视觉-语言-动作模型解剖学:从模块、里程碑到核心挑战
想象一下这个场景:你对家里的机器人说"帮我把餐桌上的蓝色杯子拿到厨房水槽里洗一下"。一个普通的机器人可能会愣住------它不知道什么是"蓝色杯子",不知道"餐桌"在哪里,更不知道"洗一下"具体要做什么动作。而一个装备了视觉-语言-动作(VLA)模型的机器人,会立刻理解你的指令,识别出餐桌上的蓝色杯子,规划出一条安全的路径,伸出手臂拿起杯子,走到水槽边打开水龙头,完成清洗动作。
这就是具身智能的终极目标:让机器人能够像人类一样,通过视觉感知世界,通过语言理解指令,通过动作改变环境。而VLA模型正是实现这个目标的核心技术。它将计算机视觉、自然语言处理和机器人控制三大领域融为一体,是当前人工智能最热门的研究方向之一。
这篇2025年12月发表的权威综述,是目前VLA领域最全面、最系统的研究总结。它没有像传统综述那样简单罗列论文,而是采用了一个独特的金字塔结构,从基础模块到发展里程碑,再到核心挑战,为我们描绘了一幅完整的VLA技术全景图。
论文信息
- 标题:An Anatomy of Vision-Language-Action Models: From Modules to Milestones and Challenges
- 期刊:IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
- 单位:IROOTECH TECHNOLOGY、三一重工、伦敦国王学院、香港理工大学、达姆施塔特工业大学、帝国理工学院等
- 代码:github.com/irootech/vla-anatomy (官方项目仓库,持续更新)
- 论文:https://arxiv.org/pdf/2512.11362
一、论文整体结构:一座VLA知识金字塔
这篇综述最独特的地方就是它的结构,它完全按照一个研究者学习VLA的自然路径来组织,形成了一个清晰的金字塔结构:
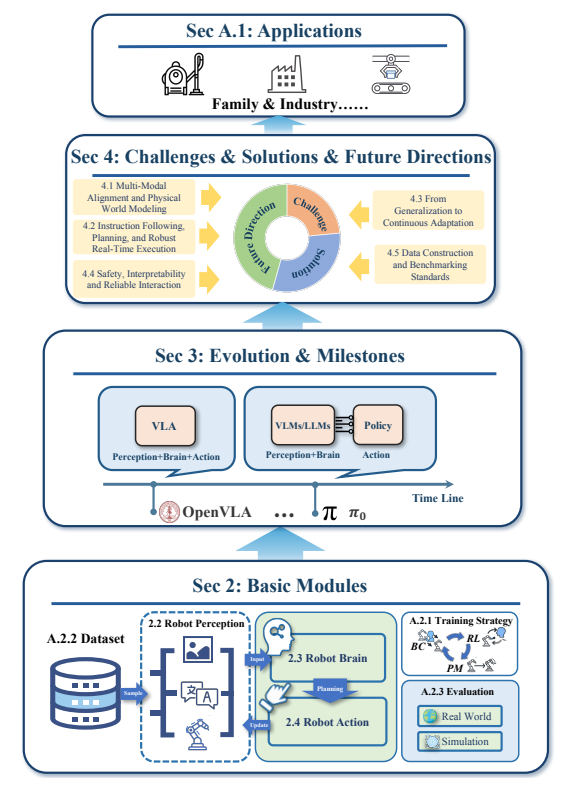
图1:本综述的金字塔结构(出处:原文Figure 1)
- 底层(基础):第2章,详细拆解了任何VLA模型都必须包含的三个核心模块:感知、大脑和动作
- 中层(历史):第3章,追溯了VLA领域从2017年到2025年的完整发展历程,标记了所有关键里程碑
- 顶层(前沿):第4章,深入分析了当前VLA研究面临的五大核心挑战,以及对应的解决方案和未来方向
- 附录(应用):详细介绍了VLA模型在家庭机器人和工业机器人领域的实际应用
这种结构让新手可以从基础开始逐步深入,而资深研究者也可以直接跳到自己感兴趣的挑战部分,非常实用。
二、VLA模型的基本模块:机器人的"五官"、"大脑"和"四肢"
任何一个VLA系统,无论多么复杂,都可以拆解为三个核心部分:感知模块 (五官)、大脑模块 (中枢神经系统)和动作模块(四肢)。
2.1 通用目标函数
所有VLA模型的训练目标都可以统一表示为行为克隆 的损失函数:
minθE(o,l,a)∼D−logπθ(a∣o,l)\min_{\theta} \mathbb{E}_{(o, l, a) \sim D} \left -\\log \\pi_\\theta(a \| o, l) \\rightθminE(o,l,a)∼D−logπθ(a∣o,l)
其中:
- θ\thetaθ:VLA模型的所有可学习参数
- ooo:观测(通常是RGB图像、深度图或点云)
- lll:自然语言指令
- aaa:机器人的动作(关节角度、末端执行器位姿等)
- DDD:由人类专家演示组成的训练数据集
- πθ(a∣o,l)\pi_\theta(a | o, l)πθ(a∣o,l):策略函数,表示在观测ooo和指令lll下执行动作aaa的概率
- E\mathbb{E}E:对数据集求期望
通俗解释:这个公式的意思是,我们要让机器人尽可能准确地模仿人类专家的行为。当机器人看到和专家一样的场景、听到一样的指令时,它应该做出和专家一样的动作。
2.2 感知模块:机器人的"五官"
感知模块负责将物理世界的原始信号转换为模型可以理解的特征表示。它由三个子模块组成:视觉编码器、语言编码器和本体感觉编码器。
2.2.1 视觉编码器:机器人的"眼睛"
视觉编码器是VLA模型中最重要的感知组件,它的发展经历了四个阶段:
| 视觉编码器类型 | 代表模型 | 优点 | 缺点 | 典型应用 |
|---|---|---|---|---|
| 卷积神经网络(CNN) | ResNet、EfficientNet | 局部特征提取能力强、速度快 | 全局上下文能力弱 | 实时性要求高的场景 |
| 语言监督ViT | CLIP、SigLIP | 视觉-语言对齐能力强 | 几何精度不足 | 语义理解任务 |
| 自监督ViT | DINOv2 | 几何结构感知能力强 | 缺乏语义对齐 | 精确操作任务 |
| 混合架构 | SigLIP+DINOv2 | 兼顾语义和几何 | 计算量较大 | 通用VLA模型 |
| 原生VLM | PaLI-X、PaliGemma | 端到端多模态理解 | 参数量大 | 大型通用模型 |
表1:视觉编码器对比(出处:原文第2.2.1节整理)
当前SOTA趋势 :几乎所有2024-2025年的SOTA VLA模型(如OpenVLA、π₀、GR-2)都采用了SigLIP+DINOv2混合视觉编码器,它同时具备CLIP的语义理解能力和DINOv2的几何精度。
2.2.2 语言编码器:机器人的"耳朵"
语言编码器负责将自然语言指令转换为语义特征。它的发展也经历了三个阶段:
- 传统Transformer:BERT、T5(2022年以前)
- 大语言模型(LLM):Llama 2、Gemma(2023-2024年)
- 原生视觉-语言模型(VLM):Qwen-VL、PaliGemma(2025年至今)
当前SOTA趋势:直接使用预训练的VLM作为语言编码器,这样可以同时处理视觉和语言输入,实现更深度的跨模态融合。
2.2.3 本体感觉编码器:机器人的"触觉"
本体感觉输入包括关节角度、末端执行器位姿、夹爪状态等低维结构化数据。由于数据维度低、结构简单,MLP(多层感知机)仍然是最常用的本体感觉编码器。
2.3 大脑模块:机器人的"中枢神经系统"
大脑模块是VLA模型的核心,负责融合多模态特征、进行推理和规划、生成动作意图。当前主流的大脑架构有四种:
2.3.1 纯Transformer架构
这是最经典的架构,将视觉、语言和本体感觉都转换为token序列,然后用一个统一的Transformer处理。
- 代表模型:RT-1、VIMA、GR-1
- 优点:简单统一、端到端训练
- 缺点:长序列处理效率低
2.3.2 扩散Transformer(DiT)架构
使用扩散模型作为生成核心,Transformer引导去噪过程。
- 代表模型:Diffusion Policy、RDT-1B、TriVLA
- 优点:擅长建模复杂的连续动作分布、生成平滑自然的运动
- 缺点:推理速度较慢,需要多次迭代
2.3.3 混合架构
将Transformer的语义推理能力与扩散/流匹配的动作生成能力结合起来。
- 代表模型:π₀、Octo、π₀.5
- 优点:兼顾推理能力和动作精度、推理速度快
- 缺点:架构相对复杂
2.3.4 原生VLM架构
直接在预训练的VLM基础上扩展动作输出头。
- 代表模型:RT-2、OpenVLA、Gemma Robotics
- 优点:继承了VLM的强大泛化能力和世界知识
- 缺点:需要大量的机器人数据进行微调
当前SOTA趋势 :混合架构 和原生VLM架构是2025年的绝对主流,几乎所有新模型都采用这两种架构之一。
2.4 动作模块:机器人的"四肢"
动作模块负责将大脑生成的抽象动作意图转换为具体的低-level控制命令。它的设计直接决定了机器人的动作精度和流畅度。
2.4.1 动作表示
动作表示有三种主流方式:
- 离散表示 :将连续动作空间离散化为bin,转换为分类问题
- 优点:训练稳定、容易与Transformer结合
- 缺点:精度有限
- 连续表示 :直接回归连续的动作值
- 优点:精度高、动作平滑
- 缺点:训练难度大
- 混合表示 :不同控制维度使用不同表示
- 例如:连续的位置+离散的旋转+离散的夹爪开合
- 优点:兼顾精度和训练稳定性
2.4.2 动作解码
动作解码也有三种方式:
- 自回归解码 :一步一步生成动作,每个动作依赖之前的所有动作
- 优点:擅长长序列建模
- 缺点:延迟高
- 非自回归解码 :一次性生成整个动作序列
- 优点:速度快、延迟低
- 缺点:长序列一致性差
- 分块解码 :自回归地生成动作块,每个块内非自回归解码
- 优点:兼顾速度和长序列一致性
- 缺点:需要调整块大小
2.5 核心代码实现:一个现代VLA模型
下面是一个简化的现代VLA模型实现,采用了当前最流行的SigLIP+DINOv2混合视觉编码器 +Llama语言编码器 +混合架构:
python
import torch
import torch.nn as nn
from transformers import (
SiglipVisionModel,
Dinov2Model,
LlamaForCausalLM,
AutoTokenizer
)
class ModernVLA(nn.Module):
def __init__(
self,
siglip_model_name="google/siglip-base-patch16-224",
dinov2_model_name="facebook/dinov2-base",
llama_model_name="meta-llama/Llama-2-7b-chat-hf",
action_dim=7, # 6维位姿 + 1维夹爪
hidden_dim=768
):
super().__init__()
# 混合视觉编码器:SigLIP(语义) + DINOv2(几何)
self.siglip_encoder = SiglipVisionModel.from_pretrained(siglip_model_name)
self.dinov2_encoder = Dinov2Model.from_pretrained(dinov2_model_name)
# 视觉投影层:将两个编码器的输出融合
self.vision_proj = nn.Sequential(
nn.Linear(self.siglip_encoder.config.hidden_size +
self.dinov2_encoder.config.hidden_size, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim)
)
# 语言编码器和分词器
self.tokenizer = AutoTokenizer.from_pretrained(llama_model_name)
self.llama_encoder = LlamaForCausalLM.from_pretrained(
llama_model_name,
output_hidden_states=True
)
# 语言投影层
self.language_proj = nn.Linear(
self.llama_encoder.config.hidden_size, hidden_dim
)
# 跨模态注意力:融合视觉和语言特征
self.cross_attention = nn.MultiheadAttention(
hidden_dim, num_heads=8, batch_first=True
)
# 动作解码器:流匹配头(Flow Matching)
self.action_decoder = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim * 2),
nn.ReLU(),
nn.Linear(hidden_dim * 2, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, action_dim)
)
# 冻结预训练编码器的大部分参数,只微调顶层
self._freeze_pretrained_weights()
def _freeze_pretrained_weights(self):
# 冻结SigLIP的前8层
for param in self.siglip_encoder.vision_model.encoder.layers[:8].parameters():
param.requires_grad = False
# 冻结DINOv2的前8层
for param in self.dinov2_encoder.encoder.layers[:8].parameters():
param.requires_grad = False
# 冻结Llama的前24层
for param in self.llama_encoder.model.layers[:24].parameters():
param.requires_grad = False
def forward(self, images, instructions):
# 编码视觉输入
siglip_outputs = self.siglip_encoder(pixel_values=images)
siglip_features = siglip_outputs.last_hidden_state # [B, N1, d1]
dinov2_outputs = self.dinov2_encoder(pixel_values=images)
dinov2_features = dinov2_outputs.last_hidden_state # [B, N2, d2]
# 融合视觉特征
combined_vision_features = torch.cat(
[siglip_features, dinov2_features], dim=-1
)
vision_features = self.vision_proj(combined_vision_features) # [B, N1+N2, d]
# 编码语言输入
language_inputs = self.tokenizer(
instructions,
padding=True,
truncation=True,
return_tensors="pt"
).to(images.device)
language_outputs = self.llama_encoder(**language_inputs)
language_features = self.language_proj(
language_outputs.hidden_states[-1]
) # [B, M, d]
# 跨模态注意力:视觉特征作为query,语言特征作为key和value
fused_features, _ = self.cross_attention(
vision_features, language_features, language_features
)
# 全局平均池化得到全局特征
global_features = torch.mean(fused_features, dim=1)
# 解码动作
actions = self.action_decoder(global_features)
return actions
# 测试模型
model = ModernVLA()
images = torch.randn(2, 3, 224, 224) # 2张RGB图像
instructions = ["把红色的方块放到蓝色的盒子里", "拿起桌子上的杯子"]
actions = model(images, instructions)
print(f"预测动作形状: {actions.shape}") # 输出: torch.Size([2, 7])三、VLA模型的发展历程:从蹒跚学步到通用智能
VLA模型的发展可以清晰地分为四个阶段,如下图所示:
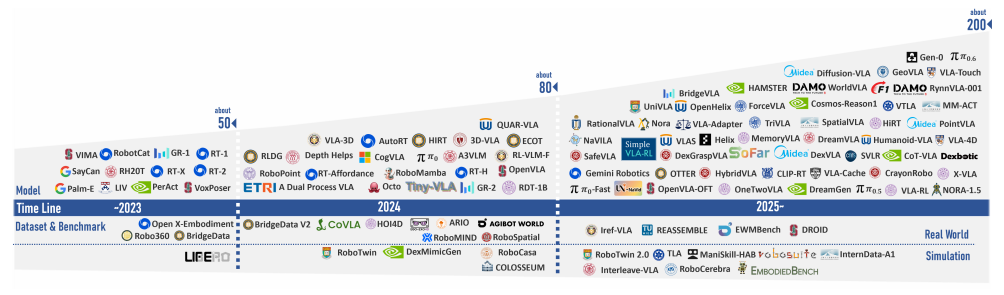
图2:VLA模型、数据集和基准的时间线(2022-2025)(出处:原文Figure 2)
3.1 萌芽期(2017-2019):视觉-语言导航的诞生
- 2018年:VLN(Vision-and-Language Navigation)基准提出,首次将语言指令与视觉导航结合起来
- 2018年:EmbodiedQA提出,定义了具身问答任务
- 特点:主要关注导航任务,动作空间简单(前后左右),没有复杂的操作
3.2 成长期(2020-2021):从导航到操作
- 2020年:ALFRED基准提出,首次引入了需要与物体交互的长horizon任务
- 2021年:CLIPort发表,首次将预训练的视觉-语言模型应用于机器人操作任务
- 特点:开始关注操作任务,引入了预训练模型,零样本泛化能力初步显现
3.3 爆发期(2022-2023):大模型时代的到来
- 2022年:SayCan发表,首次将LLM用于机器人高层规划
- 2022年:RT-1发表,第一个真正意义上的端到端VLA模型
- 2023年:RT-2发表,首次将VLM扩展到机器人控制
- 2023年:Diffusion Policy发表,扩散模型成为动作生成的主流范式
- 2023年:Open X-Embodiment数据集发布,跨机器人学习成为可能
- 特点:大模型全面进入VLA领域,端到端架构成为主流,泛化能力大幅提升
3.4 成熟期(2024-至今):通用机器人智能的黎明
- 2024年:Octo发表,第一个开源的通用机器人策略
- 2024年:OpenVLA发表,第一个开源的7B参数VLA模型
- 2024年:π₀发表,首次将流匹配用于VLA动作生成
- 2025年:Humanoid-VLA和GR00T N1发表,VLA扩展到人形机器人控制
- 特点:开源模型大量涌现,性能接近闭源模型,开始应用于人形机器人和工业场景
四、VLA研究的五大核心挑战:通往通用机器人的拦路虎
虽然VLA模型取得了巨大的进步,但仍然面临着许多根本性的挑战。这篇综述将这些挑战归纳为五大类,如下图所示:
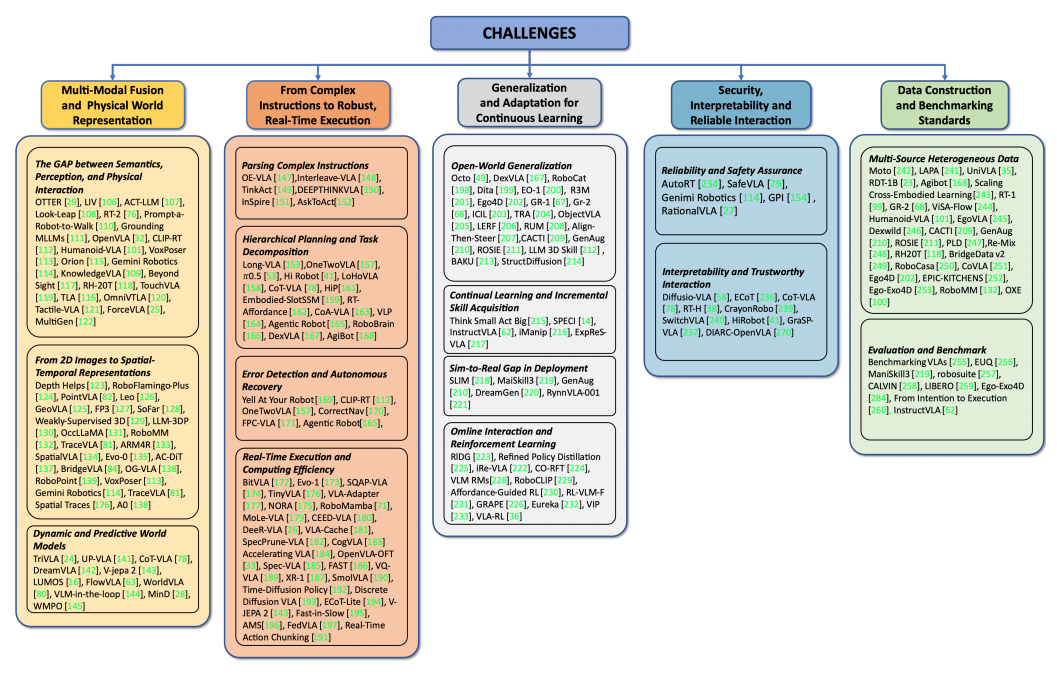
图3:VLA挑战分类体系(出处:原文Figure 3)
4.1 多模态对齐与物理世界建模
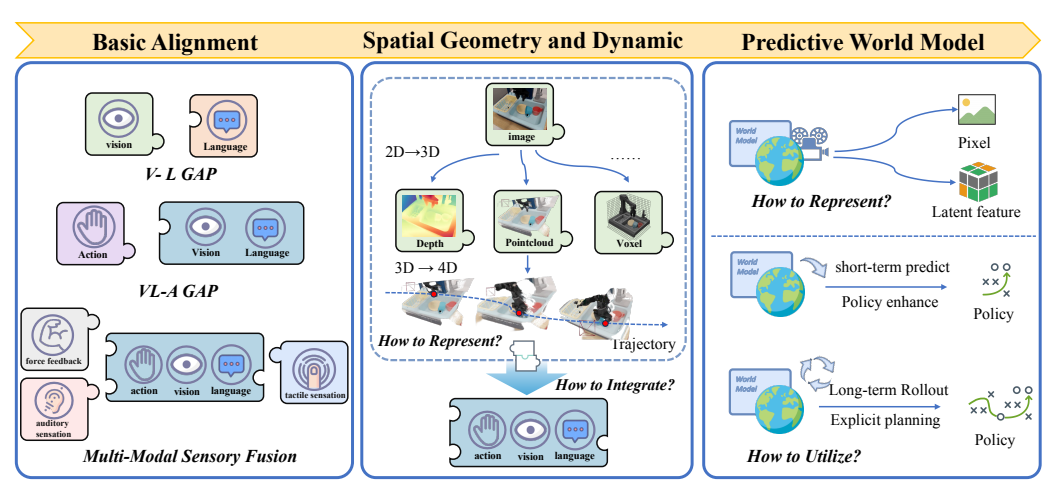
图4:多模态对齐与物理世界建模挑战(出处:原文Figure 4)
这是VLA模型最基础也是最核心的挑战。它可以分解为三个子问题:
- 视觉-语言鸿沟:如何让模型理解"红色杯子"这几个字对应图像中的哪个物体?
- 视觉-语言-动作鸿沟:如何让模型理解"拿起"这个动词对应什么样的手臂运动?
- 从2D图像到3D时空表示:如何让2D预训练的模型获得3D空间理解能力?
当前解决方案:
- 混合视觉编码器(SigLIP+DINOv2)
- 点云输入和3D VLM
- 世界模型预测未来状态
未来方向:原生多模态架构,从训练开始就将视觉、语言和动作放在同一个token空间中。
4.2 指令跟随、规划与鲁棒实时执行
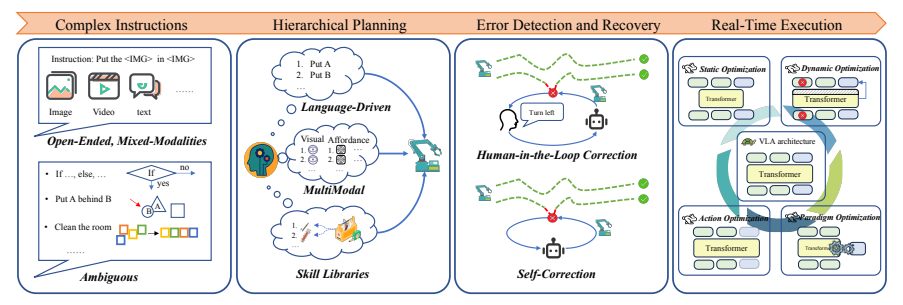
图5:指令跟随与执行挑战(出处:原文Figure 5)
这个挑战关注的是模型如何理解复杂指令、进行长horizon规划,并在真实世界中可靠执行。它包括:
- 复杂指令解析:如何理解模糊、歧义、多模态的指令?
- 分层规划与任务分解:如何将"打扫房间"这样的大任务分解为可执行的小步骤?
- 错误检测与自主恢复:当任务失败时,如何自动发现并纠正?
- 实时执行与计算效率:如何在保证性能的同时降低推理延迟?
当前解决方案:
- 分层架构:VLM做高层规划,单独的控制器做低层执行
- 思维链(CoT)推理:生成中间步骤或子目标图像
- 模型压缩与量化:1位、4位量化,蒸馏小模型
- 非自回归解码:并行生成动作序列
未来方向:自适应决策系统,根据任务复杂度自动决定思考的深度。
4.3 从泛化到持续适应
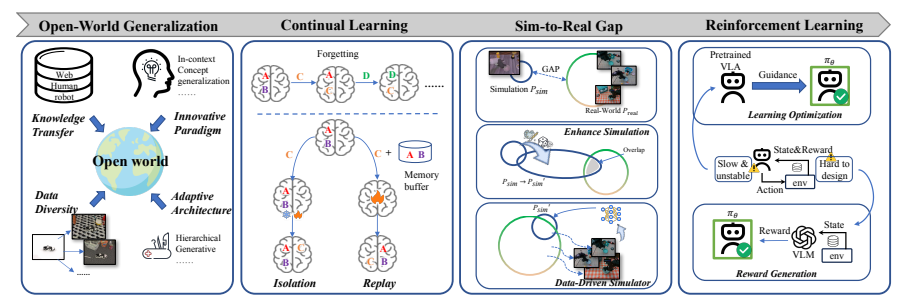
图6:泛化与持续学习挑战(出处:原文Figure 6)
这个挑战关注的是模型如何在新环境、新任务、新机器人上表现良好,并在部署后继续学习。它包括:
- 开放世界泛化:如何处理训练中没有见过的物体和场景?
- 持续学习与增量技能获取:如何学习新技能而不忘记旧技能?
- 模拟到真实迁移:如何将在模拟器中学到的技能迁移到真实世界?
- 在线交互与强化学习:如何通过与环境的交互来改进策略?
当前解决方案:
- 大规模多任务/多机器人预训练
- 互联网视频知识迁移
- 参数隔离与经验重放
- VLM作为奖励函数自动生成奖励
未来方向:形态无关表示,一个统一的大脑可以控制任何形态的机器人。
4.4 安全、可解释性与可靠交互

图7:安全与可解释性挑战(出处:原文Figure 7)
这个挑战关注的是如何让VLA模型安全、可靠、值得信任。它包括:
- 可靠性与安全保障:如何防止机器人执行危险动作?
- 可解释性:如何让人类理解机器人为什么做出某个决策?
- 可信交互:如何让人类与机器人进行自然、流畅的协作?
当前解决方案:
- 基于约束的安全范式:机器人宪法、安全阈值
- 基于学习的对齐范式:宪法AI、安全强化学习
- 思维链推理:输出自然语言解释
- 行为可预测性设计:让机器人的动作符合人类预期
未来方向:内在不确定性感知,机器人能够知道自己什么时候不知道,并主动寻求人类帮助。
4.5 数据构建与基准测试标准
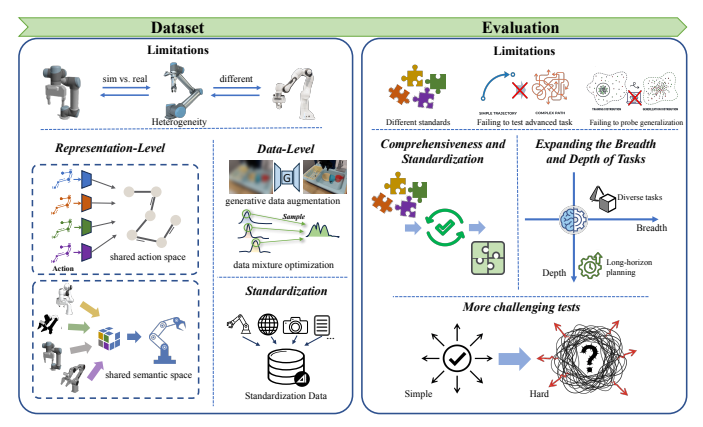
图8:数据与基准挑战(出处:原文Figure 8)
这个挑战是所有其他挑战的基础。VLA模型的能力最终受限于训练数据的规模和质量。它包括:
- 多源异构数据统一:如何整合来自不同机器人、不同环境的数据?
- 数据增强与优化:如何在有限的真实数据下提高模型性能?
- 基准测试标准化:如何公平、全面地评估VLA模型的能力?
当前解决方案:
- 表示级统一:学习共享的动作和状态表示
- 生成式数据增强:用扩散模型生成多样化的训练数据
- 标准化数据集:Open X-Embodiment、BridgeData V2
- 全面的基准测试:EmbodiedBench、EWMBench
未来方向:模拟优先、失败中心的范式,用模拟器生成无限数据,将失败作为重要的学习信号。
五、VLA模型的典型应用
VLA模型已经开始从实验室走向实际应用,在两个领域表现最为突出:
5.1 家庭服务机器人
家庭环境是VLA模型的天然试验场。未来的家庭机器人将能够:
- 理解自然语言指令,执行各种家务
- 识别和操作成千上万种不同的 household 物品
- 适应不同家庭的布局和习惯
- 与人类进行自然的交流和协作
案例:特斯拉Optimus人形机器人就是基于VLA模型设计的,它已经能够执行折叠衣服、搬运物品、浇花等复杂的家务任务。
5.2 工业与物流机器人
工业环境对机器人的精度、可靠性和安全性要求更高。VLA模型正在彻底改变工业自动化:
- 快速切换任务:不需要重新编程,只需要通过语言指令
- 处理多样化的工件:可以识别和操作不同形状、大小的物体
- 协作机器人:可以与人类工人安全地并肩工作
- 自主故障检测与恢复:当出现问题时可以自动解决
案例:亚马逊的仓库机器人已经开始使用VLA模型来处理各种不同的商品,大大提高了仓库的运营效率。
六、未来展望:通用机器人智能的黎明
这篇综述最后指出,VLA模型正处于一个关键的转折点。在未来几年,我们将看到以下几个重要的趋势:
- 形态无关的通用机器人大脑:一个统一的模型可以控制任何形态的机器人,从机械臂到四足机器人再到人形机器人。
- 自主开放进化:机器人将能够在部署后主动探索环境,发现自己的知识缺口,并自动生成训练数据来改进自己。
- 内在物理理解:VLA模型将从模仿表面行为发展到真正理解物理规律,能够预测动作的后果并进行因果推理。
- 可信的人机协作:机器人将变得更加安全、可解释和可预测,成为人类真正的合作伙伴。
总结
这篇综述为我们提供了一个全面、系统、深入的VLA技术全景图。它从基础模块到发展里程碑,再到核心挑战,清晰地展示了VLA领域的过去、现在和未来。
VLA模型是实现通用机器人智能的关键一步。虽然我们仍然面临着许多挑战,但技术的进步速度正在不断加快。在不久的将来,我们将会看到越来越多的VLA机器人走进我们的生活和工作,为我们提供各种服务。