 加 1))
[3. system V信号量](#3. system V信号量)
[(1)System V 信号量的特点](#(1)System V 信号量的特点)
一、整体概述
1. 引入
进程间通信(Inter-Process Communication, IPC) 是指在不同进程之间传播或交换信息的一种机制。在 Linux 操作系统中,每个进程都拥有独立的虚拟地址空间 。这种"相互隔离"的设计是为了保证系统的稳定性,但同时也带来了一个问题:进程之间无法直接访问对方的内存数据。 因此,为了实现协作(比如数据传输、资源共享、通知事件或进程控制),操作系统必须提供一套专门的"中转站"机制,这就是 IPC。
2. 目的
-
数据传输: 一个进程需要将它的数据发送给另一个进程。
-
资源共享: 多个进程想要操作同一份数据(需要同步机制配合)。
-
通知事件: 一个进程需要向另一个或一组进程发送消息,通知它(们)发生了某种情况(如进程终止)。
-
进程控制: 有些进程希望完全控制另一个进程的执行。
3. 本质
让不同的进程看到同一份"公共资源"!!!
由于进程独立性的存在,这份"公共资源"不能属于任何一个私有进程,它必须由操作系统内核直接提供并管理。不同的 IPC 手段,本质上就是内核开辟了不同形式的缓冲区或文件。
4. 常见通信标准与分类
在 Linux 演进过程中,逐渐形成了三大主流 IPC 体系:
- 管道(Pipe): 包括匿名管道和命名管道,是最古老、最轻量的通信方式。
- System V IPC: 也就是你大纲里提到的共享内存、消息队列和信号量。它主要用于单机内进程间的高效通信。
- POSIX IPC: System V 的现代替代方案,接口更简洁,可移植性更强。
二、匿名管道
我们把从一个进程连接到另一个进程的一个数据流称为一个"管道"。命令行中经常使用的
|符号(如ls | grep txt),其底层实现就是匿名管道。
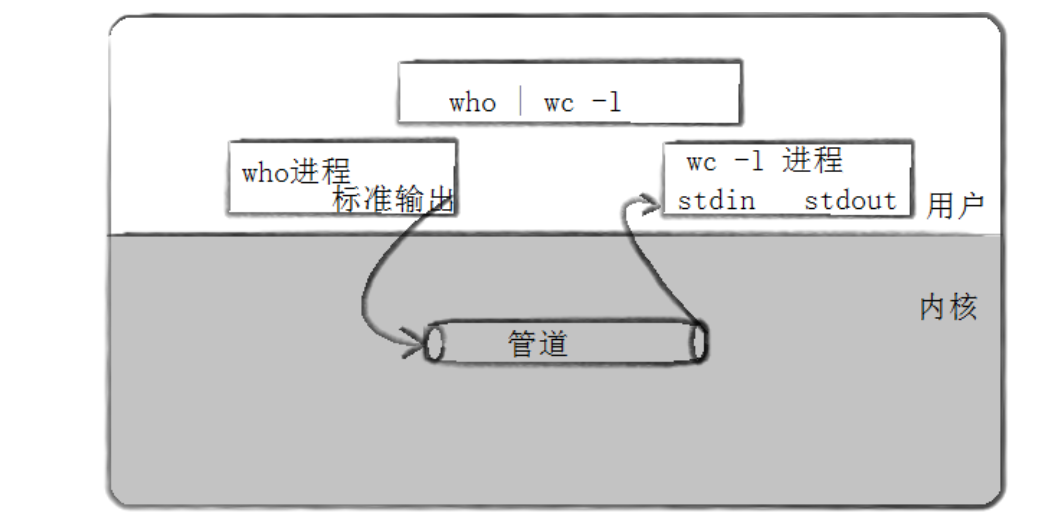
1. 使用匿名管道的方法
(1)调用接口
cpp
#include <unistd.h>
int pipe(int pipefd[2]);-
参数: 一个整型数组,包含两个文件描述符。
pipefd[0]:读端 (Read);pipefd[1]:写端 (Write) -
返回值: 成功返回 0,失败返回 -1。
(2)父子进程通信的经典步骤
-
父进程调用
pipe():得到两个 FD,分别指向管道读写端。 -
父进程调用
fork():子进程继承父进程的文件描述符表,此时父子都指向同一个管道。 -
关闭多余 FD :如果父写子读,父进程
close(fd[0]),子进程close(fd[1])。这是为了防止 FD 泄露,并确保管道在最后一名写者退出时能正确触发 EOF。
2. 管道的本质
(1)宏观理解
匿名管道本质上是 内核维护的一块内存缓冲区 。它表现为一个伪文件 ,虽然有文件描述符,但并不存在于磁盘上,在较新的 Linux 内核中,管道默认容量是 64KB。由于它没有名字(匿名),外部进程无法通过路径找到它,所以一般只能用于父子进程,且它是内存级的文件,无路径。
(2)底层理解
在 Linux 中,一切皆文件。匿名管道在内核中其实是一个没有路径名的 inode 。当父进程调用 int pipe(fd[2]) 时,内核在内存中分配一个 inode 节点和一块共享缓冲区(通常是 64KB),同时创建两个 struct file 结构体,一个标记为"只读",一个标记为"只写"。在父进程的 文件描述符表 中分配两个最小的可用数字,分别指向这两个 file 结构体。所以,fd[0] 和 fd[1] 指向的是同一个内核缓冲区,只是访问权限不同。
调用 fork() 时,子进程会完整拷贝 父进程的文件描述符表(浅拷贝)。拷贝完成后父进程的 fd[0]/fd[1] 和子进程的 fd[0]/fd[1] 指向相同的内核 file 对象。此时,管道读端的引用计数为 2,写端的引用计数也为 2。如果同一个父进程用不同的管道循环创建子进程,那每个管道都会被下一个子进程继承。
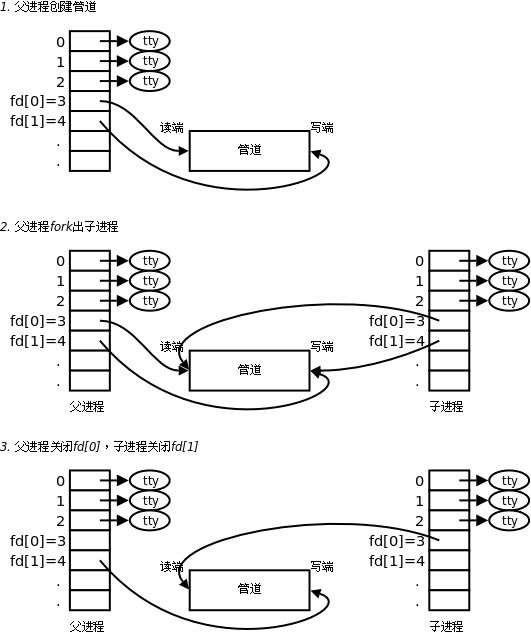
为什么要"关掉不需要的 FD"?
写端不关闭的影响 :如果父进程负责读,子进程负责写。若父进程不关闭
fd[1](写端),那么即使子进程写完退出了,管道写端的引用计数依然为 1(父进程还握着)。此时父进程调用read会永久阻塞,因为它认为"还有人可能要写",永远等不到 EOF(read 返回 0)。读端不关闭的影响:如果子进程留着
fd[0]没关,即便父进程(真正的读者)已经挂了,由于子进程自己还握着一个读端,内核会认为"这根管子还有人在听"。子进程继续写入时不会 触发SIGPIPE,它会一直写直到把管道缓冲区塞满,然后阻塞在那里。这会导致故障无法及时暴露。管道的原子性 (PIPE_BUF)
Linux 规定,当写入数据量小于
PIPE_BUF(通常是 4096 字节)时,操作是原子性的。这意味着内核保证这块数据连续写入,不会被其他进程的数据插足。如果大于这个值,数据可能会交织。
3. 管道读写常见的4种情况
| 情况 | 场景描述 | 结果 |
|---|---|---|
| 读端等待 | 写端没写,且写端 FD 没关 | 读进程阻塞,直到有数据或 FD 关闭。 |
| 写端等待 | 管道写满了,且读端 FD 没关 | 写进程阻塞,直到管道有空位。 |
| 读到结尾 | 写端已关闭++所有写++ FD | 读进程读完剩余数据后,read 返回 0 (EOF)。 |
| 异常写入 | 读端已关闭++所有读++FD | 内核向写进程发送 SIGPIPE 信号,通常导致进程终止。 |
(1)写正常&&读空
cpp
void readwait()
{
int pipefd[2];
pipe(pipefd);
if (fork() == 0)
{
const char buf[12] = "hello Linux";
close(pipefd[0]);
// 子进程故意睡 3 秒,不写任何数据,也不关闭写端
std::cout << "Child: 没写数据..." << std::endl;
sleep(3);
write(pipefd[1], buf, sizeof(buf));
std::cout << "Child: 写完了,再睡3秒..." << std::endl;
sleep(3);
std::cout << "准备关闭写端" << std::endl;
close(pipefd[1]);
exit(0);
}
close(pipefd[1]);
char buf[64];
std::cout << "Parent: 尝试读取" << std::endl;
// 此时会阻塞在这里,直到子进程写数据或关闭 FD
ssize_t s = read(pipefd[0], buf, sizeof(buf));
std::cout << "Parent: Read returned " << s << " bytes." << std::endl;
}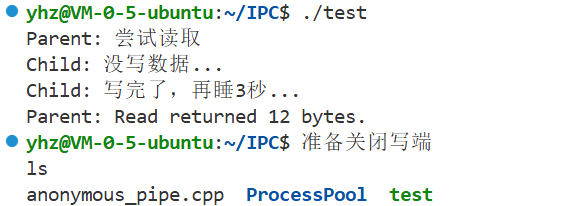
哪怕只有一个字节,read也会停止阻塞!
(2)读正常&&写满
cpp
void writewait()
{
int pipefd[2];
pipe(pipefd);
if (fork() == 0)
{
close(pipefd[1]);
// 子进程不读,直接睡死
sleep(5);
while (true)
{
char buf[24];
int s = read(pipefd[0], buf, 1);
sleep(1);
std::cout << s << " bytes." << std::endl;
}
}
close(pipefd[0]);
int count = 0;
while (true)
{
char c = 'a';
write(pipefd[1], &c, 1);
// 打印写入的字节数,观察到一定数值后会停下
std::cout << "Total bytes written: " << ++count << std::endl;
}
}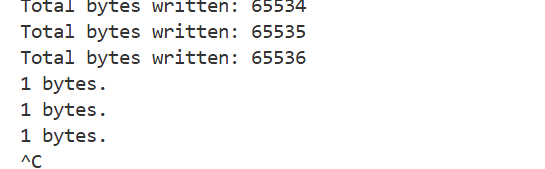
Linux 内核为了提高效率,并不是"腾出 1 字节就立刻唤醒写者"。内核通常会等到管道中有足够大的空间 (例如达到缓冲区的一半,或至少一个页面 4KB)时,才会真正唤醒阻塞在
write上的进程。
(3)写关闭&&读正常
cpp
void readEOF()
{
int pipefd[2];
pipe(pipefd);
if (fork() == 0)
{
close(pipefd[0]);
write(pipefd[1], "hello", 5);
close(pipefd[1]); // 写完立刻关闭写端
std::cout << "Child: Write-end closed." << std::endl;
exit(0);
}
close(pipefd[1]);
sleep(2); // 确保子进程已经关闭写端
char buf[64];
while (true)
{
ssize_t s = read(pipefd[0], buf, sizeof(buf) - 1);
if (s > 0)
{
buf[s] = 0;
std::cout << "Parent get data: " << buf << std::endl;
}
else if (s == 0)
{
// 关键:read 返回 0 代表 EOF
std::cout << "Parent: EOF !" << std::endl;
break;
}
}
}
bash
yhz@VM-0-5-ubuntu:~/IPC$ g++ anonymous_pipe.cpp -o test
yhz@VM-0-5-ubuntu:~/IPC$ ./test
Child: Write-end closed.
Parent get data: hello
Parent: EOF !(4)读关闭&&写正常
cpp
void sispipe()
{
int pipefd[2];
pipe(pipefd);
pid_t id = fork();
if (id == 0)
{
close(pipefd[1]);
close(pipefd[0]); // 子进程迅速关闭读端并退出
std::cout << "Child: Read-end closed, exiting..." << std::endl;
exit(0);
}
close(pipefd[0]);
sleep(2); // 确保读端已彻底关闭
std::cout << "Parent: 尝试写入" << std::endl;
// 此时内核会向父进程发送 SIGPIPE 信号
ssize_t s = write(pipefd[1], "test", 4);
// 如果没有处理 SIGPIPE,这一行永远不会打印
std::cout << "Parent: Write returned " << s << std::endl;
int status = 0;
waitpid(id, &status, 0);
}
bash
yhz@VM-0-5-ubuntu:~/IPC$ g++ anonymous_pipe.cpp -o test
yhz@VM-0-5-ubuntu:~/IPC$ ./test
Child: Read-end closed, exiting...
Parent: 尝试写入
yhz@VM-0-5-ubuntu:~/IPC$ echo $?
1414. 进程池实现
什么是进程池?
在程序启动之初,父进程就预先创建出固定数量(或动态调整)的子进程。这些进程创建后并不退出 ,而是进入一种"待命阻塞"状态,等待父进程分配任务。父进程 负责接活,并通过管道将任务分发给子进程。子进程负责干活,干完一个任务后不退出,而是回到起点继续读取管道,等待下一个任务。
cpp
//ProcessPool.hpp
#ifndef __PROCESS_POOL_HPP__
#define __PROCESS_POOL_HPP__
#include <iostream>
#include <cstdlib> // stdlib.h stdio.h -> cstdlib cstdio
#include <vector>
#include <unistd.h>
#include <string>
#include <sys/wait.h>
#include "task.hpp"
using namespace std;
// 先描述(定义信道)
class Channel
{
public:
Channel(int wfd, pid_t subpid, int id) // id相当于信道编号
: _wfd(wfd), _subpid(subpid)
{
_name = "Channel-" + std::to_string(id) + "(FD:" + std::to_string(_wfd) + ")";
}
void Sendtask(int code) { write(_wfd, &code, sizeof(code)); }
// 给子进程发送任务时,需要父进程在管道中写入任务编号
void Close() { close(_wfd); }
// 关闭该父进程的写端
// 问题1:子进程的读端在哪里关?
void Wait() { waitpid(_subpid, nullptr, 0); }
// 等待回收子进程
string Name() { return _name; }
private:
int _wfd; // 找到想要信道的重要标志
pid_t _subpid; // 该信道对应的子进程pid
string _name;
};
class ProcessPool
{
public:
ProcessPool(int num) : _process_num(num), _next(0) {}
void SubProcessWork()
{
// 问题2:这是纯工作逻辑,它是如何确保我能找到想要的信道呢?
while (true)
{
int task_code = 0;
int n = read(STDIN_FILENO, &task_code, sizeof(task_code));
// 此时的task_code变为对应的任务号,我们已经把读端重定向到STDIN_FILENO了
if (n == sizeof(task_code))
{
_tm.Execute(task_code); // 执行任务
}
else if (n == 0)
{
cout << "检测到读取至文件末尾,程序退出" << endl;
break;
}
else
{
perror("读取错误");
}
}
}
bool InitAndStart()
{
vector<int> master_write_fds;
for (int i = 0; i < _process_num; i++)
{
int pipefd[2];
pipe(pipefd);
pid_t id = fork();
if (id == 0)
{
for (auto e : master_write_fds)
close(e);
// 问题3:master_write_fds是什么,为什么要这么干
close(pipefd[1]);
dup2(pipefd[0], STDIN_FILENO);
// 问题4:这里将读端重定向到STDIN_FILENO有什么好处
close(pipefd[0]);
// 重定向后关闭读端,但此时的计数不为0
SubProcessWork();
exit(0);
}
else if (id > 0)
{
close(pipefd[0]); // 父进程不需要读
_channels.emplace_back(pipefd[1], id, i);
// 每创建一个子进程,都需要把它添加到管理链表中
// 而有了pipefd[1]与id,我就能精准找到信道并传输
master_write_fds.emplace_back(pipefd[1]);
}
else
{
perror("子进程创建异常");
return false;
}
}
return true;
}
//父进程在 DispatchTasks 时,已经通过选择特定的 _wfd 准确地把数据投递到了对应子进程的嘴里
void DispatchTasks(int count)
{
for (int i = 0; i < count; i++)
{
int code = _tm.taskcode();
_next = (_next + 1) % _channels.size();
// 使用轮询策略使得每个子进程负载均衡
// 选择信道
Channel &c = _channels[_next];
cout << "[Master] 指派任务 " << code << " 给 " << c.Name() << endl;
c.Sendtask(code);
sleep(1);
}
}
void Quit()
{
for (auto &c : _channels)
c.Close();
// 在这个过程中子进程仍然再执行任务
for (auto &c : _channels)
c.Wait();
cout << "进程池已平稳关闭并回收。" << endl;
}
private:
int _process_num; // 创建的进程数量,即有几个信道
std::vector<Channel> _channels; // 再组织,将所有信道添加在一个数组里,这样父进程才能控制子进程
TaskManager _tm; // 任务管理器
int _next; // 轮询编号
};
#endif
cpp
//task.hpp
#pragma once
#include <iostream>
#include <vector>
#include <functional>
#include <ctime>
#include <unistd.h>
using namespace std;
using task_t = std::function<void()>;
// --- 模拟具体任务 ---
void PrintLog() { std::cout << "子进程 [" << getpid() << "] 正在日志记录..." << std::endl; }
void Download() { std::cout << "子进程 [" << getpid() << "] 正在执行下载..." << std::endl; }
void FlushNet() { std::cout << "子进程 [" << getpid() << "] 正在刷新网络..." << std::endl; }
class TaskManager
{
public:
TaskManager()
{
srand(time(nullptr));
Register(PrintLog);
Register(Download);
Register(FlushNet);
}
void Register(task_t p)
{
_tm.emplace_back(p);
}
int taskcode()
{
return rand() % _tm.size();
}
void Execute(int code)
{
if (code >= 0 && code < _tm.size())
{
_tm[code]();
}
}
private:
vector<task_t> _tm;
};
cpp
#include "ProcessPool.hpp"
int main()
{
// 创建一个包含 5 个子进程的进程池
ProcessPool *pool = new ProcessPool(5);
// 1. 初始化并启动
if (!pool->InitAndStart())
{
std::cerr << "进程池启动失败!" << std::endl;
return 1;
}
// 2. 父进程开始分发任务(比如分发 10 个任务)
pool->DispatchTasks(10);
// 3. 任务处理完毕,优雅退出
pool->Quit();
delete pool;
return 0;
}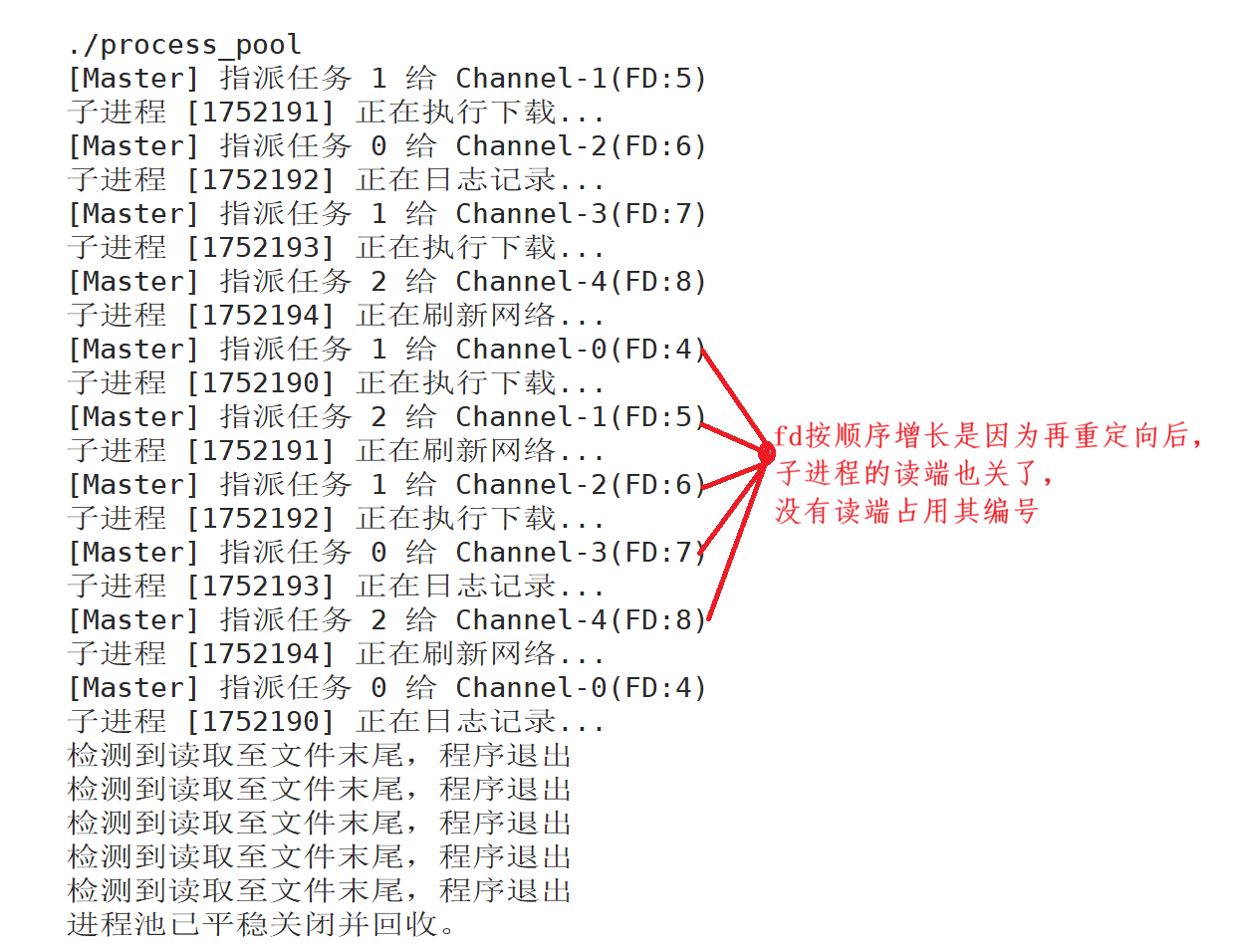
(1)为什么要重定向?
在子进程中使用 dup2(pipefd[0], STDIN_FILENO),可以将管道读端替换为标准输入。这样你的 ChildTask 任务函数就不需要关心 FD 具体是多少,直接用 read(STDIN_FILENO, ...) 即可。这体现了 解耦 的思想。另外,虽然我们立马把它的读端关了,引用计数虽然也减了,但因为 0(STDIN_FILENO) 还指向它,所以引用计数仍然 >= 1 。管道读端不会被真正销毁 ,子进程依然可以通过 0 正常读取。(这也回答了问题1,本来的读端这时就关了,当子进程 exit 时,操作系统内核会自动回收该进程打开的所有文件描述符(包括那个重定向后的读端 FD STDIN_FILENO))。
(2)FD 的"遗传"问题
① 问题解释
假设父进程循环创建子进程P1,P2,P3:
-
创建 P1 时 :父进程创建管道 1,父拥有
w1。P1 继承了w1,随后 P1 只保留读端。 -
创建 P2 时 :父进程创建管道 2,父拥有
w1和w2。P2 fork 出来时,不仅拿到了管道 2 的读端w2,还继承了父进程现有的w1! -
创建 P3 时 :P3 会继承父进程的
w1和w2。
结果: 管道 1 的写端被父进程、P2、P3 同时持有。管道 2 的写端被父进程和 P3 持有。
如果你按照创建顺序(P1,P2,P3)关闭父进程中的写端:父进程关闭 w1。我们希望P1 的 read 返回 0(EOF),然后 P1 退出。但现实是P1 的 read 继续阻塞, 因为 P2 和 P3 手里还握着 w1!只要还有进程握着 w1,P1 就永远等不到 EOF。
② 解决方法1
如果你从最后一个进程开始关 (P3,P2,P1),父进程关闭 w3。因为只有父进程持有 w3,此时管道 3 的写端引用计数清零,P3 读到 EOF,顺利退出。P3 退出时,内核会自动关闭它持有的所有 FD,其中包括它从父进程那继承来的 w1 和 w2。接着父进程关闭 w2。此时管道 2 的写端引用计数归零(因为父关了,P3也退了),P2 顺利退出。以此类推,像多米诺骨牌一样,所有进程都能正常回收。
③ 解决办法2
在 fork 之后,子进程不仅要关闭自己的写端,还要循环关闭从父进程继承来的所有旧写端 。通常父进程会用一个 vector<int> 记录之前所有的写端 FD,子进程一出生就遍历这个 vector 把它们全关了。
5. 匿名管道的特点
-
半双工通信: 数据只能单向流动。如果需要双向通信,必须建立两个管道。
-
亲缘关系限制: 仅限于具有亲缘关系的进程间通信(父子进程、兄弟进程)。
-
面向字节流: 写入和读取没有明确的消息边界,需要用户自行解析。
即使子进程
write了 100 次,每次写 1 字节;父进程也可以只调用 1 次read直接读走 100 字节。反之亦然。数据在管道里是没有"边界"的,就像自来水管里的水。
-
同步机制: 自带等待阻塞机制。如果管道为空,读进程阻塞;如果管道满了,写进程阻塞。
-
生命周期: 随进程。进程退出且引用计数归零后,管道资源由内核自动释放。
三、命名管道
1. 命名管道的创建
(1)引入
匿名管道最大的局限性是:必须有血缘关系 ,命名管道(FIFO) 突破了这个限制。它在磁盘上有一个真实的文件节点 (路径),任何进程只要知道这个路径,就能像打开普通文件一样 open 它,实现通信。
(2)指令创建与删除

(3)系统调用
cpp
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode); //创建
#include <unistd.h>
int unlink(const char *pathname); //删除-
pathname:你想创建的管道文件路径(如./fifo.ipc)。 -
mode:权限(如0666)。 -
返回值 :成功返回 0,失败返回 -1(如果文件已存在,会报错
EEXIST)。
一旦 mkfifo 成功,剩下的逻辑和你操作普通文件、匿名管道完全一致:
-
写端进程:
open(path, O_WRONLY)->write()->close() -
读端进程:
open(path, O_RDONLY)->read()->close()
unlink删除技术
删除的是文件名(目录项),不是数据;数据在没有进程打开 && 硬链接计数为 0 时才真正删除。这种延迟删除机制让临时文件变得非常安全!
2. 阻塞机制
当你调用 open 打开一个命名管道时,内核会强制进行同步。
-
场景 A: 进程以 只读 (
O_RDONLY) 方式打开 FIFO。-
结果:
open调用会直接卡住(阻塞)。 -
直到: 有另一个进程以 写 (
O_WRONLY或O_RDWR) 方式打开这个 FIFO。
-
-
场景 B: 进程以 只写 (
O_WRONLY) 方式打开 FIFO。-
结果: 同样会阻塞。
-
直到: 有另一个进程以 读 (
O_ONLY或O_RDWR) 方式打开它。
-
命名管道是用来"传情"的,不是用来"存钱"的。如果没有另一方在听/说,内核认为这次 open 没有意义,所以让你原地等待。如果成功进入下一步,read与write的阻塞原理就和匿名管道一样了。如果在 open 时指定 O_NONBLOCK,则不会等待对方,直接返回(若为只写打开且无读端,会报错 ENXIO)
3. 从内核简单理解
(1)伪装成文件的"内存缓冲区"
虽然我们通过 ls -l 能看到命名管道文件,但它与普通文件的内核实现有着本质区别:
-
磁盘上只有"名" :命名管道在磁盘上仅占用一个 Inode 节点,记录文件的路径、权限、类型(
p)。它不占用任何磁盘数据块(Data Block) ,其文件大小永远显示为 0。 -
内核中有"实" :当进程调用
open打开 FIFO 时,内核会在内存中为其开辟一块环形缓冲区(Ring Buffer) ,其核心结构是struct pipe_inode_info。 -
结论 :命名管道本质上是披着文件系统外衣的内核缓冲区。数据只在内存中流转,绝不落盘。
(2)核心数据结构:pipe_inode_info
在内核源码中,匿名管道和命名管道共享同一套管理逻辑。关键点如下:
- 环形缓冲区 :内核默认分配 64KB 的内存空间。通过
head和tail指针实现循环读写。 - 等待队列 (Wait Queues) :
rd_wait,当管道为空,读进程在此"休眠";**wr_wait,**当管道满,写进程在此"休眠"。 - 引用计数 :内核记录当前的
readers(读端数)和writers(写端数),这是触发 EOF 和 SIGPIPE 的物理依据。
(3)数据流转:两次拷贝
从内核看,管道通信虽然高效,但仍存在两次数据拷贝开销:
- Copy 1 :数据从 用户空间缓冲区 拷贝到 内核环形缓冲区 (
copy_from_user)。 - Copy 2 :数据从 内核环形缓冲区 拷贝到 目标用户空间 (
copy_to_user)。
4. 对比匿名管道
| 维度 | 匿名管道 (Pipe) | 命名管道 (FIFO) | 关系结论 |
|---|---|---|---|
| 内核数据结构 | pipe_inode_info (环形缓冲区) |
pipe_inode_info (环形缓冲区) |
相同: 底层逻辑完全一致 |
| 通信方向 | 半双工(单向流转) | 半双工(单向流转) | 相同 |
| 存在形式 | 纯内存,无文件路径 | 内核缓冲区 + 磁盘文件节点 | 不同:FIFO 拥有"名字" |
| 建立方式 | 调用 pipe() 自动生成读写端 |
先 mkfifo 创建,再 open 打开 |
不同 |
| 通信范围 | 仅限有亲缘关系的进程 | 任何进程(只要有权限访问路径) | 本质区别 |
| 生命周期 | 随进程结束而销毁 | 节点持久化 ,需手动 unlink |
不同 |
| 阻塞特性 | read/write 缓冲区满/空时阻塞 |
open 阶段就具备"等对方"的阻塞 |
不同 |
| 原子性写入 | 只要一次写入 < PIPE_BUF (4KB) |
只要一次写入 < PIPE_BUF (4KB) |
相同:多对一写入安全 |
| SIGPIPE 信号 | 读端全关,写入即触发 | 读端全关,写入即触发 | 相同 |
| 传输开销 | 两次拷贝(用户->内核->用户) | 两次拷贝(用户->内核->用户) | 相同 |
5. Client & Server通信
cpp
//common.hpp
#pragma once
#include <iostream>
#include <string>
#include <cstring>
#include <cerrno>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
using namespace std;
const std::string FIFO_PATH = "./log_fifo";
const mode_t MODE = 0666;
// 定义简单的日志格式
struct LogMsg
{
pid_t client_pid;
char text[128];
};
cpp
// Server.cpp
#include "common.hpp"
int main()
{
int n = mkfifo(FIFO_PATH.c_str(), MODE);
if (n != 0)
{
if (n != EEXIST)
{
perror("创建命名管道失败");
return 1;
}
}
std::cout << "[Server] 正在等待 Client 连接..." << std::endl;
int fd = open(FIFO_PATH.c_str(), O_RDONLY, 0666);
if (fd < 0)
{
perror("open");
return 2;
}
std::cout << "[Server] 信道已建立,准备接收日志。" << std::endl;
while (true)
{
LogMsg msg;
int n = read(fd, &msg, sizeof(msg));
if (n == sizeof(msg))
{
std::cout << "[Log From PID:" << msg.client_pid << "]: " << msg.text << std::endl;
}
else if (n == 0)
{
std::cout << "[Server] 所有 Client 已断开,退出。" << std::endl;
break;
}
else
{
perror("read");
break;
}
}
close(fd);
unlink(FIFO_PATH.c_str());
}
cpp
//Client.cpp
#include "common.hpp"
int main()
{
int fd = open(FIFO_PATH.c_str(), O_WRONLY);
if (fd < 0)
{
perror("找不到文件");
return 2;
}
for (int i = 0; i < 5; i++)
{
LogMsg msg;
msg.client_pid = getpid();
string s = "这是第 " + to_string(i) + " 条日志消息";
strncpy(msg.text, s.c_str(), sizeof(msg.text));
write(fd, &msg, sizeof(msg));
std::cout << "[Client " << getpid() << "] 已发送日志 " << i << std::endl;
sleep(1);
}
close(fd);
return 0;
}
四、system V共享内存
1. 共享内存的特点
(1)最快 IPC
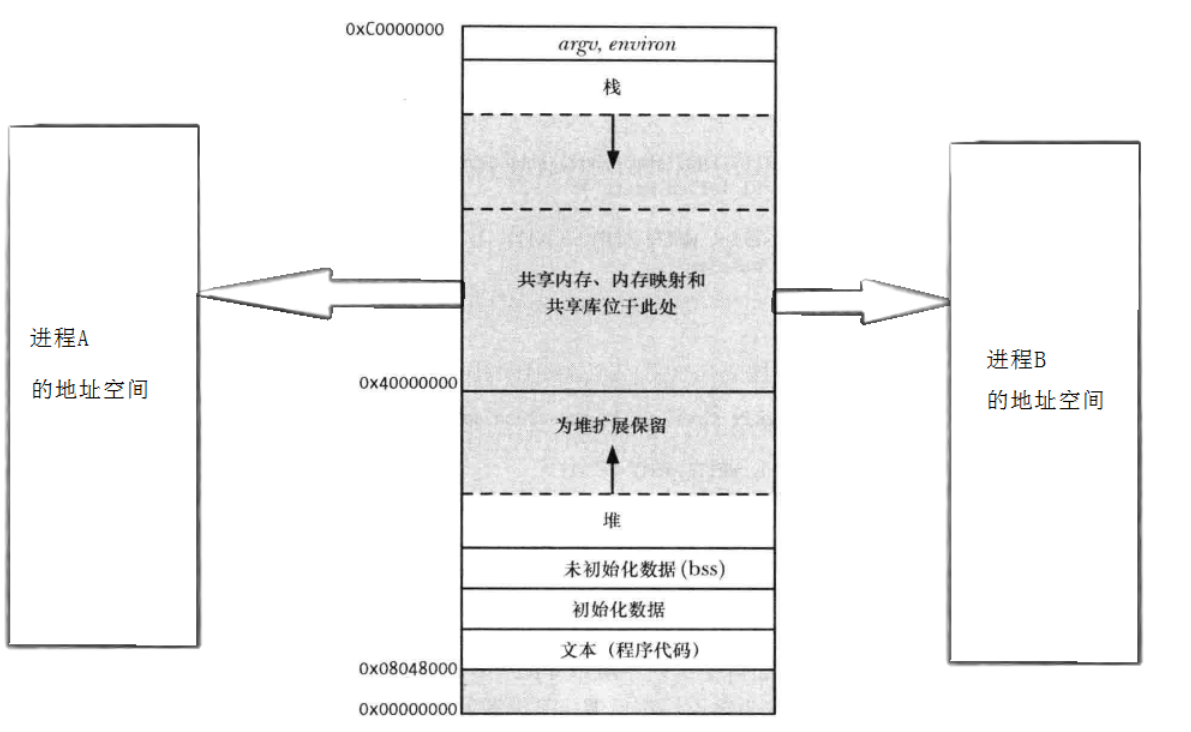
内核在物理内存开辟一块空间,然后通过页表映射 ,直接把这块物理内存挂载到进程 A 和进程 B 的虚拟地址空间 中,即内核在物理内存中开辟了一块空间(比如块丙),然后修改进程 A 的页表, 让 A 的一段虚拟地址(比如 0x4000)指向块丙,再修改进程 B 的页表, 让 B 的一段虚拟地址(比如 0x8000)也指向块丙。进程 A 往内存里写一个变量,进程 B 瞬间 就能看到。0 次系统调用,0 次内核拷贝。这就是它被称为"最快 IPC"的原因。
注意点:
你可以像定义数组、结构体一样在共享内存上操作。但不能在共享内存里存储普通的 C++ 指针 (比如
std::vector或std::string)。因为指针存的是 A 进程的虚拟地址,到了 B 进程那里就变成了野指针。
(2)没有原子性
内核不提供任何保护,它就是一块裸内存,如果进程 A 还没写完,进程 B 就去读,读到的就是破碎的数据。它必须配合信号量、互斥锁(Mutex)或命名管道(FIFO)等来协调步调。
(3)生命周期
不同于管道(随进程销毁),共享内存的元数据存储在内核的 shm_kernel_info 链表中,**如果不手动删除,**即使创建它的进程退出了,物理内存依然被占用,直到系统重启或显式调用删除函数。
(4)ipcs命令
| 命令 | 作用 | 记忆点 |
|---|---|---|
ipcs -m |
只查看 共享内存 (Memory) | 最常用 ,排查 File exists 必用 |
ipcs -s |
只查看 信号量 (Semaphore) | 后面学信号量同步时会用到 |
ipcs -q |
只查看 消息队列 (Queue) | 查看异步消息堆积情况 |
ipcs -a |
查看 所有 (All) 资源 | 默认选项,信息量很大 |

bash
yhz@VM-0-5-ubuntu:~$ ipcrm -m *****(shmid) #删除操作(5)存储结构
cpp
/* 共享内存描述符 */
struct shmid_kernel {
struct kern_ipc_perm shm_perm; // IPC 权限
struct file *shm_file; // 关联的文件对象
unsigned long shm_nattch; // 附加进程数
unsigned long shm_segsz; // 段大小(字节)
time64_t shm_atim; // 最后附加时间
time64_t shm_dtim; // 最后分离时间
time64_t shm_ctim; // 最后修改时间
pid_t shm_cprid; // 创建者 PID
pid_t shm_lprid; // 最后操作者 PID
struct user_struct *mlock_user; // 锁内存的用户
};
// ipc/shm.c 中的全局数组
struct shmid_kernel *shm_segs[SHMMNI]; // 共享内存段数组2. 使用方法
(1)ftok ------ 生成唯一 Key
cpp
#include <sys/ipc.h>
#include <sys/types.h>
key_t ftok(const char *pathname, int proj_id);① 参数详解:
-
pathname:一个已经存在 且进程有权访问的路径(通常用当前目录.)。内核会利用该路径的 Inode 编号进行计算。 -
proj_id:子序号。虽然是int,但只有低 8 位有效(取值范围 1-255)。
② 返回值:
-
成功:返回一个
key_t值(本质是int)。 -
失败:返回
-1,并设置errno。
③ 注意点:
它不创建任何东西,只是一个哈希算法 。只要路径和 ID 相同,不同进程生成的 key 就相同,从而能找到同一块内存。
(2)shmget ------ 创建/获取共享内存
cpp
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);① 参数详解:
-
key:由ftok产生的标识符。 -
size:共享内存的大小(单位:字节)。内核是以页(4KB)为单位分配的。如果你申请 4097 字节,内核实际会给你 8KB,但你只能用 4097字节。在共享内存的世界里,用户是按'字节'买单,但内核是按'页'发货。你可以申请 1 字节,但内核必须给你一整张 4KB 的入场券,因为这是硬件映射的底线。 -
shmflg:IPC_CREAT,不存在则创建,存在则返回已有的 ID;IPC_EXCL,与IPC_CREAT连用(IPC_CREAT | IPC_EXCL),若已存在则报错返回-1,它可以保证你创建的是全新的块 ;权限位 :必须加上0666等权限,否则后续shmat会失败。
② 返回值:
-
成功:返回共享内存的 ID(shmid)。这是进程内操作的句柄(类似文件描述符)。
-
失败:返回
-1。
(3)shmat ------ 挂接(Attach)
cpp
void *shmat(int shmid, const void *shmaddr, int shmflg);① 参数详解:
-
shmid:shmget返回的 ID。 -
shmaddr:指定映射到虚拟地址空间的哪个位置,一般传nullptr。 -
shmflg:0,可读可写;SHM_RDONLY,只读模式。
② 返回值:
-
成功:返回指向共享内存首地址的 虚拟地址指针 (
void*), 这就是你操作内存的起点, 可以直接强转为char*或struct*。 -
失败:返回
(void*)-1。
(4)shmdt ------ 去关联(Detach)
cpp
int shmdt(const void *shmaddr);-
参数详解:
shmaddr传``shmat成功返回的那个指针。 -
返回值:成功返回0,失败返回-1。
-
注意:这个函数不删除共享内存,只是把当前进程页表里的映射关系给断开了。
(5)shmctl ------ 控制/删除
cpp
int shmctl(int shmid, int cmd, struct shmid_ds *buf);① 参数详解:
-
shmid:共享内存 ID。 -
cmd:操作命令。IPC_RMID是最常用的,用来标记删除该内存段。IPC_STAT,获取共享内存的状态(放入buf中)。 -
buf:指向shmid_ds结构的指针,用于获取或设置属性。如果只是删除,传NULL。
② 返回值:成功返回0,失败返回-1。
③ 关键点:IPC_RMID 并不是立即销毁,而是将该内存标记为"已删除"。只有当所有挂接该内存的进程都断开(引用计数归零)后,内核才会真正释放物理内存。
④ struct shmid_ds 结构体
cpp
struct shmid_ds
{
struct ipc_perm shm_perm; // 操作权限
size_t shm_segsz; // 共享内存段大小(字节)
time_t shm_atime; // 最后一次 attach 时间
time_t shm_dtime; // 最后一次 detach 时间
time_t shm_ctime; // 最后一次修改时间
pid_t shm_cpid; // 创建者 PID
pid_t shm_lpid; // 最后一次操作者的 PID
shmatt_t shm_nattch; // 当前 attach 的进程数
// ... 其他实现相关的字段
};(6)创建流程
cpp
#include <iostream>
#include <ctime>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
// 1. 生成 Key
key_t key = ftok(".", 0x88);
// 2. 创建共享内存 (4KB)
int shmid = shmget(key, 4089, IPC_CREAT | 0666);
if (shmid < 0)
{
perror("shmget");
return 1;
}
// 3. 挂接
void *ptr = shmat(shmid, nullptr, 0);
// 4. 获取内核属性 (IPC_STAT),这一步非必须。
struct shmid_ds ds; // 定义一个输出型参数结构体
if (shmctl(shmid, IPC_STAT, &ds) == 0)
{
std::cout << "内存大小: " << ds.shm_segsz << " bytes" << std::endl;
std::cout << "当前挂接进程数: " << ds.shm_nattch << std::endl;
printf("权限 : %o\n", ds.shm_perm.mode);
std::cout << "最后挂接时间: " << ctime(&ds.shm_atime);
std::cout << "创建者 PID: " << ds.shm_cpid << std::endl;
}
// 5. 去关联
shmdt(ptr);
// 6. 销毁共享内存 (IPC_RMID)
if (shmctl(shmid, IPC_RMID, nullptr) == 0)
{
std::cout << "\n共享内存标记删除成功!" << std::endl;
}
return 0;
}3. 结合FIFO进行有原子性的急速通信
cpp
//common.hpp
#pragma once
#include <iostream>
#include <string>
#include <cstdio>
#include <cstdlib>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/ipc.h>
#include <sys/shm.h>
const int gdefaultid = -1;
const int gsize = 4096;
const std::string pathname = ".";
const int projid = 0x66;
const int gmode = 0666;
using namespace std;
enum class Role
{
CREATER, // 创建者(Server)
USER // 使用者(Client)
};
#define ERR_EXIT(m) \
do \
{ \
perror(m); \
exit(EXIT_FAILURE); \
} while (0)
cpp
//Fifo.hpp
#include "common.hpp"
class Namepipe
{
public:
string fifoname;
Namepipe(const string &path = pathname, const string &name = "myfife")
{
fifoname = path + "/" + name;
int n = mkfifo(fifoname.c_str(), gmode);
if (n != 0)
{
if (n != EEXIST)
{
ERR_EXIT("mkfifo");
}
}
}
~Namepipe()
{
int n = unlink(fifoname.c_str());
if (n < 0)
ERR_EXIT("unlink");
}
};
class FileOper
{
public:
FileOper(const string &path, const string &name, Role role)
: _fd(-1)
{
_fifoname = path + "/" + name;
if (role == Role::CREATER)
readfile();
else
writefile();
}
void readfile()
{
_fd = open(_fifoname.c_str(), O_RDONLY, 0666);
if (_fd < 0)
{
ERR_EXIT("open");
}
}
void writefile()
{
_fd = open(_fifoname.c_str(), O_WRONLY);
if (_fd < 0)
{
ERR_EXIT("open");
}
}
bool Wait()
{
char c = ' ';
int n = read(_fd, &c, sizeof(c));
if (n > 0)
return true;
else
return false;
}
void Wakeup()
{
char c;
int n = write(_fd, &c, sizeof(c));
if (n < 0)
ERR_EXIT("write");
}
~FileOper()
{
if (_fd != -1)
close(_fd);
}
private:
int _fd;
string _fifoname;
};
cpp
//Shm.cpp
#include "common.hpp"
class Shm
{
public:
Shm(const string &pathname, const int projid, Role role)
: _id(-1), _shmptr(nullptr), _role(role)
{
key_t key = ftok(pathname.c_str(), projid);
int flg;
if (_role == Role::CREATER)
flg = IPC_CREAT | IPC_EXCL | gmode;
else
flg = IPC_CREAT;
_id = shmget(key, 4096, flg);
if (_id < 0 && errno == EEXIST)
{
// 如果已存在,先获取旧的 ID 删掉,再重新创建
int old_id = shmget(key, gsize, IPC_CREAT);
shmctl(old_id, IPC_RMID, nullptr);
_id = shmget(key, 4096, flg);
}
if (_id < 0)
ERR_EXIT("shmget failed");
_shmptr = shmat(_id, nullptr, 0);
if (_shmptr == (void *)-1)
ERR_EXIT("shmat");
}
void *VirtualAddr() { return _shmptr; }
~Shm()
{
if (_shmptr != (void *)-1)
shmdt(_shmptr);
if (_role == Role::CREATER)
{
if (shmctl(_id, IPC_RMID, nullptr) < 0)
std::cerr << "[Warning] shmctl RMID failed" << std::endl;
else
std::cout << "shm deleted successfully!" << std::endl;
}
}
private:
int _id;
void *_shmptr;
Role _role;
};
cpp
//server.cpp
#include "Fifo.hpp"
#include "Shm.hpp"
int main()
{
Shm shmfifo(pathname, projid, Role::CREATER);
Namepipe fifo(".", "myfifo");
FileOper reader(".", "myfifo", Role::CREATER);
cout << "接收端启动成功,正在接受消息..." << endl;
char *mem = (char *)shmfifo.VirtualAddr();
while (reader.Wait())
{
cout << mem << endl;
}
std::cout << "Server 正常结束" << std::endl;
return 0;
}
//client.cpp
#include "Fifo.hpp"
#include "Shm.hpp"
#include <cstring>
int main()
{
Shm shmfifo(pathname, projid, Role::USER);
FileOper writer(".", "myfifo", Role::USER);
char *mem = (char *)shmfifo.VirtualAddr();
std::cout << "--- 客户端已启动,请输入消息 (输入 'quit' 退出) ---" << std::endl;
while (true)
{
std::cout << "Please Enter# ";
if (fgets(mem, gsize, stdin) == nullptr)
break;
mem[strlen(mem) - 1] = '\0';
if (strcmp(mem, "quit") == 0)
break;
writer.Wakeup();
}
return 0;
}亮点:保证原子性
共享内存本身**不保证原子性,**但在这段代码里,我们人为制造了一个"时序先后":
写者(Client)侧:
-
第一步:直接操作内存(写
mem[0]=c, mem[1]=c)。 -
第二步:调用
writer.Wakeup()。 -
关键点 :只有当 Client 彻底写完内存里的数据后,才会向管道发信号。
读者(Server)侧:
-
第一步:卡在
reader.Wait()睡眠。 -
第二步:管道里有信号了,Server 被唤醒。
-
第三步:读取内存。
结论:管道在这里充当了一个"信号哨兵"。因为 Client 是"先写内存、后发信号",Server 是"先等信号、后读内存",所以 Server 读到的一定是 Client 已经写完的内容。
五、system V消息队列(略讲)
1. 特点
-
内核结构 :它是内核维护的一个消息链表。
-
带标签(Type) :每个消息都有一个
long类型的类型标记。这意味着进程 A 可以只发类型为1的消息,进程 B 可以选择只收类型为1的消息,或者按顺序全收。 -
异步性:发送方把消息丢进队列就可以走人,接收方可以在任意时间去取。
-
双向通信(全双工) :你可以规定,类型
1是 Client 发给 Server 的,类型2是 Server 回复给 Client 的。这样只需要一个队列就能实现双向喊话。
2. 使用方法
(1)my_msg结构体
cpp
struct my_msg
{
long mtype; // 必须 > 0,用于 msgrcv 过滤
char mtext[1024]; // 真正的业务数据
};在使用前,你必须自己定义一个结构体,但第一个成员必须是 long 类型,用于存放消息类型
(2)核心接口
-
msgget:通过key获取或创建消息队列。 -
msgsnd:向队列发送一条消息(包含类型和数据)。 -
msgrcv:从队列中读取指定类型的消息。 -
msgctl:控制队列(如获取状态或销毁IPC_RMID)
六、system V信号量(略讲)
1. 并发编程的核心概念(多线程铺垫)
- 共享资源: 多个执行流(进程或线程)都能看到并访问的资源(共享内存就是)。
- 临界资源 (Critical Resource) :在共享资源中,那些在同一时刻只允许一个执行流访问的特殊资源(即被保护起来的共享资源,所谓的对共享资源进行保护,本质是对访问共享资源的代码进行保护)。
- 临界区 (Critical Section) :进程中访问临界资源的那段代码。你写的代码 = 访问临界资源的代码(临界区)+ 不访问临界资源的代码(非临界区)
- 互斥 (Mutual Exclusion):任何时刻,只允许一个执行流进入临界区。
- 同步(Synchronization) :在互斥的基础上,增加了顺序性。进程间需要按照某种预定的先后顺序来访问资源,它和互斥都是保护的方式。
- 原子性 (Atomicity):一个操作要么不做,要么做完,中间不允许被任何干扰中断。
- 加锁 (Lock): 进入临界区之前的"申请"动作(对应信号量的 P 操作 )。如果锁被占用,进程阻塞。在 System V 信号量里,这叫 获取元(Acquire)。
- 解锁 (Unlock): 离开临界区之后的"释放"动作(对应信号量的 V 操作 )。释放后,唤醒等待的其他进程。在 System V 信号量里,这叫 释放元(Release)。
2. 信号量的理解
(1)信号量的引入
想象一下,你家楼下有一个共享充电桩 (这就是临界资源 )。 如果所有的车主(进程 )都想冲过去充电,由于大家互相不打招呼,可能会发生两辆车同时撞向一个桩的情况,或者你还没充完,别人就把你的枪拔了。为了解决这个混乱,物业想了个办法:在充电桩旁边挂了一个红色的数字显示屏。
(2)信号量的本质
一个计数器!
这个显示屏上的数字 ,就是信号量(Semaphore), 它其实也是一种对资源的预订机制 。如果数字是 1, 代表现在有 1 个空闲车位。如果数字是 0, 代表现在车位满了,请排队。信号量本身并不传输数据(它不告诉你车位在哪、电桩什么型号),它只负责告诉你:"能不能进?"
| 类型 | 初始值 | 含义 | 典型场景 |
|---|---|---|---|
| 二元信号量 | 0 或 1 | 互斥锁,保护临界区 | 一次只有一个进程访问资源 |
| 多元信号量 | > 1 | 计数信号量,管理资源池 | 多个相同资源(如连接池) |
(3)信号量的核心操作
① P 操作(申请资源 / 减 1)
当你开车进入充电位之前,你必须看一眼显示屏:如果数字 > 0 (比如是 1),你把数字减 1 (变成 0),然后开进去;如果数字 == 0, 显示屏不让你进,你的车只能在门口熄火等待(进程阻塞/挂起)。
② V 操作(释放资源 / 加 1)
当你充完电,开车离开车位时,要把显示屏的数字加 1 (从 0 变回 1);一旦数字加了 1,在门口熄火等待的那辆车就会被显示屏叫醒,让他进去。
(4)保护资源的作用
-
初始化 :我们把信号量设为 1。
-
加锁(P操作) :进程 A 想写数据,先执行 P,信号量变成 0。进程 A 开始写。
-
互斥执行 :此时进程 B 也想写,执行 P,发现信号量是 0,只能在内核里"睡觉"等待。
-
解锁(V操作) :进程 A 写完了,执行 V,信号量变回 1。
-
唤醒:内核发现信号量变 1 了,立刻踢醒进程 B,进程 B 这才进入代码区开始写。
(5)信号量的特点
-
原子性 : 如果你和另一个车主同时看显示屏,看到数字是 1。在现实中,你们可能同时冲过去。但在 Linux 内核里,P操作是原子的。内核会排队处理,保证只有一个人能把 1 减成 0,另一个人绝对会看到 0。
-
随内核: 这块"显示屏"是挂在 Linux 内核里的。即使你的程序崩了,如果你没拆掉这块屏幕(调用删除函数),这个数字会一直留在内核里。
3. system V信号量
(1)System V 信号量的特点
-
它是"信号量集" :
semget创建的不是一个计数器,而是一个数组(可以一次性创建多个信号量)。 -
操作极其复杂 :它通过
struct sembuf结构体来定义操作,支持"一次性对多个信号量进行原子修改"。 -
生命周期随内核 :同样需要用
ipcs -s查看和ipcrm -s删除。
信号量集 是指一组信号量的集合,通过一个 ID 管理多个信号量,每个信号量独立工作。
(2)常用接口
cpp
#include <sys/sem.h>
// 1. 获取信号量集(nsems 表示数组长度)
int semget(key_t key, int nsems, int semflg);
// 2. 控制/初始化(如将第 0 个信号量初始化为 1)
semctl(semid, 0, SETVAL, 1);
// 3. 核心操作(P/V 都在这里)
int semop(int semid, struct sembuf *sops, size_t nsops);七、深入内核理解IPC
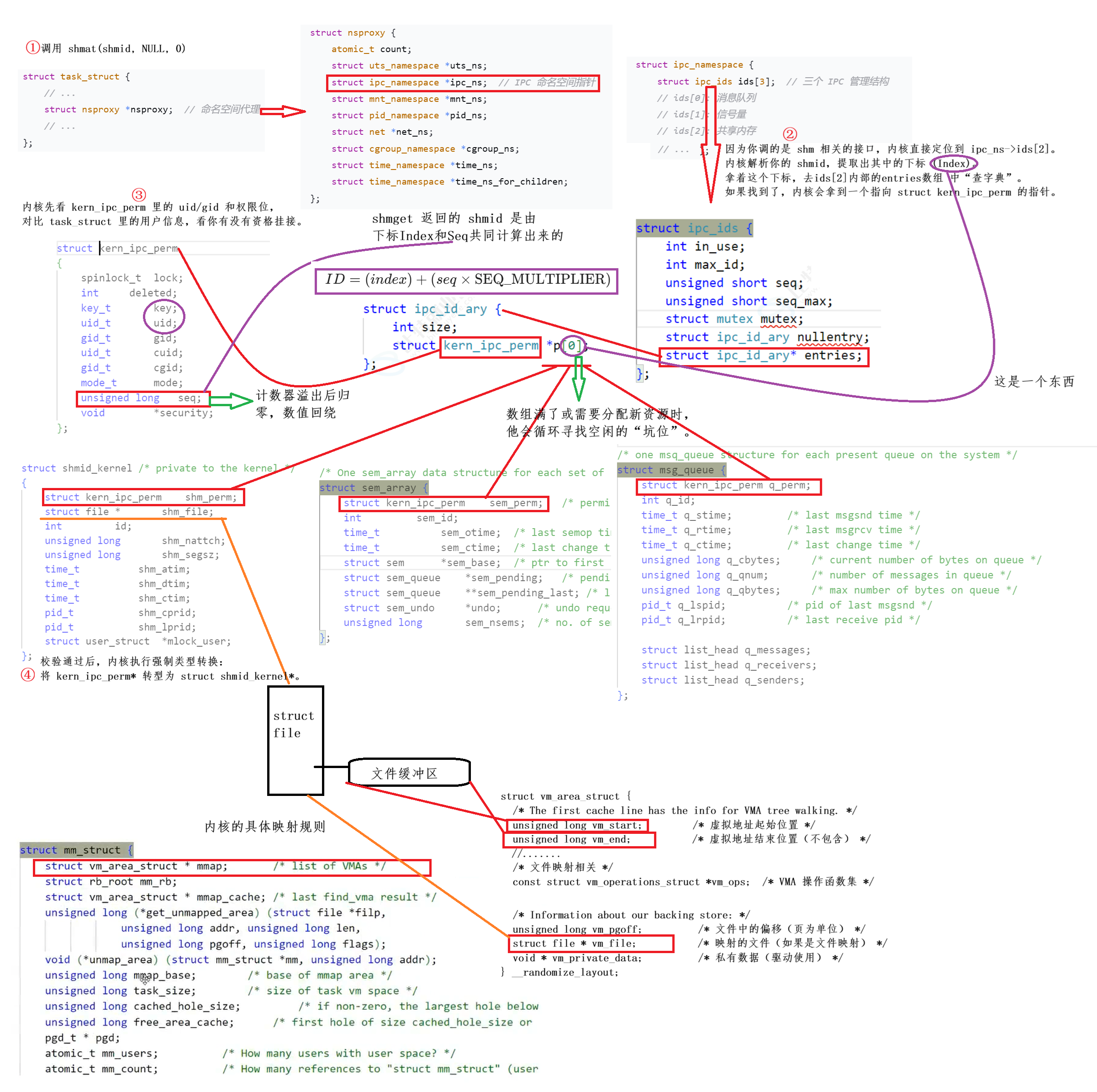
很早版本的内核是用entries存储的,本质上是柔性数组,这也是我们上面的图片所展示的。但在现在的内核里,它的容器变为了基数树(IDR),基数树的叶子节点存放的就是指向 kern_ipc_perm 的指针,当你拿 shmid 来找共享内存时,内核把这个 shmid 拆成几组二进制位(比如每 6 位一组),作为树的每一层索引,快速定位到叶子节点。即便用了基数树,序列号(seq)机制 依然保留。计算 ID 的公式逻辑没变,只是存储 ID 的"容器"变高级了,查找时间是O(logN)。
后记:
无论是匿名管道的 inode 引用计数,还是共享内存那块被映射到不同进程空间的物理内存,其核心命题永远只有一个:协同。 在复杂的系统环境中,通信不难,难的是在追求"急速"的同时,如何通过信号量与管道的阻塞机制守住"原子性"的底线。如果说进程是 OS 的肉体,那么 IPC 就是它的经络。理解了 IPC,你才算真正看懂了 Linux 系统是如何将成百上千个独立的进程串联成一个高效运转的整体。如果对你有帮助,麻烦点个小心心吧!