Transformer 架构里关于 Attention 概念的澄清
flyfish
先分 Encoder Stack 和 Decoder Stack 论文里的图没画
Encoder Stack由 N 个完全相同的 Encoder 层 堆叠而成
Decoder Stack由 N 个完全相同的 Decoder 层 堆叠而成
Encoder Stack = 堆叠 N 层编码器
Decoder Stack = 堆叠 N 层解码器
如果在编程里也可以这样命名
如果是整体叫Encoder Stack,里面堆叠了N个Encoder
如果是整体叫 Encoder, 里面堆叠了N个 Encoder block
这里是术语澄清,所以知道左边Encoder ,右边 Decoder 就行。
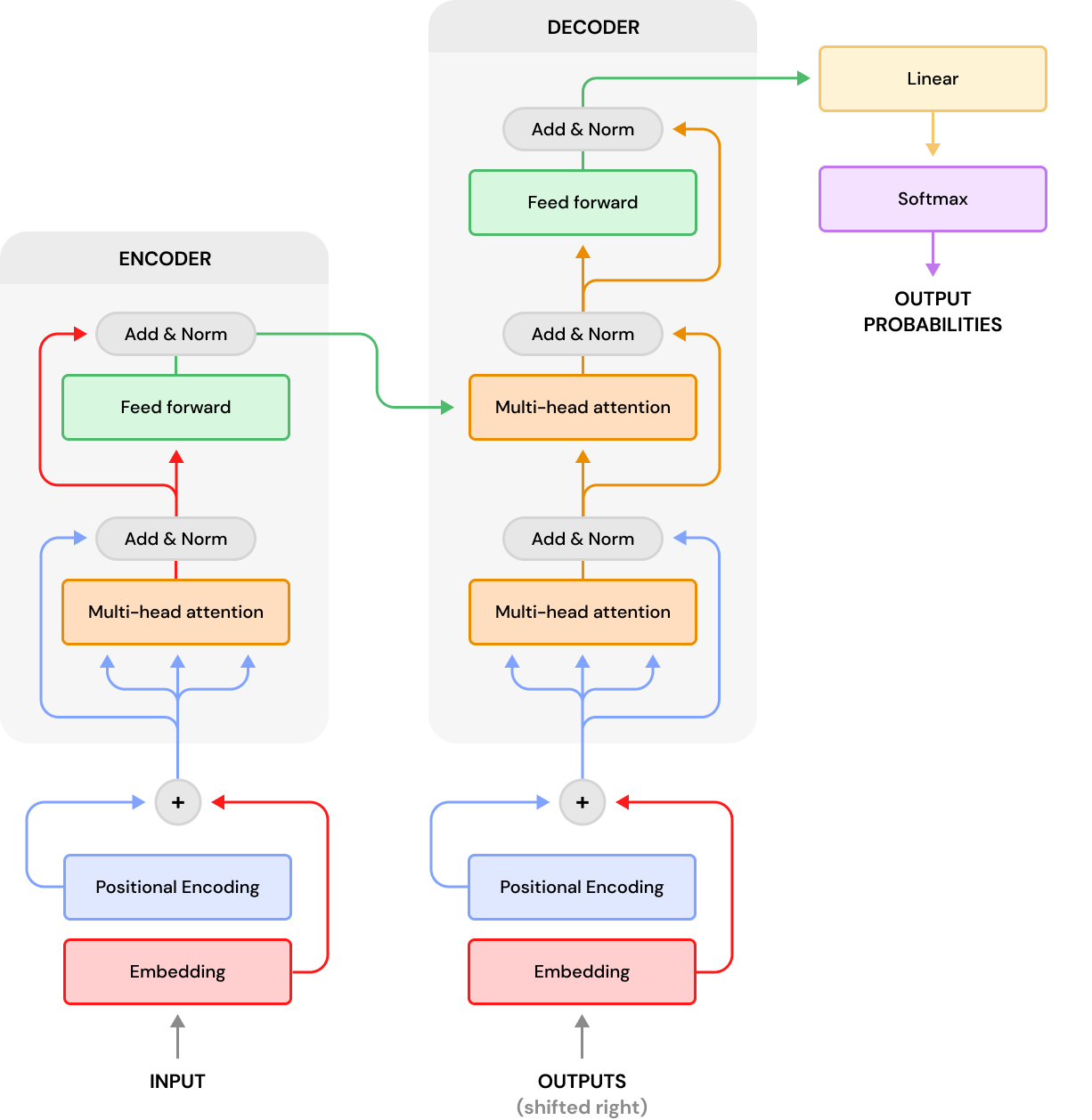 再看论文里的图的attention,这里用红色数字标了出来,下面也是按照这个序号说的
再看论文里的图的attention,这里用红色数字标了出来,下面也是按照这个序号说的
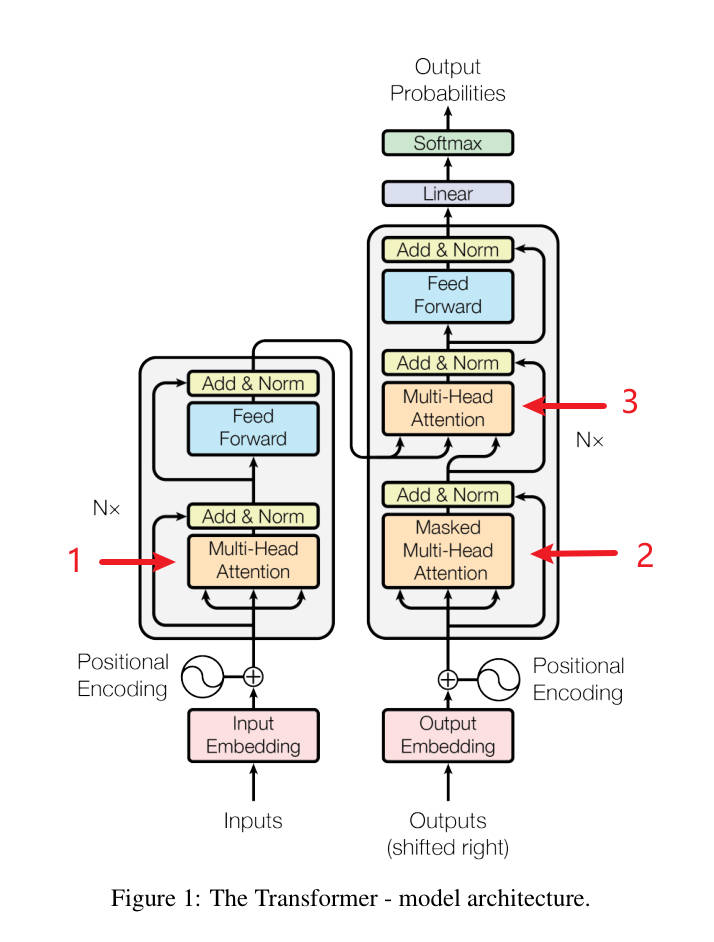
看Transformer架构图 里面有三类Attention
这里的Transformer 里只有一种机制:Scaled Dot-Product Attention,但在不同位置/用途上,被拆成三种用法,只有一种 Attention + 三种使用方式。
Self(同源)
Masked(加约束)
Cross(跨源)
Self-Attention(自注意力):Q、K、V 来源完全相同
Cross-Attention(交叉注意力):Q 与 K/V 来源完全不同
所以图中 名字 可以这样叫(看对应的红色箭头指向部分)
cpp
(格式效果 前面 加 - )- 1 Multi-Head Attention 是 Multi-Head Self-Attention (加
Self) - 2 Masked Multi-Head Attention 是 Masked Multi-Head Self-Attention (加
self) - 3 Multi-Head Attention 是 Multi-Head Cross-Attention (加
Cross)
Multi-Head Cross-Attention也叫 Multi-Head Source-Target Attention (Cross变Source-Target)
先说名词
不同的文献和资料中有不同的名字,其实是一样的意思
-
- 编码器-解码器多头注意力机制(Encoder-Decoder Multi-Head Attention Mechanism)
(论文图标注的3)
其他名字:
交叉注意力机制(Cross-Attention Mechanism)
源-目标注意力机制(Source-Target Attention Mechanism)
解码器-编码器注意力机制(Decoder-Encoder Attention Mechanism)
- 编码器-解码器多头注意力机制(Encoder-Decoder Multi-Head Attention Mechanism)
-
- 遮蔽多头自注意力机制(Masked Multi-Head Self-Attention Mechanism )
(论文图标注的2)
其他名字:
因果注意力机制(Causal Attention Mechanism)
未来位置遮蔽注意力机制(Look-Ahead Masking Attention Mechanism)
遮蔽自注意力机制(Masked Self-Attention Mechanism)
前向遮蔽注意力机制(Forward Masking Attention Mechanism)
- 遮蔽多头自注意力机制(Masked Multi-Head Self-Attention Mechanism )
名字很多,意思是一样的
所以表格可以这样写
| 模块 | Attention 类型 | Q 来源 | K/V 来源 | Padding Mask | Look-Ahead Mask |
|---|---|---|---|---|---|
| Encoder | Multi-Head Self-Attention | Encoder | Encoder | 是 | 否 |
| Decoder (1) | Masked Multi-Head Self-Attention | Decoder | Decoder | 是 | 是 |
| Decoder (2) | Multi-Head Cross-Attention | Decoder | Encoder | 是(作用在 Encoder 输出) | 否 |
Multi-Head Cross-Attention也是 Multi-Head Source-Target Attention
所以图可以这样画
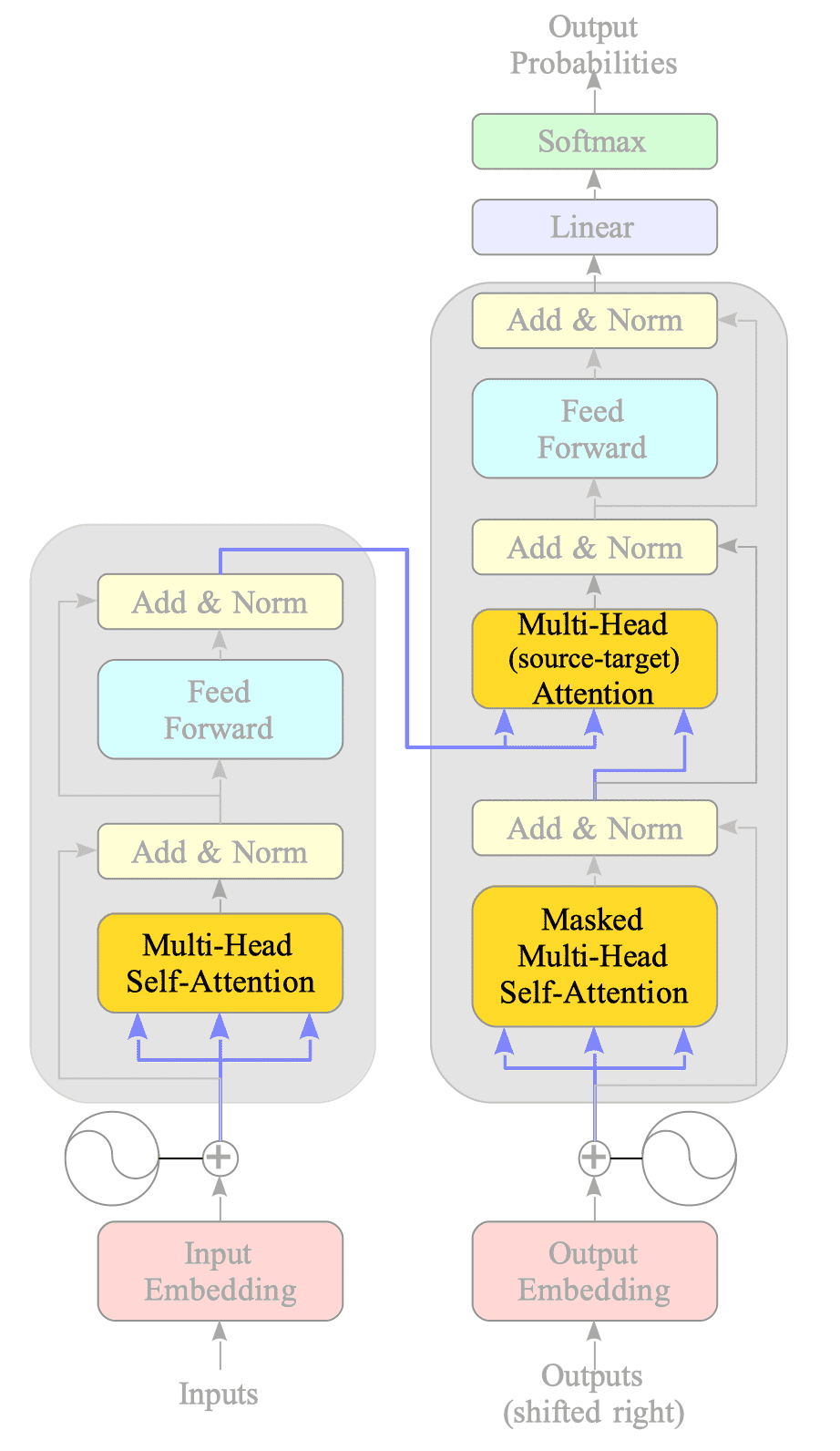
看Padding Mask 和 Look-Ahead Mask
Padding Mask 填充掩码 指的是屏蔽类似 [PAD]填充掩码 空白填充无效字符
Look-Ahead Mask的理解
向前看(look ahead)在这里指偷看模型接下来要生成的位置,加 mask 把这个向前偷看的行为挡住。
Look-Ahead Mask可以叫未来遮蔽掩码 或者
Look-Ahead Mask → 前瞻掩码
Causal Mask → 因果掩码(和 Look-Ahead Mask 完全等价)
Forward Mask → 前向遮蔽(同义)
-
文本序列方向规则
书写/生成顺序:从左到右
[SOS] 字1 字2 字3 字4 [EOS]
左边 = 过去(behind / past / already generated)
右边 = 未来(ahead / forward / not yet generated) -
ahead / forward 含义
日常:ahead = 往前走(如果面向前进方向,ahead 是前面还没走到的地方)
Transformer :ahead = 序列右侧 = 下一步要生成的内容 = 未来因为模型是自回归(autoregressive)一步步向右推进的,所以向前推进(move forward/ahead)的目标区域就是右边还没写的东西。
-
Look-Ahead Mask
Look-Ahead = 偷看未来(look into the ahead region)所以 Look-Ahead Mask = 禁止偷看未来的遮蔽(或叫 "Don't Look Ahead Mask")
-
等价关系
Look-Ahead Mask ≈ Forward Mask ≈ Causal Mask (因果掩码)
实现上就是下三角矩阵 (lower triangular):位置 i 只能 attend 到 j ≤ i ,j > i 的注意力分数被设为
-inf(softmax 后为 0)。
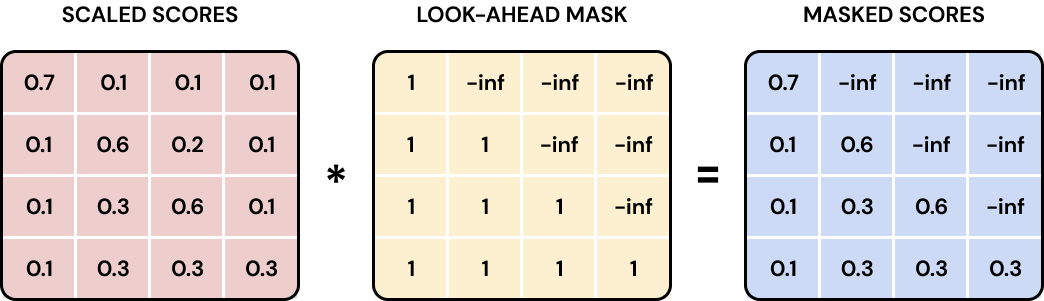
序列 [SOS] 2 5 7 9,模型当前在生成/预测 5 的时候:可以看左边 [SOS] 2(过去), 绝对不能看 右边 7 9(未来)。
Look-Ahead Mask = 防止 look-ahead 的 mask,或者直接叫 No-Look-Ahead Mask/ Don't Look Ahead Mask。
这个 mask 的是强制因果关系(causality),当前 token 的表示(representation),只能依赖于它之前 的 tokens(cause),不能依赖之后 的 tokens(effect)。
这符合语言生成的自然时间顺序:说出一个词的时候,后面的词还没说出来。
Causal Mask (因果掩码),三角掩码(triangular mask)在这里也是一个意思
用论文《Attention Is All You Need》的话说就是
We also modify the self-attention sub-layer in the decoder stack to
prevent positions from attending to subsequent positions.
我们同样对解码器堆叠结构中的自注意力子层进行改造,阻止当前位置关注后续位置。