文章目录
- 前端手动实现大文件分片上传调度层:分片计算、并发上传与断点续传
-
- [1.初始化上传会话:获取 uploadId](#1.初始化上传会话:获取 uploadId)
- [2. 前端分片计算:File -> Blob/File chunks](#2. 前端分片计算:File -> Blob/File chunks)
-
- [2.1 计算分片数量和分片大小](#2.1 计算分片数量和分片大小)
- [2.2 生成分片数组](#2.2 生成分片数组)
- 3.分片指纹
- 4.并发上传分片
-
- [4.1 默认配置](#4.1 默认配置)
- [4.2 并发池核心逻辑](#4.2 并发池核心逻辑)
- [4.3 单个分片上传逻辑](#4.3 单个分片上传逻辑)
- 5.断点续传:暂停与恢复
-
- [5.1 pause:取消进行中的请求,保留已成功分片](#5.1 pause:取消进行中的请求,保留已成功分片)
- [5.2 resume:筛出未上传分片,继续并发上传](#5.2 resume:筛出未上传分片,继续并发上传)
- [6. 总结](#6. 总结)
前端手动实现大文件分片上传调度层:分片计算、并发上传与断点续传
这个方案没有直接用 MinIO 的预签名 URL 直传,主要不是因为 MinIO 做不了,而是因为需要更强的业务控制。同时减少适配 s3 协议的复杂度.这套方案的重点不是"前端直接操作 MinIO",而是:前端实现上传调度层,后端实现上传协议和存储落盘,MinIO 作为最终对象存储底座
普通整文件上传太简单,大文件一断就得重传,不适合 20GB 这种场景;简单的预签名 PUT URL 也更适合中小文件,S3 单次 PUT 最大通常是 5GB;预签名 URL 配合 multipart upload 虽然也能做大文件直传,但前端还要维护每个 part 的 URL、ETag、过期重签,后端也要处理 complete multipart,整体复杂度更高。前端既要控制上传流程,又要适配 S3/MinIO 那套对象存储协议
所以我们选择在业务层自己实现一套 init / upload / merge 协议。前端负责切片、MD5、并发、重试、暂停恢复和断点续传状态;后端负责 uploadId、分片状态、缺片检查、merge 和最终落 MinIO。这样虽然文件流量会经过业务后端,但整个上传过程对业务系统更可控。
1.初始化上传会话:获取 uploadId
upload.ts
typescript
async initUpload(params: InitUploadParams): Promise<InitUploadResponse> {
const { data } = await request<InitUploadResponse>({
url: `${BASE_URL}/init`,
method: 'POST',
data: params,
})
return data
},
initUpload不做业务编排,只做 API 封装。关键是把文件元信息发给/init,拿回uploadId和后续分片策略参数。
2. 前端分片计算:File -> Blob/File chunks
useChunkUpload.ts
上传前置流程
typescript
async function initializeUpload(file: File): Promise<string> {
validateFileSize(file.size)
// 计算分片信息
const chunkInfo = calculateChunkInfo(file, config.chunkSize)
chunks.value = chunkInfo.chunks
state.totalChunks = chunkInfo.chunkCount
// 初始化分片上传
const response = await initChunkUpload(UploadService, {
fileName: file.name,
fileSize: String(file.size),
partSize: chunkInfo.chunkSize,
partCount: chunkInfo.chunkCount,
})
return response.data.uploadId
}
init阶段前端先本地切片,拿到partCount/partSize,再调用/init。后端返回uploadId,它是整个上传会话的唯一标识。之后每个分片请求都带uploadId + partNumber,服务端就能知道哪些分片已到达,从而支持中断后继续上传。"
2.1 计算分片数量和分片大小
在上传前置流程的开始,需要计算分片信息,分片信息相关封装在了一个工具函数中utils/chunkCalculator.ts
javascript
// 计算分片信息
const chunkInfo = calculateChunkInfo(file, config.chunkSize)
chunks.value = chunkInfo.chunks
state.totalChunks = chunkInfo.chunkCount- 得到分片信息,传原始 file 文件和对应的业务要求每个分片分多大的业务要求
calculateChunkInfo 如下:
javascript
/**
* 完整的分片计算(包含生成分片信息)
* @param file 文件对象
* @param chunkSize 分片大小(字节)
* @returns 完整的分片计算结果
*/
export function calculateChunkInfo(
file: File,
chunkSize: number = CHUNK_SIZE,
): ChunkCalculationResult {
const { chunkSize: actualChunkSize, chunkCount } = calculateChunks(file.size, chunkSize)
const chunks = generateChunks(file, actualChunkSize)
return {
chunkSize: actualChunkSize,
chunkCount,
chunks,
}
}核心逻辑:
通过封装好的方法,最终得到了每一个分片的大小,分片的数量,和包含有各种信息的完整的分好的分片数组
2.2 生成分片数组
calculateChunks 如下:
typescript
/**
* 计算分片信息
* @param fileSize 文件大小(字节)
* @param chunkSize 分片大小(字节),默认 5MB
* @returns 分片计算结果
*/
export function calculateChunks(
fileSize: number,
chunkSize: number = CHUNK_SIZE,
): { chunkSize: number; chunkCount: number } {
validateFileSize(fileSize)
// 如果文件小于分片大小,分片大小设为 5MB,数量为 1
if (fileSize < CHUNK_SIZE) {
return {
chunkSize: CHUNK_SIZE,
chunkCount: 1,
}
}
// 确保分片大小不小于 5MB
const actualChunkSize = Math.max(chunkSize, CHUNK_SIZE)
const chunkCount = Math.ceil(fileSize / actualChunkSize)
return {
chunkSize: actualChunkSize,
chunkCount,
}
}核心逻辑:
得到分片大小和分片数量,校验分片大小,上取整得到分片数量
generateChunks 如下:
typescript
/**
* 生成分片信息数组
* @param file 文件对象
* @param chunkSize 分片大小(字节)
* @returns 分片信息数组
*/
export function generateChunks(file: File, chunkSize: number = CHUNK_SIZE): ChunkInfo[] {
validateFileSize(file.size)
const { chunkSize: actualChunkSize, chunkCount } = calculateChunks(file.size, chunkSize)
const chunks: ChunkInfo[] = []
for (let i = 0; i < chunkCount; i++) {
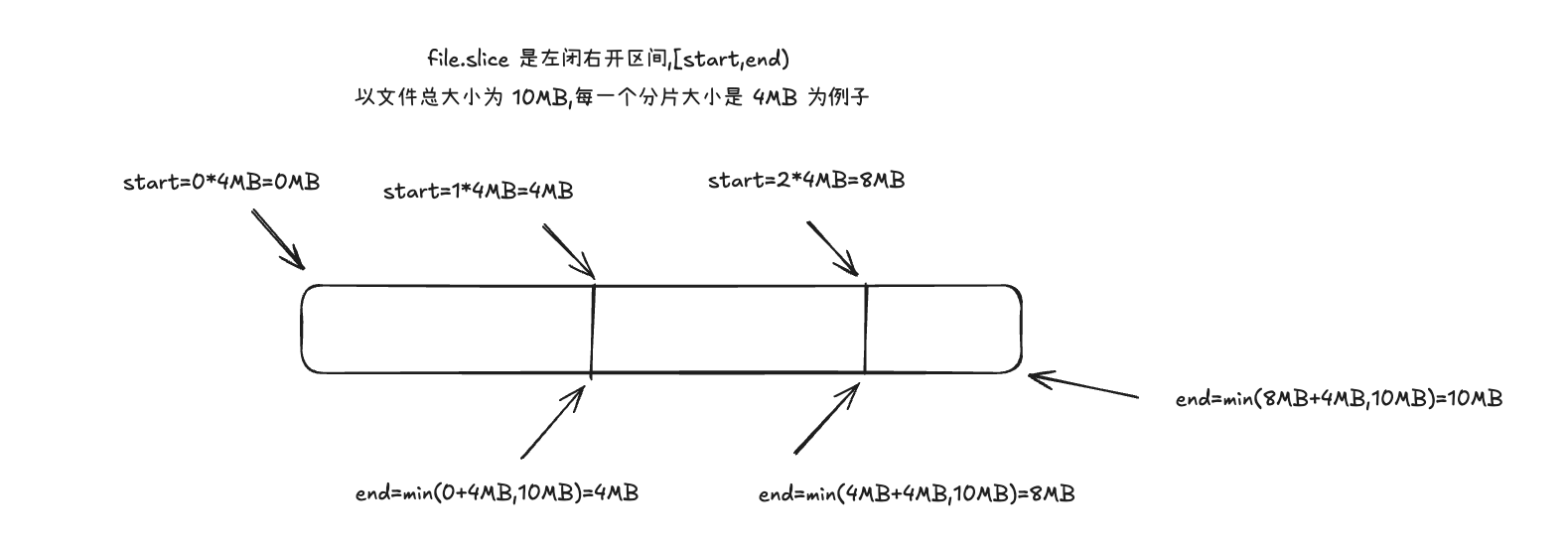
const start = i * actualChunkSize
const end = Math.min(start + actualChunkSize, file.size)
const size = end - start
// 将 Blob 转换为 File 对象
// 功能:file.slice() 返回的是 Blob,但服务端需要 File 对象(MultipartFile)
// 使用 File 构造函数将 Blob 转换为 File
const blob = file.slice(start, end)
const chunkFile = new File([blob], `${file.name}.part${i + 1}`, {
type: file.type || 'application/octet-stream',
lastModified: file.lastModified,
})
chunks.push({
partNumber: i + 1, // 分片序号从 1 开始
start,
end,
size,
blob: chunkFile, // 现在 blob 字段存储的是 File 对象
})
}
return chunks
}核心逻辑:
start 代表每一片分片的开始,end 代表每一片分片的结尾,end-start 代表每一片的真实大小
Blob:slice()方法:官方文档,通过官方文档中可知,这是一个左闭右开的区间,返回一个 blob
因为后端的需求是拿到 file,所以应该使用 file 构造函数,得到 file,官方文档,type 字段稍微解释一下,表示这个数据是什么格式的,例如图片还是文本
注意 chunks 数组中 blob 字段存储的是 file对象
拓展:
file 和 blob 的区别?
Blob 是"二进制数据块";File 是"带文件信息的 Blob"。
File是一种更具体的Blob,它通常来自:,File除了有Blob的能力,还多了几个文件相关信息,比如
javascriptfile.name // 文件名,例如 "demo.mp4" file.lastModified // 最后修改时间 file.webkitRelativePath // 上传文件夹时可能用到
3.分片指纹
在单个文件上传的过程中,后端需要,每一个小分片的上传过程中上传一个 md5 摘要,md5 是在上传前由前端计算生成的
计算 md5
typescript
async function calculateChunkMD5(chunk: ChunkInfo): Promise<string> {
if (chunk.md5) {
return chunk.md5
}
const md5 = await calculateMD5(chunk.blob)
chunk.md5 = md5
return md5
}具体md5 工具函数:
具体的实现不用过多纠结,只需要知道,我们在上传每个分片前,会先对当前分片 Blob 计算 MD5。前端通过 FileReader 把 Blob 读取成 ArrayBuffer,再转成 CryptoJS 可以处理的 WordArray,最后调用 CryptoJS.MD5 得到该分片的哈希值。这个 MD5 主要用于分片完整性校验、断点续传或后端判断分片是否已上传。
typescript
/**
* MD5 计算工具
*/
import CryptoJS from 'crypto-js'
/**
* 计算 Blob 的 MD5 值
* @param blob 要计算 MD5 的 Blob 对象
* @returns Promise<string> MD5 哈希值
*/
export function calculateMD5(blob: Blob): Promise<string> {
return new Promise((resolve, reject) => {
const reader = new FileReader()
reader.onload = (event) => {
try {
if (!event.target?.result) {
reject(new Error('读取文件失败'))
return
}
// 将 ArrayBuffer 转换为 WordArray
const wordArray = CryptoJS.lib.WordArray.create(event.target.result as ArrayBuffer)
// 计算 MD5
const hash = CryptoJS.MD5(wordArray)
// 转换为字符串
resolve(hash.toString())
} catch (error) {
reject(error instanceof Error ? error : new Error('MD5 计算失败'))
}
}
reader.onerror = () => {
reject(new Error('文件读取错误'))
}
// 读取为 ArrayBuffer
reader.readAsArrayBuffer(blob)
})
}
/**
* 批量计算多个 Blob 的 MD5 值
* @param blobs Blob 数组
* @returns Promise<string[]> MD5 哈希值数组
*/
export async function calculateMD5Batch(blobs: Blob[]): Promise<string[]> {
const promises = blobs.map((blob) => calculateMD5(blob))
return Promise.all(promises)
}
/**
* 使用 Web Worker 异步计算 MD5(可选优化)
* 注意:需要单独创建 worker 文件
* @param blob 要计算 MD5 的 Blob 对象
* @returns Promise<string> MD5 哈希值
*/
export function calculateMD5WithWorker(blob: Blob): Promise<string> {
// 如果浏览器不支持 Worker,回退到同步计算
if (typeof Worker === 'undefined') {
return calculateMD5(blob)
}
return new Promise((resolve, reject) => {
// 这里可以创建一个 Web Worker 来处理大文件的 MD5 计算
// 为了简化,这里先使用同步方式
// 后续可以优化为 Worker 实现
calculateMD5(blob).then(resolve).catch(reject)
})
}4.并发上传分片
4.1 默认配置
typescript
// 默认配置
const DEFAULT_OPTIONS: Required<
Pick<
ChunkUploadOptions,
'chunkSize' | 'maxFileSize' | 'maxConcurrent' | 'maxRetries' | 'retryDelay'
>
> = {
chunkSize: CHUNK_SIZE,
maxFileSize: MAX_FILE_SIZE,
maxConcurrent: 3,
maxRetries: 3,
retryDelay: 1000,
}- 规定了并发路数,最大重试数,重试秒数
4.2 并发池核心逻辑
并发上传多个分片:
javascript
/**
* 并发上传分片
*/
async function uploadChunksConcurrently(partNumbers: number[]) {
const queue = [...partNumbers]
const workers: Promise<void>[] = []
while (queue.length > 0 || workers.length > 0) {
// 如果已取消或暂停,停止上传
if (state.isCancelled || state.isPaused) {
// 取消所有进行中的上传
workers.forEach(() => {
// 这里可以添加取消逻辑
})
break
}
// 填充工作队列
while (workers.length < config.maxConcurrent && queue.length > 0) {
const partNumber = queue.shift()!
state.pendingChunks.add(partNumber)
const worker = uploadSingleChunk(partNumber)
.catch((error) => {
// 错误已在 uploadSingleChunk 中处理
console.error(`分片 ${partNumber} 上传失败:`, error)
})
.finally(() => {
const index = workers.indexOf(worker)
if (index > -1) {
workers.splice(index, 1)
}
})
workers.push(worker)
}
// 等待至少一个任务完成
if (workers.length > 0) {
await Promise.race(workers)
}
}
}核心逻辑:
传入切好的分片数组中的数字编号,比如分了 10 片就是 1-10,把这些编号丢进并发队列queue ,workers作为正在执行的 Promise 任务池让 worker 按编号逐个上传对应分片.
workers里面放的就是一个个 Promise 任务,uploadSingleChunk 是单个上传分片的逻辑如果错误,打印第几个分片错误了,无论正确还是错误,都要把这个分片,从工作队列中移除
如果有一个任务完成(无论失败还是成功),进入到下一轮的循环
状态管理:
typescript
// 状态管理
const state = reactive<ChunkUploadState>({
file: null,
fileName: '',
fileSize: 0,
status: 'idle',
progress: 0,
uploadId: null,
totalChunks: 0,
uploadedChunks: new Set<number>(),
failedChunks: new Set<number>(),
pendingChunks: new Set<number>(),
isPaused: false,
isCancelled: false,
error: null,
result: null,
})核心逻辑:
很明显的看到了 3 个 set
uploadedChunks:已上传成功的分片编号
failedChunks:上传失败的分片编号
pendingChunks:当前待处理中的分片编号
4.3 单个分片上传逻辑
javascript
/**
* 上传单个分片
*/
async function uploadSingleChunk(partNumber: number, retryCount = 0): Promise<void> {
if (state.isCancelled || state.isPaused) {
return
}
const chunk = chunks.value.find((c) => c.partNumber === partNumber)
if (!chunk) {
throw new Error(`分片 ${partNumber} 不存在`)
}
// 如果已经上传成功,跳过
if (state.uploadedChunks.has(partNumber)) {
return
}
// 创建 CancelToken
const source = axios.CancelToken.source()
cancelTokens.set(partNumber, source)
try {
// 计算 MD5
const md5 = await calculateChunkMD5(chunk)
// 上传分片
// 功能:调用阶段二的 uploadChunk API 上传单个分片
// chunk.blob 现在已经是 File 对象(在 chunkCalculator 中已转换)
await uploadChunk(
UploadService,
{
fileName: state.fileName,
uploadId: state.uploadId!,
partNumber,
partSize: chunk.size,
file: chunk.blob as File, // 确保是 File 对象
md5,
},
source.token,
)
// 标记为已上传
state.uploadedChunks.add(partNumber)
state.failedChunks.delete(partNumber)
state.pendingChunks.delete(partNumber)
cancelTokens.delete(partNumber)
// 更新进度
updateProgress()
// 调用回调
if (config.onChunkComplete) {
config.onChunkComplete(partNumber)
}
} catch (error) {
cancelTokens.delete(partNumber)
// 如果是取消或暂停,不处理错误
if (state.isCancelled || state.isPaused) {
// 从 pendingChunks 中删除,因为已经被取消/暂停
state.pendingChunks.delete(partNumber)
return
}
// 检查是否是取消错误
if (
error &&
typeof error === 'object' &&
'message' in error &&
typeof error.message === 'string' &&
(error.message === '上传已取消' || error.message.includes('cancel'))
) {
return
}
// 重试逻辑
if (retryCount < config.maxRetries) {
await new Promise((resolve) => setTimeout(resolve, config.retryDelay))
return uploadSingleChunk(partNumber, retryCount + 1)
}
// 标记为失败
state.failedChunks.add(partNumber)
state.pendingChunks.delete(partNumber)
const err = error instanceof Error ? error : new Error('分片上传失败')
state.error = err
// 调用错误回调
if (config.onChunkError) {
config.onChunkError(partNumber, err)
}
throw err
}
}核心逻辑:
javascript// 创建 CancelToken const source = axios.CancelToken.source() cancelTokens.set(partNumber, source)给当前这个分片请求创建一个"取消令牌",并且按分片号存起来,后面暂停/取消时能找到它并中断这个分片的 axios 请求。Axios 官方文档里也是这样用的:通过
CancelToken.source()创建source,请求配置里传cancelToken: source.token,然后调用source.cancel()来取消请求。这个 API 现在已被官方标记为 deprecated,但旧项目里仍然能看懂和维护。这个 source,跟对应的分片号对应存在一个 map 中在调用对应的 axios 接口的时候,就把对应cancelToken 传入.
在单个分片上传中,包含了计算 md5,更新进度,重试
更新进度是,就是整个已经上传成功的分片数和分片的总数做比
重试就是setTimeout 这个 promise,根据配置的重传次数和重传时间
调用并发上传的逻辑:
javascript
// 1. 初始化上传
state.uploadId = await initializeUpload(file)
// 2. 准备所有分片序号
const allPartNumbers = chunks.value.map((c) => c.partNumber)
allPartNumbers.forEach((num) => state.pendingChunks.add(num))
// 3. 并发上传所有分片
await uploadChunksConcurrently(allPartNumbers)核心逻辑:
从
chunks.value这个分片数组里,只取每个分片的partNumber,生成一个新的数组。map()的作用就是对数组每个元素执行一次回调,并返回一个新数组。讲这个新数组的每一项加入到pendingChunks,这个 set 中
5.断点续传:暂停与恢复
5.1 pause:取消进行中的请求,保留已成功分片
断点续传主要就看暂停和恢复这两部分
javascript
/**
* 暂停上传
*/
function pause() {
// 如果已经暂停,直接返回(幂等性)
if (state.status === 'paused' || state.isPaused) {
return
}
// 只有在 uploading 状态时才能暂停
if (state.status !== 'uploading') {
return
}
state.isPaused = true
state.status = 'paused'
// 取消所有进行中的上传
cancelTokens.forEach((source) => {
source.cancel('上传已暂停')
})
cancelTokens.clear()
// 清理 pendingChunks,因为暂停时这些分片会被取消,恢复时需要重新上传
// 只保留已上传成功的分片,其他都清理掉,这样恢复时才能正确识别需要继续上传的分片
state.pendingChunks.clear()
}核心逻辑:
cancelTokens 里面就是正在上传的分片序号和对应取消 source 的映射,因为在上传成功后cancelTokens.delete(partNumber)会对应的删除
所以把正在上传的请求取消,再把对应还没有上传也就是pendingChunks 中的序号清空
5.2 resume:筛出未上传分片,继续并发上传
javascript
/**
* 继续上传
*/
async function resume() {
if (state.status !== 'paused') {
return
}
if (!state.uploadId || !state.file) {
throw new Error('无法继续:缺少必要信息')
}
state.isPaused = false
state.status = 'uploading'
isUploading.value = true
try {
// 找出未上传的分片
const remainingPartNumbers = chunks.value
.map((c) => c.partNumber)
.filter((num) => !state.uploadedChunks.has(num) && !state.pendingChunks.has(num))
if (remainingPartNumbers.length === 0) {
// 所有分片都已上传,直接合并
await mergeUploadedChunks()
return
}
// 继续上传剩余分片
await uploadChunksConcurrently(remainingPartNumbers)
// 检查是否在恢复过程中被暂停
if (state.isPaused) {
// 如果在恢复过程中被暂停,直接返回,不继续合并
return
}
// 检查是否有失败的分片
if (state.failedChunks.size > 0) {
throw new Error(`${state.failedChunks.size} 个分片上传失败,请重试`)
}
// 合并分片
await mergeUploadedChunks()
} catch (error) {
// 如果是暂停导致的错误,不处理为错误状态
if (state.isPaused) {
return
}
state.status = 'error'
state.error = error instanceof Error ? error : new Error('继续上传失败')
isUploading.value = false
if (config.onError) {
config.onError(state.error)
}
throw state.error
} finally {
// 只有在没有被暂停的情况下才重置 isUploading
if (!state.isPaused) {
isUploading.value = false
}
}
}核心逻辑:
用 map+filter 方法拿到还没有上传成功的序号数组,调用并发上传函数(这个序号数组),记得合并分片
小总结:为什么能断点续传?
断点指的是已经成功上传的分片集合,续传指的是恢复时只上传
uploadedChunks之外的分片。uploadId + partNumber让服务端能识别这次上传会话里的每个分片,前端通过uploadedChunks跳过已成功分片,最后所有分片上传完成后再触发 merge。
6. 总结
这个大文件上传方案本质上是一个
init -> upload part -> merge的分片上传流程。前端首先根据文件大小和配置的 chunkSize 计算分片数量,通过
file.slice(start, end)按左闭右开的字节区间切出 Blob。由于后端接口接收 MultipartFile,所以项目里又用new File([blob], filename, options)把 Blob 包装成 File。初始化阶段,前端把 fileName、fileSize、partSize、partCount 等元信息传给后端,后端返回 uploadId。后续每个分片上传时都会带上
uploadId + partNumber + md5 + file,这样后端就能识别当前分片属于哪一次上传任务、在原文件中的第几片。并发上传阶段,前端维护一个 queue 和 workers。queue 保存待上传分片编号,workers 保存当前正在上传的 Promise 任务。通过
workers.length < maxConcurrent控制最大并发数,通过Promise.race(workers)等待任意一个任务完成后释放并发名额,再补充新的分片任务。断点续传的核心是保留
uploadedChunks。暂停时,前端通过 CancelToken 取消当前正在上传的请求,并清理 pendingChunks,但不会清空 uploadedChunks。恢复时,通过chunks.map(...).filter(...)筛出还没有上传成功的分片,只继续上传剩余分片。所有分片上传完成后,再调用 merge 接口完成合并。这套方案里,
uploadId负责标识上传会话,partNumber负责标识分片位置,md5负责分片完整性校验,uploadedChunks / failedChunks / pendingChunks负责维护前端任务状态。